
인과추론이 왜 필요한가?
인과추론은 상관관계로부터 인과관계를 추론하고 언제, 그리고 왜 서로 다른지 이해하는 과학이다. 목적은 바로 현실을 이해하는 것이다.
예를 들어 회사에서 어떤 마케팅이 매출 증가로 이어지는지 알고 싶어한다고 하자. 그것을 알아야 그 마케팅으로서 수익을 늘릴 수 있기 때문이다. 일반적으로 원인과 결과의 관계를 알아야만 원인에 개입하여 원하는 결과를 가져올 수 있다. 이렇게 인과추론을 산업에 적용하면 의사결정 과학의 한 분야가 된다.
상관관계(Correlation)는 인과관계(Cauality)가 아니다
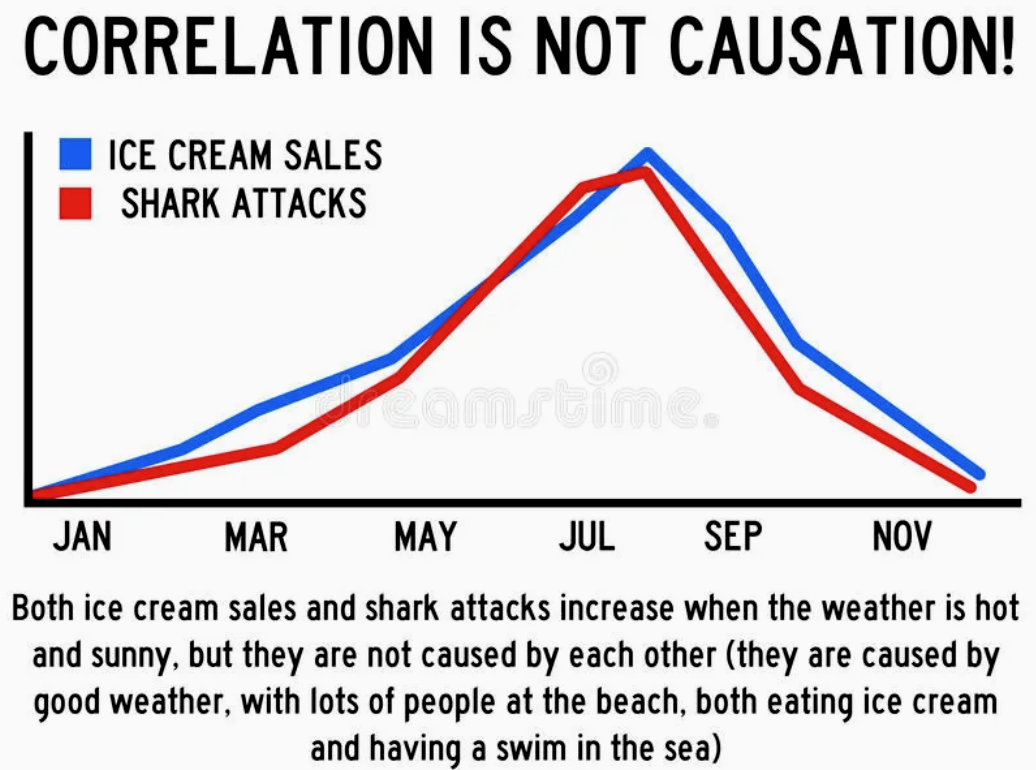
위 사진은 아이스크림 판매량과 상어의 사고횟수를 나타내는 그래프다. 둘은 상관관계는 있으나 인과관계는 없다. 그저 여름에 덥기 때문에 아이스크림을 많이 사먹는 거고, 해변에서 수영을 자주 하다보니 상어에 노출되는 경우가 많은 것뿐이다. 이렇듯 상관관계와 인과관계를 구분할 줄 알아야 한다.
- 상관관계 : 두 개의 수치나 확률변수가 같이 움직이는 것, 즉 통계적 변수가 다른 통계적 변수와 함께 공변(covariance)하는 관계를 말한다. ML모델의 예측을 목적으로 사용된다.
- 인과관계 : 한 변수의 변화가 다른 변수의 변화를 일으키는 것, 즉 선행하는 한 변수가 후행하는 다른 변수의 원인이 되고 있다고 믿어지는 관계를 말한다. ‘원인 설명’이 목적이다.
