[논문 리뷰] Graph-constrained Reasoning: Faithful Reasoning on Knowledge Graphs with Large Language Models
미완성본
본 논문은 ICML 2025 포스터 발표로 소개된 논문으로, 대형 언어모델과 지식 그래프를 결합하여 추론의 신뢰성을 높인 연구를 다룬다.
1. Background
LLM은 뛰어난 추론 능력을 가지고 있다. 하지만 모델의 활용도가 높아질수록 환각(Hallucination) 현상에 대한 경각심 또한 커지고 있다. 이때 언어 모델의 환각이란, 사실과 다르거나 논리적이지 않은 잘못된 추론을 하는 현상을 말한다.
이를 해결하기 위해 최근들어 KG (Knoledge Graph, 지식 그래프)의 활용과 관련 연구들이 활발히 진행되고 있다. 하지만 방대한 지식 그래프에서 정확한 정보를 검색해오거나 효율적으로 탐색하는 데에는 여전히 한계가 있다.
2. Preliminary
따라서 본 저자들은 이를 해결하기 위해 'Graph-Constrained Reasoning, GCR)'이라는 그래프 제약 추론 프레임워크를 제안한다.
이를 좀 더 자세히 알기 위해서는 기존의 KG 기반 LLM 추론 방식에 대해 짚고 넘어가고자 한다.
a. Related Work
- Retrieval-based (e.g., RoG--Linhao Luo et al, 2024): 외부 Retriever로 KG에서 관련 사실을 검색해서 LLM 입력에 넣는 방식.
하지만 Retriever이 부정확하거나 그래프 구조를 반영하지 못하며, KG 밖의 경로를 생성할 수 있다는 취약점이 있다. - Agent-based (e.g., ToG--Jiashou Sun et al, 2023): LLM을 에이전트처럼 활용해 KG를 반복적으로 탐색해 추론 경로를 찾는 방식.
하지만 LLM이 KG와 여러 번 상호작용해야 돼, 비용과 지연 문제에 취약하다.
하지만 대표적인 KG 기반 추론 방식인 RoG조차 KG를 기반으로 추론할 때 33%의 환각 반응이 관찰된다고 한다. 그 중 18%는 형식 오류(Format Error), 15%는 KG에 존재하지 않는 관계를 지어내는 관계 오류(Relation Error)로 나타났다.
이 점이 본 논문의 직접적인 동기이다. 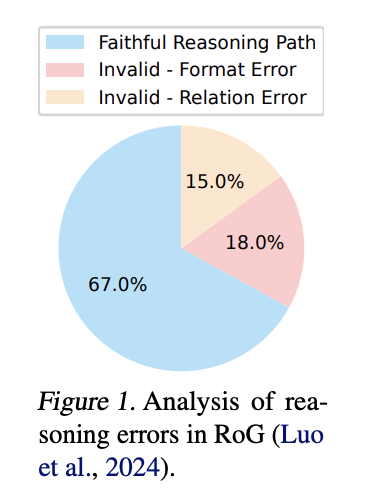
위의 방식들을 적용해 KG를 활용한 질의 응답 추론 해결 문제가 활발히 진행됨.
따라서 KG-constrained Zero-hallucination를 도입하고자 한다. 이는 지식 그래프 제약 기반으로 하여 환각을 줄이는 방식이다. 지식 그래프 안의 사실들은 대개 검증되었단 점을 활용해(Nguyen et al., 2024), LLM 추론의 신뢰성을 평가하는 믿을 수 있는 출처가 된다. 따라서 LLM이 생성한 추론 경로가 지식 그래프 내에 fully grounded 해야되며, 이를 통해 추론 과정이 실제 사실과 정확히 일치하도록 보장하는 방식을 본 논문에서 적용하려는 것이다.
b. CoT
CoT는 Chain-of-thought의 약어로, "답을 바로 내는 것이 아닌, 추론 과정 z를 먼저 생성하라."는 것이다.
수식으로 나타냈을 때는 아래와 같다.
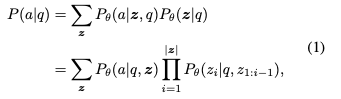
- : LLM 파라미터
- : 추론 과정
- : i번째 추론 단계 (토큰)
- : 입력 질문
- : 최종 답안
상세하게 보기 위해서 예시를 들겠다. 우선 KG의 트리플렛이 아래와 같이 정의가 된다.
