
NLP의 과제
- Order Matters : 시퀀스 데이터의 순서를 반영하는가
- Variable length : 시퀀스 길이의 가변성을 반영하는가
- Differentiable : 학습되기 위한 미분이 되는가
- Pairwise encoding : 단어끼리(pairwise)의 의미를 반영하는가
- Preserves long-term : 기울기소실 문제를 해결하는가
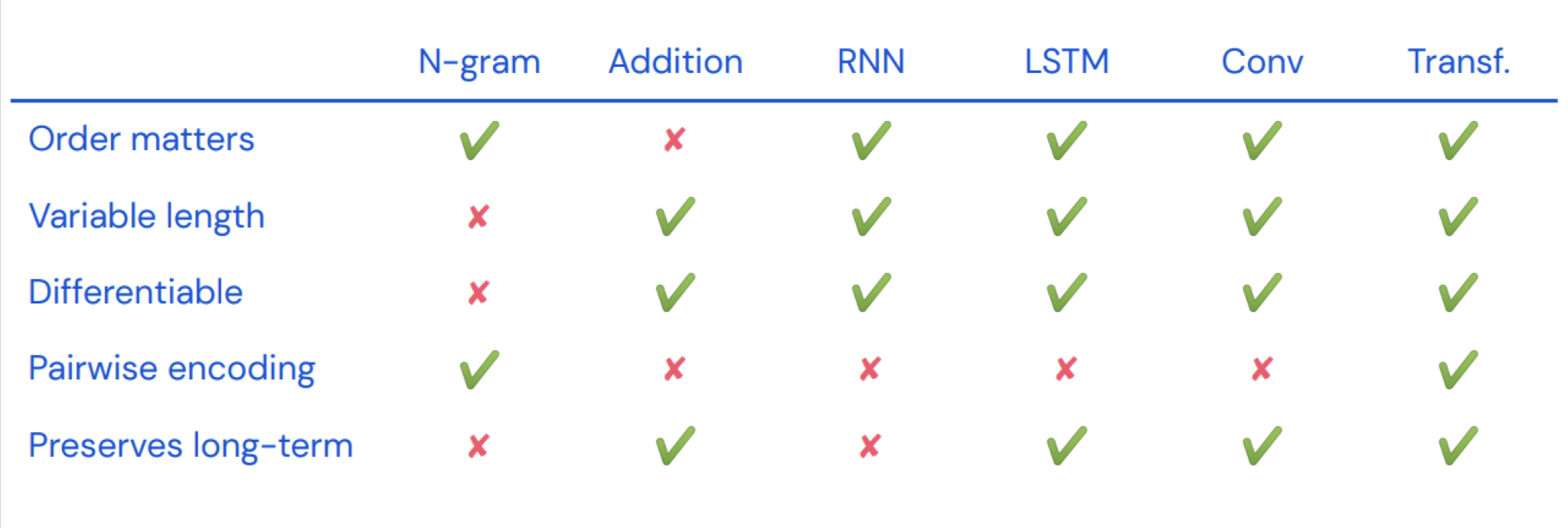
Transformer는 위 NLP의 과제를 모두 해결하고 있다.
- 데이터 순서를 반영하기 위해 Positional Encoding이란 걸 함
- 행렬곱이므로 시퀀스 길이의 가변성을 반영할 수 있음
- 모든 과정이 미분가능함
- Attention으로 단어끼리의 의미를 반영함
- Preserve long-term 문제의 경우 잔여학습(Residual Learning)을 사용해서 성능을 높이지만, 완전히 해결했다고 할 수는 없음.
1. Seq2Seq
1-1. Seq2Seq모델이란?
- Encoder와 Decoder로 나뉨. 단어가 순서대로 입력이 되면 임베딩을 통해 벡터로 표현되고, 이게 RNN모델로 들어가 Hidden State가 만들어짐.
