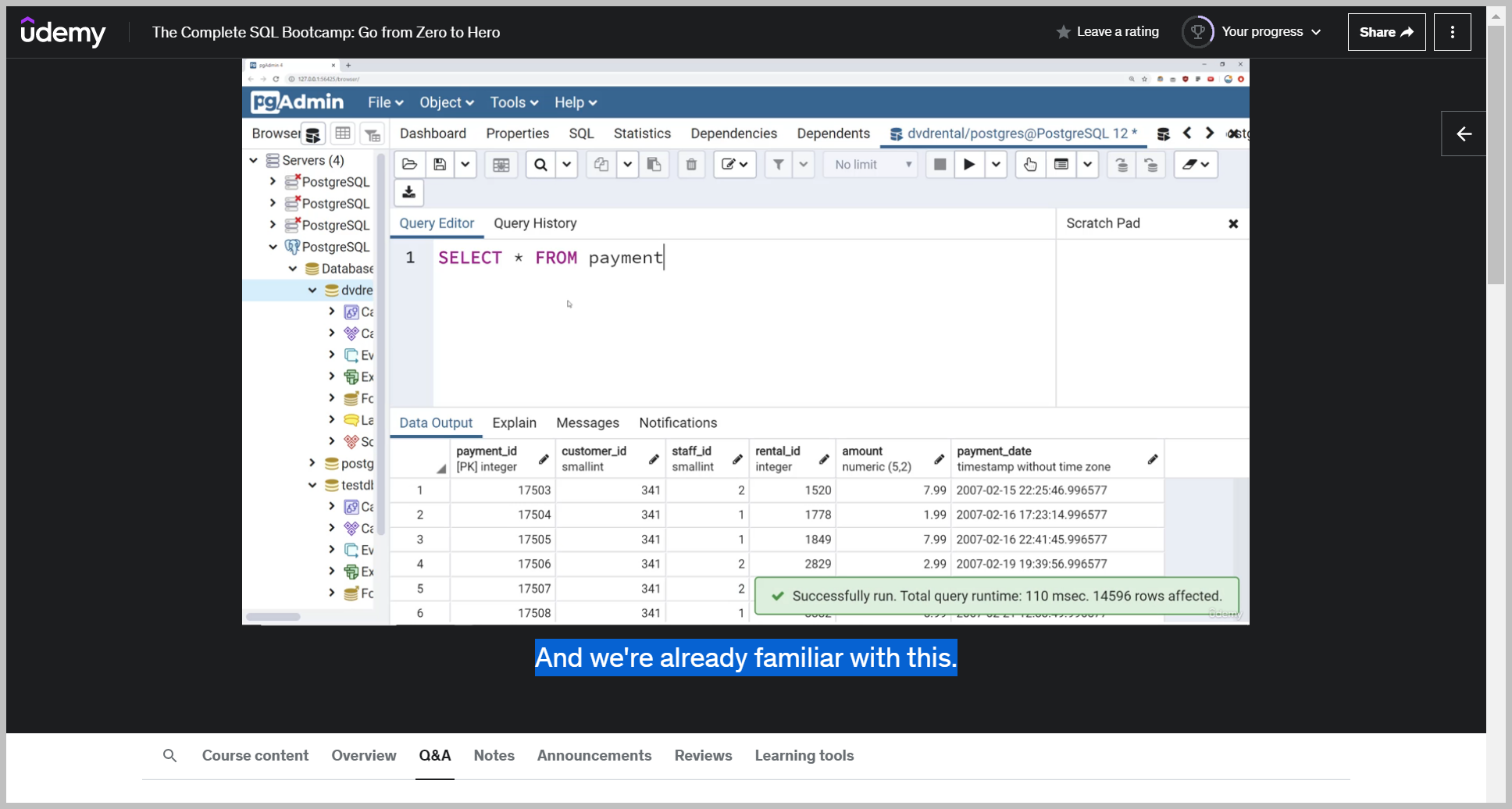
SQL 연습
DISTINCT 키워드
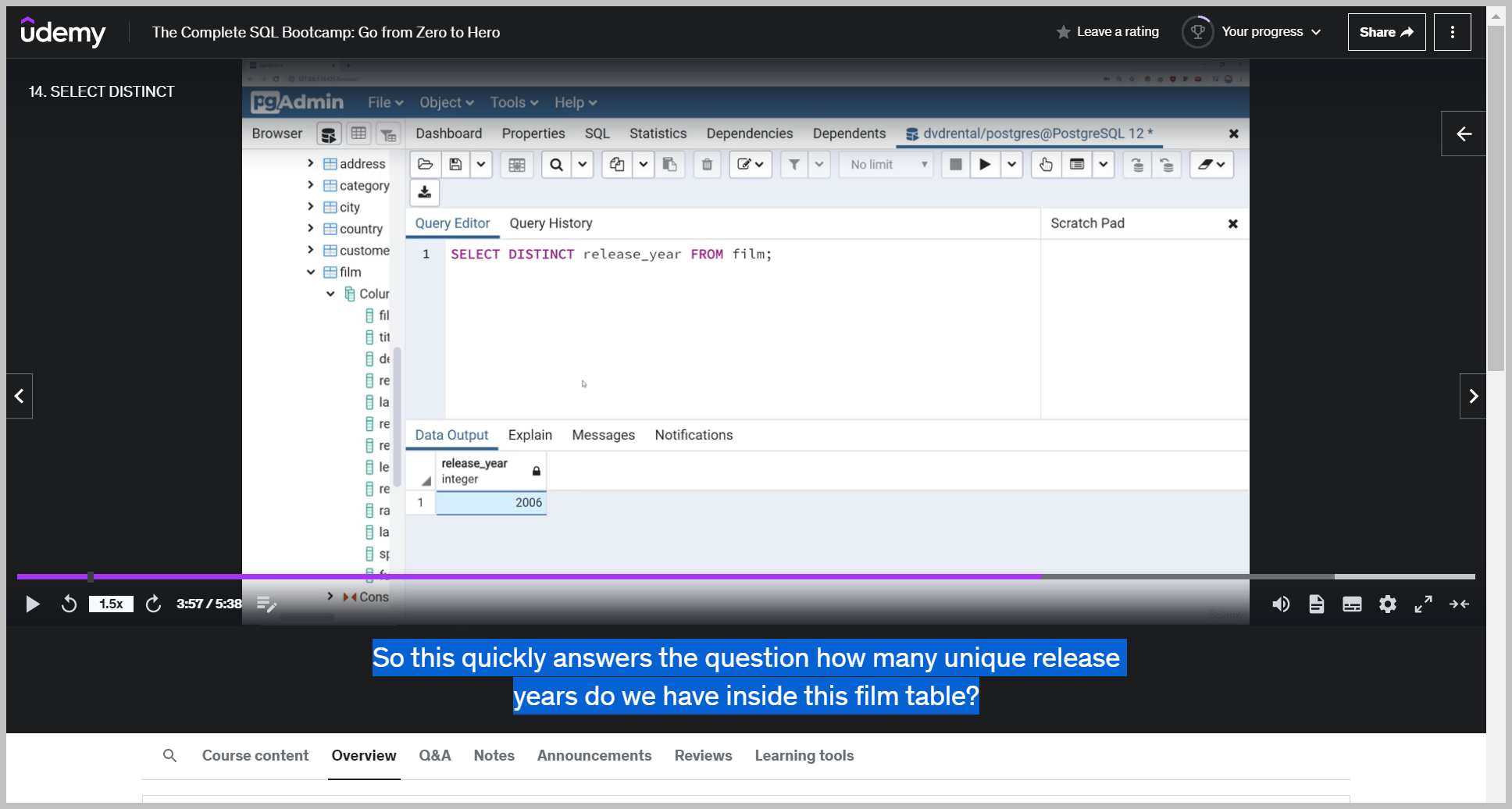
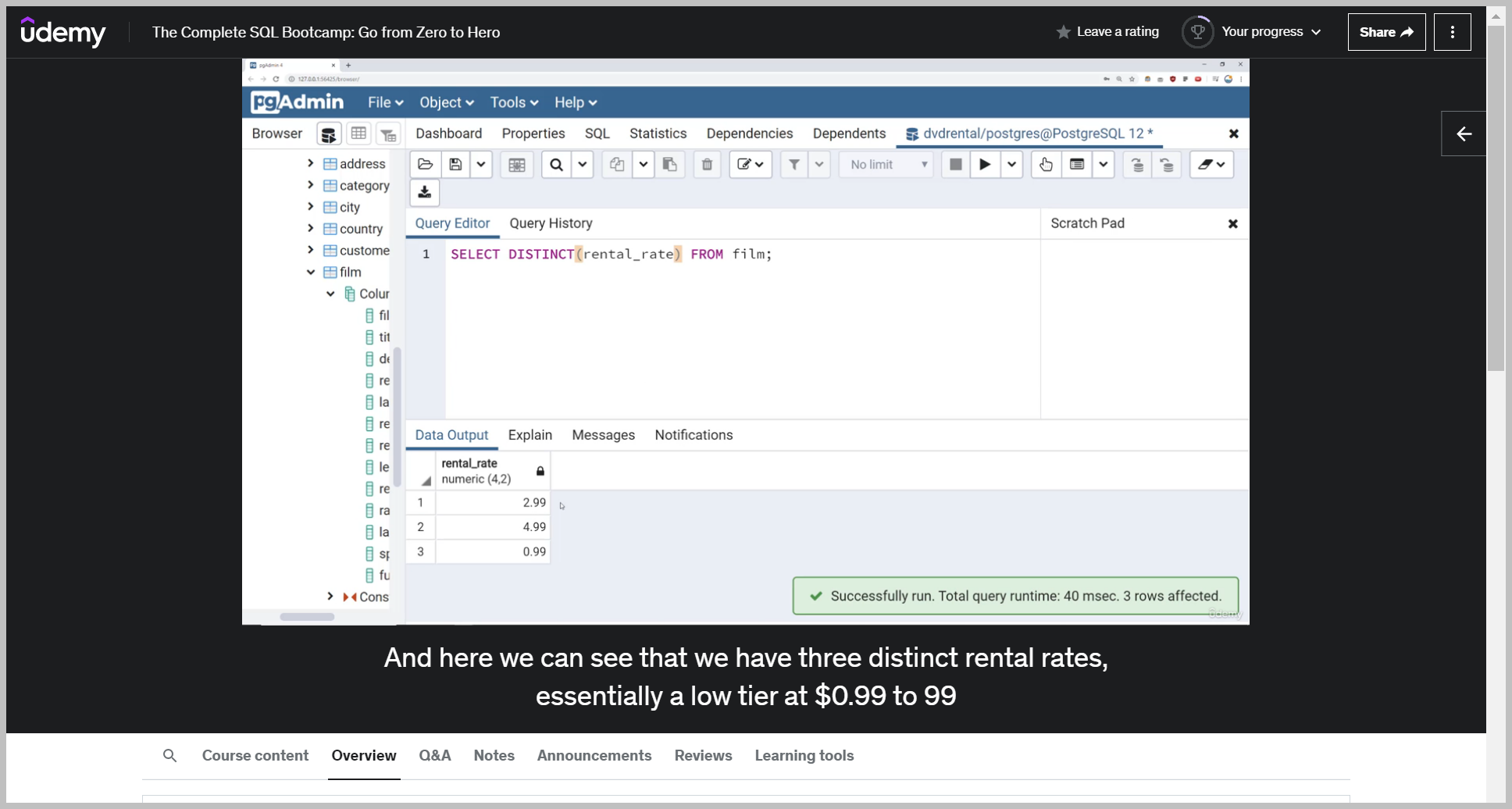
Distinct really helps when we want to know the unique values inside of a column.
So this quickly answers the question how many unique release years do we have inside this film table?
COUNT 함수
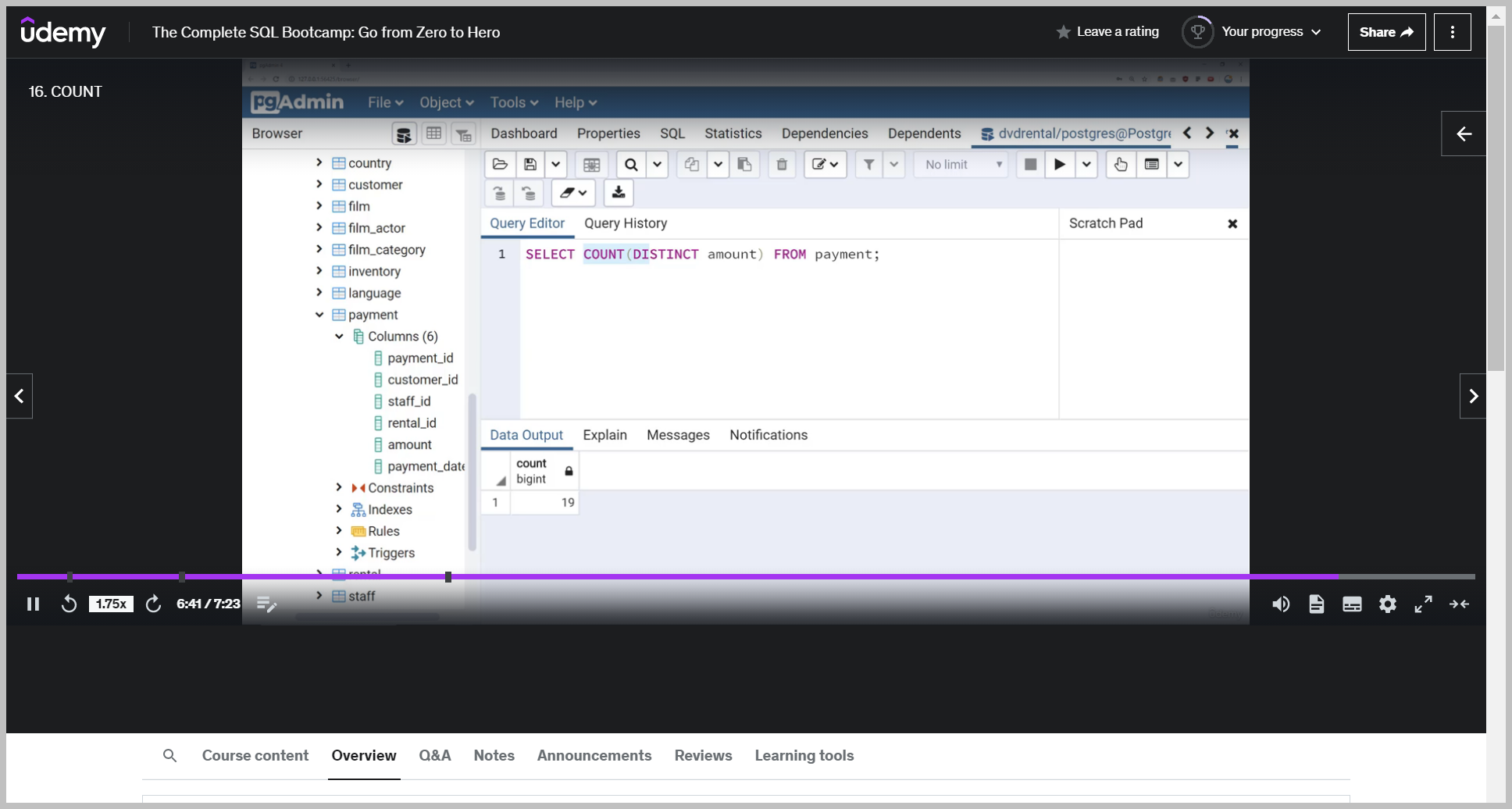
Notice here Count does need the parentheses because it's a function acting on something so it won't work with ().
So again, it's simply returning the number of rows in the table.
count is usually much more useful when combined with other commands, such as the distinct command.
Imagine we wanted to know how many unique names are there in the table.
WHERE 구문(condition)
where 구문 다음에는 불리언 판단이 가능한 값이 들어가야한다
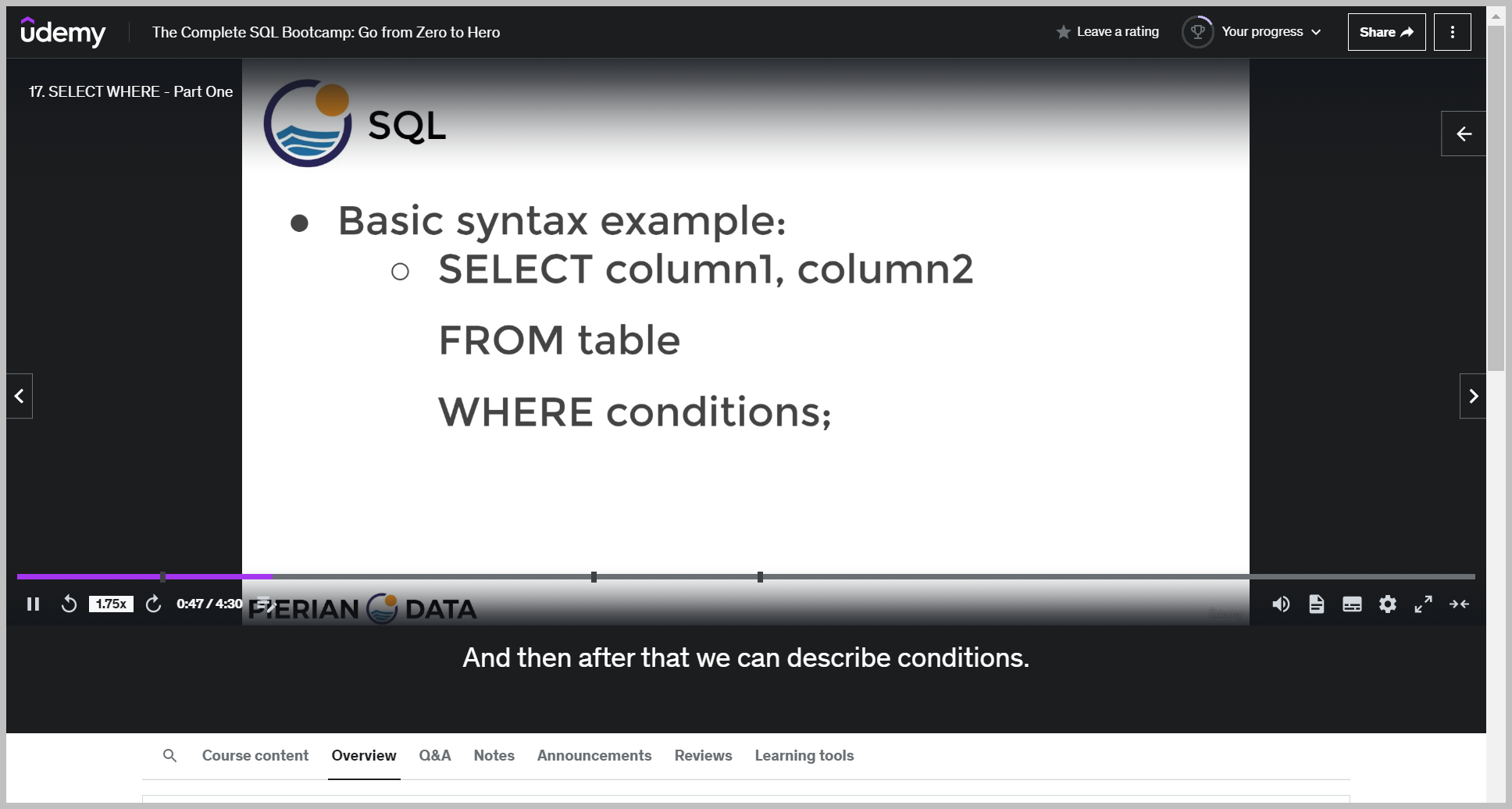
table 에서 조건을 specify 해준다
비교 연산자
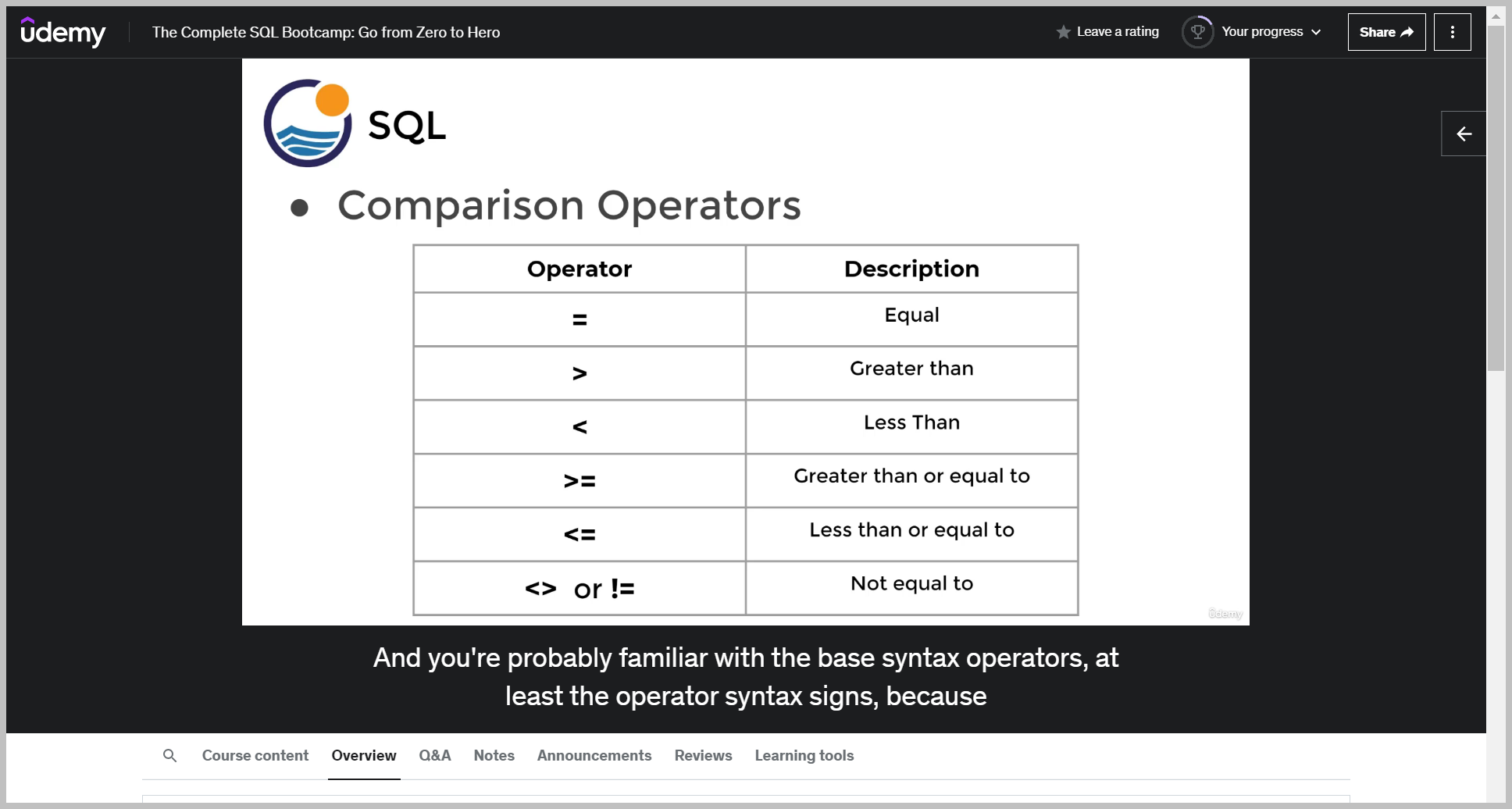
논리 연산자
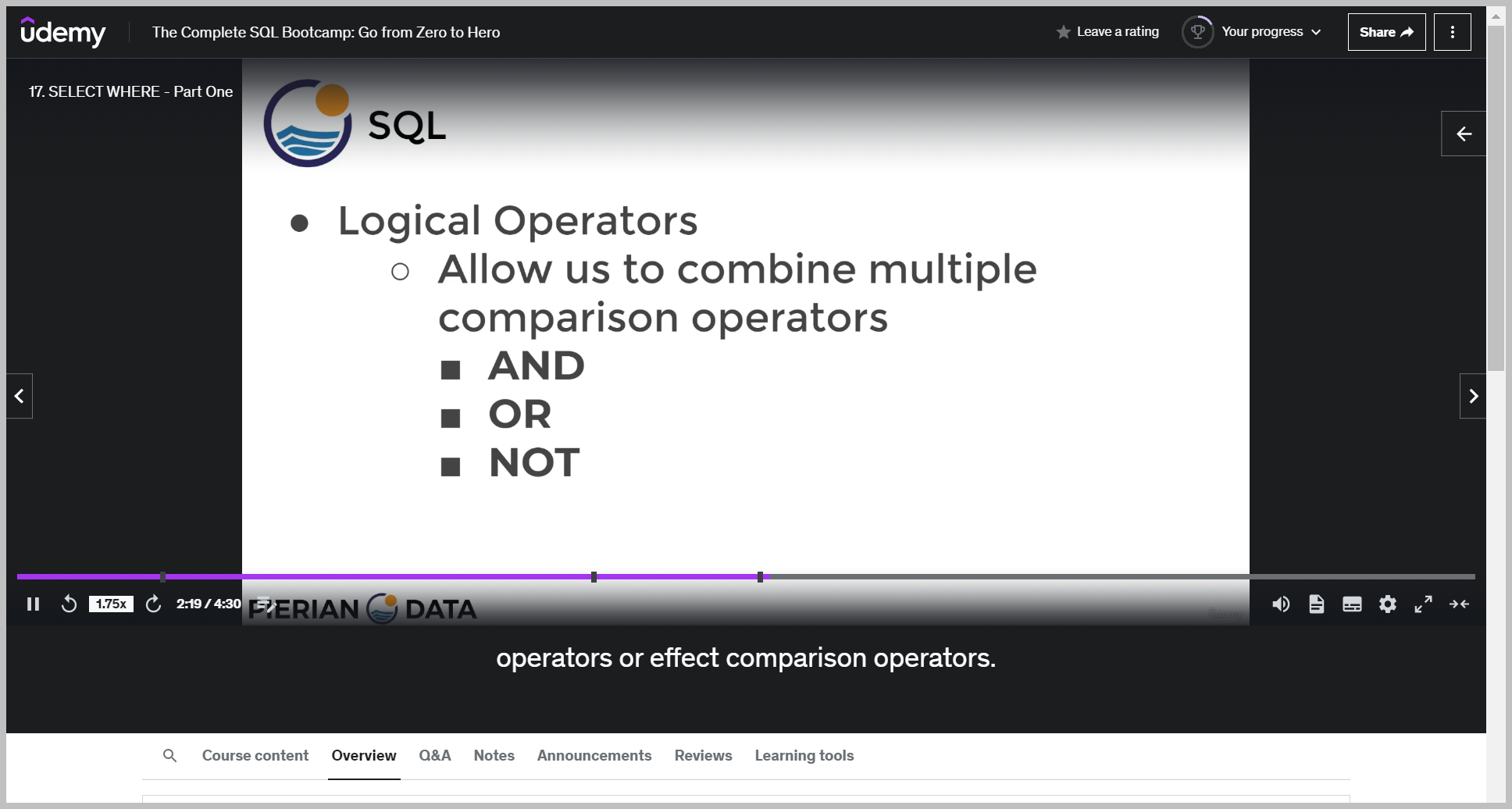
예제
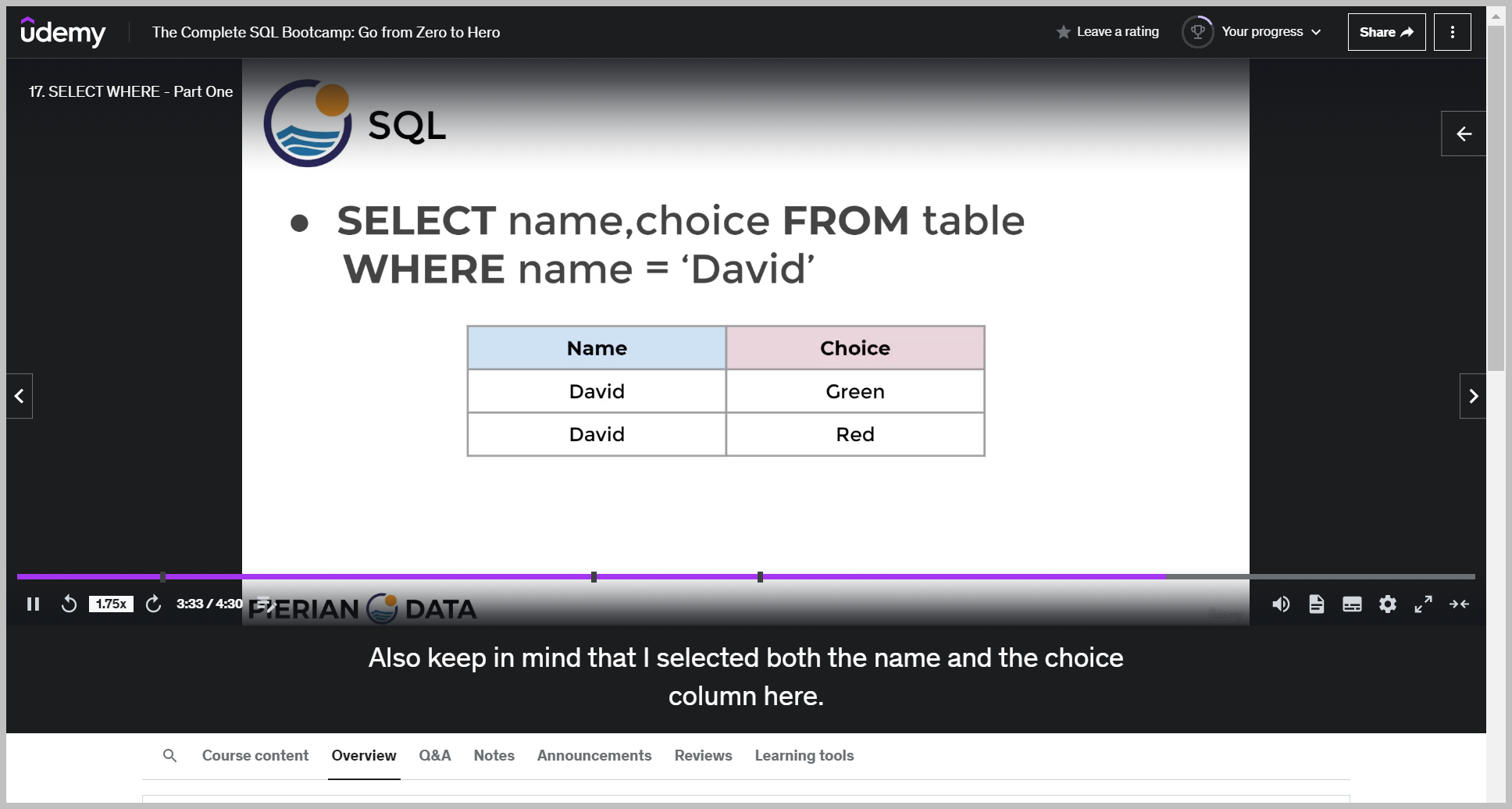
예제2

So we're going to focus much more on trying to have you build the skills of translating a business question or business related task to an actual SQL query.
Test
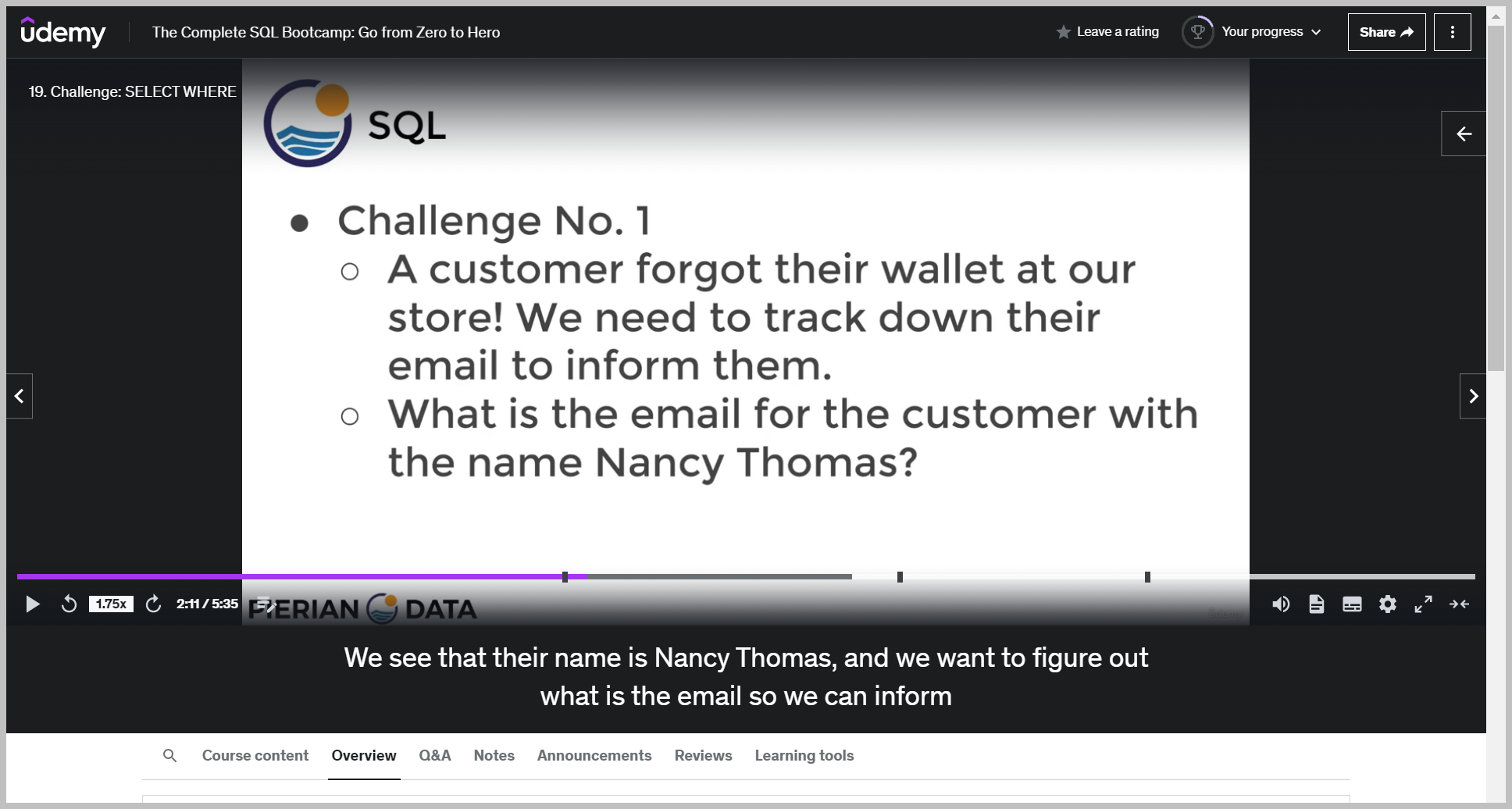
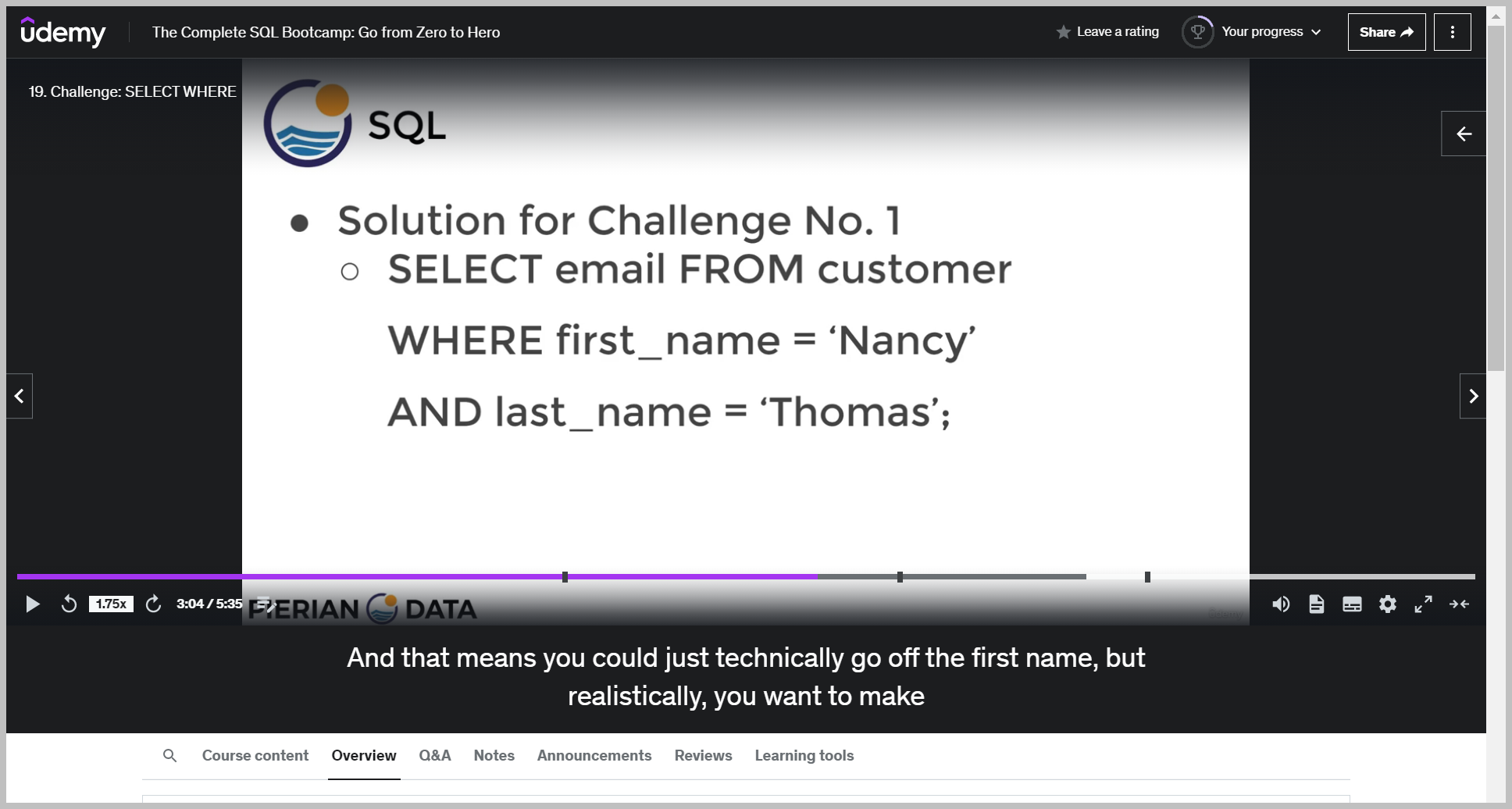
ORDER BY 구문
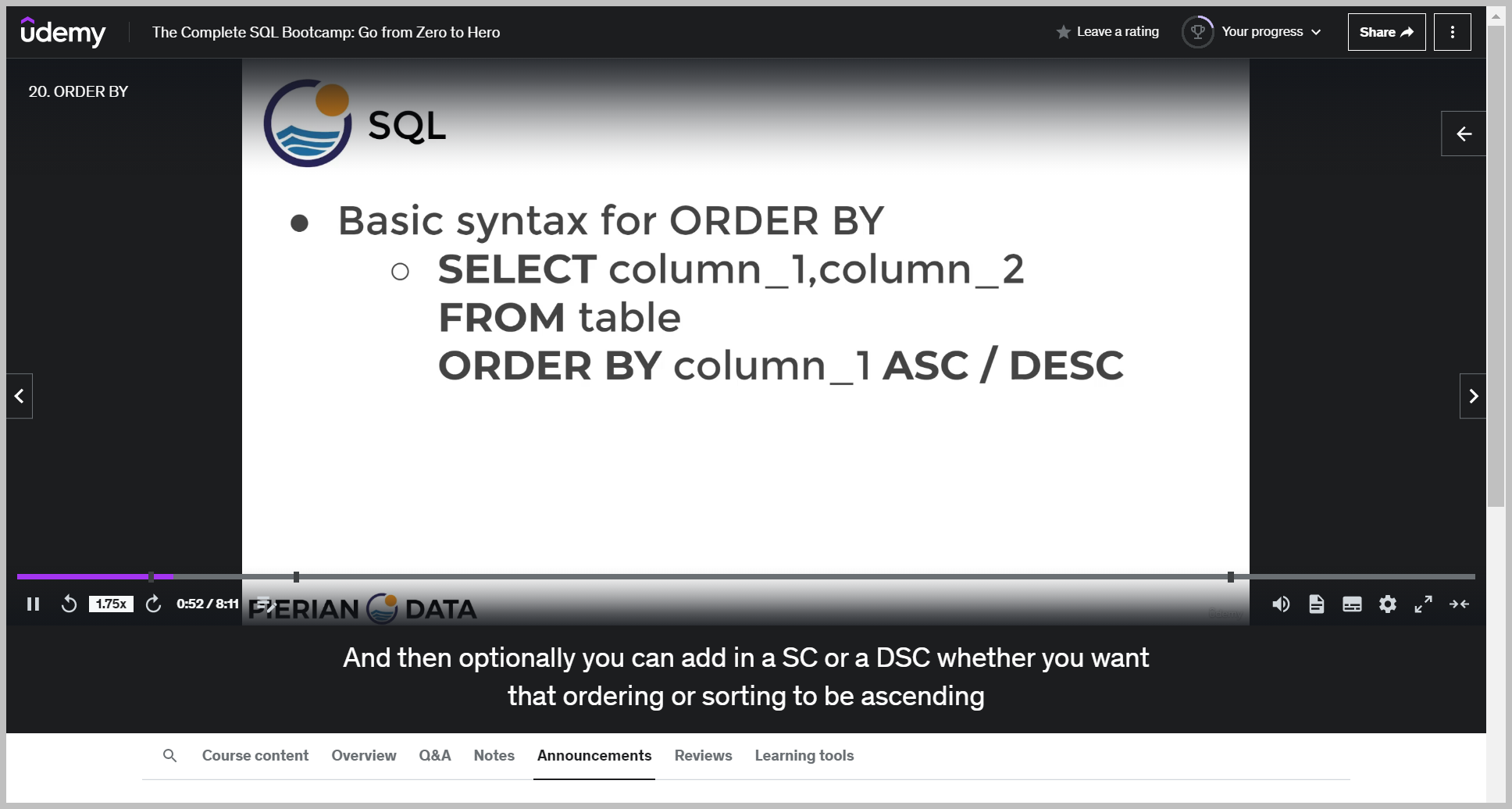
기본 문법
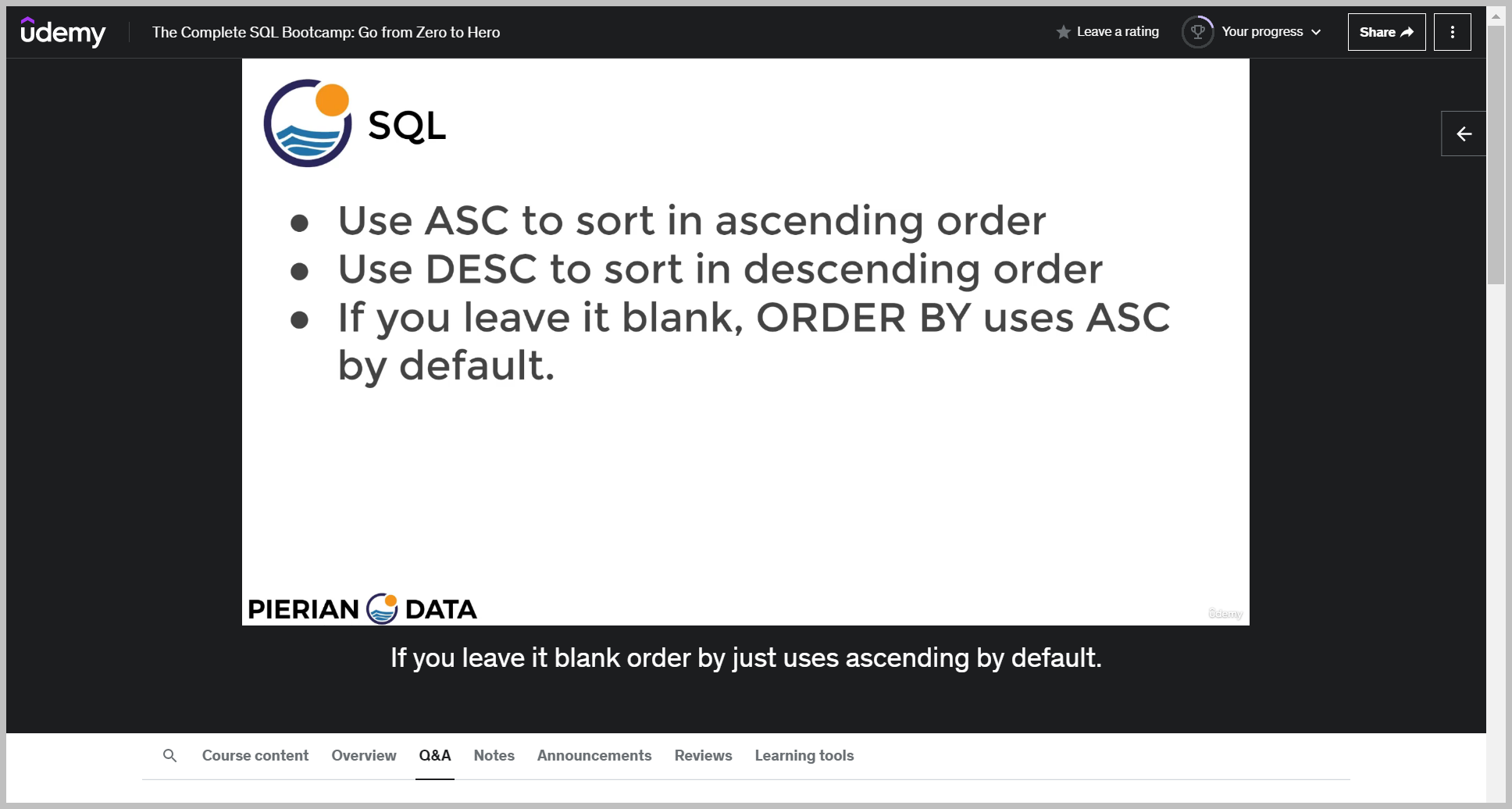
예제
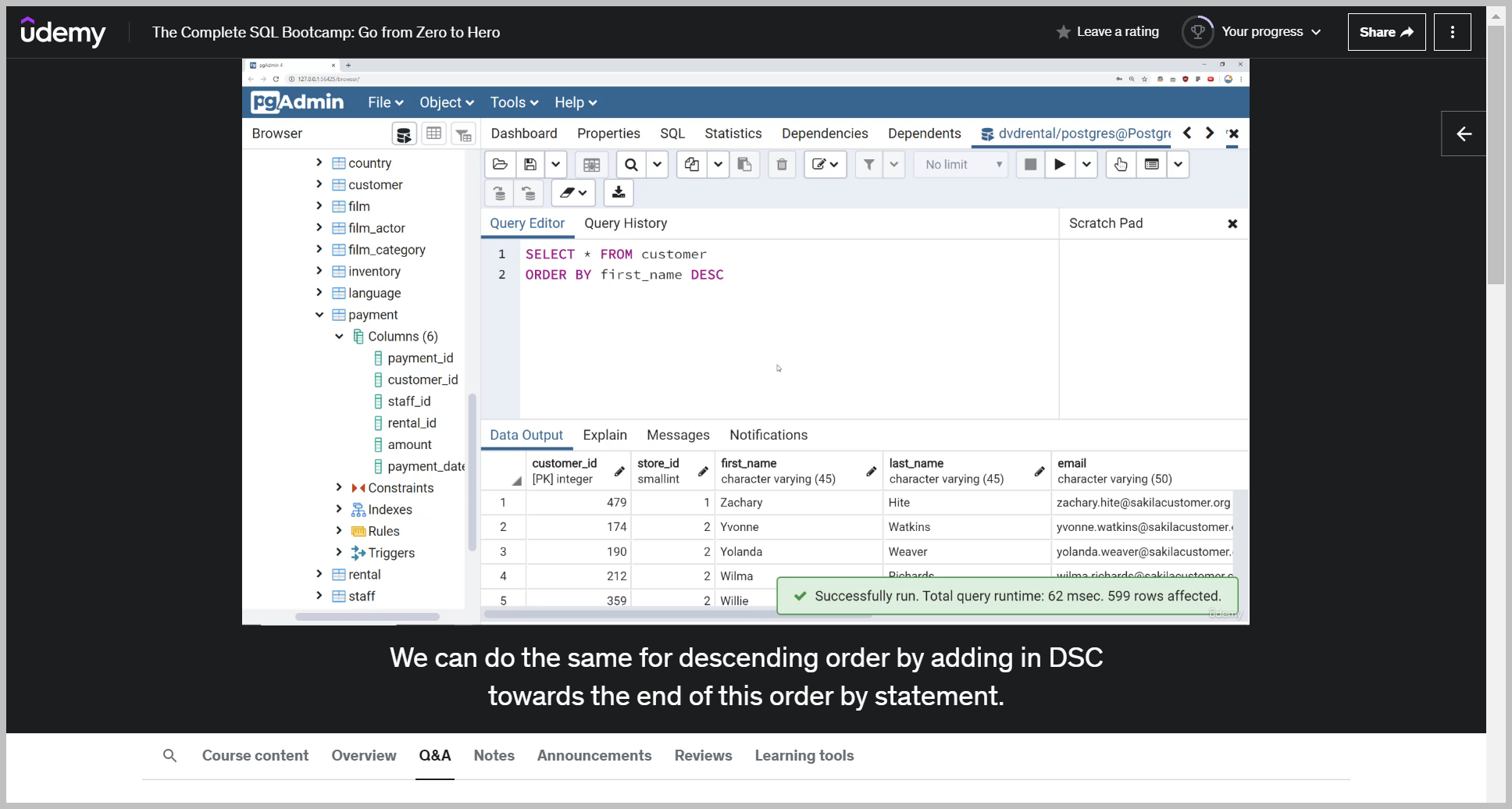
예제2
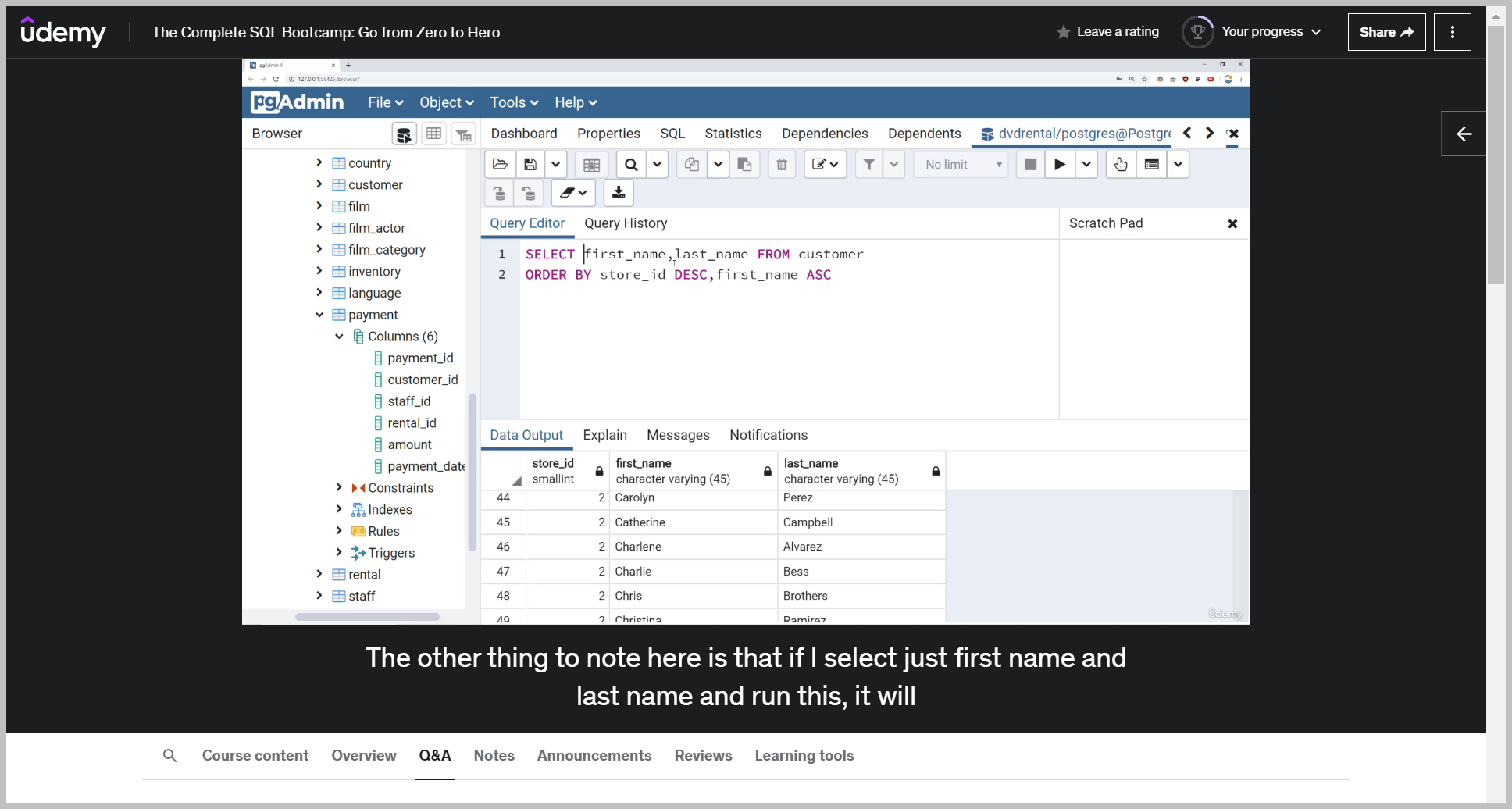
The other thing to note here is that if I select just first name and last name and run this, it will still work.
Which means I can technically sort by columns that I do not actually request in my select statement.
LIMIT 함수
예제
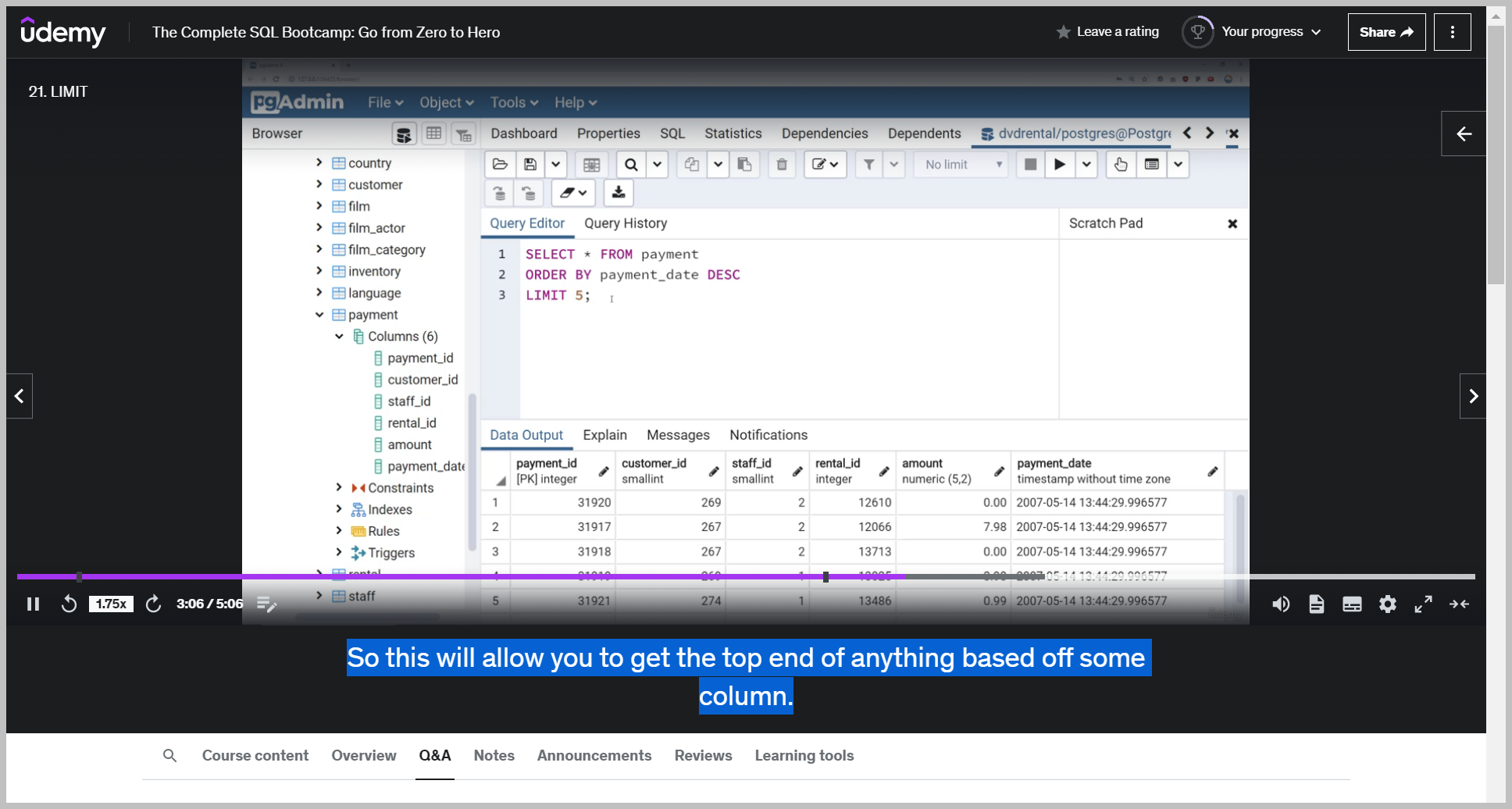
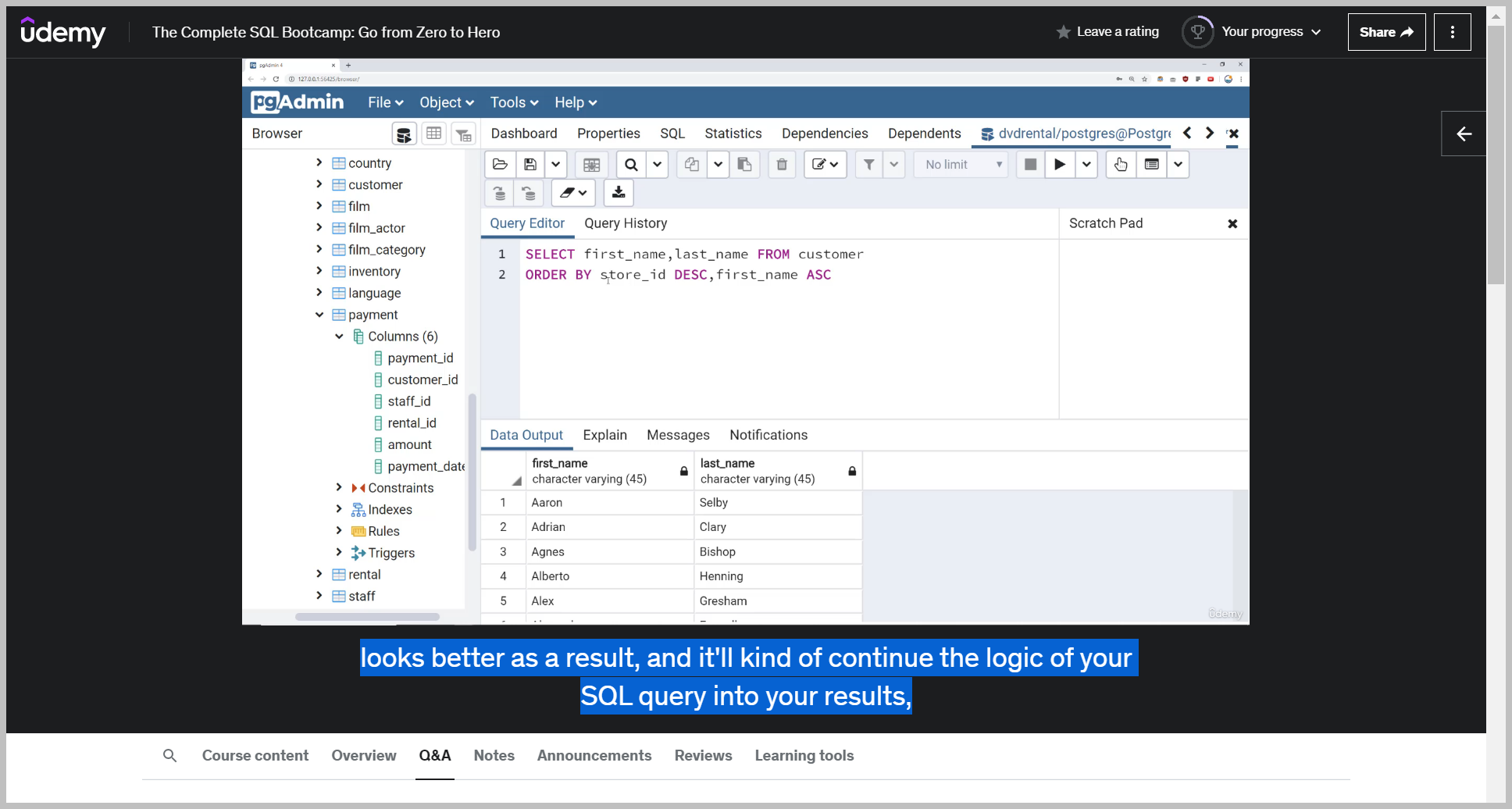
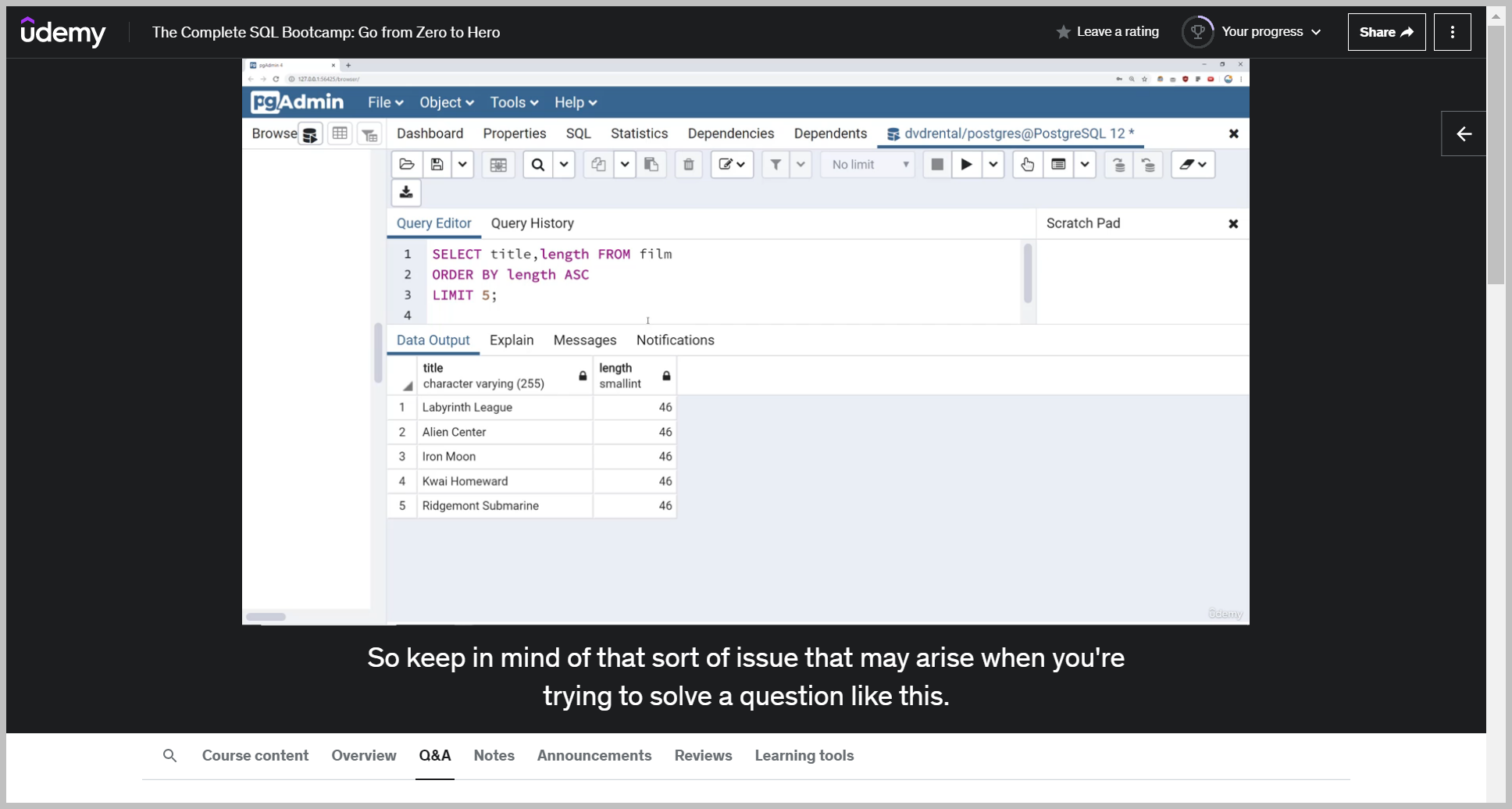
So I can say select everything from the payment table saying select all the columns from this payment table.