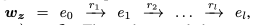
가령
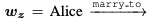
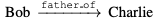 이런 관계가 있다고 하면, "Alice는 Bob이랑 결혼을 하는데, Bob은 Charlie의 아버지이다." 그럼 "Alice는 Charlie의 어머니이기도 하다."라는 추론 또한 가능해진다.
이런 관계가 있다고 하면, "Alice는 Bob이랑 결혼을 하는데, Bob은 Charlie의 아버지이다." 그럼 "Alice는 Charlie의 어머니이기도 하다."라는 추론 또한 가능해진다.
이러한 과정이 Chain of Though, CoT이다.
위의 식과 연결해서 생각해보면, "Alice의 아들은?"이라는 쿼리가 주어졌을 때, 생성() 할 때는 'Alice는 Bob과 결혼'이라는 노드와 관계를 통해 할 수 있다. 이후 생성(), "Bob은 Charlie의 아버지"를 참조한....
그러면 결론적으로 는 토큰 단위 auto-regressive한 생성을 하게 되고 위의 식이 성립한다.
3. Methodology
효율성에도 불구하고 LLM의 추론 능력을 높이기 위해 '생각의 사슬(Chain-of-Thought, CoT)'을 많이 쓰지만, 이는 단어를 한 단계씩 예측하며(Autoregressively) 문장을 잇는 방식이라 오류가 누적되면 결국 '환각(Hallucination)'으로 이어진다.
따라서 이 "KG를 참조하되 디코딩 과정에서 문제가 발생하는 이 문제점"을 신뢰성있는 추론이 가능하도록 하기 위해 본 저자들은 KG-enhanced Reasoning 기법을 활용한 방법론을 제안하였다. KG-enhanced Reasoning란 말 그대로 KG의 지식 구조를 사용하되, LLM의 추론 성능을 향상시키는 방법이다.
이는 아래와 같이 정의될 수 있으며, 일반적으로 KG의 추론 경로 를 찾는 과정이다.
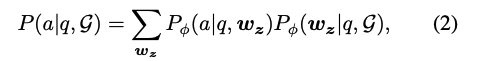
이를 위해서 앞서 Preliminary에서 소개한 'Retrieval-based'와 'Agent-based' 패러다임이 사용되었지만 각각 한계점이 존재했다.
- Retrieval-based Paradigm: RAG처럼 외부 검색기를 사용하여 경로를 찾아오지만 검색기의 성능에 의존하는 단점이 있다. 따라서 검색기가 엉뚱한 추론 경로를 가져오면 LLM 또한 엉뚱한 응답만 생성한다.
- Agent-based Paradigm: LLM에게 지식 그래프 내부를 탐색하도록 시키는 방법이나, 모델이 매 턴마다 생각하고 움직여야하므로 computing resource가 많이 들고, 결정적으로 너무 느리다는 단점이 있다.
따라서 검색 기반(Retrieval)이나 에이전트(Agent) 기반 방식의 한계점을 극복하고자, 이 논문은 아예 LLM이 텍스트를 생성하는 디코딩 과정 자체에 지식 그래프(KG)를 직접 밀어 넣는 그래프 제약 추론(GCR)이라는 새로운 패러다임을 제안한다.
GCR의 작동 방식은 아래와 같다.
1. Entity 추출 + BFS 경로 수집
질문 에서 topic entity 를 추출하고, 위에서 최대 -hop BFS를 수행해 모든 경로 집합 를 수집한다.
BFS Algorithm
BFS(Breadth-First Search)는 그래프나 트리 구조에서 데이터를 탐색할 때 사용하는 대표적인 알고리즘이다. 직관적으로 말하자면 "나랑 제일 가까운 이웃부터 다 확인하고, 그 다음 멀리 있는 애들로 넘어가는 방식"이다. 깊게 파고들기 전에 얕고 넓게 훑는다고 해서 '너비 우선'이라고 부른다.
1. BFS가 작동하는 원리 (물수제비 파문)
호수에 돌을 던지면 물결이 동심원을 그리며 퍼져나가는 것을 생각하면 이해하기 쉽다.
1) 시작점 (Topic Entity): 질문에서 찾은 핵심 단어 (예:Justin Bieber)가 호수에 던진 돌맹이, 즉 시작점(루트 노드)이 됨. 이것이 0-hop.