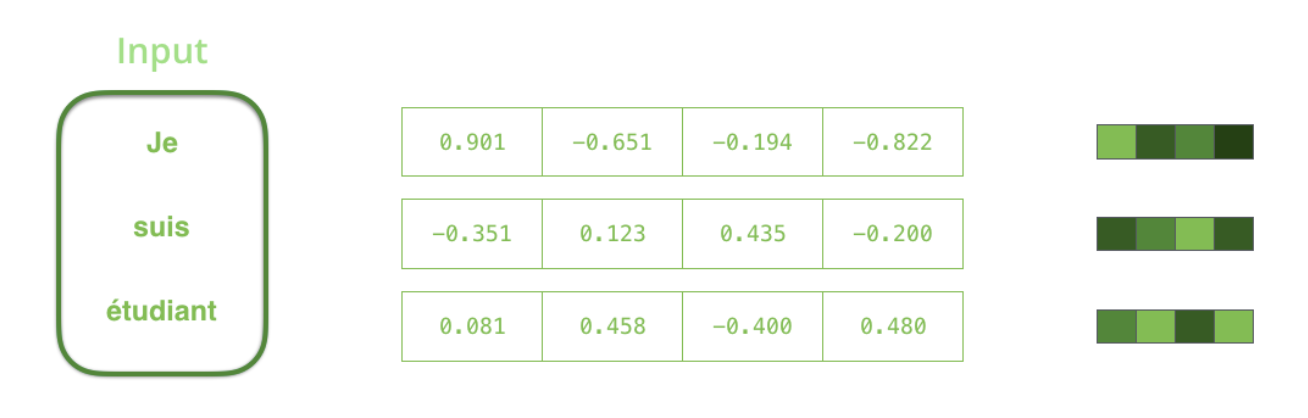
- 그 Hidden State 벡터가 다음 입력되는 단어벡터에 참고가 되고, 마지막 셀의 Hidden State가 고정된 크기의 Context Vector가 된다.
- Context Vector는 입력되는 문장을 representaion(표현)하는 벡터로, 의미를 압축해서 담고 있음
- 따라서 여기서 ‘인코딩 한다’는 건 임의의 길이의 시계열 데이터를 고정된 길이의 벡터로 표현하겠다는 것
Decoder에서는 이렇게 만들어진 context vector를 참고하여 출력을 한다.
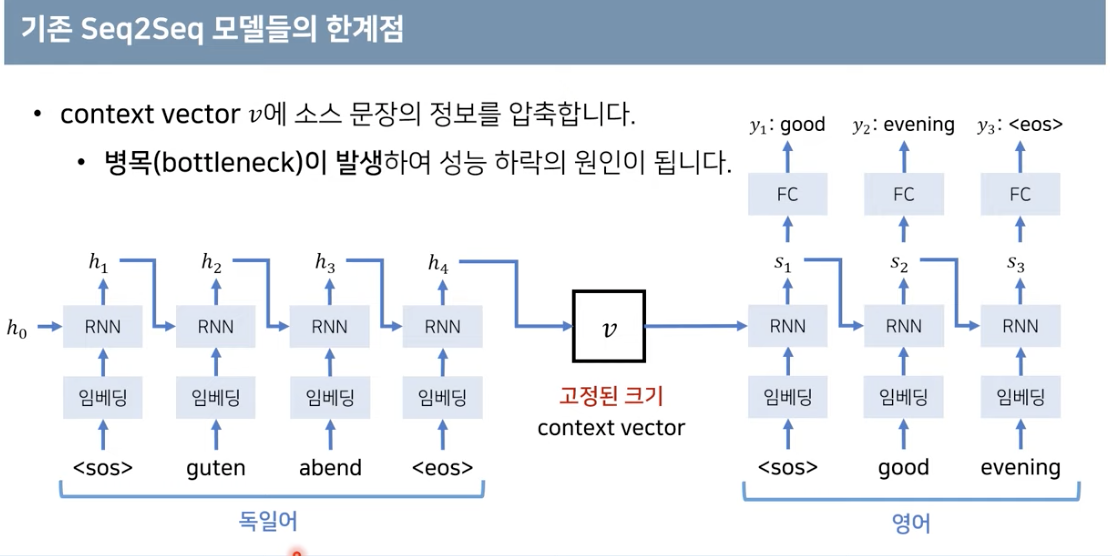
1-2. 기존 Seq2Seq모델의 한계
- 입력문장의 길이(단어의 수)는 다양한데, 이걸 고정된 크기의 벡터로 만들려니 정보의 손실이 발생할 수밖에 없음. 특히 시퀀스의 길이가 길수록 정보의 손실이 더 커진다.
