1. LoRA 개요
LoRA는 대형 언어 모델(LLM)의 일부 선형 변환 레이어에 “저용량 어댑터”를 추가하여, 모델 파라미터를 거의 건드리지 않으면서 새로운 태스크로 미세 조정(fine-tuning)할 수 있는 기술입니다.
- 장점: 전체 모델을 재학습·저장할 필요 없이, 어댑터(작은 행렬)만 저장 → 빠른 실험, 경량 배포
- 핵심 아이디어: 원본 가중치 를 아래의 A 형태로 두되, B로 Low-Rank 행렬 분해해서 학습 파라미터 수를 대폭 줄임
(A)
(B)
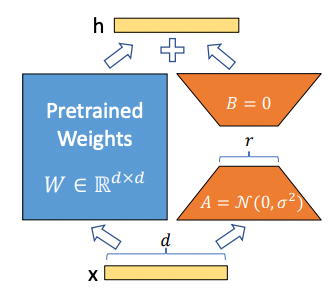 <그림1.> LoRA Matrix Multiplication
<그림1.> LoRA Matrix Multiplication
2. 주요 하이퍼파라미터
각 파라미터 역할
-
r (rank): 어댑터 행렬 , 의 랭크 (내부차원)
-
α (alpha): 학습 시 의 스케일링 인자. 학습률 보정용 스케일 팩터
-
dropout: LoRA 어댑터의 드롭아웃 비율. 과적합 방지를 위해 어댑터 활성화 일부를 무작위 차단
이때, rank와 alpha는 2/4, 4/8과 같은 형태로 주로 조정하며, dropout은 0.00~0...
이유:
2.1. r (Rank)
- 정의: LoRA가 원본 가중치에 더하는 추가 저랭크 행렬의 내적 차원
- 공식: ,
이때,
A:
B:
- 총 학습 파라미터 수:
- 효과:
- r↑ → 표현 용량 증가 → 더 복잡한 태스크 학습 가능
- r↓ → 파라미터 절감(up to ) → 속도 및 메모리 효율 좋아짐 - 일반적 설정 범위:
- 소규모 태스크(문법 교정, 요약) → r=4~8
- 중규모 태스크(요약+질의응답) → r=16~32
- 데이터·컴퓨팅 여유가 충분하면 r=64까지 실험
2.2. α (Alpha)
- 정의: LoRA로 학습된 를 스케일하는 하이퍼파라미터
- 작동 원리:
or
형태로 구현
- 이유: 랭크 r를 늘리면 가 커지므로, 학습 안정화를 위해 스케일링
- 추천 값:
- 보통 (default)
- 이 작으면 를 작게 유지, 이 크면 를 키워 실효 학습률 유지e.g.,) r=4 α=8, r=16 α=32
2.3. dropout
- 정의: 어댑터가 학습 중 무작위로 일부 뉴런을 비활성화하는 비율
- 역할:
- 과적합(overfit) 방지
- 다양한 어댑터 조합 학습 유도 → 일반화 성능 ↑ - 추천 범위:
- 데이터 적을 때 → 0.1‒0.2 (과적합 위험↑)
- 데이터 많거나 태스크 단순 → 0.0‒0.05 - 사용 예시:
LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.1, # 10% 확률로 어댑터 비활성화
target_modules=[...],
task_type="CAUSAL_LM",
)3. 하이퍼파라미터 튜닝 팁
- 먼저 r 실험
- 작은 r (4, 8) → 학습 속도 빠름
- 성능 모니터링하며 r 증가
- α로 학습률 보정
- r이 증가할 때 α를 선형 비례로 증가시켜 안정적 학습
- dropout으로 과적합 제어
- validation loss가 train loss보다 크게 차이날 때 dropout↑
- 조합 전략
- r=8, α=16, dropout=0.05부터 시작
- 최종 모델 성능에 따라 하나씩 조정
4. 시각화 예시
| 조합 | 파라미터 수 절감량 | 기대 성능 | 메모리 사용량 |
|---|---|---|---|
| 99.95%↓ | 중간 | 낮음 | |
| 99.9%↓ | 우수 | 보통 | |
| 99.8%↓ | 최고 | 높음 |
5. 결론
LoRA 하이퍼파라미터는
- r: 모델 적응력 ↔ 파라미터 효율
- α: 학습 안정화 스케일링
- dropout: 일반화 제어
이 세 가지를 순차적·단계적으로 튜닝하면, 적은 비용으로도 원하는 태스크에서 최적 성능을 얻을 수 있다.

베풀기 위해 더 많이 공부하고 성장하기 ᓚᘏᗢ: 공부 정리용