인과추론의 기본 지식
이제 인과추론에서 사용되는 기본 용어들과 개념을 알아보자.
가격할인이 판매량에 미치는 영향을 알고 싶다고 해보자. 가격할인이 판매량에 영향을 미친다면, 이는 인과관계에 관한 문제이다. 즉, 가격을 할인했을 때가 그렇지 않았을 때보다 얼마나 더 많이 판매했을지를 알고 싶은 거다.
할인여부(is_on_sale)가 주간 판매량(weekly_amount_sold)에 미치는 효과를 알아보자
: 실험 대상 i의 처치 여부
: 실험 대상 i의 결과
- 처치(treatment) : 효과에 대한 개입(intervention)을 나타내는 용어, 이 예시에서는 ‘가격할인(is_on_sale)’을 말함
- 결과(outcome) : 영향을 주려는 변수, 여기서는 주간 판매량(weekly_amout_sold)
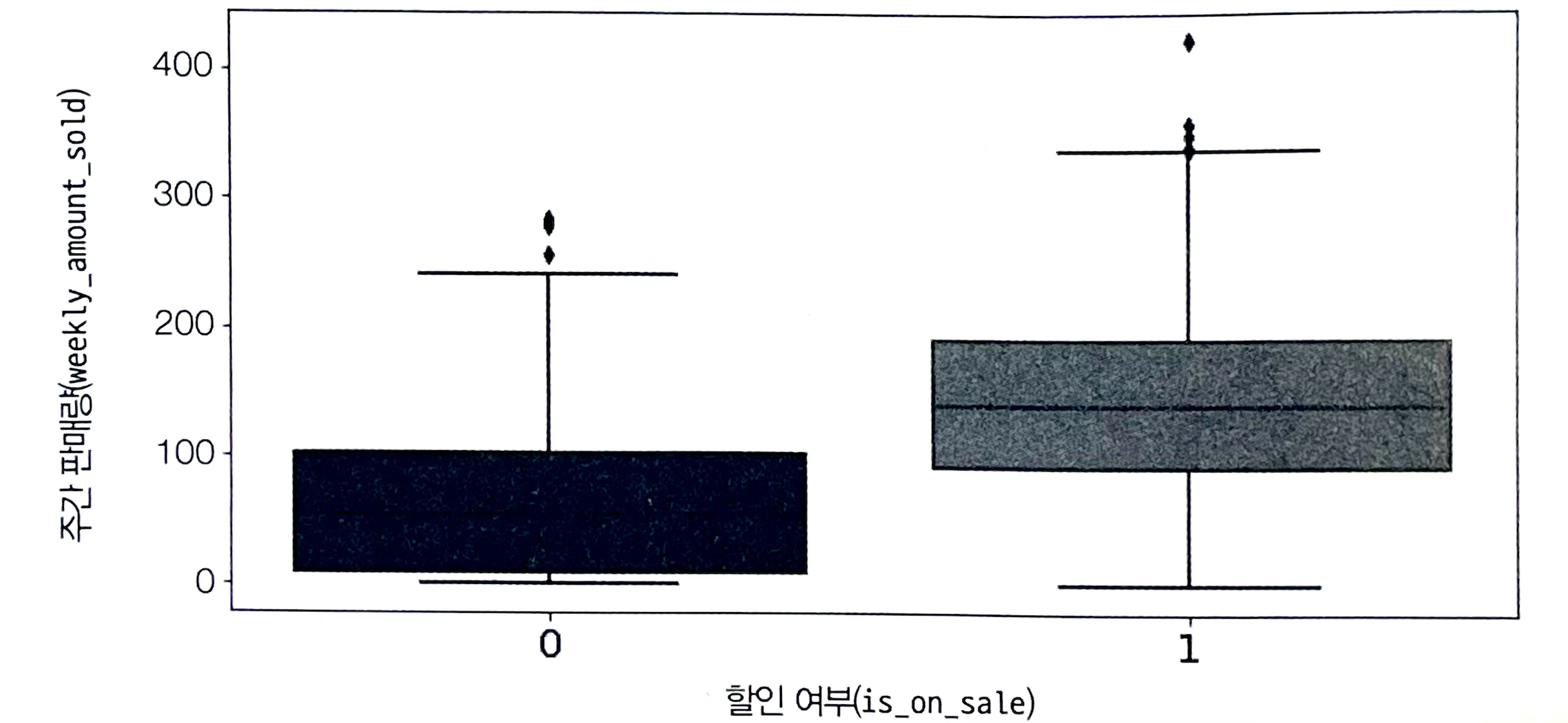
위는 처치(is_on_sale)에 따른 결과(weekly_amount_sold)를 그래프로 나타낸 것이다. 이것만 보면 할인한 경우 판매량이 더 많았음을 알 수 있다.