2) 가장 가까운 이웃 (1-hop): 0-hop 노드와 선 (Edge, 논문에서는 Relation)으로 직접 연결된 모든 노드를 싹 다 방문. (예:저스틴 비버의 엄마, 아빠, 출생지)
3) 그 다음 이웃 (2-hop): 1-hop에서 찾은 노드들과 연결된 또 다른 노드들을 방문합니다. (예:엄마의 직업, 아빠의 다른 자녀(Jaxon Bieber))
4) 반복: 우리가 미리 정해둔 깊이, 즉 최대 -hop에 도달할 때까지 이 과정을 물결처럼 넓혀가며 반복합니다.
2. 구현 (큐, Queue)
이 '넓게 퍼지는' 순서를 헷갈리지 않고 기억하기 위해 BFS는 보통 큐(Queue, 대기열)라는 자료구조를 사용한다. (First In First Out; FIFO)
여담으로 미국식 영어에서는 사람이 서는 줄이 line이지만, 영국식 영어에서는 사람이 서는 줄을 queue라고 한다. 이를 연상하면 자료 구조도 쉽다.1) 대기열에 먼저 시작점(Justin Bieber)을 넣는다.
2) 대기열에서 하나를 꺼내고, 그와 연결된 이웃들(엄마, 아빠)을 대기열 맨 뒤에 줄을 세운다.
3) 다시 대기열 맨 앞에서 하나를 꺼내고(엄마), 엄마의 이웃들을 또 맨 뒤에 줄 세운다.
4) 이렇게 줄 서 있는 순서대로 차곡차곡 처리하면, 자연스럽게 거리가 가까운 1-hop 노드들부터 먼저 다 꺼내보고 나서 2-hop 노드들을 꺼내보게 된다.
3. 논문에서 BFS를 선택한 이유 (Why BFS?)
저자들은 빠짐없는 그래프 탐색을 위해 해당 알고리즘을 사용하였다고 밝혔다.
논문의 목적은 LLM이 정답을 놓치지 않도록 지식 그래프 안에서 유효한 모든 추론 경로()를 긁어오는 것이다. BFS는 주변부터 층층이 샅샅이 뒤지기 때문에, 지정된 거리(-hop) 내에 있는 관련 지식을 절대 놓치지 않는다는 강력한 장점이 있다.
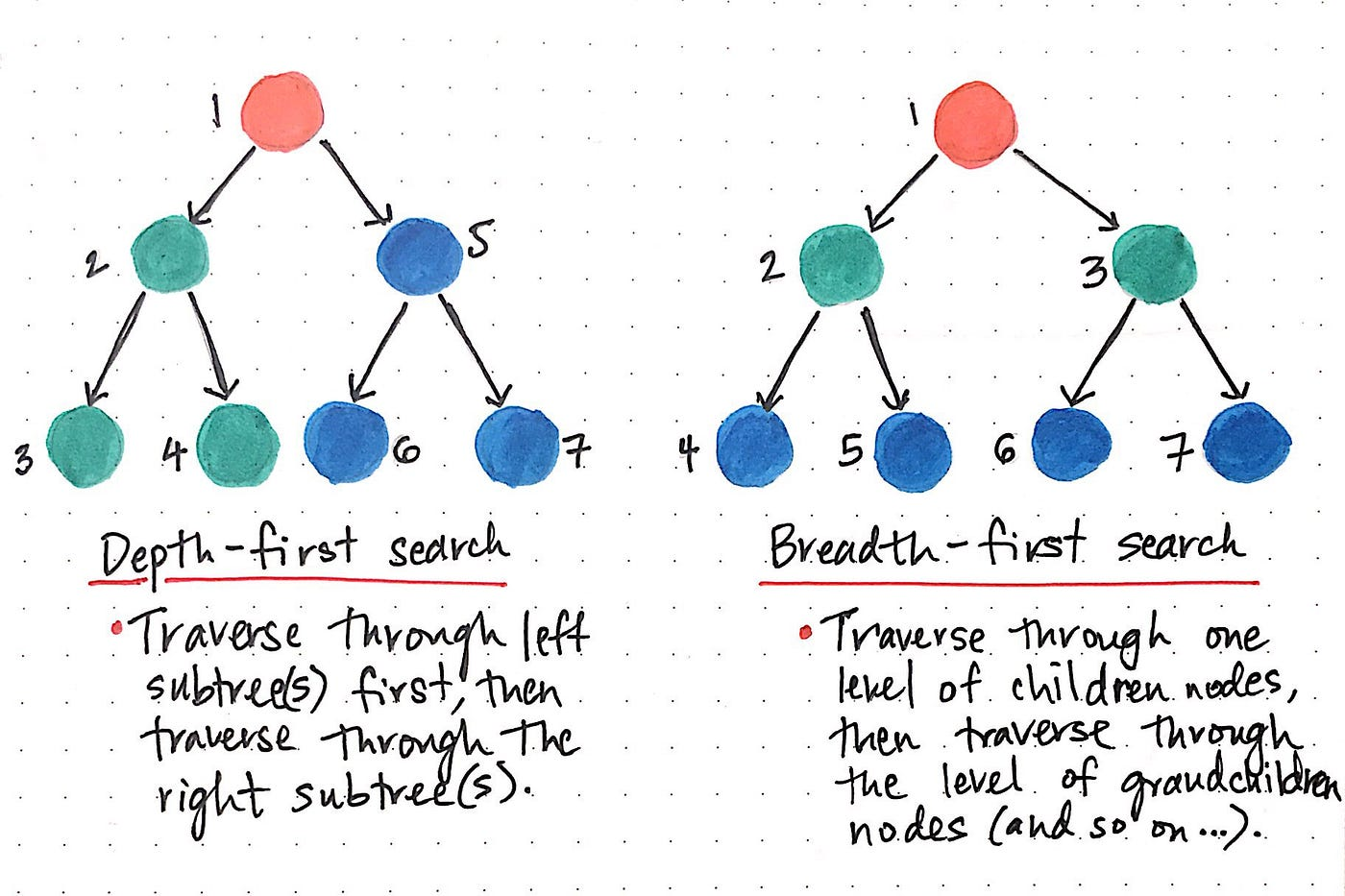
논문은 BFS를 기본으로 썼지만, random walk 등 다른 그래프 탐색 알고리즘으로도 대체 가능하다고 명시한다. BFS를 선택한 이유는 층위별로 모든 경로를 놓치지 않기 위해서라고 밝혔다.