And then right here we're limiting it to the top five most recent ones based off payment date in descending order.
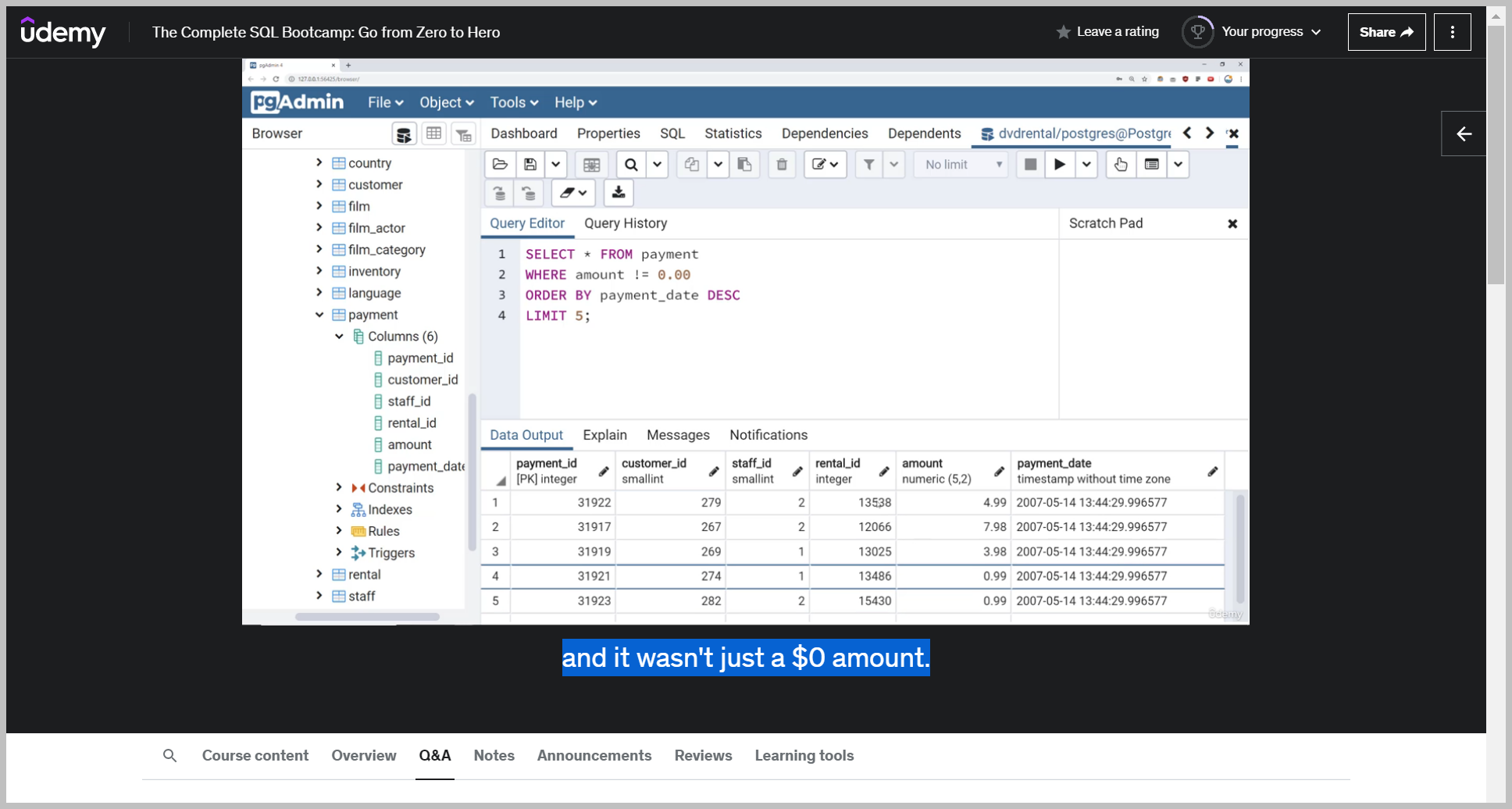
So we run this and now I can see the five most recent payments where there was actually a monetary transaction and it wasn't just a $0 amount.
퀴즈
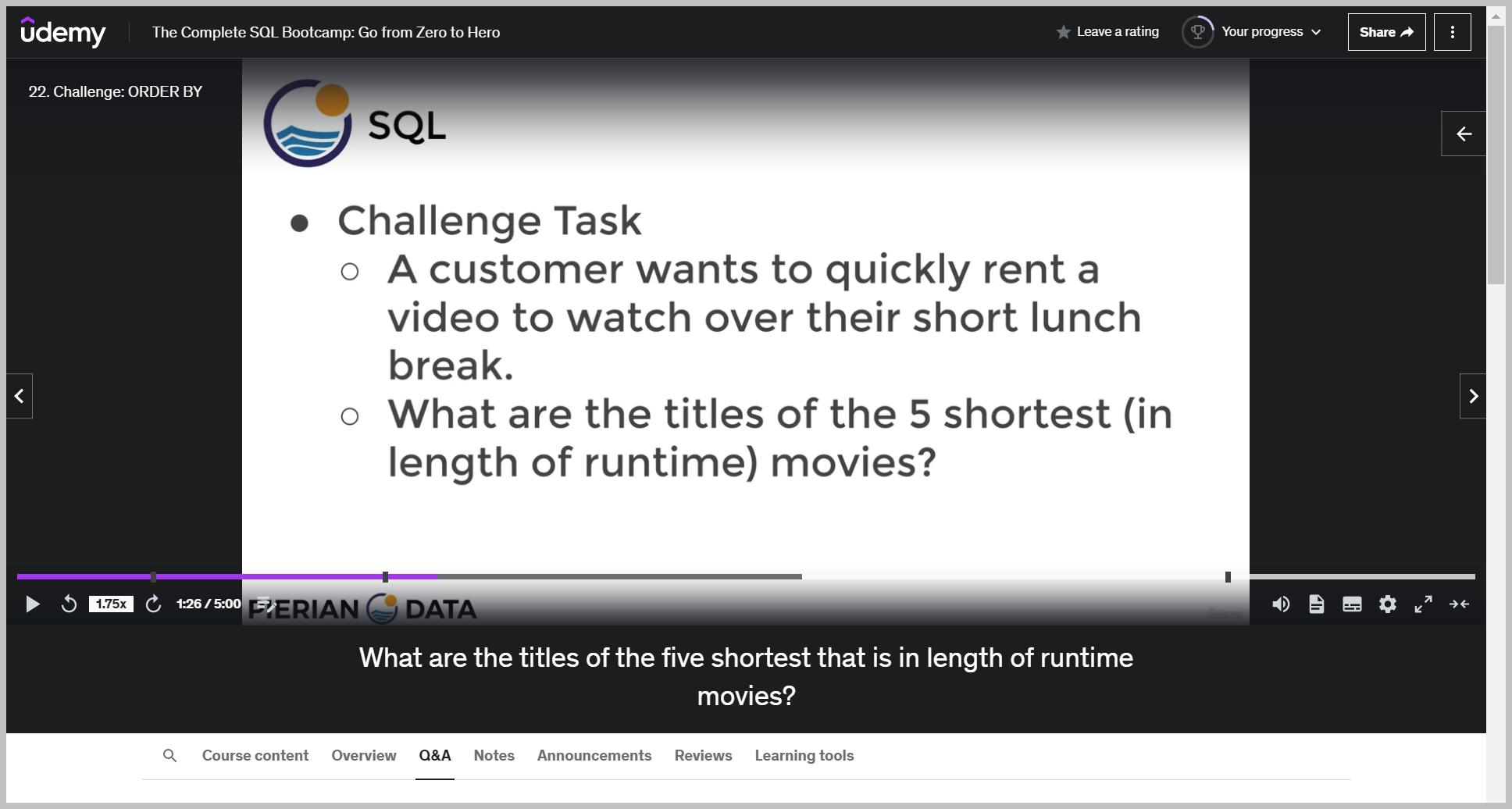
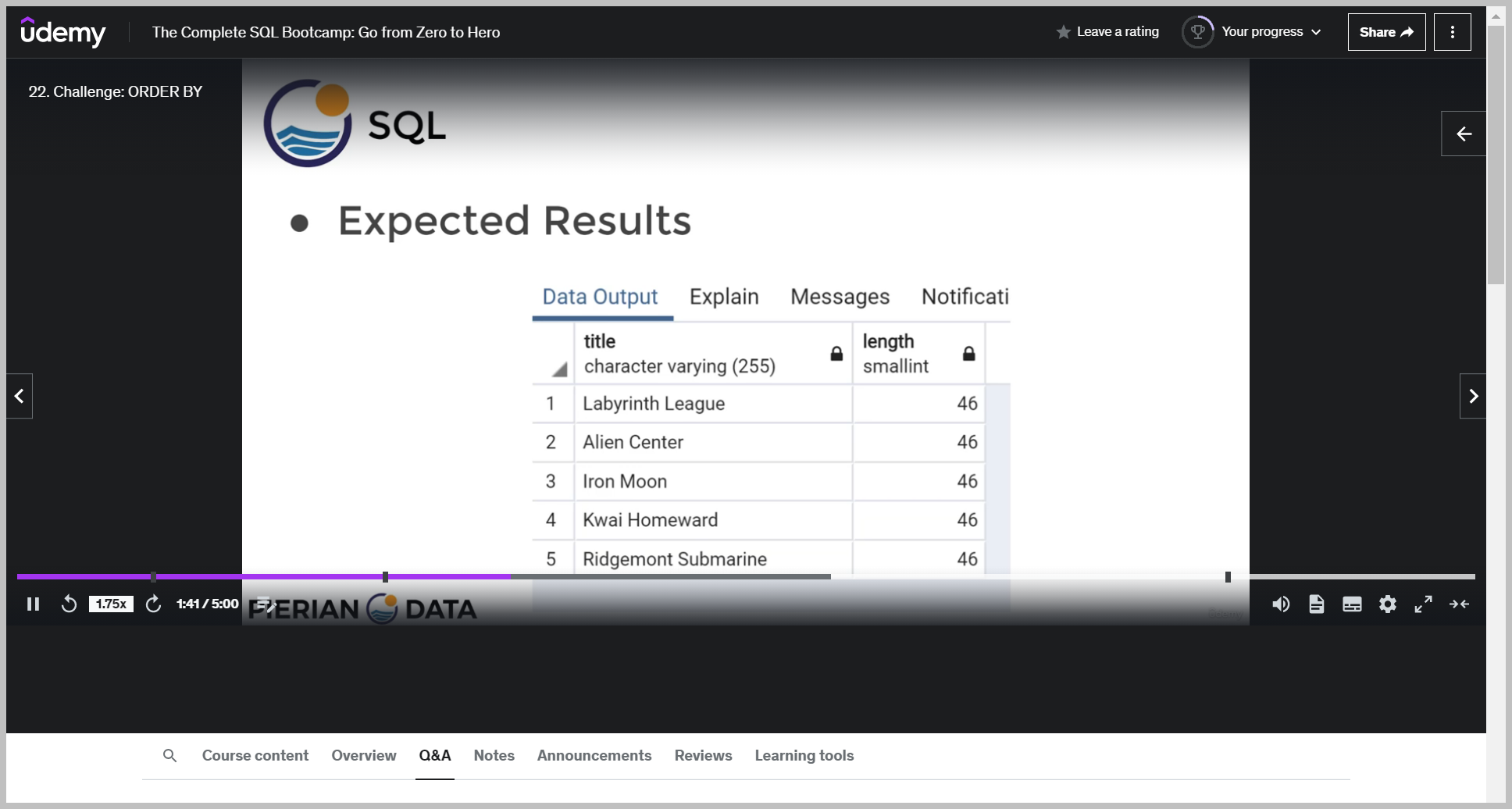
솔루션
BETWEEN 연산자
주의사항

예제
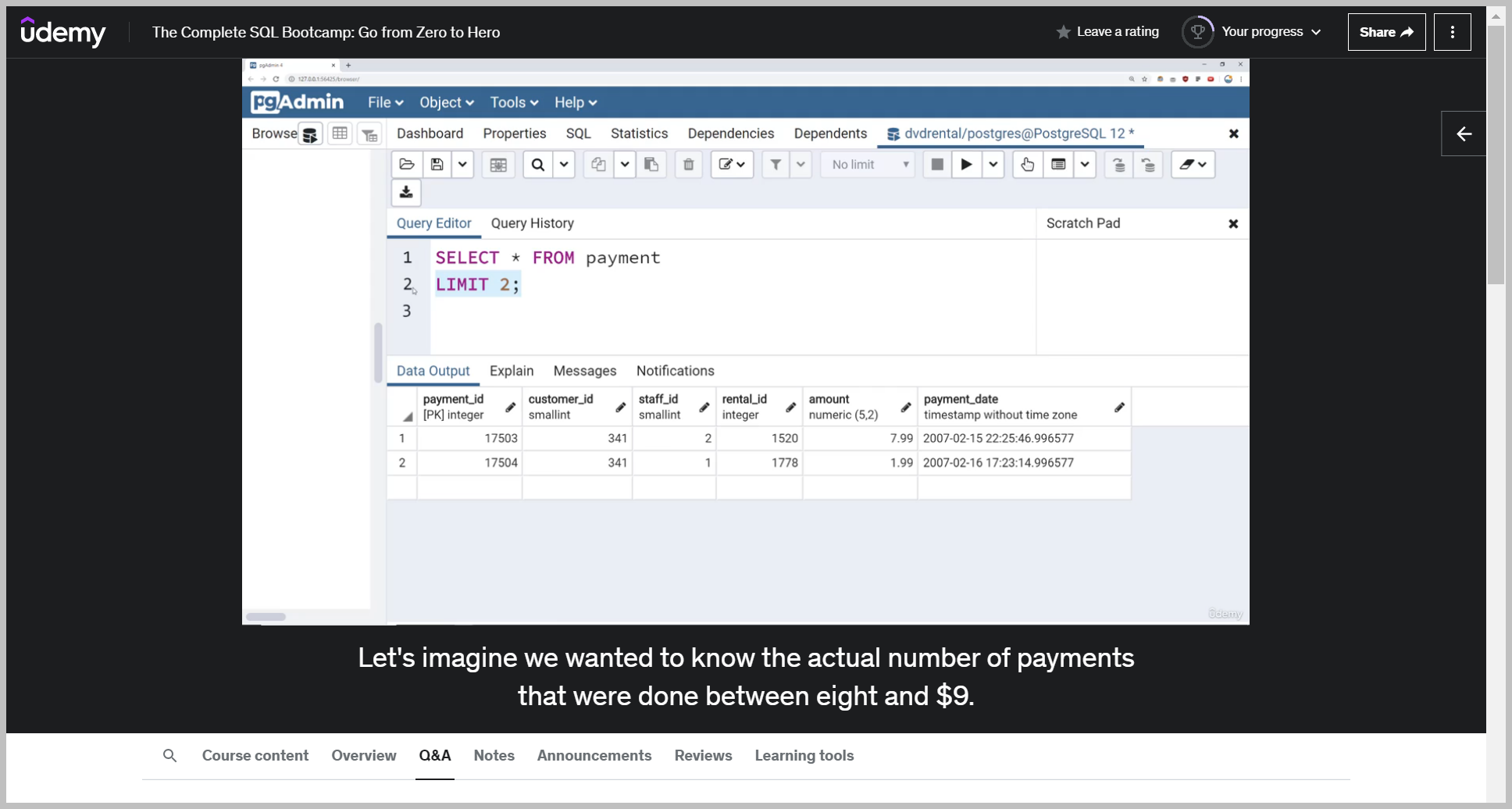
Let's imagine we wanted to know the actual number of payments that were done between eight and $9.
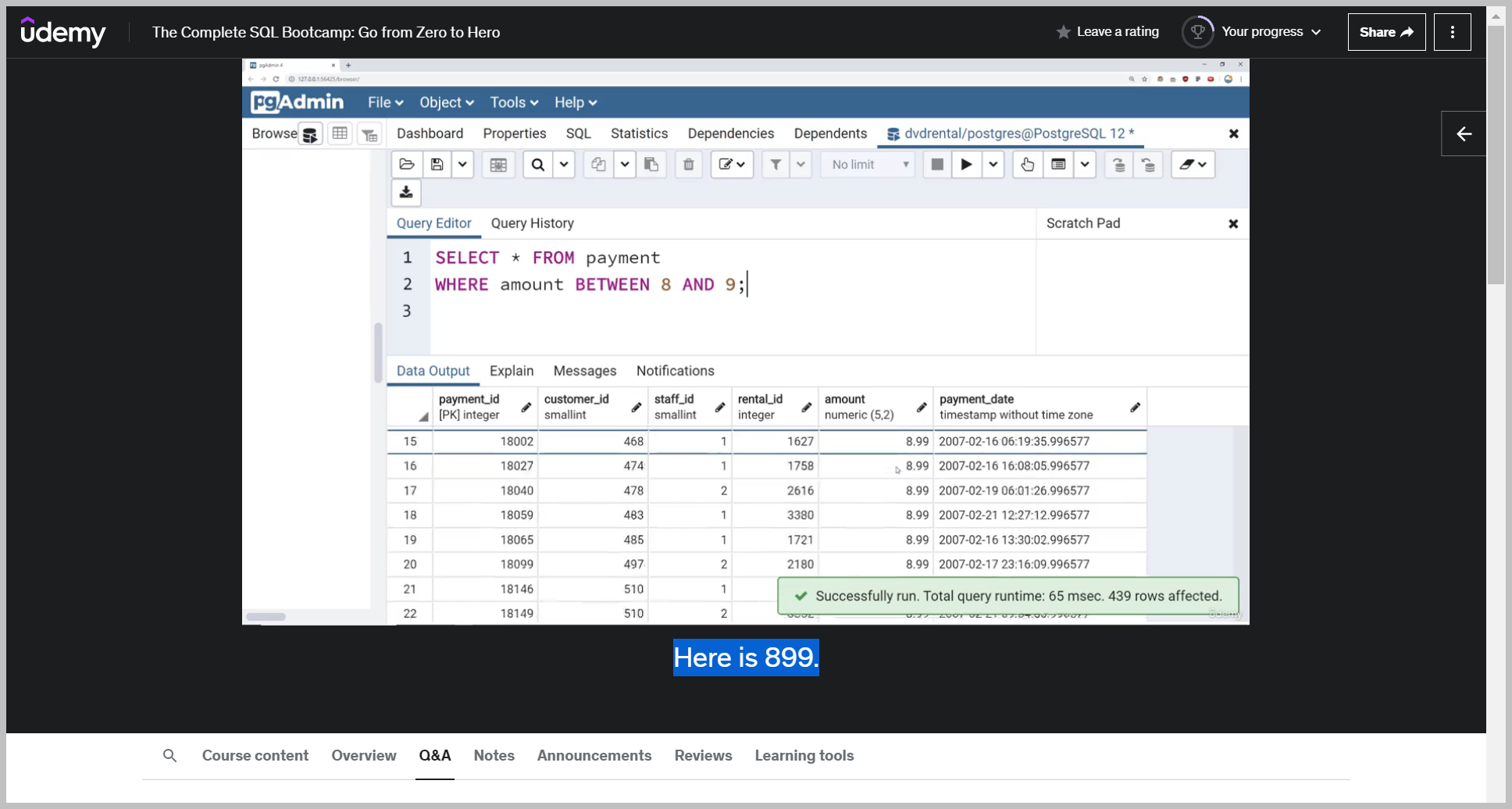
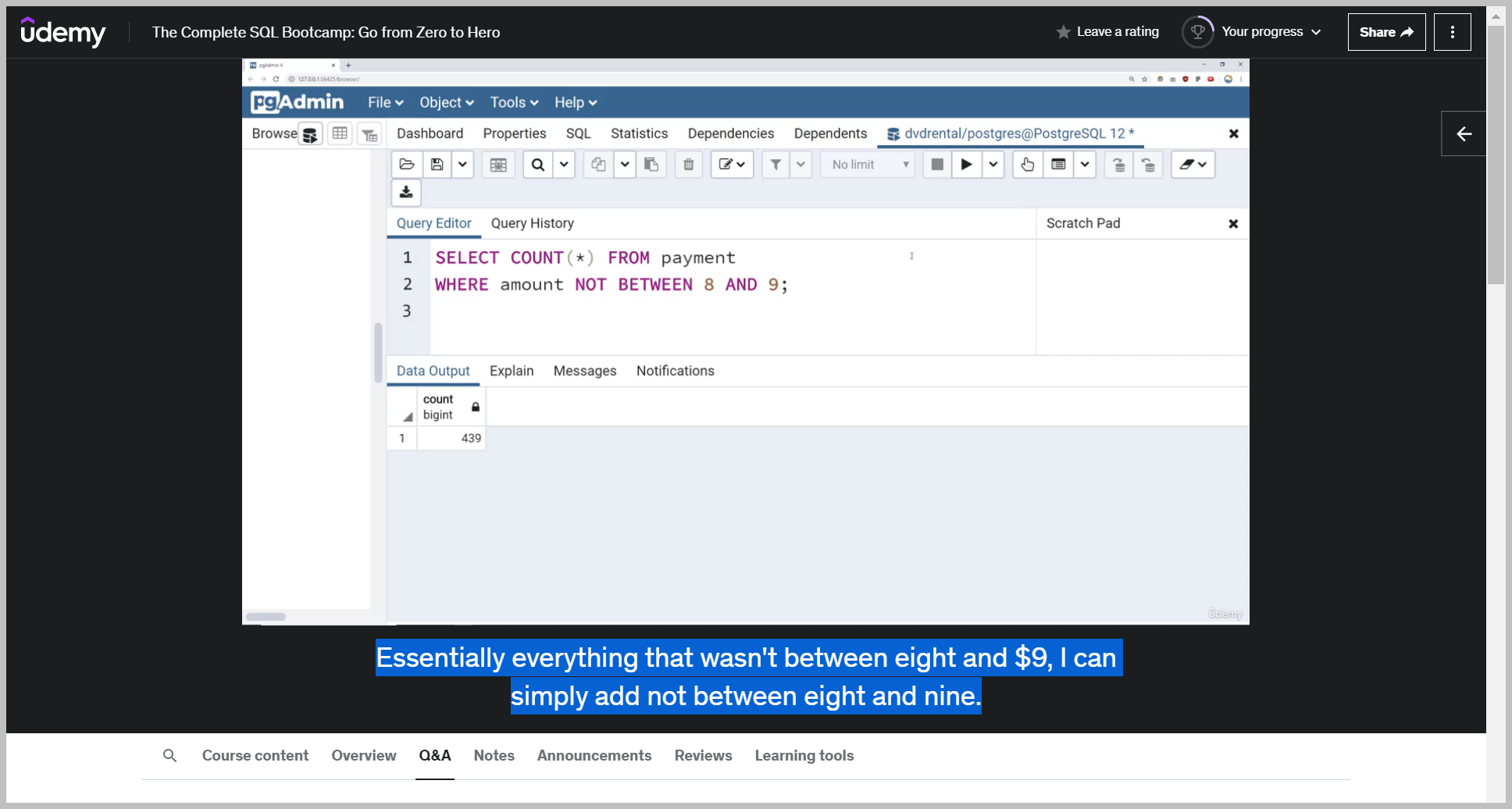
Essentially everything that wasn't between eight and $9, I can simply add not between eight and nine.
주의사항(타임스탬프 정보)
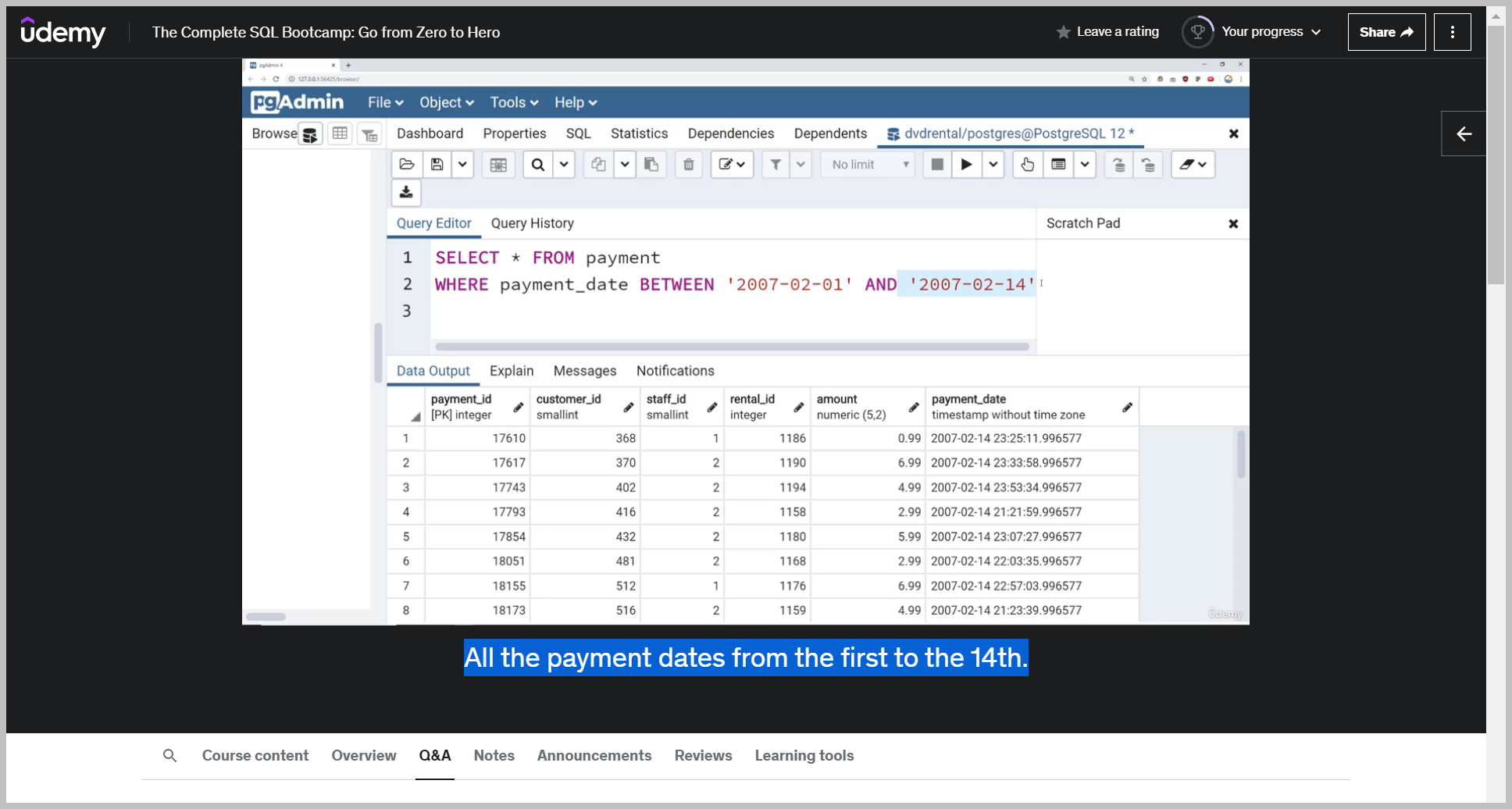
Now, something to keep in mind, especially when you're dealing with a timestamp information, is that this timestamp information includes both the dates and our minutes, etc..
So that means PostgreSQL essentially has to decide does a day start at zero hundred hours or at 2400 And if you're dealing with exclusivity versus inclusivity, that actually might affect your logic.
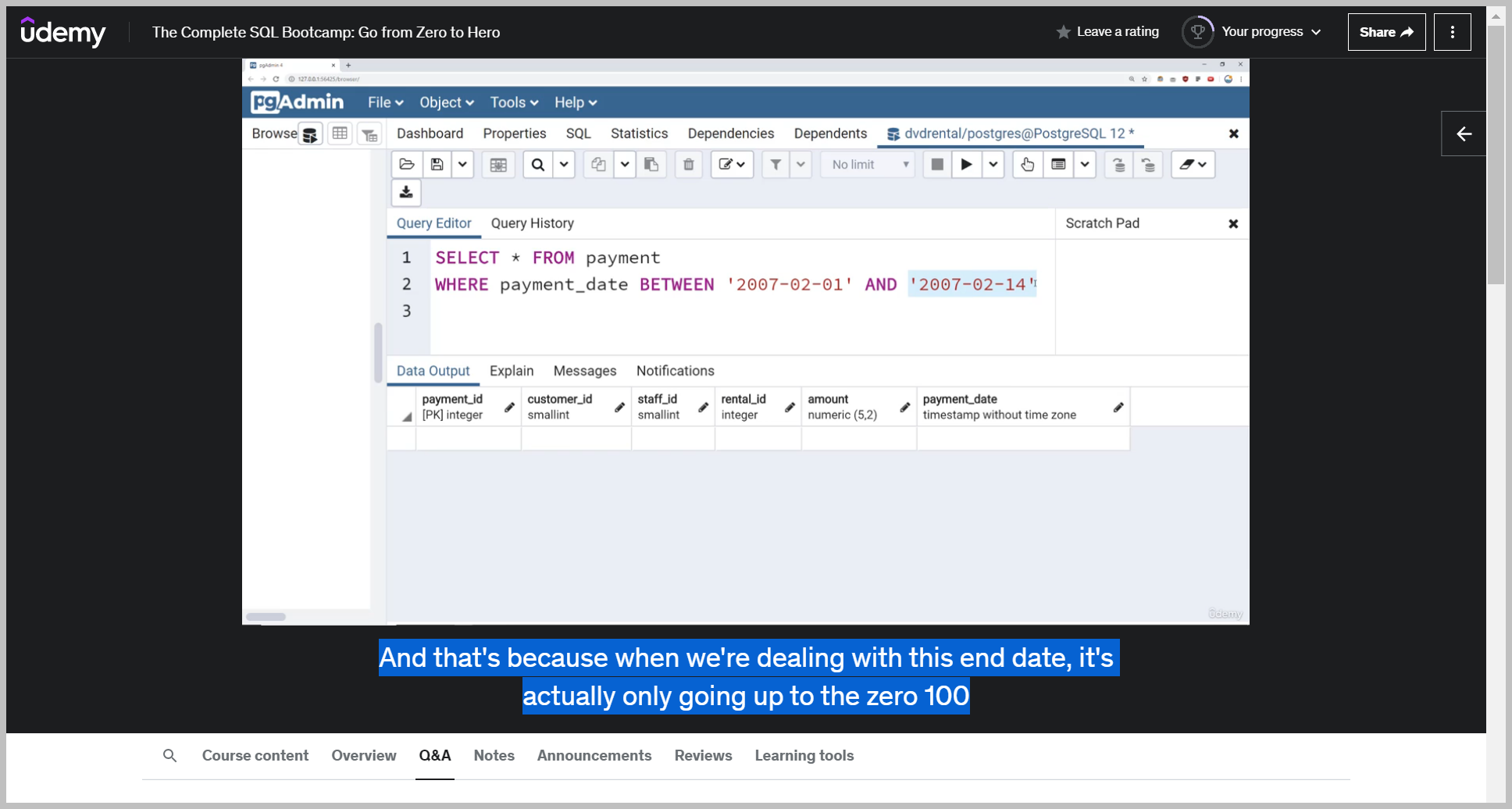
And that's because when we're dealing with this end date, it's actually only going up to the zero 100 hour mark.
It's not going to the end, which would be the 2400 hour mark of the 14th, which is why for these sort of between statements, when you're dealing with timestamp information, you just have to be careful that.
IN 연산자
기본 문법
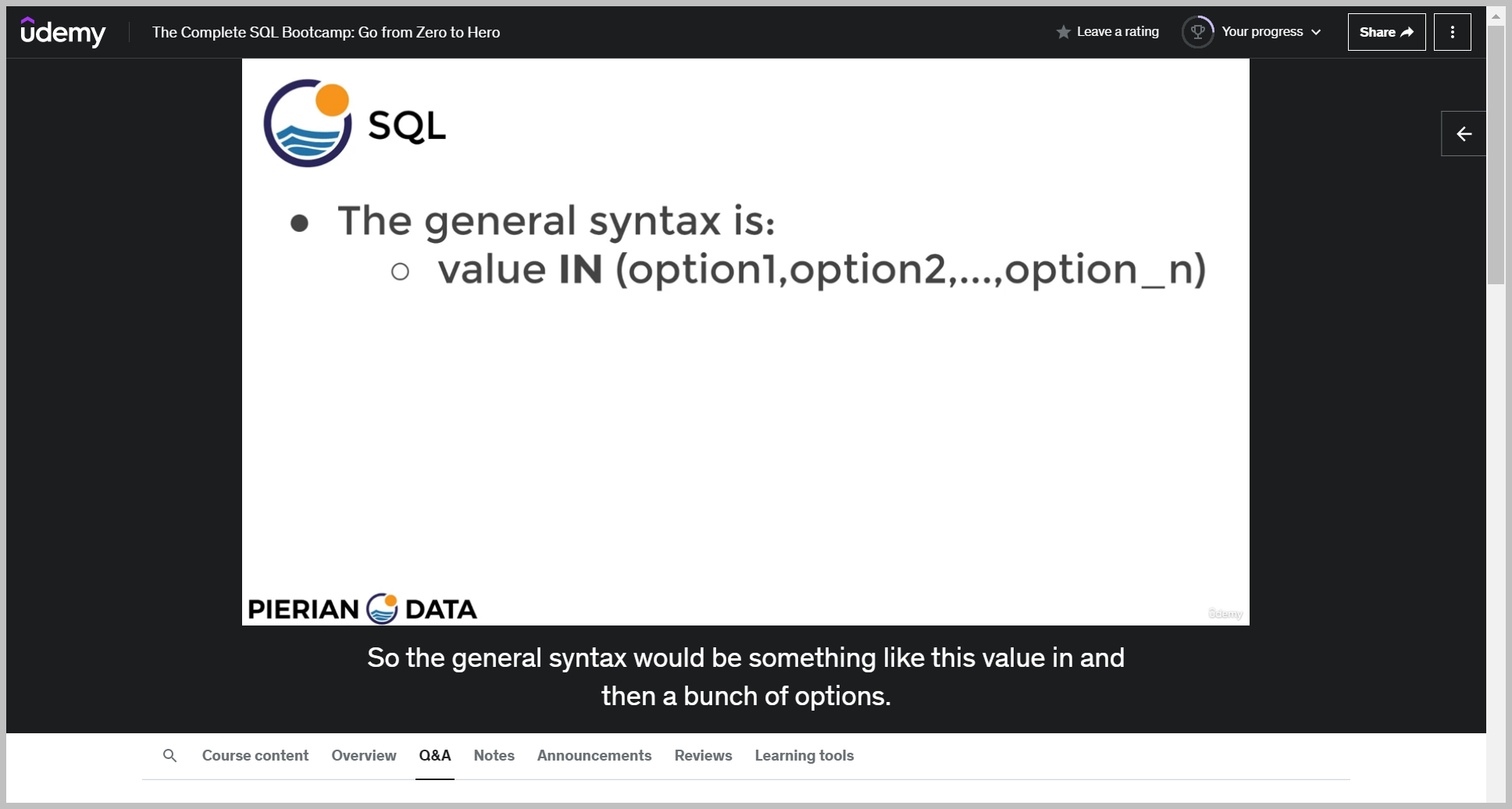
예제
So maybe I want to figure out all the orders that happen to be $0.99, 198 and 199.
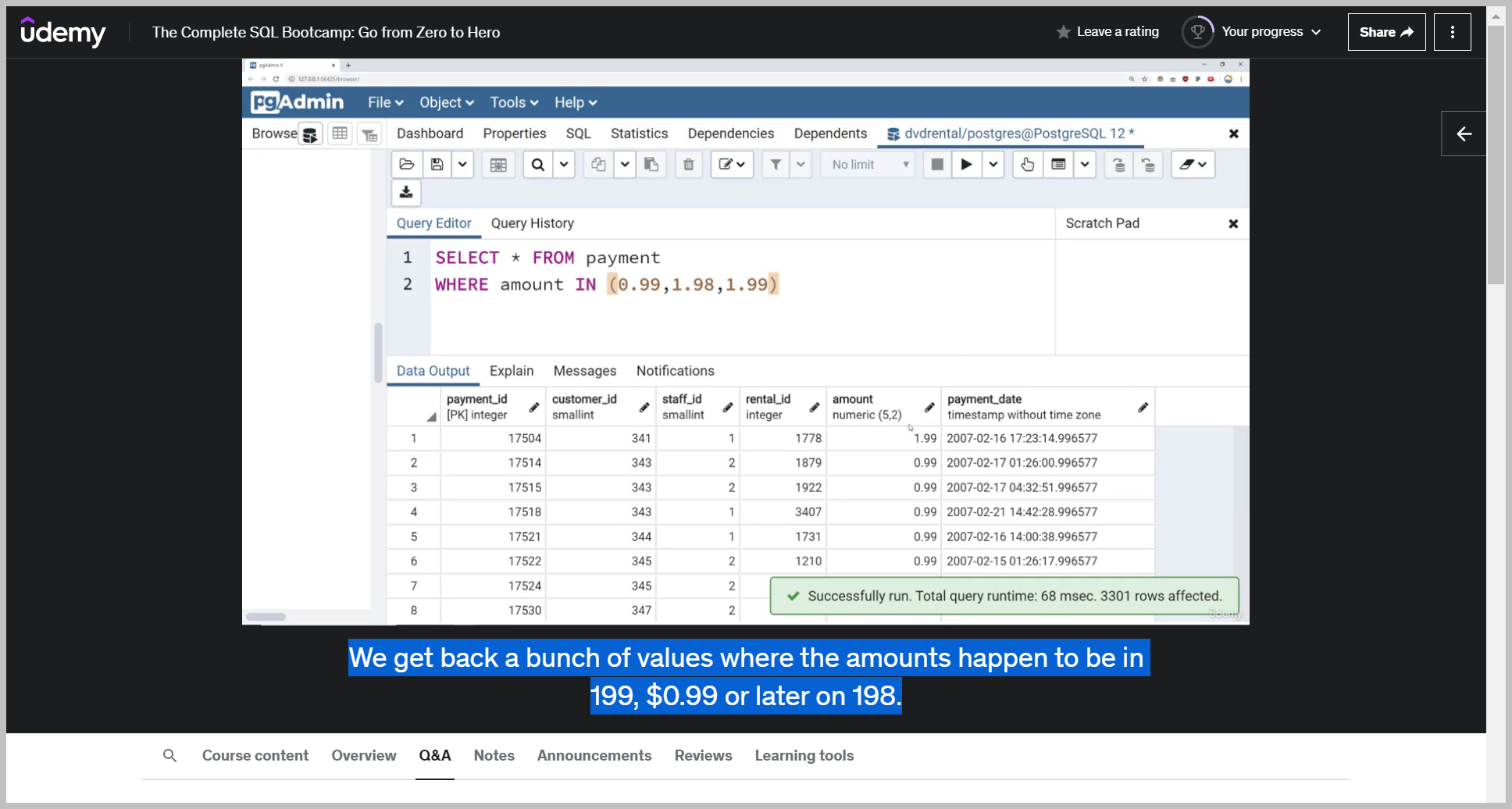
I'm not using strings or quotes because this is a numeric data type.
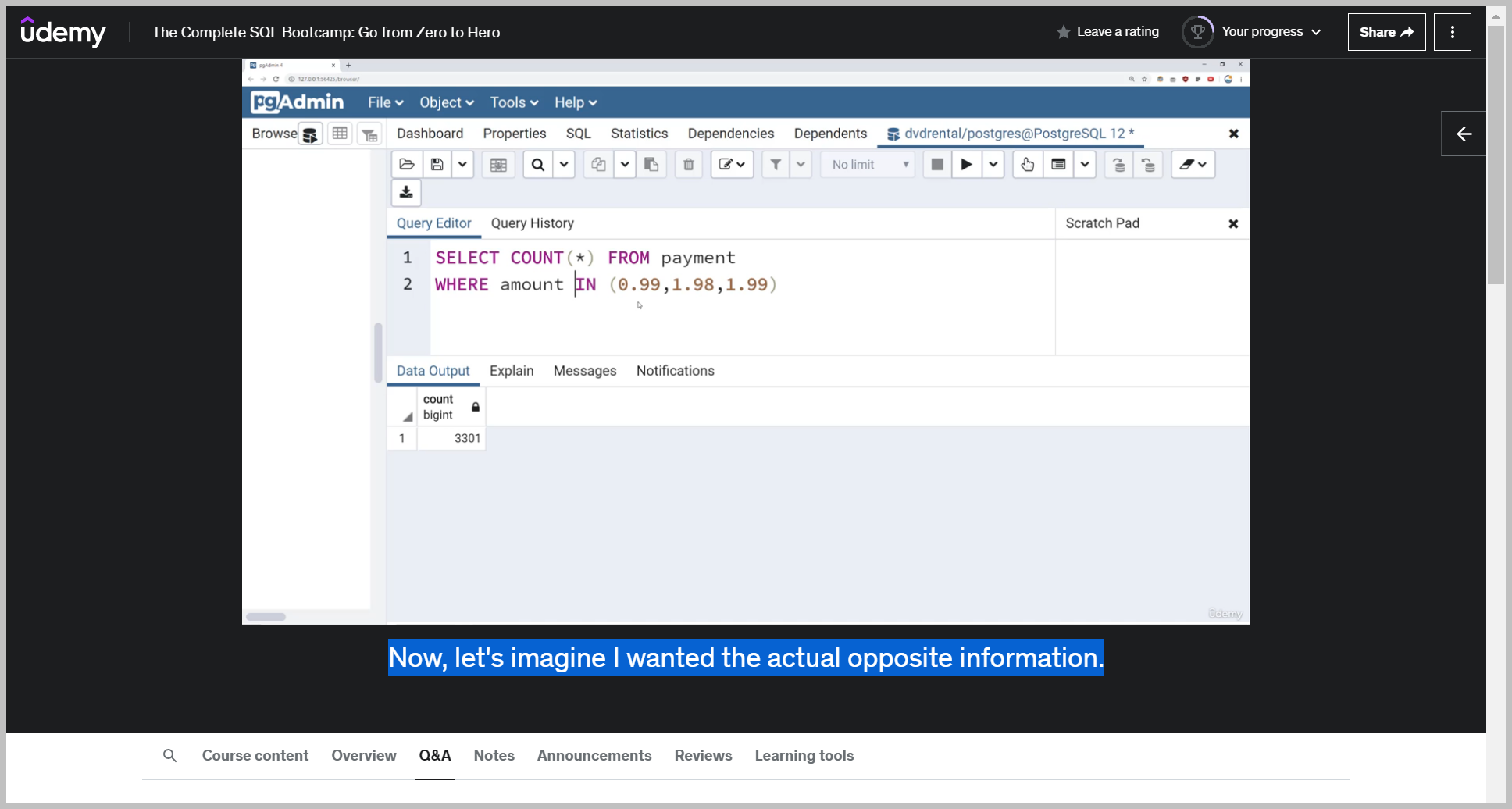
NOT IN
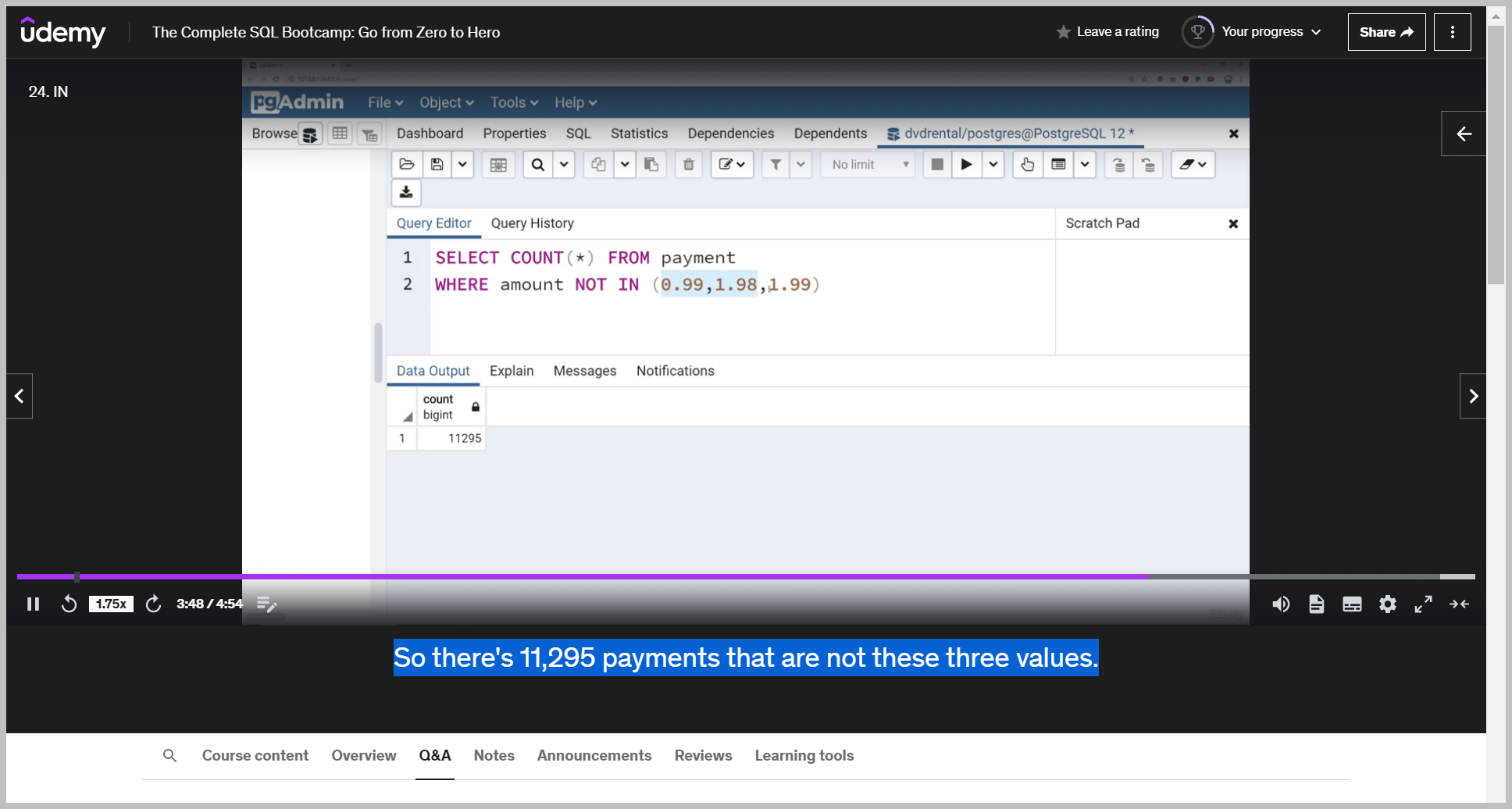
Q: I wanted to count out how many payments were not $0.99, $1.98 or 199?
LIKE & ILIKE 연산자
기본 문법

_ 언더바 활용

So here we have Cheryl, which starts with a single C, then HDR and then has two characters.
예제 (%싸인 활용)
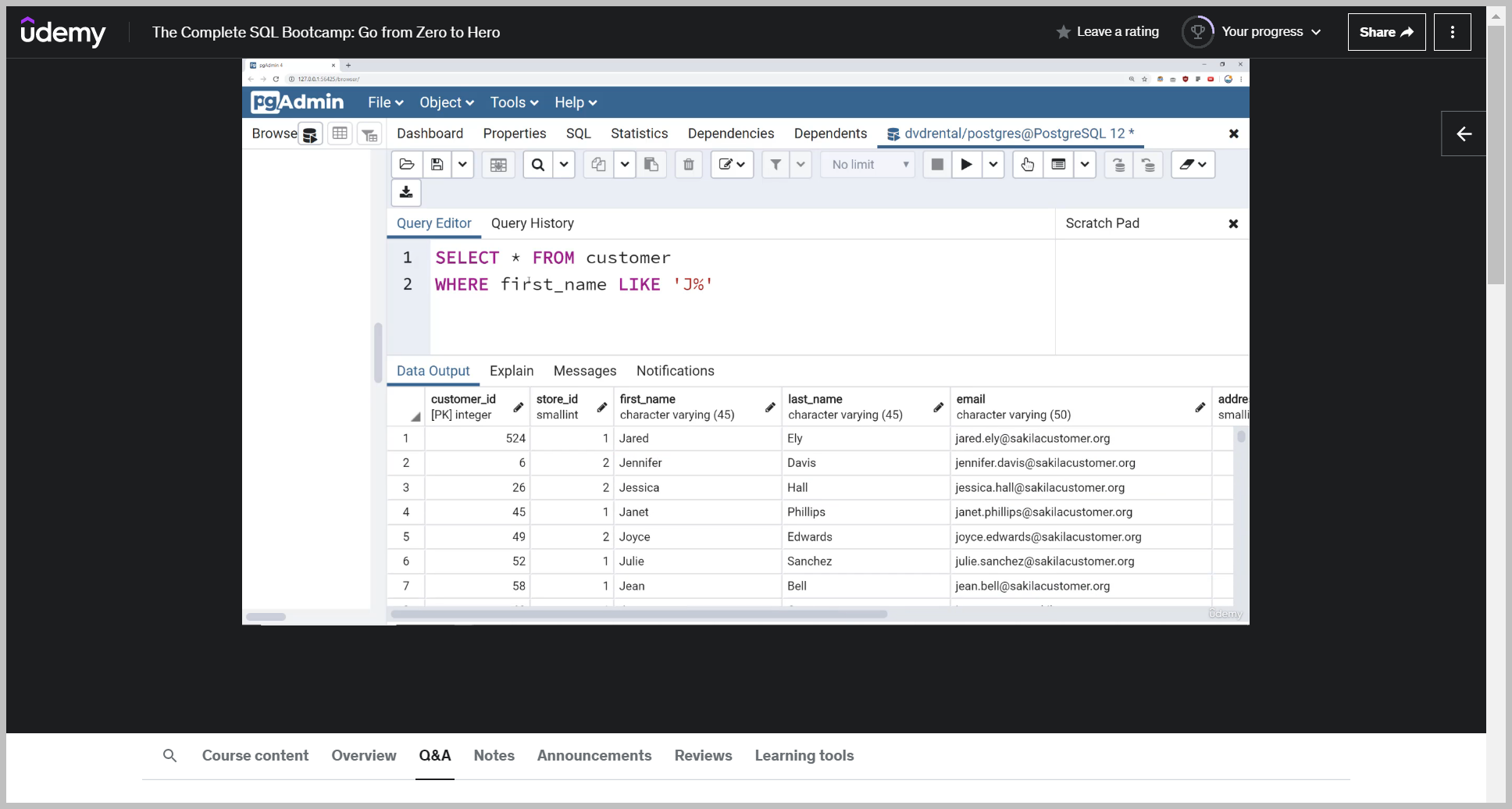
And then if I run this, I get back the results for every one that has a first name that starts with letter J.
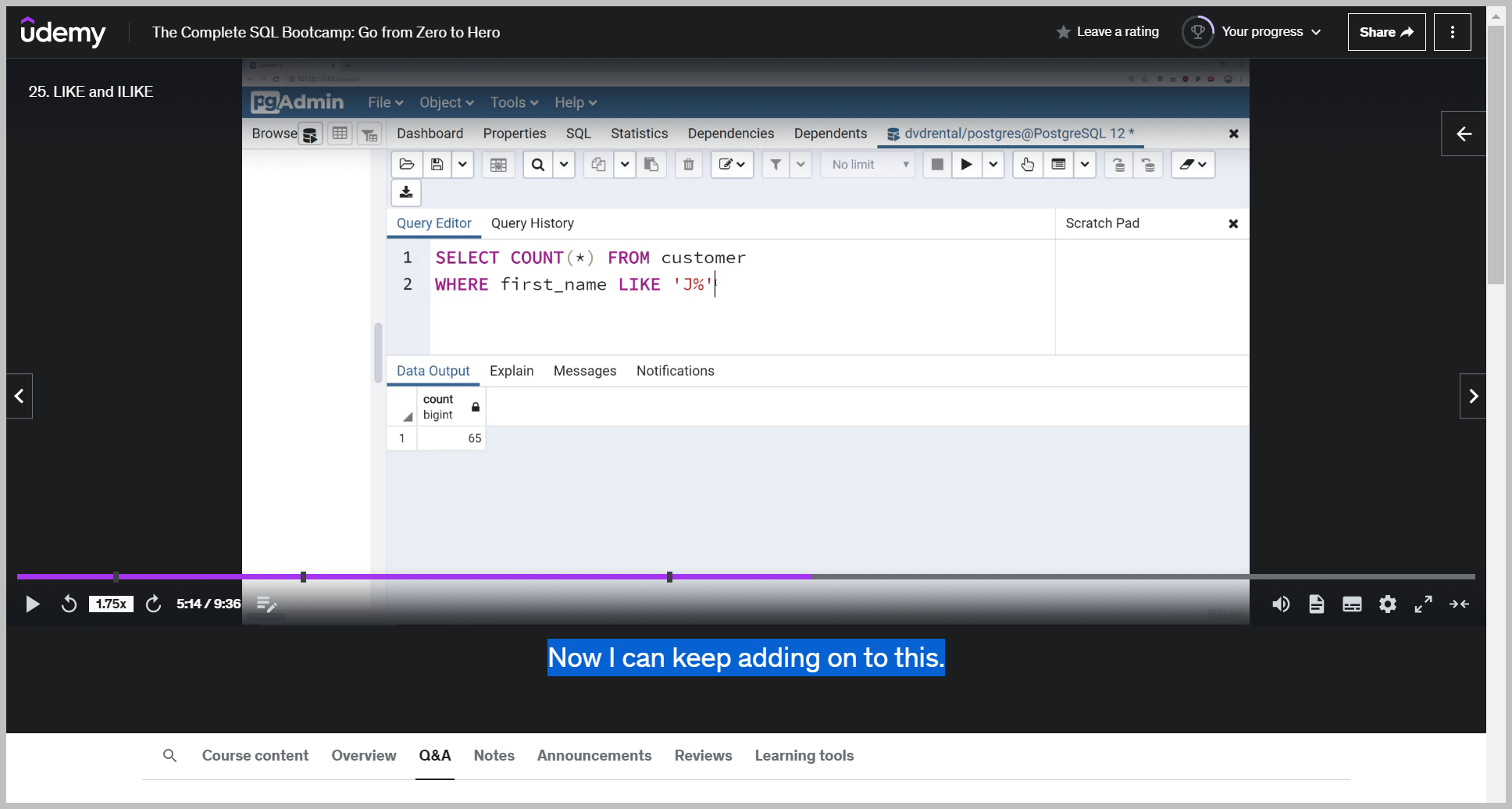
And if I want to to actually figure out how many of these there were, I could simply just provide a count on the number of rows returned and I get back there.
