지식 그래프 설계 기초 (개념적)

1. Preliminary
2024년 이후 LLM(대형 언어 모델)이 고도화됨에 따라, 사람들은 단순한 성능을 넘어 자원의 효율성과 환각(Hallucination) 현상 해결에 집중하기 시작했다. 이는 데이터 업데이트 시 모델 전체를 재학습시키는 막대한 비용 부담과, 정확한 근거 없이 그럴듯한 오답을 내놓는 생성형 AI의 고질적인 문제에서 비롯되었다.
이러한 한계를 극복하기 위해 RAG(Retrieval-Augmented Generation)와 같은 "검색 기반 데이터 증진" 기술이 대두되었다. 아마 AI를 공부하는 사람이라면 무조건 들어봤을 것이다.
이 과정에서 단순히 텍스트 조각을 찾는 것을 넘어, 데이터 간의 유기적인 관계를 파악할 수 있는 데이터 형태가 주목받았는데, 그것이 바로 지식그래프(Knowledge Graph)이다.
🤠
지식그래프(Knowledge Graph, KG)는 현대 AI와 빅데이터 시대의 핵심 기술로, 구글 검색 엔진부터 기업용 데이터 분석까지 이미 우리 일상 곳곳에서 널리 쓰이게 되었다.
a. 지식그래프의 정의와 모양
지식그래프는 이름 그대로 지식을 '거미줄(Graph)'처럼 엉켜 있는 형태로 표현한 것이다. 단순히 개별적인 데이터를 나열하는 것이 아니라, 데이터 사이의 '관계'를 촘촘하게 엮어져 있다.
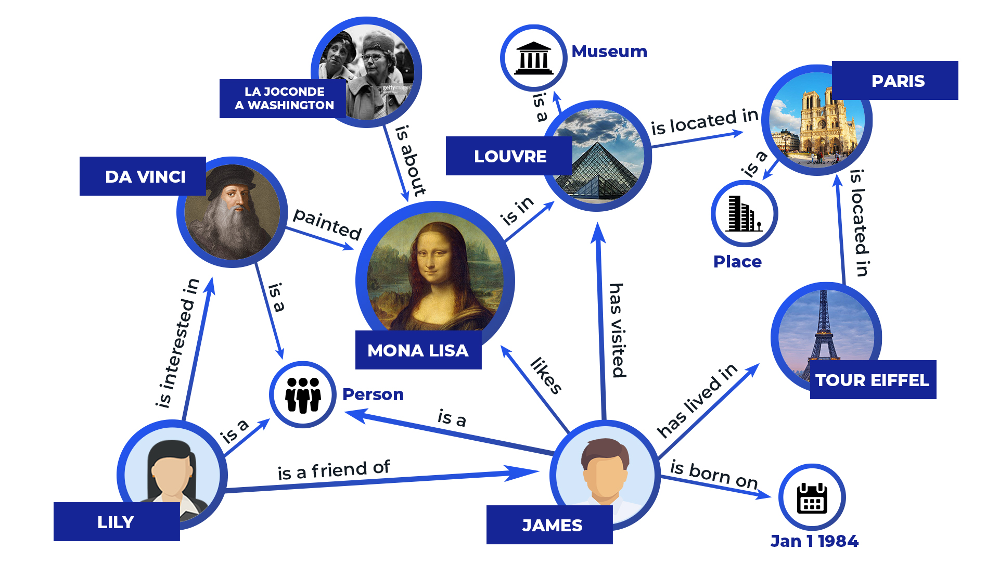
학술적으로 지식그래프 모델링이란, 지식을 효율적으로 저장하고 검색(Querying)하며, 새로운 정보를 찾아내기(Reasoning) 위해 그래프 형태로 구조화하고 표현하는 일련의 과정을 의미한다.
🕸️ 지식 그래프의 구성:
- 노드(Nodes/Entities): 사람, 제품, 장소와 같은 실세계의 객체.
- 엣지(Edges/Relations): 객체들 사이를 잇는 관계.
- 레이블(Labels): 사람이 읽을 수 있고 기계가 식별할 수 있는 의미 있는 이름.
이러한 형식의 지식 그래프를 사용할 때의 장점은 무엇일까?
