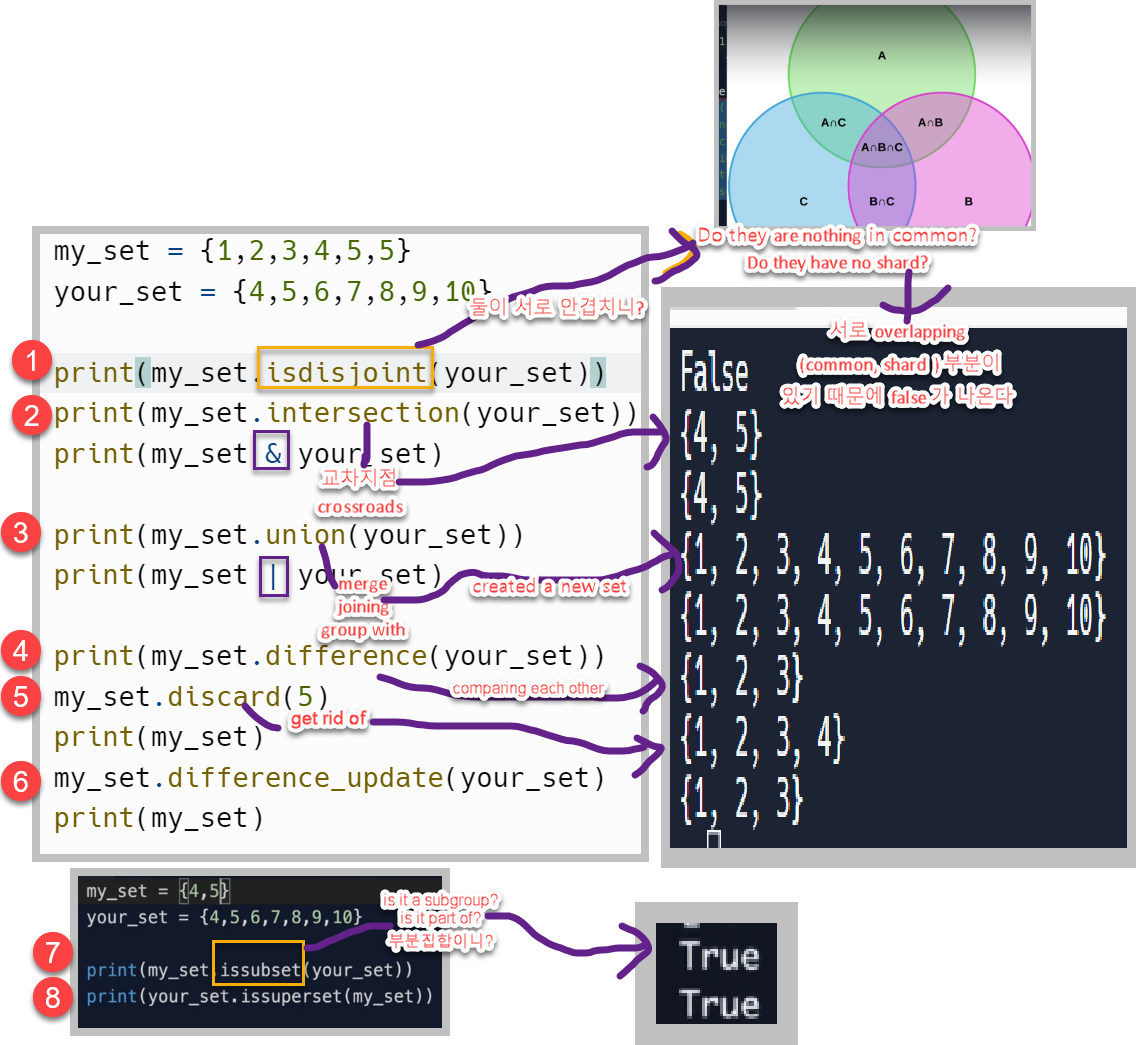
자료구조: List
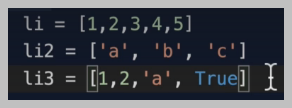
list 자료구조는 item들을 담은 collection(모음집)이다. 파이썬에서 list는 sqare brackets [] 를 이용하여 array의 형식으로 표현한다.
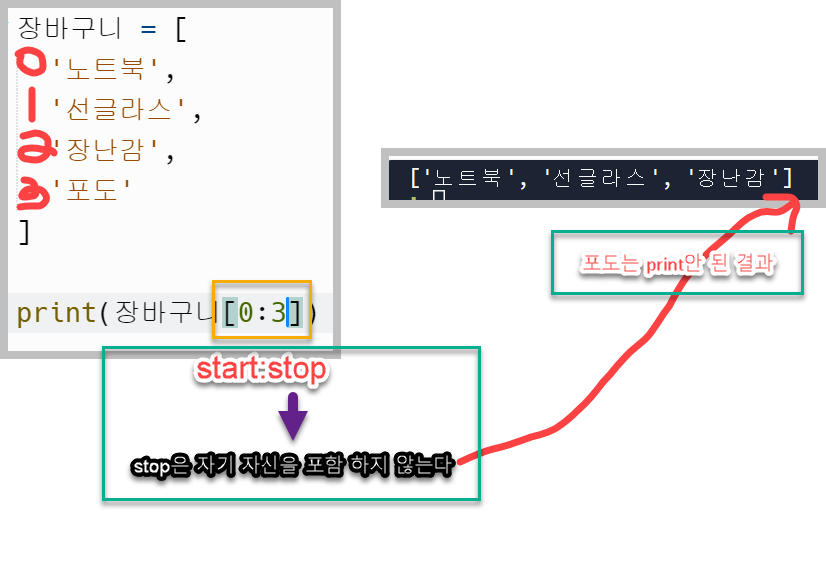
List: slicing
List 의 특징 (= mutable)
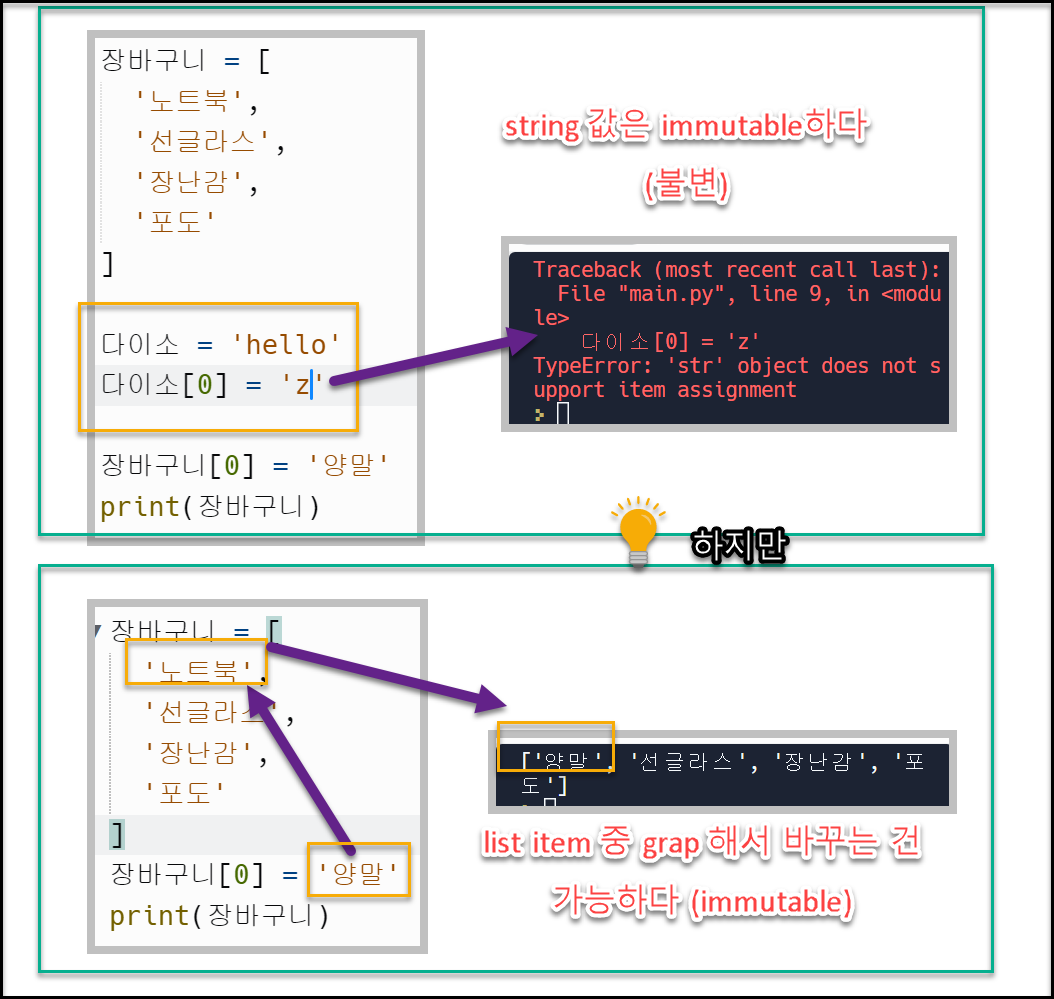
