[RL] GRPO와 PPO

오늘은 시간이 없으니 GRPO와 PPO에 대해 공부한 내용을 개념/수식적으로 간략히 정리하는 글을 작성하겠다.
오늘은 추석 전날이기 때문... ~
우선은~~ 기본적인 개념적 강화학습과 Markov Decision Process(MDP)에 대한 내용을 알고있다고 가정하겠다.
간략히 설명하자면 MDP는 Agent가 Environment과 상호작용하는 과정을 수학적으로 모델링한 것으로, 아래와 같은 다섯 가지 요소로 구성된 튜플 형식이다.
1. 상태 집합 (: States)
Agent가 처해질 수 있는 모든 가능한 상황의 집합 (e.g., 로봇 센서 값 등)
2. 행동 집합 (: Actions)
Agent가 각 State에서 취할 수 있는 모든 가능한 행동의 집합 (e.g., 왼쪽으로 이동, 오른쪽으로 이동, 점프 등)
3. 상태 전이 확률 (: Transition Probability)
Agent가 특정 State 에서 행동 를 취했을 때, 다음 상태인 로 이동할 확률
이때, 다음 상태 가 현재 상태인 와 행동 에만 의존하며, 과거의 상태에는 영향을 받지 않는다는 가정을 Markov Property에 근거한 수식임
4. 보상 함수 (: Reward Function)
Agent가 상태 에서 행동 를 취하고, 새로운 상태인 로 전이했을 때 받게되는 즉각적인 Scalar 값
5. 감가율 (: Discount Factor)
미래에 받을 보상의 가치를 현재 시점에서 얼마나 할인하여 평가할지 결정하는 값으로, 의 범위를 갖는다.
이때, $\lambda가 1에 가까울수록 먼 미래의 보상도 중요하게 여기는 것이다.
ㅠㅠ.. 여담이지만.. 이거 처음에 잘못된 기술 블로그를 봐서 할인율로 해석하는 줄 알았다는 사실... 부끄럽듭니다.... 다들 검수도 안하고 GPT 복붙하는건 너무한거 아닙니까....
아무뜬 이 다섯 요소를 바탕으로 강화학습이 정의되며, 여기서 중요한 Policy는 상태 에서 Agent가 어떤 행동 를 취할지를 결정하는 규칙이다.
이를 기반으로 학습이 진행된다.
- Polcy 정의 수식
즉, 이 정책은 상태 에서 행동 를 취할 확률 분포이다.
PPO
Proximal Policy Optimization
: 정책 경사(Policy Gradient) 기반의 강화 학습 알고리즘 중 제일 일반적이고 보편적인 알고리즘
- 기본 PPO 수식:
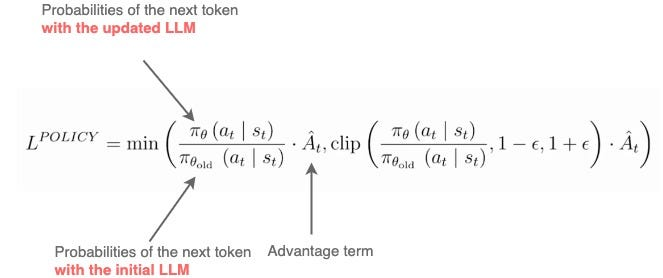
1. 정책경사(Policy Gradient)?
PPO는 Agent의 행동을 결정하는 정책 를 직접 최적화하여 누적 보상 Cumulative Reward를 최대화하는 것을 목표로 한다.
2. 안정적 업데이트
이 PPO 알고리즘이 일반적으로 많이 사용되는 강화학습 알고리즘인 이유는 기존의 TRPO의 내용을 기반으로 하지만 구현이 훨씬 간단하며 안정적인 업데이트가 가능하다는 장점이 있기 때문이다.
이 알고리즘은 정책을 업데이트 할 때, 이전 정책()과 현재 정책() 간의 차이가 너무 커지는 것을 KL divergence로 방지하는 역할을 한다.
