
순환신경망 RNN (Recurrent Neural Network)
RNN의 경우, 입력층에서 출력층으로만 향하는 기존 방식은 문장에서 앞의 단어가 뒤에 단어에 영향을 미치는 경우를 잘 설명하지 못 함
Seq2Seq 언어모델
RNN을 활용한 언어모델
언어모델 : 문장을 차례로 생성하는 모델
앞에서 나온 내용의 가중치 수정이 잘 안되는 문제가 생김.
→ LSTM
Attention 매커니즘
단순 근거리의 정보를 크게 보지 않고 각각의 단어를 계산한 결과를 잘 가지고 있다가 동시에 보는 것
중요한 단어가 어디에 있던지 그 정보만 중요하게 보고 나머지는 적당히 볼 수 있음
해당 단어 결과 벡터 값을 그대로 활용 → 희석되지 않은 선명한 정보에 바로 접근 가능
중요한 단어는 모델이 알아서 결정
만약 RNN을 거치지 않고 각 단어의 특정 결과값을 미리 결정할 수 있다면 어텐션 구조하에서 병렬 연산에 의해 빠르게 동작하는 모델을 만들 수 있지 않을까?
→ 그걸 구글이 만들어냄. 논문제목 : ‘Attention is all you need!’
RNN없이 단어를 바로 인베딩 처리하고 몇 가지 연산으로 문장 전체에서 한꺼번에 연산할 수 있게 만듦.
문장의 단어에 대한 특성이 가중된 수치를 미리 뽑아 이를 행렬로.!
전이학습 : 미리 사전 학습된 모델을 바탕으로 시간과 비용을 줄인 모델
Transformer (전이)
순환신경망의 경우 전의 결과가 후의 입력값으로 사용되기 때문에 전의 결과값이 나올 때까지 기다려야 함. (RNN 구조의 한계) 그러나 성능은 좋은데 너무너무 오래걸림
그러나 컴퓨터는 병렬연산이 가능함.
트랜스포머 구조로 나온
- 일론 머스크 OPEN-AI의 GPT
- 구글의 BERT (Bidirectional 양방향)
사전학습모델 비교
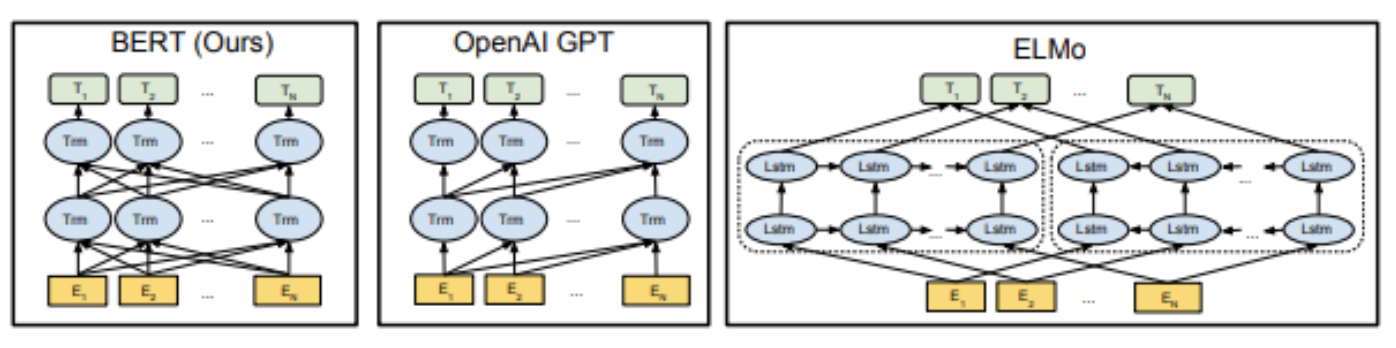
- ELMo
좌-우(left-to-right), 우-좌(right-to-left)우-좌(right-to-left) 문맥을 각각 독립적으로 계산하여 접합한 형태 - OpenAI GPT
좌-우(left-to-right)로만 계산. - ELMo와 GPT 모두 양방향 문맥을 보지 못함 → 충분한 언어 표현 X
- BERT
사전 학습을 위해 두 가지 방법 (Masked Language Model(MLM)과 Next Sentence Prediction(NSP))를 사용 → BERT가 양방향으로 학습되어 문맥을 더 잘 파악
1) Token Embeddings
Token Embeddings는 Word piece 임베딩 방식을 사용.
Word Piece 임베딩은 자주 등장하면서 가장 긴 길이의 sub-word을 하나의 단위로 만듦.
즉, 자주 등장하는 단어(sub-word)는 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 더 작은 sub-word로 쪼개짐.
이는 이전에 자주 등장하지 않은 단어를 전부 Out-of-vocabulary(OOV)로 처리하여 모델링의 성능을 저하했던 문제를 해결.
- OOV(Out-Of-Vocabulary) 문제란? 기계에게 아무리 많은 단어를 학습시켜도 세상의 모든 단어를 알려줄 수는 없음. 만약 기계가 모르는 단어가 등장하면 그 단어를 단어 집합에 없는 단어란 의미에서 해당 토큰을 UNK(Unknown Token)라고 표현. 기계가 문제를 풀 때 모르는 단어가 등장하면 (사람도 마찬가지지만) 주어진 문제를 푸는 것이 까다로워짐. 이와 같이 모르는 단어로 인해 문제를 푸는 것이 까다로워지는 상황을 OOV(Out-Of-Vocabulary) 문제라고 함.