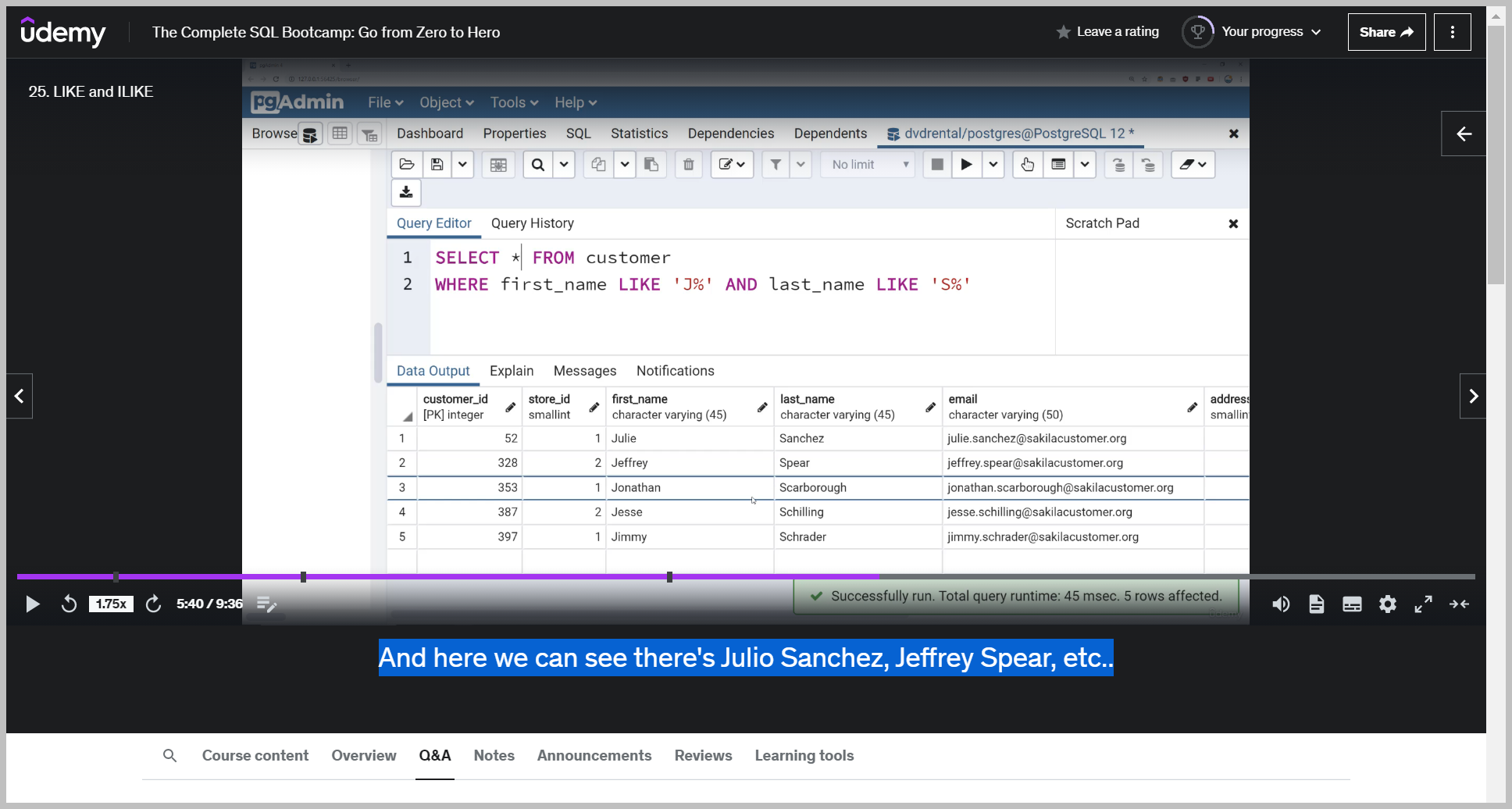
LIKE vs ILIKE
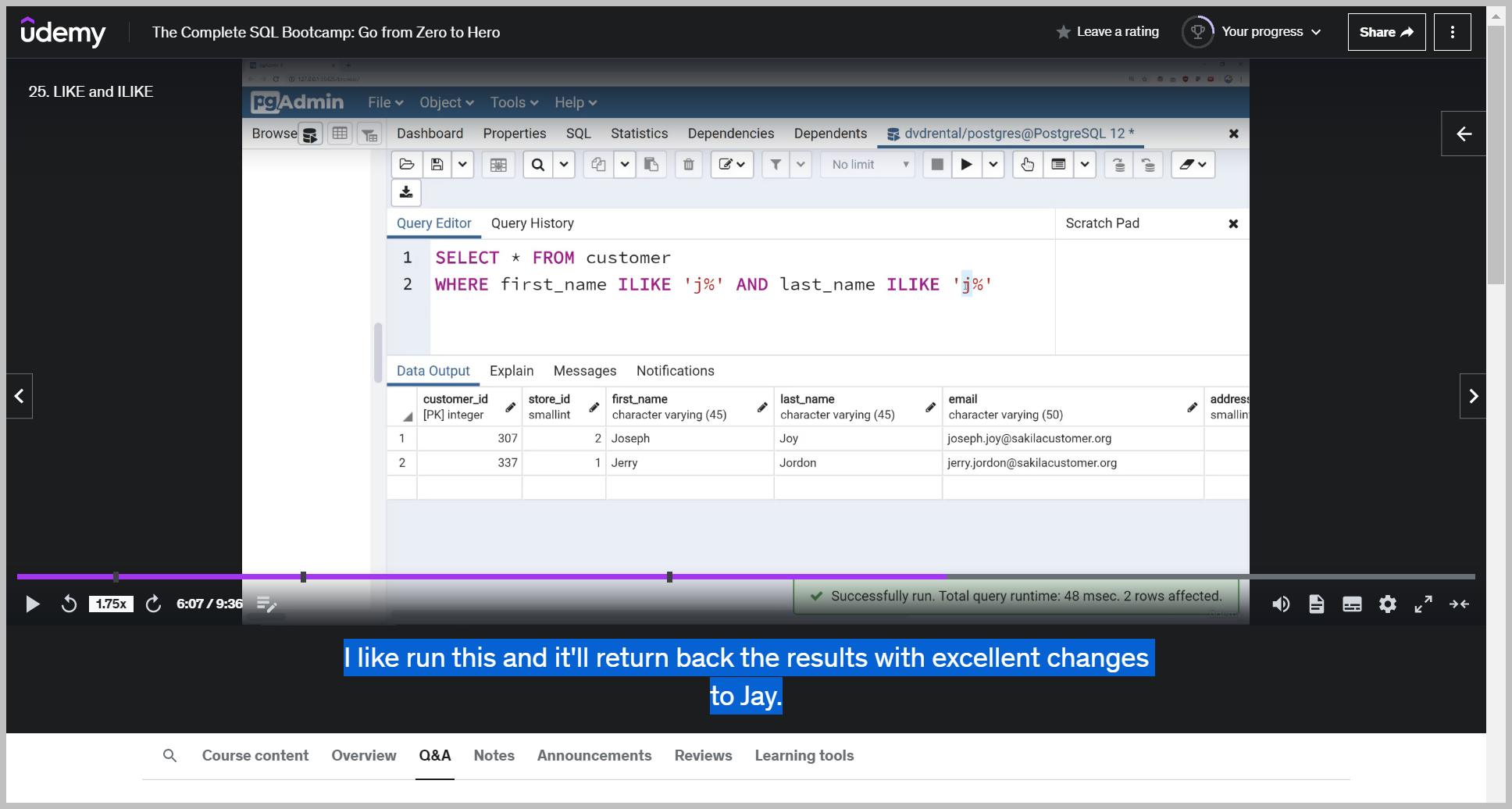
Ilike is case insensitive, which means it doesn't matter if I use the lowercase j.
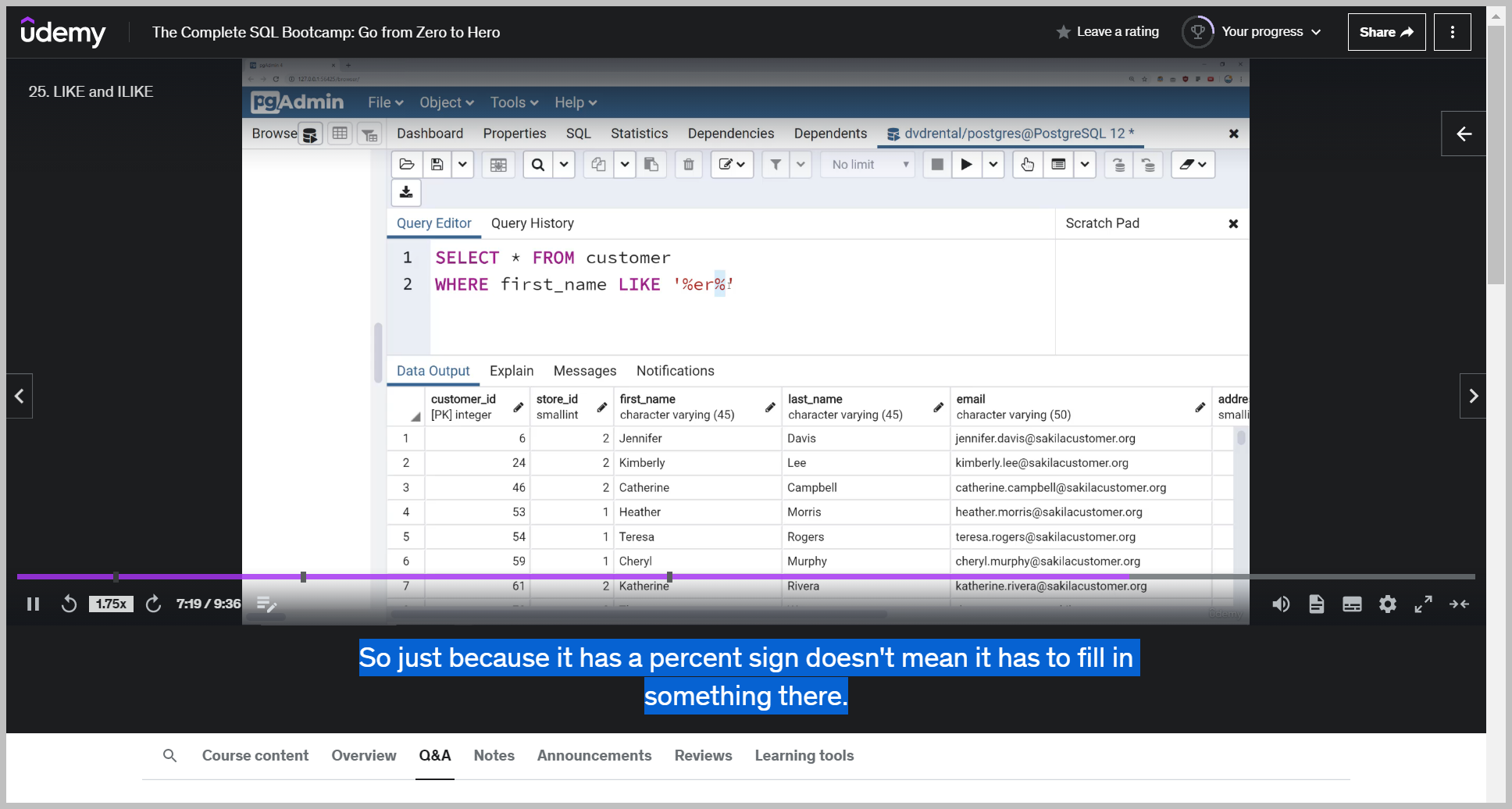
And basically what that's asking for is anyone who has e r somewhere in their first name.
So e r is at the end of Jennifer and this sequence of characters can also be nothin So that means e r just has to show up anywhere inside this name.
So just because it has a percent sign doesn't mean it has to fill in something there.
예제2 (_ 언더바 활용)
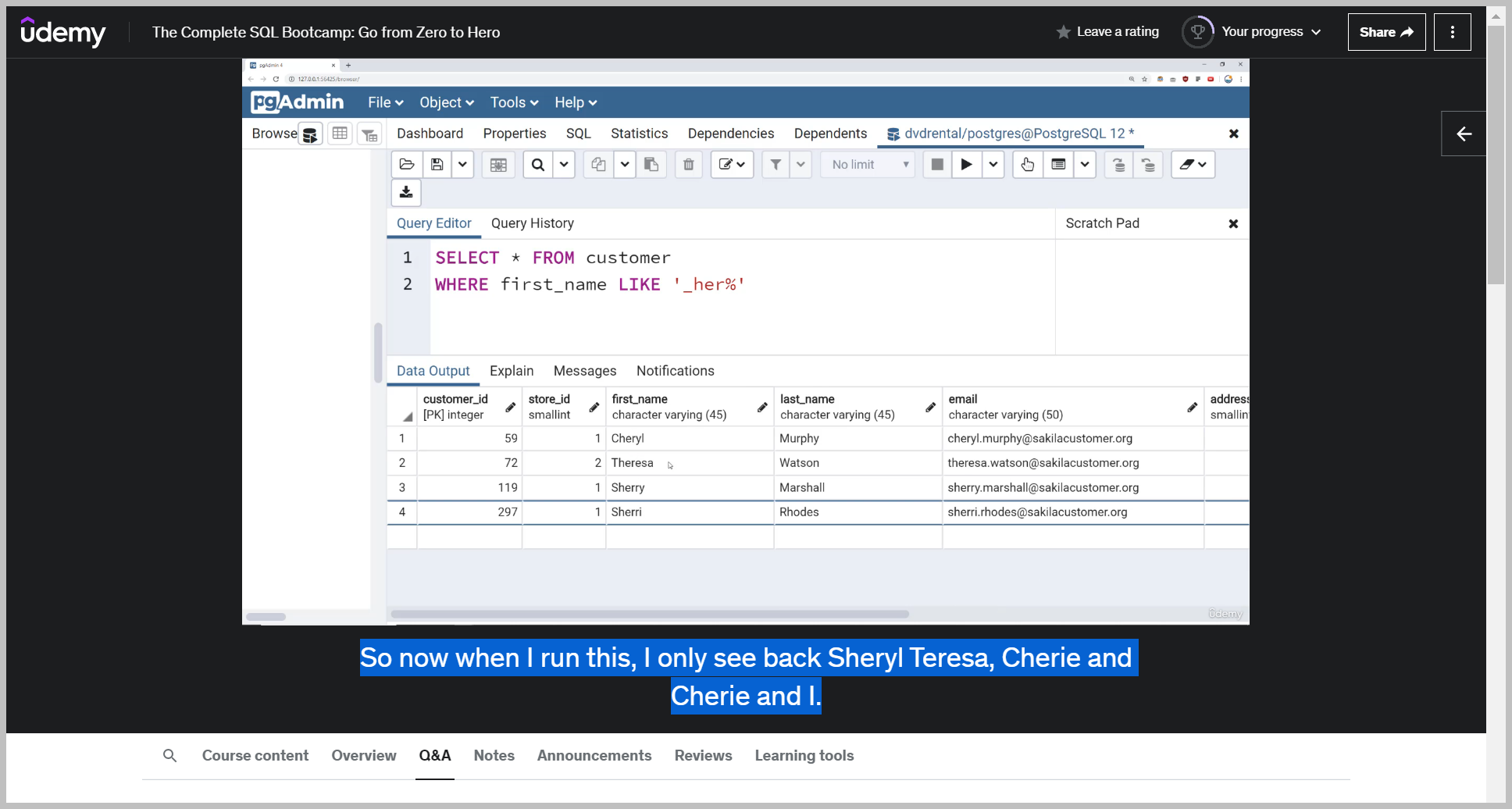
Or we can do what we did in the slides, which is replace one of these with a single underscore, which means only one character is now allowed in that space.
언더바 + 논리연산자
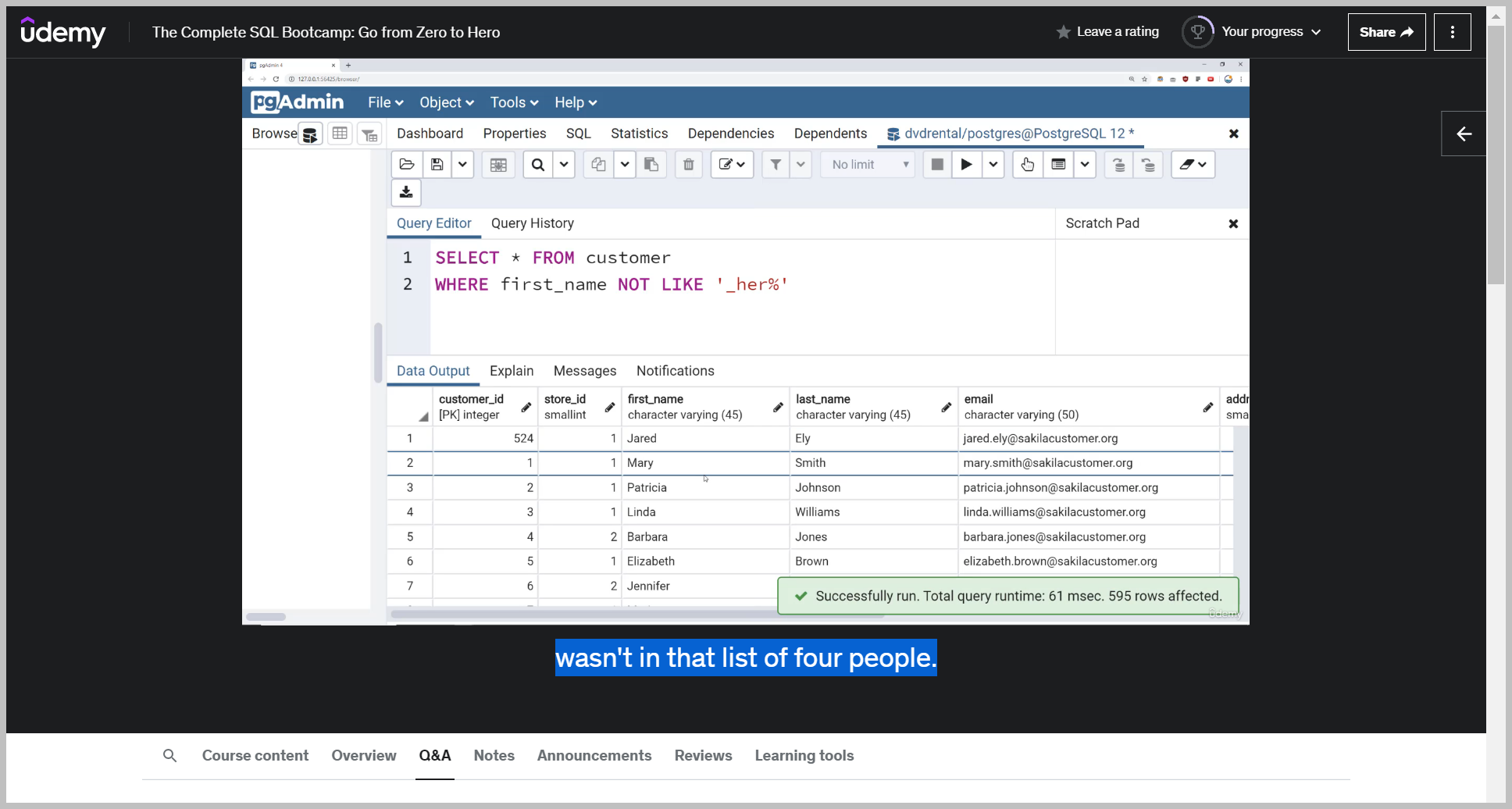
Something that's also important to note and we'll finish this off, is to show you that you can also add in the knot operator to essentially get the opposite.
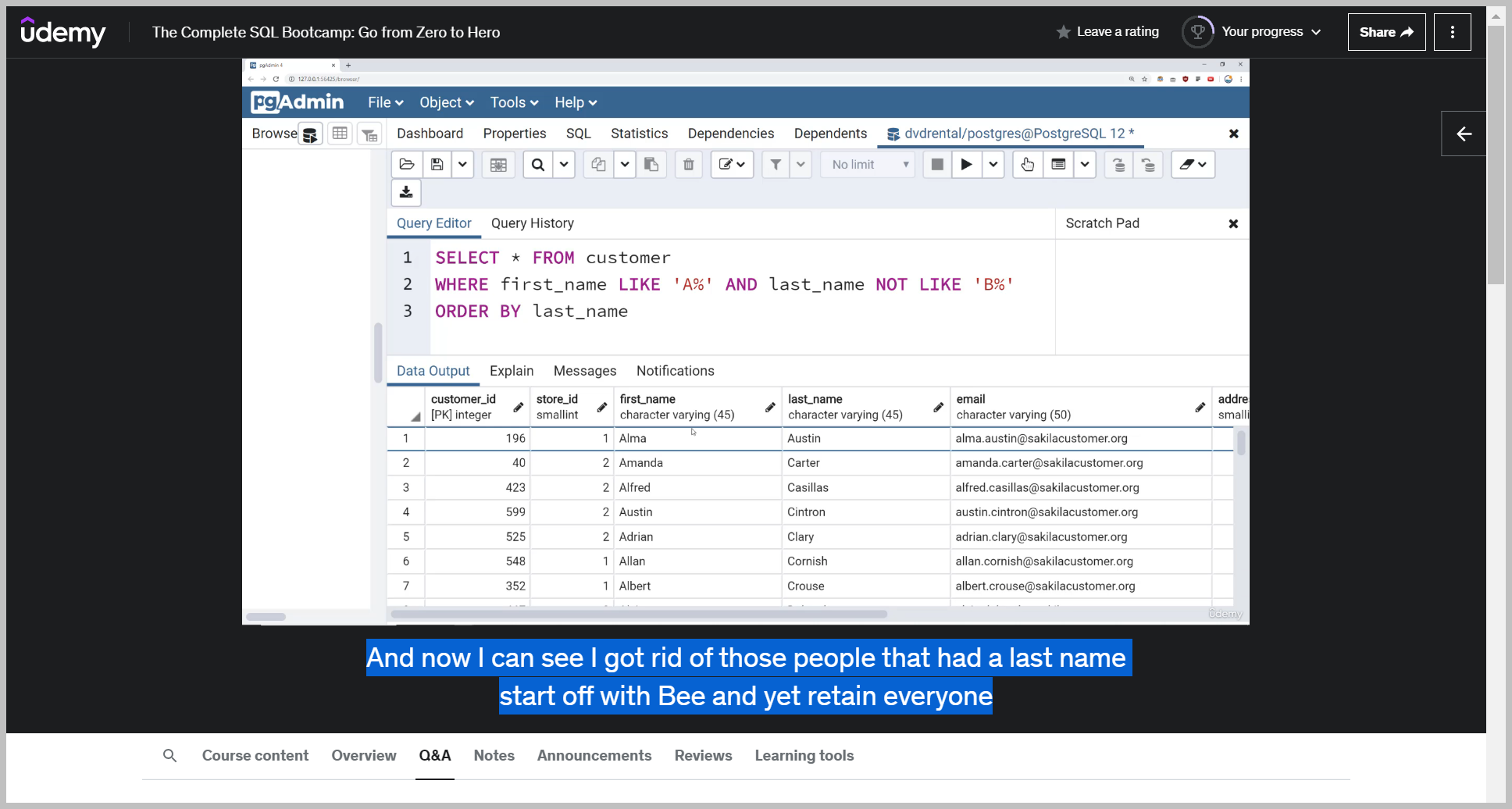
And now I can see I got rid of those people that had a last name start off with B and yet retain everyone who has a first name starts A.
GROUP BY 구문
Aggregation(집계) 함수

MIN()
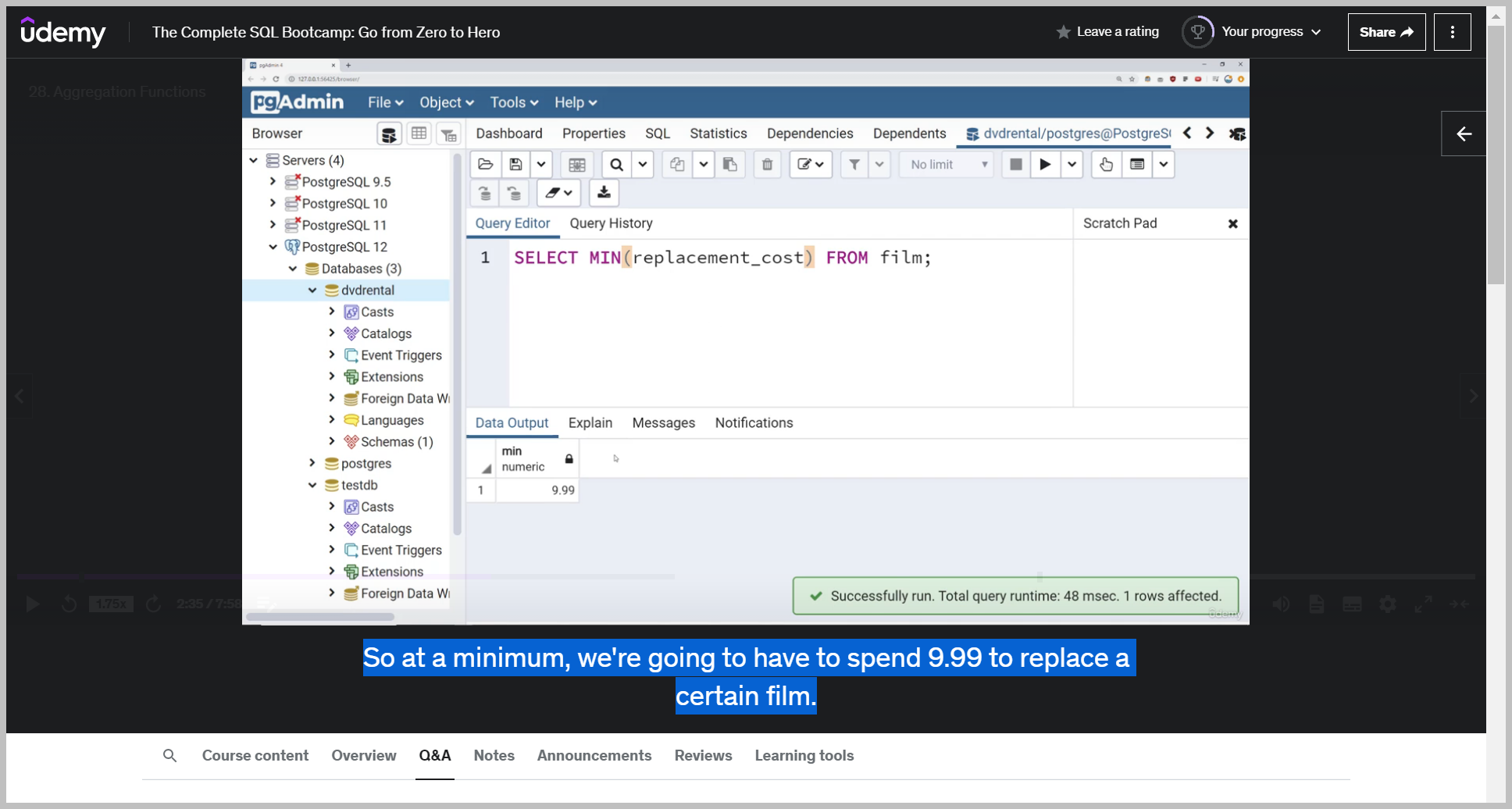
Well, what I could do is call my aggregate function and then I'm going to call parentheses, since this is a function call and I call it on that column replacement cost.
MAX()
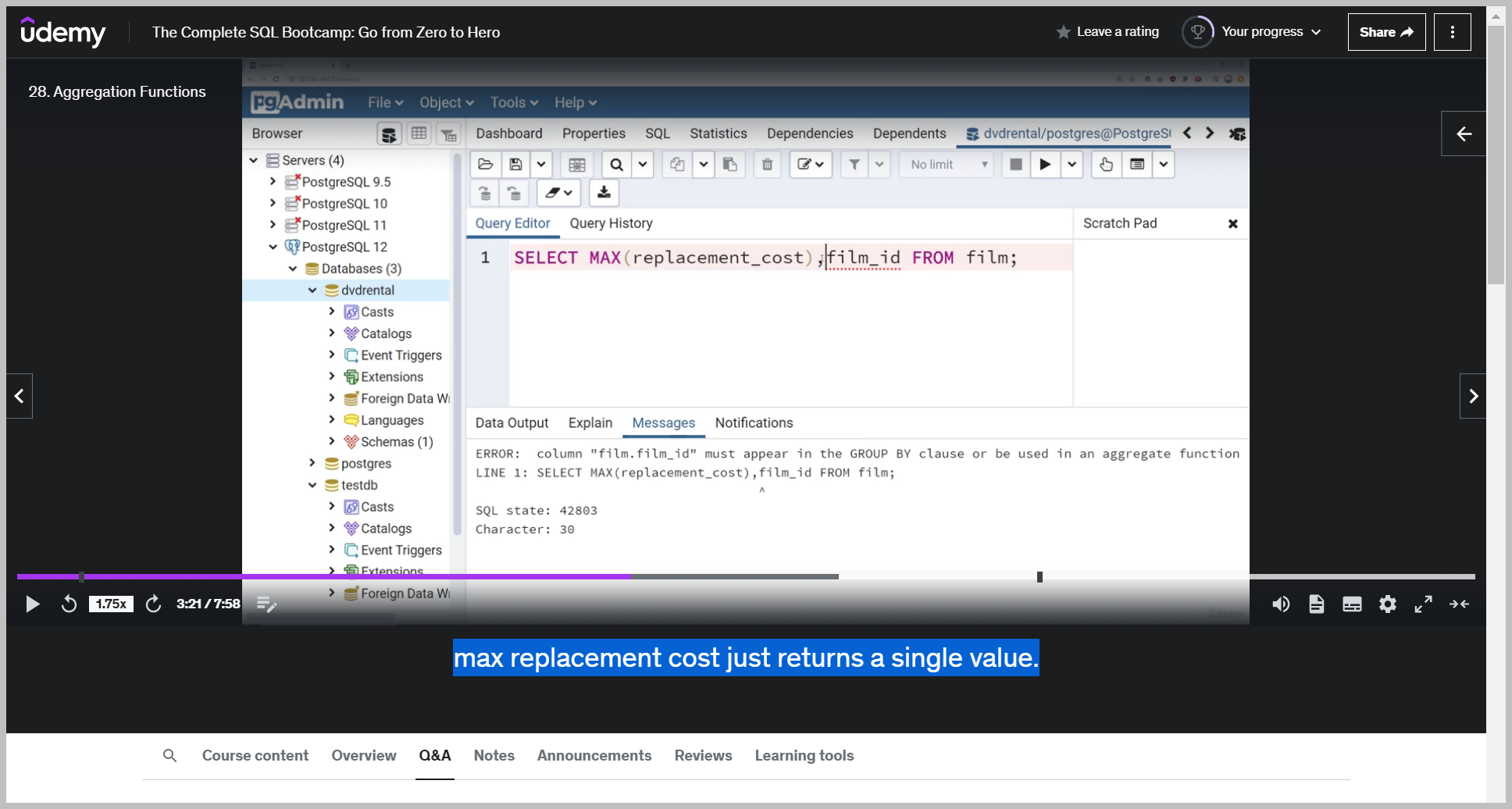
max replacement cost just returns a single value.
So it doesn't really make sense to call another column with this.
주의사항
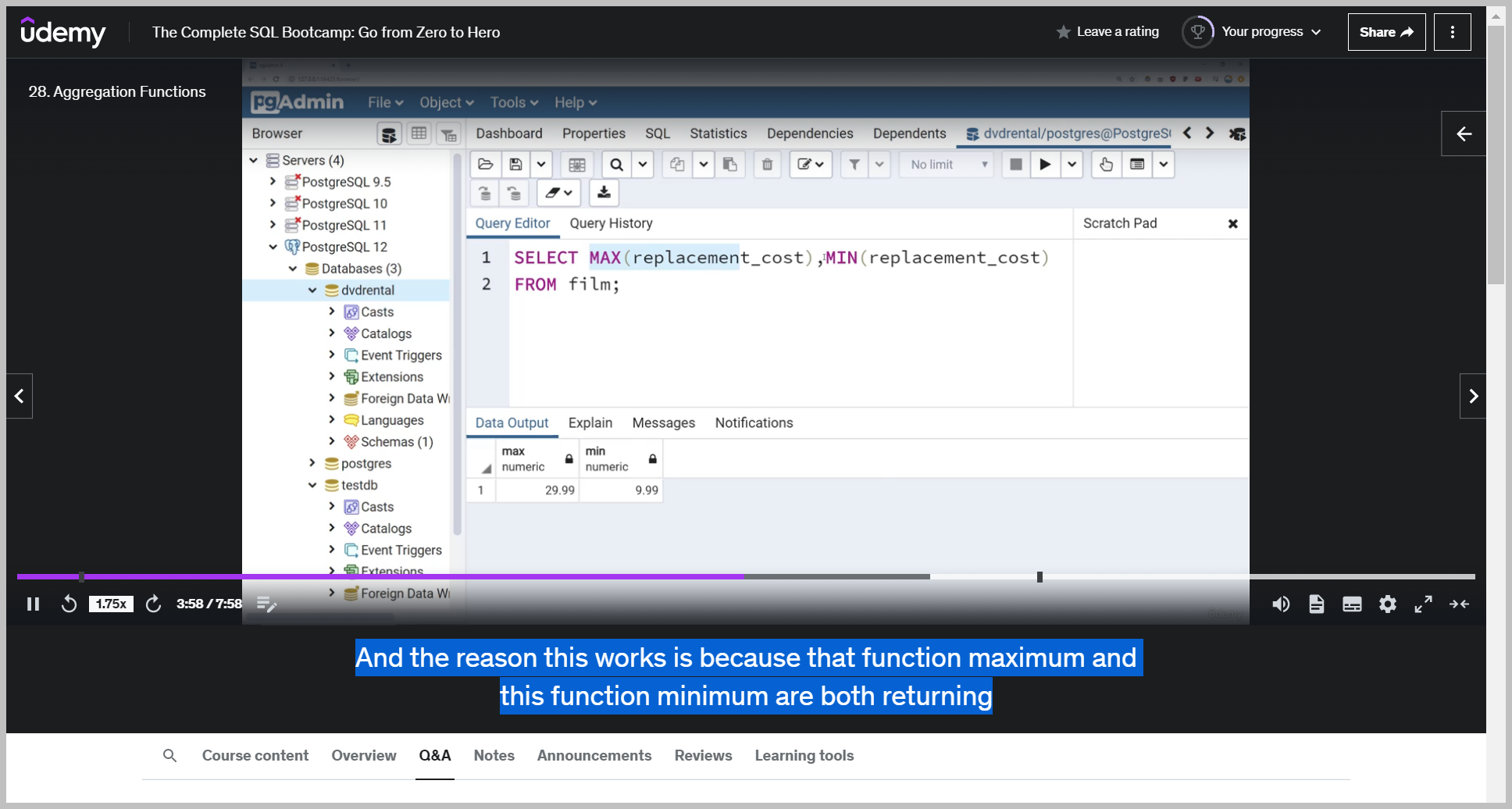
And the reason this works is because that function maximum and this function minimum are both returning singular value.
ROUND() + AVG()
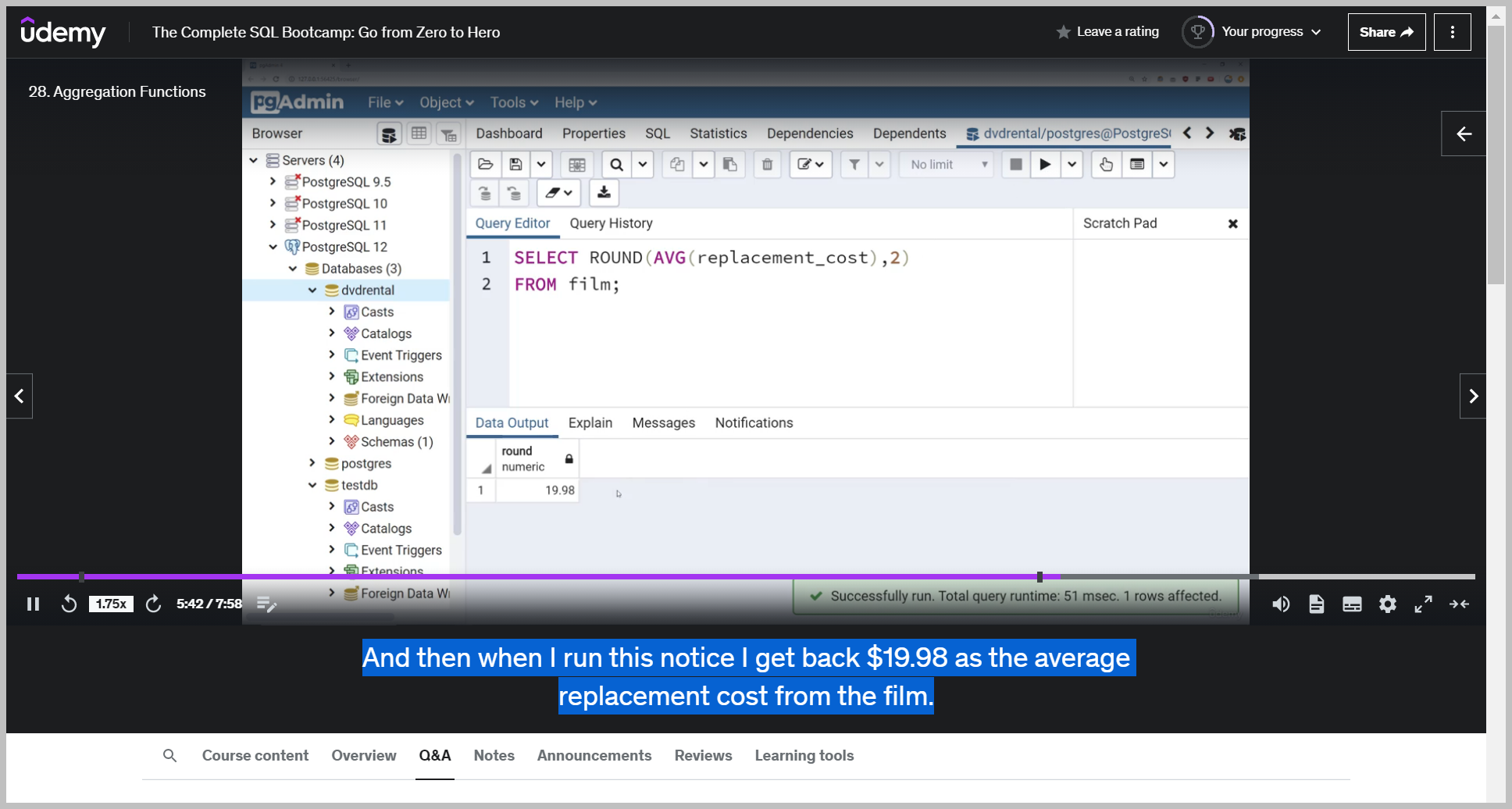
And the round function actually takes in two parameters.
One is the value you actually want to round, and then we're going to put a comma here and how many decimal places we want to round it to.
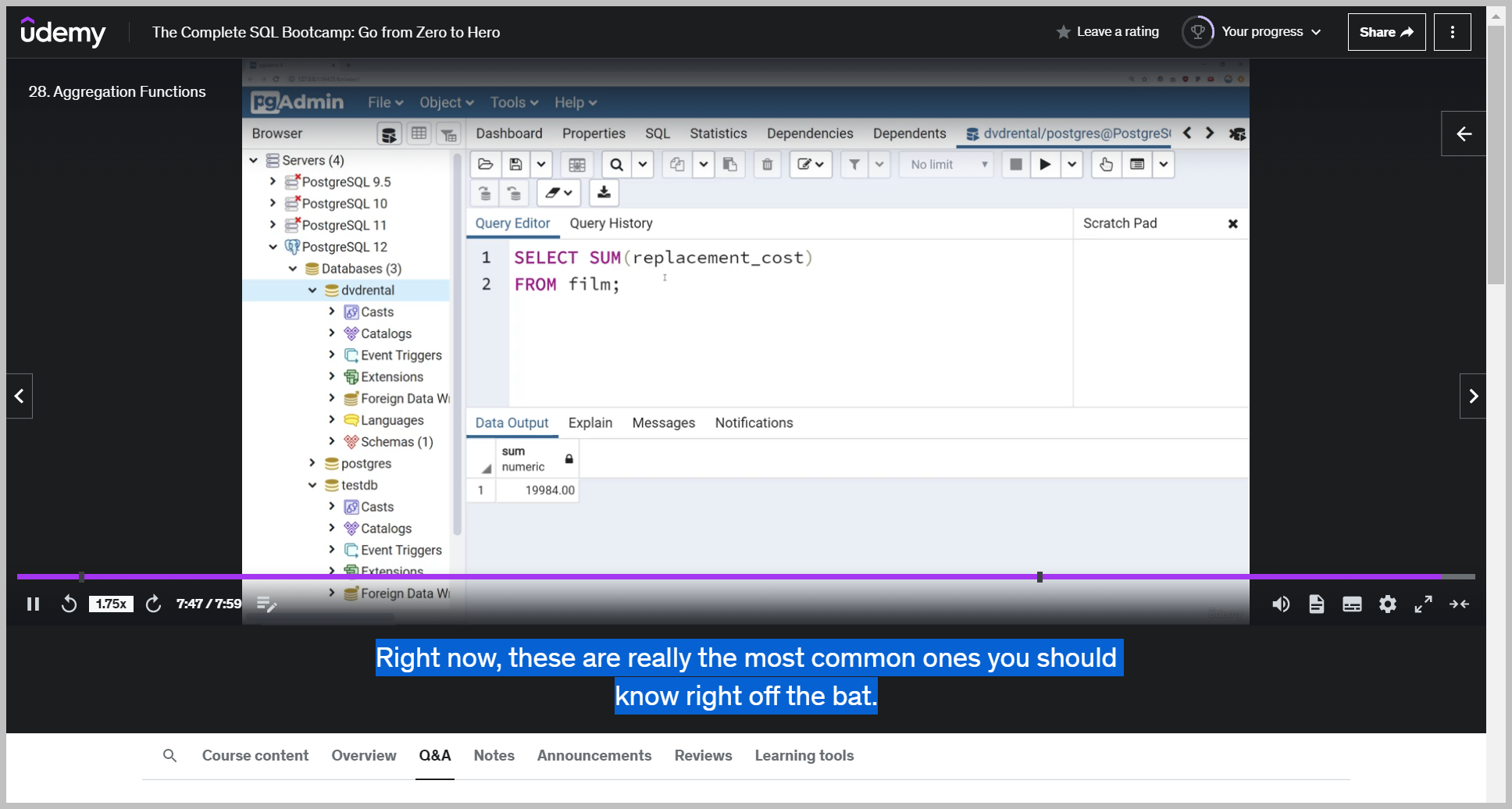
SUM()
GROUP BY1
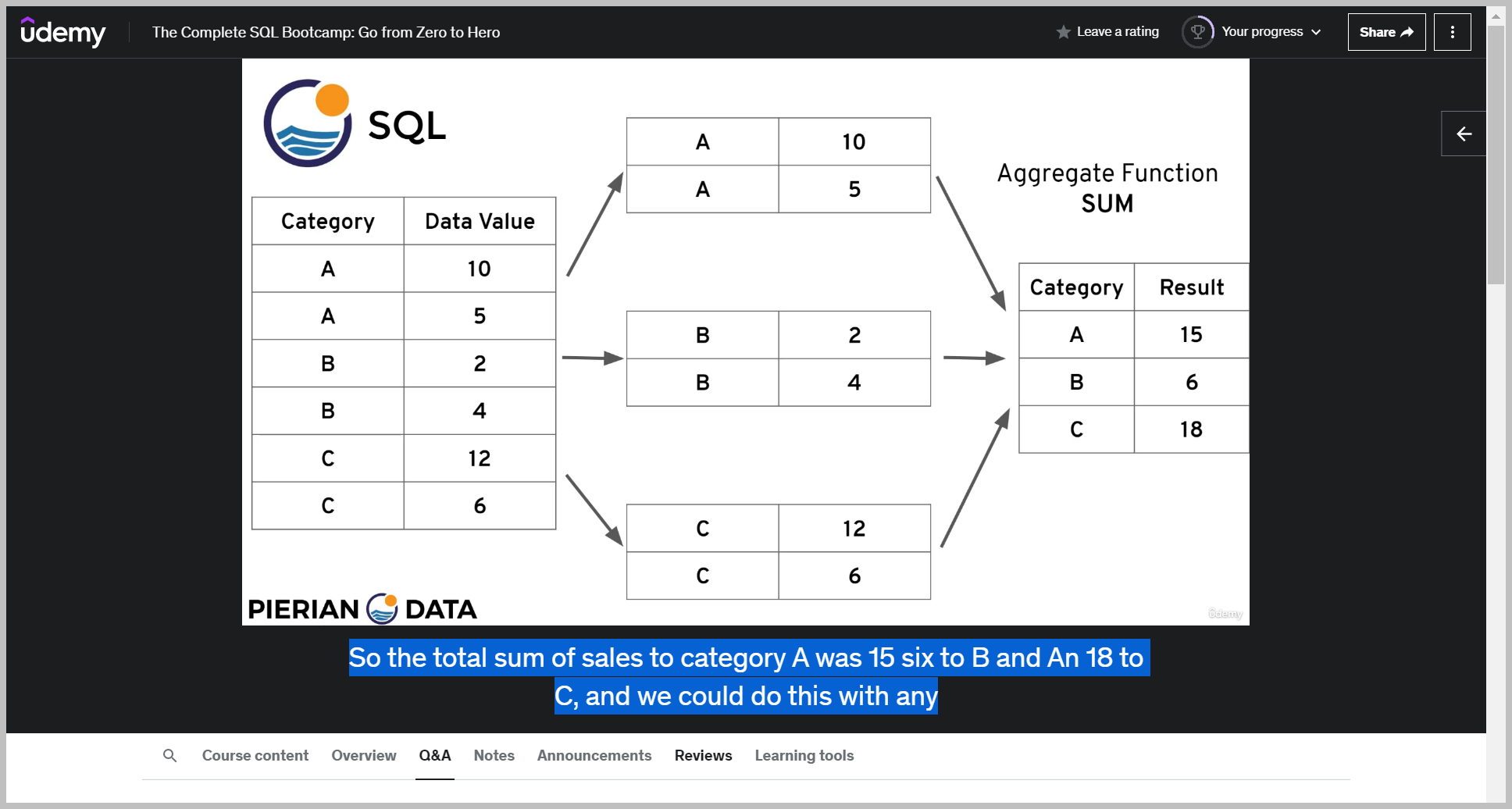
Recall that an aggregate function takes in multiple values and reduces them back down to one single value, such as the sum function can take in all these values per category or grouped by category and
GROUP BY2
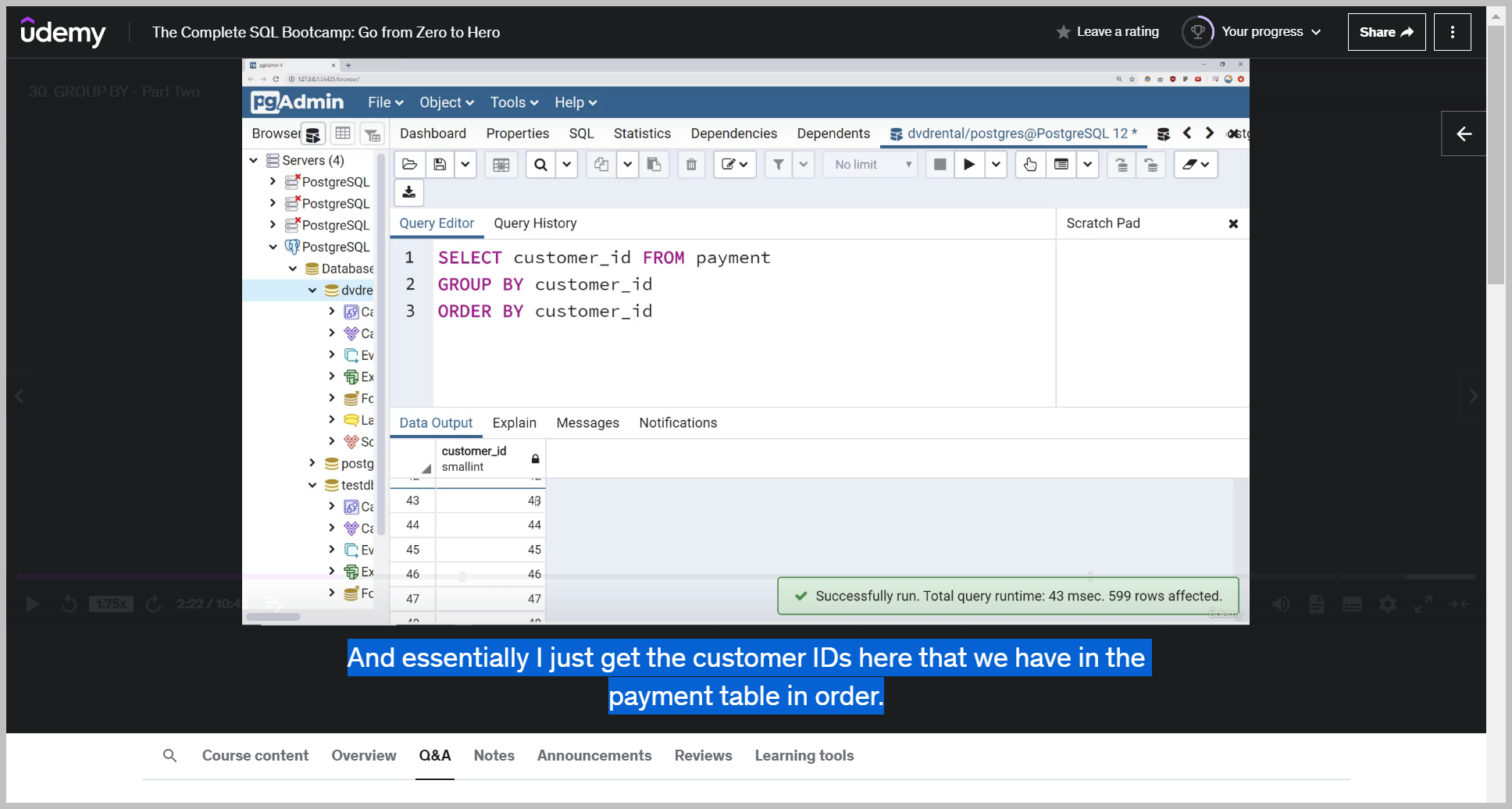
So if I run this, this is actually essentially the same thing as selecting the distinct customer IDs.
This is a bit of a roundabout way to go about it, but if you think what we're doing here, we're just kind of aggregating all the customer IDs together and we're not performing any aggregate functions on any other columns.
And essentially I just get the customer IDs here that we have in the payment table in order.
Question
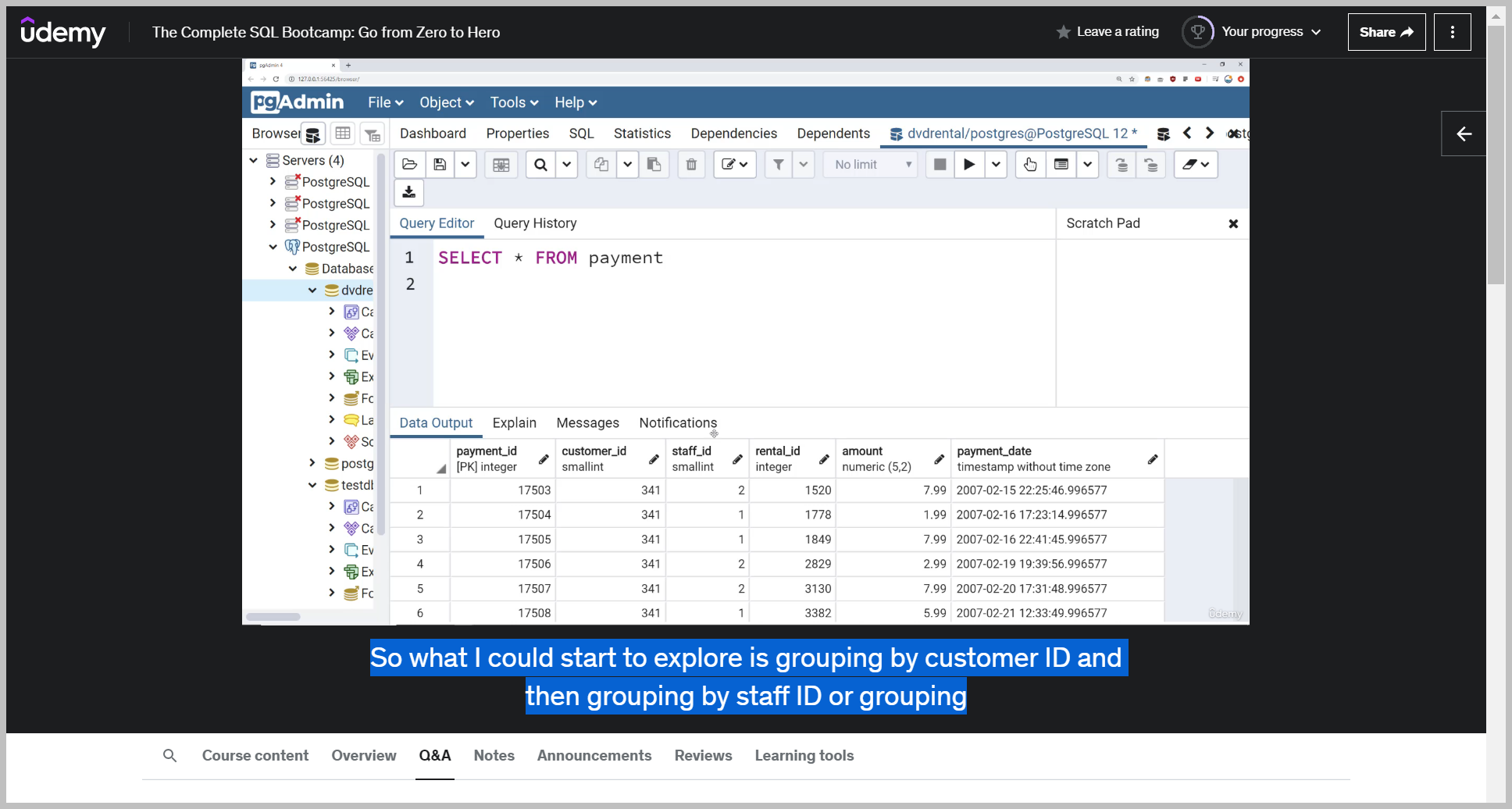
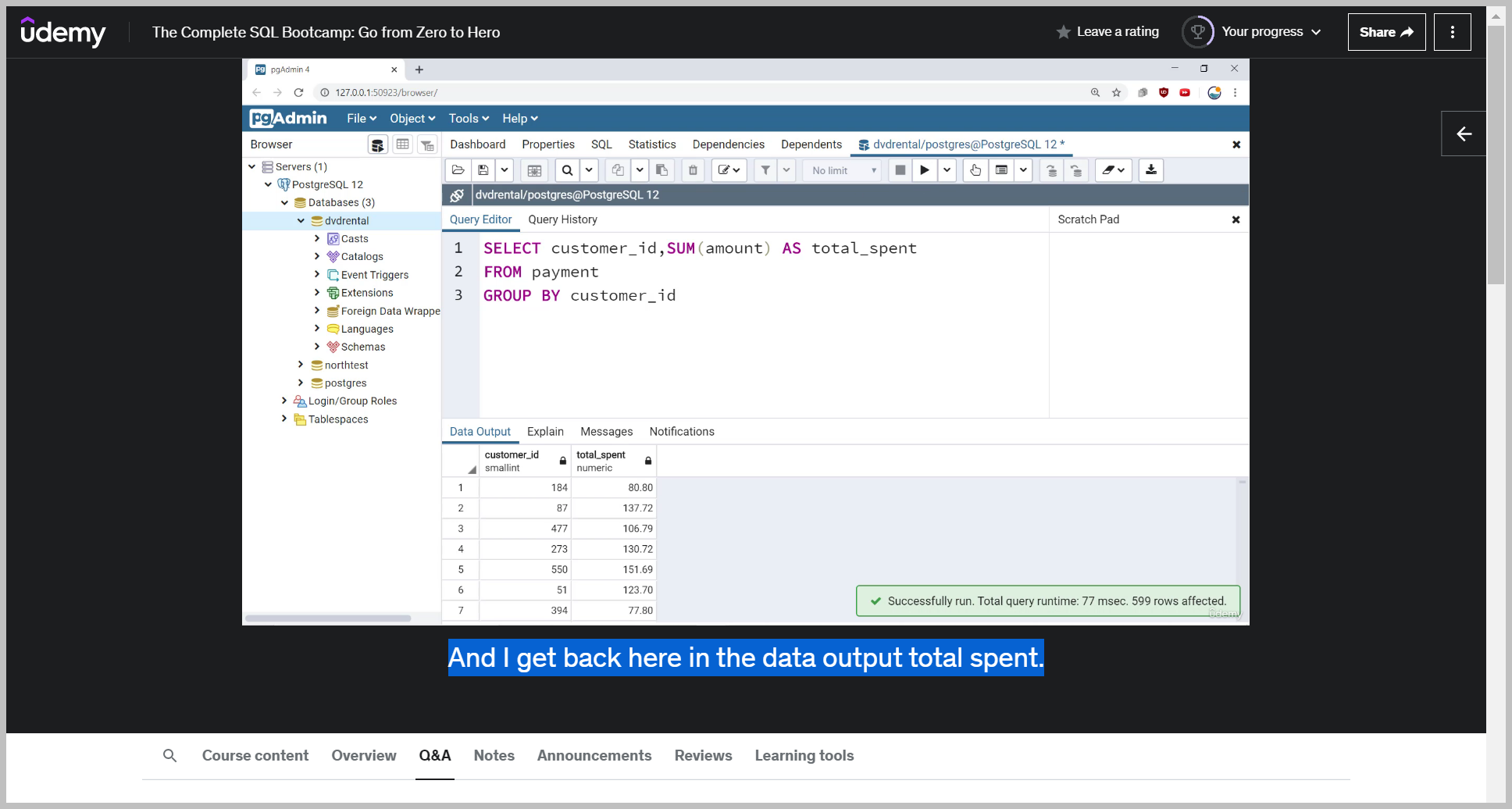
Let's imagine I wanted to answer the question What customer is spending the most money in total?
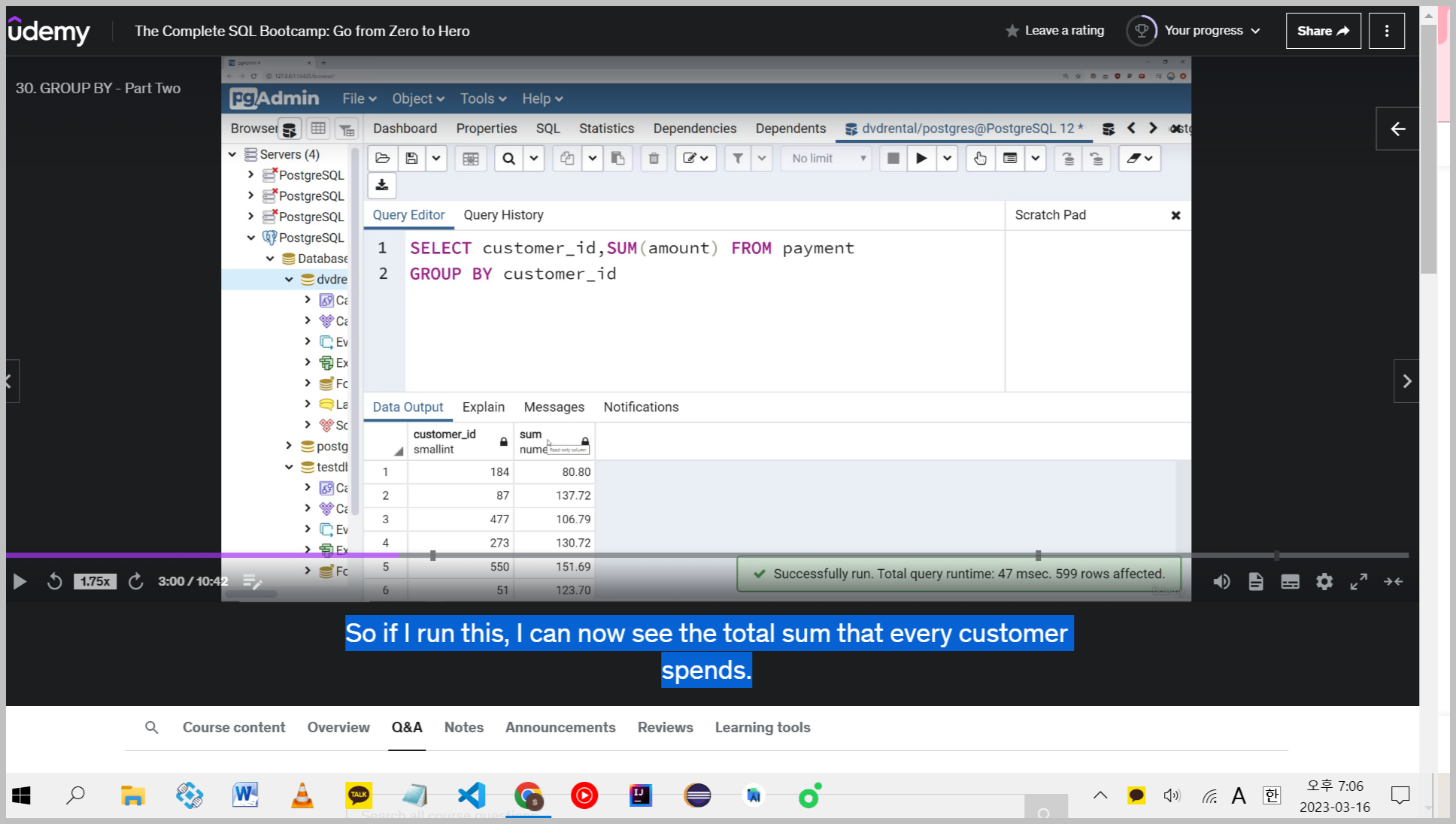
So if I run this, I can now see the total sum that every customer spends.