2. 자연어 문장화 (Path Formatting)
이후 아래의 템플릿을 활용해 수집된 경로를 자연어 문장 형태로 변환한다. 이 과정을 통해 LLM이 처리하는 방식은 텍스트 방식으로 KG를 바꿔주기 때문에, KG의 구조적 정보를 LLM이 인식할 수 있는 형태로 직렬화 하는 과정이 본 과정에 해당한다.
결과:

e.g., "[엔티티1] [관계1] [엔티티2] [관계2] [엔티티3]" → "Justin Bieber people.person.parents Jeremy Bieber people.person.children Jaxon Bieber"
3. 토크나이징
포맷팅된 문장들을 KG-specialized LLM의 토크나이저로 분할해 토큰 시퀀스 를 만든다.
이때 중요한 문제는 같은 엔티티 이름이라도 tokenizer에 따라 다른 토큰으로 분할될 수 있다는 점이다. 가령 "Jeremy Bieber"가 ["Jeremy", " Bie", "ber"]로 분할될 수 있다. KG-Trie는 이 토큰 수준에서 구성되기 때문에, Trie의 각 노드는 KG 엔티티/관계 단위가 아니라 토크나이저 토큰 단위이다.
이것이 논문이 "LLM의 토크나이저와 결합"이라고 강조하는 이유이다.
4. Trie 구성
토큰 시퀀스들을 Trie에 삽입하고, 이후 디코딩 시 가 제약으로 사용된다. (즉 에 주어진 정보 내부에서만 LLM이 답변을 생성하도록)
따라서 전반적인 과정은 아래와 같은 수식으로 정의가 된다.
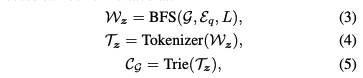
위와 같이 각 질문 엔티티에 대해 KG-Trie를 설계함으로써, 그래프 순회를 비싸게 할 필요없이 의 효율적인 constant time이 정의가 된다. 게다가 KG-Trie는 이미 구조화된 그래프를 로드해서 오면 되는 구조이기 때문에 KG만 있다면 본 방법론을 적용하는 것은 효율적인 그래프 기반 검색 방식이라 본 저자들은 주장한다.
지금까지가 KG를 "어떻게 사용할 것인가"에 대한 문제였다면, 아래는 LLM을 활용해 KG 기반 지식을 "어떻게 디코딩할 것인가"의 문제이다!