list는 mutable(changeable)하다.
modifying vs copying
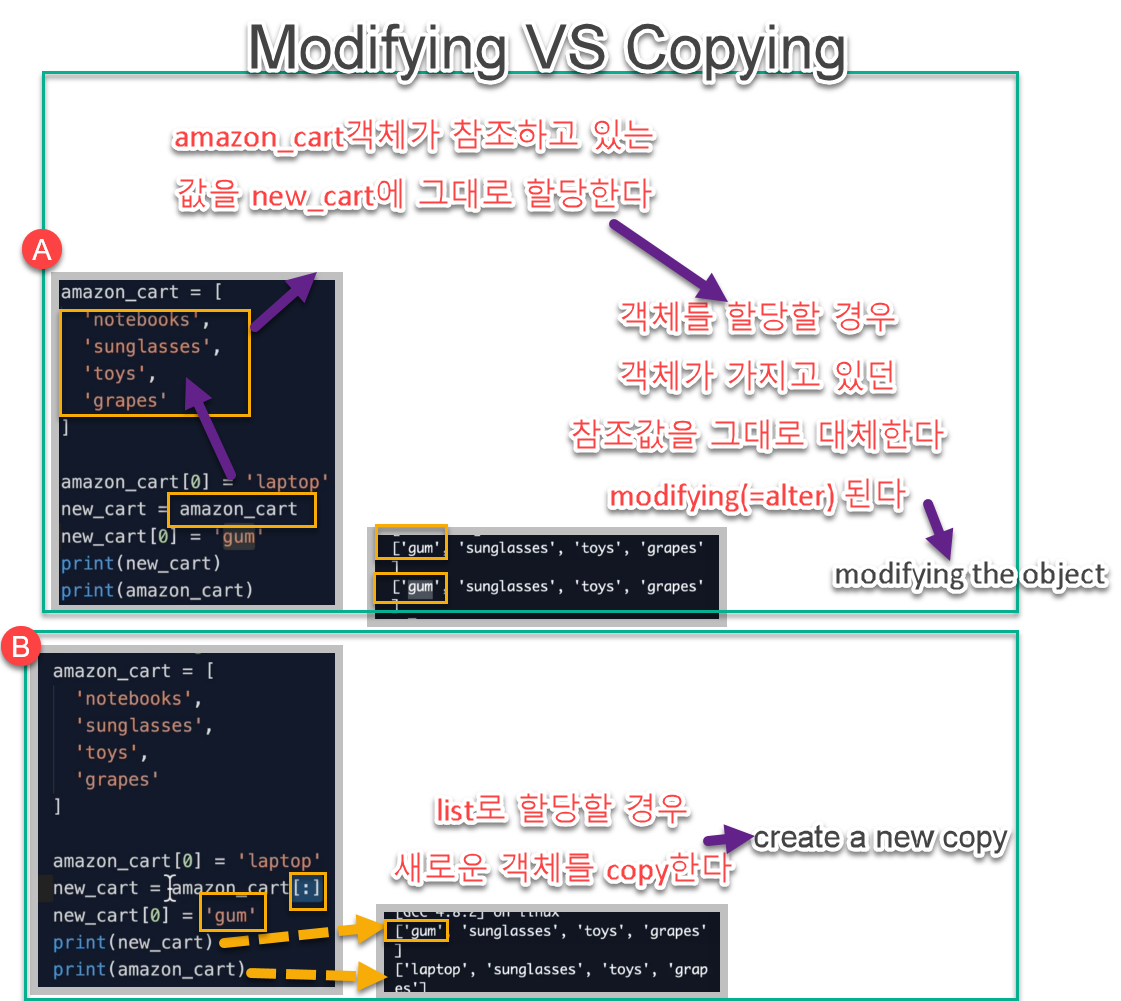
Modifying( =alternating)
Reference by value 항목 참고
new_cart = amazon_cart 라고 할당하는 것은 value를 copy하는 것이 아니라 그 object를 가리키고 있는 pointer를 copy하는 것이다. 즉, 메모리 상에서 new_cart 와 amazon_cart가 가리키는 메모리 주소가 동일해지는 것이다.