지식그래프는 전통적인 데이터베이스와 비교했을 때 다음과 같은 독보적인 강점을 가진다.
| 주요 장점 | 상세 설명 | 기대 효과 |
|---|---|---|
| 의미적 명확성 (Semantic Meaning) | 데이터의 맥락과 의미를 강조하여 해석 가능성을 극대화함 | 기계가 데이터의 '진짜 의미'를 이해 |
| 강력한 연결 및 추론 (Reasoning) | 흩어진 데이터를 연결하여 숨겨진 관계를 논리적으로 찾아냄 | 지능형 추천 및 의사결정 지원 |
| 유연한 구조 (Flexible Schema) | 고정된 틀이 없어 새로운 데이터나 관계를 추가하기가 매우 용이함 | 변화하는 비즈니스 환경에 빠르게 대응 |
| 다중 관계 표현 (Multi-relational) | 엔티티 사이에 수많은 종류의 복잡한 관계를 동시에 정의 가능 | 현실 세계의 복잡성을 그대로 반영 |
b. 지식 그래프의 데이터 기저(Web Documents vs. Semantic Web Documents)
지식그래프가 단순히 연결된 데이터를 넘어 '지능'을 갖게 되는 이유는 데이터를 웹상에서 기계가 해석할 수 있는 표준 규격으로 구현하기 때문이다.
# 이때 지능을 갖는다는 표현은 곧 '사람이 일일이 가르쳐주지 않아도
기계가 규칙과 맥락을 통해 스스로 정보를 판단하고 연결할 수 있는 구조가 되었다.'는 뜻이다.
조금 더 자세한 내용은 아래에서 다시 설명하도록 하겠다.Web Documents (Traditional Web)
- 사람 중심으로 디자인되었음.
- 주로 HTML의 형식으로 작성됨.
- 텍스트, 이미지, 링크 등의 Presentation과 Layout에 집중적임.
- 의미가 "암시적(Implicit)"이며, 기계가 이해할 수 없는 형태로 나타있음.
웹 페이지에 "Apple"이라는 단어가 있을 때, 이 단어가 과일인지 기업인지 기계는 명확히 구분이 어려움.Semantic Web Documents
- 사람과 기계 모두가 이해할 수 있도록 설계됨.
- RDF, RDFS, OWL과 같은 표준을 사용.
- 데이터의 "명시적인 의미(Semantics)"에 집중적임.
- 의미가 구조화되어 있으며, 기계가 읽을 수 있음 (Machine-readable).
(Apple, type, Company) 또는 (Apple, type, Fruit)와 같이 관계를 명시하여 혼동을 방지
가령 기존의 Web Documents가 Wikipidia라면 Semantic Web Documents는 WikiData 데이터 형태인 것이다.
