https://github.com/sosa-p/CPS-detector/blob/main/decision%20tree.ipynb
깃허브에서 전체 코드 확인 가능
1.설계 목적
Decision Tree를 분류 모델로 훈련 세트를 학습시켜서 테스트 세트에서 malware 여부를 판단하고, 잘 학습이 되었는지 정확도를 확인한다.
2.데이터 세트
데이터 세트: top_1000_pe_imports.csv
본 데이터 세트는 malware와 goodware를 다양한 컬럼 속성으로 분석, 분류해 놓은 데이터 세트이다. 마지막 컬럼인 ‘malware’가 0이면 Goodware이고, 1이면 Malware이다.
3.분석 방법
3.1 Decision Tree
나무 구조로 도표화하여 분류와 예측을 수행하는 분석방법이다. Decision Tree는 최종적인 결정에 도달하기 위해서 이진분류에 대한 질문을 이어나가면서 학습한다. 기본적인 학습 방향은 데이터를 나누는 과정을 반복하며 각 노드가 테스트 하나씩을 가진 이진 트리를 만들어 계층적으로 영역을 분할하여 데이터를 학습시킨다.
3.2 분석 개요
1) 데이터 세트를 읽어와서 47580 row와 1002 column을 확인
2) 각 파일 별 다른 값을 갖는 hash값과 목표 노드로 사용할 malware 컬럼을 drop
3) 전체 데이터 세트 중 훈련세트는 70%, 테스트 세트는 30%로 나눔
4) Decision Tree 모델을 적용하여 파라미터 값을 설정
5) 교차검증 적용
6) 예측값에 대한 정확도 계산
7) 학습한 모델 시각화
8) 학습에 사용한 칼럼에 대해 변수 중요도 계산
3.3 파라미터
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 101) - test_size: 테스트 세트의 크기를 0.3으로 설정하여, 훈련 세트는 전체 데이터 세트의 70%, 테스트 세트는 전체 데이터 세트의 30%로 분리하였다.
- random_state: 알고리즘은 실행마다 값이 변하기 때문에 random_state를 설정하여 값을 고정한다. 유사 난수 생성기에 넣을 난수 초기값을 임의로 101으로 설정하여 random_state 매개변수로 전달한다.
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier(criterion = 'entropy', max_depth = 5, min_samples_split = 20)- criterion: 노드의 분리기준으로 ‘gini’와 ‘entropy’를 사용한다. 임의로 entropy를 선택한다.
- max_depth: decision tree에서 모델의 복잡도를 조절하는 매개변수로 tree가 완전히 만들어지기 전에 멈추게 하는 사전 가지치기 변수이다. 보통 사전 가지치기 방법인 max_depth, max_leaf_nodes, min_samples_leaf에서 하나만 지정해도 과적합을 막을 수 있다. 이때 max_depth는 tree 모형의 최대 깊이를 의미하여 값이 커질수록 깊어져 과적합이 쉽게 일어난다. 따라서 max_depth를 적절히 5로 설정한다.
- min_samples_split: 앞의 파라미터와 마찬가지로 과적합을 방지하기 위해 사용하는 파라미터로 노드를 분할하기 위한 최소한의 샘플 데이터 수를 가리킨다. Default는 2로, 작게 설정할수록 분할 노드가 많아져 과적합 가능성이 증가하기 때문에 적절하게 20으로 설정하였다.
3.4 교차검증
from sklearn.model_selection import cross_val_score
score=cross_val_score(dtree, x_train, y_train, cv=5)
print('cross validation score : {:.3f}'.format(score.mean()))일정한 하나의 테스트 셋으로 계속해서 평가를 진행하거나 하나의 훈련셋으로 학습을 진행하면 과적합이 쉽게 일어나기 때문에 K-Fold 교차검증을 적용한다. fold를 5개로 나누어서 다섯 개의 fold를 다르게 적용하여 테스트 셋으로 사용하여 모델에 대해 교차검증을 수행한다.
4. 탐지 결과
4.1 Malware 여부
i = 1
mal =0
good =0
for each in predicties : #예측값이
if each == 1: #1이라면 malware
mal +=1
print("NO.%d is Malware." %(i))
else: #0이라면 goodware
good +=1
print("NO.%d is Goodware." %(i))
i+=1예측값이 1이면 malware이고, 예측값이 1이 아니면 즉 0이면 goodware로 출력하도록 코드를 작성하였다.

각각 malware인지 goodware인지 출력한다.
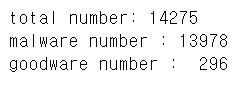
테스트 세트의 전체 14275개 중에서 13978개가 malware로 분류되었고, 296개가 goodware로 분류되었다.
4.2 모델 정확도

- Accuracy: 모델이 예측한 것에서 실제로 정답을 맞힌 비율로, 본 학습 모델에서 accuracy는 0.974이 나왔다.
- Recall: 실제 true인 것 중에서 모델이 true라고 예측한 것의 비율로, 본 학습 모델에서 recall은 0.996이 나왔다.
- Precision: 모델이 true라고 예측한 것 중에서 실제 true를 예측한 것의 비율로, 본 학습 모델에서 precision은 0.977이 나왔다.
- F1 score: Precision과 Recall의 조화평균으로, 본 학습 모델에서 F1 score은 0.987이 나왔다.
즉, 머신러닝 분류 모델의 성능 평가 지표가 전부 0.9 이상이 나왔으므로 본 학습 모델은 비교적 정확한 확률로 테스트 세트를 분류하였다고 볼 수 있다.
4.3 시각화
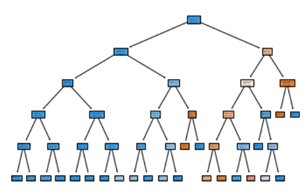
모델이 어떤 방식으로 분류되었는지 가지치기 과정을 시각화하여 살펴볼 수 있다.
4.4 변수중요도

Decision Tree의 학습이 마무리되면, 각 종속 변수 분류에 대해서 각각의 독립 변수가 어느 정도 기여를 했는지 나타내는 변수 중요도를 확인할 수 있다. 본 학습 모델에서는 1000개의 컬럼 중에 22개의 컬럼만 데이터 세트를 학습하는데 유의미하게 작용했다는 것을 알 수 있다.
5. 평가 및 고찰
Decision Tree는 지도 학습의 모델 중 하나로, 다양한 의사결정 경로와 결과를 나타내는 트리구조를 사용하여 이해하기 쉽고, 과정이 명백하다. 하지만, Decision Tree는 학습 데이터에 대한 최적의 트리를 찾기 힘들고, 새로운 데이터에 대한 일반화 성능이 좋지 않아 과적합되기 쉽다.
본 학습 모델에서는 과적합을 방지하기 위해서 다양한 파라미터 값을 적용하고, 교차 검증을 적용하였고, 최적의 학습모델을 구축하기 위해 변수들의 값을 지속적으로 변경하며 테스트하였다. 따라서, 1에 가까운 정확도를 갖는 높은 성능의 학습 모델을 구축할 수 있었다.