즉, 두 object가 참조하는 값이 같아 지는 것이다. 때문에 나중에 new_cart와 amazon_cart 둘 중 하나의 modify하면 결국 둘 다 modified 되는 것이다.
Copying : :
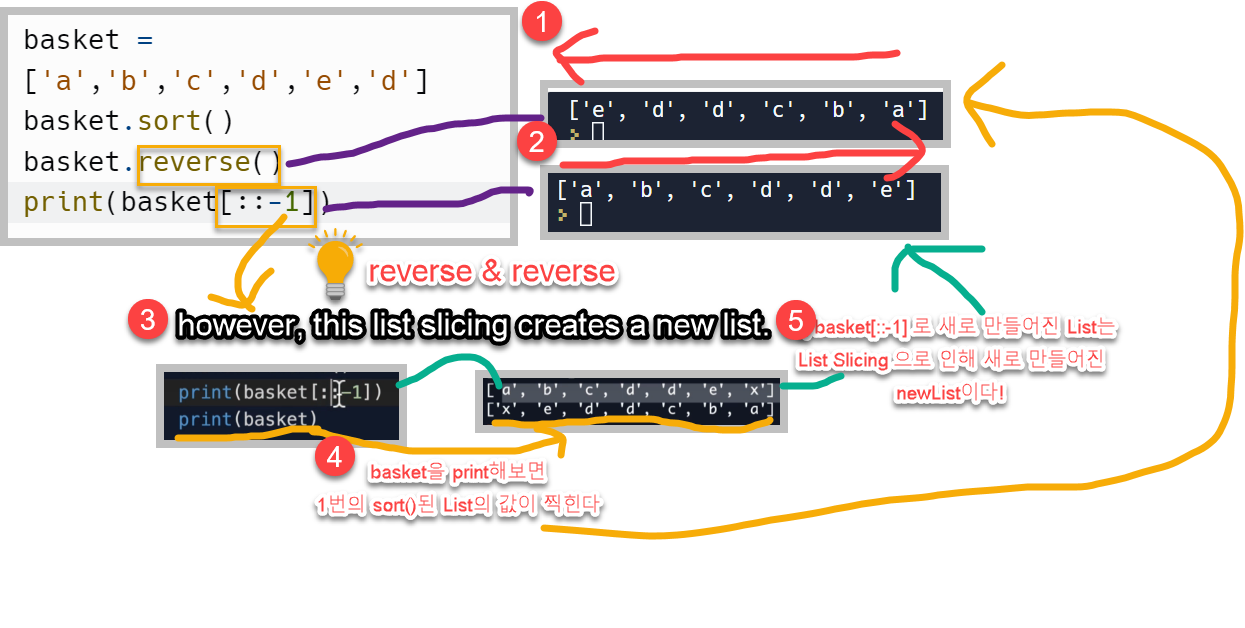
Slicing [:] 을 이용하면 원본 list를 copy한 new list 를 생성한다.
Matrix(행렬)
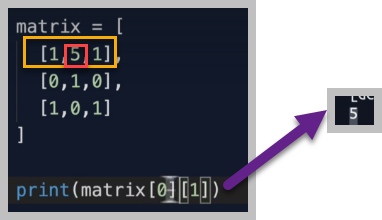
Maxtrix는 2차원 배열(twe dimensinal array) 이다. main array와 3개의 sub array들 있다. matrix라는 main array의 index[0]번인 sub array [1,5,1]의 1번 index인 5를 grap한다
List 메서드들
list: 추가하는 메서드: adding List methods( append, insert, extend)
.append() 메서드
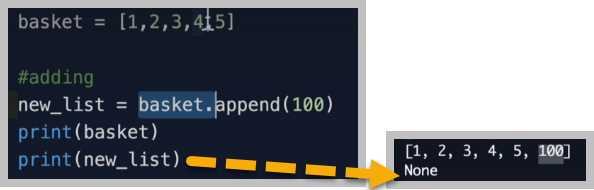
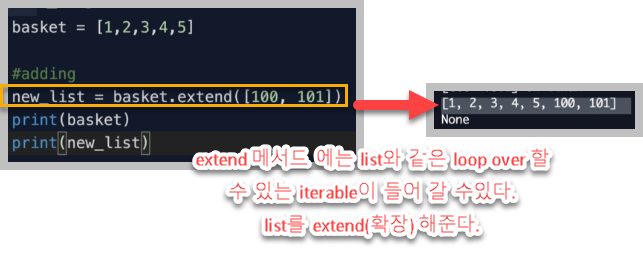