인과추론의 근본적 문제
인과추론에는 근본적인 문제가 있는데, 동일한 실험 대상이 ‘처치’를 받은 상태와 받지 않은 상태를 동시에 관측할 수 없다는 점이다.
위의 예시를 조금 더 깊이 생각해보면, 연관관계를 인과관계로 착각하고 있었음을 알 수 있다. 판매량이 많게 나타난 이유는 상품을 많이 판매하는 대기업들이 더 공격적으로 가격을 낮출 여유가 있기 때문일 수 있다. 또, 시기에 따라 다른 원인이 발생할 수 있다.
즉, 동일한 실험 대상인 회사가 할인이 진행되는 상황과 그렇지 않은 상황을 동시에 관측할 수 있어야만 가격할인이 판매량에 미치는 효과를 확신할 수 있다는 것이다.
이런 문제들에 대한 대안을 앞으로 하나씩 알아보자.
인과모델
인과모델을 표시하는 공식 표기법을 알아보자. 인과모델에서는 화살표를 써서 인과관계의 비가역성을 표시한다.
첫 번째 식은 모델링 하지 않는 변수 집합인 외부변수()가 함수 를 통해 처치변수 를 유발하는 원인이 됨을 설명한다.
두 번째 식은 처치변수 와 다른 변수 집합 가 함수 를 통해 결과 를 유발함을 의미한다.
이 식에서 알 수 있는 것은 모델링하지 않기로 선택한 변수라 하다더라도 결과에 영향을 미친다는 것이다. 우리 예시에서 보자면, 판매량은 처치()에 해당하는 할인 여부 뿐만 아니라 특정되지 않은 요인인 에 의해 발생한다는 것이다. 변수 의 목적은 모델에 포함된 변수로는 아직 설명되지 않은 변수의 모든 변동을 설명하는 것이다. 이러한 변수를 내생변수(endogenous variable)라고 한다.
더 많은 변수를 사용해 모델링하려면 에서 변수를 꺼내서 인과모델에 명시적으로 포함시키면 된다. 예를 들어 대기업이 더 많이 할인을 할 수 있기 때문이라는 근거에서 BusinessSize를 명시적으로 포함시키는 거다. 그럼 아래와 같이 모델링 할 수 있다.
(1) 추가 내생변수(BusinessSize)를 포함하기 위해, 먼저 그 변수가 어떻게 생성되었는지 나타내는 수식
(2) BusinessSize를 모델 외부벼수로 다루지 않도록 에서 꺼내고, IsOnSalse가 BusinessSize와 외부변수들인 에 의해 발생함을 나타냄
(3) 판매량에는 할인여부(IsOnSalse)와 BusinessSize와, 그 외의 외부변수들이 원인으로 작용함을 나타냄
개입(Intervention)
아주 간단한 인과모델에서 모든 실험 대상이 처치 를 받도록 하는 상황을 가정해보자. 이렇게 하면 에 대한 자연적 원인을 제거하여 상수로 대체할 수 있다.
처치를 로 설정한다면 결과 에 어떤 일이 일어날까?
인과추론에서는 개입을 연산자를 활용해 나타낸다. 에 개입해서 어떤 일이 일어날지를 추론하고 싶다면 로 표현할 수 있다.
연산자로 보는 연관관계와 인과관계의 차이
실제로 가격을 할인한 회사의 판매량 기댓값은 로 표현할 수 있고,
가격을 할인하도록 개입한 경우의 판매량 기댓값은 로 표현한다. 모든 회사가 가격을 할인하도록 통제했을 때 어떤 일이 발생했을지를 나타낸다.
중요한 것은 이 두 개의 조건부 기댓값이 다르다는 점이다.
