0. 프로젝트 소개
앞으로 블로그에 데이콘 대회나 학습 내용을 남기려고 한다. 데이콘 첫 포스팅인 만큼, 가볍게 학습(중급)에서 아파트 실거래가 예측 프로젝트를 데이콘이 제공한 코드에 따라 학습해보겠다.
이 프로젝트는 아파트의 실거래가를 예측하는 프로젝트이다.
1. 데이터 확인
준비된 데이터는 이와 같다.
train.head(), train.info(), train.describe()를 통해 간략하게 데이터 확인 작업을 걸친다.
- info(): 데이터프레인의 전체 크기, 열 이름, 열 데이터 타입, non-null의 수, 메모리 사용량
- describe(): 개수, 평균, 표준편차, 최소값~분위수~최대값
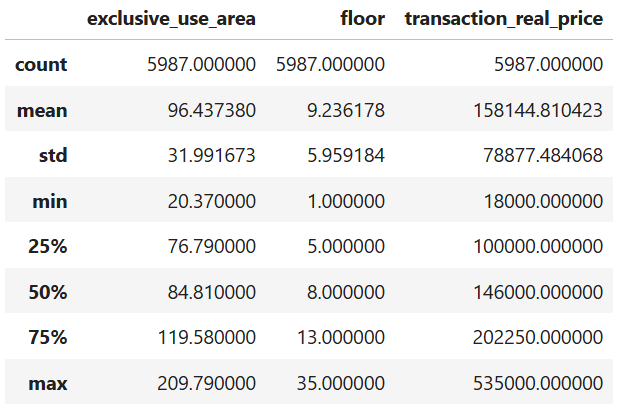
object 데이터를 제외하고 확인한 결과이다. 매매가 1사분위수 76m^2, 2사분위수 84m^2 사이즈의 아파트에서 매매가 활발히 일어난다.
2. EDA
- transaction_real_price: 우선 타겟 데이터(가격)의 데이터 형식을 문자형에서 수치형으로 변환하여 히스토그램으로 확인한다.
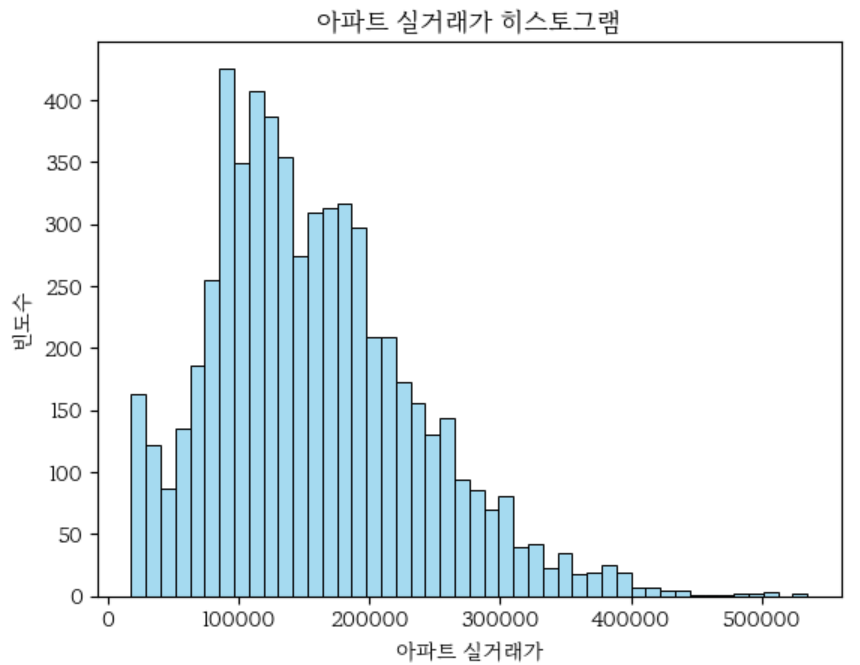
타겟 데이터의 분포를 히스토그램으로 확인해봤을 때, 왼쪽으로 쏠려있는 분포를 가진다. 10억원의 가격대가 가장 많은 것도 확인할 수 있다.
- sigungu, jibun 컬럼: value_count()로 확인해봤을 때, sigungu는 하나의 데이터 값만을 가지기 때문에 생략하고, jibun은 위치 데이터를 가져와야하는데, 이번 프로젝트에서는 생략하기로 했다.
- apt 컬럼: 아파트 단지별로 실거래가를 살펴 봤을 때, 10억원 정도의 아파트 단지 수가 가장 많다.