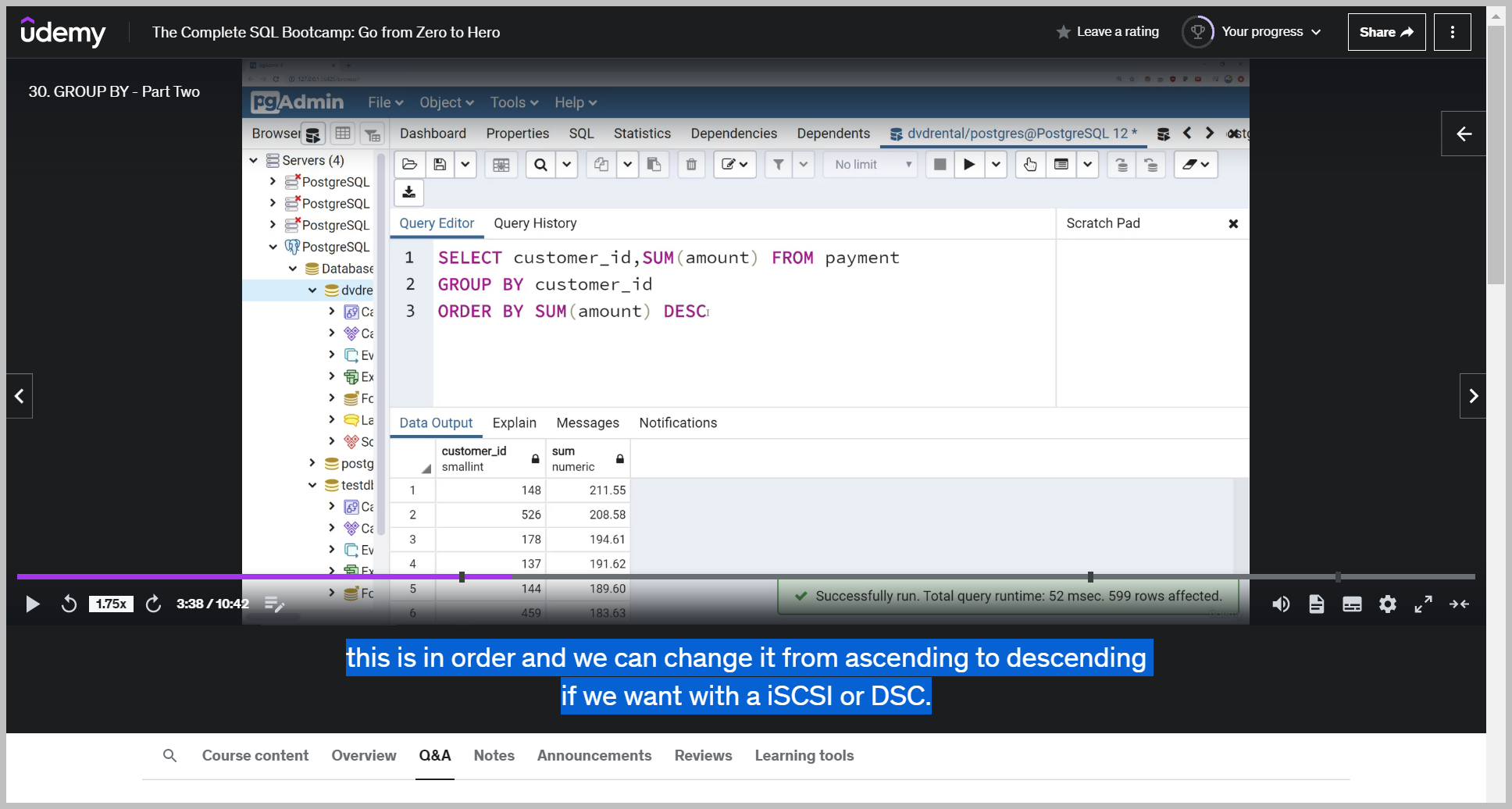
And then if I want to, to actually order this, I would say order by And I can't just say order by amount.
I have to say order by the sum amount, since that is truly what this column is It's not just the amount column, it's the total sum of the amount column per customer ID and a lot of times the word per.
예제2
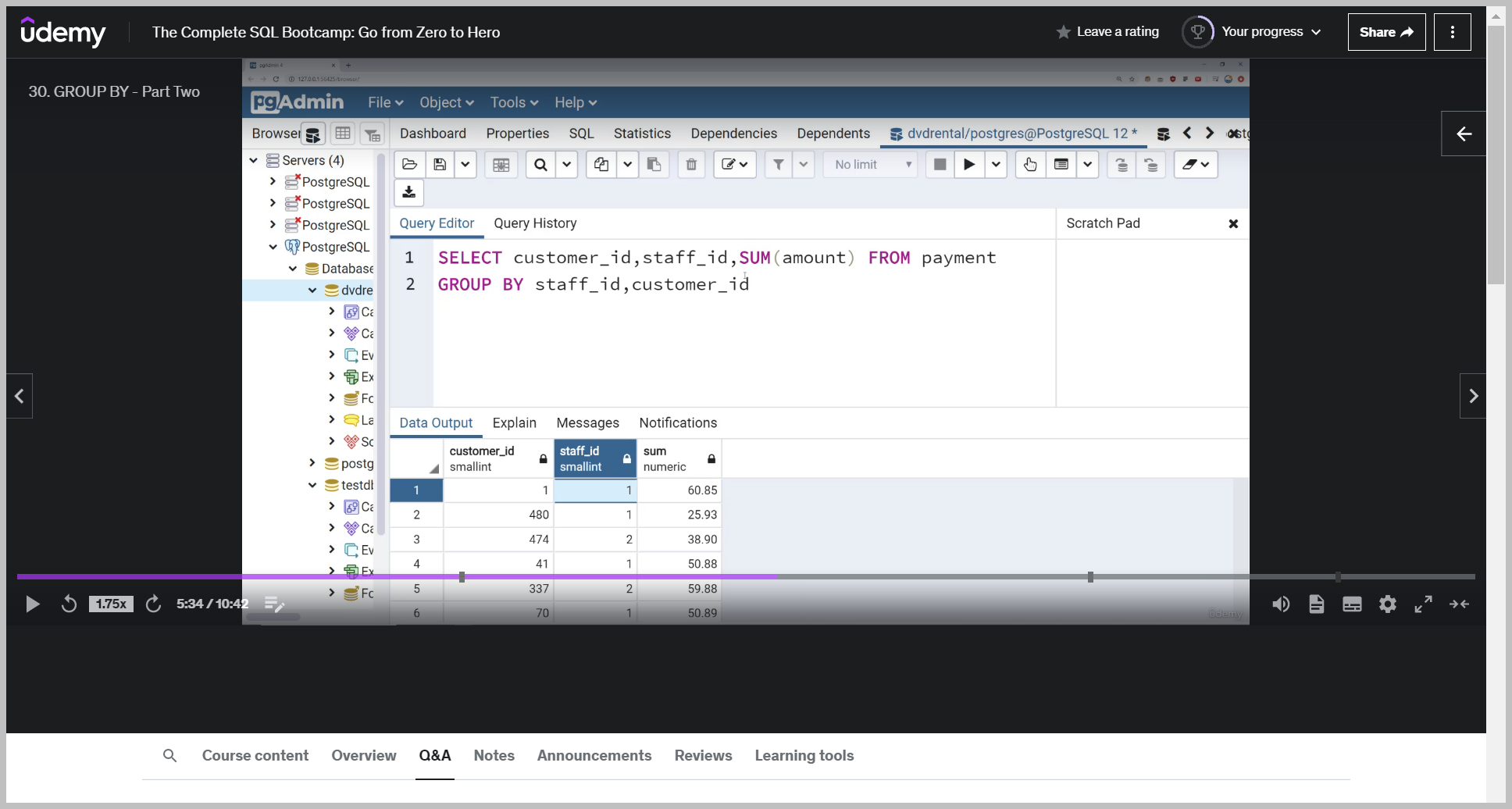
So what I could start to explore is grouping by customer ID and then grouping by staff ID or grouping by staff ID and then grouping by customer ID.
So if I just run this, what's happening here is it's telling me the total amount spent per staff Per customer.
So that means customer number one spends $60.85 with the staff ID person number one.
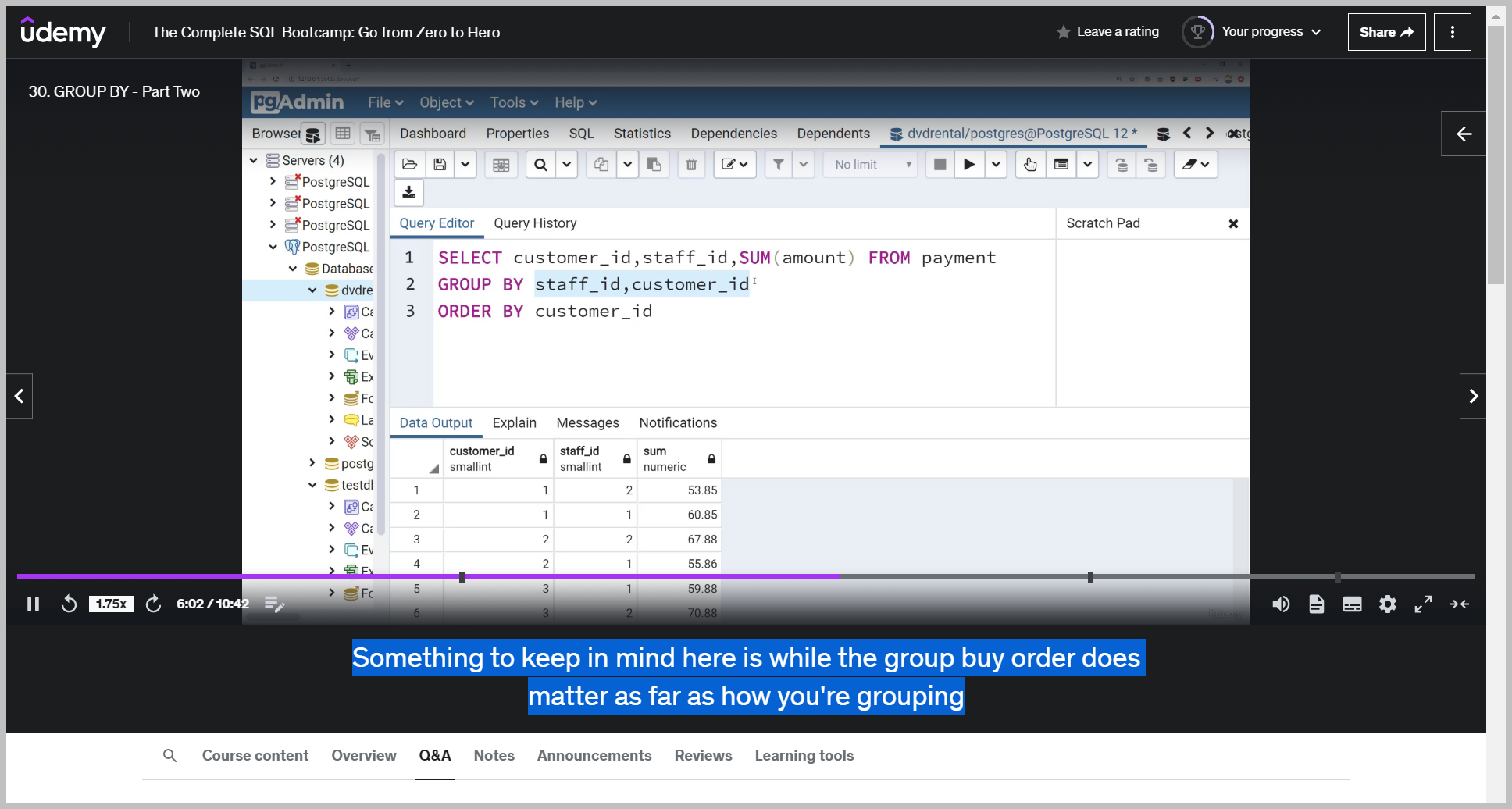
And what I could do if I wanted to is order by The customer ID.
So when I run this, I can now essentially see how much each customer spent with each staff member.
So in this case, it looks like customer one spent $60.95 with staff ID number one and then $53.85 with Something to keep in mind here is while the group buy order does matter as far as how you're grouping things together, the actual select statement, that order doesn't really matter.
예제3 (타임스템프)
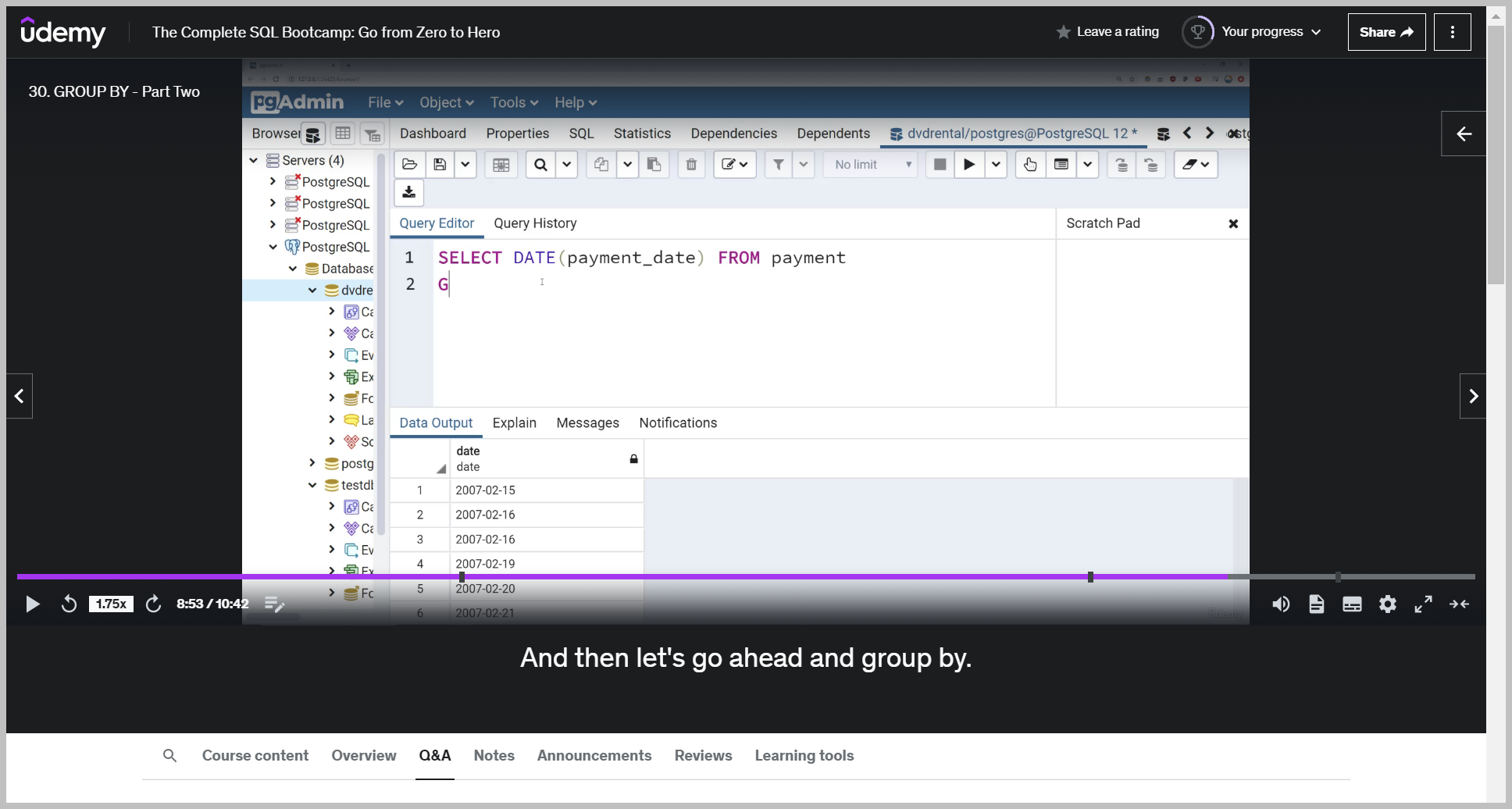
So if we actually want to perform a group by a date, we have to call a specialized date function to convert the timestamp to a date, and then we can actually group by that.
It's removed that timestamp information, which makes sense because we don't want to group by every single transaction per minute.
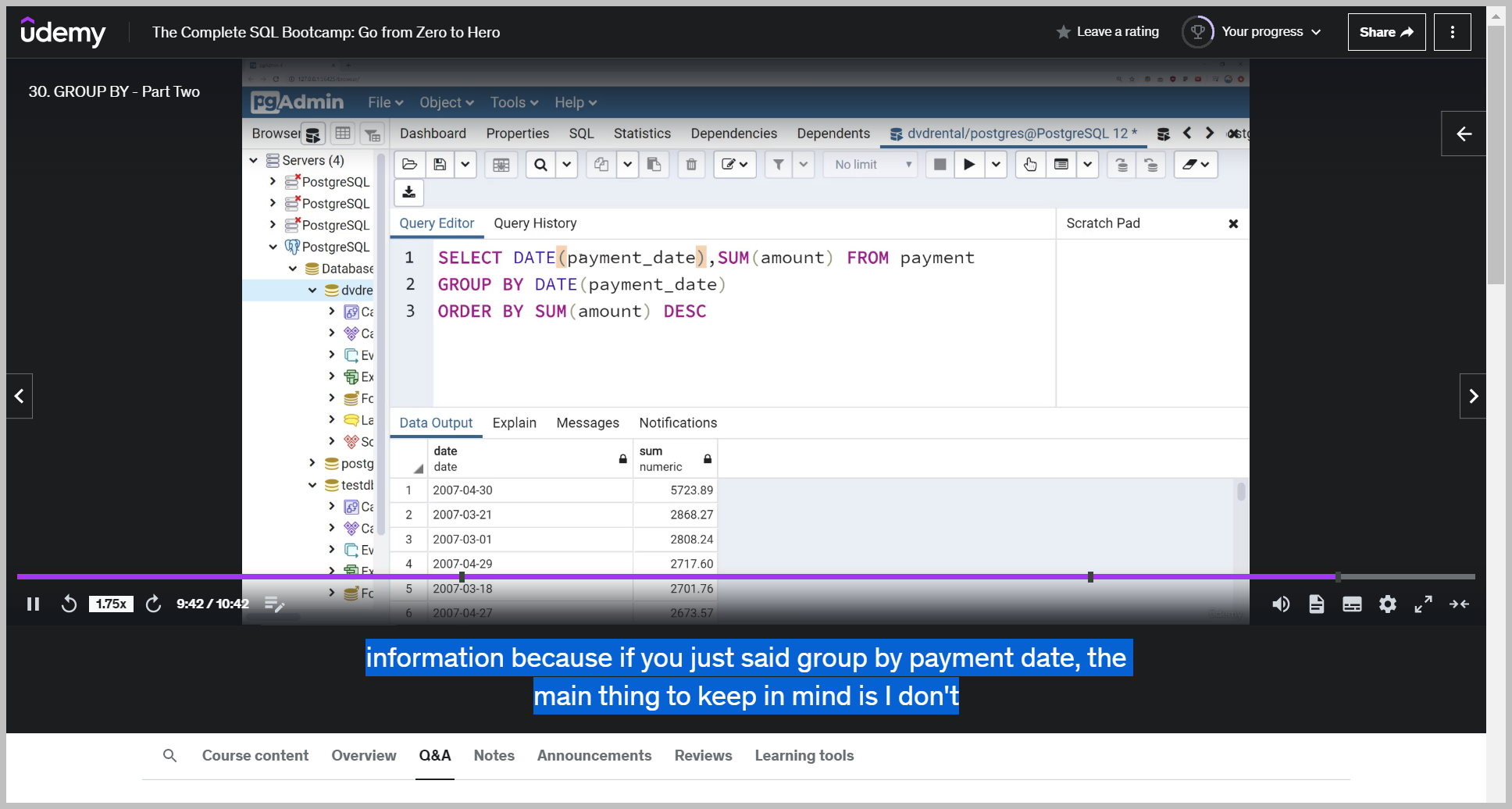
And I can see the days where we're having the least amount in total dollar transactions, or depending how I sort this, if I sort it in descending order, I can see the dates that we're having the most in dollar transactions.
TEST
질문
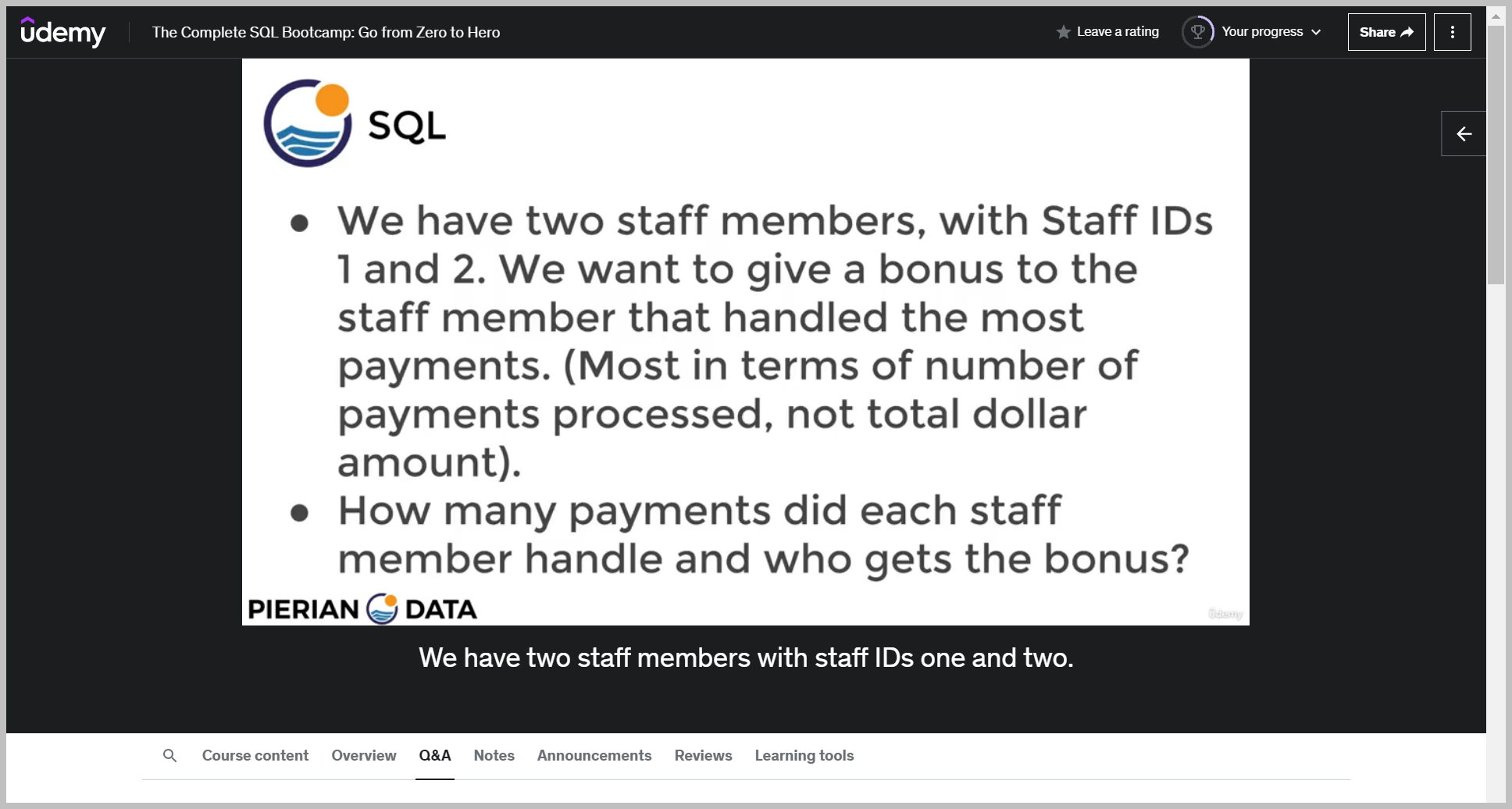
So how many payments did each staff member handle and who gets the bonus?
기대값
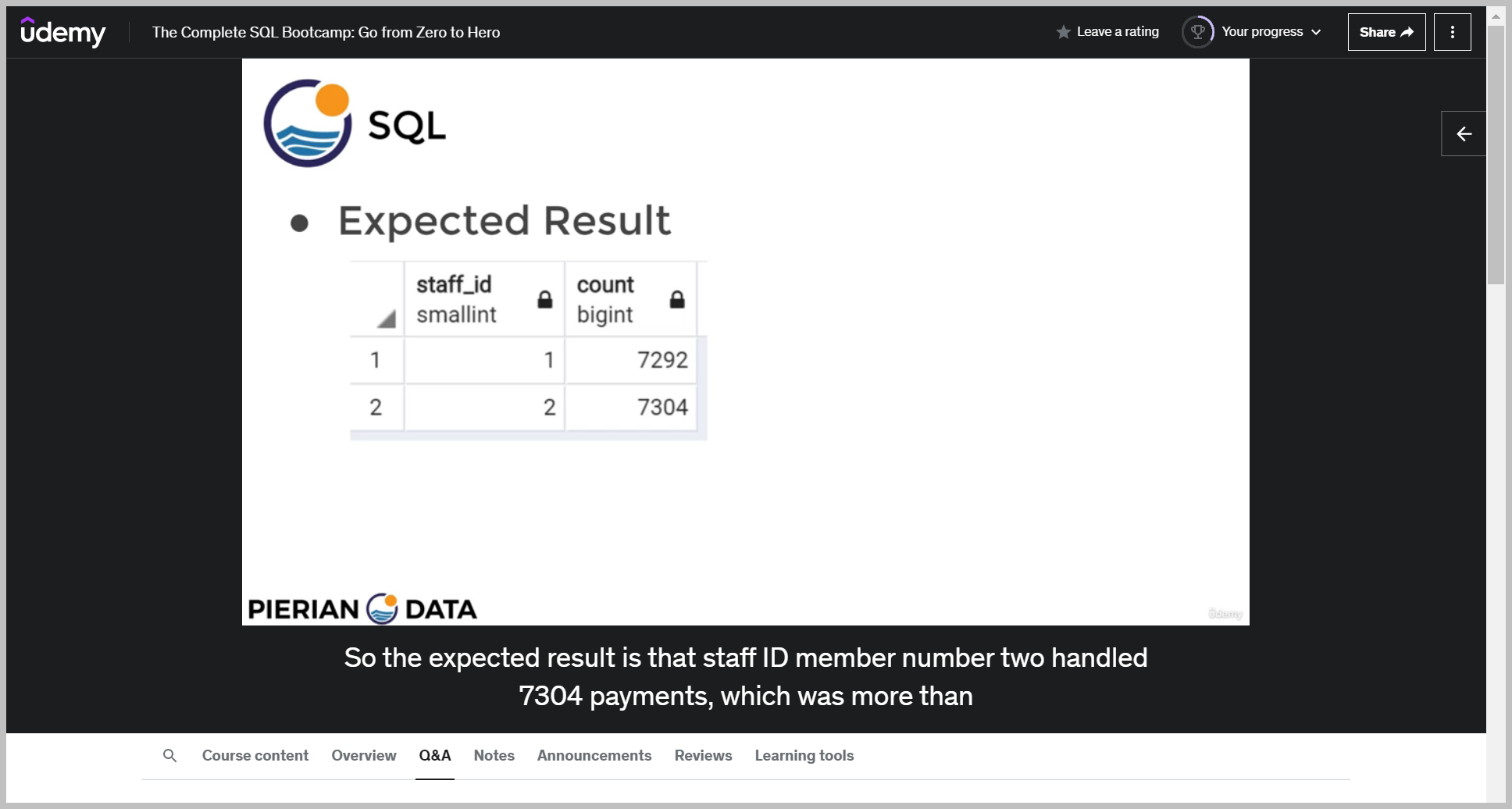
힌트
솔루션
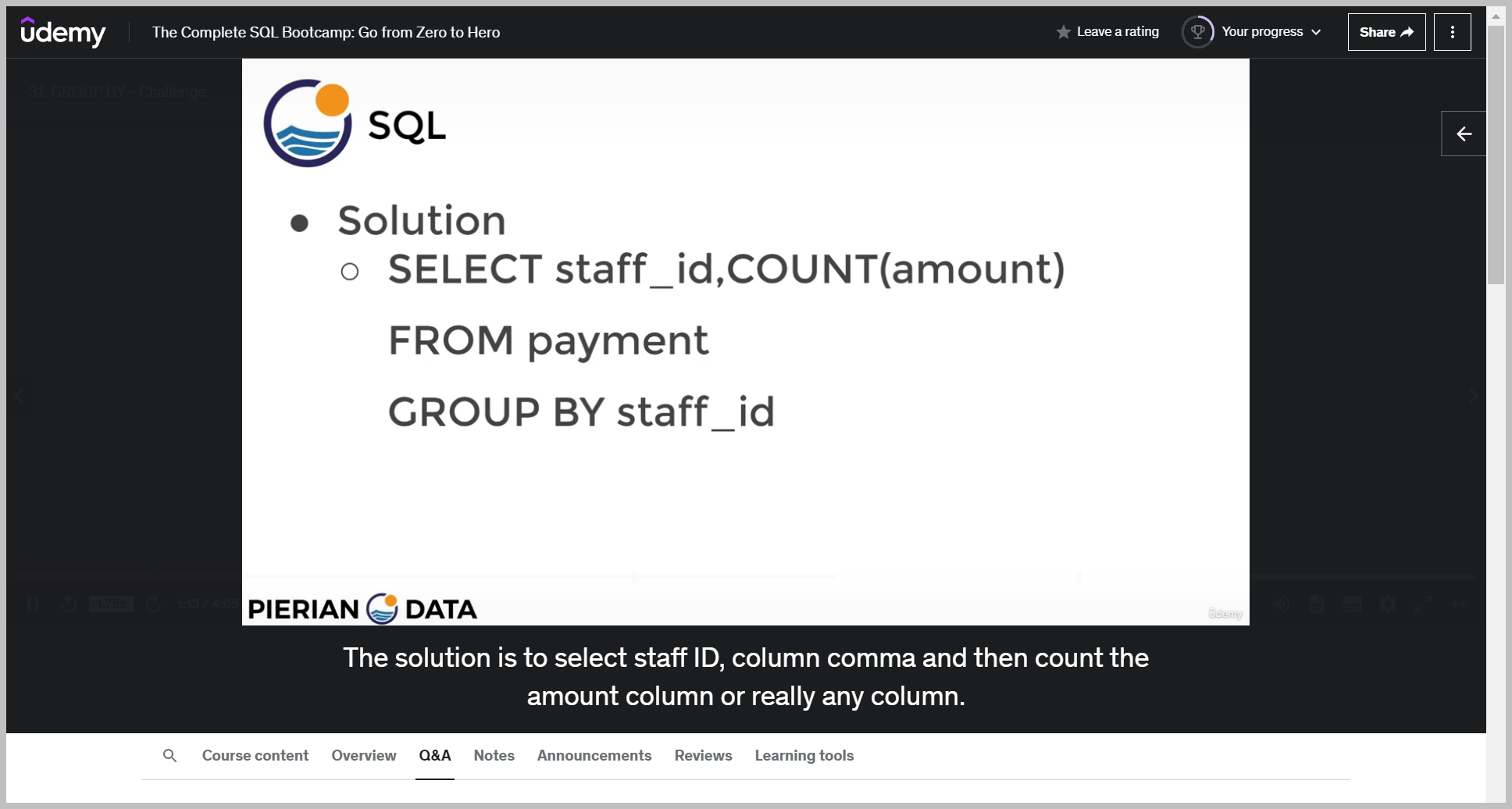
The solution is to select staff ID, column comma and then count the amount column or really any column.
And then we'll say from the payment table group by staff ID and as I mentioned, you can technically
TEST2
질문

기대값
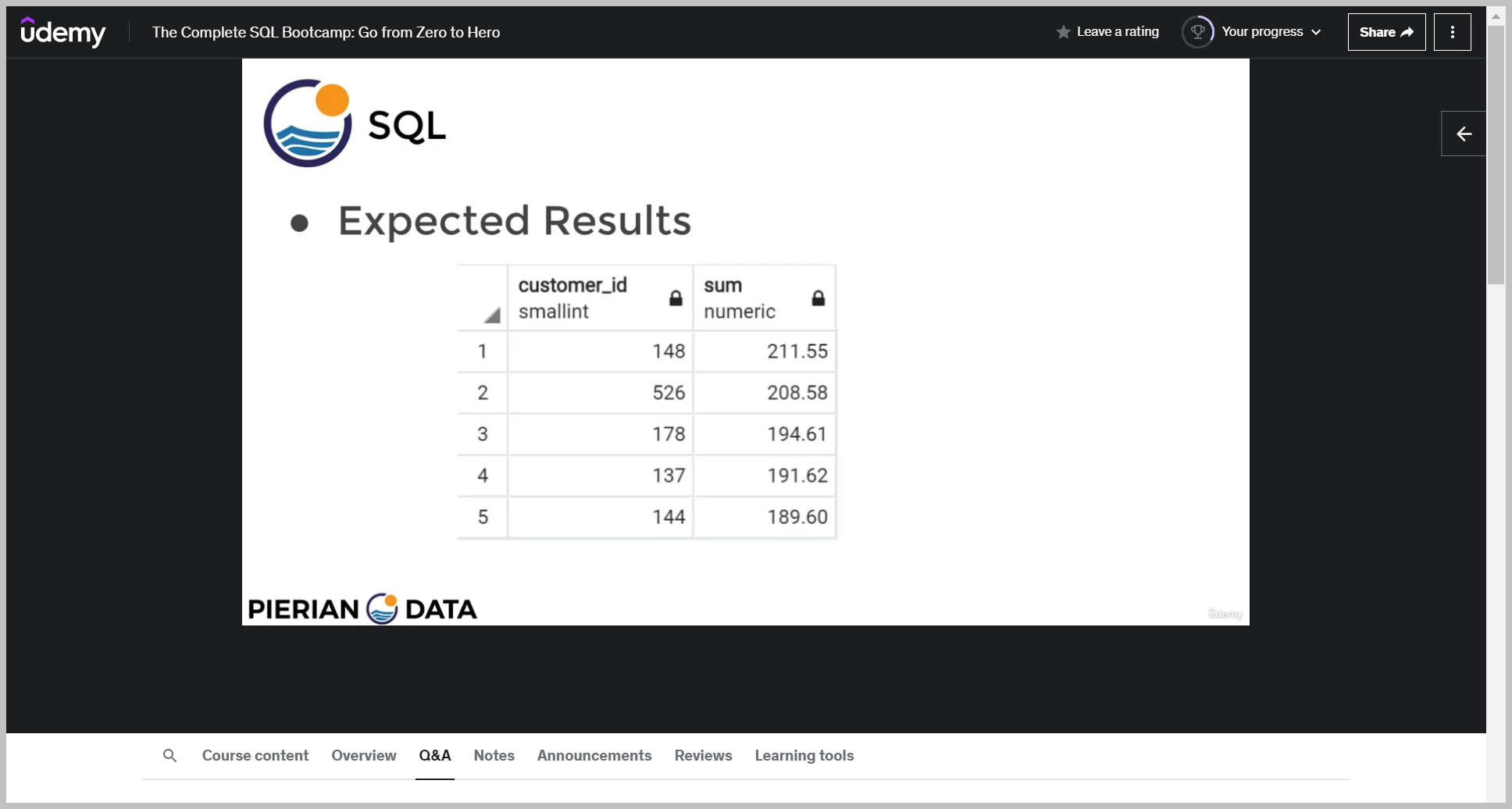
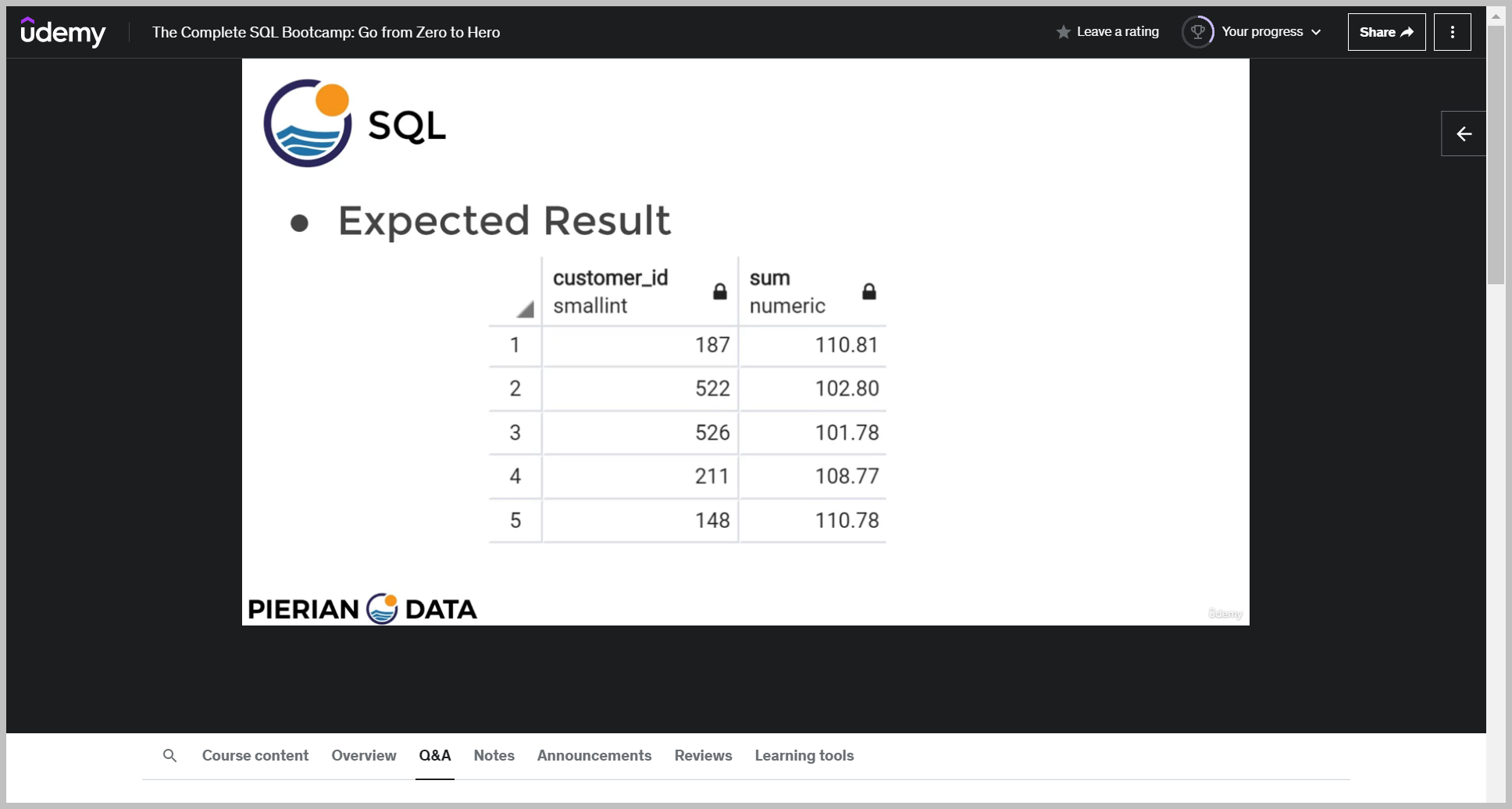
So the expected results are these five customer IDs and here are their total amount expenditures.
힌트
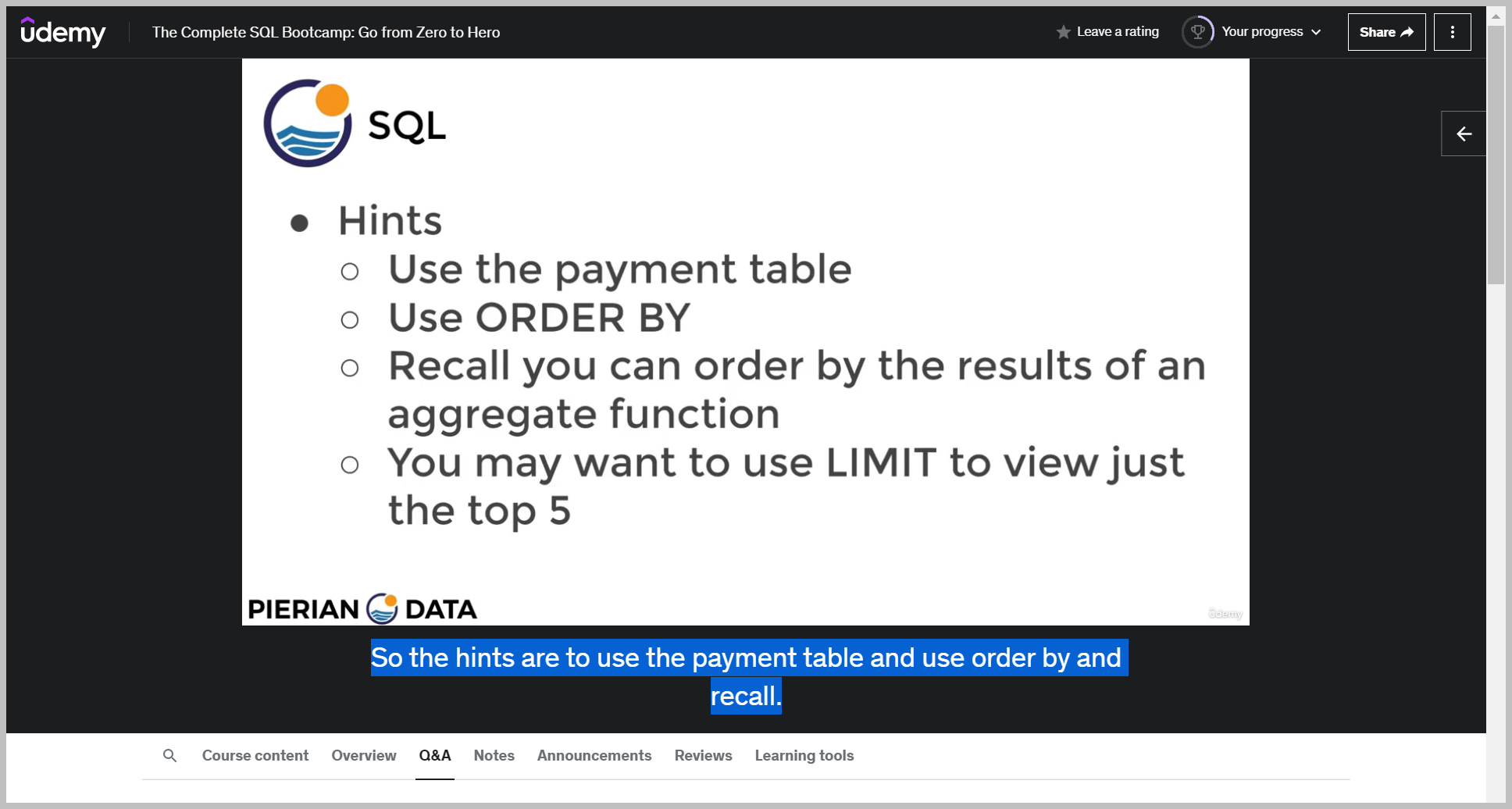
솔루션
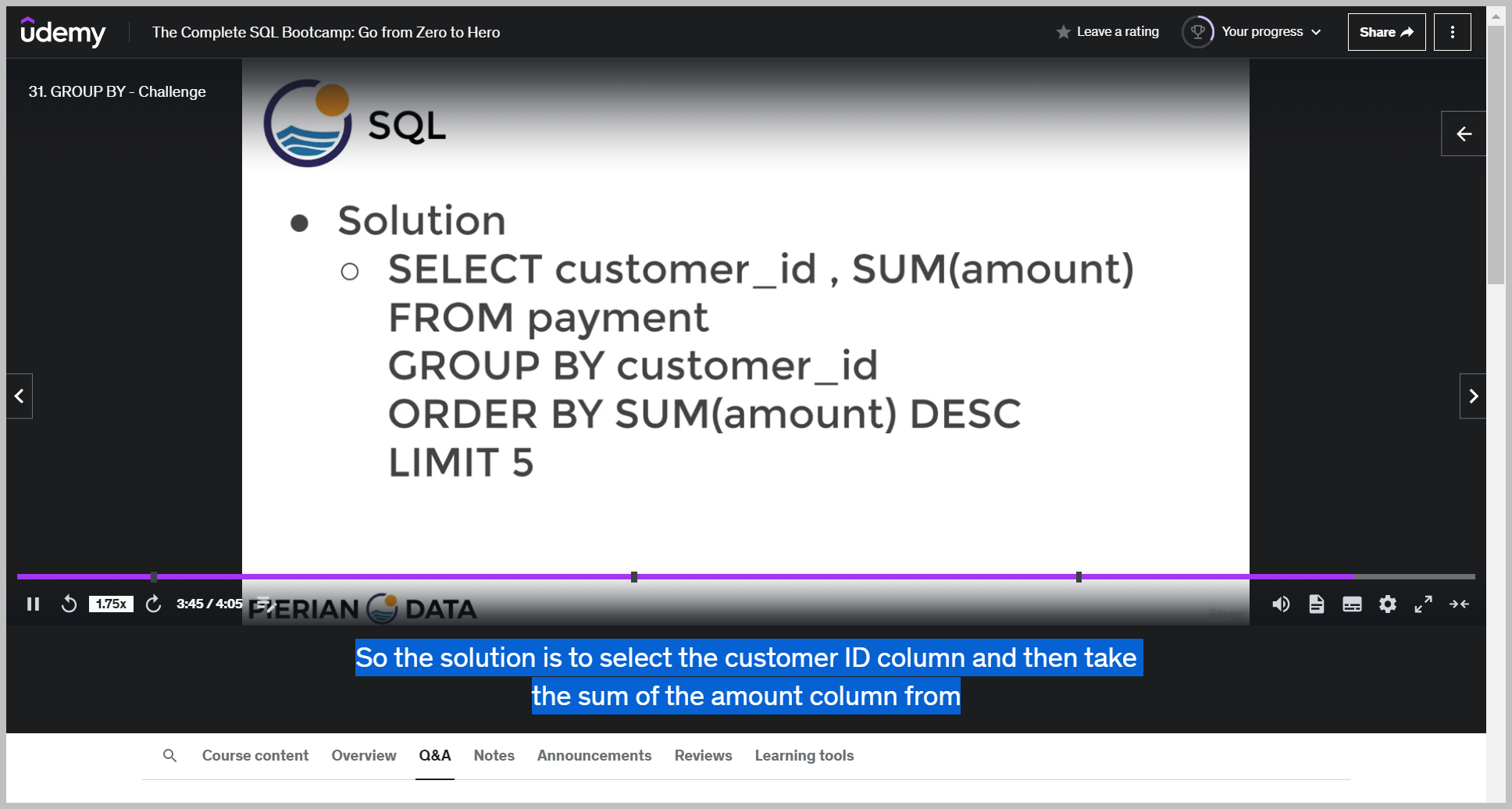
So the solution is to select the customer ID column and then take the sum of the amount column from the payment table group by the customer ID and then order by some amount in descending order So we also added limit five.
HAVING 구문
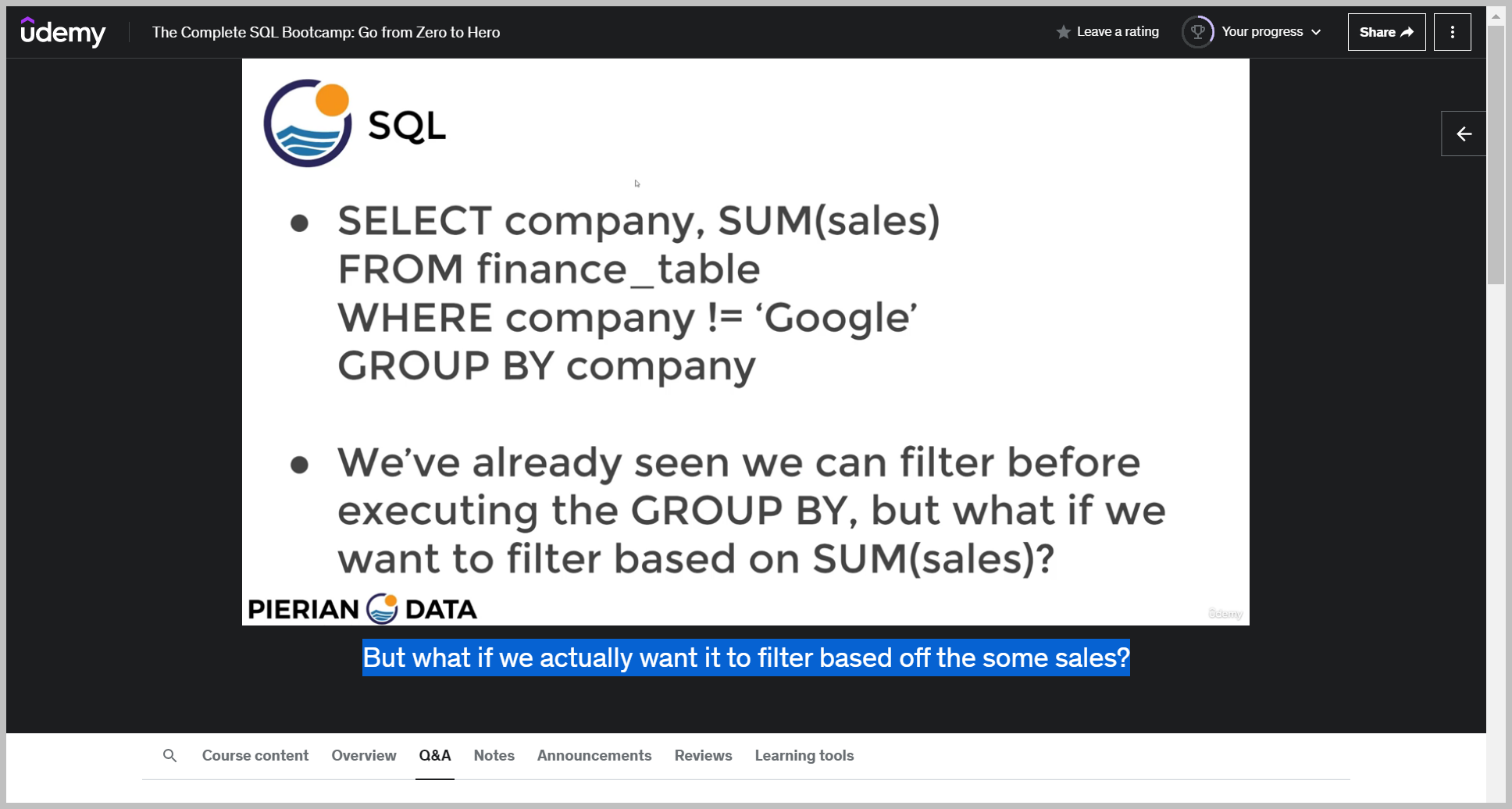
The having clause allows us to filter after an aggregation has already taken place So it comes after a group buy call.
But what if we actually want it to filter based off the some sales?
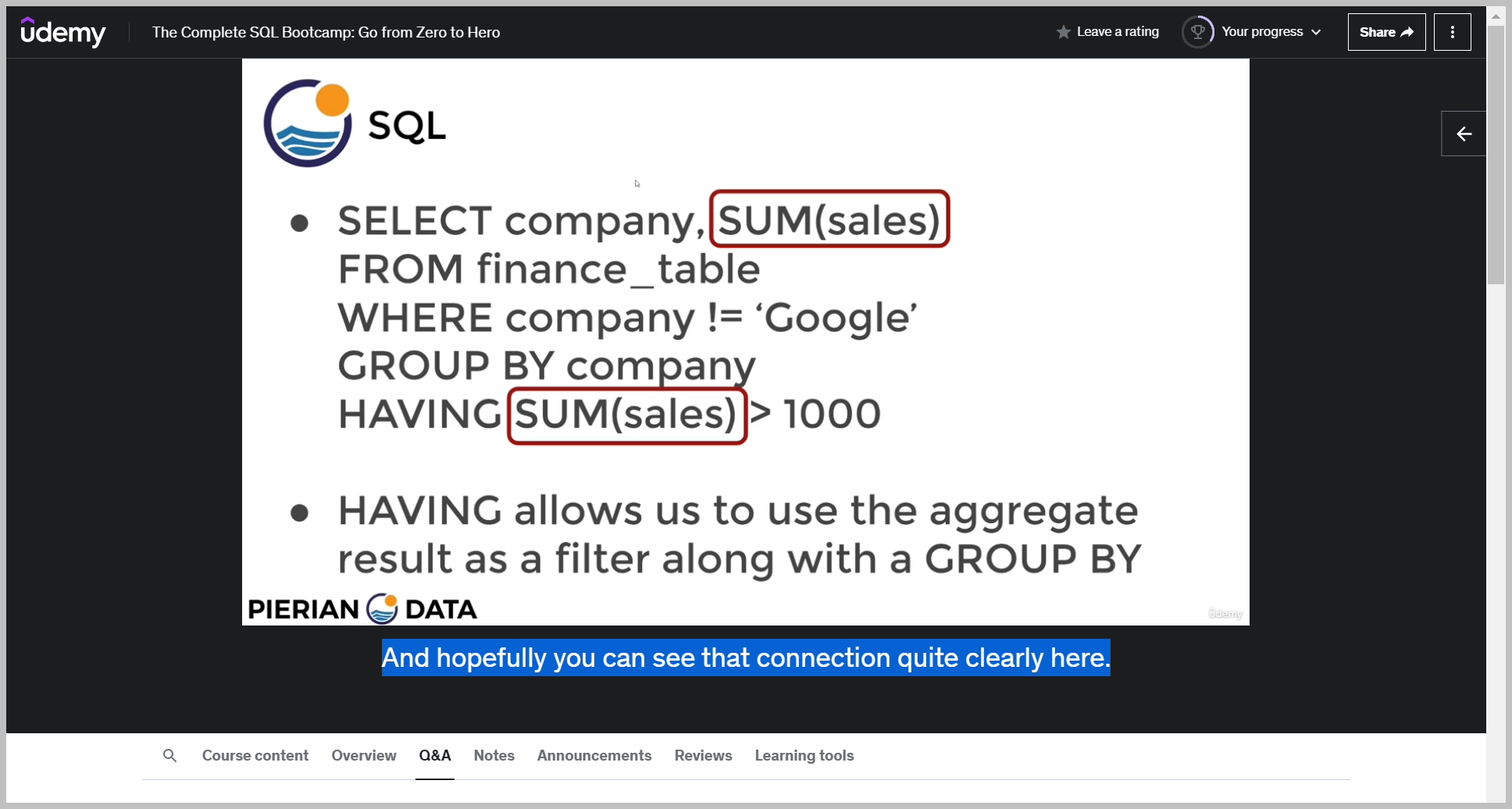
So keep in mind that since we're calling some on sales, that's not going to happen until after that group buy statement is executed all the way at the bottom, which means we cannot use where to filter based off aggregate results because those happen after the actual where statement is executed.
So if after performing the group buy and calculating the sum of sales per company, I want it to then perform an additional filter on that result based off the sum of sales.
I could add the having clause, so having allows us to use the aggregate result as a filter along with a group by.
So again, here, I'm able to now filter based off the aggregate result of some of sales in my having clause.
So here I'm saying do the filter of the wear and then after you group buy, go ahead and do another filtering where we're having the sum of sales greater than some number like 1000 dollars.
예제1
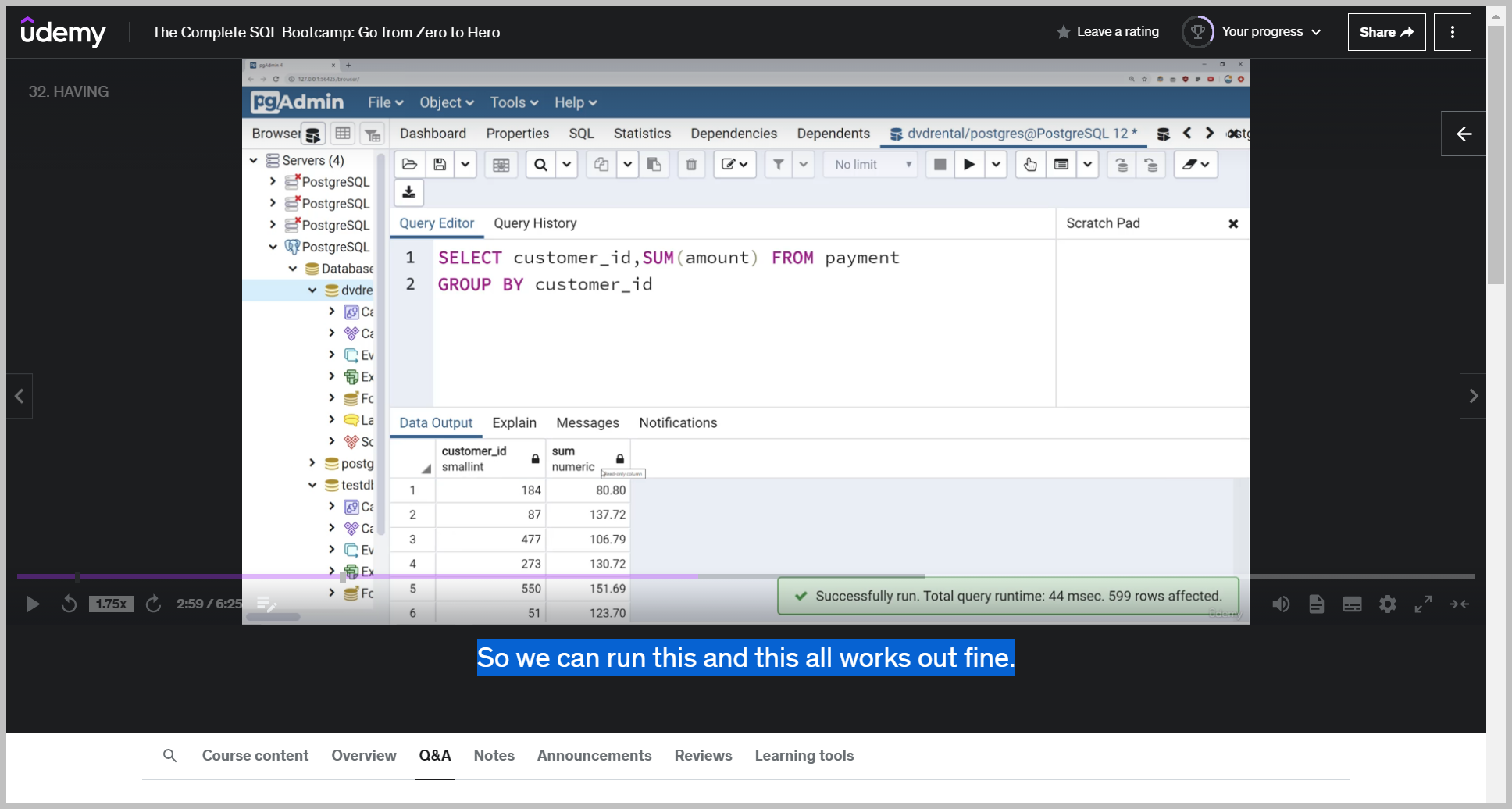
Let's go ahead and take the total sum amounts for a customer.
So we'll say select the customer ID.
And then take the sum amount from payments and we will group this by customer ID. And then take the sum amount from payments and we will group this by customer ID.
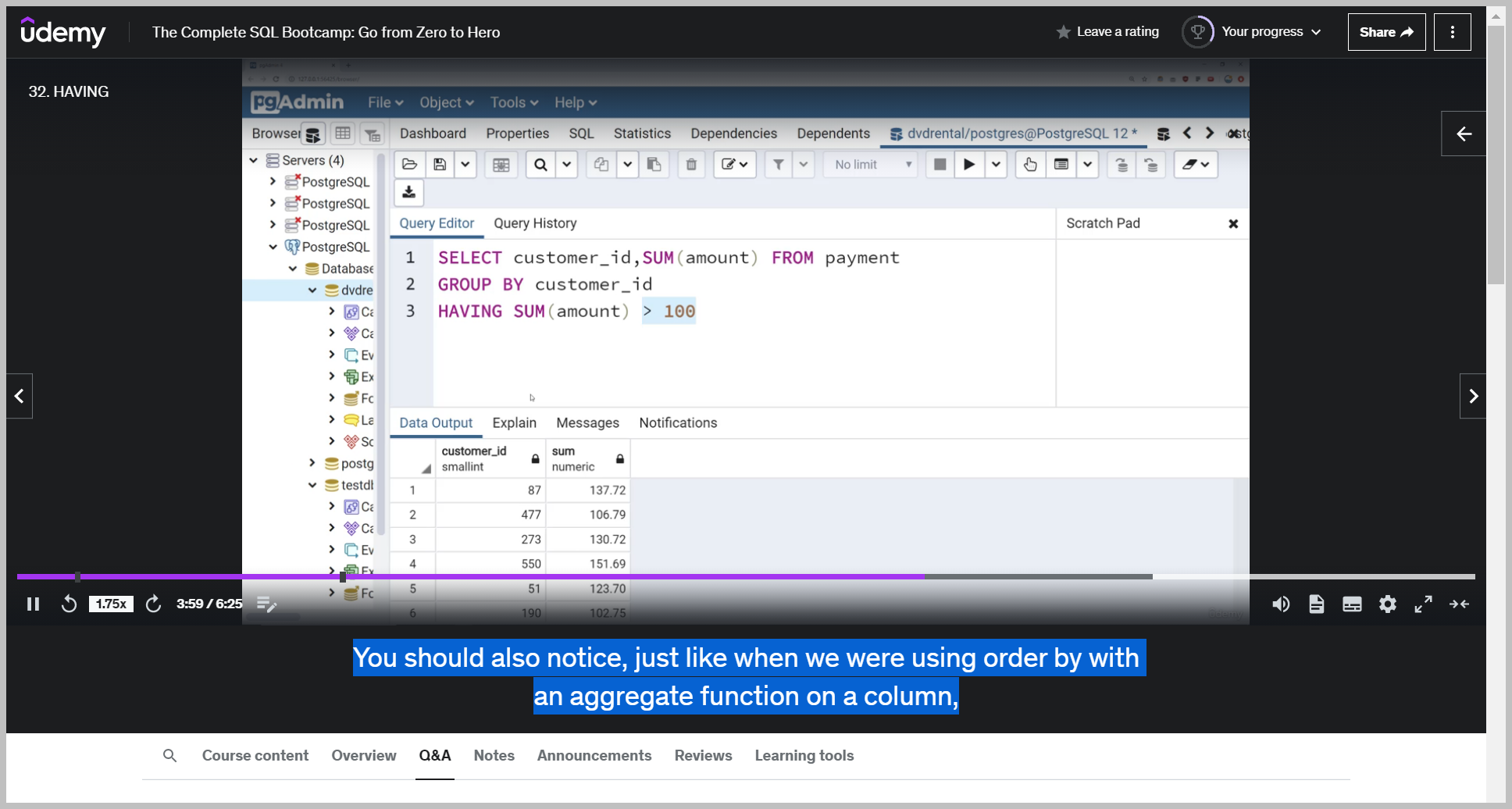
Now, what I cannot do is filter with a wear statement on some amounts because the sum of the amounts not going to happen until after I call the group by. So what I'm going to do then let's go to remove this where example to simplify things.