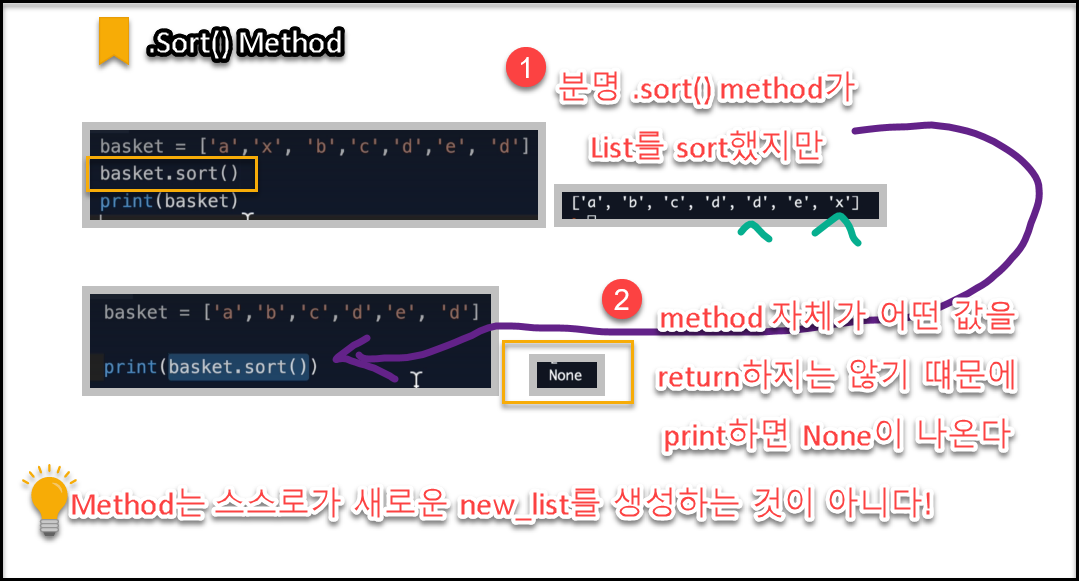
append() 메서드는 basket array에 새로운 value인 100을 추가해주는 역할을 해줄 뿐이다. basket array에 100이 추가된 [1,2,3,4,5,100] 이라는 array 그 자체를 새롭게 생성하지 않는다. 즉, 이 말을 다르게 말하면 "append() 메서드는 value를 return하지 않는다"라고 표현할 수 있다.
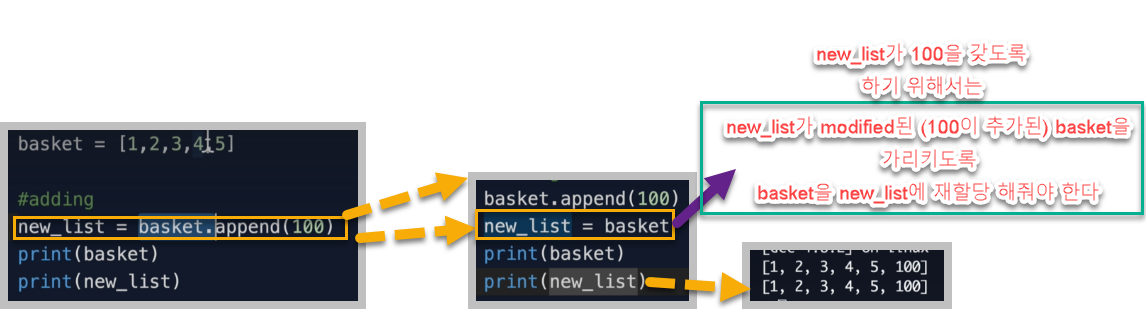
때문에 new_list가 100이 포함된 basket의 value값을 가지려면 이렇게 해줘야 한다.
new_list 에 basket을 assign 해서 100을 포함하는 modify된 basket array가 가리키는 heap의메모리주소를 참조할 수 있도록 해야한다.
.insert() 메서드

.extend() 메서드
list: 제거하는 메서드:Removing List methods ( pop, remove, clear)
.remove(value) & .pop(index) 메서드