- 또 RNN 구조이므로 Gradient Vanishing문제도 존재한다.
- 이런 현상을 해결하기 위해 디코더에서 context vector를 참고하는 형식을 써서 성능을 향상하려고 함
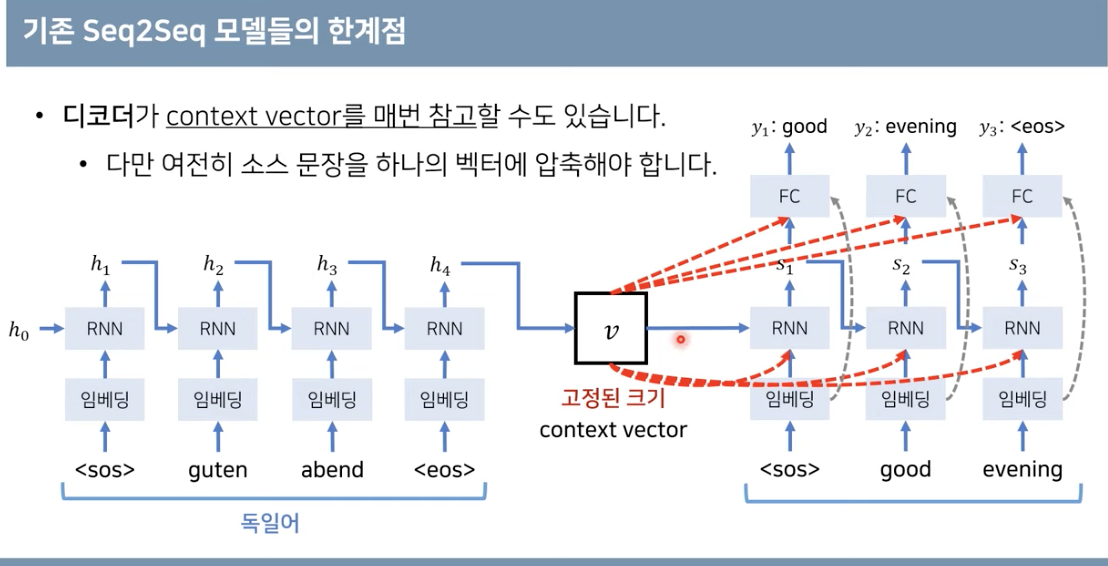
- 그러나 여전히 context vector가 인풋문장의 모든 정보를 가지고 있어야 하기 때문에 병목 문제는 사라지지 않음
- 그렇다면 매번 소스 문장에서의 출력 전부를 입력으로 받아서 문제를 해결해보자 → GPU로 가능할 거야!
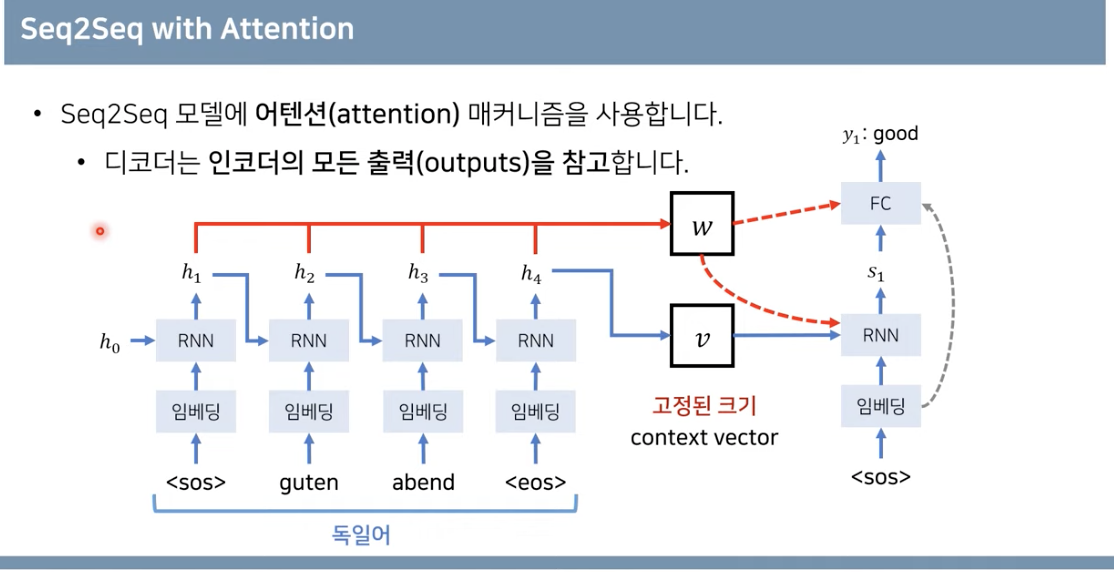
→ Attention 도입
- Transformer(NIPS 2017)에서는 RNN말고 Attention만 사용했더니 훨씬 더 성능이 향상
2. Attention Mechanism 어텐션 매커니즘
💡 어떤 벡터(단어) 에 얼마나 집중해야 할지(Attention) 가중치로 표현하자Seq2Seq 모델의 문제점을 개선하기 위해 제안되었다. 디코더에서 다음 단어 예측을 위해 인코더의 마지막 은닉 상태(컨텍스트 벡터)뿐만 아니라 인코더의 매 시점 은닉 상태들을 모두 사용하자는 것이다.