After the group by having. Some amounts and let's just say greater than 100.
And now you'll notice everything's been filtered, so all the sums are now greater than 100.
예제2
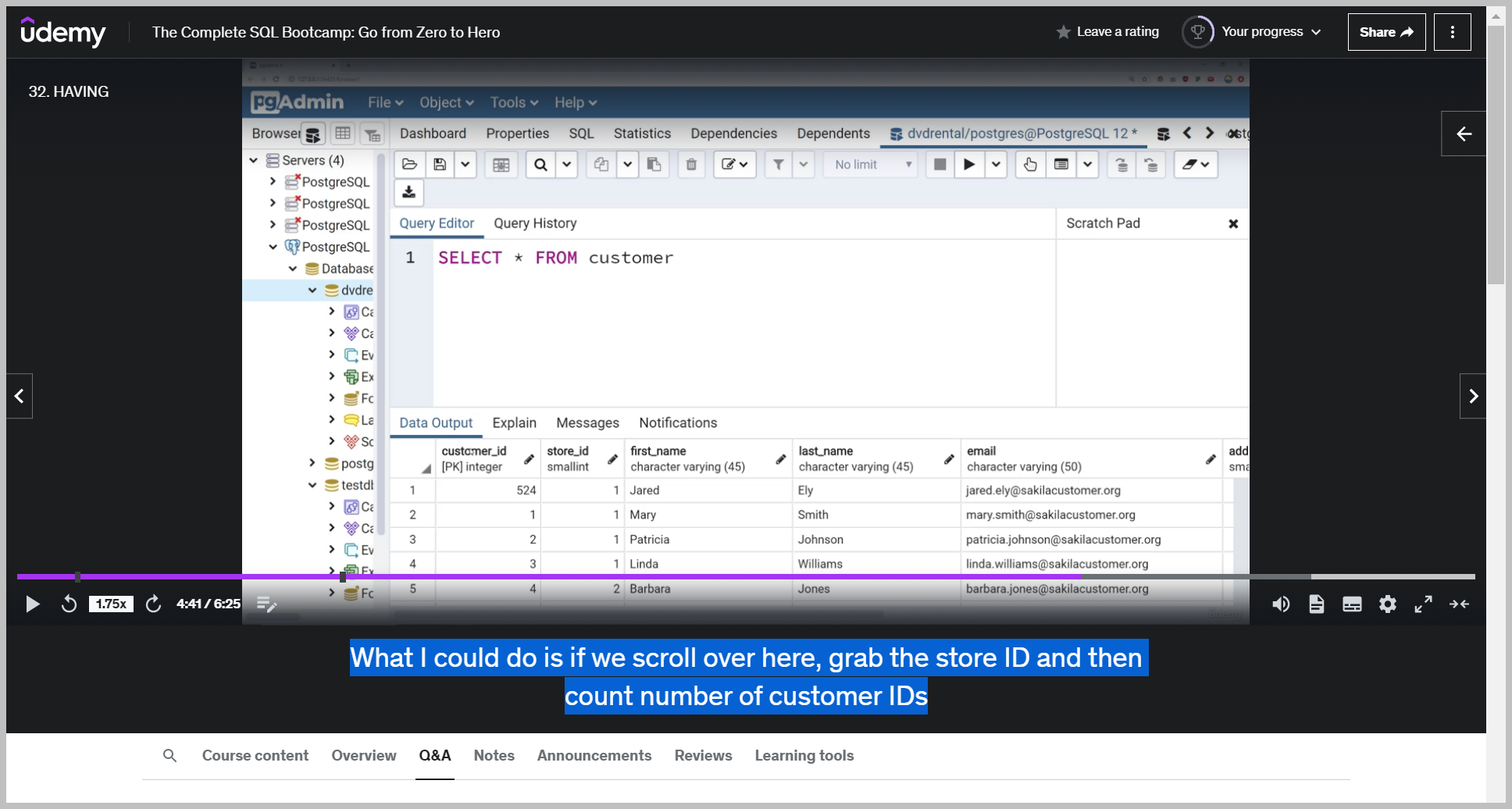
So what we can do here is let's imagine we wanted to know the number of customers per store.
What I could do is if we scroll over here, grab the store ID and then count number of customer IDs associative them after I group buy store ID.
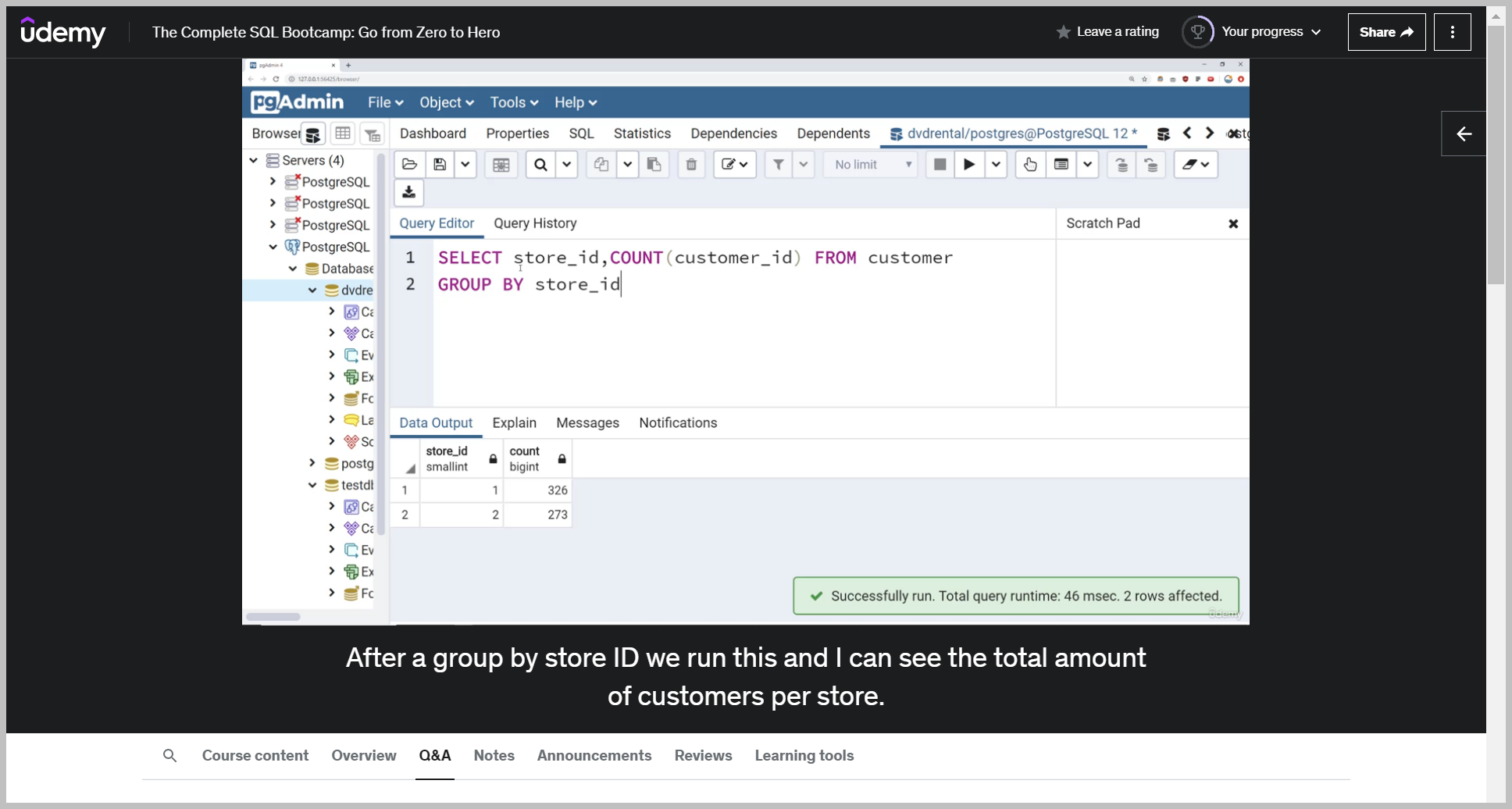
After a group by store ID we run this and I can see the total amount of customers per store.
Keep in mind I don't have to actually pass on customer ID because this is just saying how many rows are there per store ID.
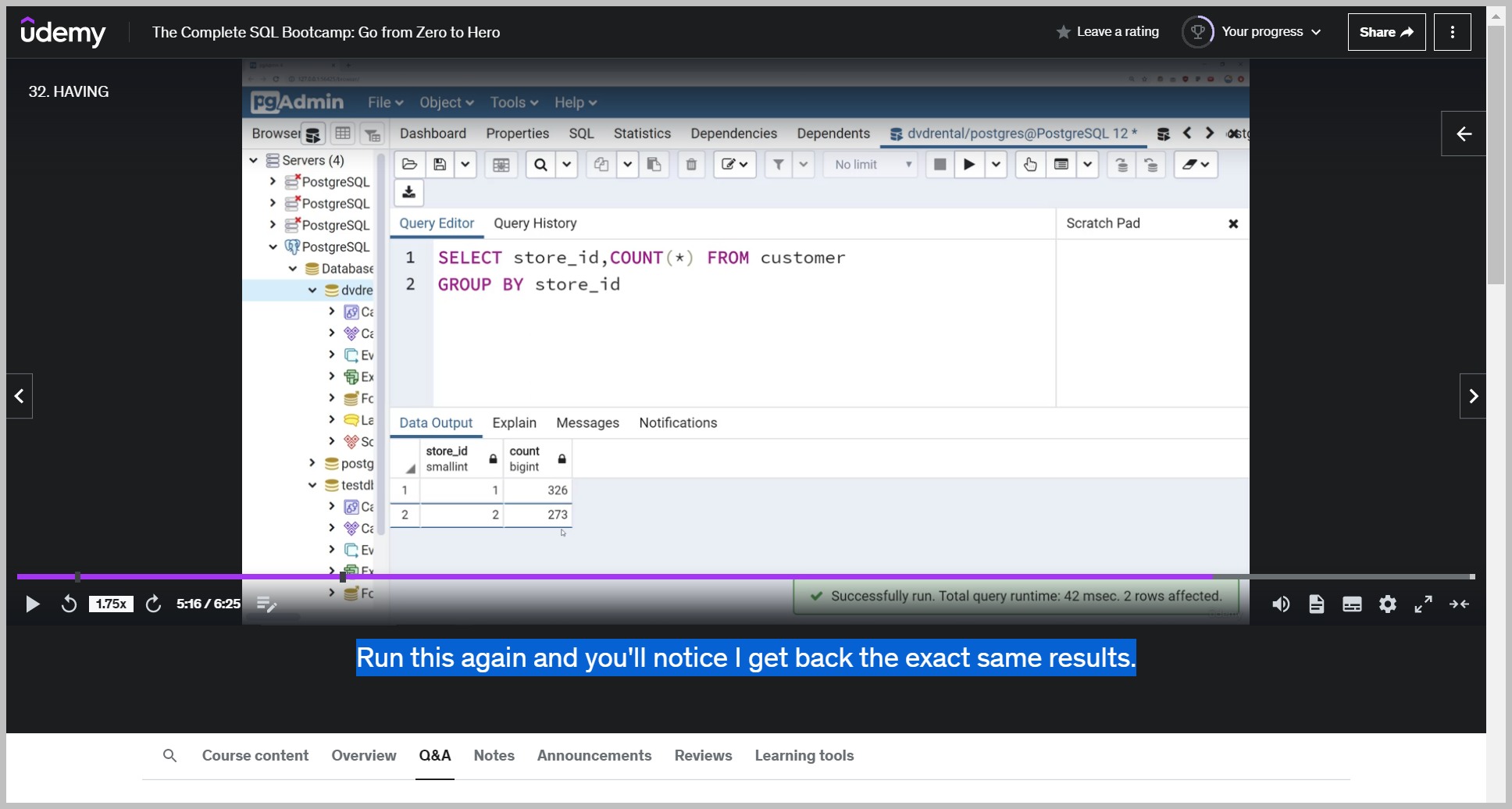
Run this again and you'll notice I get back the exact same results.
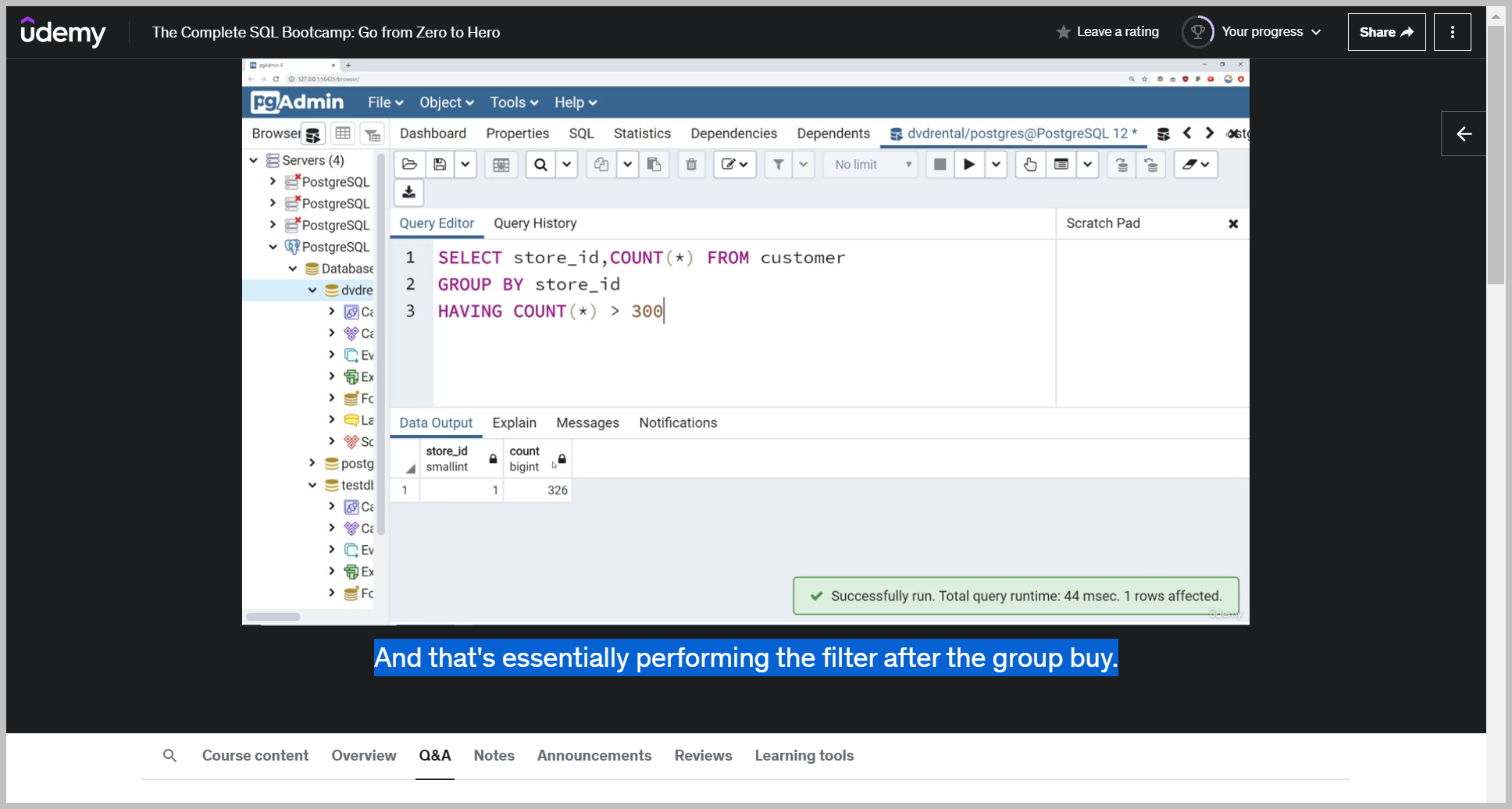
Now let's imagine I wanted to select only stores that had more than 300 customers.
Well, in this case, I'd have to filter based off something that's already been aggregated.
So I can't do that where.
But I can do it with having.
And that's essentially performing the filter after the group buy.
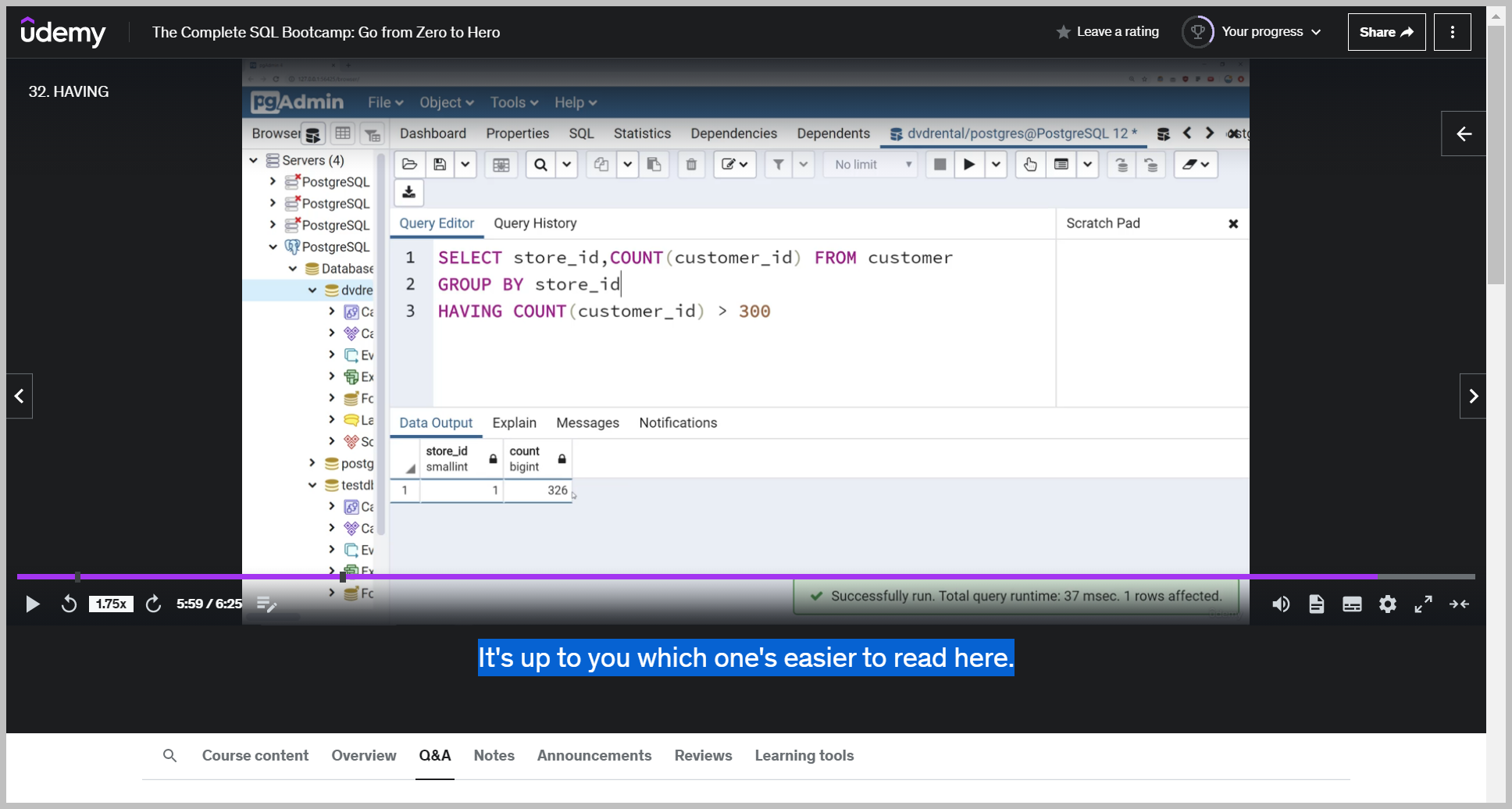
And keep in mind, depending on how you want to think about this, you can switch out. An asterisk(*) there for customer ID and it'll perform the exact same. It's up to you which one's easier to read here.
TEST
질문
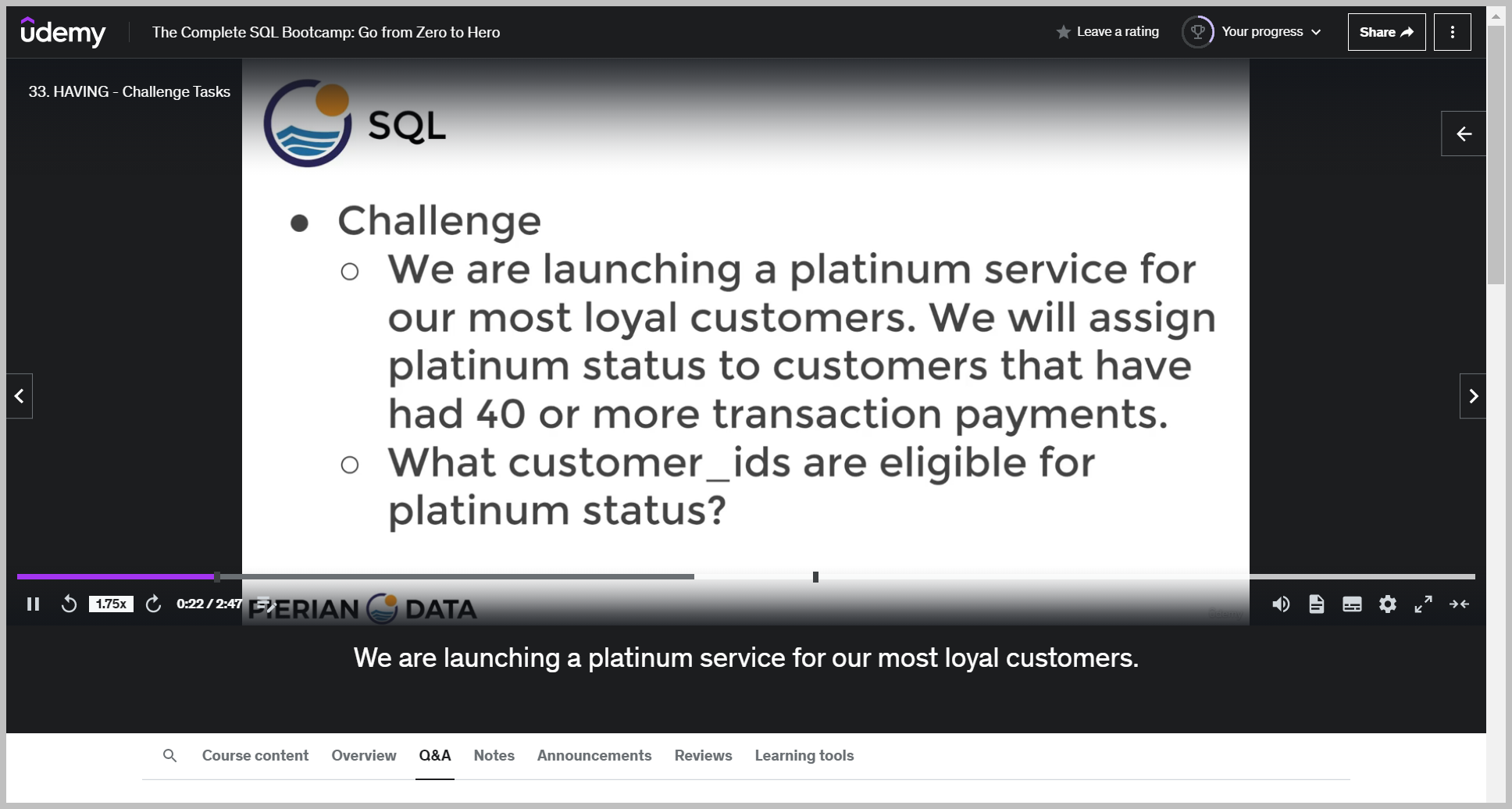
기대값
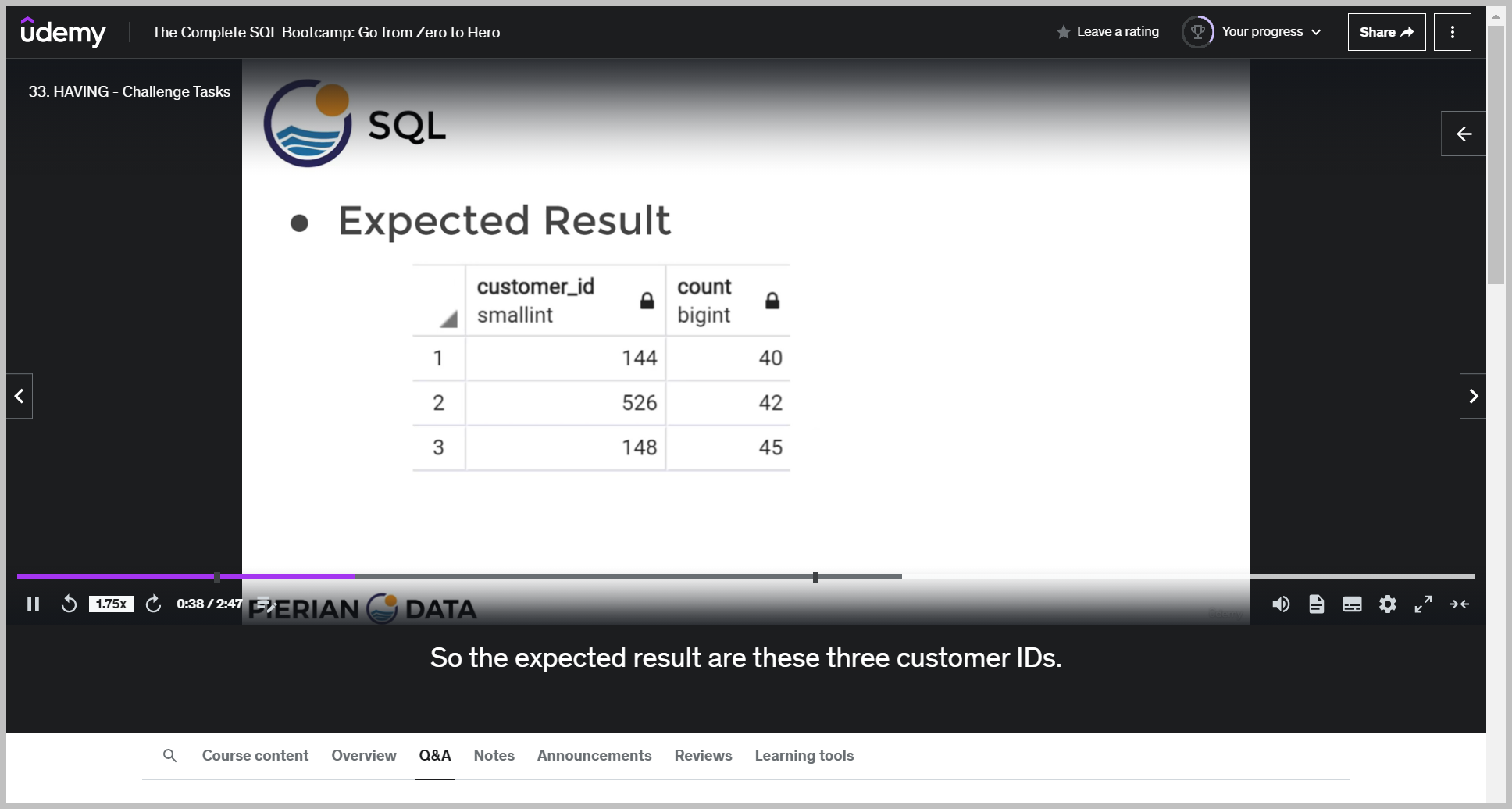
And if you want, you can also show how many transactions they had. We can see here that there's three people that have had 40 or more transactions.
힌트
솔루션
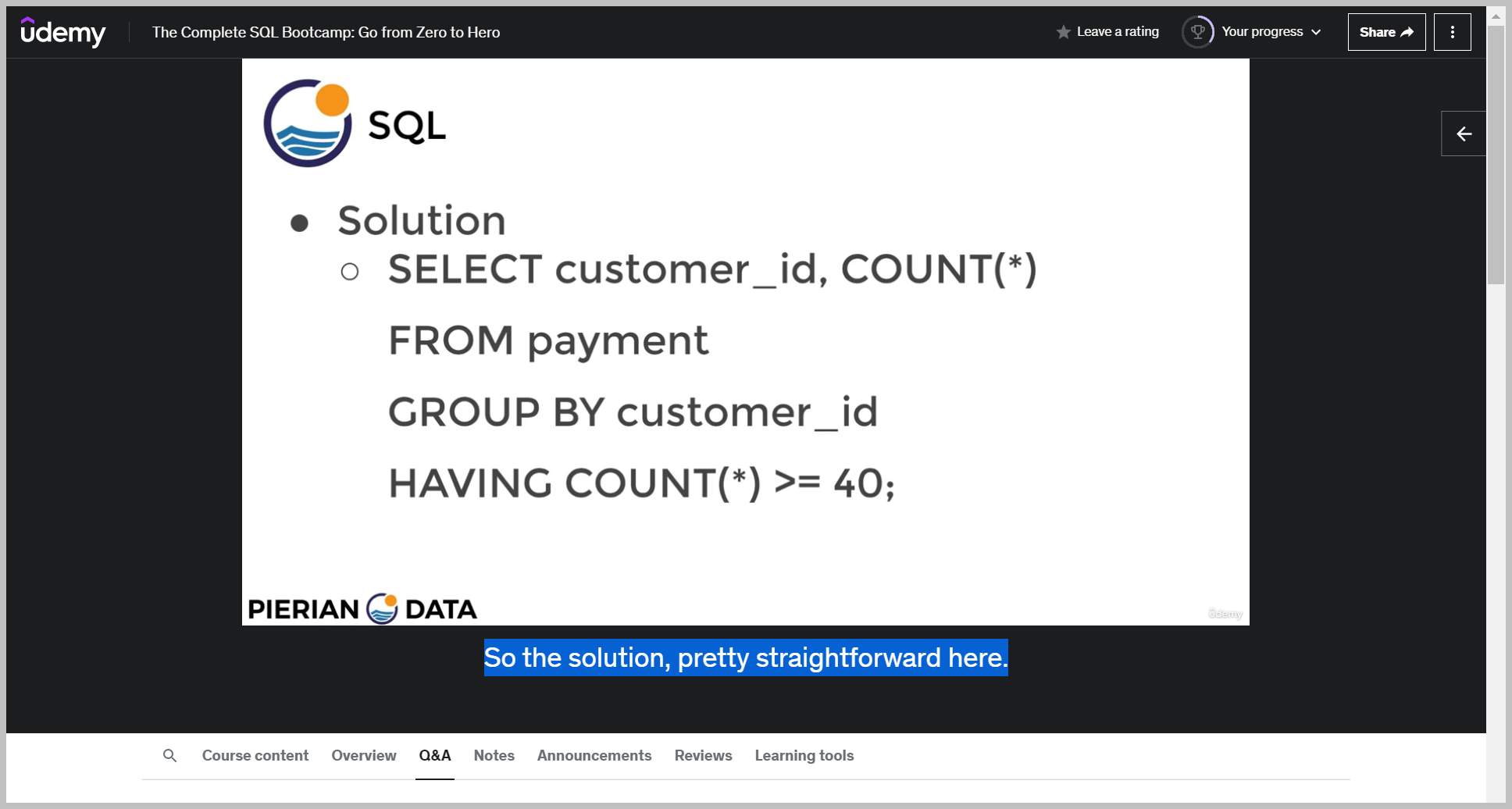
We're going to select the customer ID and then we're going to count. And you can either pass in a column here specific to the amount or just pass an asterisk. And then we're going to grab this from the payment table group by the customer ID and then we're going to say having a count greater than or equal to 40.
TEST2
질문
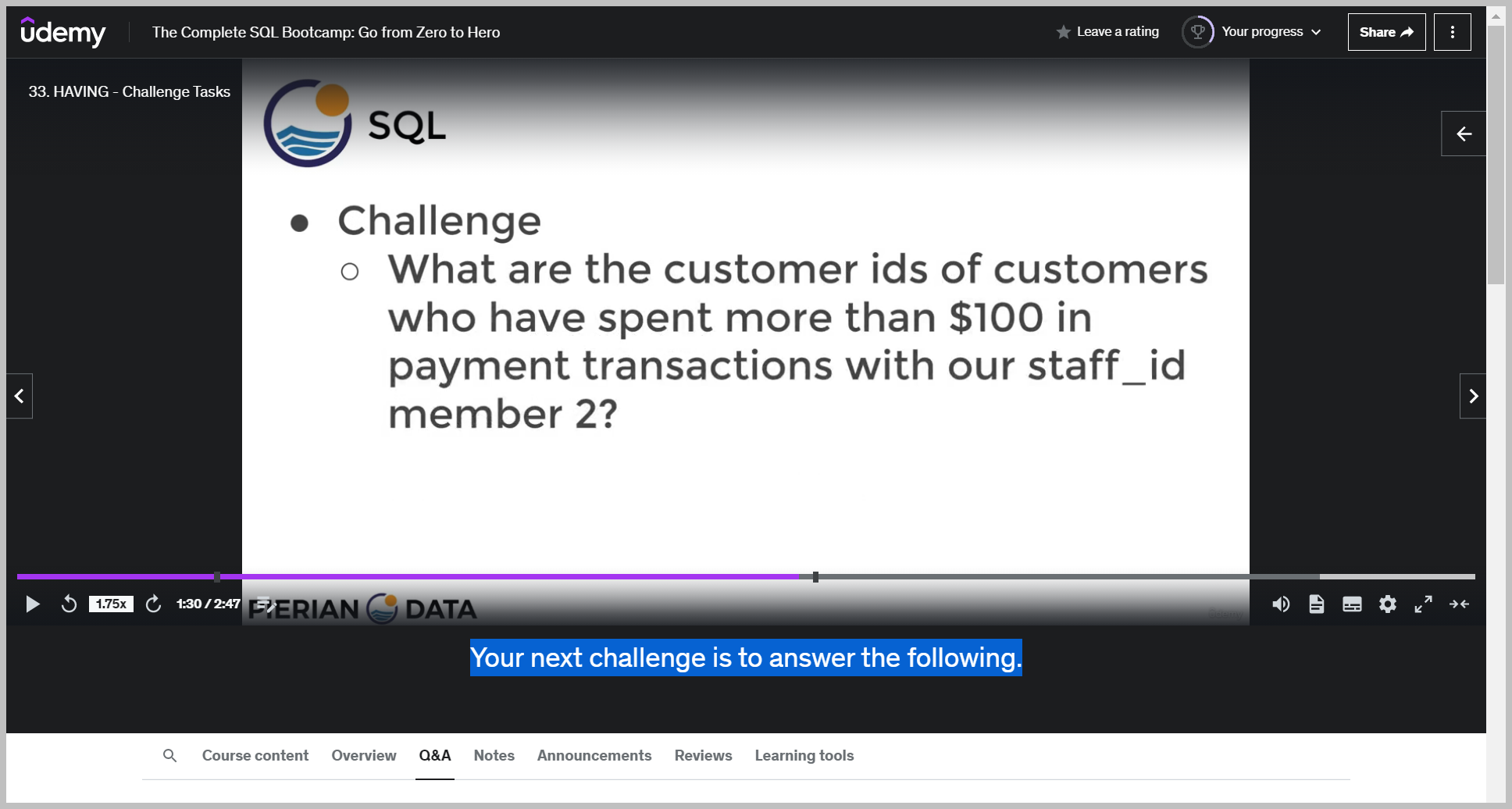
기대값
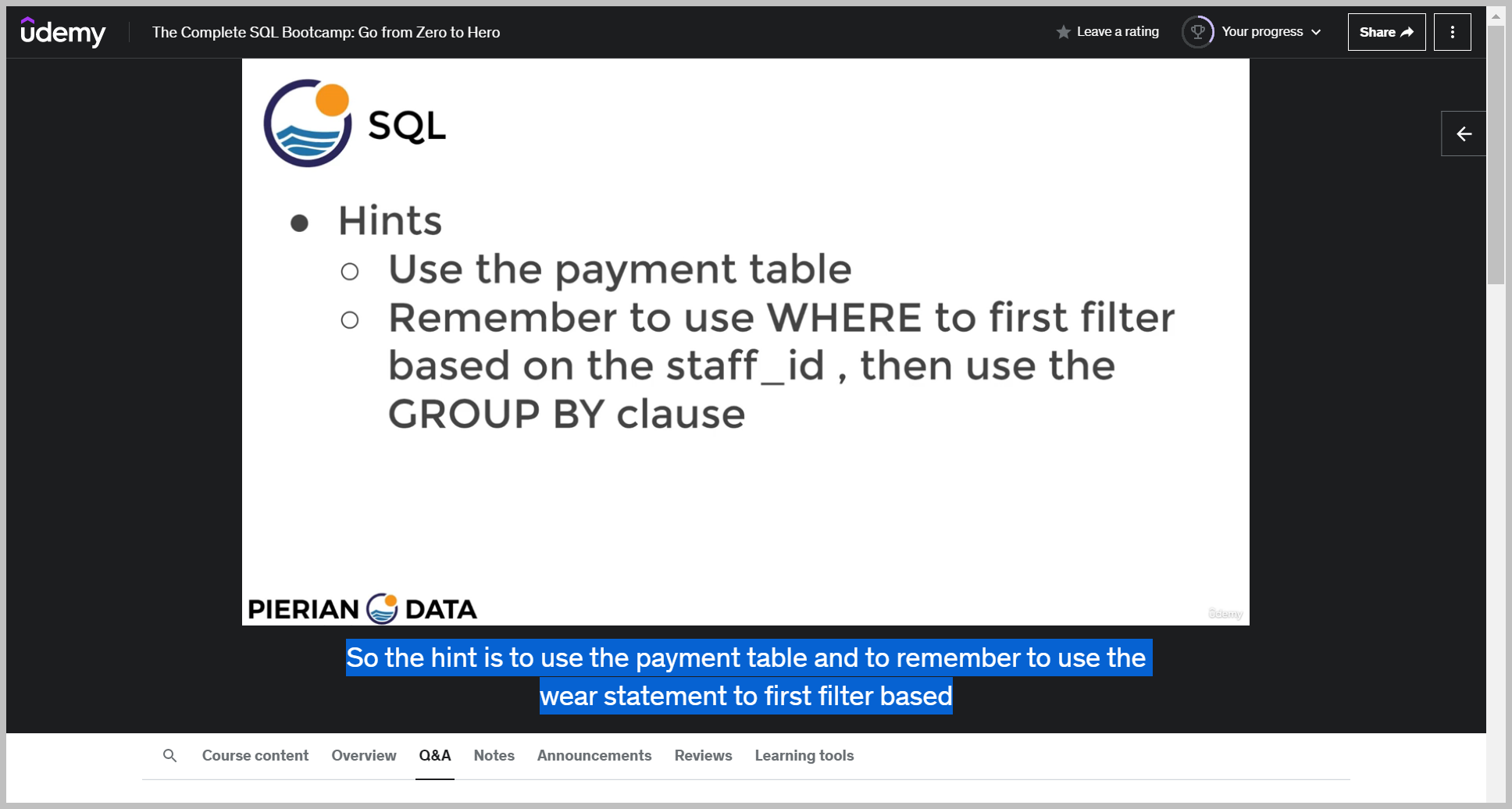
힌트
솔루션
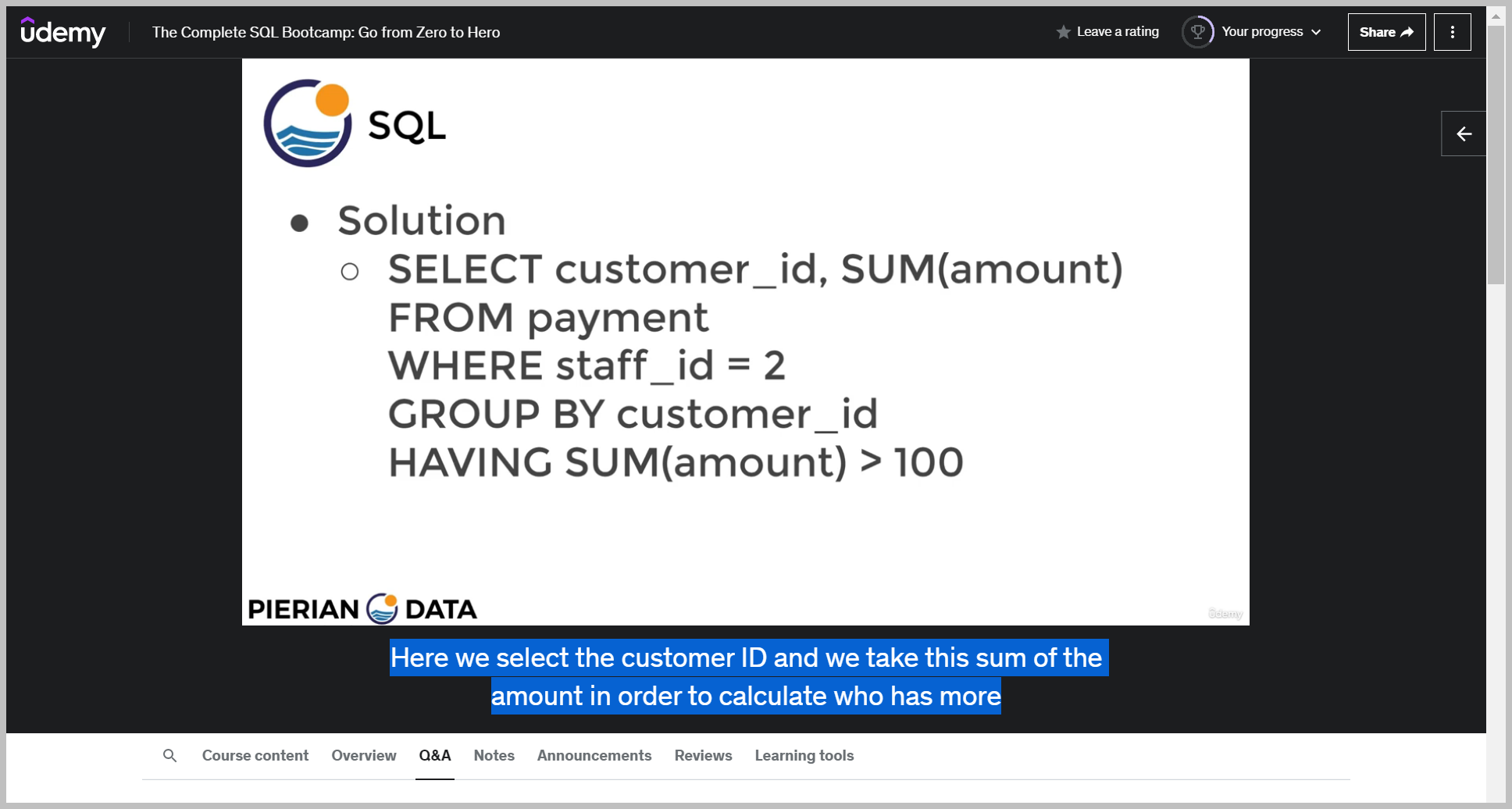
Here we select the customer ID and we take this sum of the amount in order to calculate who has more than $100 from the payment table.
We first, however, filter where staff ID is equal to two.
That way, when we do the group buy on the customer ID, we're only considering people where the actual payment transaction occurred with the staff ID equal to two.
And then we check for having a sum amount of greater than 100.
JOINS
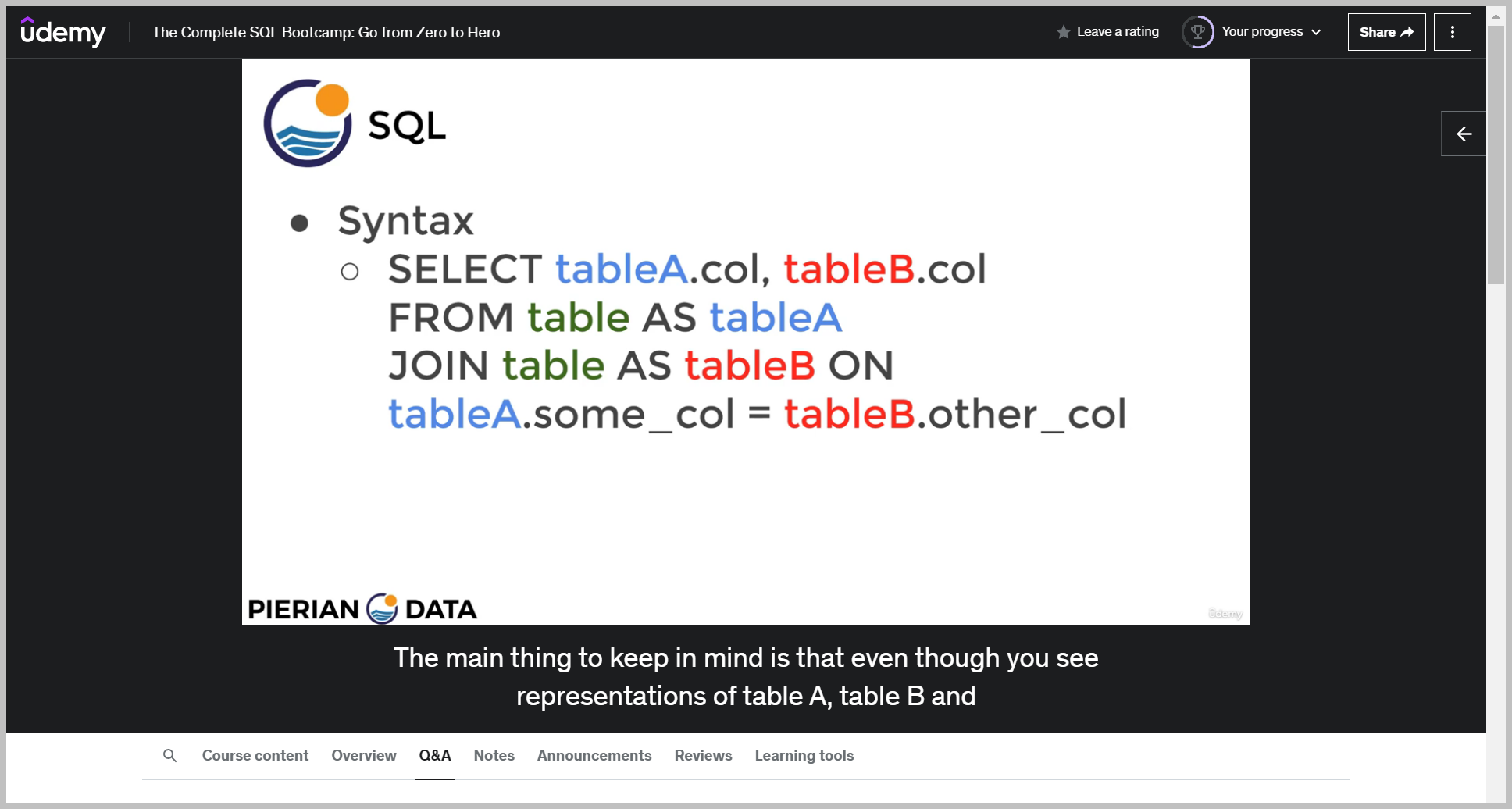
AS 구문
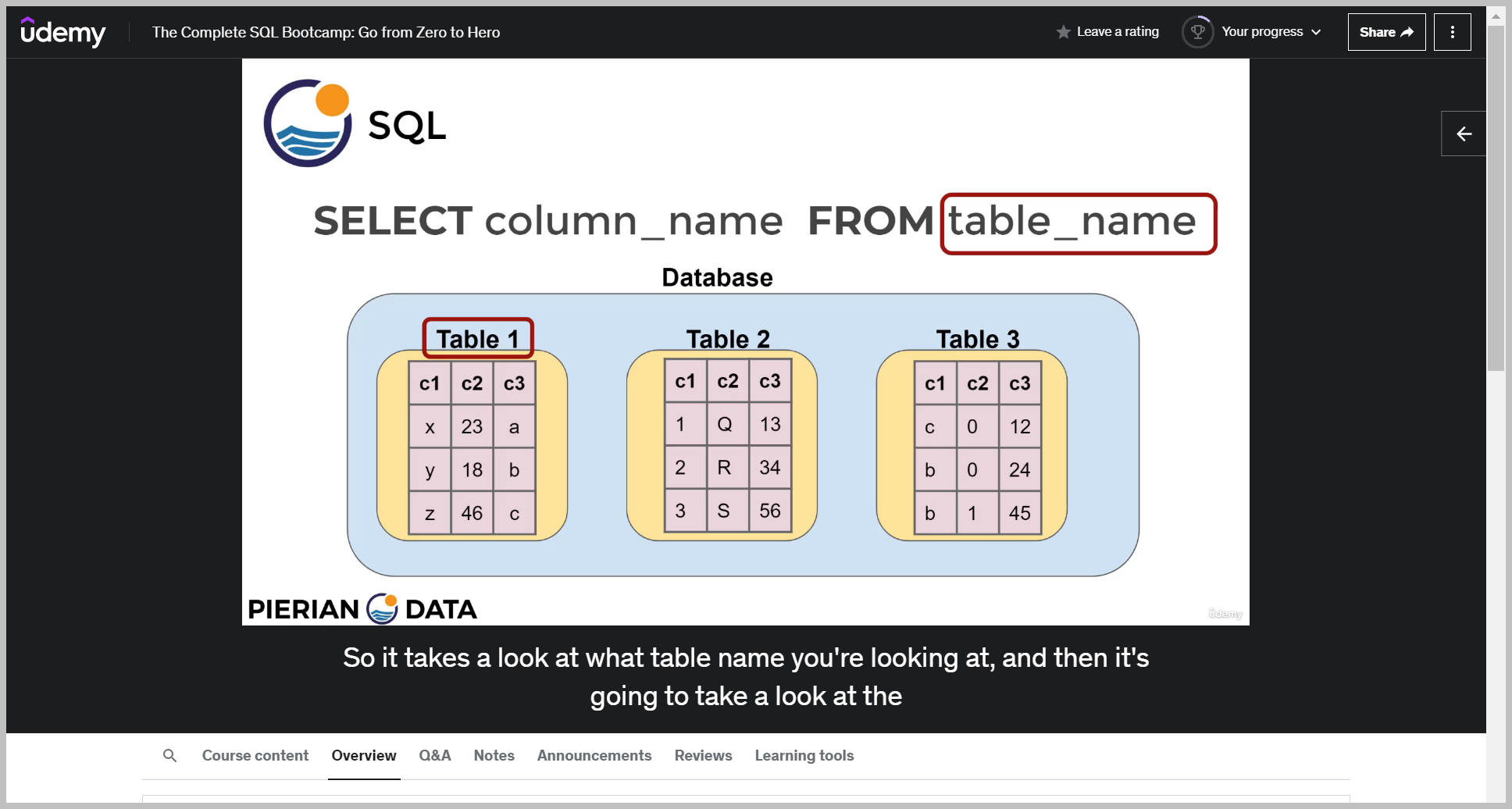
기본 문법
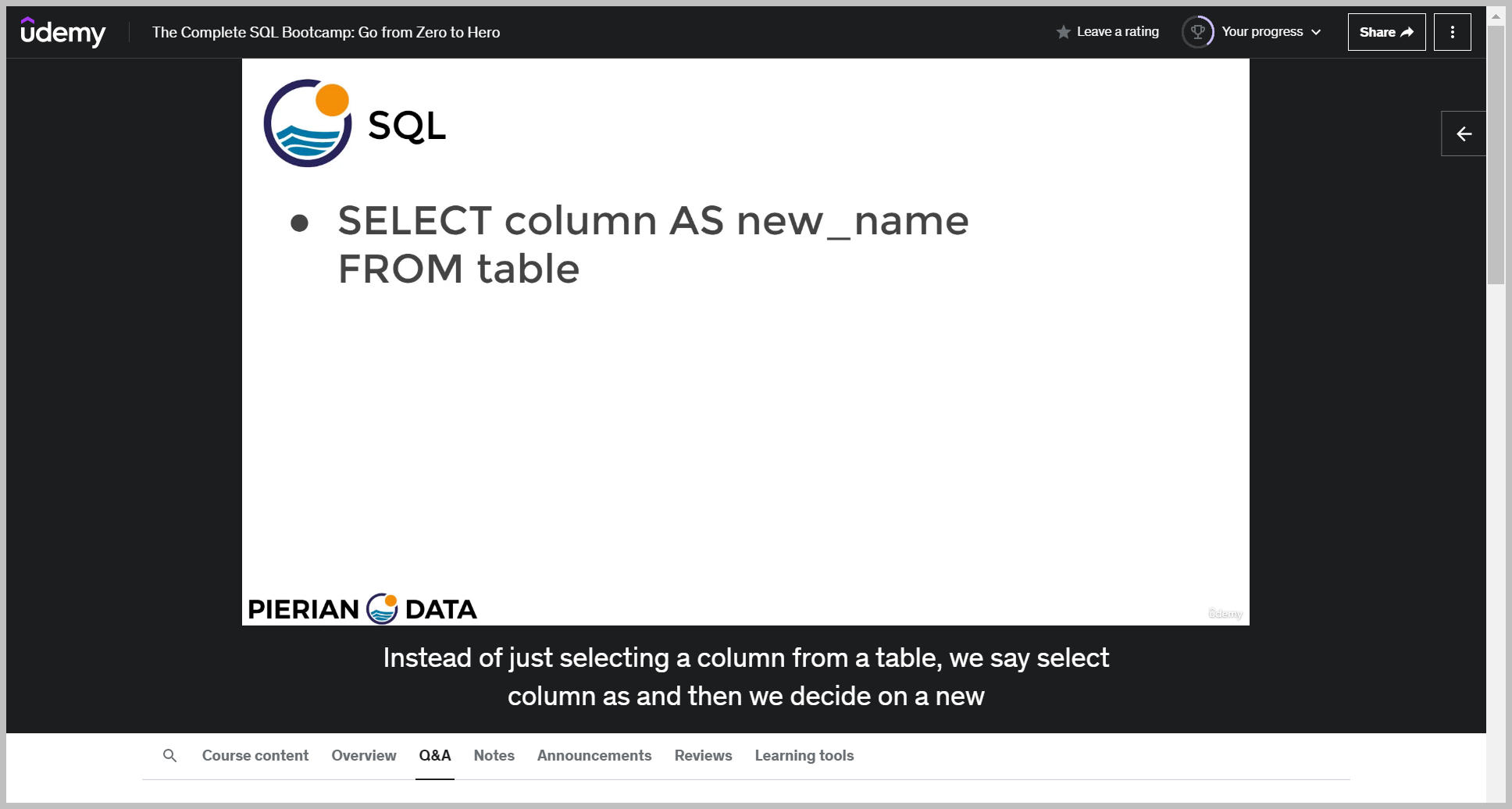
예제
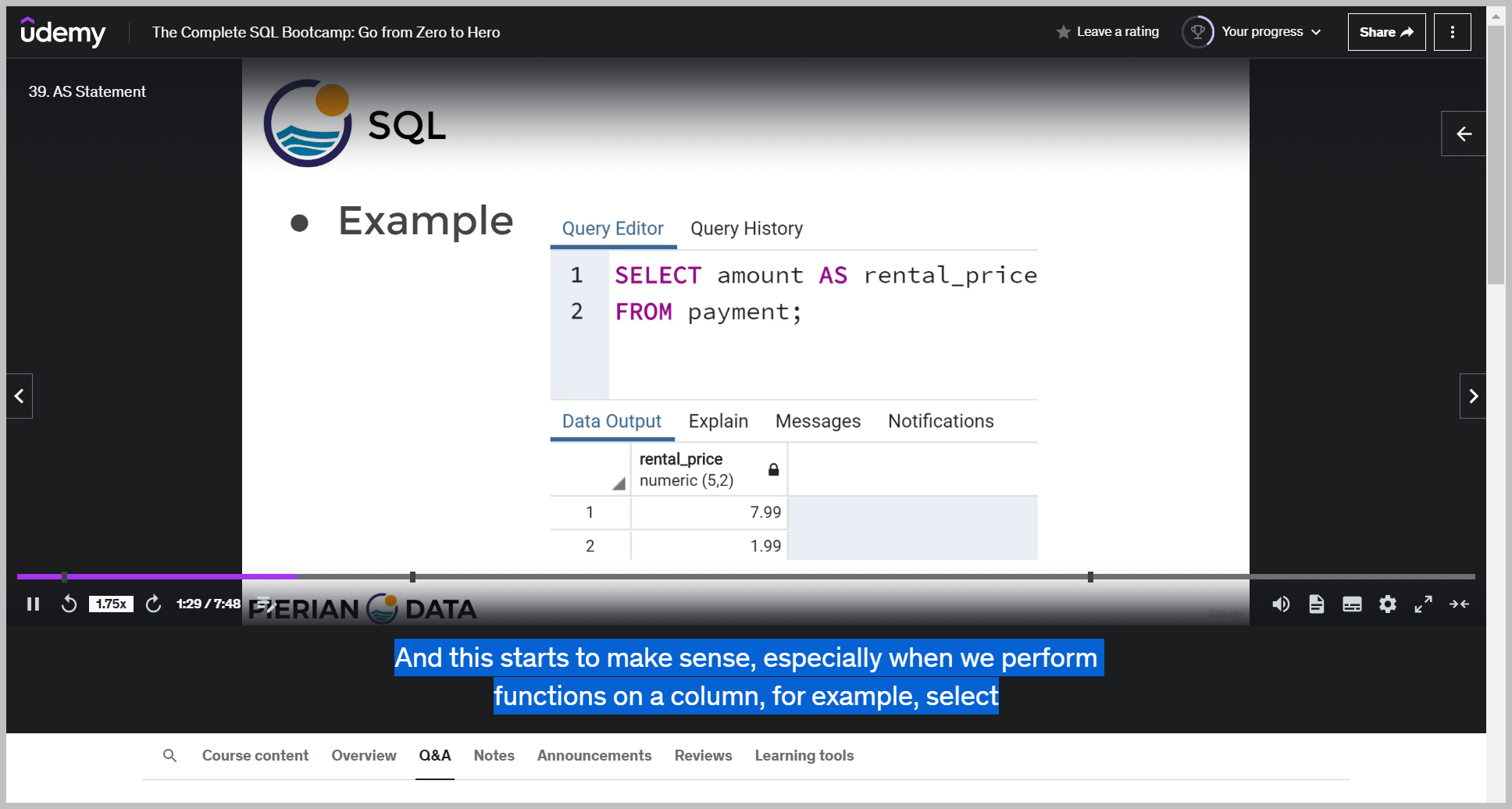
So notice here, instead of having the output reported as the amount column, instead we decided to give it an alias or rename it as rental underscore price.
So really here it's just for readability on the data output.