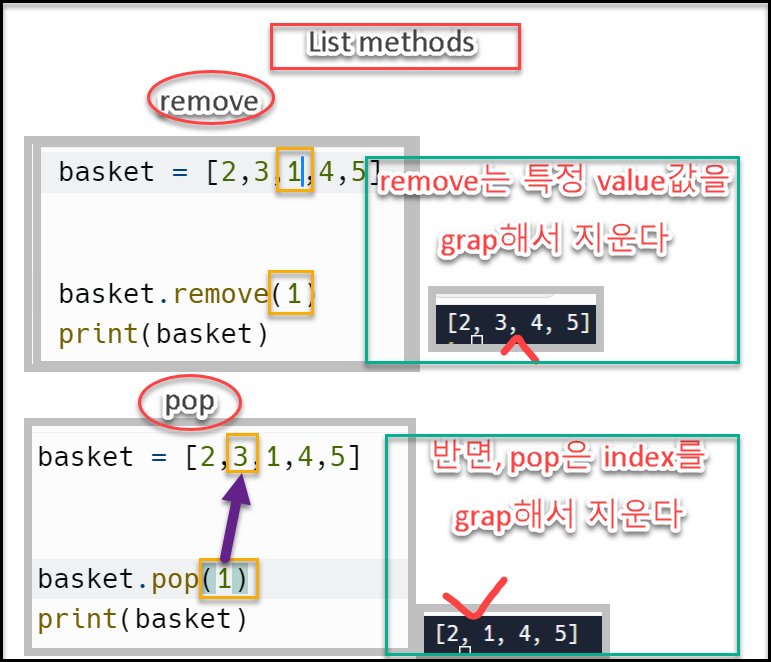
.pop메서드 vs .remove메서드
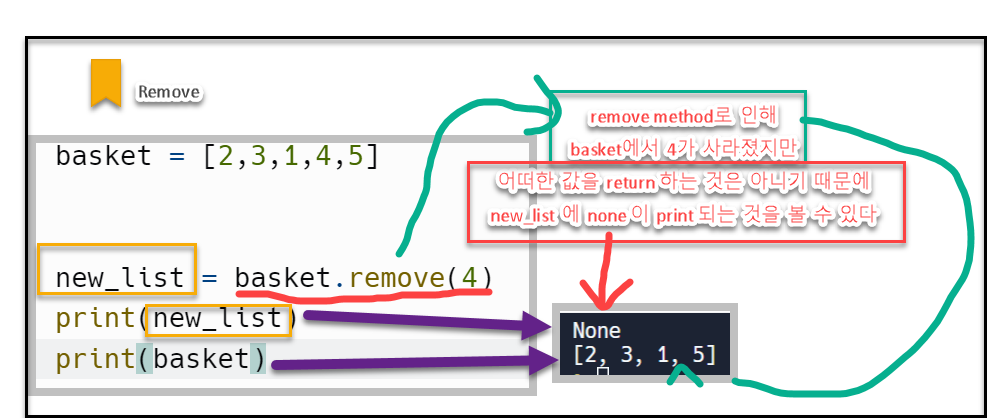
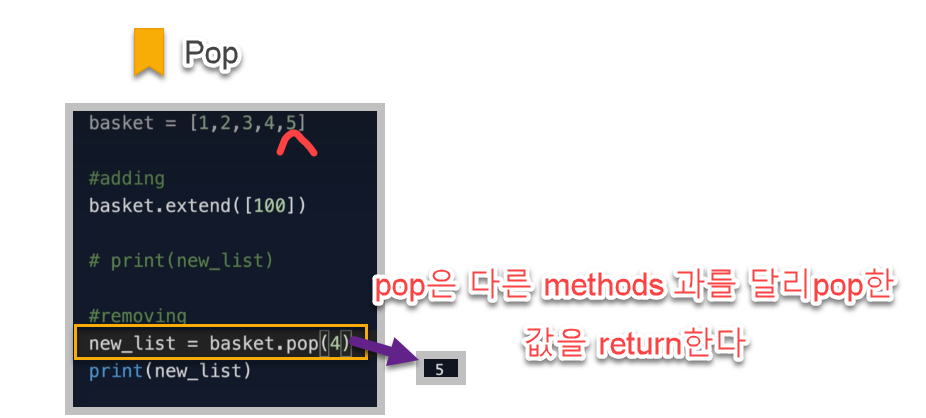
다른 list 메서드들을 value를 return 하지만 pop 메서드는 list상에서 pop된 그 value return한다
None 데이터타입
list가 return하는 value 중 None 이라는 데이터 타입이 있다. 메서드가 원본 list를 modify하는 역할은 하지만, 어떠한 value를 return 하지 않을 때, 즉 어떤 결과값도 스스로 생성하지 않을 때 None이라고 표시한다. 이는 다른 언어에서 value가 부재(absence) 함을 나타내는 데이터타입인 Null과 같은 의미이다.
list:다른 여러 메서드들
.clear() 메서드
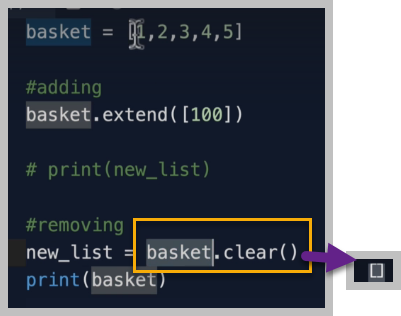
clear메서드는 list 안의 모든 item들을 remove한다.
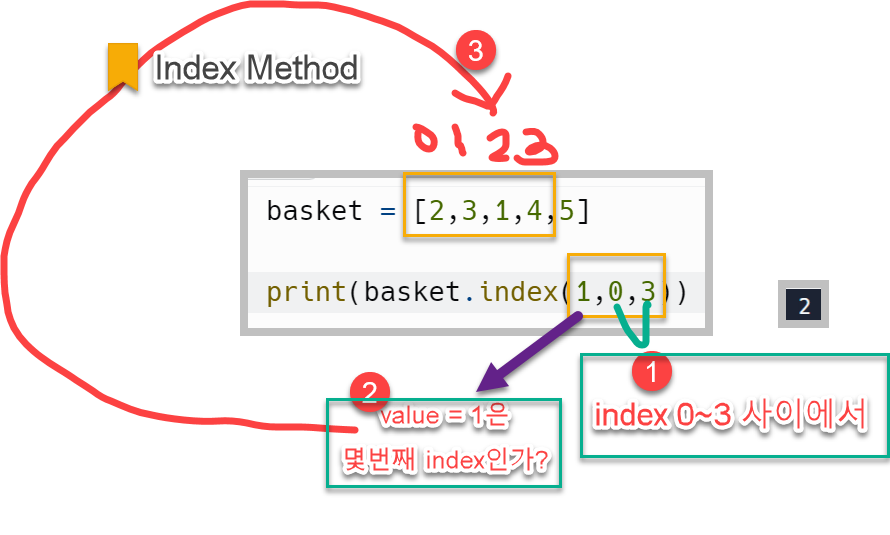