2-1. Self Attention

- 위 사진처럼 한 문장에 대해 자기 자신의 문장의 어떤 부분에 집중해야하는지 나타내는 게 Self-Attetion
2-2. Attention 계산 과정
'Thinking Machines'라는 문장에서 'Thinking'이라는 단어의 Attention을 구해보자.
아래처럼 Query, Key, Value 각각을 구할 수 있다.
최종적으로 얻고 싶은 건 Z값!
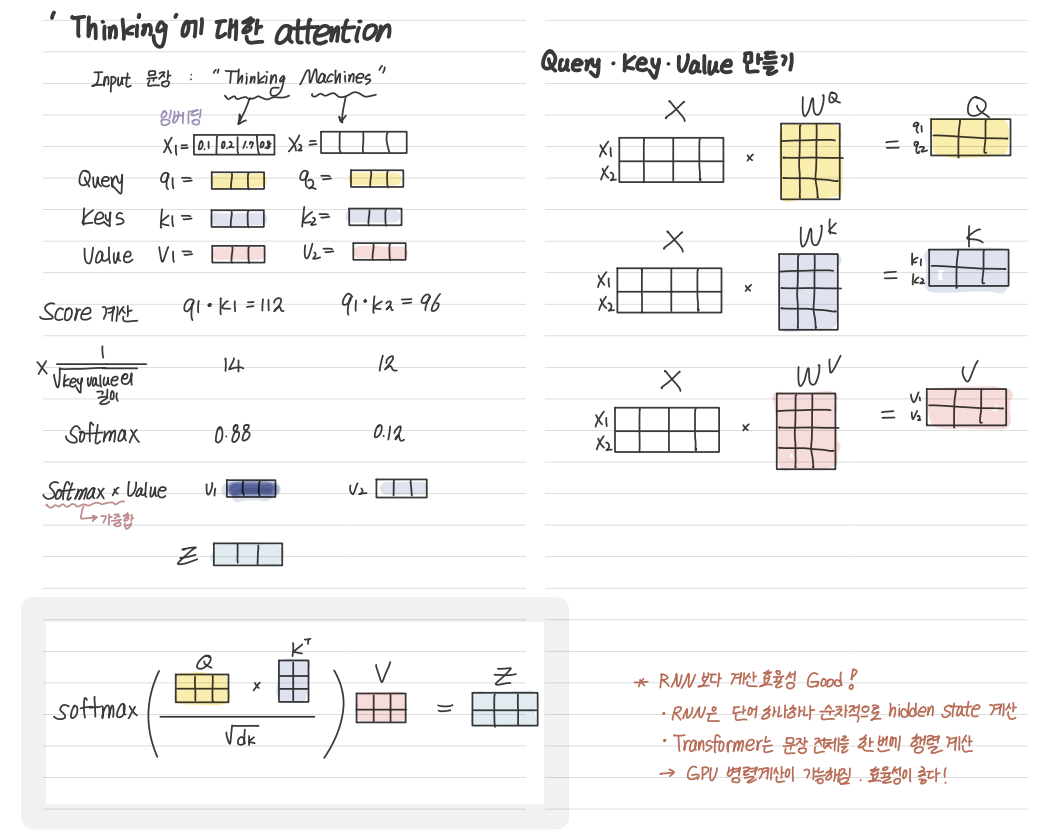
-
중간에 key value길이의 루트값을 나누는 것을 scale factor라고 하는데, 이렇게 하는 이유는 softmax 함수의 0근처에서는 Gradient가 크니까 Vanishing Gradient 문제를 줄이기 위함임
-
RNN에서 계산 효율성이 좋은 이유가 여기에서 나오는데, RNN은 단어 하나하나 순차적으로 hidden state를 계산해야 하는 반면, Transformer는 문장 전체를 한 번에 행렬 계산을 할 수 있고, 이걸 GPU 병렬계산이 가능해지니 계산 효율이 더 좋다고 하는 것!