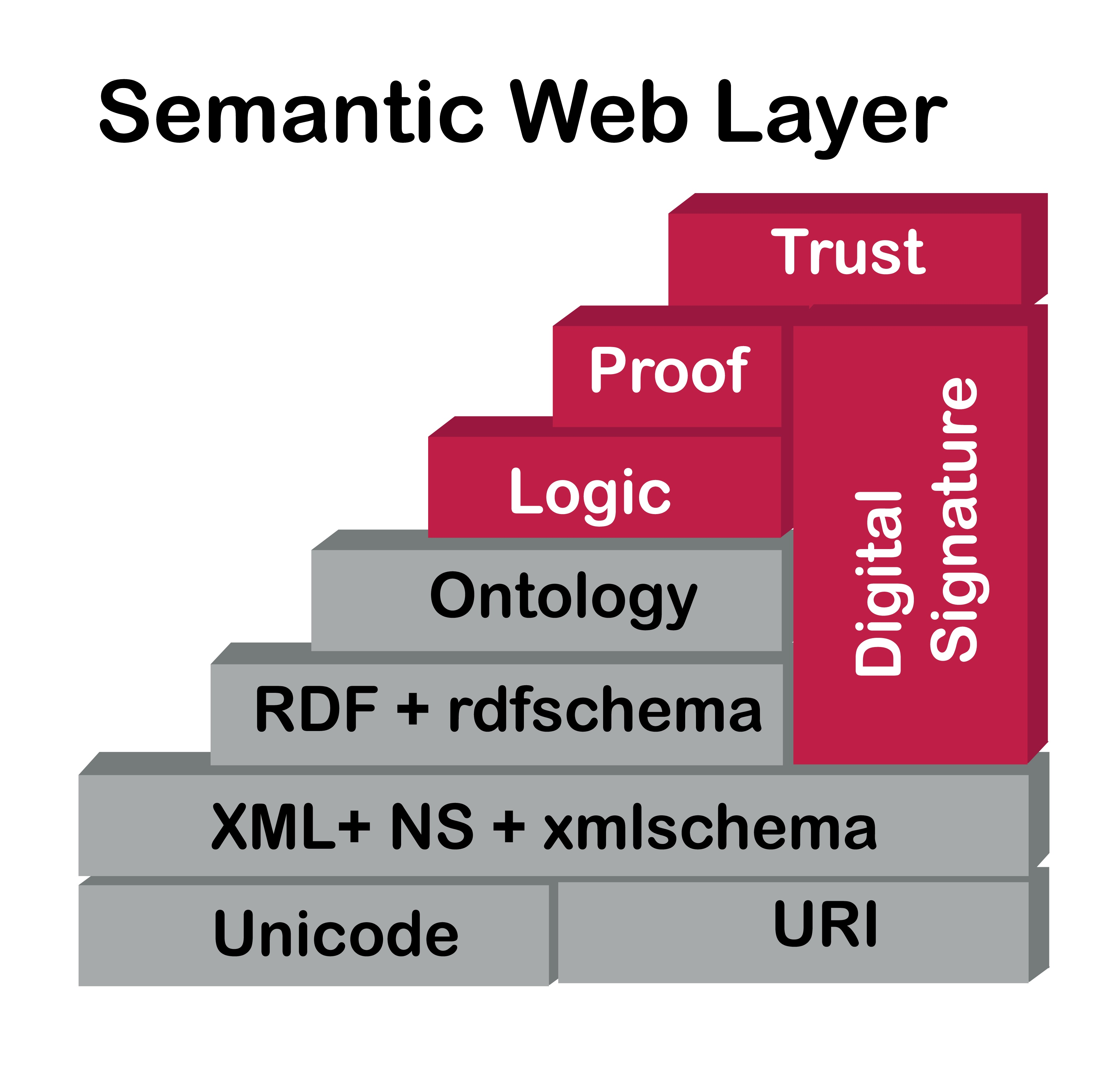
🍰 Semantic Web Layer Cake (계층 구조)
시맨틱 웹은 아래에서 위로 쌓이는 기술 계층으로 구성된다.
- 기초: URI/Unicode (식별 및 문자)
- 구조화: XML, RDF, RDFS (데이터 모델 및 스키마)
- 논리 및 추론: OWL (온톨로지), Rules, Logic, Proof
- 보안 및 신뢰: Digital Signature, Encryption, Trust
- 인터페이스: SPARQL (쿼리 언어)
2. Knowledge Graph (KG) Modeling
그렇다면 Knowledge Graph란?
지식을 그래프 형태로 "구조화 (Structuring), 표현 (Representing), 그리고 조직화 (Organizing)"하는 프로세스
이는 효율적인 저장, 쿼리(Querying, 데이터 검색 및 질의), 그리고 추론 (Reasoning)을 가능하게 하기 위함이다.
핵심 구성요소는 아래와 같다.
- 노드(Nodes/Entities): 사람, 제품 등 실세계의 객체.
- 엣지(Edges/Relations): 엔티티 간의 관계.
- 레이블(Labels): 기계와 사람이 식별할 수 있는 의미 있는 식별자.
이 데이터 구조의 특징은 다중 관계성(Multi-relational), 유연한 스키마, 그리고 의미적 명확성이 또렷하다.
3. KEY of KG
Resource Description Framework (RDF)
RDF는 웹상의 정보를 표현하기 위해 W3C에서 표준화한 모델이다.
- RDF 데이터 모델: Triple (트리플)
데이터를 표현하는 기본 단위로, 아래의 세 부분으로 구성된다.
1. Subject (주어): 관계의 주체.
2. Predicate (술어): 주어와 목적어 사이의 관계/속성.
3. Object (목적어): 관계의 대상 또는 값.
예시: Alice(Subject) --hasFriend(Predicate)--> Bob(Object)
식별자: URI, URL, IRI
- URI (Uniform Resource Identifier): 웹상의 리소스를 고유하게 식별합니다. 주어, 술어, 목적어 위치에 모두 올 수 있다.
- URL (Uniform Resource Locator): URI의 일종으로, 리소스에 접근하는 방법(프로토콜)까지 명시한다.
- IRI (Internationalized Resource Identifier): URI를 확장하여 전 세계의 다양한 언어(Unicode) 문자를 지원한다.