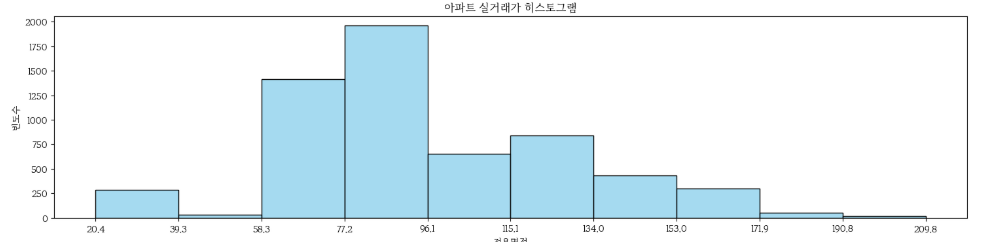
data = train[['apt_name', 'transaction_real_price']].groupby('apt_name').mean() - exclusive_use_area 컬럼: sns.histplot()으로 히스토그램을 그린다. 구간의 개수는 num_bins로 조절한다. 58~96m^2의 집 거래량이 가장 많다.
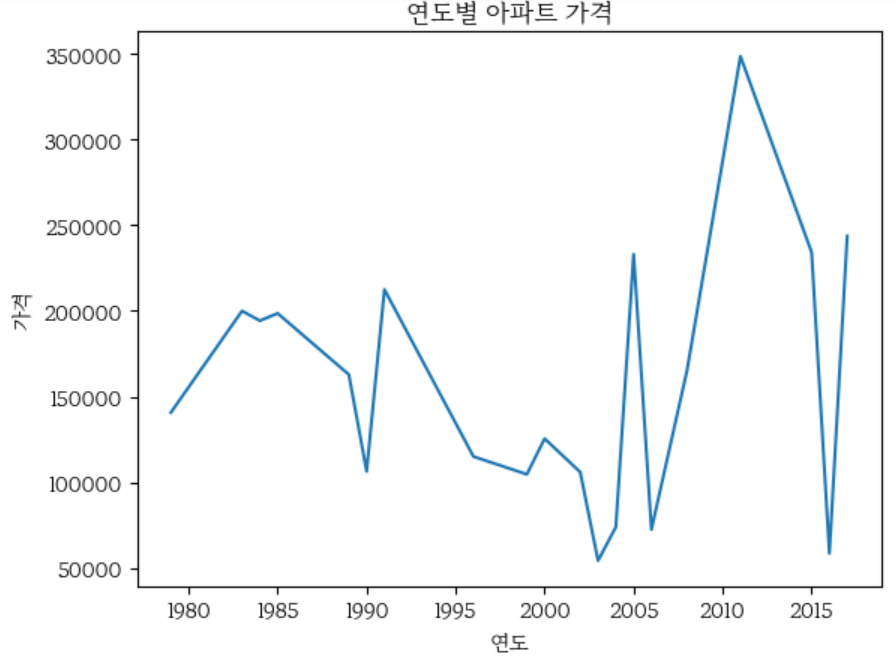
- year_of_completion 컬럼: plt.plot()으로 선 그래프를 그린다. 오래된 아파트가 새 아파트보다 상대적으로 가격이 낮다.
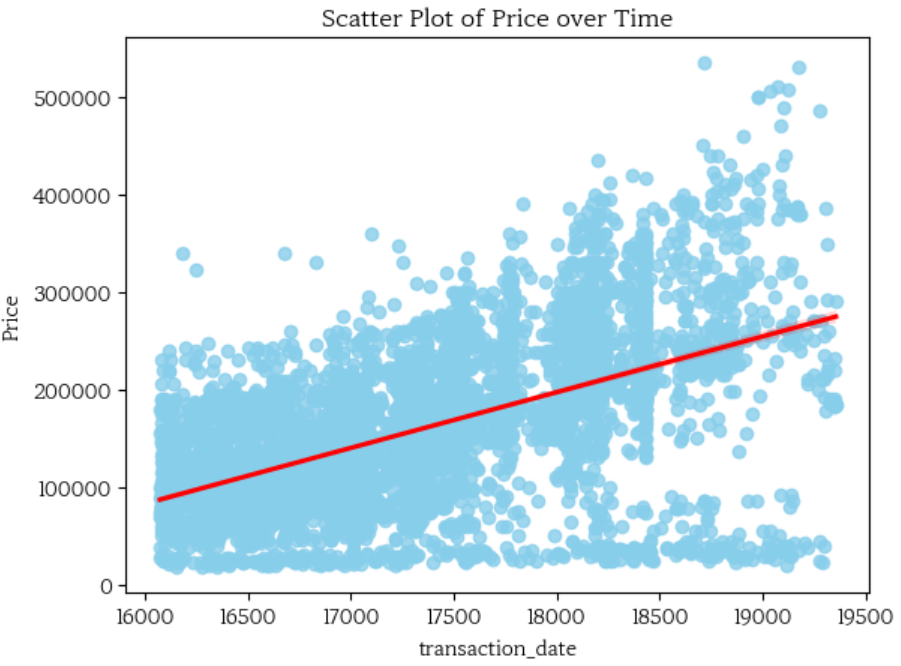
- 날짜 데이터 전처리: 'transaction_day'피처와 'transaction_date'피처를 합치고, 데이터의 형식을 datetime으로 변경해주고 sns.regplot()으로 scatter plot을 그린다. regplot은 Seaborn에서 제공하는 함수로, 데이터 간의 선형 관계를 시각화하는 선형 회귀 플롯을 만든다. 그래프를 확인해 보면, 날짜와 가격 사이에 양의 상관관계가 있다.