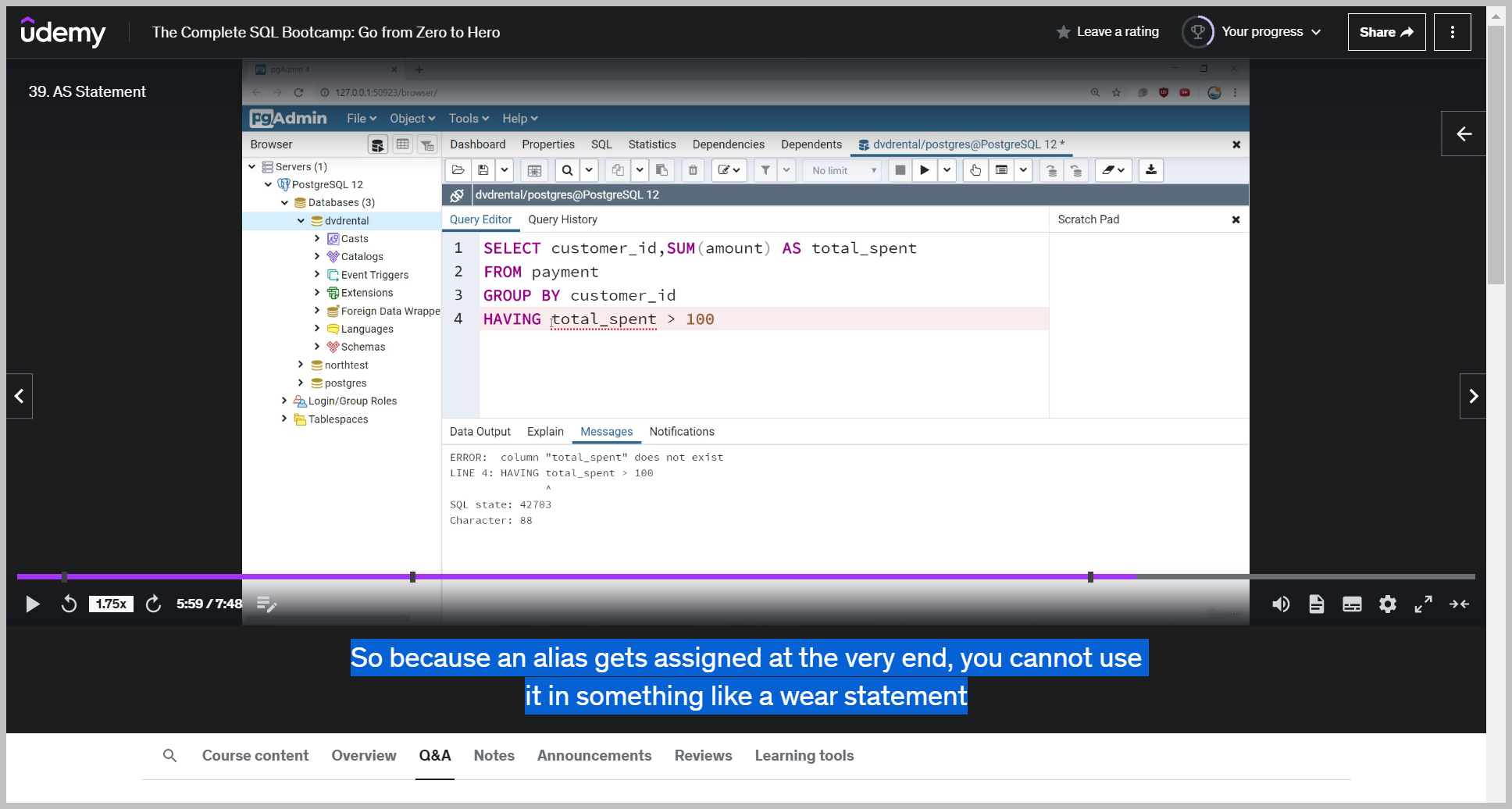
Now keep in mind the AS operator gets executed at the very end of a query.
So because an alias gets assigned at the very end, you cannot use it in something like a where statement.
Unfortunately, you have to go back and choose the original either column name or the original function.
INNER JOIN
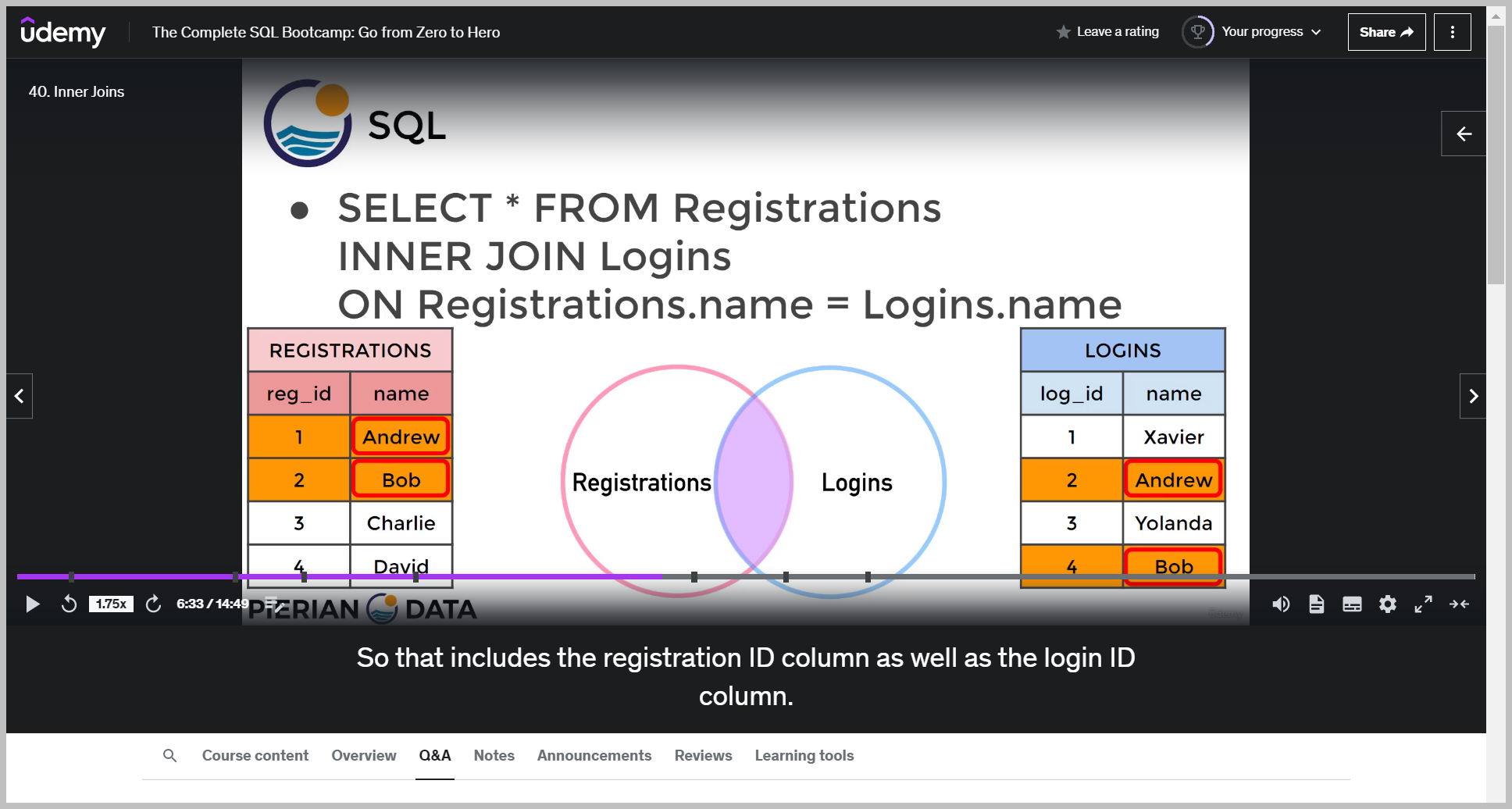
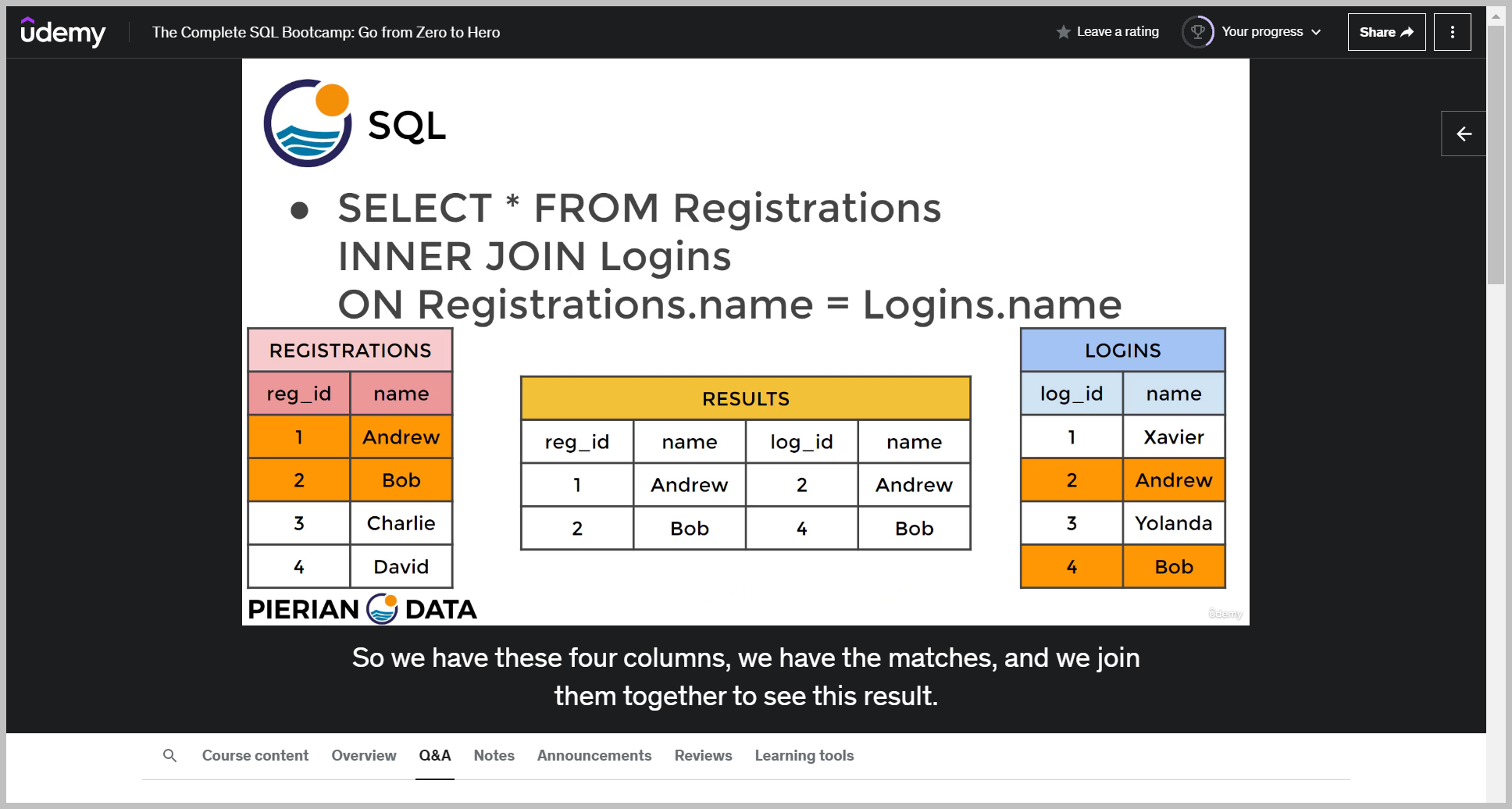
So this is selecting all the columns from the resulting of registration inter joined with logins on the name column.
Again, an inner join is looking for matches that exist within both tables.
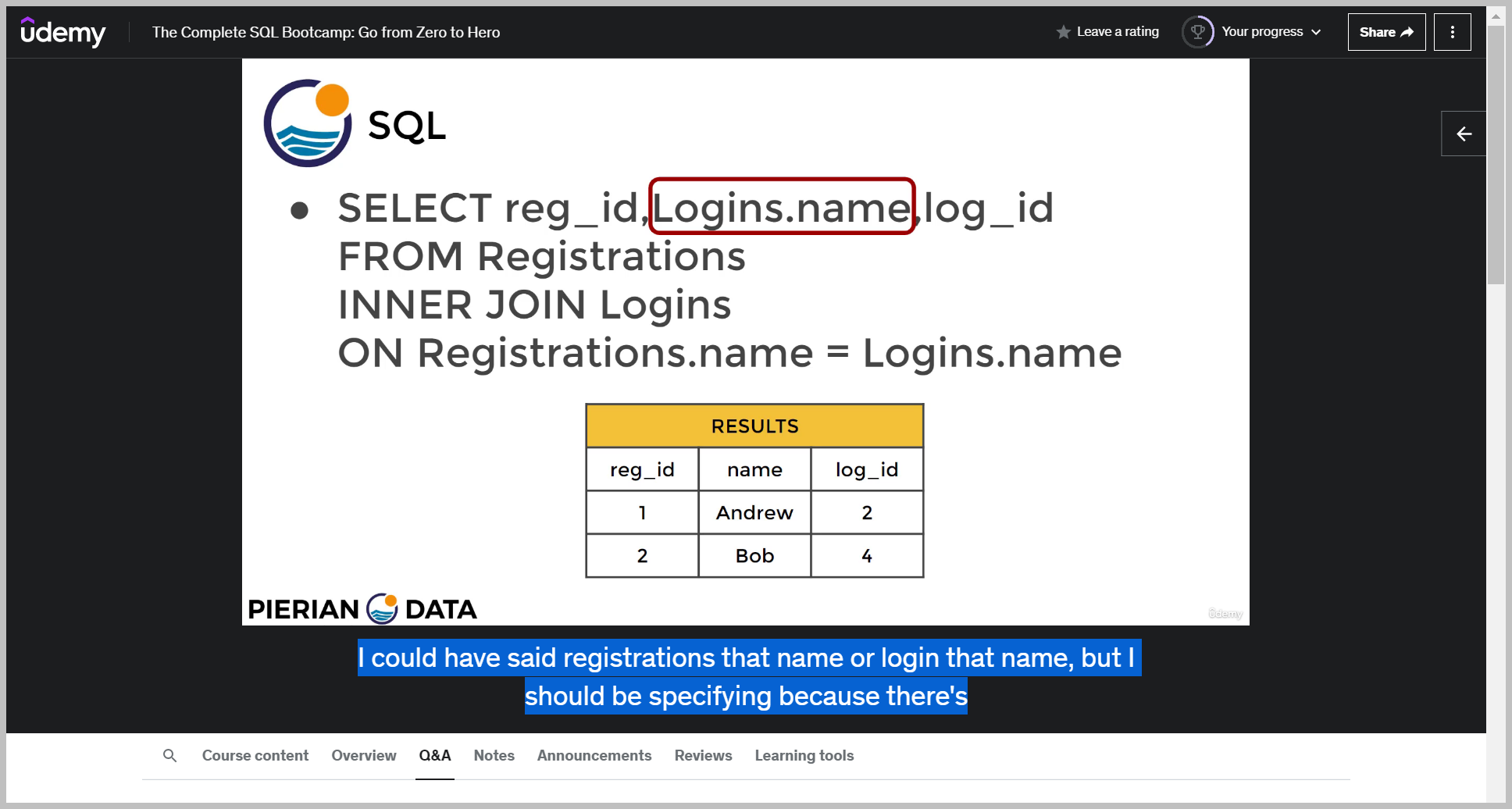
If you wanted to get rid of this duplication, what you can do is actually specify what columns you want.So you might be wondering why that I have to specify log ins name instead of just saying name.
Well, the reason for that is because name existed in both tables.
So we had both tables share a column name, which means if I'm selecting something after a join, I should specify what table I'm referring to in regards to the name column.
예제
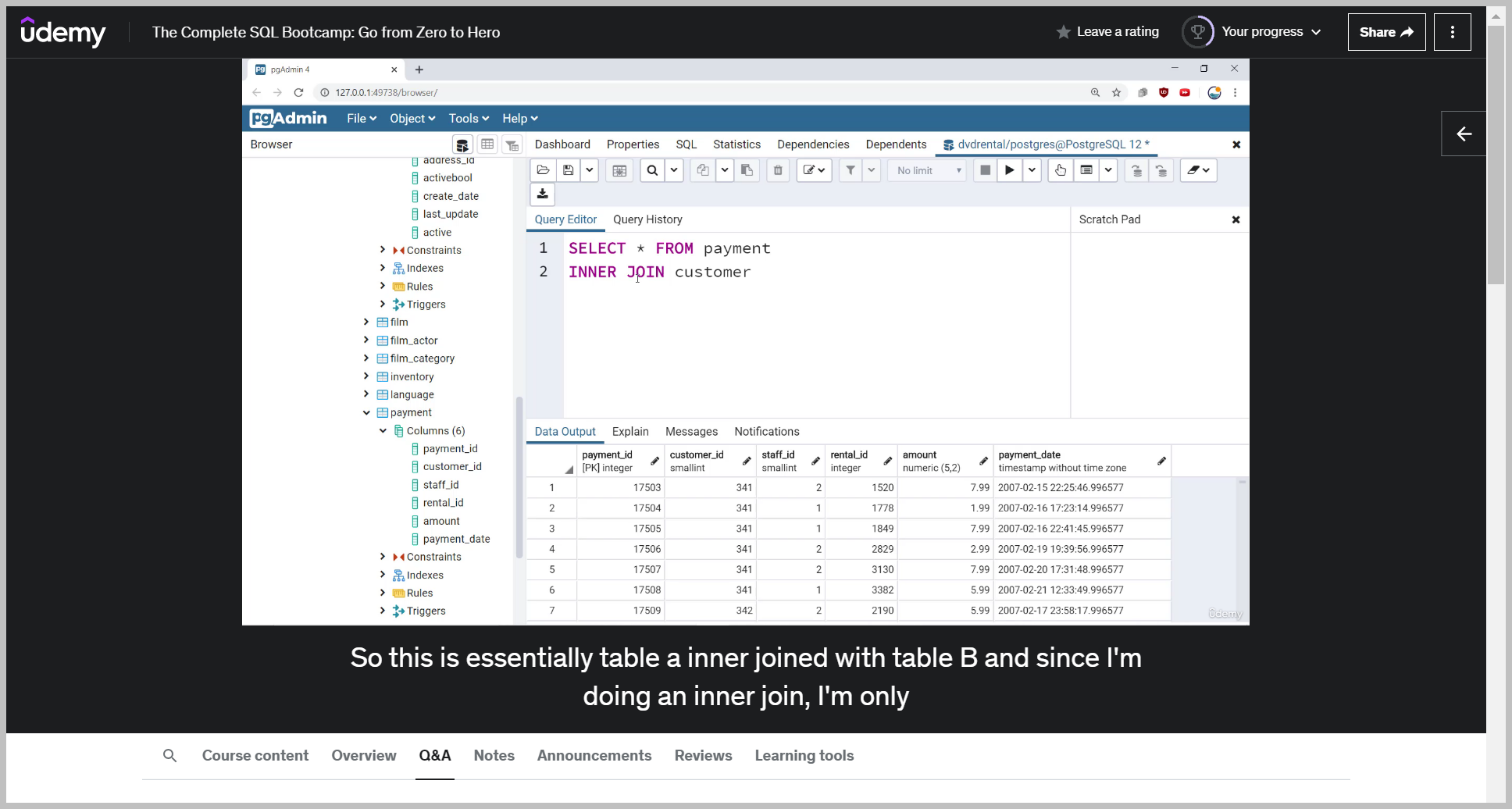
So this is essentially table a inner joined with table B and since I'm doing an inner join, I'm only going to get back results where that particular customer happens to be both in the payment table.
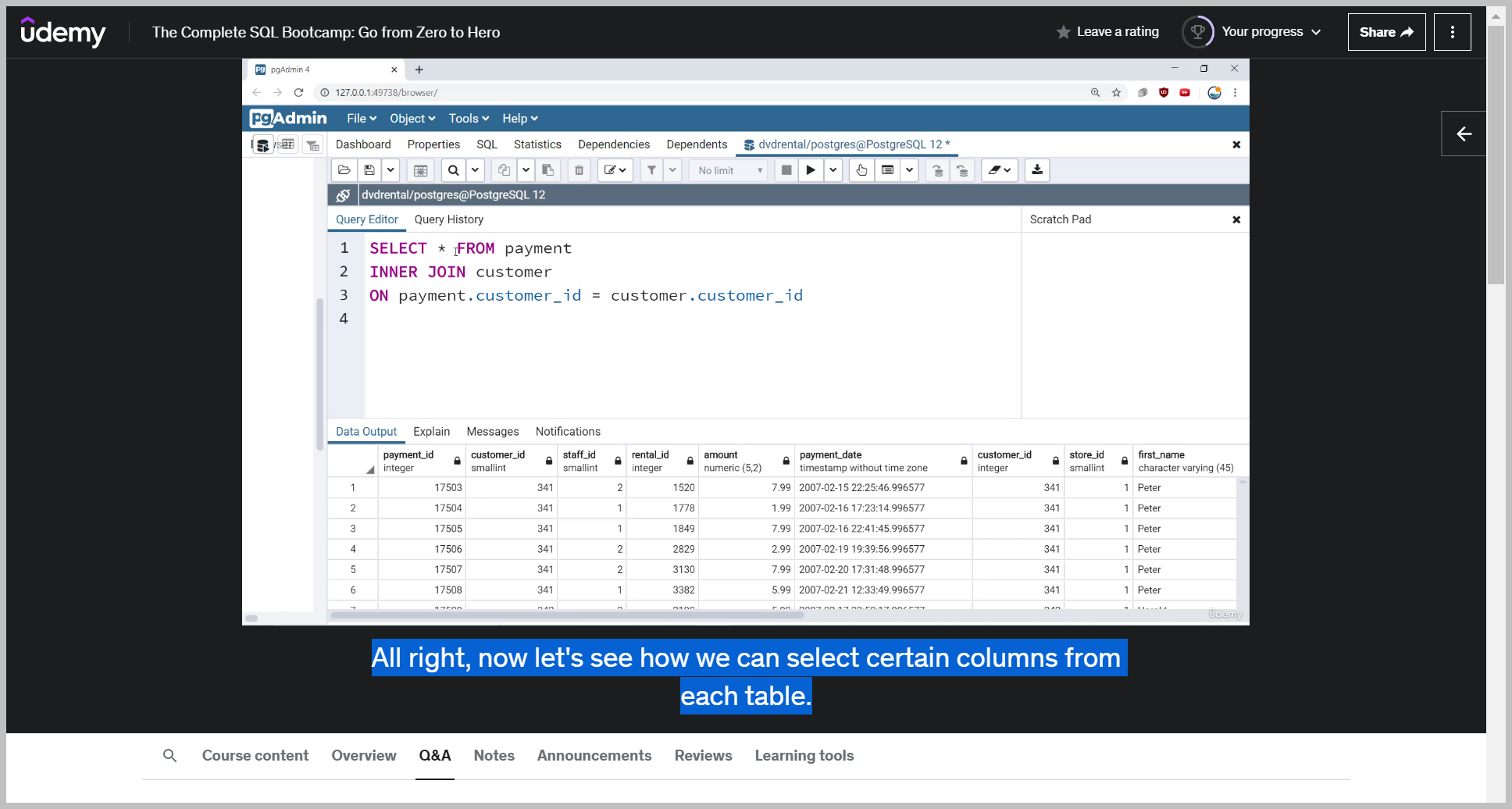
And now you'll see I have the payment ID, customer ID, essentially all the information from the original payment table.
Now I see the repeated information based off customer ID, but now it's on the customer table.
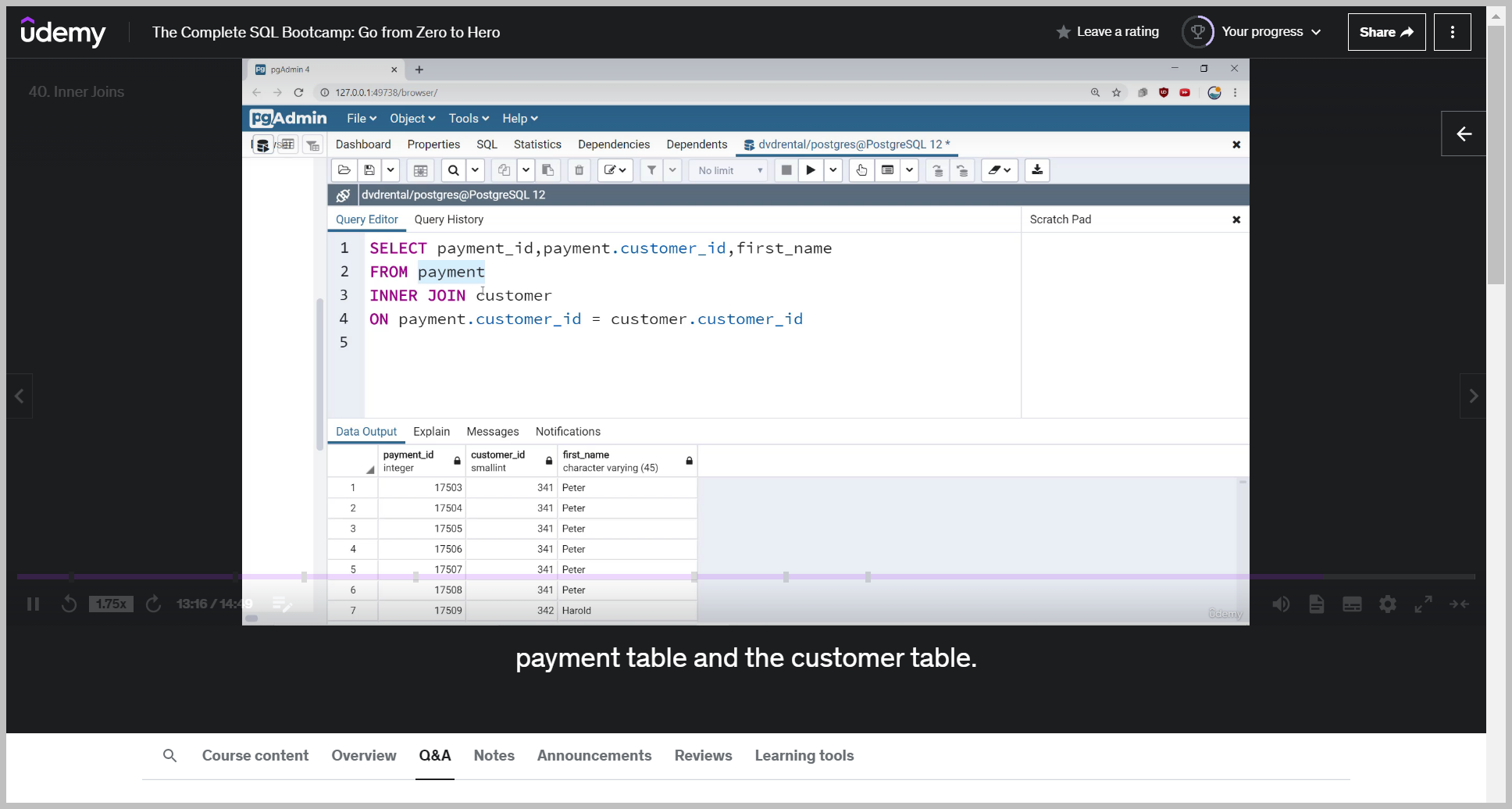
Notice now I could see payment ID, customer ID and first name.
So this is the general syntax that we're using for inner join.
Notice how the inner join is only going to join customers that are found in both payments and the customer table.
So again, general syntax, I select columns from a table, let's say table a inner join on table B and then on payment customer ID equal to customer customer ID.
So table A, the identifying column equal to table B and the same identifying column.
OUTER JOIN
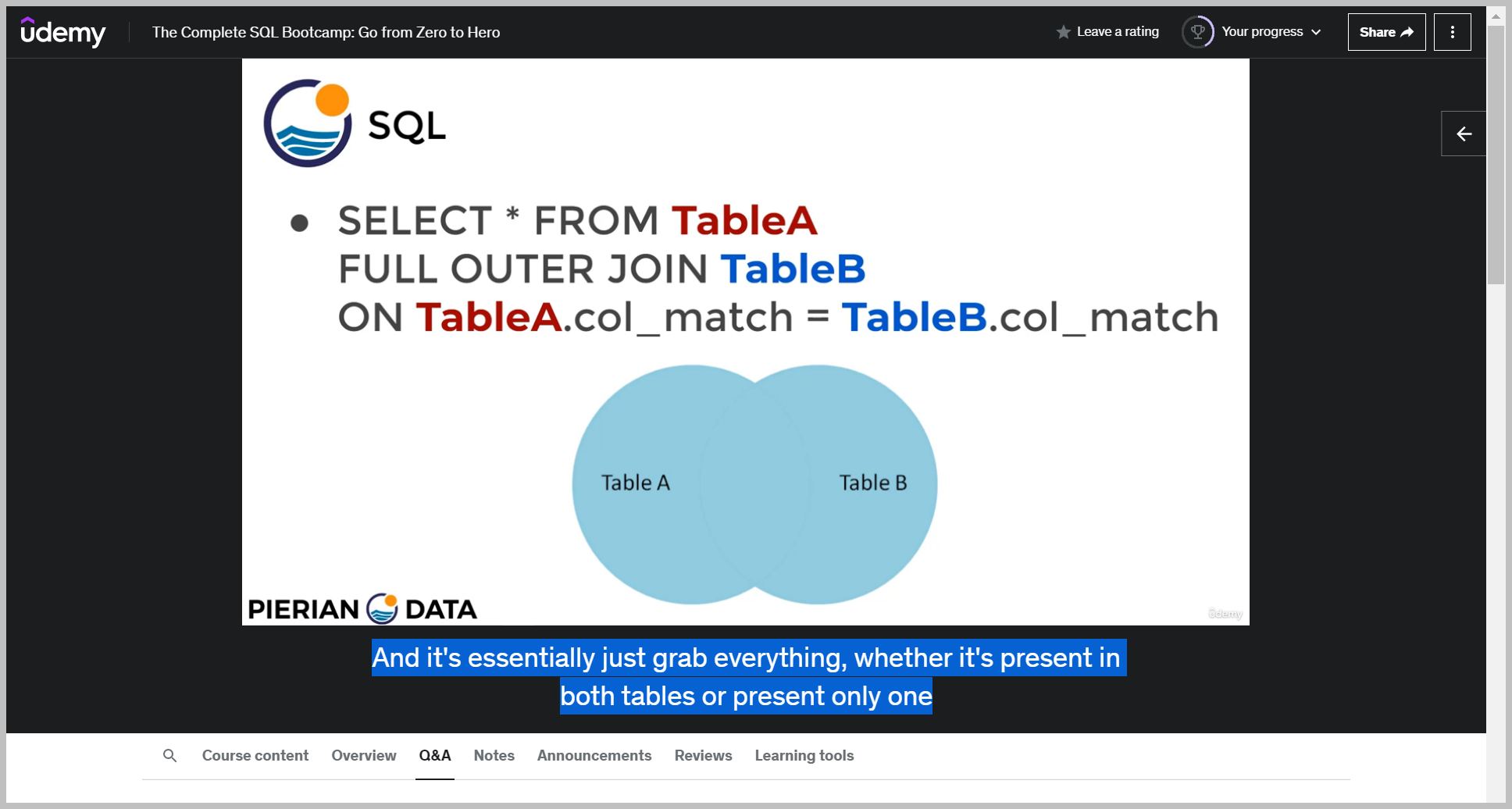
So an outer join or a full outer join just grabs everything.
So the syntax is select all the columns from table A do we fool outer join of table B and then on wherever that column match occurs from Table A, equal to table B column match.
예제
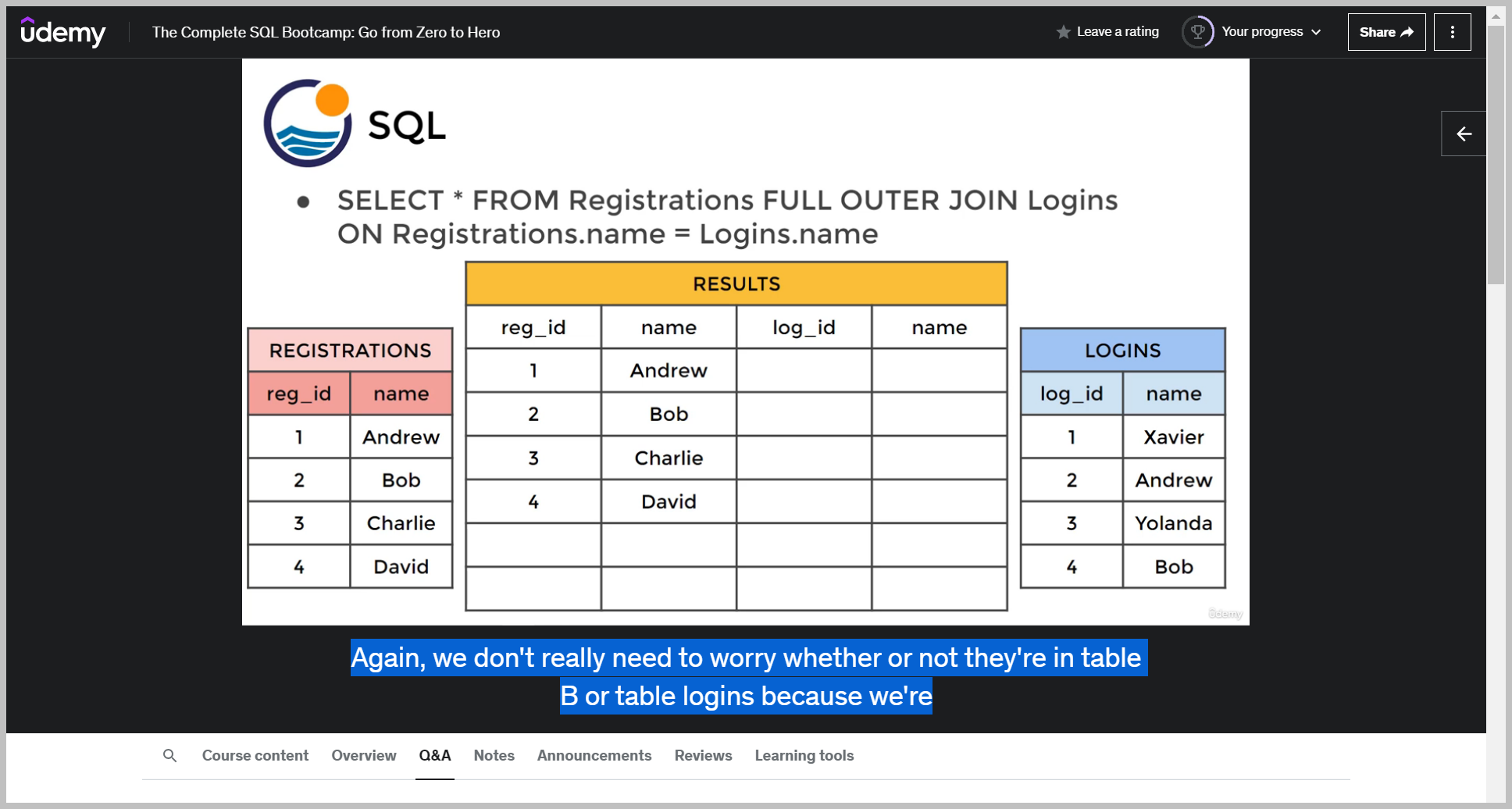
First, we're saying grab everything from the registration table.

so we need to start filling information for where we actually have a name match and we know we have a name match on Andrew and Bob and then we fill it in with the corresponding login ID.
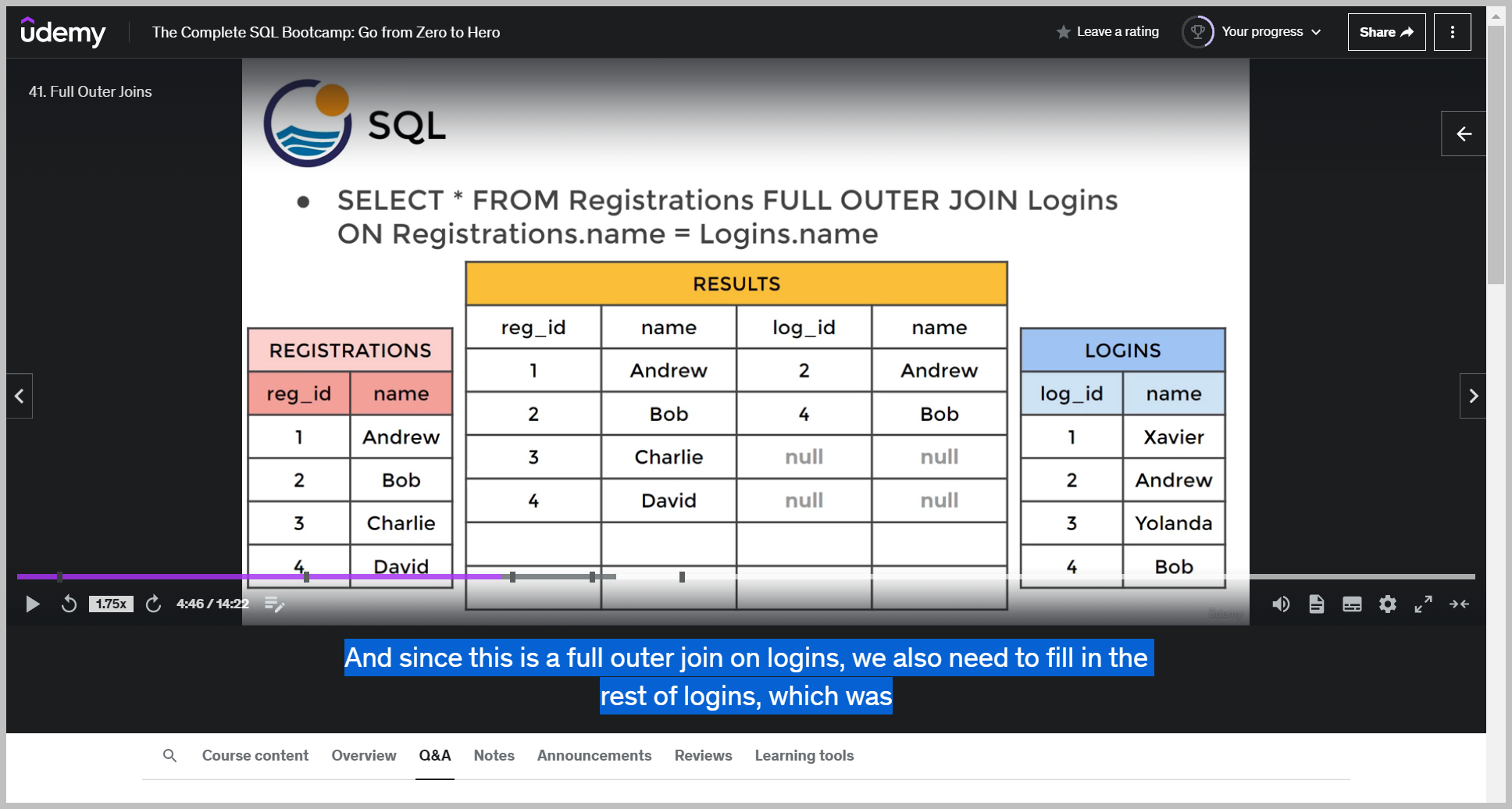
Now the issue we arise with is that we didn't have a Charlie or David in logins, but we're still asking for everything.
So what SQL ends up automatically doing for us is filling this in with NULL, essentially clarifying to you that there was no value there present, so there was no Charlie or David in the Logins column.
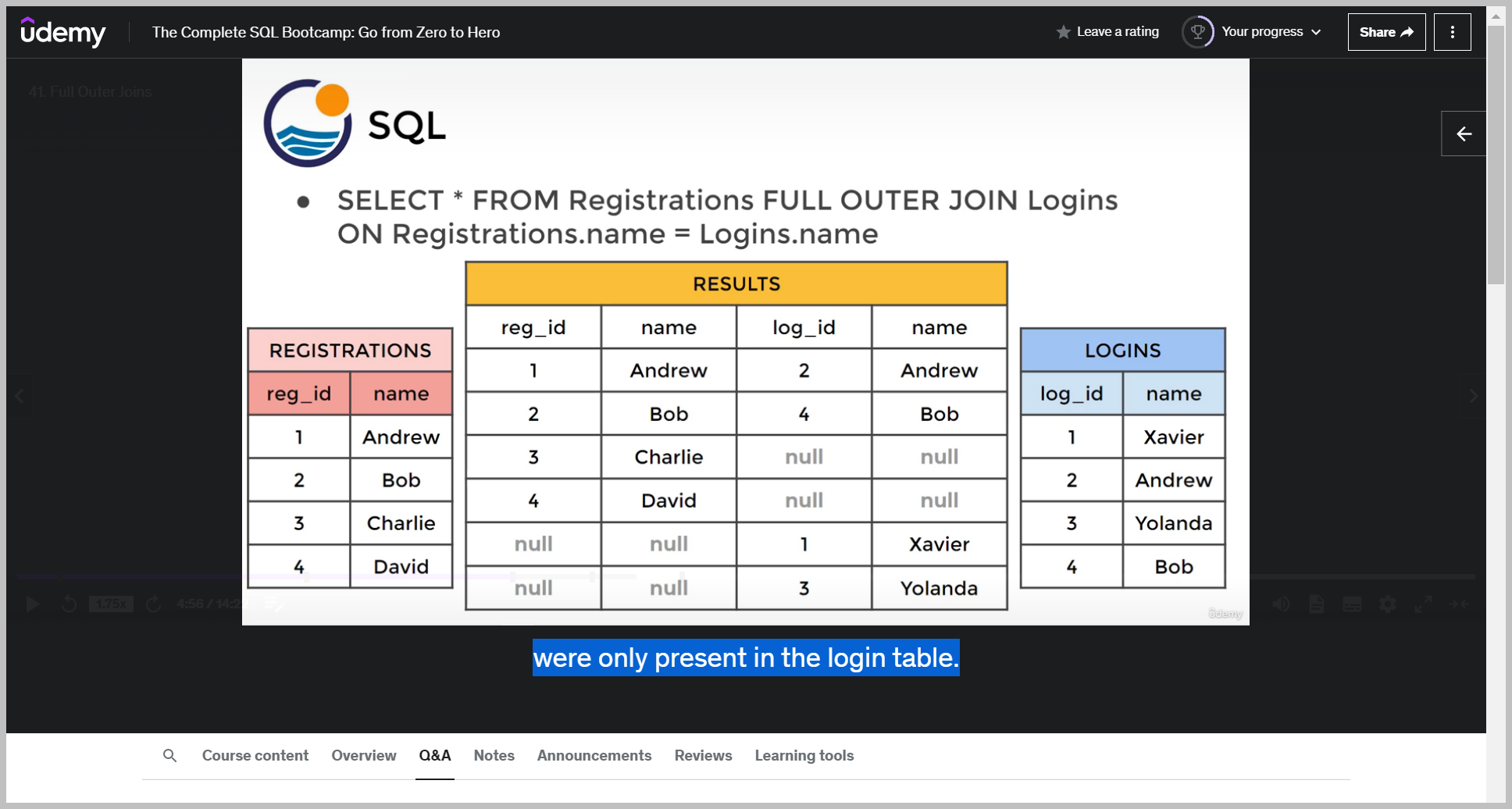
And since this is a full outer join on logins, we also need to fill in the rest of logins, which was Xavier and Yolanda, and then the corresponding null values for the registration table because they were only present in the login table.
null
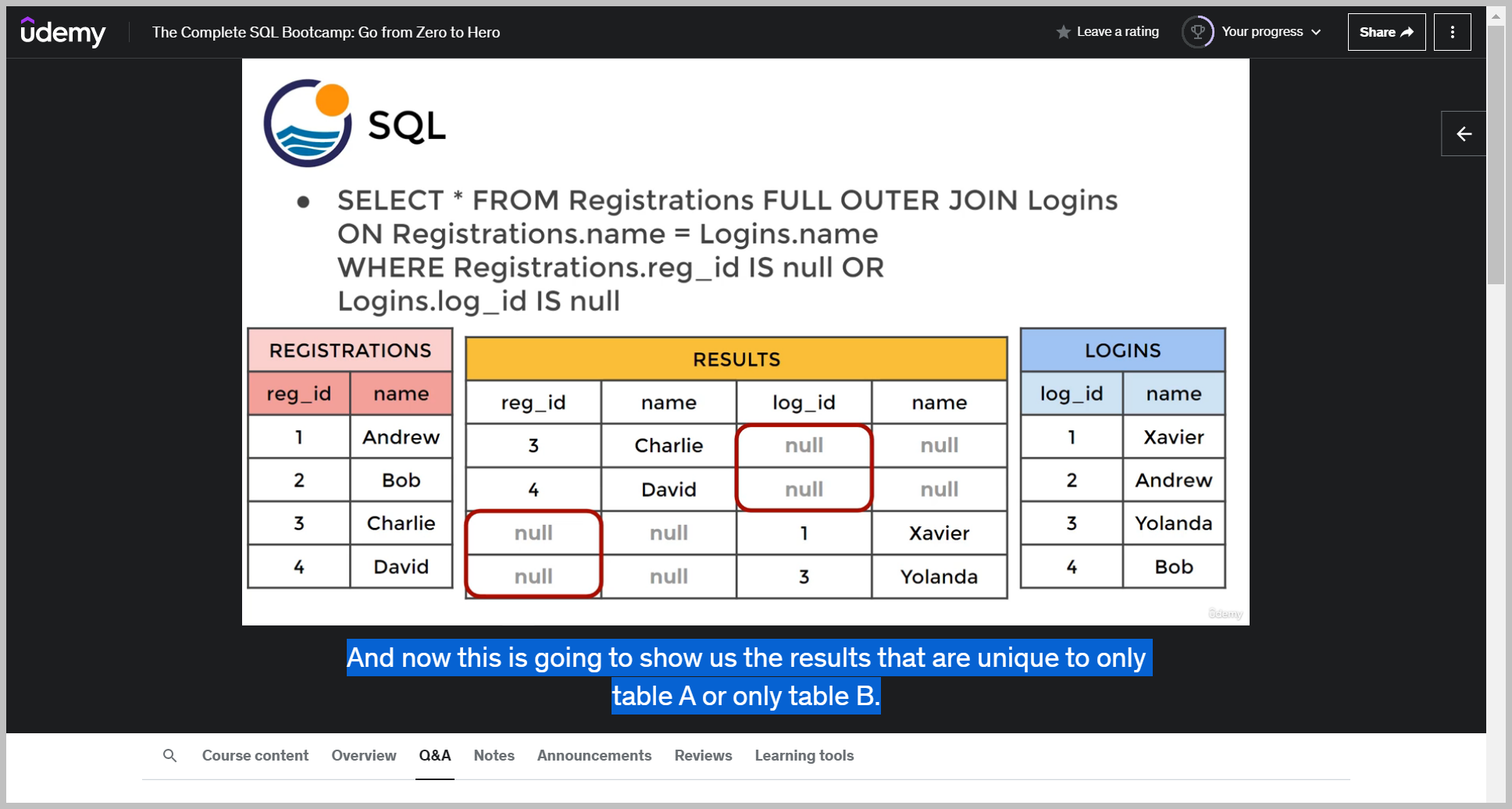
So look here, we're going to add in where registration is, that reg ID is null or we're log in, log ID is null.
You're going from this full outer join table and then specifying, find me where those ID columns are null.
And that essentially removes those first two rows, which was the match for Andrew and Bob.
LEFT OUTER JOIN
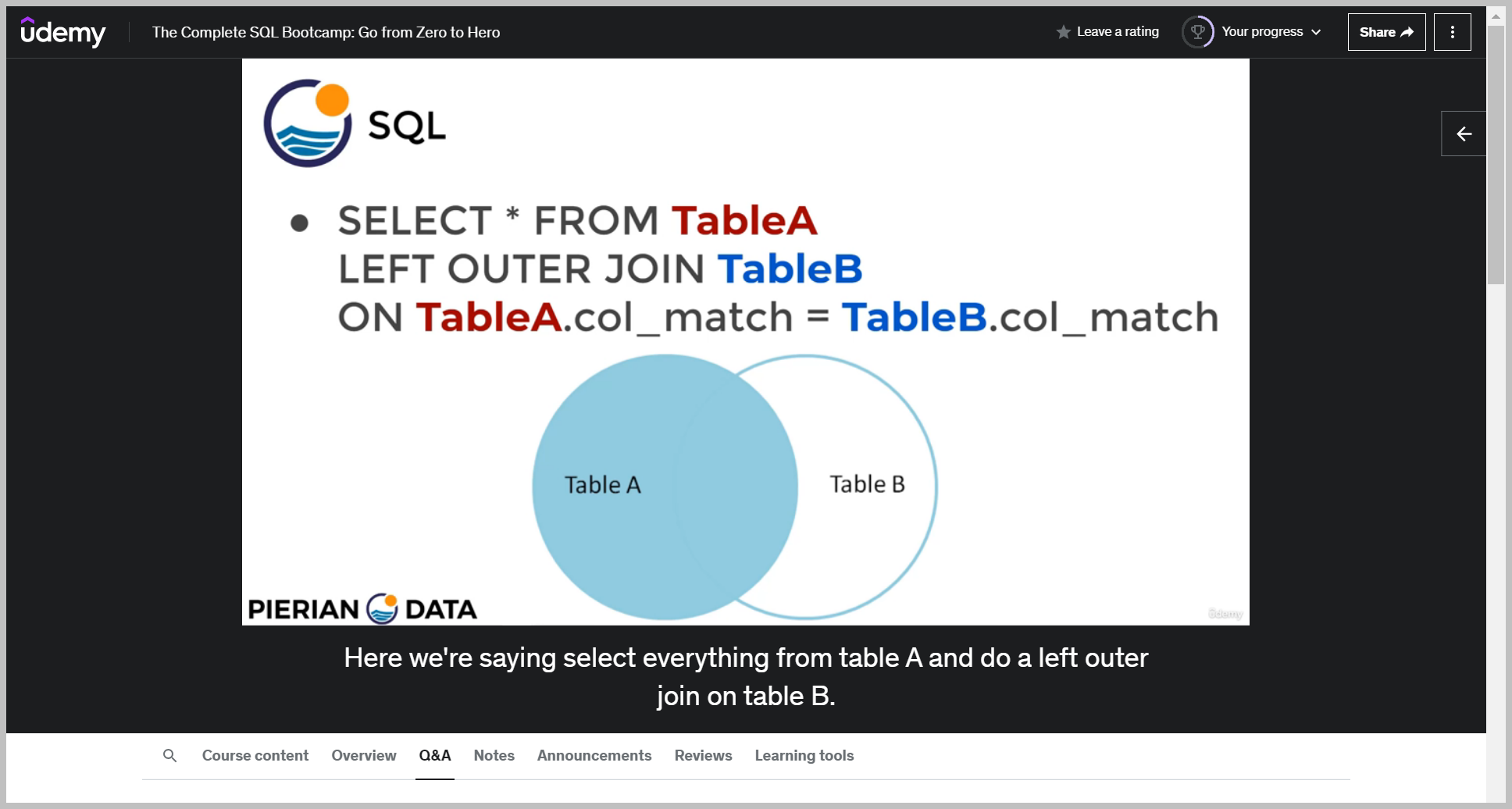
Notice that our Venn diagram is no longer symmetrical, which means the order will actually matter.
Here we're saying select everything from table A and do a left outer join on table B.
The left hand table is the first table referred to in that from statement.
So notice here we're saying table A, which means we're going to grab things that are exclusive to Table A or can be found in both table A and table B.
예제
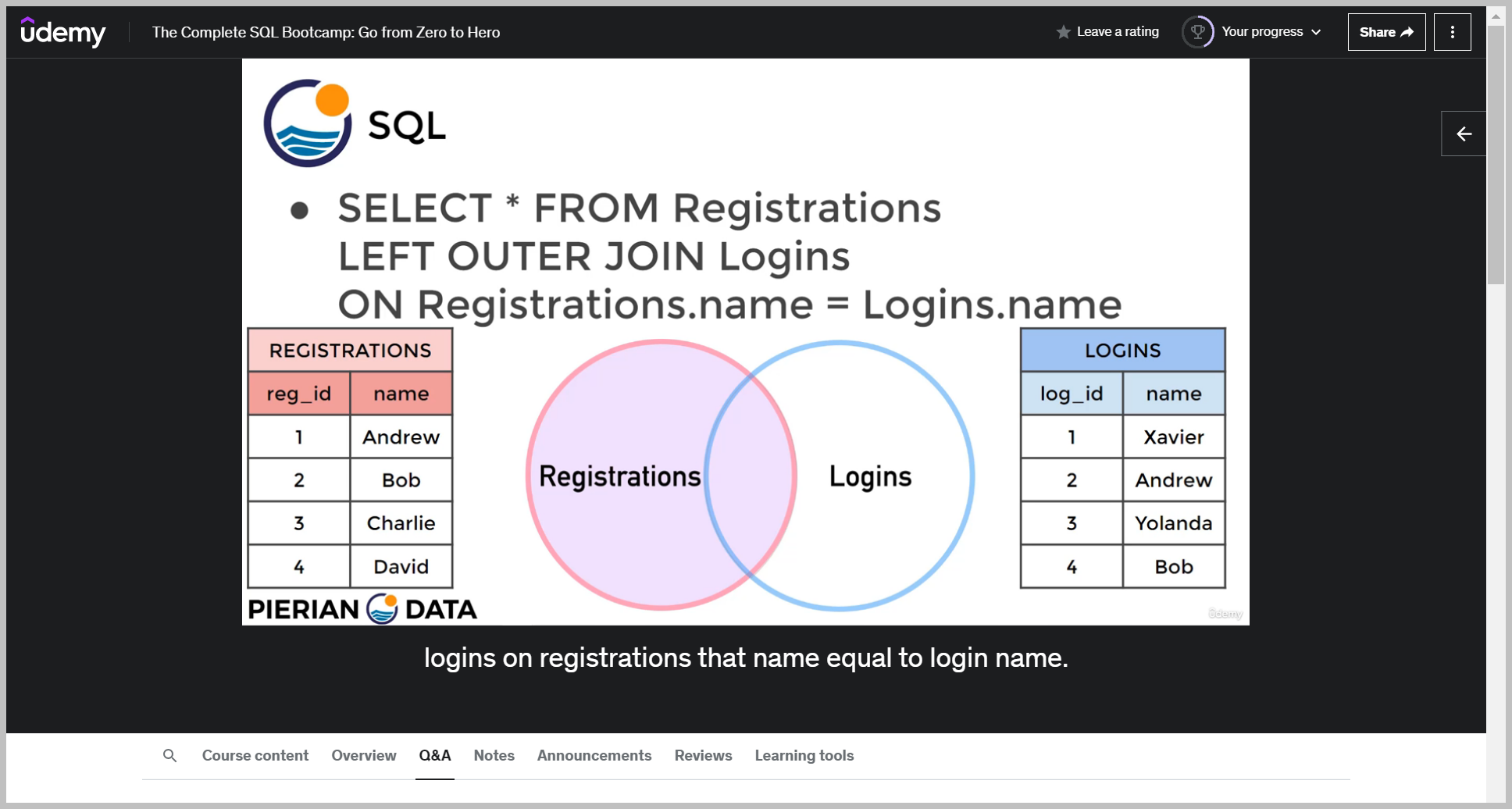
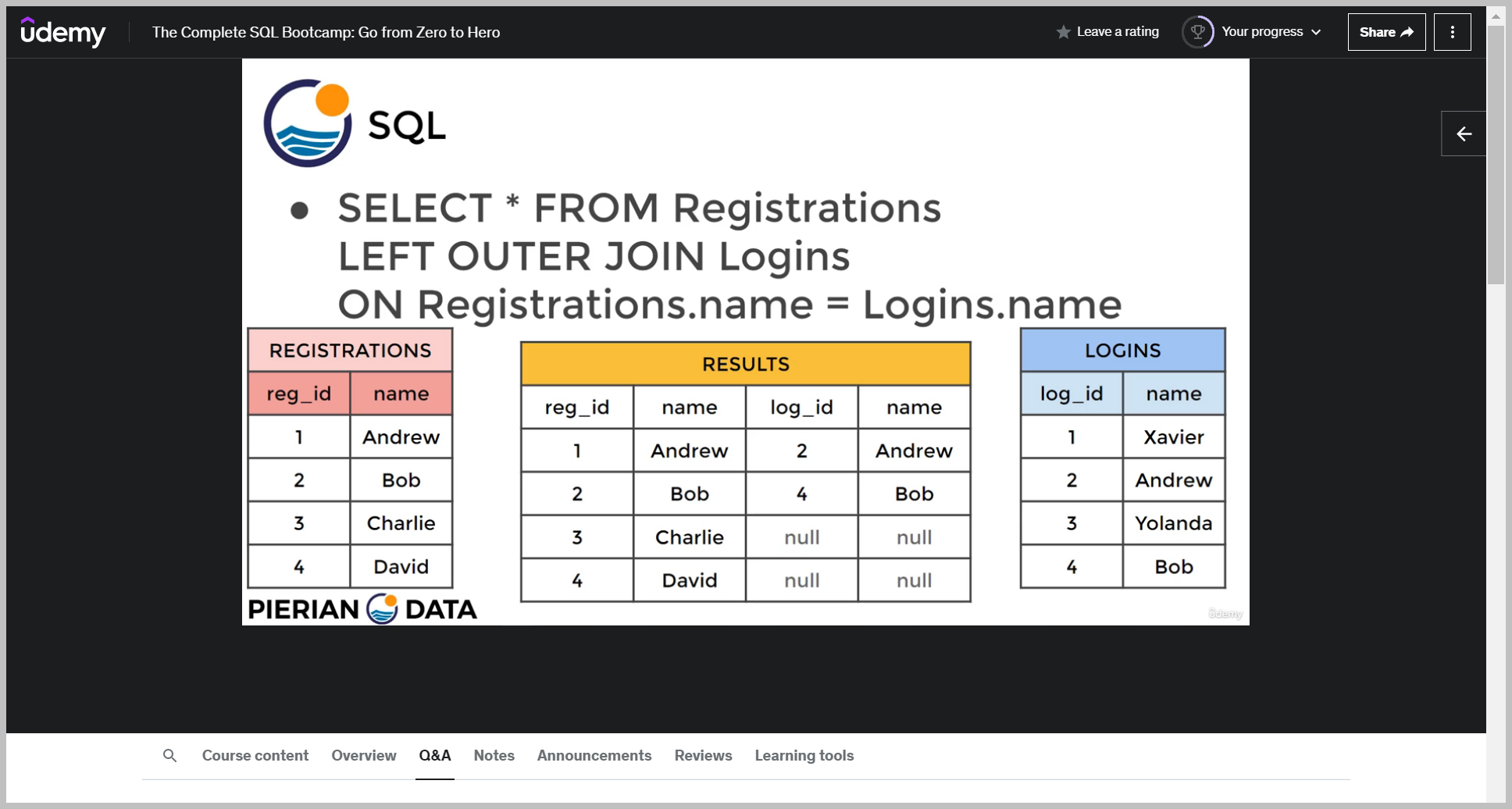
Well, it's going to return the following recall that we're going to grab everything from the registrations table, and if there happens to be a match with the login table, we'll go ahead and return it.
If there is no match, we're still going to grab that information from the left hand table, which is from registrations.
But because there's nothing in table B for it, we're going to fill it in with NULL.
Notice that things that were exclusive to the right hand table, that is the login table or table B, that was Xavier and Yolanda.
We don't actually see them in this result of the left outer join.
Previously when we saw a full outer join, we did see those results.