.index() 메서드
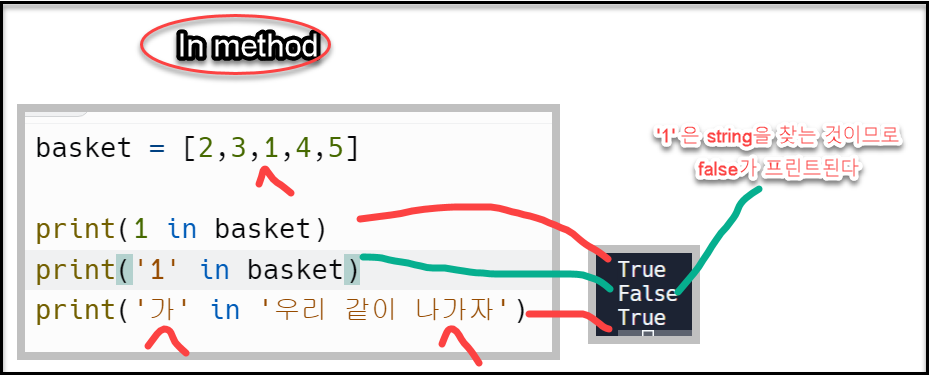
.In() 메서드
.count() 메서드
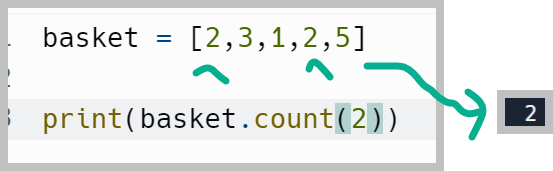
list 내에 특정 value의 duplication이 몇번 counting 되는지
list: 분류하는 메서드
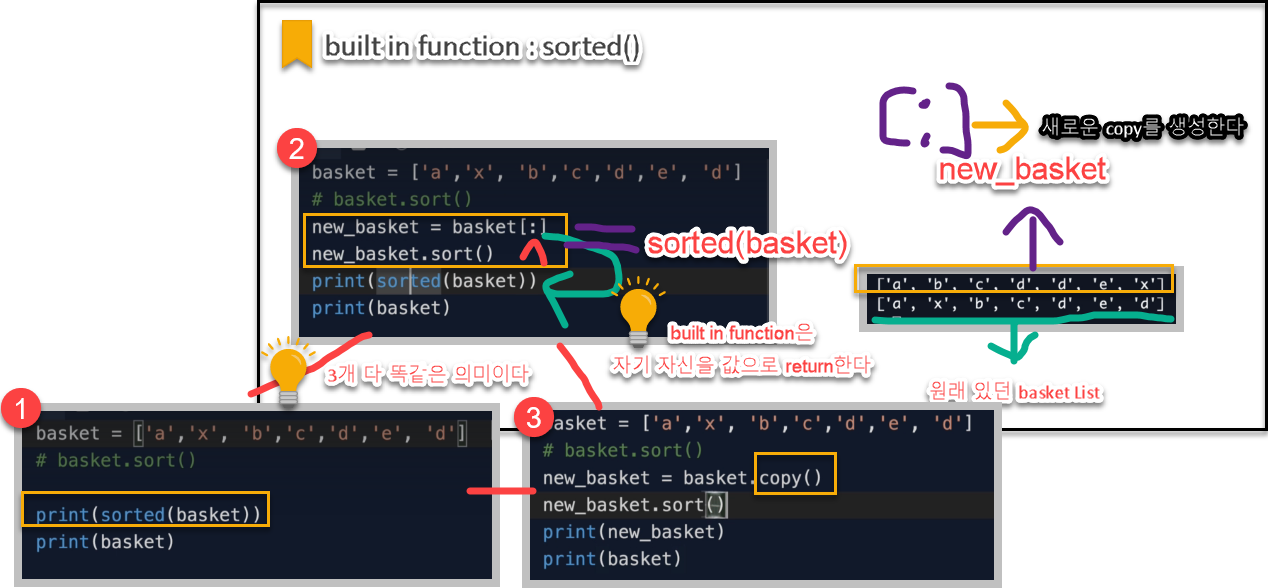
.sort() 메서드 vs sorted(내장함수) 차이
.Sort() 메서드
sorted() 내장함수
.reverse() 메서드

range() 내장함수
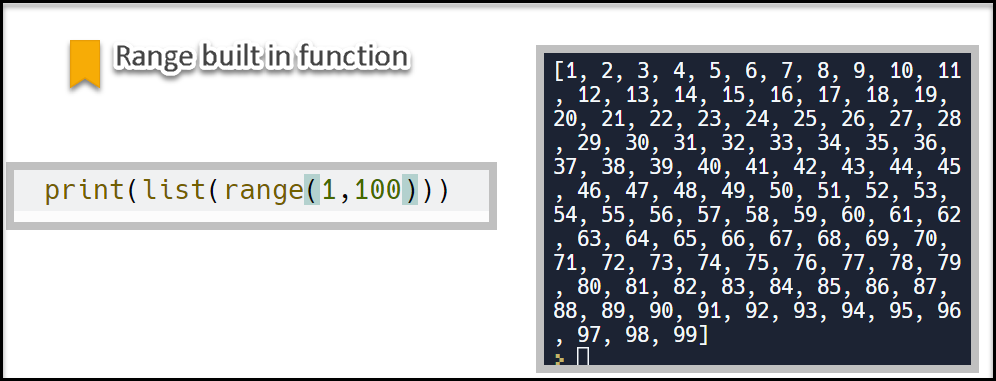
1부터 99까지의 숫자를 list로 generate 하고 싶다면 range() 내장 함수로 생성할 수 있다.
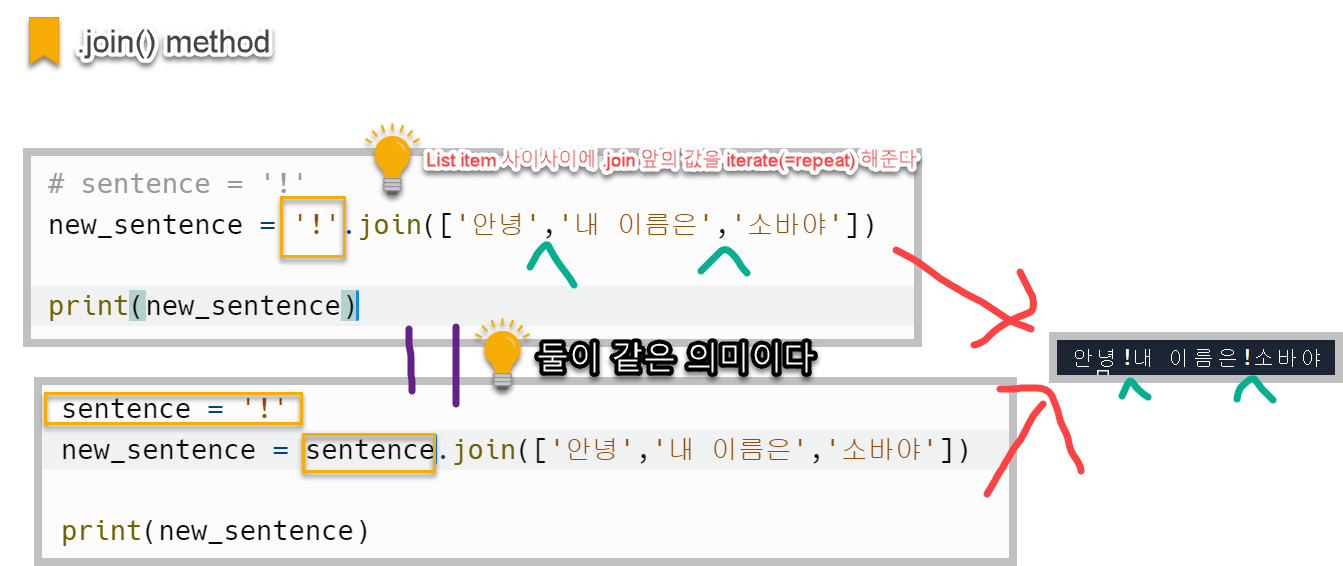
.join() 메서드
내장함수(bulit in function)와 메서드(method) 의 차이점
둘다 액션을 수행하는 것은 동일하다. 하지만 하차이점이 두 가지 있다.