연산자는 관측된 데이터에서 항상 얻을 수 없은 인과 추정량(causal quantity, causal effect estimand) 을 정의하는 데 사용한다. 이 예제에서 보면 모든 기업이 가격할인이 강요되지 않았기 때문에 모든 회사의 인 상황을 관측할 수 없다. 즉, 연산자는 구하려는 인과 추정량을 분명하게 표현하는 데 사용할 수 있는 이론적 개념으로 사용된다. 대부분의 인과추론은 인과 추정량에 대한 이론적 표현에서 직접 관측할 수 없는 부분을 제거하기 위한 일련의 과정으로, 이를 식별(identification)이라고 부른다.
개별 처치효과(Individual Treatment Effect, ITE)
연산자를 사용하면 실험 대상 i에 처치가 결과에 미치는 영향인 개별 처치효과(Individual Treatment Effect, ITE)를 표현할 수 있다. 아래처럼 두 개입의 차이로 나타낸다.
예시를 적용해보면 아래처럼 쓸 수 있다.
그런데! 앞서 말했듯 인과추론의 근본적인 문제, 앞 식의 두 항 중 하나의 항에 대해서만 관측이 가능하다는 것이다. 그래서 이론적인 식이라고 보면 된다.
잠재적 결과(Potential Outcome)
- 사실적 결과(Factual Outcome) : 관측할 수 있는 한 가지 잠재적 겨과
- 반사실적 결과(Conterfactual Outcome) : 관측할 수 없는 다른 한 가지 결과
→ 예를 들어, 실험 대상 i가 처치를 받았다면, 사실적 결과인 를 관측할 수 있으나 반사실적 결과인 는 알 수 없는 것이다.
그래서 잠재적 결과를 아래처럼 나타낼 수 있다. 이는 ‘처치가 t인 상태일 때, 실험 대상 i의 결과는 Y가 될 것이다’를 의미한다.
잠재적 결과에 따라 회사 i의 인과효과를 정의할 수도 있다.
일치성과 SUTVA
앞서 본 식에는 두 가지 가정이 있다.
1. 일치성(Consisency)이 있어야 한다.
즉, 일 때 여야 한다는 것이다. 로 지정된 처치 외에 숨겨진 다른 처치가 존재하지 않음을 의미한다. 예를 들어 할인쿠폰(처치)을 여러 번 시도했다면, 일치성 가정을 위배하는 것이다. 또 처치가 잘못 정의된 경우에도 일치성 가정이 위배될 수 있다. 예를 들어 재무 설계사의 도움이 개인 자산에 어떤 영향을 미치는지 파악하려고 하는데, 여기서 ‘도움’이 일회성 상담인지, 정기적 조언인지가 다를 수 있는데 이를 하나로 묶어버리면 일치성 가정에 위배되는 것이다.
2. 상호 간섭 없음(No interference) 또는 SUTVA(Stable Unit of Treatment Value Assumption)이다.
하나의 실험 대상에 대한 효과가 다른 실험 대상에 영향을 주지 않아야 한다는 것이다.
파급효과(spillovers effect)나 네트워크 효과가 있는 경우 이런 가정을 위배할 수 있다. 예를 들어 백신이 전염성 질환에 미치는 영향을 알고 싶은 경우, 한 사람에게 백신을 접종하면 보통 그 주위 사람들의 질병 확률이 낮아진다. 이렇게 가정을 위배하는 경우, 일반적으로 처치효과가 실제보다 작다고 결론내리게 된다. 파급 효과가 발생하면 대조군도 처치의 영향을 받으므로, 파급 효과가 없을 때보다 실험군과 대조군 간의 차이가 작아지기 때문이다.
인과 추정량
이렇게 인과추론의 근본적인 한계가 무엇인지 알게 되었다. 그러나 추정량을 통해 이 문제를 어느정도 해결해볼 수 있다. ATE라는 것인데, 이를 세 가지 방식으로 정의해 볼 수 있다.
평균 처치효과(Average Treatment Effect, ATE)
평균 처치효과(ATE)는 처치 가 평균적으로 미치는 영향을 나타낸다. 앞서 본 인과추론의 근본적 문제 때문에 하나의 실험 대상의 효과는 알기 어려나, 기댓값은 알 수 있는 것이다.
가격할인이 판매량에 미치는 평균 영향을 아래와 같이 쓸 수 있다.