입력받은 모든 문장의 시작으로 [CLS] 토큰(special classification token)이 주어지며 이 [CLS] 토큰은 모델의 전체 계층을 다 거친 후 토큰 시퀀스의 결합된 의미를 가지게 됨.
여기에 간단한 classifier을 붙이면 단일 문장, 또는 연속된 문장을 분류할 수 있고
만약 분류 작업이 아니라면 이 토큰을 무시.
또한 문장의 구분을 위해 문장의 끝에 [SEP] 토큰을 사용.
3) Position Embeddings
BERT는 어떻게 학습되나?
1. Input Representation
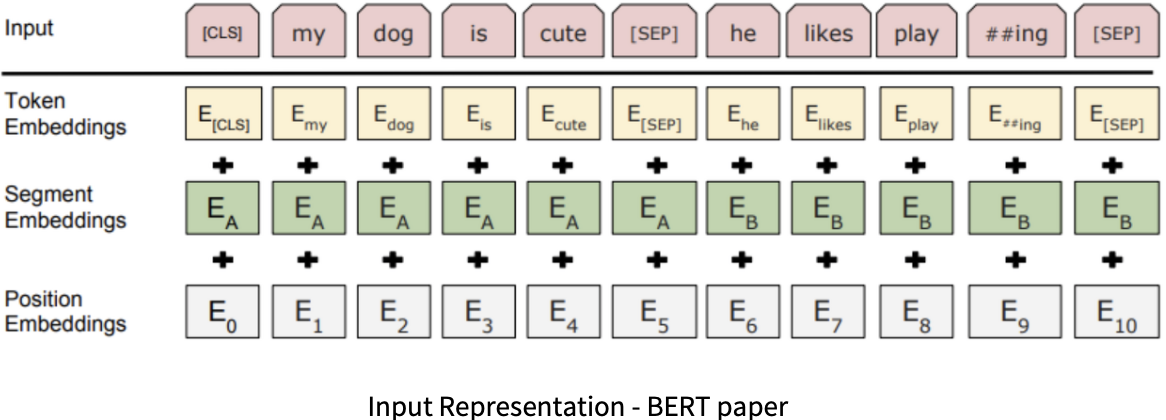
1) Token Embedding
두 가지 특수 토큰(CLS, SEP)을 사용하여 문장을 구별.
Special Classification token(CLS) : 모든 문장의 가장 첫 번째(문장의 시작)에 토큰으로 삽입. Classification task에서는 사용되지만, 그렇지 않을 경우엔 무시됨.
Special Separator token(SEP) : 첫 번째 문장과 두 번째 문장을 구별.
2) segment Embedding
앞뒤 문장을 더욱 쉽게 구별할 수 있도록 도와줌.
토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고 첫 번째 [SEP] 토큰까지는 0, 그 이후 [SEP] 토큰까지는 1 값으로 마스크를 만들어 각 문장들을 구분.
3) Position Embedding
transformer 구조에서도 사용된 방법으로 각 토큰의 위치(순서)를 인코딩.
BERT는 transformer의 encoder를 사용하는데 Transformer는 Self-Attention 모델을 사용함.(위에서 설명) Self-Attention은 입력의 위치에 대해 고려하지 못하므로 입력 토큰의 위치 정보를 주어야 함.
⇒ 최종적으로 세 가지 임베딩들의 토큰 별로 더해 input으로 사용
2. Pre-Training
BERT는 문장 표현을 학습하기 위해 두 가지 비지도학습 방법을 사용.
-
Masked Language Model
-
Next Sentence Model
-
Masked Language Model (MLM)
문장에서 단어 중의 일부를 [Mask] 토큰으로 가려, 이 단어를 예측하도록 함.
이 과정에서 BERT는 문맥을 파악하는 능력을 기름
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 [Mask] 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 흐리다고 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 예쁘다고 생각한다.
추가적으로 더욱 다양한 표현을 학습할 수 있도록 80%는 [Mask] 토큰으로 바꾸어 학습하지만, 나머지 10%는 token을 random word로 바꾸고, 마지막 10%는 원본 word 그대로를 사용.
- Next Sentence Prediction (NSP)
다음 문장이 올바른 문장인지 맞추는 문제.
두 번째 문장이 첫 번째 문장의 바로 다음에 오는 문장인지 예측하는 방식.
→ 두 문장 사이의 관계를 학습
이러한 종류의 이해를 갖춘 사전 학습 모델은 질문 답변(QA), NLI(Natural Language Inference) task과 같은 작업이 가능.
문장 A와 B를 이어 붙이는데, B는 50% 확률로 관련 있는 문장(IsNext label) 또는 관련 없는 문장(NotNext label)을 사용.
이런 방식으로 학습된 BERT를 fine-tuning할 때는 (Classification task라면) Image task에서의 fine-tuning과 비슷하게 class label 개수만큼의 output을 가지는 Dense Layer를 붙여서 사용.
레퍼런스