첫 번째로 내장함수는 독립적으로 쓰일 수 있다. 반면, 메서드는 ' 자료구조.method() '의 형태 처럼 자신을 가지고 있는 주체자인 owner가 있다. 즉, 항상 어떤 것에 속해있다.
두 번째로 내장함수는 독립적이므로 스스로의 value를 return한다. 메서드의 경우 pop() 같은 예외를 제외하고는 값을 스스로 return 하지 않는다. 때문에 method의 경우 값을 사용해야할 경우 재할당 해줘야한다.
List: 언패킹(unpacking)

list 안에 있는 item들을 각각의 변수들에 꺼내서(unpacking) 담아준다(assign). 원본 list를 modify 하지 않고 새로운 변수에 assign 해주는 메서드이다.
자료구조: 딕셔너리(Dictionary)

다른 언어에서 table, map, object 등 다양한 이름으로 불린다. 파이썬에서는 dict. 라고 한다.
Dict. {} 를 이용해서 선언한다.
curly bracket는 이 자료구조가 dictionary라는 것을 나타내며 list와는 다르게 그 안에는 key : value pair가 있다. key와 value 가 짝꿍처럼 한쌍으로 있다는 의미이다.
key는 string의 형식으로 짝꿍인 value를 grab하기 위해 존재한다.
print(my_list['a']) 라고 썼을 때 컴퓨터에게 my_list 라는 이름의 list 안에 있는 key가 a인 value를 grap 해오라고 명령하는 것이다. 그러면 메모리에서 a가 저장된 위치를 찾고 key a의 value인 [1,2,3]을 grap 해올 것이다.
Dict는 list와는 다르게 unordered한 key:value pair이다. 각각의 key들이 컴퓨터 메모리 상에서 서로 옆에 있지 않는다는 것이다. 이것이 중요한 이유는 순서(ordered)가 있는 list에서는 index번호로 grap할 수 있지만, dict안의 data들은 순서대로 저장된 것이 아니기 때문에 index라는 개념이 없다.
my_list의 index[1] 번 dict. 의 a와 b가 메모리상에서 각각 다른 spot에 흩어져 저장 되어있다는 것이다.
즉, dict.를 나타내는 {}안에서는 무조건 index가 아니라 key를 이용해서 value를 grap해야한다.
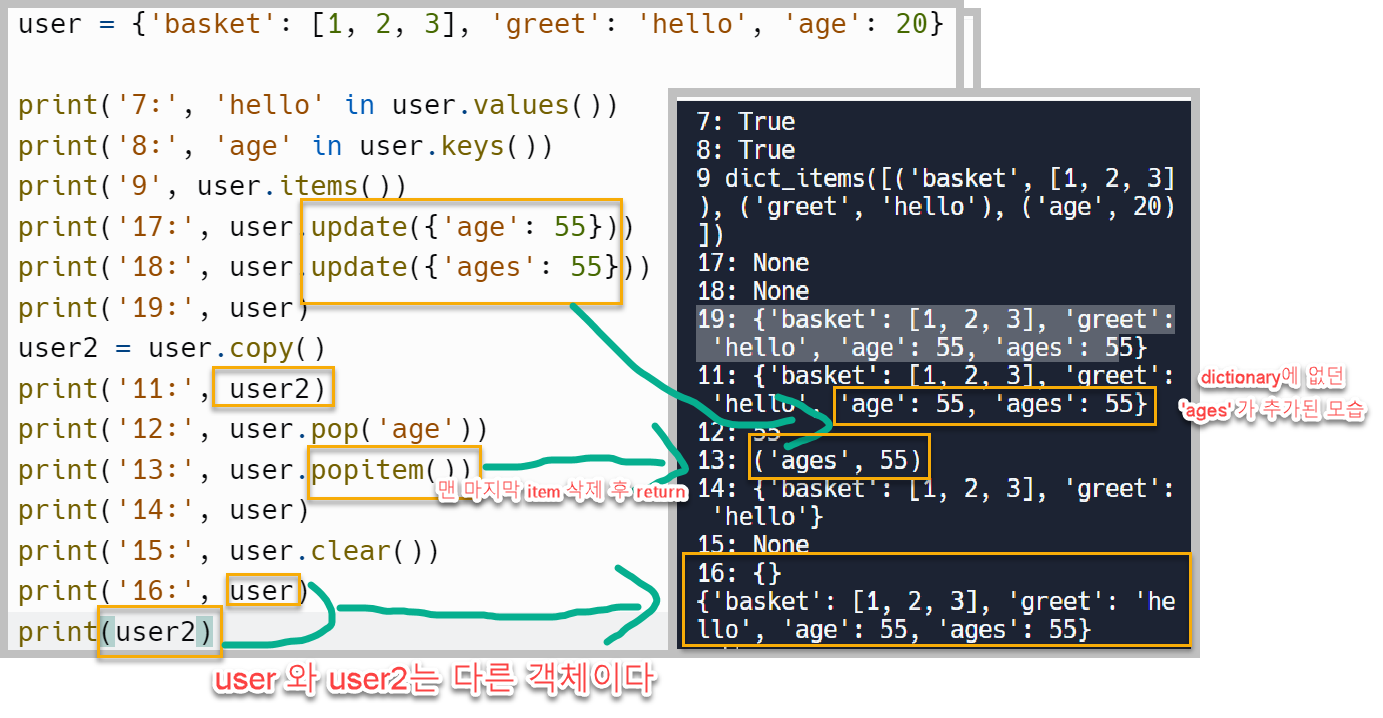
Dictionary 메서드
https://www.w3schools.com/python/python_ref_dictionary.asp
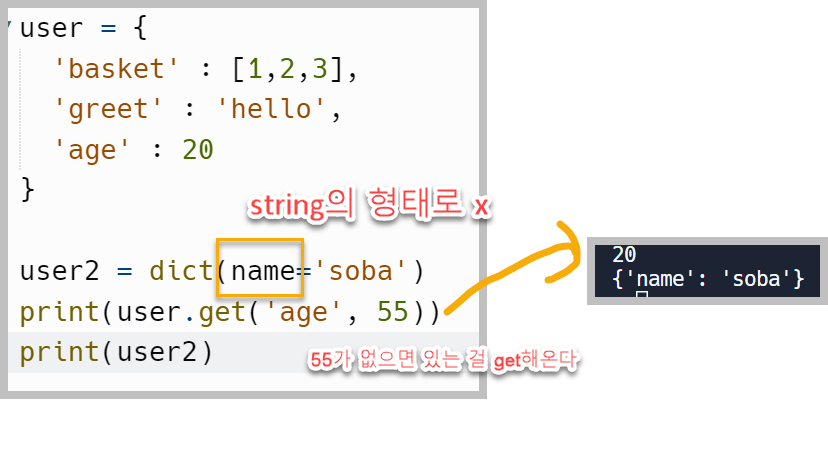
.get() 메서드
다른 여러 메서드들
자료구조: Tuple
Tuple은 list와 비슷하지만 modify 할 수 없다는 특징이 있다. Immutable한 list라고 생각하면 된다. 하지만 list와는 다르게 Tuple은 일단 생성하면 sort하거나 reverse 할 수 없다.