실험군에 대한 평균 처치효과(Average Treatment Effect on the Treated, ATT)
이는 처치 받은 대상에 대한 처치효과이다. ATT는 처치 받은 대상을 조건으로 하므로, 는 항상 관측되지 않지만, 이론적으로는 잘 정의될 수 있다. (무슨 말이지??)
가격을 할인한 회사가 어떻게 판매량을 늘렸는지 보자.
조건부 평균 처치효과(Conditional Average Treatment Effect, CATE)
변수 X로 정의된 그룹에서의 처치효과를 의미한다. 예를 들어 50세 이상과 그보다 젊은 고객에게 광고가 미치는 영향을 비교하는 데 쓸 수 있다. 이렇듯 어떤 유형의 실험 대상이 개입에 더 잘 반응하는지를 봐서 개인화에 유용하다.
크리스마스 주간의 할인 여부가 미치는 영향은 아래처럼 나타낼 수 있다.
인과 추정량 예시
다음 표는 잠재적 결과를 알고 있다고 가정하고 작성한 표이다. 다음 표를 기준으로 ATE, ATT, CATE를 구하는 예시를 보자.
| i | y0 | y1 | t | x | y | te(y1-y0 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 200 | 220 | 0 | 0 | 200 | 20 |
| 1 | 2 | 120 | 140 | 0 | 0 | 120 | 20 |
| 2 | 3 | 300 | 400 | 0 | 1 | 300 | 100 |
| 3 | 4 | 450 | 500 | 1 | 0 | 500 | 50 |
| 4 | 5 | 600 | 600 | 1 | 0 | 600 | 0 |
| 5 | 6 | 600 | 800 | 1 | 1 | 800 | 200 |
- i : 실험 대상
- y0, y1 : 실험군 및 대조군에 따른 잠재적 결과
- t : 처치(할인) 여부
- x : 크리스마스 일주일 전이면 1, 크리스마스 주면 0
만약 AmountSold0과 AmountSold1를 모두 알 수 있다면 모든 인과 추정량을 쉽게 구할 수 있다.
ATE는 마지막 열(te)의 평균이다. 65의 의미는 가격 할인으로 판매량이 65개가 증가함을 의미한다.
ATT는 일 때 마지막 열의 평균이다. 즉, 가격을 할인한 회사는 가격할인에 따른 판매량이 83.33개가 증가했다.
크리스마스 1주일 전이라는 조건부 평균효과는 회사 3번과 6번 효과의 평균이다.
크리스마스 주에 대한 평균 처치효과(CATE)는 다음과 같이 구한다.
즉, 크리스마스 주간에 가격을 할인하면 평균 22.5개의 판매량이 증가하고, 크리스마스 1주일 전에 할인했을 때는 평균 150개가 증가하는 것이다. 따라서 가격을 일찍 할인한 매장이 나중에 할인한 매장보다 더 많은 이득을 보았다고 할 수 있다.
현실 세계에서는 다음 표처럼 알 수 없는 값이 많다. 잠재적 결과중 하나만을 볼 수 있으므로, 개별 처치효과를 파악할 수 없다.
| i | y0 | y1 | t | x | y | te(y1-y0 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 200 | NaN | 0 | 0 | 200 | NaN |
| 1 | 2 | 120 | NaN | 0 | 0 | 120 | NaN |
| 2 | 3 | 300 | NaN | 0 | 1 | 300 | NaN |
| 3 | 4 | NaN | 500 | 1 | 0 | 500 | NaN |
| 4 | 5 | NaN | 600 | 1 | 0 | 600 | NaN |
| 5 | 6 | NaN | 800 | 1 | 1 | 800 | NaN |
처치를 받은 회사와 그렇지 않은 회사의 평균을 비교하는 것은 연관관계를 인과관계로 착각하는 중대한 오류를 범하는 것이다. 이제 연관관계가 인과관계가 아닌 이유를 이해해보자.
편향(bias)
편향(Bias)는 인과관계와 연관관계를 다르게 만드는 요소이다.
ATE를 추정하려면 실험군이 처치 받지 않았을 경우인 와 대조군이 처치 받았을 경우인 을 추정해야 한다. 즉, 를 찾을 때 를 추정하게 된다. 두 값이 일치하지 않는다면, 처치 t를 받은 실험 대상의 평균 결과인 는 추정하고 싶은 의 편향 추정량이 된다.

