1장 웹에서 주문 수를 분석하는 테크닉 10
0. 10개의 테크닉
- 001 데이터 읽기
- 002 데이터 결합(Union)
- 003 매출 데이터끼리 결합(Join)
- 004 마스터데이터 결합(Join)
- 005 필요한 데이터 칼럼 만들기
- 006 데이터 검산
- 007 각종 통계량 파악
- 008 월별로 데이터 집계
- 009 월별, 상품별 데이터 집계
- 010 상품별 매출 추이 가시화
예제 코드: https://github.com/wikibook/pyda100
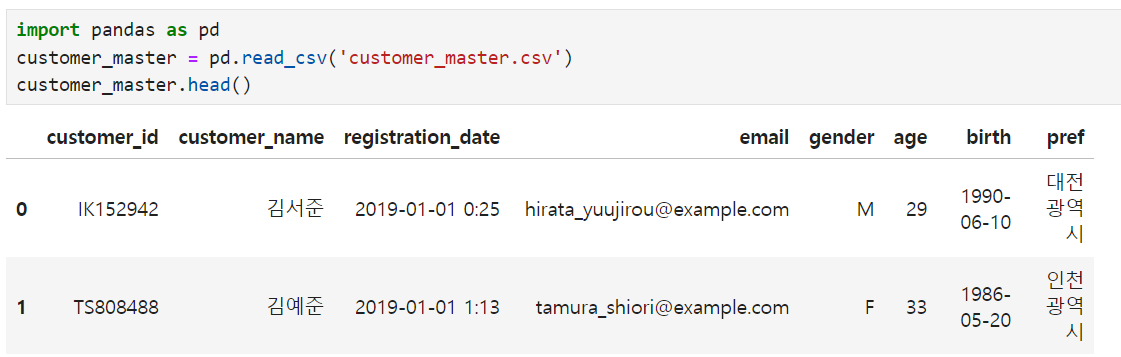
1. 데이터 읽기
2. 데이터 결합
002 Union: 행 방향 결합
transaction = pd.concat([transaction_1, transaction_2], ignore_index=True)
transaction_detail=pd.concat([transaction_detail_1,transaction_detail_2], ignore_index=True)concat 이용
003, 004 Join: 열 방향 결합
기준 데이터 결정 후 -> 어떤 칼럼을 키로 조인할지 생각(부족한 데이터 칼럼 생각 & 공통 데이터 칼럼 생각)
# 003 거래 정보
join_data = pd.merge(transaction_detail, transaction[["transaction_id", "payment_date", "customer_id"]],
on="transaction_id", how="left")

merge 이용
