[DL기초] Softmax의 성질과 관련된 마스크 행렬의 덧셈
들어가기에 앞서, 기본적인 어텐션 연산에 대한 설명은 해당 포스트에서 하지 않겠다!
대신... 공부를 하다가 간과했던 부분이 알고보니 꽤 재밌는 내용이어서 가지고 왔다! 사실 제발 아무도 안봤으면 좋겠다. 지금 당장은 글로 정리가 좀 덜된 것 같아서 부끄럽슨..
...
이어가겠기니?

기본적인 Attention 연산의 식은 다음과 같다: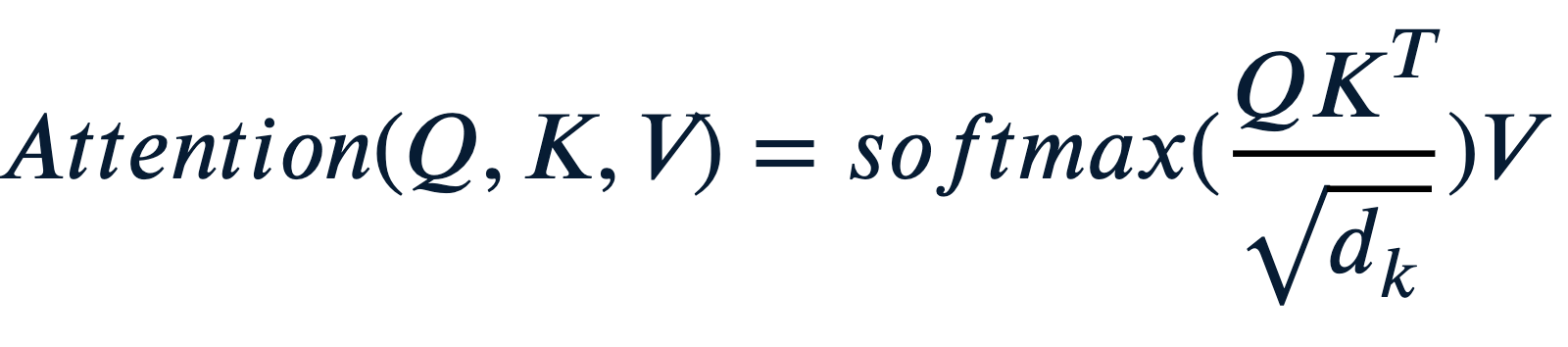
이때,
-
: Attention Score
- shape:
두 시퀀스 사이의 연관도
- shape:
-
: Attention Weight
- shape:
어텐션 스코어의 확률적 분포
이때,[PAD]토큰이 있는 경우나 Causal하게 다음 토큰을 예측하도록 할 경우, 이를 마스크 처리를 해야된다. 그 마스크에 대한 정보가 에 담겨져있다. 아래서 더 자세히 설명하겠다.
- shape:
-
: Attention Output
- shape:
최종적인 어텐션 스코어의 행렬. 이때 열에는 Key와 Value의 압축된 정보가 포함되어 있다.
- shape:
이렇게 두 개의 시퀀스의 연관도를 측정하는 Attention 연산이 진행된다.
오늘 이야기할 내용은 특히 를 계산할 때 [PAD]토큰이나 Causal 마스킹 처리를 할 때 어떻게 마스킹 행렬을 적용하고, 연산이 되는지에 대한 내용이다.
기본적으로 Mask 행렬은 아래와 같은 형식이다. 이 행렬은 하나씩 이 줄어드는 것과 마지막 행의 마스크 값이 모두 0인 것으로 보아, Causal Masking에 대한 예시이다.
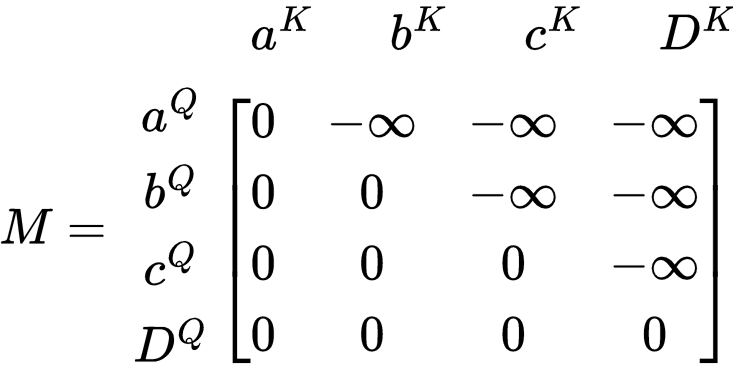 [출처] https://gmongaras.medium.com/how-do-self-attention-masks-work-72ed9382510f
[출처] https://gmongaras.medium.com/how-do-self-attention-masks-work-72ed9382510f
식에서도 알 수 있듯, 우리는 Scale된 Attention Score에 해당 Mask 행렬을 더한 후, 확률 분포값인 Attention Weight로 변환하는 연산을 수행한다.