- floor 컬럼: floor가 1일 때와 1이 아닐 때의 아파트 실거래가 평균을 구해봤을 때, 무의미하여 제거해준다.
3. 데이터 전처리
- 날짜 데이터를 datetime 형태로 만들어준다.
- 아파트 면적을 기준으로 0, 1, 2로 분류하여 새로운 피처를 만들어준다.
- 아파트의 최근 거래량을 가져온다.
- 거래 데이터에 금리를 적용시킨다.
- 아파트의 과거 가격 순서대로 정렬한 후, 비슷한 아파트끼리 묶어 그룹을 만들어준다.: K-Means
4. 데이터 모델링
랜덤포레스트 모델을 이용해 모델링 하였다. 하이퍼파라미터를 최적화하기 위해서 Optuna 라이브러리를 사용해주었다. 베이즈 최적화 알고리즘을 기반으로 탐색을 수행한다.
# RandomForestRegressor
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth)
model.fit(train_x, train_y)# Optuna를 사용하여 하이퍼파라미터 탐색
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=50)
- 이렇게 학습된 결과를 MAE로 평가해보았더니 27530.7989라는 결과가 나왔다.
- feature_importance도 확인해보았다.
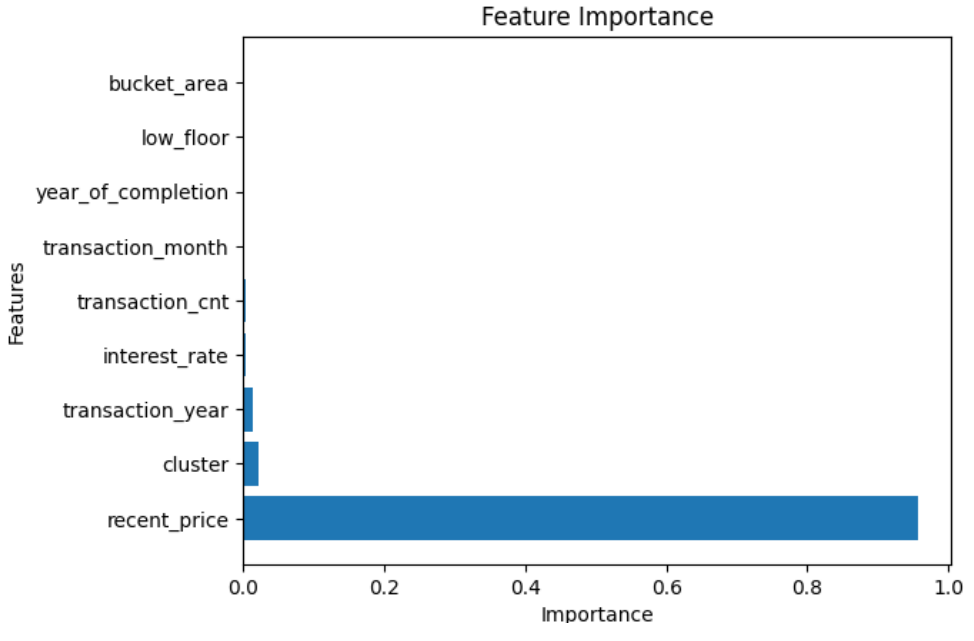
피처 중요도가 낮은 'bucket_area', 'low_floor', 'year_of_completion'은 제외하고 다시 학습해보자.
- 시계열 모델 교차검증을 시행했다. 시계열 데이터의 순서를 섞지 않도록 주의해야 하며, 검증 데이터가 학습 데이터보다 미래 시점이 되어야한다. 검증 데이터를 분리할 때, 1년 단위로 추출하였다.
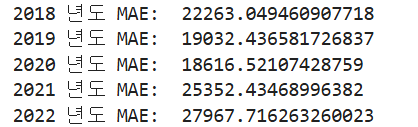
결과를 확인해보면, 2018~2020에는 오차가 점점 줄어들다가 2021~2022에는 오차가 점점 증가하는 것을 볼 수 있다. 실제로 2021~2022에는 부동산 가격의 변화가 급격해진 시기이기도 하다.
- 아래와 같이 학습이 마무리된 아파트 실거래가 예측 데이터를 확인할 수 있다.