편향의 수식적 이해
표본평균이 추정하려는 잠재적 결과의 평균과 다를 수 있는 이유를 앞서 살펴봤다. 이제는 평균의 차이가 ATE와 같지 않은 이유를 살펴보자.
예제에서 처치와 결과 간의 연관관계는 으로 측정된다. 이는 할인을 진행한 회사의 평균 판매량과 할인하지 않은 회사의 평균 판매량을 뺸 값이다.
반면, 인과관계는 으로 측정할 수 있다.
이 두 식이 왜 다른지 살펴보자.

위 식으로 알 수 있다시피, 연관관계는 실험군에 대한 처치효과(ATT)에 편향을 더한 값이다. 편향은 처치와 관계 없이 실험군과 대조군이 어떻게 다른지에 따라 주어지고, 이는 의 차이로 표현된다.
이런 일이 왜 발생할까?
바로 교란(Confounding)때문이다. ‘관측할 수 없는 많은 요소가 처치와 함께 변화하므로 편향이 발생한다’고 생각하면 된다. 실험군과 대조군은 단순히 할인 여부뿐만 아니라 회사규모, 위치, 경영 방식 등의 다른 여러 요소가 다르다. 때문에 가격할인으로 인해 판매량이 얼마나 증가하는지 알기 위해서는 할인한 회사와 그렇지 않은 회사가 평균적으로 비슷해야 한다. 이것을 ‘실험군과 대조군이 교환가능(Exchangeable)하다’고 표현한다.
인과효과 식별
실험군과 대조군이 서로 교환 가능하다면, 주어진 데이터만으로도 인과관계를 표현하는 일이 아주 간단해진다는 의미다. 즉, 가격을 할인한 회사와 그렇지 않은 회사가 서로 비슷하다면(교환 가능하다면), 두 그룹 간의 판매량 차이는 오직 가격할인 때문이라고 볼 수 있다는 것이다. 수식으로 살펴보면 다음과 같다.

그러나 현실에서는 하나의 잠재적 결과만 관측할 수 있으므로, 인과 추정량을 관측할 수 없다. 하지만, 관측 가능한 다른 수치를 찾아서 이를 관심있는 인과 추정량을 찾는 데 활용할 수 있다. 관측 가능한 데이터에서 인과 추정량을 찾아내는 방법을 ‘식별 과정’이라고 한다.
독립성 가정
교환 가능성은 인과추론의 핵심 가정이다.
와 같이 잠재적 결과와 처치가 독립적이라고 가정한다. 독립성 가정은 , 즉 처치가 잠재적 결과에 관한 어떠한 정보도 제공하지 않음을 의미한다. 어
랜덤화와 식별
독립성 가정으로 연관관계를 인과관계로 같게 만드는 방법을 알아보자. 인과추론 문제는 보통 다음과 같이 두 단계로 나뉜다.
- 식별(identification) : 관측 가능한 데이터로 인과 추정량을 표현하는 방법을 알아내는 단계
- 추정(estimation) : 실제로 데이터를 사용하여 식별한 인과 추정량을 추정하는 단계
처치를 무작위로(Randomize) 배정할 수 있다고 가정하자. 실험 대상에 처치가 무작위로 이루어진다면 잠재적 결과는 물론이고 어떤 변수와도 독립적이 된다. 이렇듯, 랜덤화는 독립성 가정을 만족시키도록 한다.
이게 인과적 식별 작업의 핵심이다. 즉, 인과적 식별은 편향을 제거하고 실험군과 대조군을 비교할 수 있게 만드는 방법을 찾아서 눈에 보이는 모든 차이를 처치에 따른 효과로 돌리는 과정이다. 여기서 식별은 데이터 생성 과정을 알거나 기꺼이 가정할 수 있는 경우에만 가능하다. 즉, 일반적으로 처치가 어떻게 배정되었는지를 알 수 있을 때 식별이 가능하다.
다음 장에서는 랜덤화추출(Randomization)를 통해 인과추론의 추론 부분을 알아보도록 하자!
Reference
- 책 : 실무로 통하는 인과추론
- 인과관계 vs. 상관관계 - Granger causality - The Pabii Research

자세한 글 덕분에 헷갈렸던 개념이 정리가 잘 되었어요! 수식도 함께 있어서 더 좋은것 같아요:)