# 004 거래 정보 + 고객 정보 + 상품 정보
join_data = pd.merge(join_data, customer_master, on="customer_id", how="left")
join_data = pd.merge(join_data, item_master, on="item_id", how="left")
join_data.head()3. 데이터 컬럼 생성 및 검산
매출 = quantity * item_price
- 데이터 컬럼 생성
join_data["price"] = join_data["quantity"] * join_data["item_price"]- 검산
join_data["price"].sum() == transaction["price"].sum()4. 통계량 파악
- 결손치 개수: True 개수 sum
join_data.isnull().sum()- 전체 파악: 데이터 개수(count), 평균값(mean), 표준편차(std), min~max
join_data.describe()- 데이터 타입 파악(열 속성)
join_data.dtypes5. 데이터 집계
008 월별 데이터 집계
- payment_date -> payment_month: datatime 형태로 변환
#datatime형 변환
join_data["payment_date"] = pd.to_datetime(join_data["payment_date"])
#새로운 칼럼 payment_month 연월 단위로 작성 / dt 사용
join_data["payment_month"] = join_data["payment_date"].dt.strftime("%Y%m")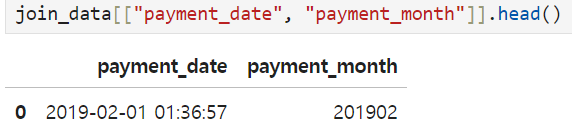
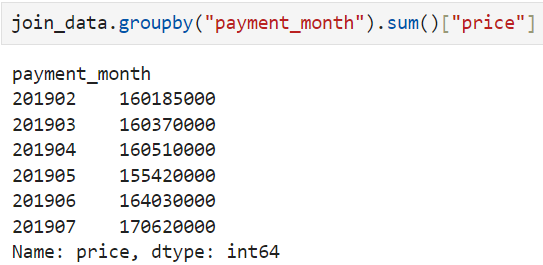
- 월별 매출 집계
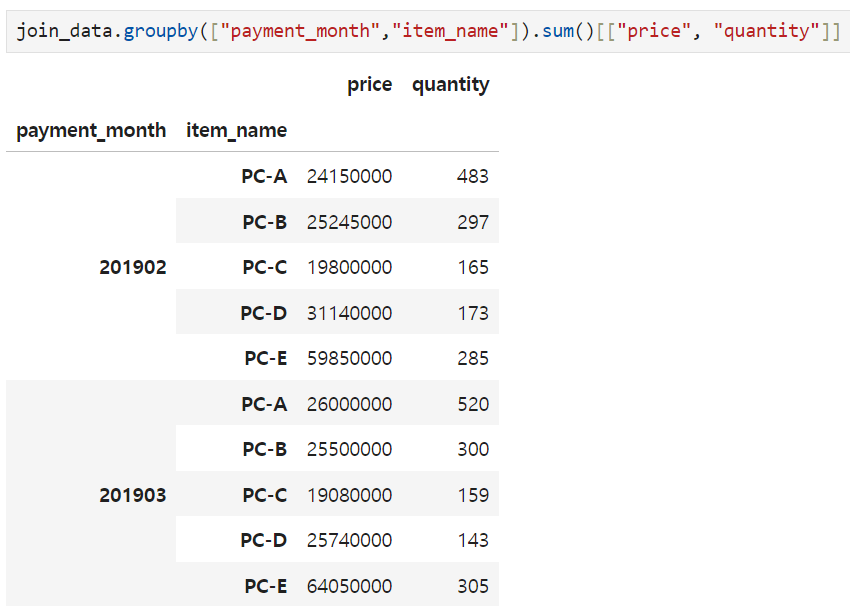
009 월별, 상품별 데이터 집계
-
groupby로 집계: 덜 직관적
-
pivot_table로 집계
pd.pivot_table(join_data, index='item_name', columns='payment_month', values=['price', 'quantity'], aggfunc='sum')
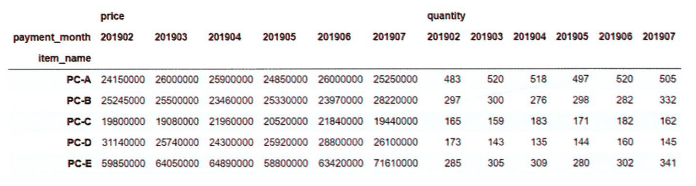
행: 상품명
열: 연월
value: 집계하고 싶은 칼럼(price, quantity)
aggfunc: 집계 방식(sum)
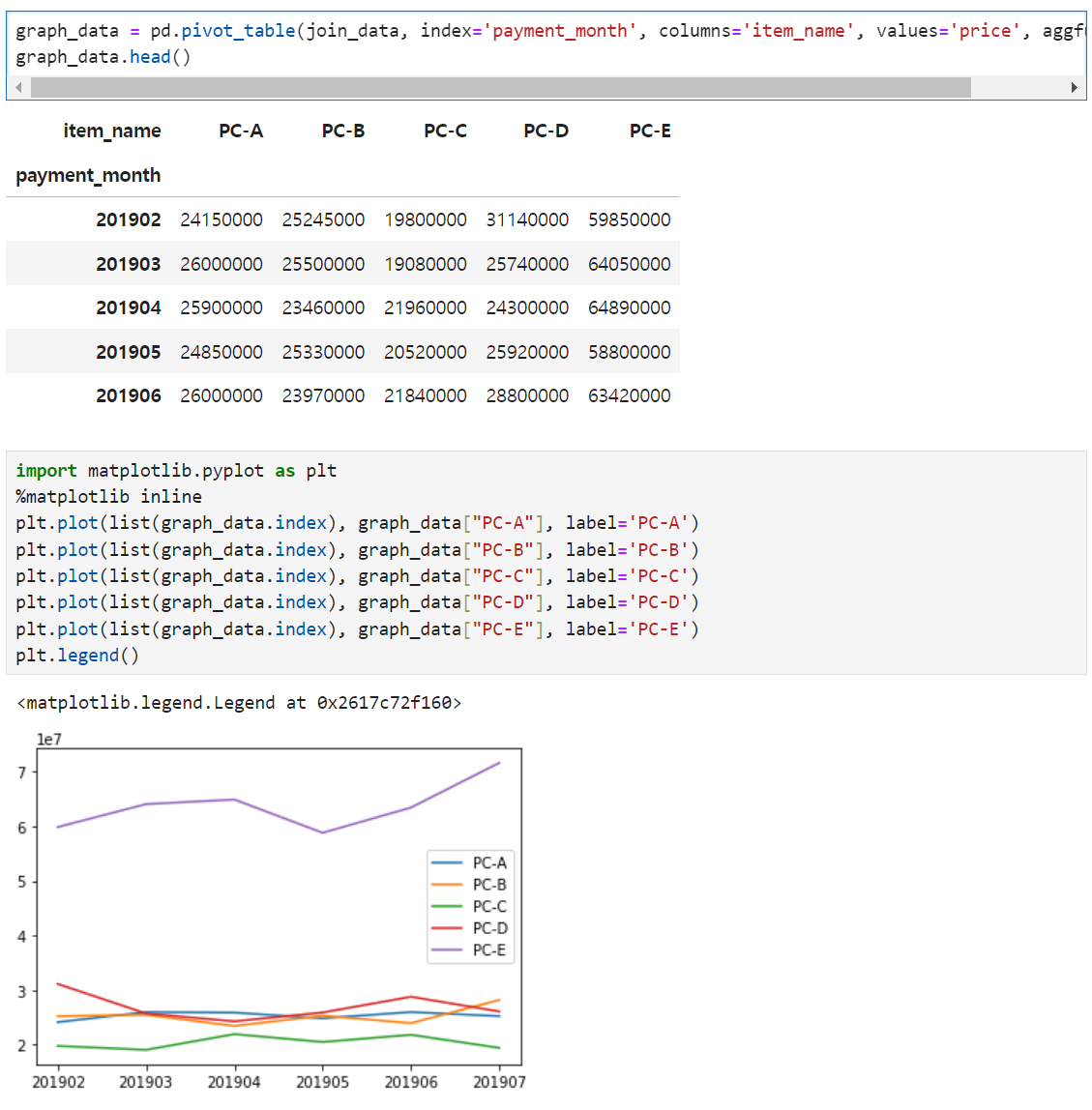
6. 상품별 매출 추이 가시화
2. 대리점 데이터를 가공하는 테크닉 10
0. 10개의 테크닉
- 011 데이터 읽기
- 012 오류 살피기
- 013 오류가 있는 상태로 집계
- 014 상품명 오류 수정
- 015 금액 결측치 수정
- 016 고객 이름 오류 수정
- 017 날짜 오류 수정
- 018 고객 이름을 키로 두 개의 데이터 결합(Join)
- 019 정제한 데이터 덤프
- 020 데이터 집계
1. 데이터 읽기
- 결측치, 오류가 있는 데이터
- '데이터의 정합성에 문제가 있다.'