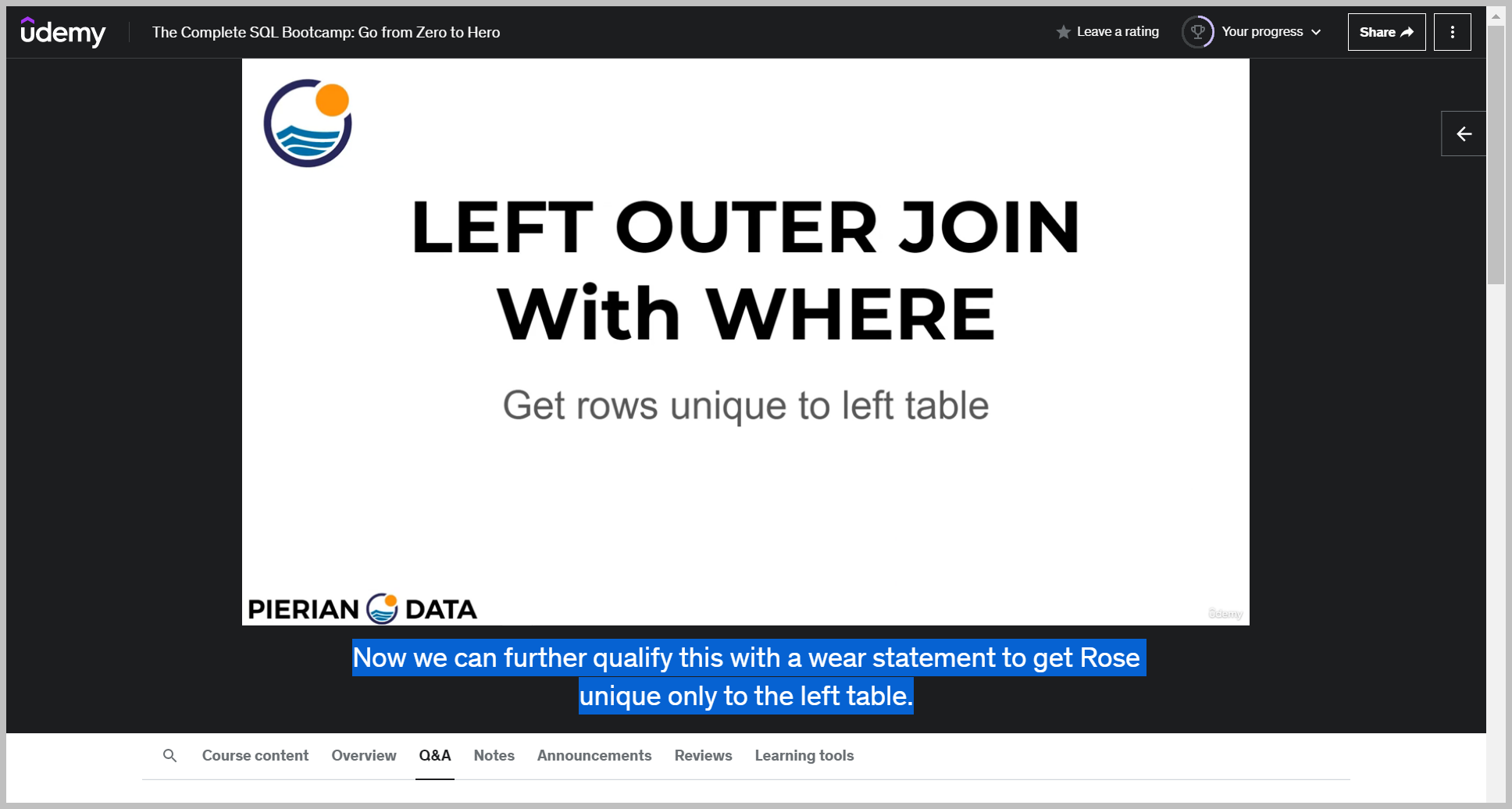
Now we can further qualify this with a wear statement to get Rose unique only to the left table.
null
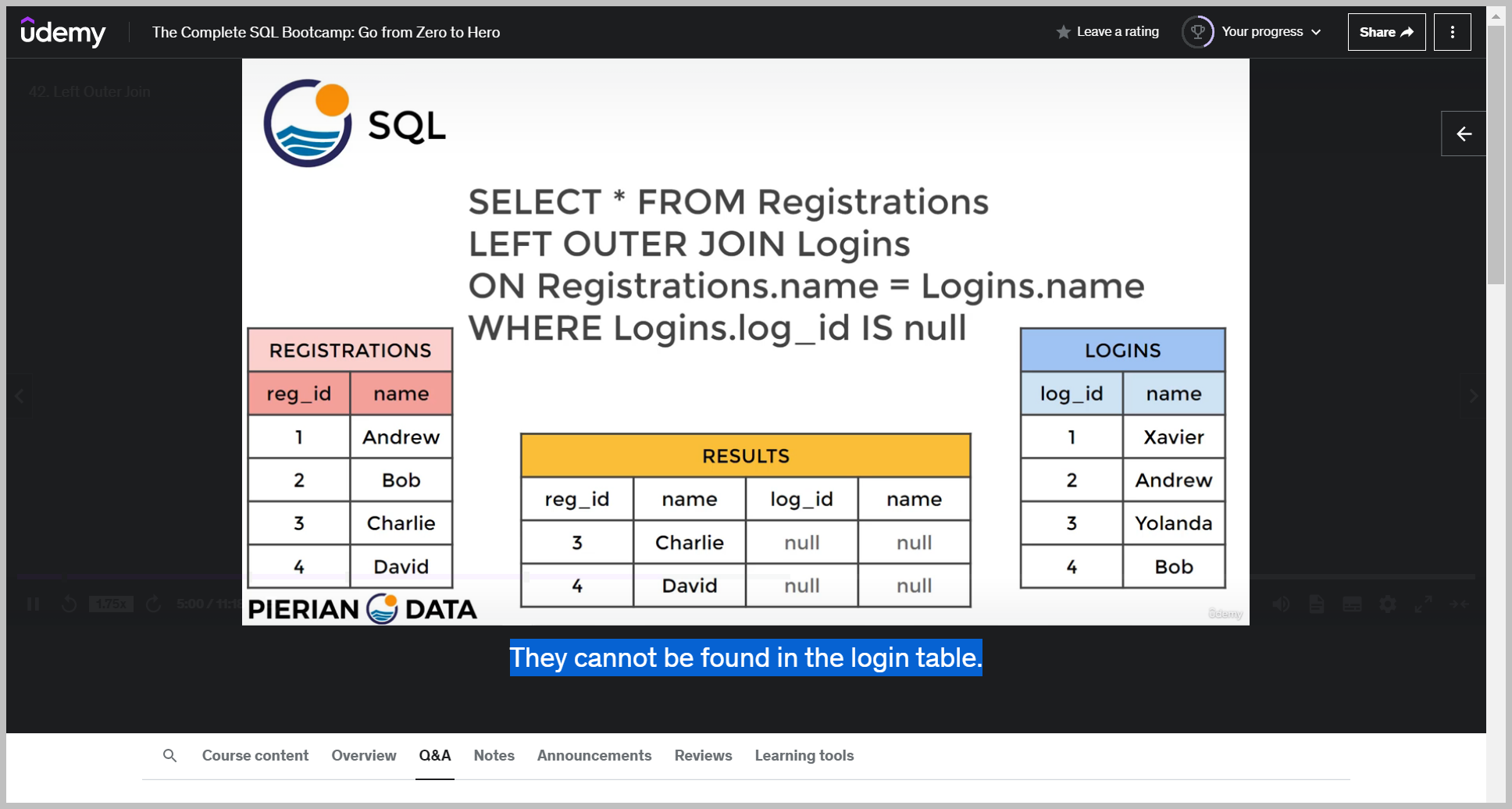
So what we're going to say here is go ahead and grab wear log in, log ID is null.
And because the logins ID that is from the right hand table or table B was null, this answers the question that these particular rows are exclusive to the left hand table or the registrations table.
예제2
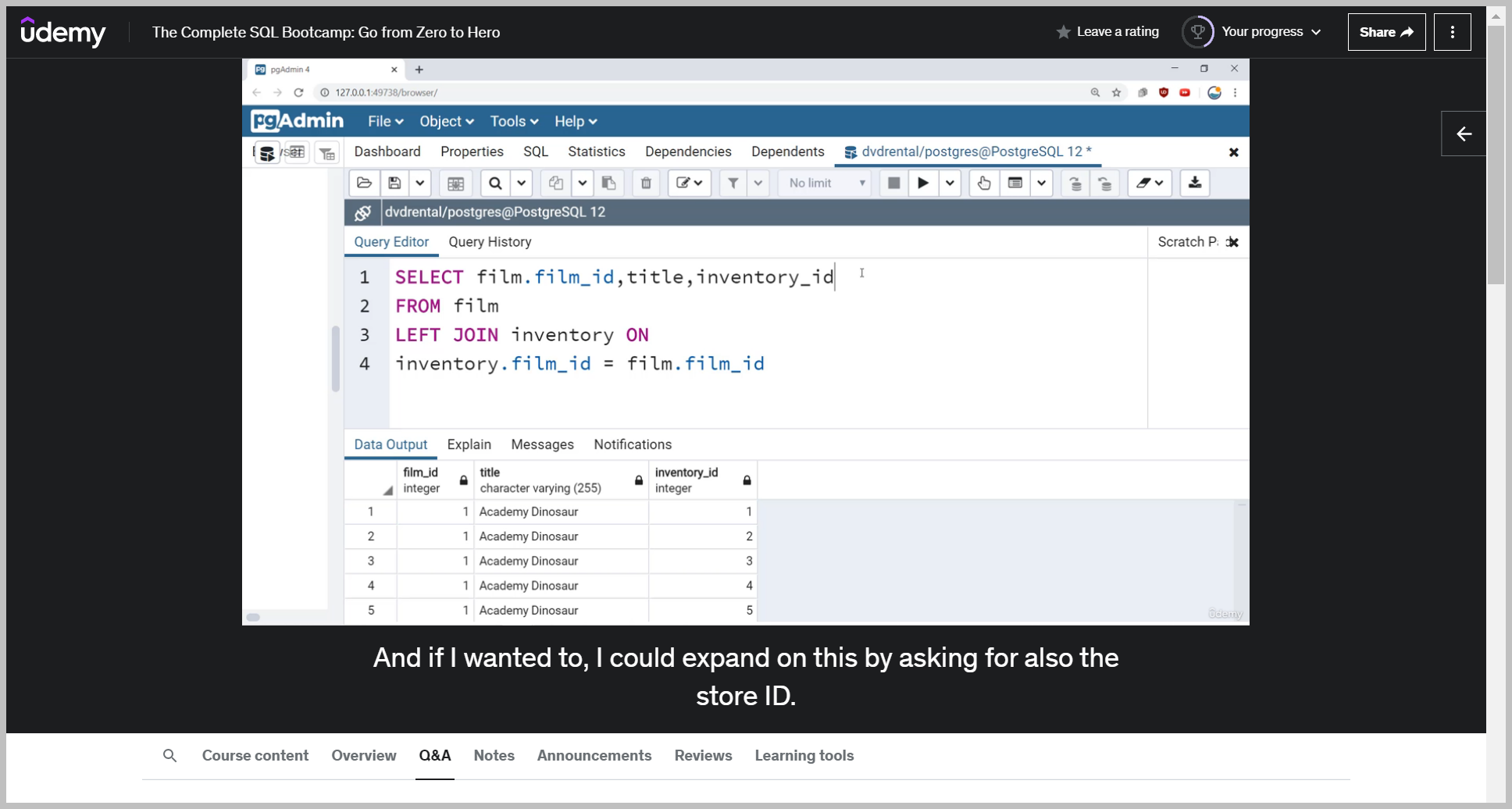
So that is a left join essentially showing us the left joining of film on inventory.
Because film is on the left hand side, I'm only going to see rows that are either in just the film table or in both film and inventory.
Right now, I am not seeing any films where they happen to only be in inventory for some reason but not have some sort of title attached.
So because some rows in the film table do not have corresponding rows in the inventory table, we would see that the values of the inventory ID are null.
RIGHT JOIN
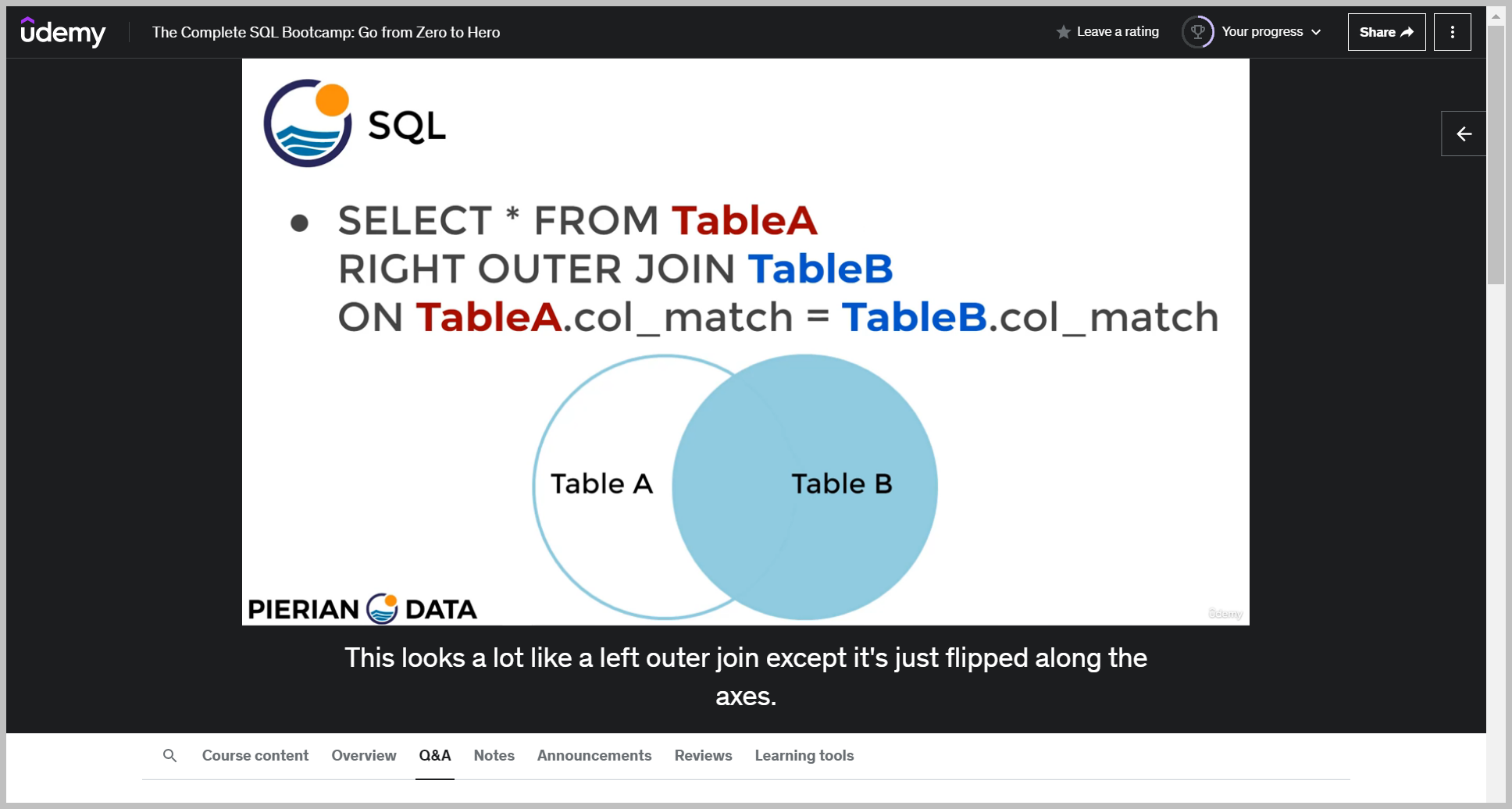
And what this saying is return back rows that can be found either exclusively in table B or in both Table B and table A and do not return back rows that are exclusively only found in table A notice how this would have been the exact same thing as a left join had we just switched around the table order.
null
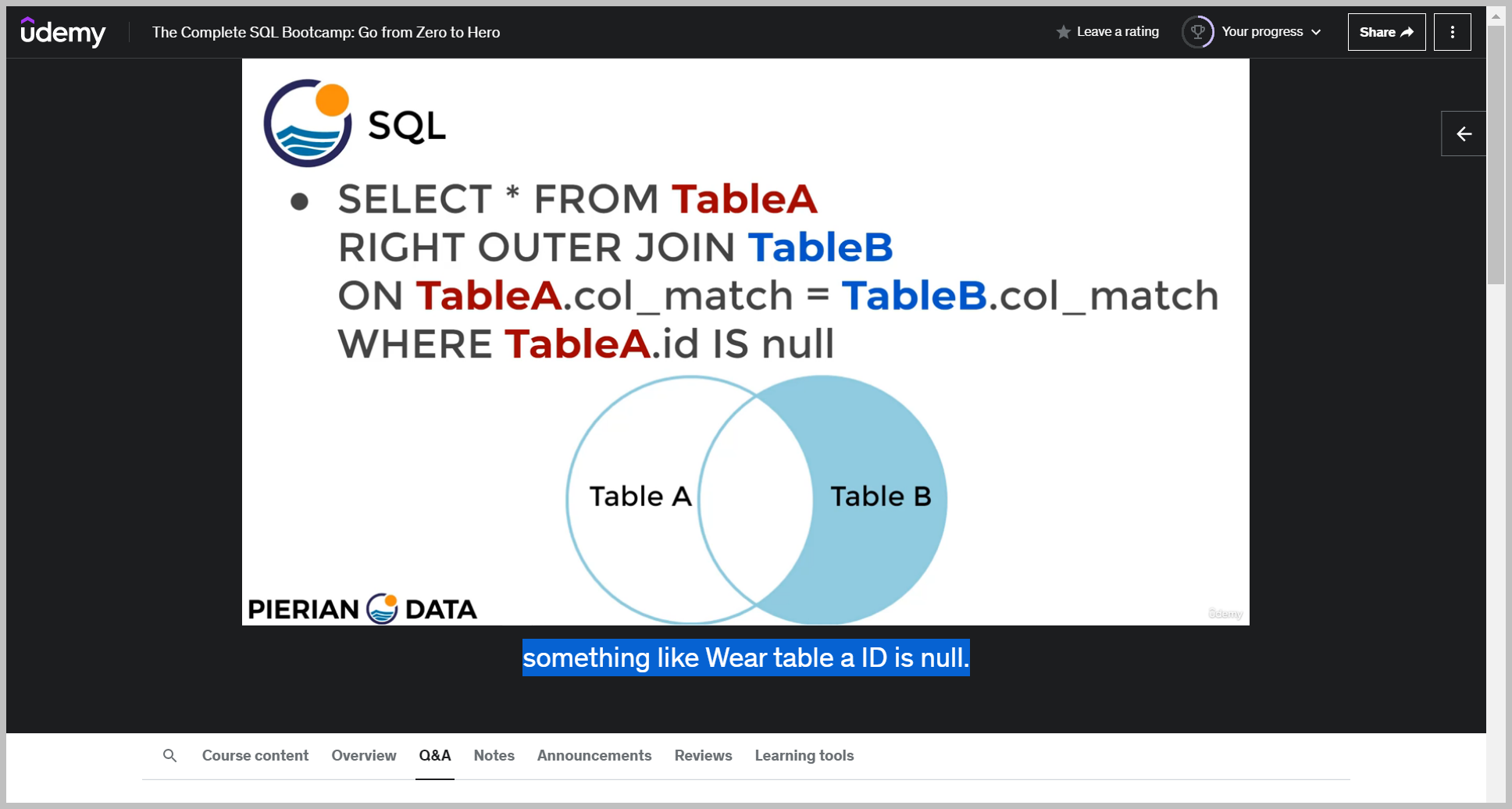
And just like we could with a left outer join, you can also add a clarifying wear statement to say something like Wear table a ID is null.
In order to clarify that, you only want tables that can be found exclusively in Table B and are not found in Table A.
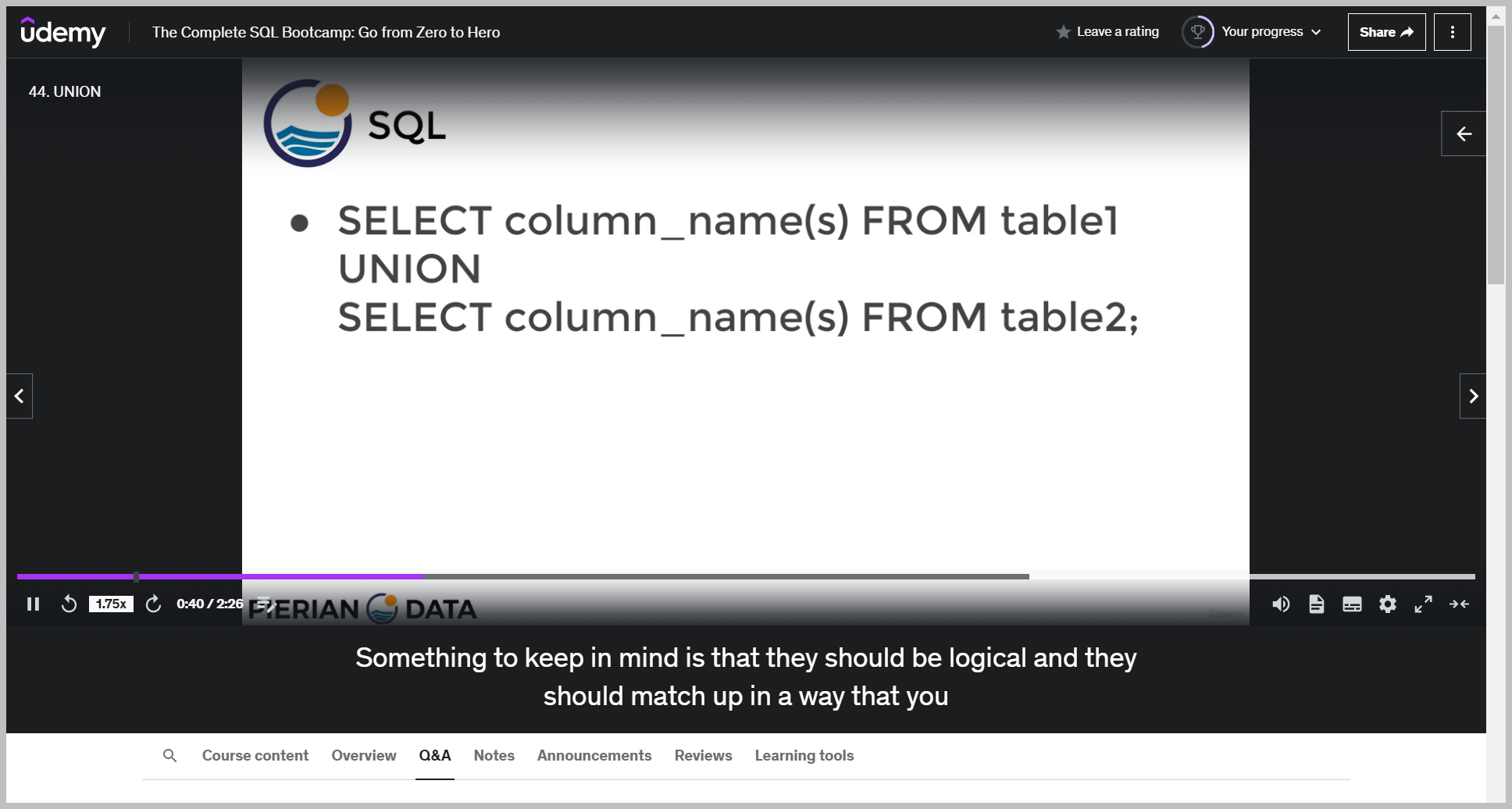
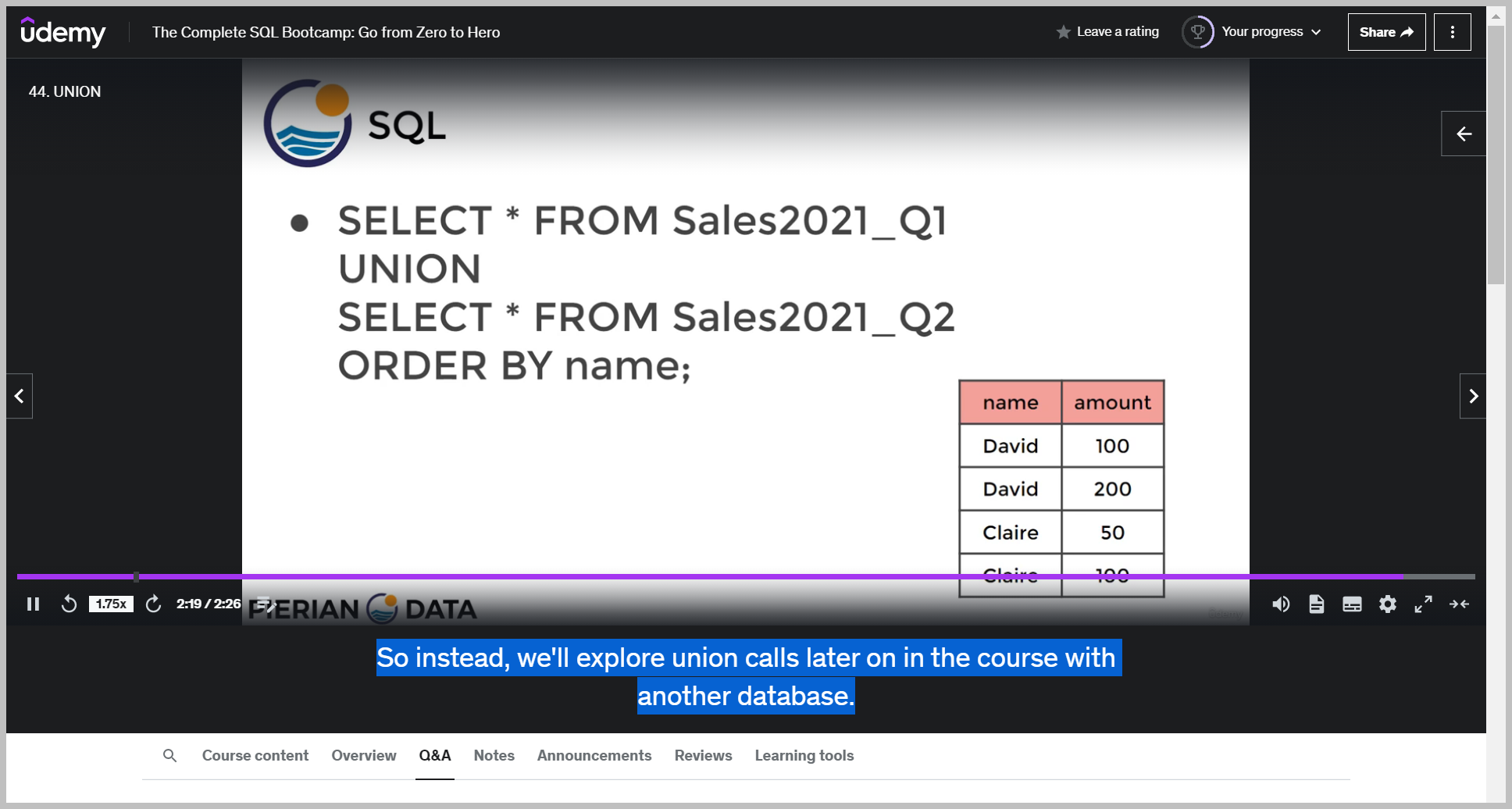
UNION
기본 문법
예제
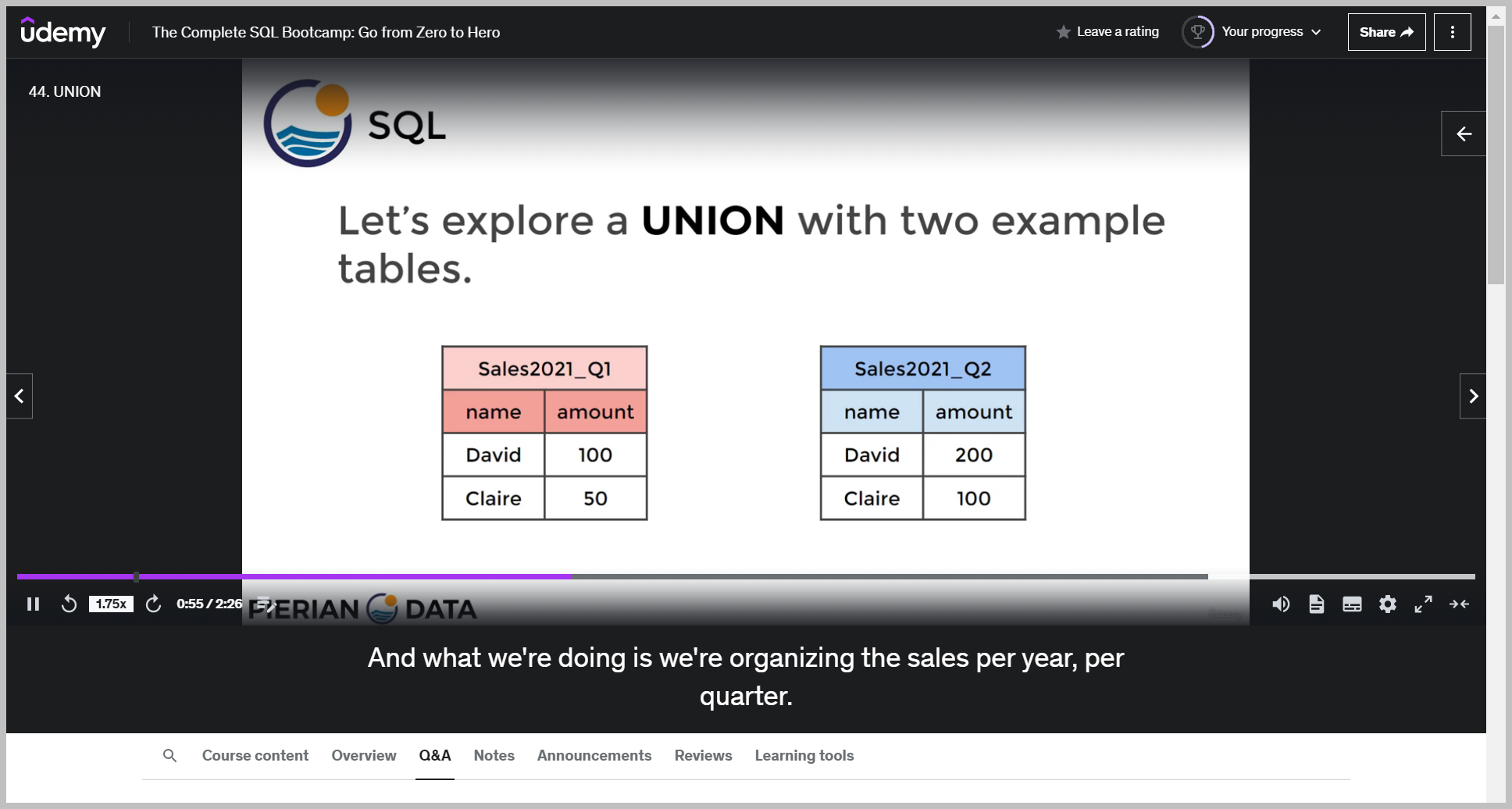
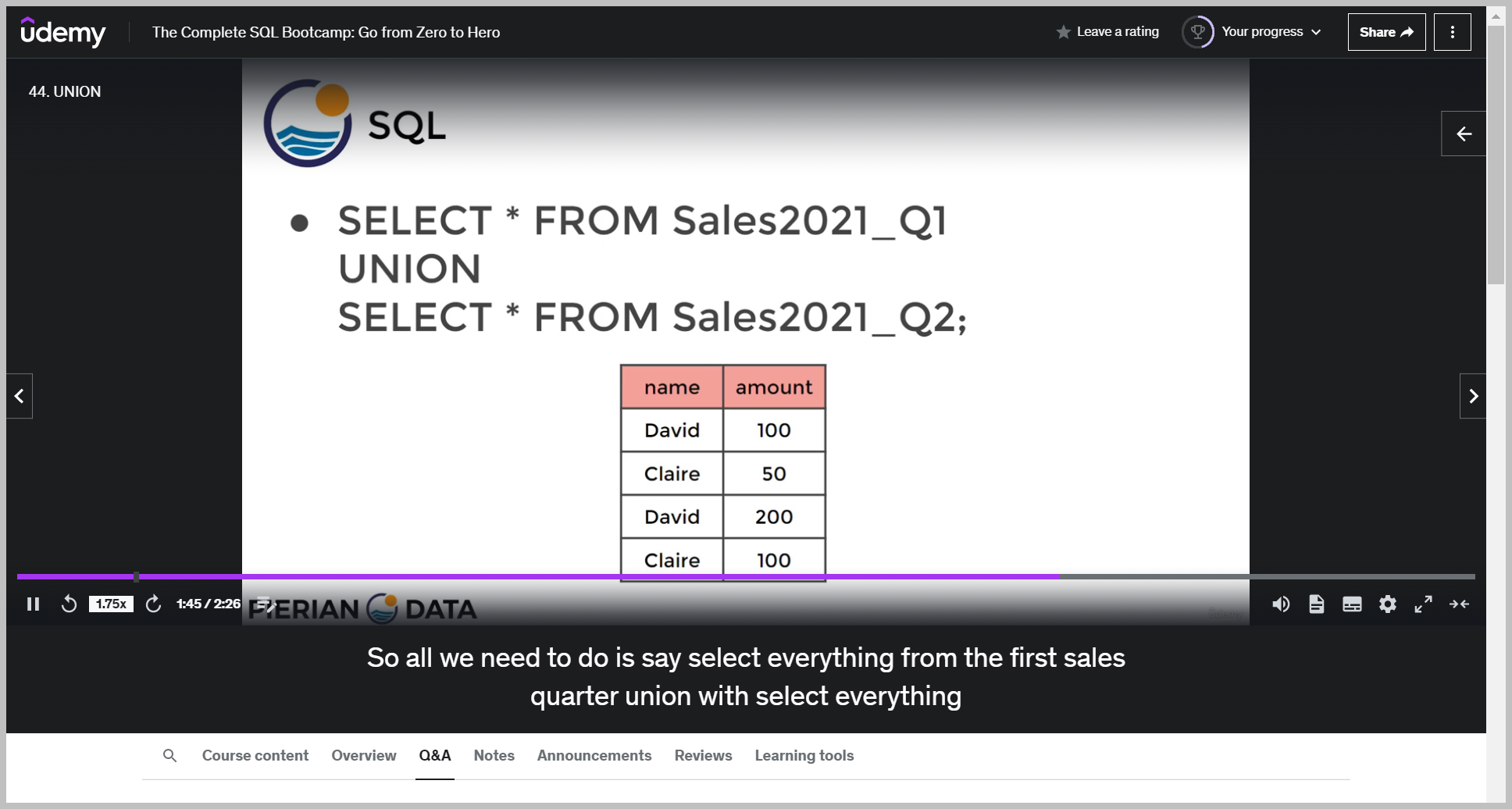
And what it's going to do is just grab the results from the first query and then paste them right on top of the second query.
SQL 명령어들
SHOW ALL
TIMEZONE()
NOW()
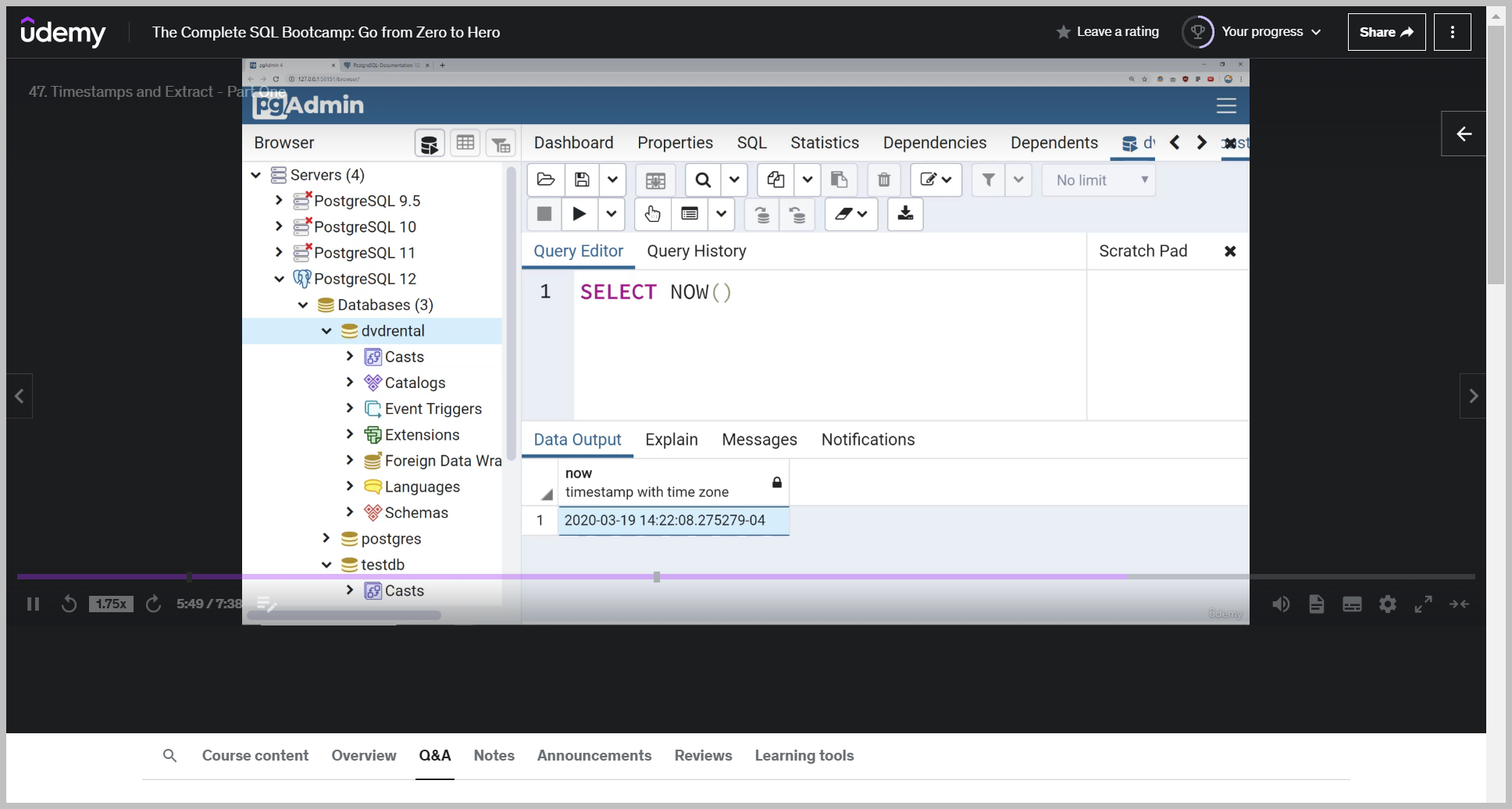
So it's now open and close parentheses, which basically just says, give me the time stamp information
TIMEOFDAY()
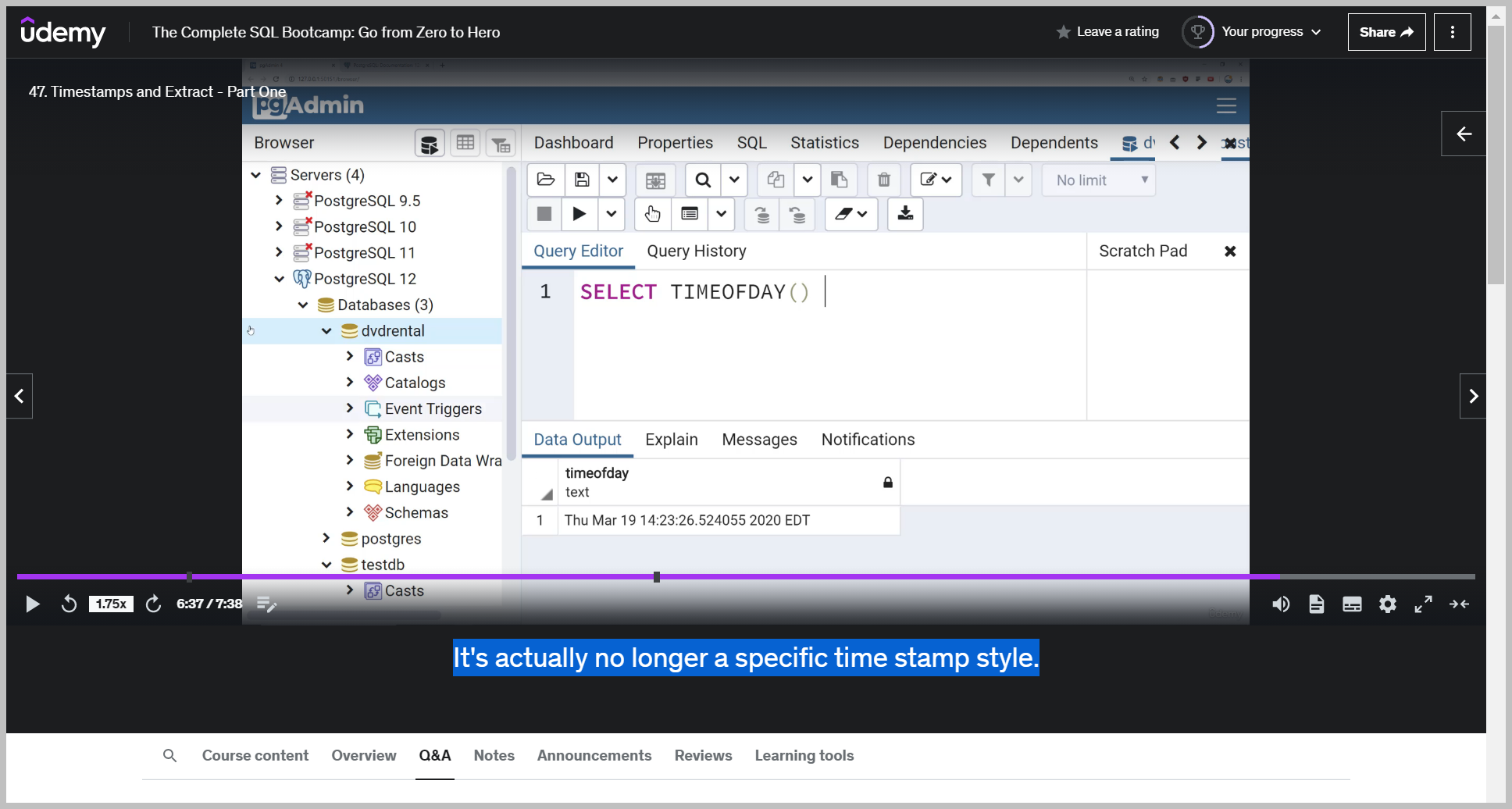
And this returns back basically the same information, but as a string.
CURRENT_TIME
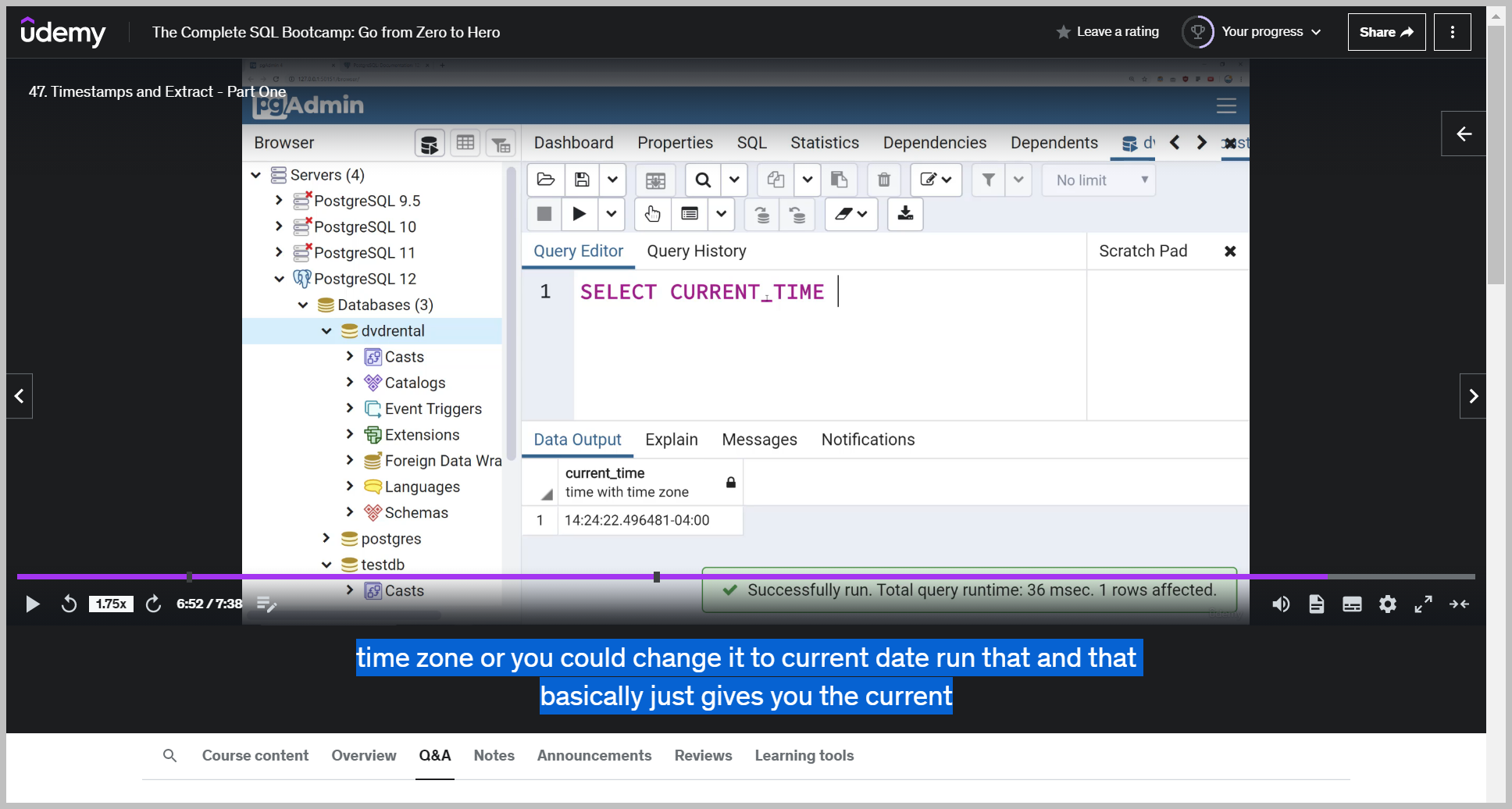
Just the current time which would be select current time run that that gives you just the time with time zone or you could change it to
CURRENT_DATE
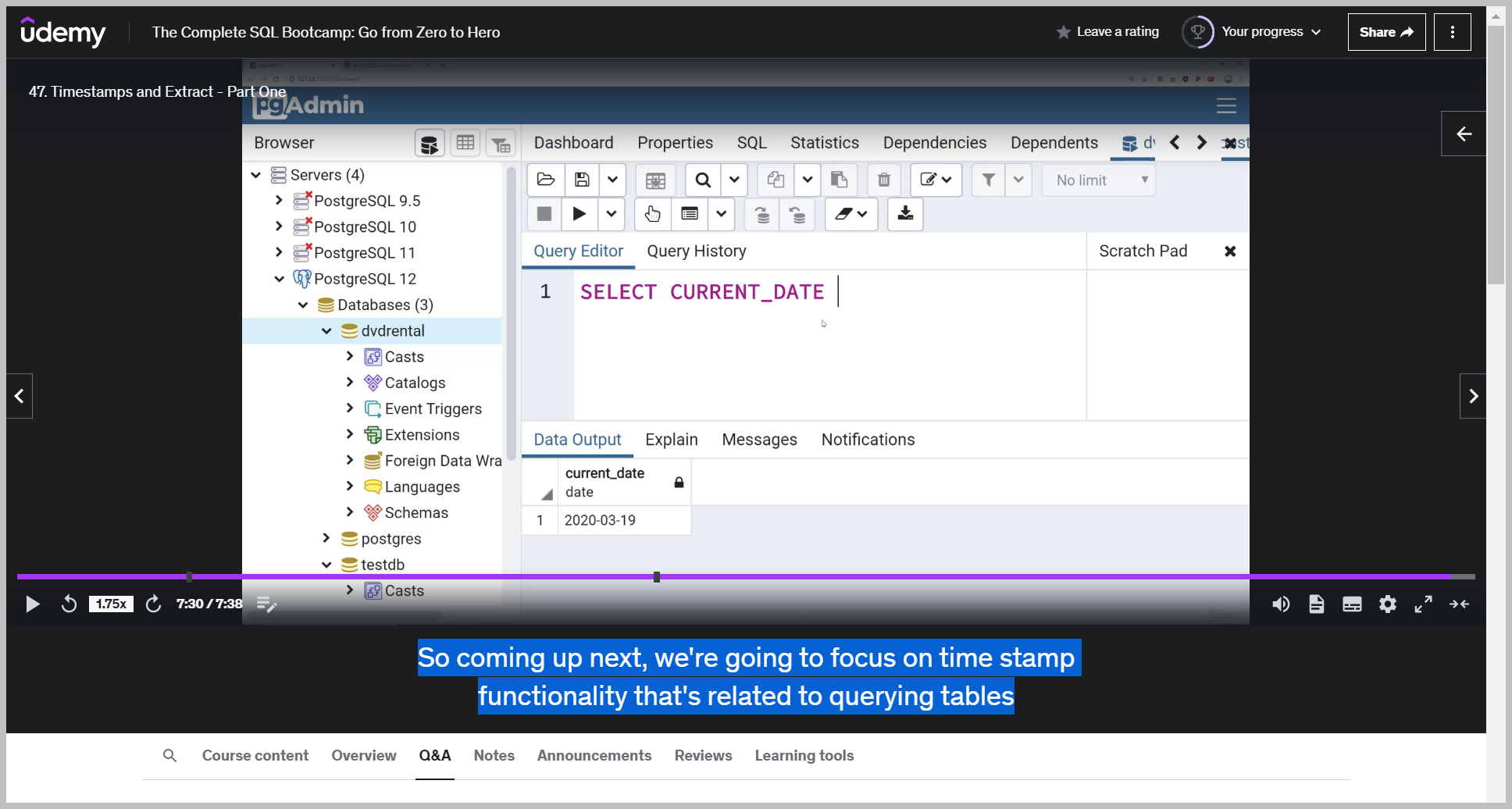
current date run that and that basically just gives you the current
추출 함수들

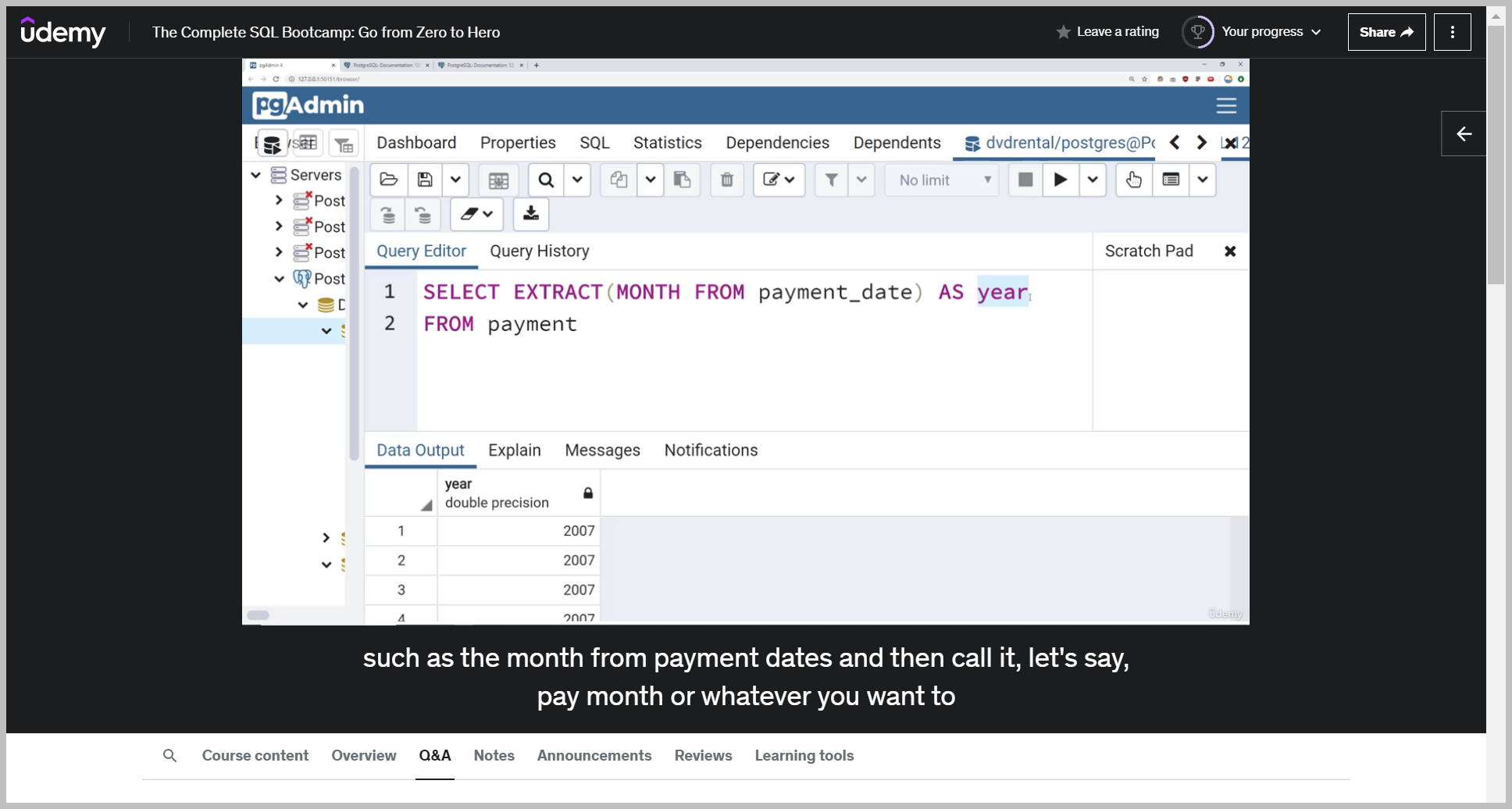
EXTRACT()
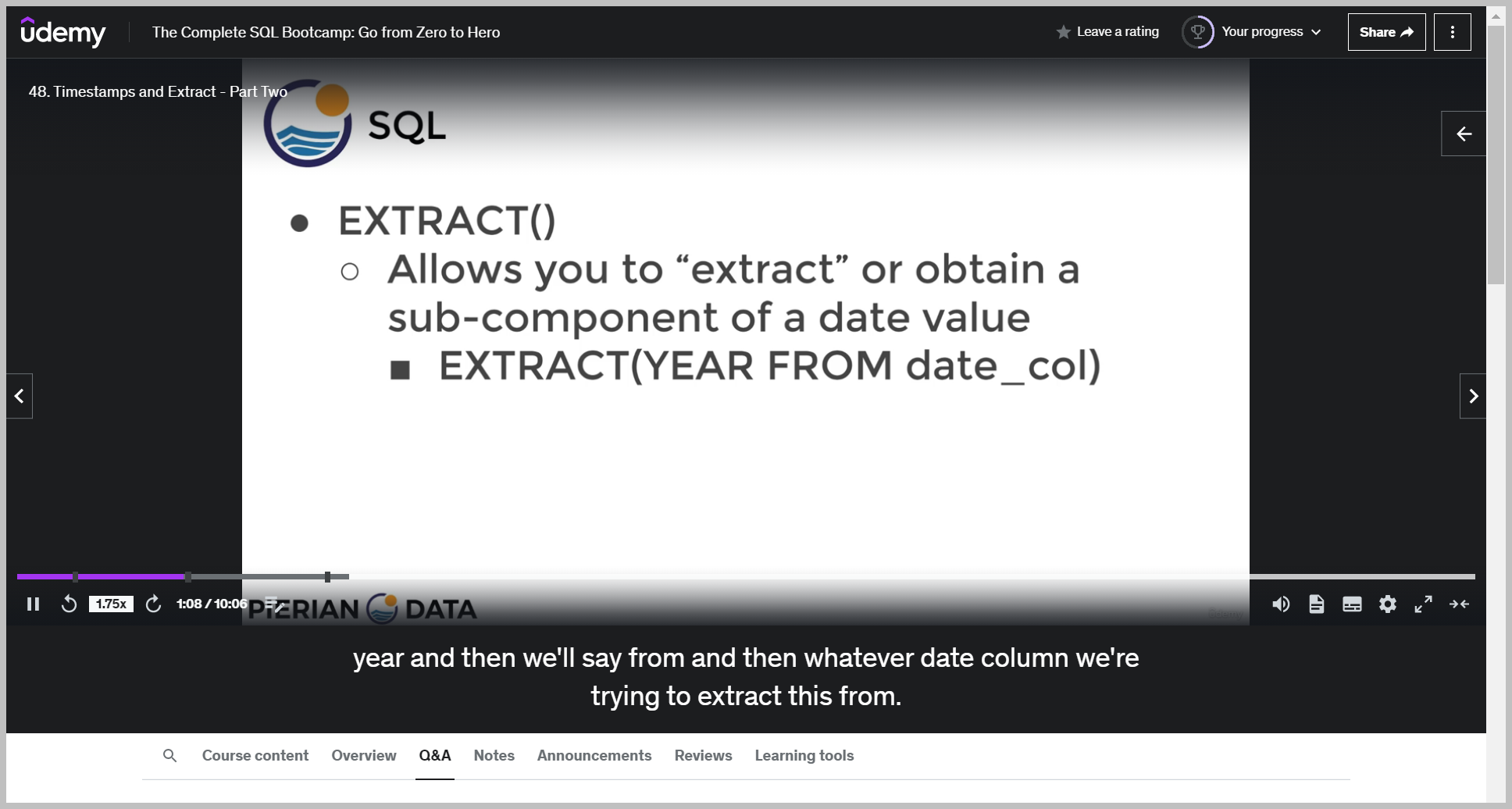
And we put it in all caps, just so it's clear to whoever is reading this that we are extracting the year and then we'll say from and then whatever date column we're trying to extract this from.
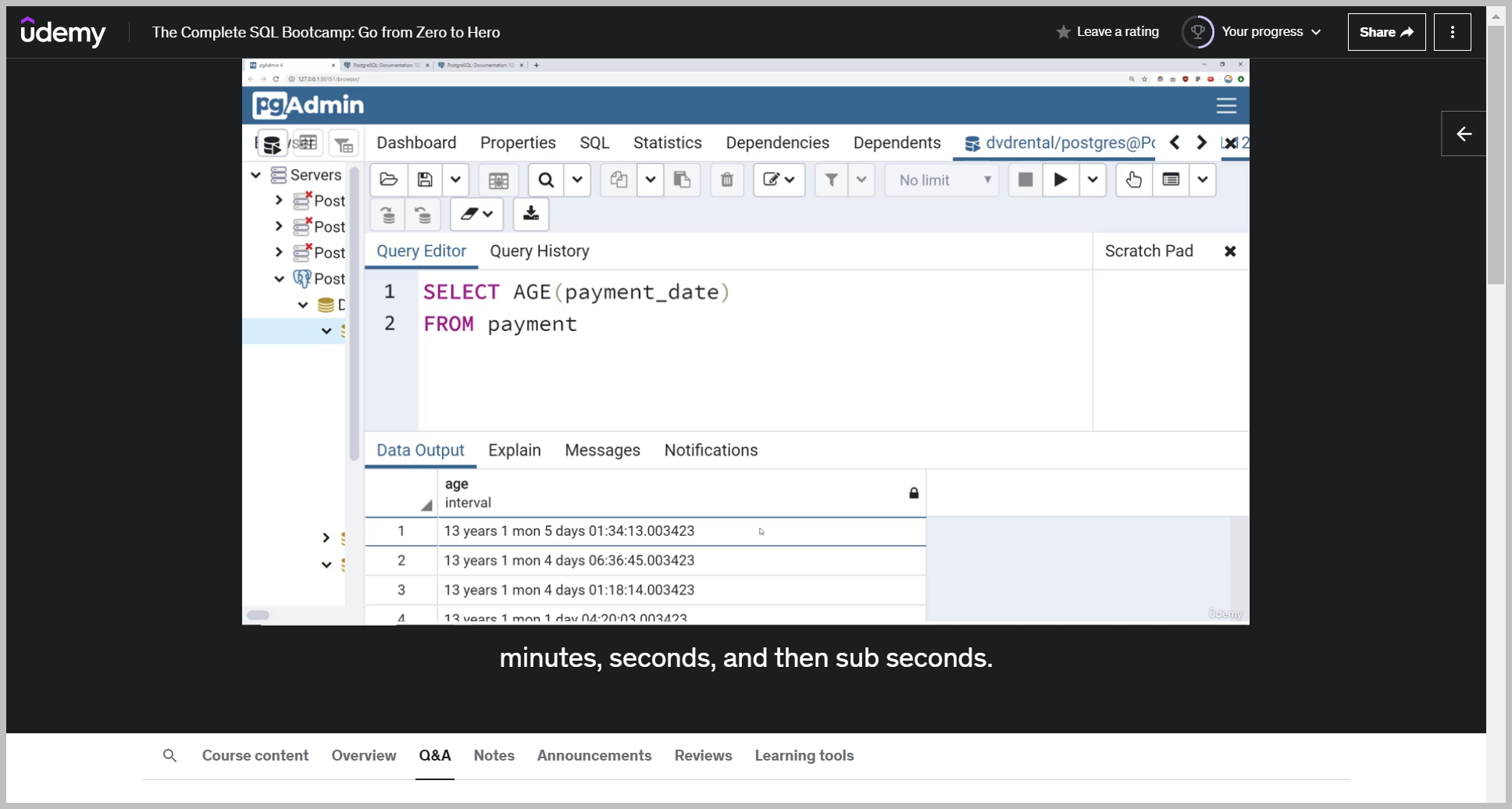
AGE()
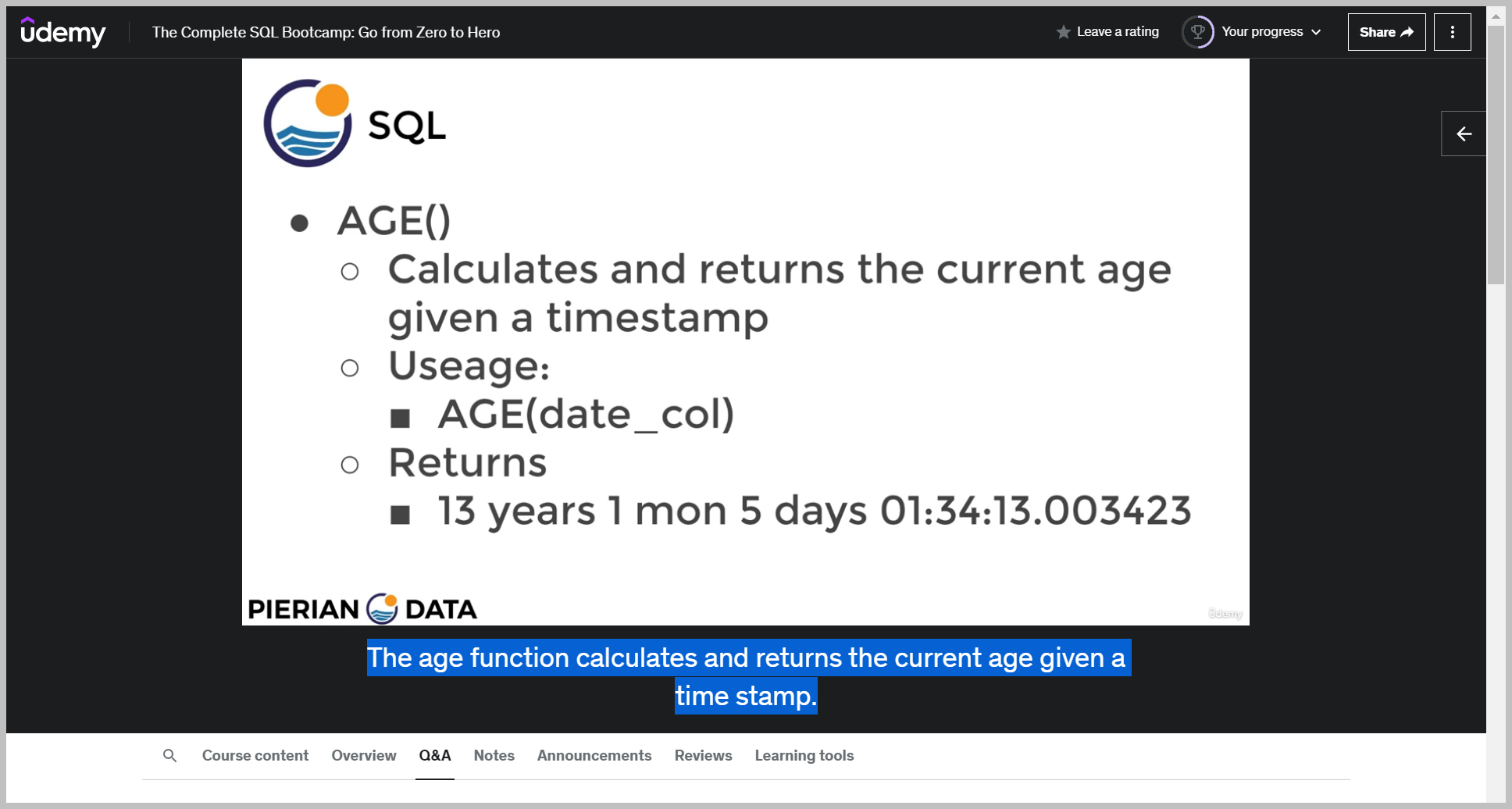
The age function calculates and returns the current age given a time stamp. So you simply just pass in some time stamp column into the age function and that will return something.