5. Graph-constraied Decoding
아래의 6번 수식은 토큰 생성을 위한 디코딩 시 수식이며, 7번 수식은 마스킹 함수 정의 수식이다.

지금까지 생성된 토큰 시퀀스 가 KG-Trie의 어떤 유효한 경로의 접두사로 존재하면 이 토큰은 허용(1), 아니면 확률을 0으로 만들어 원천 차단시키고자 하는 방식이다.
매 토큰 생성 단계에서 위의 과정을 수행함으로써, 현재 생성중인 prefix를 KG-Trie에서 조회하고, Trie에서 현재 prefix의 다음으로 올 수 있는 유효 토큰 집합을 추출한다. LLM의 전체 vocab.에서 이 유효 토큰 집합에 속하지 않는 토큰들의 logit을 으로 설정하여, softmax 적용 이후의 그 토큰들의 확률은 0이 되도록 한다.
이 과정이 Beam Search와 결합되어 여러 개의 KG-grounded 경로와 가설 답변이 생성된다.
더 나아가, Agent-based 방식과 같이 KG의 경로를 완벽히 참조한다면 Agent-based와 제안 방법론인 GCR이 무엇이 다른지 의문이 들 것이다. Appendix B.2에 따르면, KG-Trie 조회는 상수 시간으로, agent-based 방법이 매 스텝마다 KG와의 상호작용을 해야해서 쿼리 당 수백초가 걸리는 반면, GCR은 이미 구축된 Trie를 "단순 조회"한다는 점에서 추론 시간이 극적으로 짧아진다고 언급한다.
Appendix B. KG-Trie Construction
본 부록 절에서는 시공간 복잡도 문제를 구체적으로 어떤 방식을 통해 해결하였는지를 다룬다.
- B.1. Construction Strategies
KG-Trie 설계에 있어서 두 가지 방식이 있다.
- On-demand 모드: 질문이 들어올 때마다 해당 질문의 topic entity에 대해 즉석해서 Trie를 구성하는 방식이다. 전처리 시간이 없으며 메모리 효율적이고, 실시간 응용에 적합하다는 장점이 있다.
- Offline pre-computation 모드: 자주 등장하는 엔티티들의 KG-Trie를 미리 구축하여 캐싱하는 방식이다. 자주 쓰는 엔티티는 반복 구축 비용을 절약할 수 있으며, 논문이 언급하는 캐싱 전략이 바로 해당 전략이다.
- B.2. Time and Space Complexity Analysis
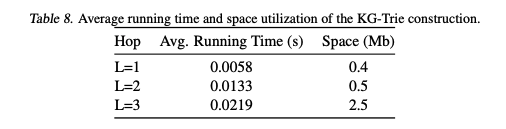
Trie 구축:
- 시간: — 경로 수 × hop 수 × 토큰 길이
- 공간: — 같은 prefix를 공유하므로 실제로는 더 적음따라서 디코딩 시 조회를 할 때는 토큰 당 의 복잡도가 발생한다. (Prefix 조회가 Trie에서는 constant time)
가 최적점이며, 는 Trie 크기가 급증하나 성능 향상이 미미하단 것을 확인할 수 있다.
- B.3. Strategies for Optimizing Efficiency
- 엔티티 캐싱: hub node (degree가 큰 엔티티)는 KG-Trie가 매우 커짐. 이 엔티티들의 Trie를 미리 캐싱해두면 반복 구축 비용 절약 가능하다.
- Path pruning: BFS로 수집된 경로 중 질문과 관련성이 낮은 경로를 미리 필터링해 Trie 크기를 줄이는 방향도 언급한다.
6. Graph Inductive Reasoning
이후, KG-specialized LLM이 beam search로 KK
K개의 경로와 가설 답변 쌍을 생성한다.
이것을 general LLM에 전부 입력해 귀납적 추론으로 최종 답변을 도출하고, 이 부분이 FiD (Fusion-in-Decoder) 방식과 유사하다. 단일 경로만 쓰는게 아닌, 여러 경로의 다양성을 한 번에 활용해서 더 robust한 답변을 내는 방식이다.
따라서 최종적으로 정리하면 다음과 같다.
본 방법론 적용을 위해서는 LLM이 두 번 호출되어야하며, KG-specialized LLM과 General LLM이 필요하다. 각각은 경량화된 모델과 GPT-4o같은 강력한 모델을 사용하였다고 밝힌다.