♨️ KL Divergence
정책 업데이트 폭을 제한하여 안정성을 확보하는 도구로, 일반적으로는 PPO의 목적함수에 KL Divergence를 포함하진 않으나, 아래의 Clipping을 사용하여 정책 비율(를 일정 범위 내로 제한한다.
3. 클리핑 목적 함수(Clipped Surrogate Objective)
PPO는 정책 비율()을 일정 범위()로 Clipping하여 정책이 급격히 변화하는 것을 막고, 안정적인 학습을 할 수 있도록 유도한다.
이는 복잡한 KL Divergence의 제약을 우회하면서도 그 효과를 얻는 방법이다.
4. 어드밴티지 추정(Advantage Estimation)
정책 업데이트에서 사용되는 이점(Advantage) 함수()는 특정 상태 에서 취한 행동 이 평균적인 행동보다 얼마나 더 좋았는지를 나타내는 함수이다.
- Advantage Function 수식:
()
이때, PPO에서는 일반적으로 가치 함수(Value Function, Critic) 를 별도로 학습해서 이점 추정의 베이스라인으로 사용한다.
GRPO
Group Relative Policy Optimization
GRPO는 주로 LLM의 정렬(Alignment)과 같은 특정 환경에서 PPO의 단점을 보완하기 위해 제안된 알고리즘이다.
GRPO는 PPO와 동일하게 정책을 최적화하지만, Advantage Estimation 방식에서 차이점이 있다.
- 기본 GRPO 수식:
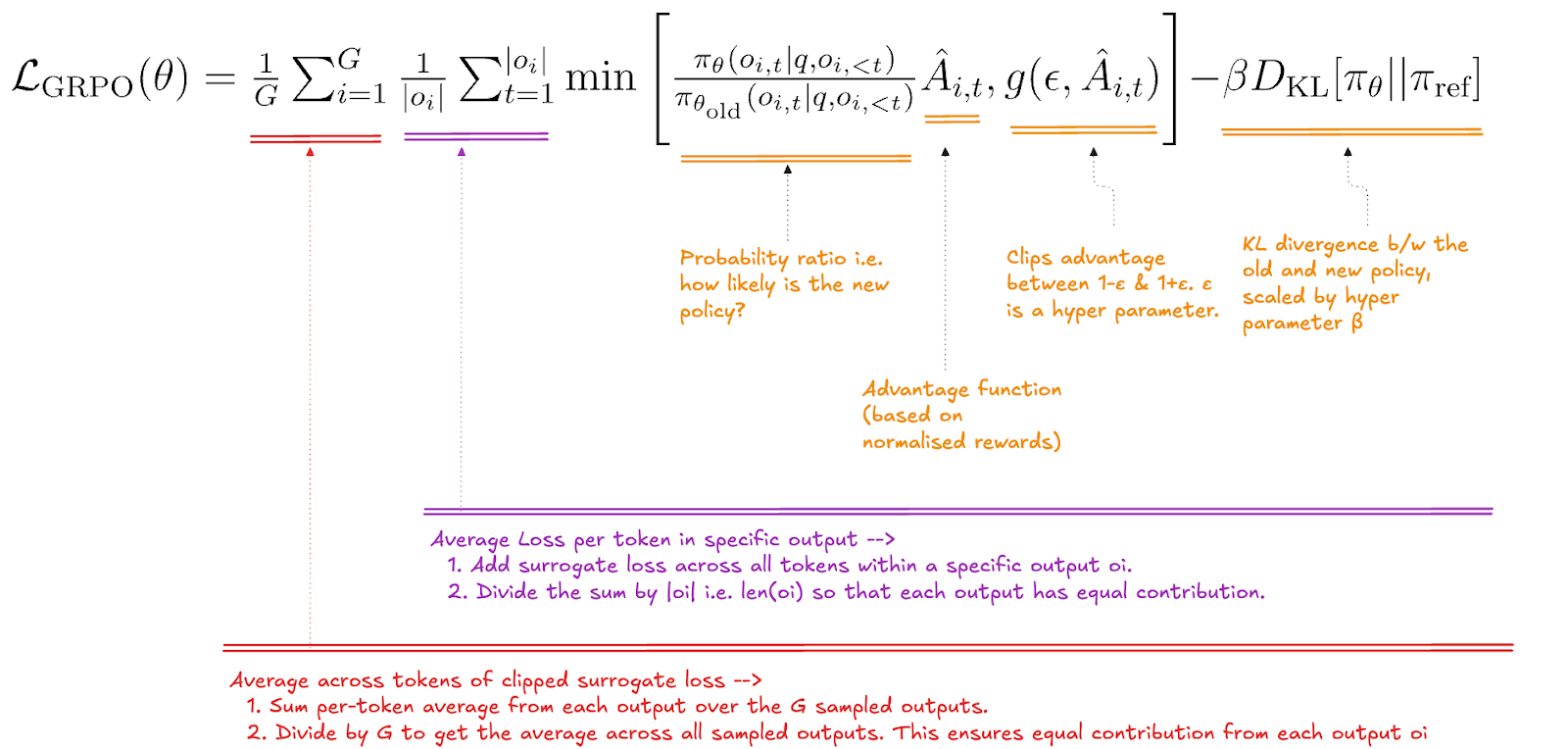
이렇듯 GRPO는 PPO와 마찬가지로 정책의 안정적인 업데이트를 위해 KL Divergence 페널티 항을 목적 함수에 포함하는 것이 일반적이다.
좀 더 간략히 수식으로 작성하자면 GRPO의 목적 함수는 다음과 같다.
이때,
- : GRPO가 새롭게 정의한 이점을 사용하는 정책 목적 함수
- : PPO와 동일하게 정책의 변화를 제어하는 KL Divergence 페널티 항
PPO/GRPO의 핵심 차이점
