
우선 데이터 불러오기
!git clone https://github.com/taehojo/data.git
# 집 값 데이터를 불러옵니다.
df = pd.read_csv("./data/house_train.csv")
df.head()
그룹 지정 및 그룹별 데이터 수 표시
# 팔린 연도를 중심으로 그룹 만든 후 그룹별 수 표시
df.groupby(by='YrSold').size()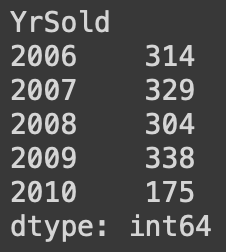
그룹 지정 후 원하는 칼럼 표시하기
# 팔린 연도를 기준으로 그룹 만든 후 그룹별 주차장 넓이의 평균 표시
df.groupby(by='YrSold')['LotArea'].mean()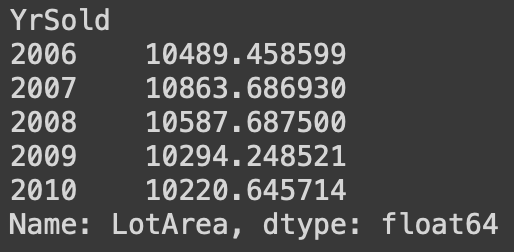
밀집도 기준으로 순위 부여하기
# 각 집 값은 밀집도 기준으로 몇 번째인지
df['SalePrice'].rank(method='dense')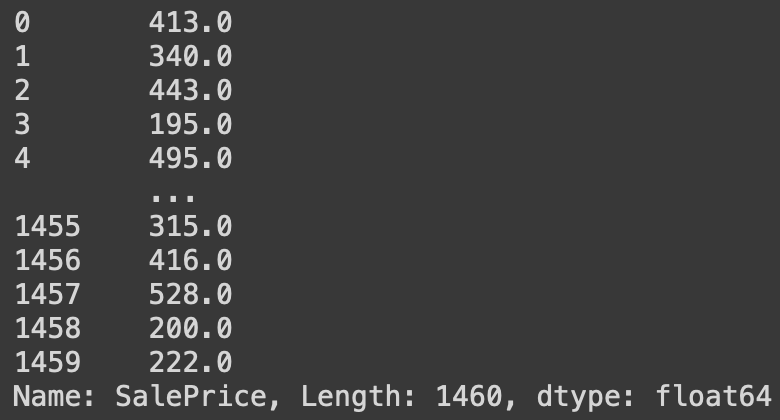
최저값을 기준으로 순위 부여하기
# 각 집 값이 최저값을 기준으로 몇 번째인지
df['SalePrice'].rank(method='min')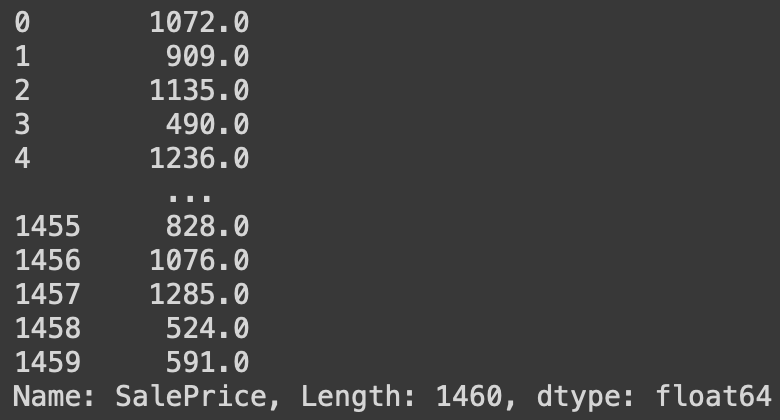
순위를 비율로 표시하기
# 집 값의 순위를 비율로 표시함 (0=가장 싼 집, 1=가장 비싼 집)
df['SalePrice'].rank(pct=True)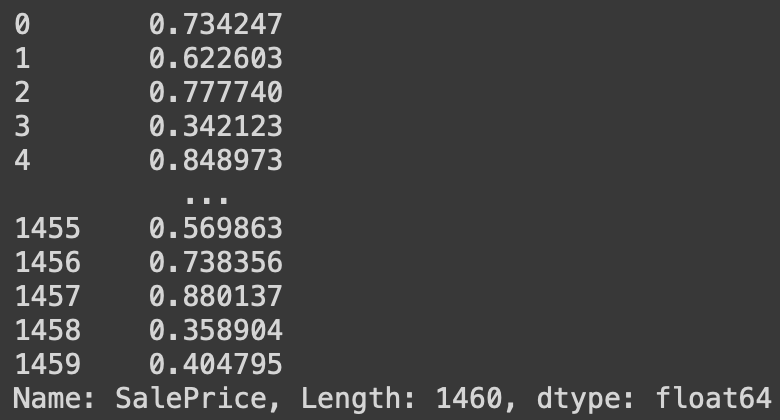
동일 순위 처리 방법
# 순위가 같을 떄 순서가 빠른 것을 상위로 처리
df['SalePrice'].rank(method='first')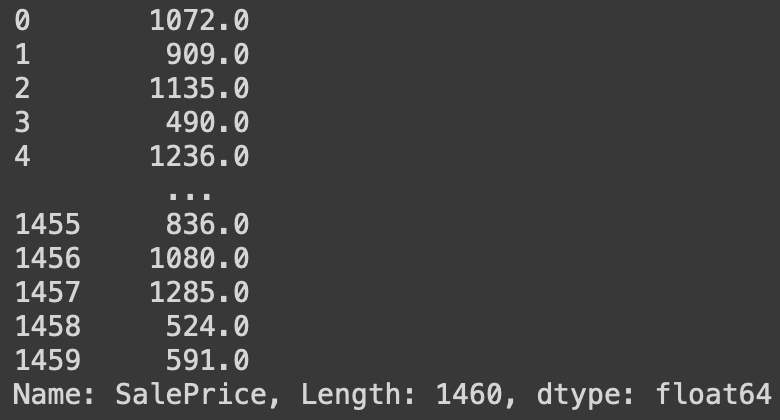

블로그 이전 중입니다 : https://soyeong-blog.netlify.app/