4. Types of RDF Node
RDF 그래프를 구성하는 노드는 세 가지 유형이 있다.
| 노드 유형 | 의미 및 특징 | 트리플 내 위치 (Triple Position) |
|---|---|---|
| URI (IRI) Node | 리소스를 고유하게 식별하는 글로벌 식별자 | 주어, 술어, 목적어 모두 가능 |
| Literal Node | 텍스트, 숫자, 날짜 등 실제 데이터 값 | 목적어(Object) 위치만 가능 |
| Blank Node | 고유 식별자가 없는 익명 리소스 | 주어(Subject) 또는 목적어(Object) 가능 |
5. RDF Syntaxes & Serialization (구문 및 직렬화)
RDF 데이터를 컴퓨터 파일 형태로 저장하고 전송하는 방식들이다.
- XML: XML 도구들을 활용할 수 있으나 사람이 읽기 어려움.
- N-Triples: 한 줄에 하나의 트리플만 작성하는 단순한 구조이다. 대용량 데이터 덤프에 표준적으로 사용되나 가독성은 낮다.
- Turtle (Terse RDF Triple Language): N-Triples보다 압축된 형태로, 사람이 읽기 가장 좋은 형식이다. 이때, 접두사(Prefix)를 통해 긴 URI를 줄여 쓸 수 있다.
- JSON-LD: JSON 형식을 사용하여 웹 개발자가 다루기 쉽다.
- RDFa: HTML 페이지 내에 RDF 데이터를 직접 삽입할 수 있게 해준다.
6. 지식 그래프 구축 후 작동 방식
앞서 Preliminary부분에서 말한 바와 같이, 지식그래프가 단순히 연결된 데이터를 넘어 '지능'을 갖게 되는 이유는 데이터를 웹상에서 기계가 해석할 수 있는 표준 규격(RDF, OWL 등)으로 구현했기 때문이다. 이렇게 구축된 지식그래프는 다음과 같은 방식으로 지능적으로 작동한다.
1. 단순 연결을 넘어선 '논리적 추론' (Reasoning)
일반적인 데이터베이스는 우리가 입력한 데이터만 찾아줍니다. 하지만 지식그래프는 명시적으로 적어주지 않은 사실도 기계가 스스로 찾아낼 수 있다.
예시: A는 B의 아버지다와 B는 C의 아버지다라는 데이터를 넣으면, 기계가 논리 규칙을 통해 A는 C의 할아버지다라는 새로운 지식을 스스로 도출한다.
이러한 자동화된 추론(Automated Reasoning) 능력 활용이 가능해진다.
2. 데이터 스스로가 가진 '자기 설명력' (Semantic Meaning)
기존 웹 문서(HTML)는 기계 입장에서 그저 '글자 뭉치'이다. 하지만 시맨틱 웹 표준(RDF)을 따르면 데이터에 '의미'가 뒤따라 붙는다.
- 기존 웹: "Apple" → 단순 텍스트.
- 지식그래프: Apple + type: Company → 기계가 이 데이터는 '먹는 과일'이 아니라 'IT 기업'임을 명확히 인지하고 그에 맞는 연관 정보를 연결한다.
이는 데이터가 스스로의 정체를 기계에게 설명할 수 있는 체계(Ontology)를 갖췄기 때문이다.
3. 유연한 확장을 통한 '맥락 이해' (Context)
지식그래프는 다중 관계(Multi-relational)를 지원하며 틀이 정해져 있지 않다.
- 새로운 데이터가 들어올 때마다 기존 거미줄에 계속 이어 붙일 수 있어, 데이터가 쌓일수록 정보 간의 거대한 맥락(Context)이 형성된다.
- 기계가 특정 단어 하나만 보는 게 아닌, 그 단어와 연결된 거대한 관계망 전체를 훑으며 결과를 내놓기 때문에 훨씬 지능적인 답변(Intelligent search)이 가능해진다.
정리하며
효과적인 지식그래프 구축을 위해서는 단순한 데이터 수집을 넘어, 기계가 추론할 수 있는 논리적인 모델링이 필수적이다.
이러한 작동 방식 덕분에 지식그래프는 LLM의 할루시네이션을 억제하고, 정교한 RAG 시스템을 구축하는 데 있어 필수적인 '지식의 뼈대' 역할을 수행하게 된다.
하지만 사실상 민간 차원에서 지식그래프를 구축하기에는 모델링 부재 시 데이터가 오도(Misleading)될 위험과 대규모 분산 데이터 관리 및 전문 인력 확보에 따른 비용 과다라는 점들이 있어 실질적으로 불가능에 가깝다.