2. 오류 살피기 & 집계
012 오류 살피기
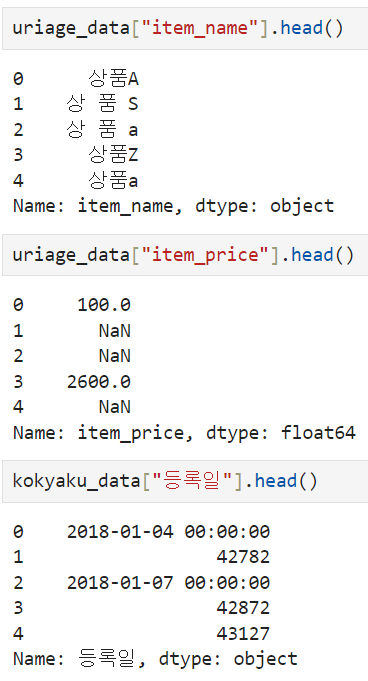
013 오류 데이터 집계
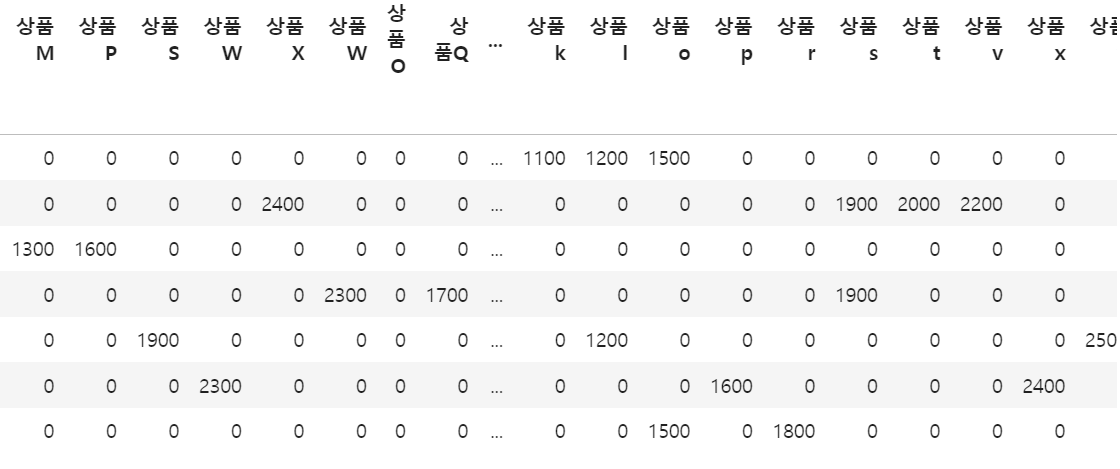
3. 오류 수정
014, 016 상품명, 고객이름 오류 수정
# 대문자 변환
uriage_data["item_name"] = uriage_data["item_name"].str.upper()
# 공백 제거
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
# item_name 순으로 정렬
uriage_data.sort_values(by=["item_name"], ascending=True)015 금액 결측치 수정
flg_is_null = uriage_data["item_price"].isnull()
# 결측치가 존재하는 상품명 추출해서 중복 제거
for trg in list(uriage_data.loc[flg_is_null, "item_name"].unique()):
# 결측치 상품과 같은 상품의 데이터 금액을 결측치에 대입
price = uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"] == trg), "item_price"].max()
uriage_data["item_price"].loc[(flg_is_null) & (uriage_data["item_name"]==trg)] = price
uriage_data.head()- skipna=false : 결측값을 건너뛰지 않는다, 최솟값이 NaN으로 표시된다.
017 날짜 오류 수정
flg_is_serial = kokyaku_data["등록일"].astype("str").str.isdigit()
fromSerial = pd.to_timedelta(kokyaku_data.loc[flg_is_serial, "등록일"].astype("float"), unit="D") + pd.to_datetime("1900/01/01")
fromString = pd.to_datetime(kokyaku_data.loc[~flg_is_serial, "등록일"])
kokyaku_data["등록일"] = pd.concat([fromSerial, fromString])
kokyaku_data["등록연월"] = kokyaku_data["등록일"].dt.strftime("%Y%m")
rslt = kokyaku_data.groupby("등록연월").count()["고객이름"]4. 데이터 결합 & 덤프
018 데이터 결합
join_data = pd.merge(uriage_data, kokyaku_data, left_on="customer_name", right_on="고객이름", how="left")
join_data = join_data.drop("customer_name", axis=1)
join_data019 데이터 덤프
dump_data = join_data[["purchase_date", "purchase_month", "item_name", "item_price", "고객이름", "지역", "등록일"]]
dump_data.to_csv("dump_data.csv", index=False)