//이거 표로 바꿔야됨
KG-specialized LLMGeneral LLM크기경량 (LLaMA 3.1 8B)강력 (GPT-4o)역할KG-Trie 제약 하에서 경로 탐색여러 경로 종합해 최종 답변학습Instruction tuning 필요추가 학습 없음 (plug-and-play)
Result & Analysis
본 방법론은 학습이 필요없는 디코딩 차원에서 LLM에게 제약을 걸어 불필요한 답안 생성을 막고 효율적인 KG 참조를 하여 최종 모델 정확도 성능을 올리는 것을 목표로 한다.
해당 방법론 적용을 통해 본 저자들은 다음과 같은 Research Questions 관점에서 결과를 해석하고자 한다.
Research Questions in GCR
- RQ1: Reasoning Performance and Efficiency
메인 결과표 분석과 함께 제거 실험을 적용하여 본 방법론을 적용했을 때 효율성과 최종 정확도에 있어 어떤 수치적 변화가 있는지 확인하고자 한다.- RQ2: Hallucination Elimination and Faithful
Reasoning
정성적 분석을 통해 실제 환각 현상이 얼마나 제거가 됐고, 얼마나 신뢰성있는 답변이 출력됐는지 Case study를 통해 확인하고자 한다.- RQ3: Zero-shot Generalizability to Unseen KGs
새로운 KG 데이터셋을 적용하여, 본 방법론을 Zero-shot 방식으로 적용했을 때 얼마나 도메인 의존적인지?를 확인하기 위해 일반화 성능을 검증하고자 한다.
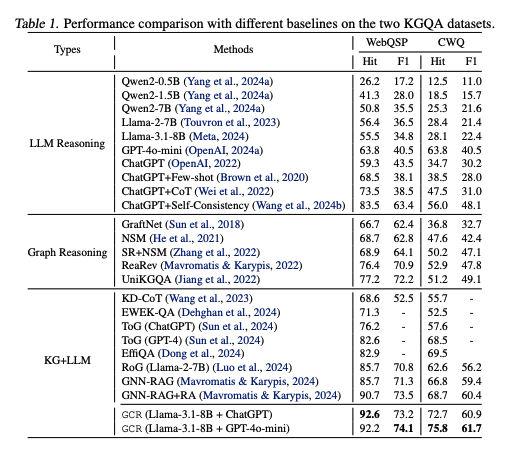
메인 결과표이다.
또한 KG는 노드들이 이제 엔티티별로 묶여있으니까 Hop의 개념이 중요하다. 몇 개 노드까지 살펴볼건지 -> 이게 출력에 참고할 정보가 되니까 출력의 질과도 직접적인 관계가 있다. 그래서 Appendix F의 추가 실험 결과에 따르면,
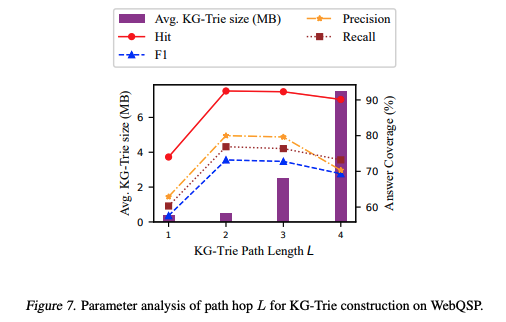
가 WebQSP와 CWQ 모두에서 최적. 은 너무 짧아 answer entity에 도달 못하는 경우가 많은 반면, 이상은 성능 향상이 미미하고 Trie 크기만 커지는 것을 확인할 수 있다.
또한 Reasoning on Graph (RoG) 방법론과 비교했을 때, beam search로 개 경로를 생성하고, general LLM이 통합할 때 가 클수록 성능이 오르는 경향을 확인할 수 있었다. (단, 가 너무 크면 general LLM의 context 길이 제한에 걸림.)
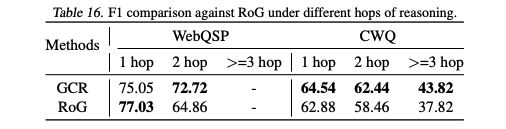
Table 16에 따르면, 4-hop 이상의 복잡한 질문(CWQ 데이터셋)에서도 GCR은 강한 성능을 보임. agent-based 방법이 긴 hop에서 비용이 폭발하는 것과 대조되는 결과를 확인할 수 있었다.