Why do we need this? (= predictable, safe)
Tuple을 언제쓰냐하면 list 안에 있는 item들이 추후에 변경할 필요는 것들이라면 list보다 tuple을 사용하는 것이 좋다. 왜냐하면 다른 개발자가 코드를 볼 때 modify 하지 말아야할 코드라는 것을 직관적으로 알 수 있기 때문이다. 예를 들면, 우버라는 기업에서는 특정 장소의 지리적인 위도와 경도 같은 정보를 저장할 때 변경될 일이 없으니 tuple을 사용한다.
그리고 Tuple은 list를 사용하는 것보다 성능면에서 빠르다는 장점이있다.

Dict. 내부의 item들은 모두 immutable한 tuble이다. 실제로 key와 value쌍을 tuple로 반환하는 것을 볼 수 있다.
tuple slicing

tuple methods
https://www.w3schools.com/python/python_ref_tuple.asp

자료구조: Set

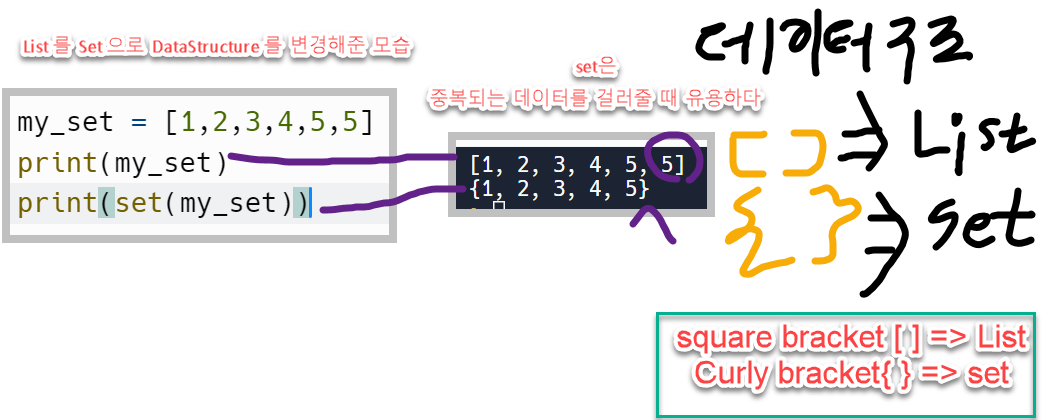
set 자료구조는 dict. 와 마찬가지로 unordered 하고 {} 로 선언하지만 key:value 쌍이 없다. 또한 내부의 모든 key들은 unique하게 존재하며 duplicate를 허용하지 않는다.
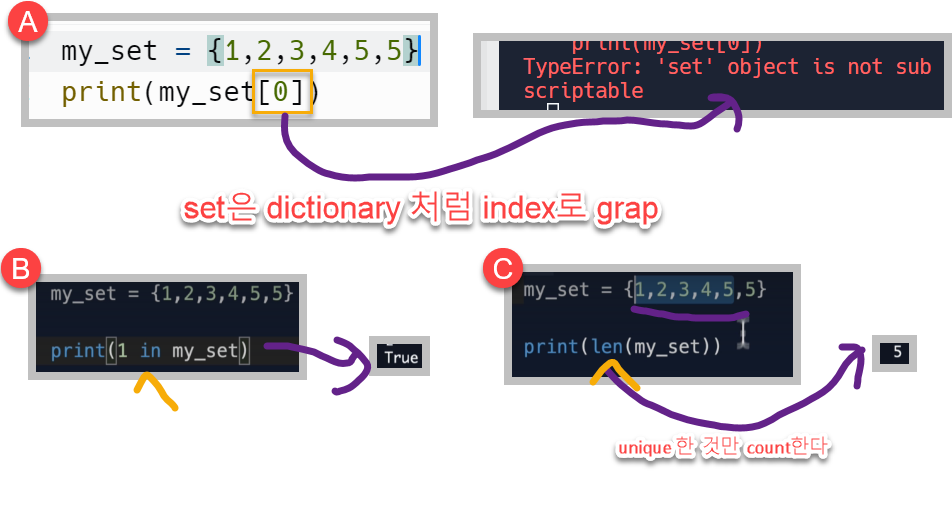
set은 dict. 처럼 unordered하기 때문에 index로 grap할 수 없다. dict과 마찬가지로 key 값으로 grap을해야한다.
또한 len() 메서드를 사용하여 컬렉션 내의 개수를 파악할 때에도, set자체가 duplicate를 허용하지 않기 때문에 length에도 unique한 것만 count된다.