- Critic Network 제거:
GRPO는 PPO와 다르게 별도의 Critic(가치 함수) 네트워크를 학습하지 않는다. - Group-based Advantage Estimation(그룹 기반 이점 추정):
하나의 상태()에 대해 현재 정책()으로부터 여러 개의 응답(행동() 그룹)을 샘플링하고, 그룹 내의 보상을 상호 비교하여 상대적인 이점(Relative Advantage)를 계산한다.
- 기존 Advantage 수식:
(정규화된 보상)
이 그룹 기반 상대 보상이 의 역할을 대체한다.따라서, GRPO의 이점 함수 는 다음과 같은 그룹 보상 에 대한 정규화로 정의됨.
- 수식:
이에 대한 의의는 다음과 같다.
- Critic 불필요:
Critic, 가 없으므로 를 학습하는 데 필요한 추가적인 신경망과 메모리가 필요 없다. 따라서 LLM처럼 모델 크기가 매우 클 때 자원 효율성이 극대화됨.
- 안정적인 베이스라인:
PPO에서 는 학습되는 값으로, 불안정하거나 노이즈가 많을 수 있다.
하지만 GRPO는 샘플링된 그룹의 통계랑을 기준으로 삼기 때문에 보다 적은 범위이므로, 안정적이고 On-Policy에 기반한 베이스라인을 사용하게 됨.
- LLM의 Alignment에 최적화:
RLHF와 같은 LLM 정렬 환경에서는 최종 출력 시퀀스에 대해서만 보상()이 주어지는 경우가 많음.
하지만 GRPO는 이 최종 보상을 토큰 단위 이점()으로 역전파할 때, GAE 대신 이 정규화된 상대 보상을 모든 토큰에 동일하게 적용하여, 학습을 보다 효율적이고 효과적으로 만듦.
- 수식:
즉 ~~ PPO가 가치 네트워크를 학습해서 절대적인 기준선을 설정한다면, GRPO는 샘플링된 그룹의 평균을 상대적인 기준선으로 설정하여 이점 함수를 계산하는 방식이다.....
처음에 이걸 알고 너무 신기해서 멍때림.. 멍~~..
오늘의 한마디..
모든 것은... 이전 사건의 확률에 기반한다.....
확률... 확률...... 확률........