이때 생각해봐야될 것은 크게 세 가지가 있다.
1. 마스킹을 하는 이유와 원리
패딩 마스킹의 목표는 모델이 의미없는 패딩 토큰이나 참조하면 안되는 토큰에 일절 주의(Attention)를 주지 않게 하기 위해 해당 토큰의 최종 Attention Weight를 0으로 만드는 것이다.
Attention Weight가 0임은 곧 각 토큰간의 연관성, 예측 확률이 낮아도 된다는 뜻이기 때문이다.
2. 의 성질
[출처] https://botpenguin.com/glossary/softmax-function
Softmax는 그룹 내 확률을 확률 분포로 만들어주는 정규화 과정에 적용되는 내용이다. 사이의 열린 구간의 확률값으로 출력값이 완전히 0이거나 1이 되진 못하며, 1에 매우 가까운 출력값을 갖는다.
또한, Softmax는 양수/음수로 나누어 증폭/감소 시키는 것이 아닌, 가장 큰 값을 다른 값보다 훨씬 더 높게 증폭시키고, 상대적으로 작은 값들은 모두 0에 가깝게 낮추는 역할을 한다.
Softmax 함수의 출력인 가 0이 되기 위한 입력인 의 조건은 다음과 같다.
따라서, Softmax의 출력을 0으로 만들기 위해서는 입력 점수 를 반드시 로 만들어야된다. 주어진 점수 분포들의 합을 1로 만드는 확률적 분포로 정규화 시키는 것이 이 과정의 의의이다.
여기서 일차원적으로 생각할 수 있는 내용은 ~..~....
사실 내가 한..
- 0을 곱하는 것도 유효하지 않니
- 을 곱하는 것도 유효하지 않니
였다.
3. 지수함수(Exponential Function)의 성질
[출처] https://en.wikipedia.org/wiki/Exponential_function
지수함수는 입력값을 를 열린 구간으로 가지며, 출력값은 (0, )을 갖는다. 0으로는 닿을 수 없다. 해당 함수는 입력값이 0일때, 1이라는 완전한 양수의 값을 가진다. 위의 Softmax성질과 이 지수함수의 성질을 함께 살펴보면, 왜 Scaled Attention Score에 Mask 행렬을 "더하는 지" 확실히 알 수 있다.
- Scaled Attention Score에 0을 곱할 경우
제일 멍청한 생각이었다.. 이렇게 되면 Softmax의 입력은 0이 될 것이고, 의 양수 출력값을 가진다. 결론적으로 양수 가중치가 된다.
Softmax의 핵심은 총합이 1인 확률 분포를 만드는 것이다. 유효한 토큰들에 비해서 패딩 토큰이 아무리 작은 양수의 값을 가져 정규화로 약간의 무시가 된다고 해도, 패딩 토큰이 무의미하게 전체 주의력의 일부를 강제로 가져가도록 허용하게 되는 것이다. 이로 인해 유효한 토큰들 사이의 상대적인 주의력 분배가 미세하게 왜곡될 위험이 있다는 것이다......
- Scaled Attention Score에 을 곱핧 경우
쩝 이 또한 멍청한 생각이었다. Attention Score가 모두 양수라는 보장이 어디있나? 이미 음수로 나온 "정말 관계 없는" 토큰을 되려 증폭시키고, 확률 분포로 변환할 때는 주의해야되는 토큰들만을 모두 배제해버리는 역효과가 나는 상황이었다.
이렇듯 [PAD] 토큰이 있을 때나 Causal한 생성을 목적으로 하여 마스킹을 해야되는 경우, 주의해야되는 토큰에서 완전히 배제해야되기 때문에 마스킹 행렬을 더해주는 방식으로 이를 돕는다.
아~~ 나는 이 섬세한 하나하나가 너무 신기했는데 나만 신기했다면 ~~
ㅠㅠ
공부 더 열심히 해야겠은..
명작은 역시 뭘 파도파도 계속 나오는 것 같다.....