하지만 생성된 reasoning path가 논리적으로 일관성 있는지를 분석하는 과정에서, KG-Trie 제약 덕분에 경로 자체의 사실성은 보장된다는 긍정적인 면이 있지만, 경로가 질문에 "논리적으로 관련이 있는지"는 별개의 문제라고 본 저자들은 밝힌다. 저자들은 이러한 실패가 주로 다음 두 가지 요인에서 비롯된다고 분석하였다.
- KG 불완정성: KG에 필요한 사실이 아예 없어서 Trie에 올바른 경로가 포함되지 않는 경우
- Topic Entity 추출 성능: Topic Entity 추출이 애초에 잘못되어 엉뚱한 엔티티에서 BFS가 시작되는 경우
Conclusion
따라서 위의 정량/정성적인 결과를 고려해보았을 때, 본 논문의 저자들은 해당 제안 방법론인 GCR의 한계점을 아래와 같이 정의한다.
1. KG-constrained zero-hallucination의 정의 범위의 모호성
KG 안에 경로가 존재한다는 것이 곧 정답으로 이어진다는 보장을 할 수 없다. 이 이유는 직전에 설명했던 내용과 같이 KG의 정밀성과 완전성에 의존하는 방법론임을 밝힌다.
2. KG의 불완정성
필요한 사실이 KG에 없으면 Trie에 올바른 경로가 기재되지 못하고, GCR 방법을 적용해도 답을 하지 못한다. 따라서 구조적 의존성과 한계를 지닌다.
3. Hub node에서의 Trie 폭발
Degree가 매우 높은 엔티티는 에서 경로 수가 기하급수적으로 증가한다. 이를 캐싱으로 미리 해결하고자 하지만 근본적인 해결책이 되지 못한다고 밝힌다.
4. API 사용 비용
두 LLM 사용 비용
KG-specialized LLM + general LLM(GPT-4o)을 동시에 쓰는 구조라 API 비용이 올라갑니다. 단일 모델 통합이 future work라고 밝힌다.
디코딩 단에서 모델의 환각 현상을 억제하려는 연구도 기존에 많았고, KG를 활용한 LLM의 신뢰성 향상 시도는 많았지만, KG를 LLM의 생성 제약으로 통합하는 프레임워크가 기존에 없었다는 점에서 큰 기술적 기여도가 있었다.
더 나아가, Zero Hallucination을 구조적으로 달성하고, 캐싱 전략을 활용해 agent-based 방법 대비 속도가 수백 배 빠르며, unseen KG에 대한 일반화 성능까지 검증을 거쳤다는 점에서 실용적 기여 또한 있는 논문이라 생각된다.
💡 저스틴 비버 예시로 이해하는 '접두사 압축(Trie)'앞선 BFS 단계에서 저스틴 비버에 대한 3개의 지식 경로를 찾았고, 이를 토큰으로 쪼갰다고 가정해 봅시다.
["Justin", " Bieber"]
경로 A: ["Justin", " Bieber", " parents", " Jeremy", " Bieber", " children", " Jaxon", " Bieber"]
경로 B: ["Justin", " Bieber", " parents", " Jeremy", " Bieber", " children", " Jazmyn", " Bieber"]
경로 C: ["Justin", " Bieber", " spouse", " Hailey", " Bieber"]
[압축 전: 일반적인 저장 방식]
보통은 저 3개의 긴 문장을 따로따로 다 저장합니다. 메모리도 많이 차지하고, 나중에 LLM이 "다음에 올 단어가 뭐지?" 하고 찾을 때마다 처음부터 끝까지 다 뒤져봐야 해서 매우 느립니다.
[압축 후: Trie(접두사 트리) 방식]경로 A와 B를 잘 보세요. 처음 시작부터 " children" 토큰까지 앞부분(접두사)이 100% 똑같습니다. 경로 C 역시 두 번째 토큰인 " Bieber"까지는 앞부분이 똑같습니다.그래서 트라이(Trie)는 이 겹치는 앞부분을 하나의 굵은 나무 기둥(공통 접두사)으로 합쳐버립니다.뿌리에서 출발해 Justin Bieber 까지는 하나의 길로 갑니다.여기서 spouse 길과 parents 길로 가지가 나뉩니다(Branch).parents 길을 따라 Jeremy Bieber children 까지 다시 쭉 하나의 길로 갑니다.그리고 마지막에 Jaxon과 Jazmyn으로 다시 한번 가지가 나뉩니다.