3. Multi-Head Attention
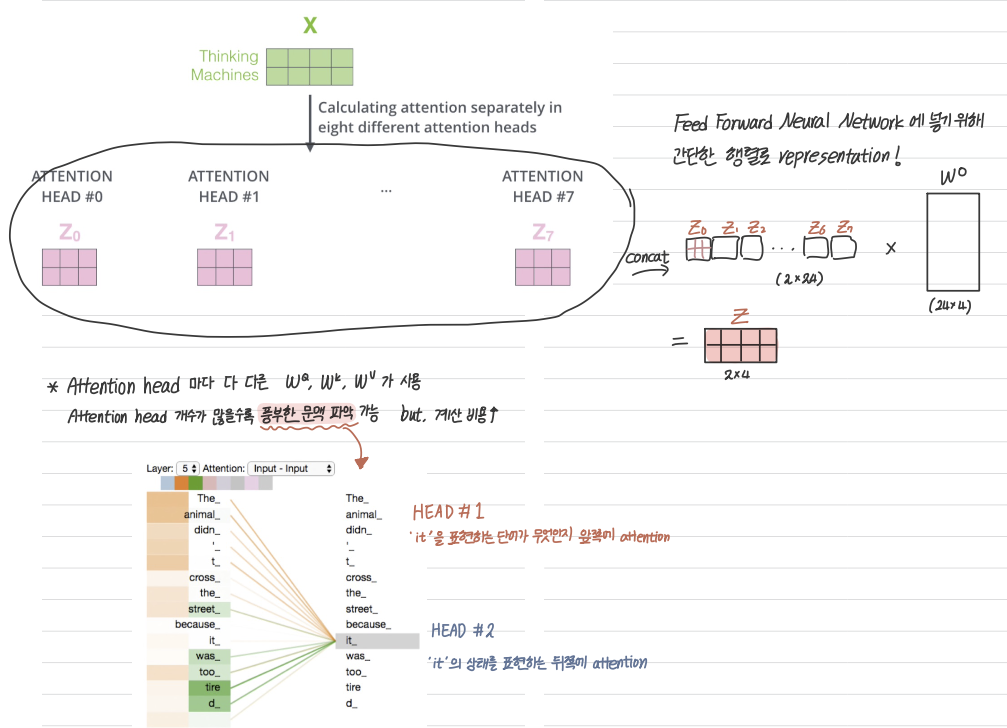
위에서 계산한 Attention과정을 Head라고 하고, 이걸 여러개를 사용해서 Multi-head Attention 이라고 함.
이렇게 여러 개의 헤드를 쓰는 이유는 아래처럼 헤드마다 다 다른 가중치행렬을 쓰기 떄문에 Attention하는 부분이 다르고, 그렇기 때문에 헤드 개수가 많을수록 풍부한 문맥을 파악할 수 있음. (but 계산 비용은 올라가겠지?)
아래 사진 예시를 보면 주황색 선인 HEAD #1은 'it'을 표현하는 Attention을 'The animal'쪽으로 두고 있는데, 대명사가 어떤 명사를 표현하는지를 보여주고,
초록색 선인 HEAD #2는 'it'을 상태를 표현하는 동사쪽에 Attention하는 것을 알 수 있다.
이렇게 여러 개의 어텐션 헤드를 만들어서 그냥 양 옆으로 붙이고, 이를 Feed Forward Neural Network에 넣어야 하니까 한 번 더 행렬곱을 진행해 간단한 행렬로 representation을 한다!
4. 레퍼런스