TO_CHAR()
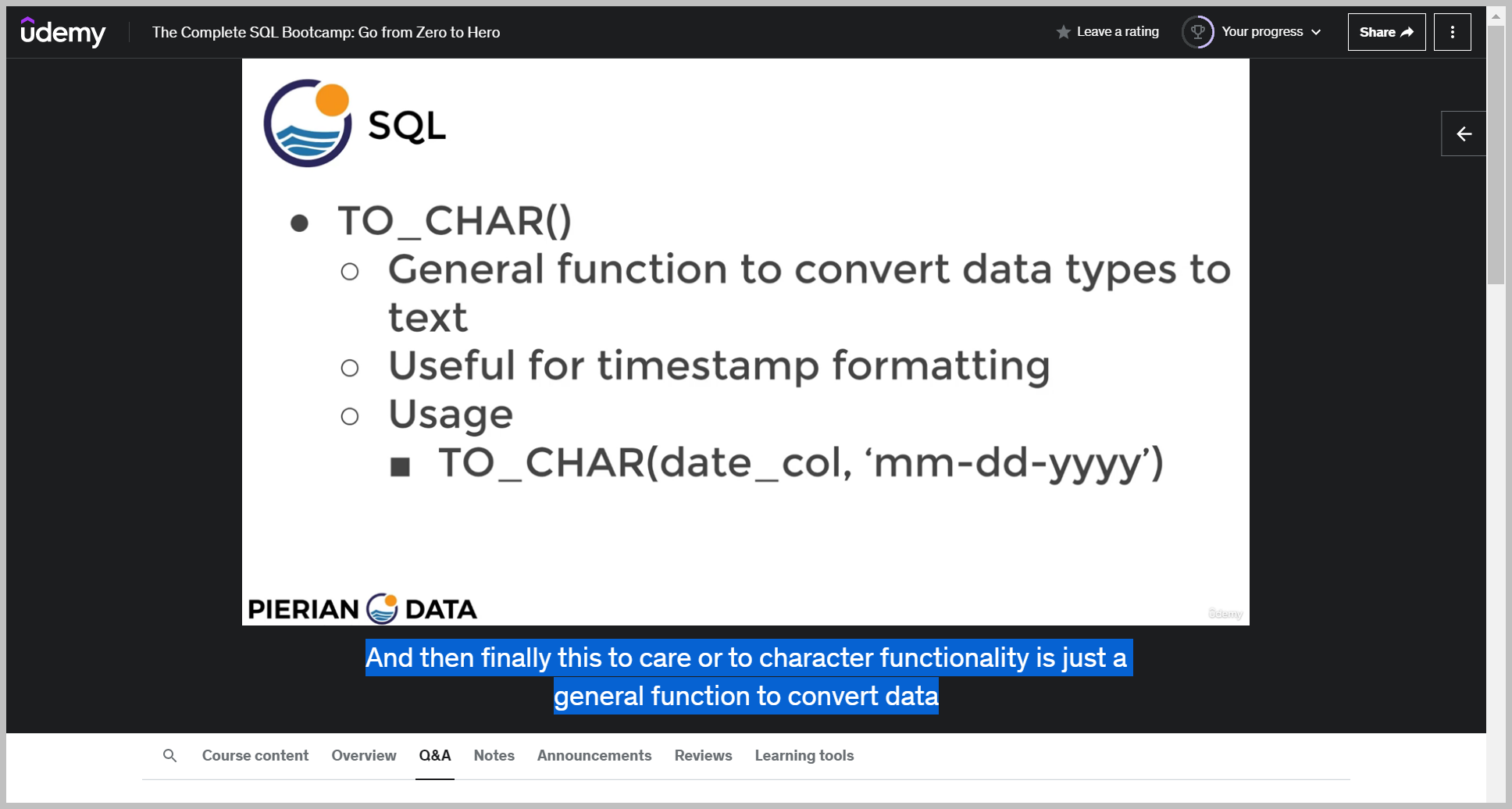
And then finally this to care or to character functionality is just a general function to convert data types to text, and it's actually not explicitly used just for timestamps.
you're going to type in as a first parameter, the date column name and then comma and then as a string parameter, the text formatting you want.
예제
DATE()
AGE()
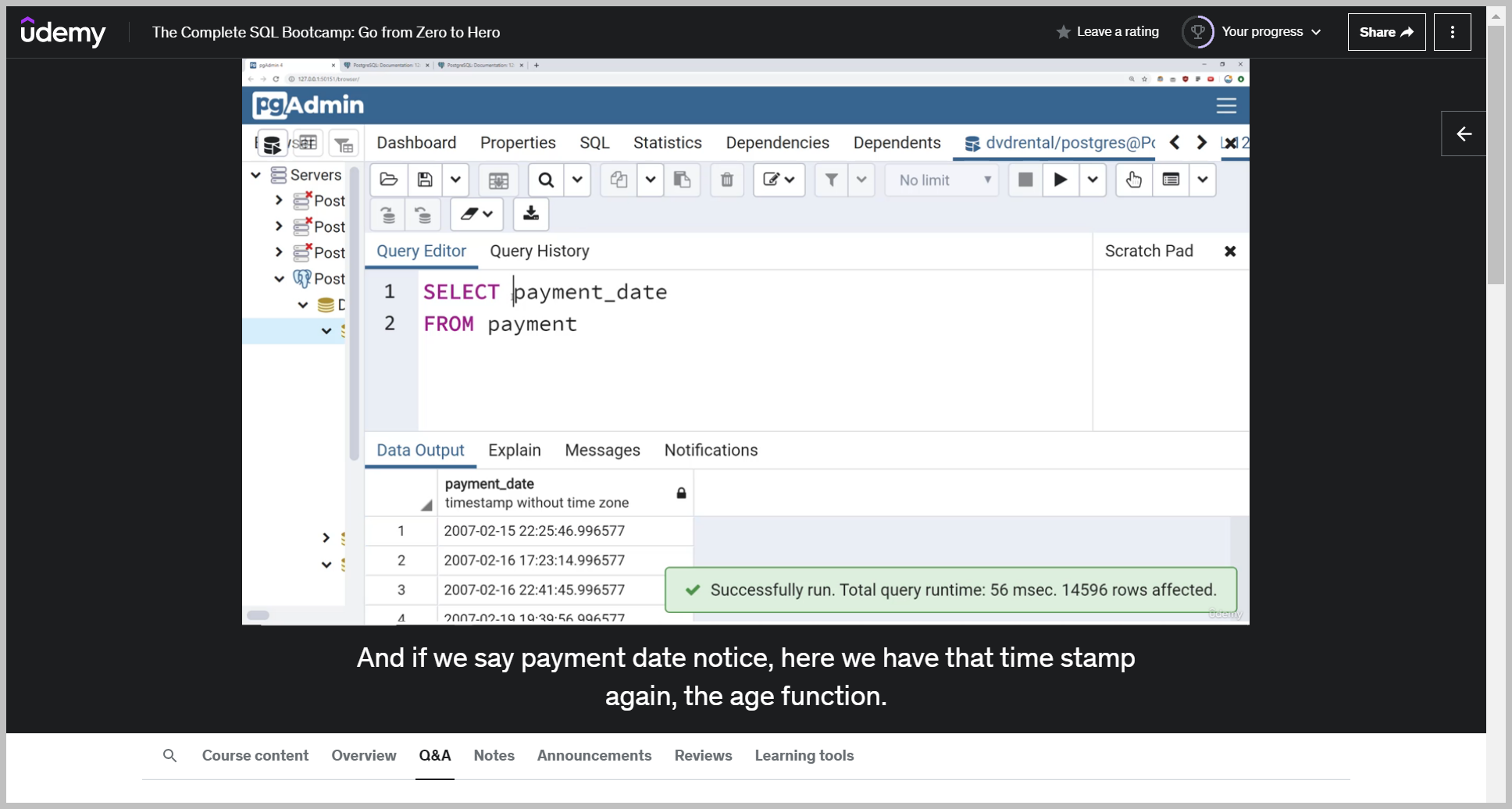
TO_CHAR()
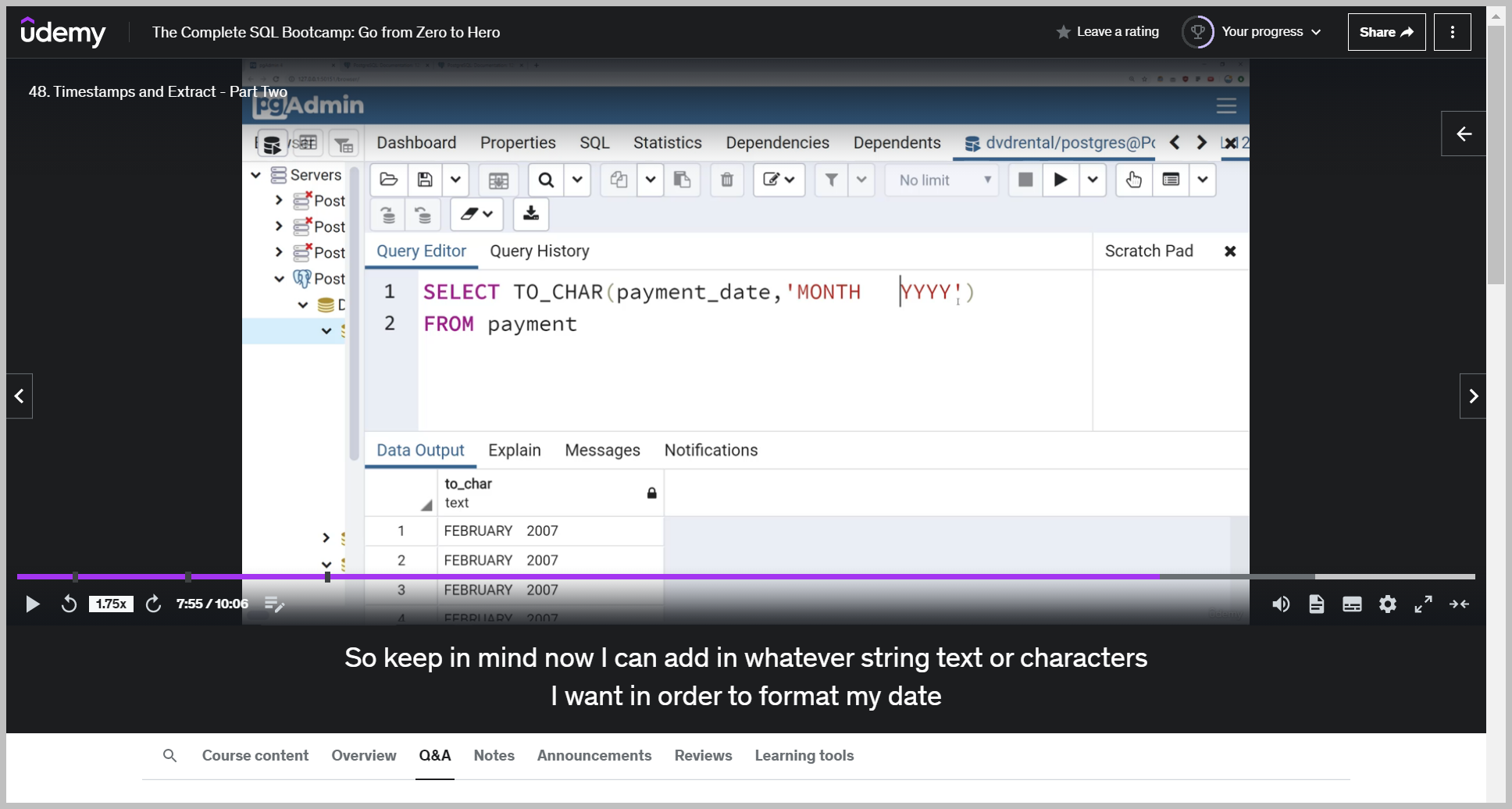
So keep in mind now I can add in whatever string text or characters I want in order to format my date as I so choose.
STRING 함수
CONCAT
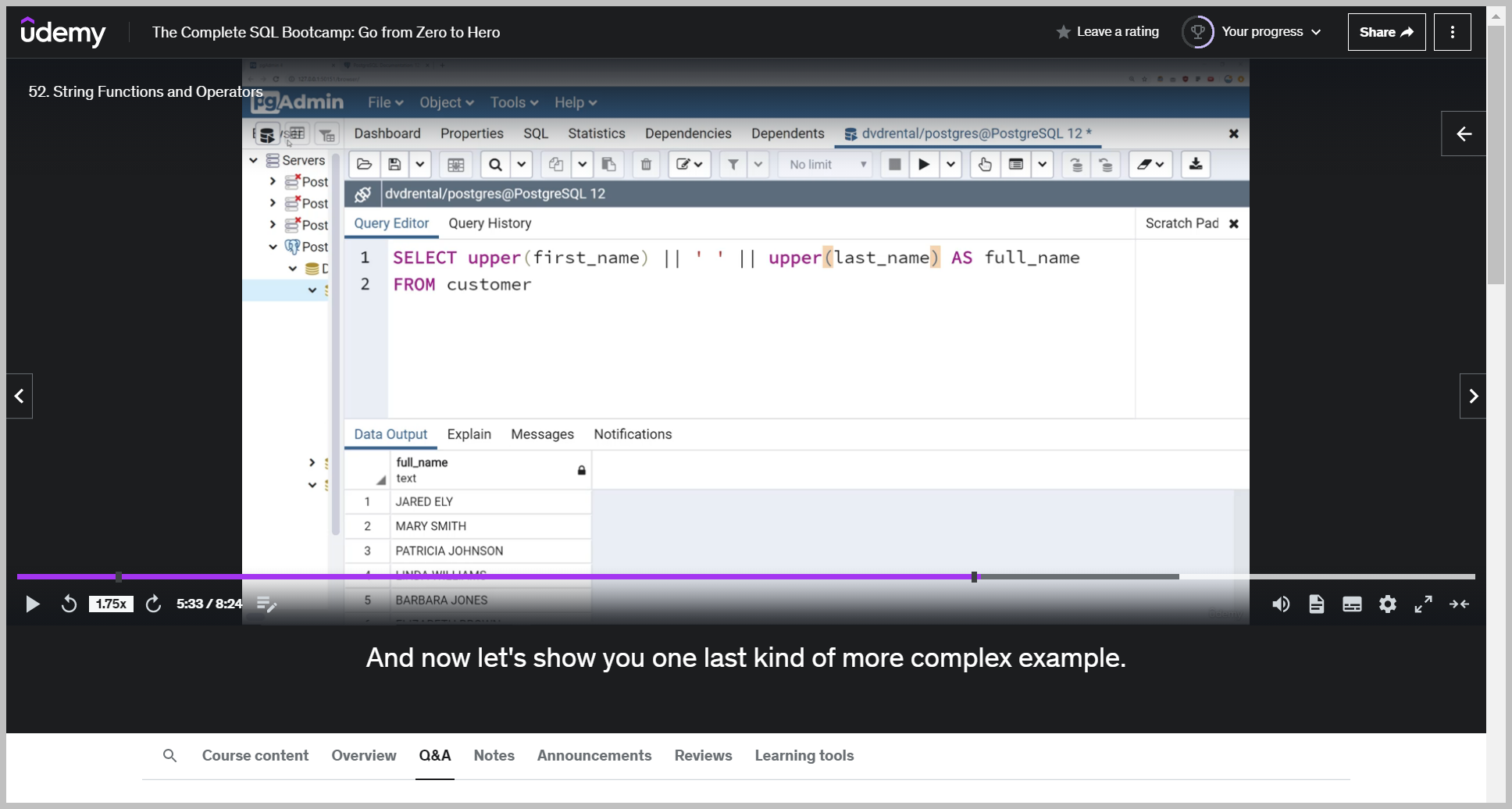
LEFT()
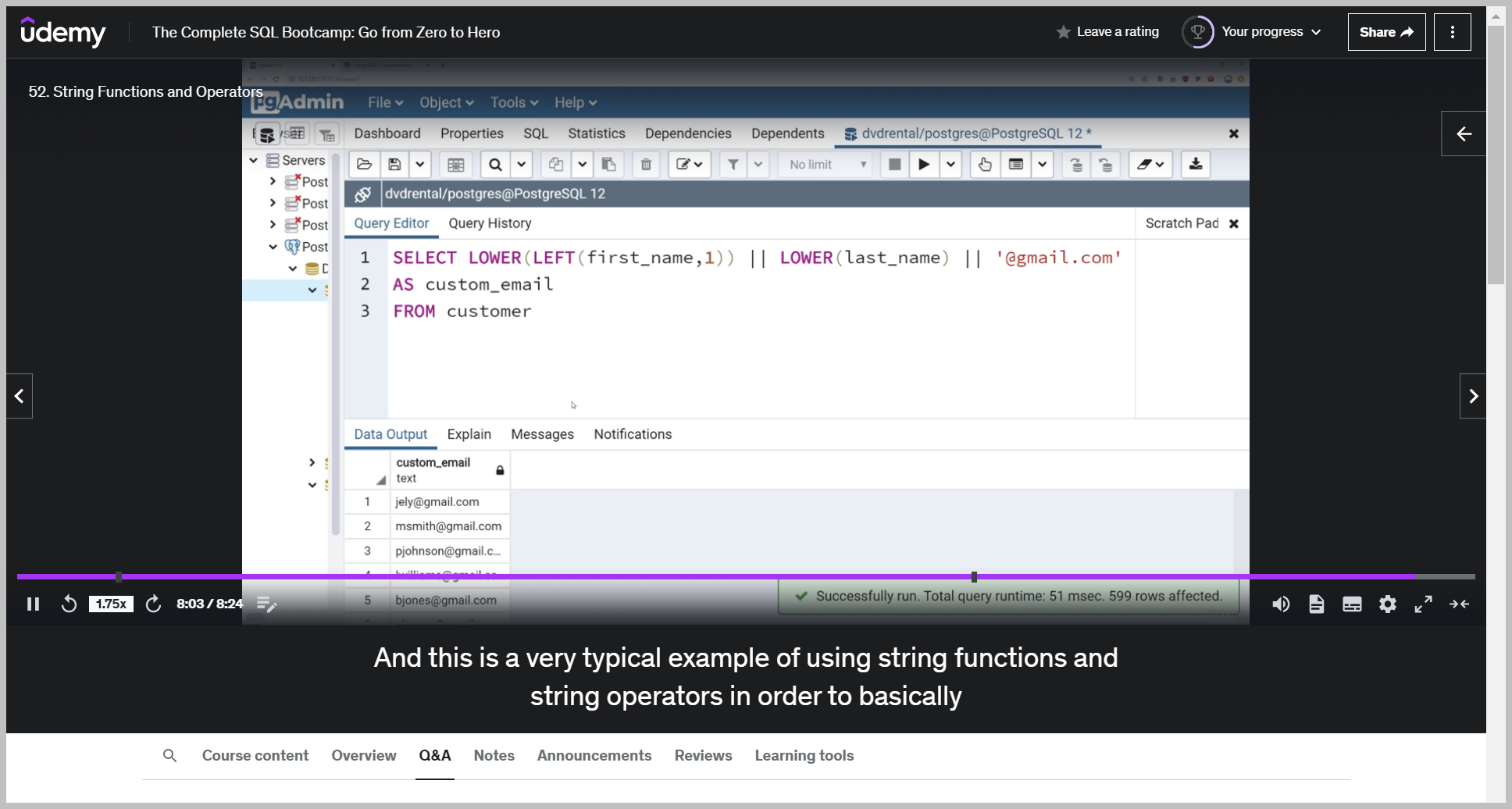
SUB쿼리
예제
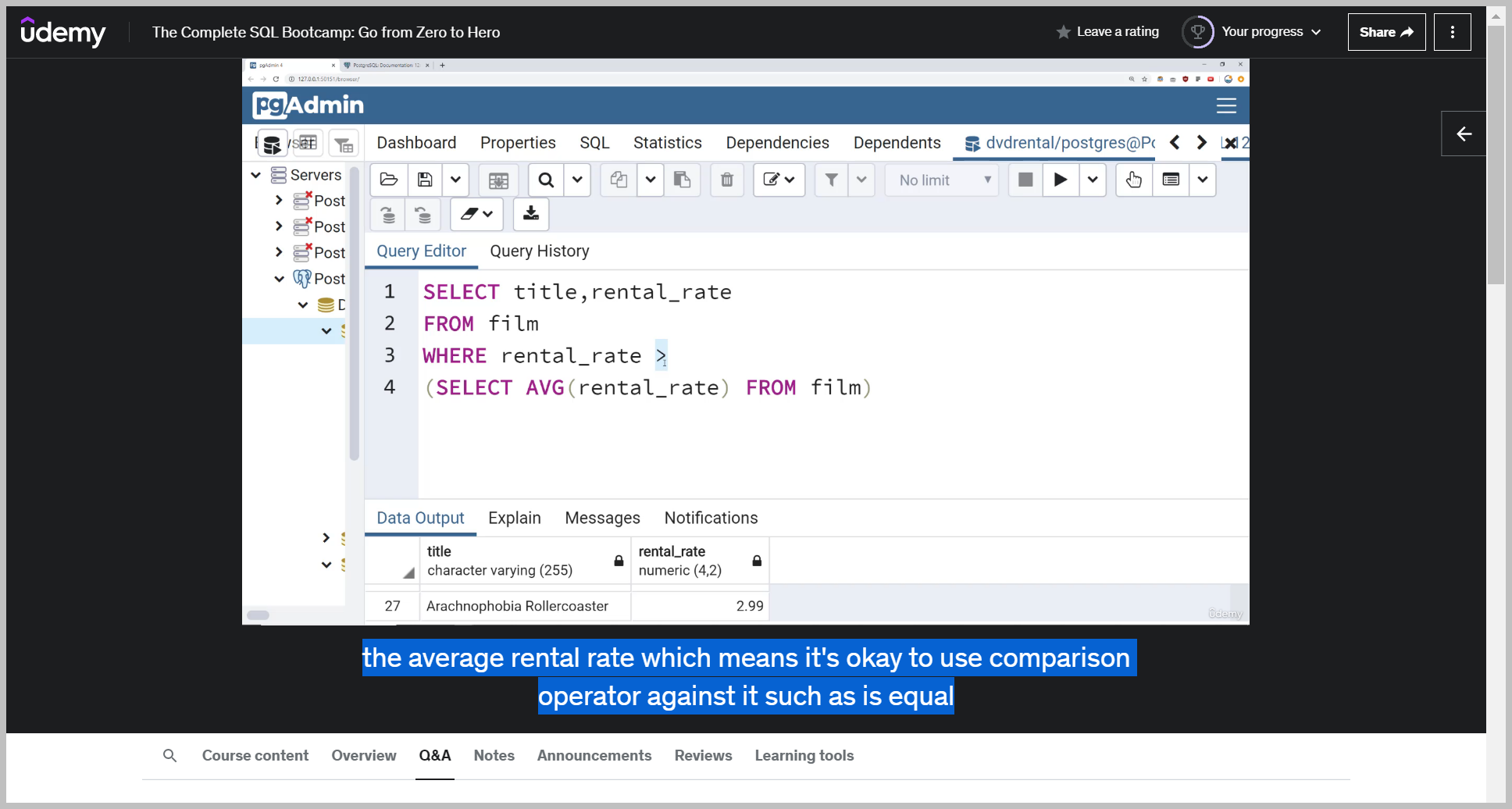
notice here that the subquery in parentheses will get executed first in order to calculate that average, and then it becomes part of this larger query. The other thing that's important to notice is this particular subquery returns back just a single value,
IN 연산자
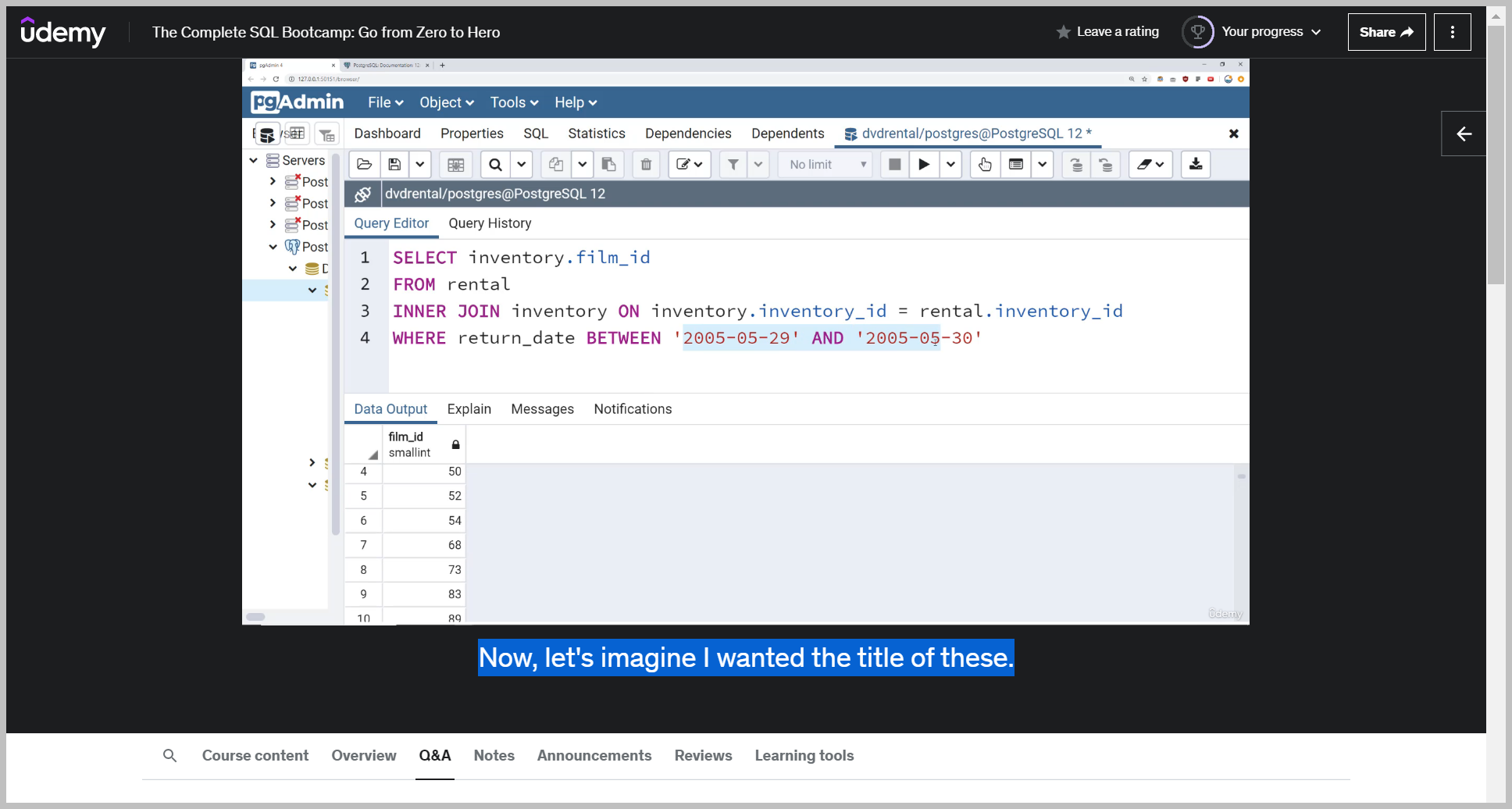
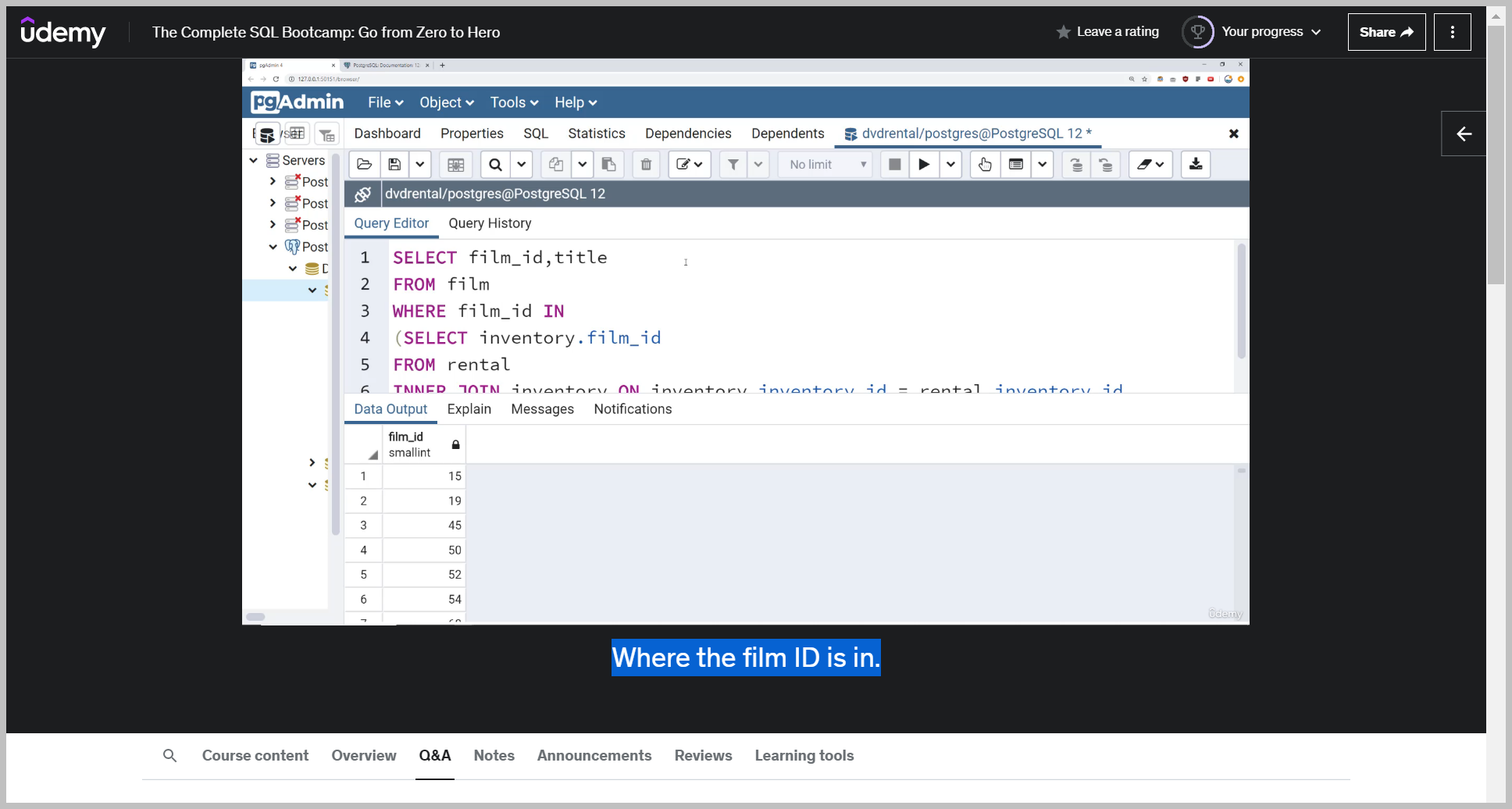
Now, let's imagine I wanted the title of these.
If your subquery however returns back multiple values, then you need to use the in operator on it.
Note This subquery is returning back multiple results so I can use the inner operator.
EXIST 연산자
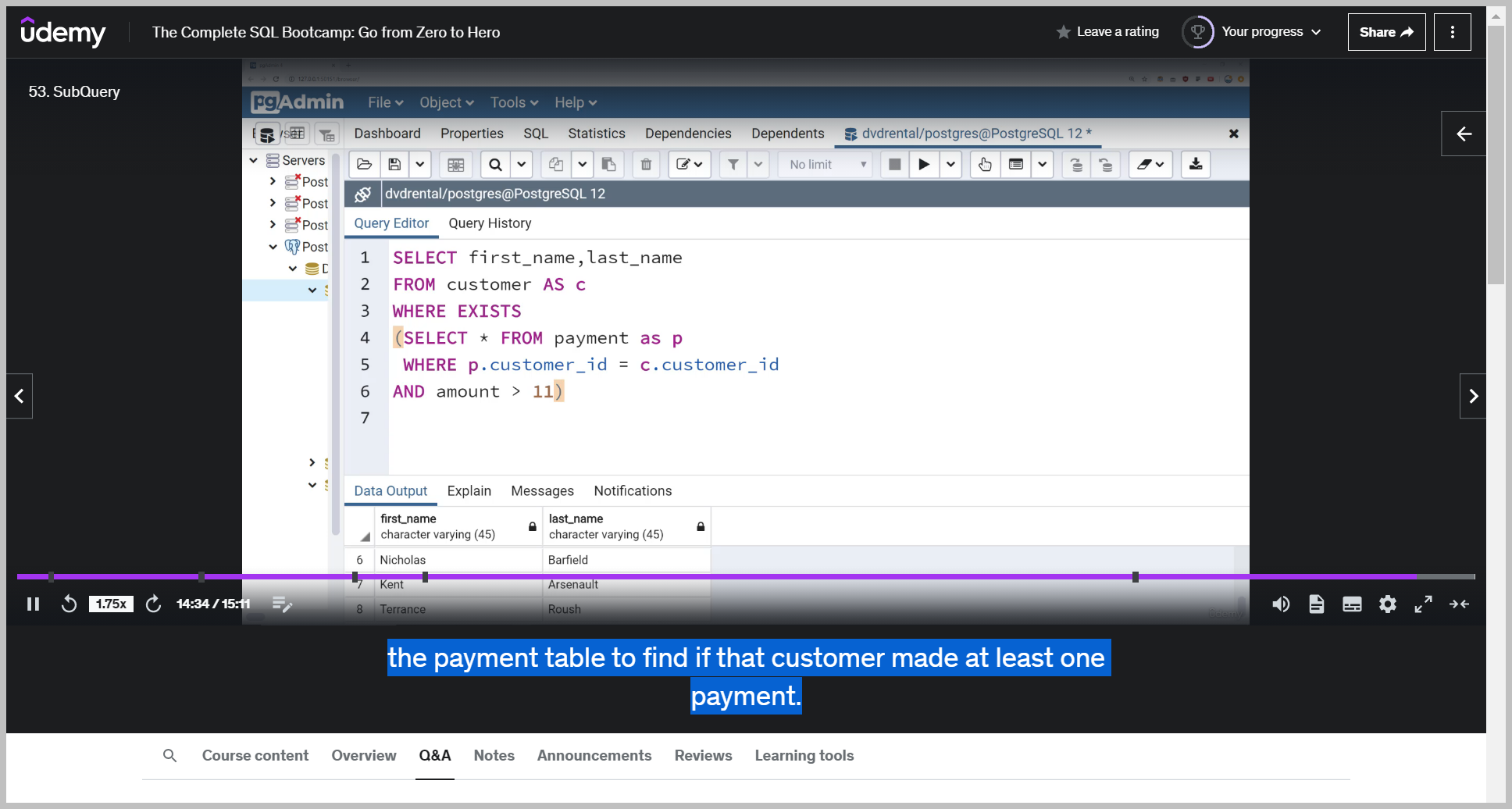
So know what we're doing here.
We're going to say select the first name and last name from the customer table where and then the exists Operator is checking to see if any rows are returned based off this subquery where we're saying select everything from the payment table, where the payment customer ID matches the customer ID and the amount they paid, which comes from the payment table.
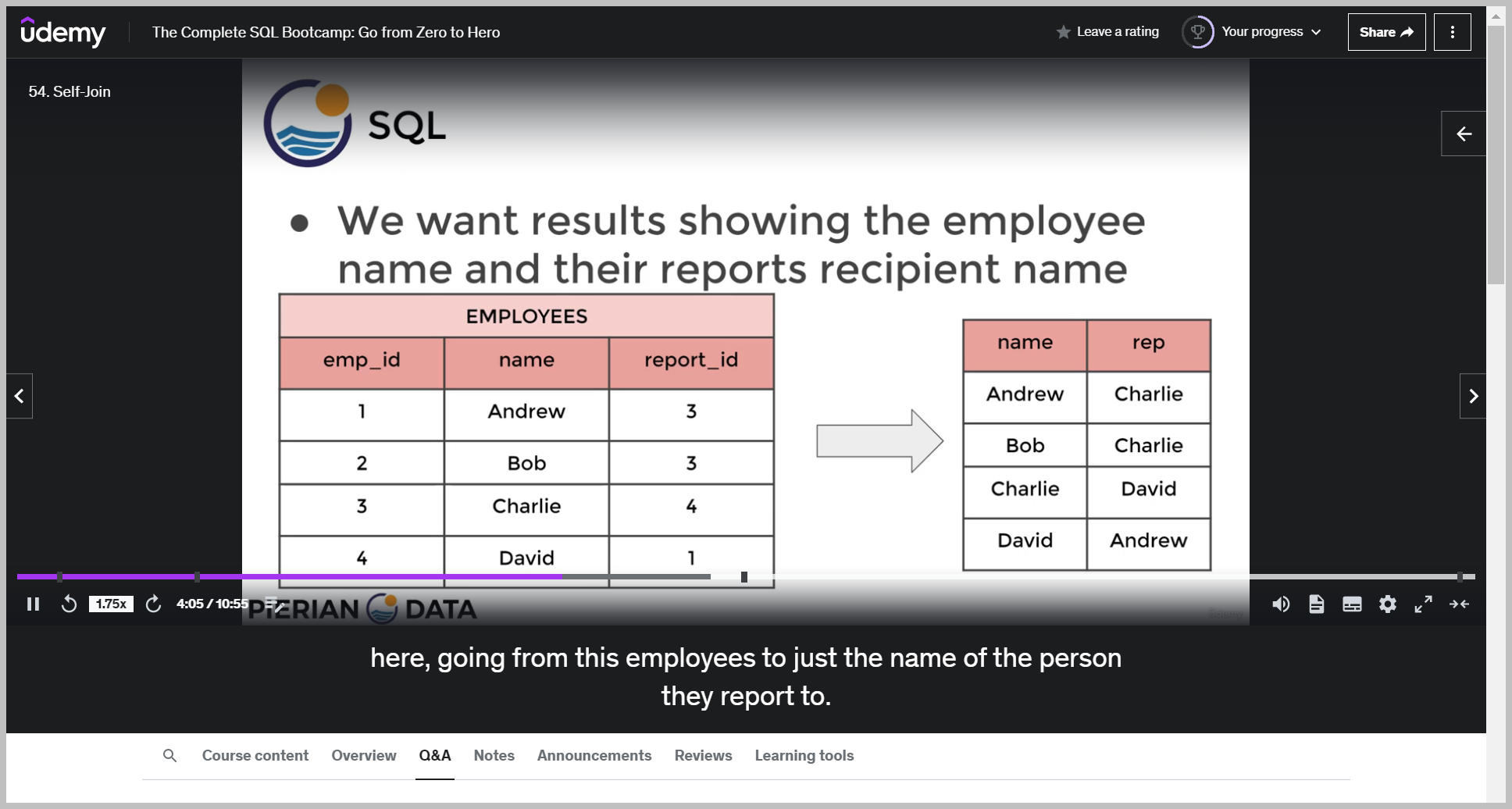
Self-join
기본 문법
예제
1. table
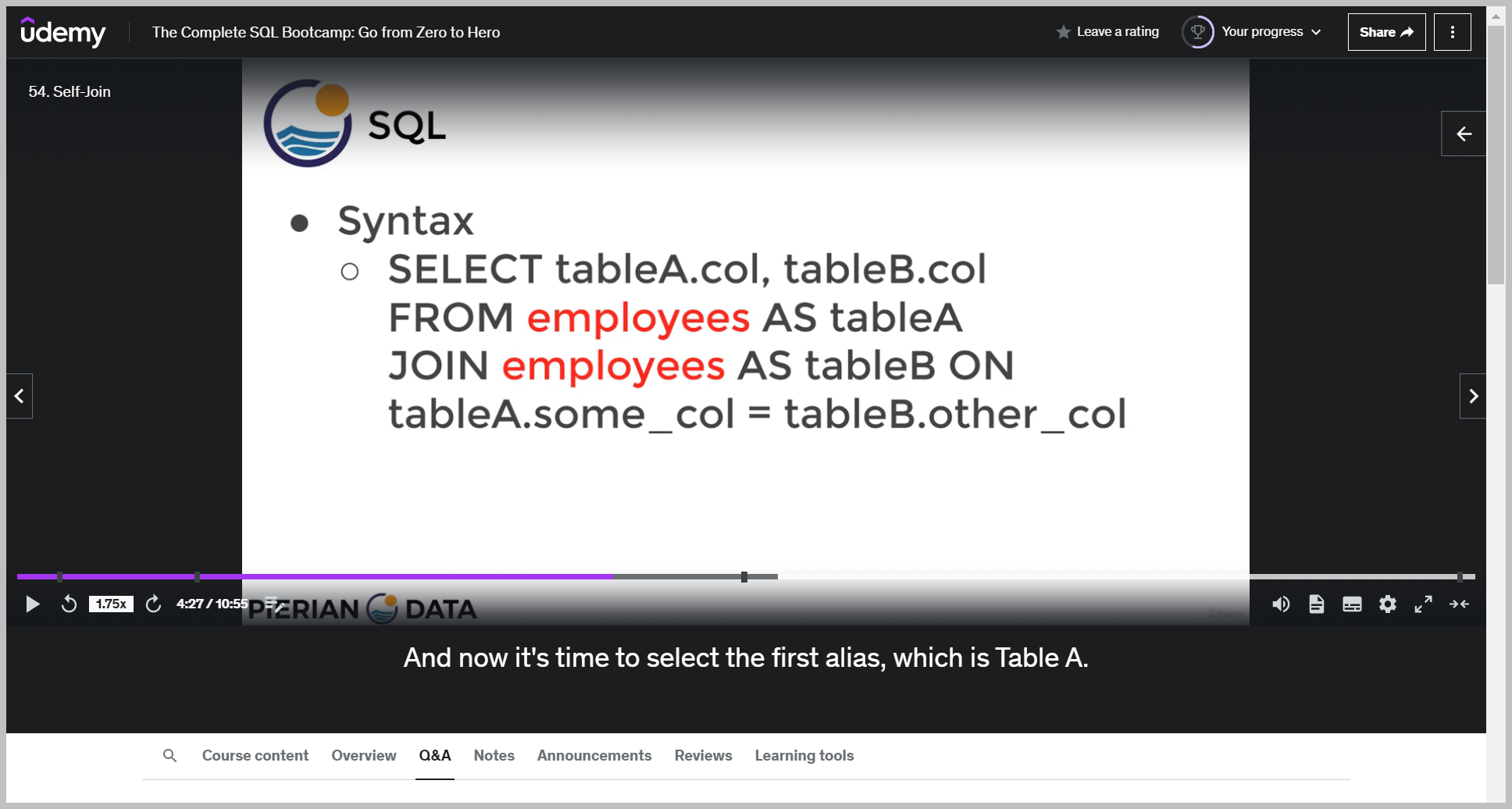
2. table A.col
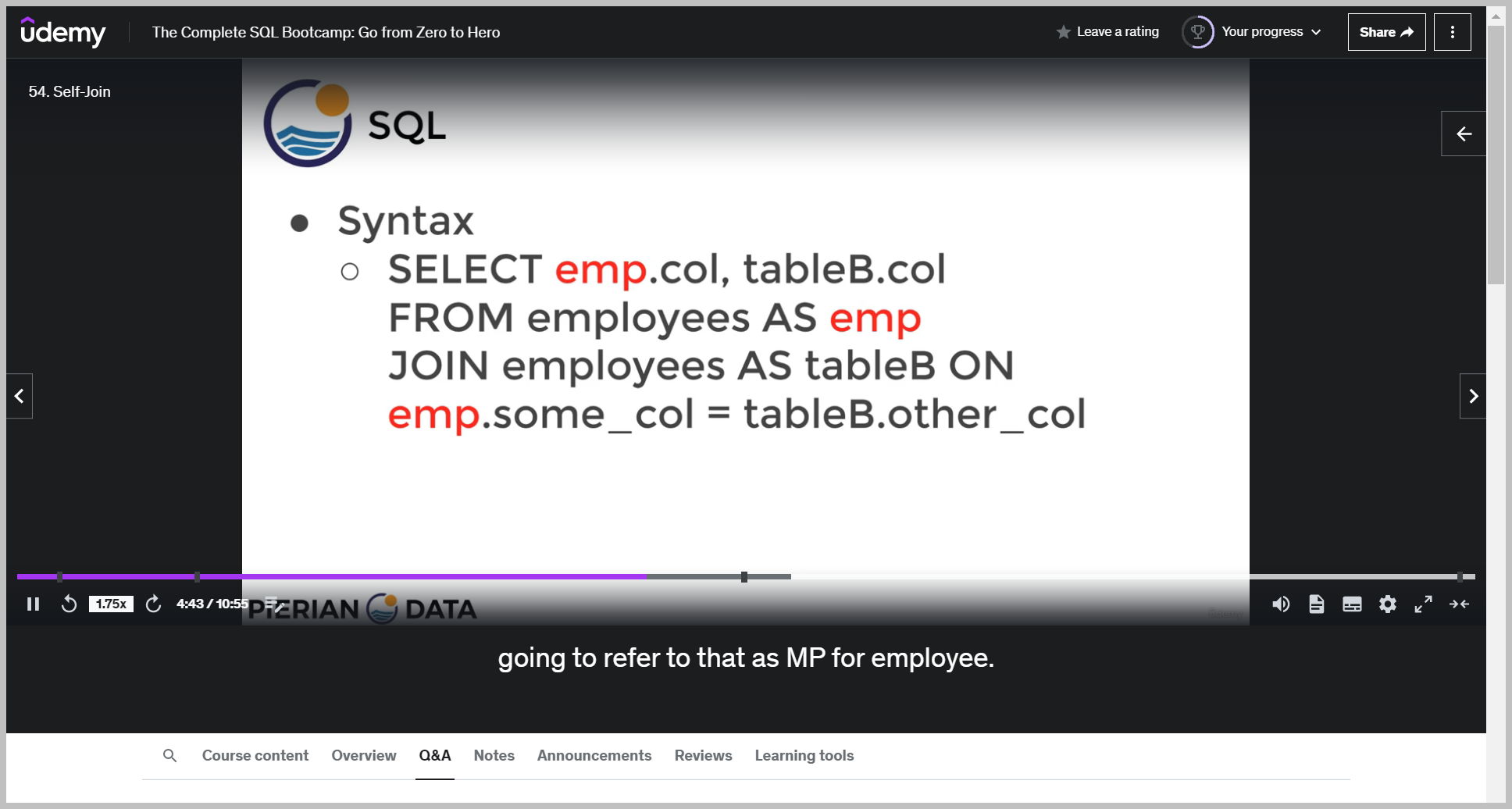
3. table B.col
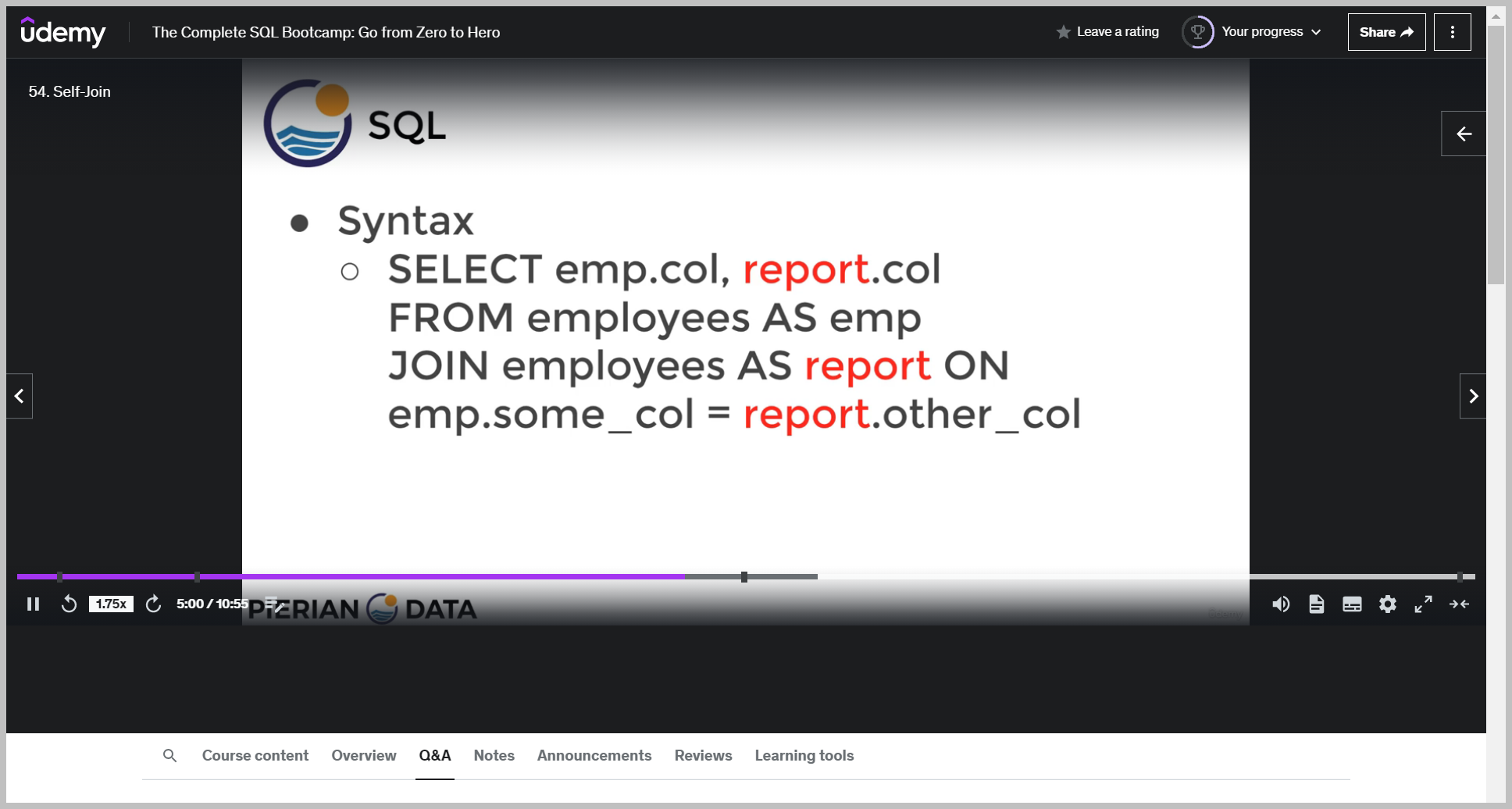
4. join col
Then I need to decide what column am I going to join this on?
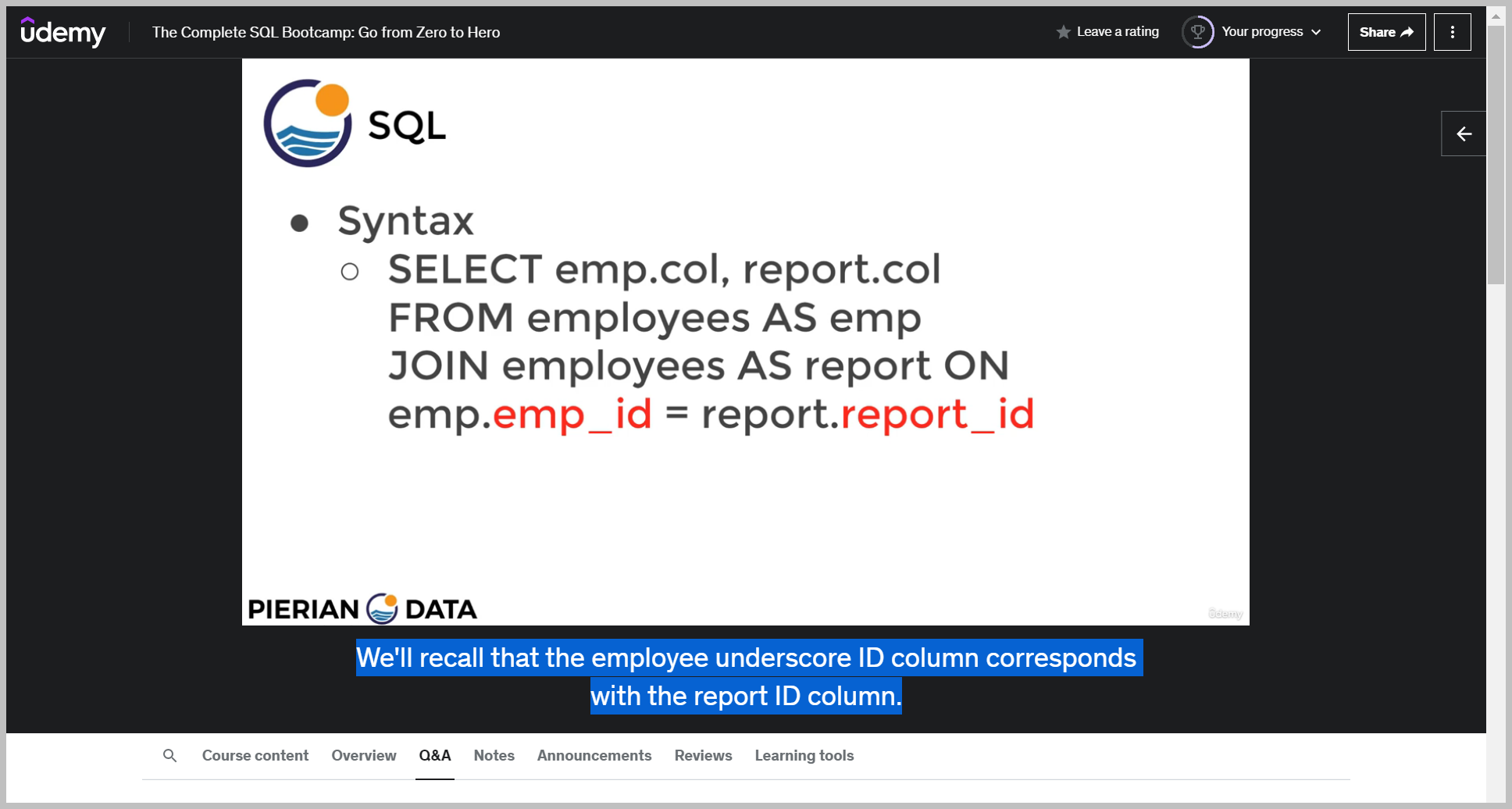
5. 완성
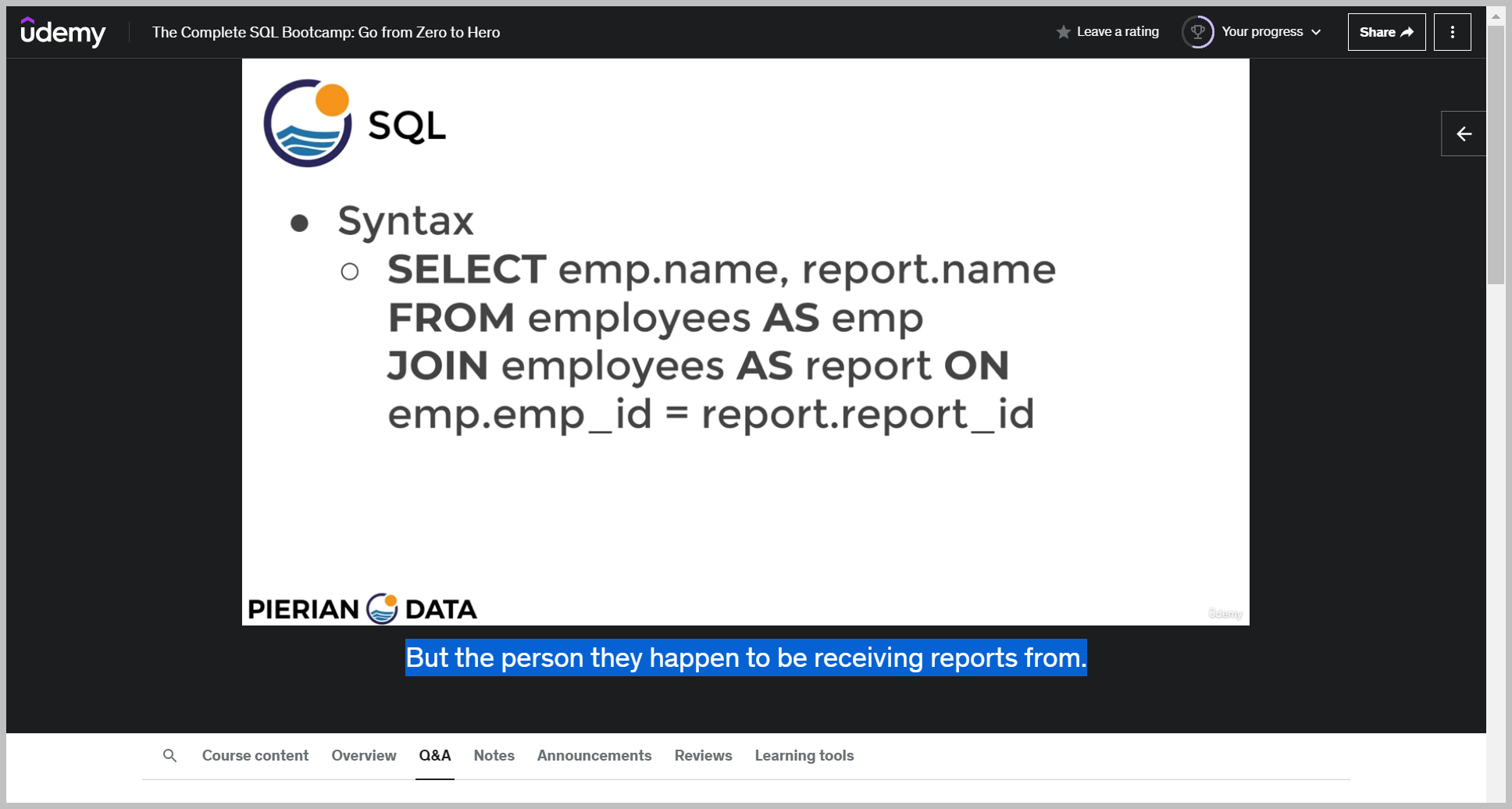
조건문
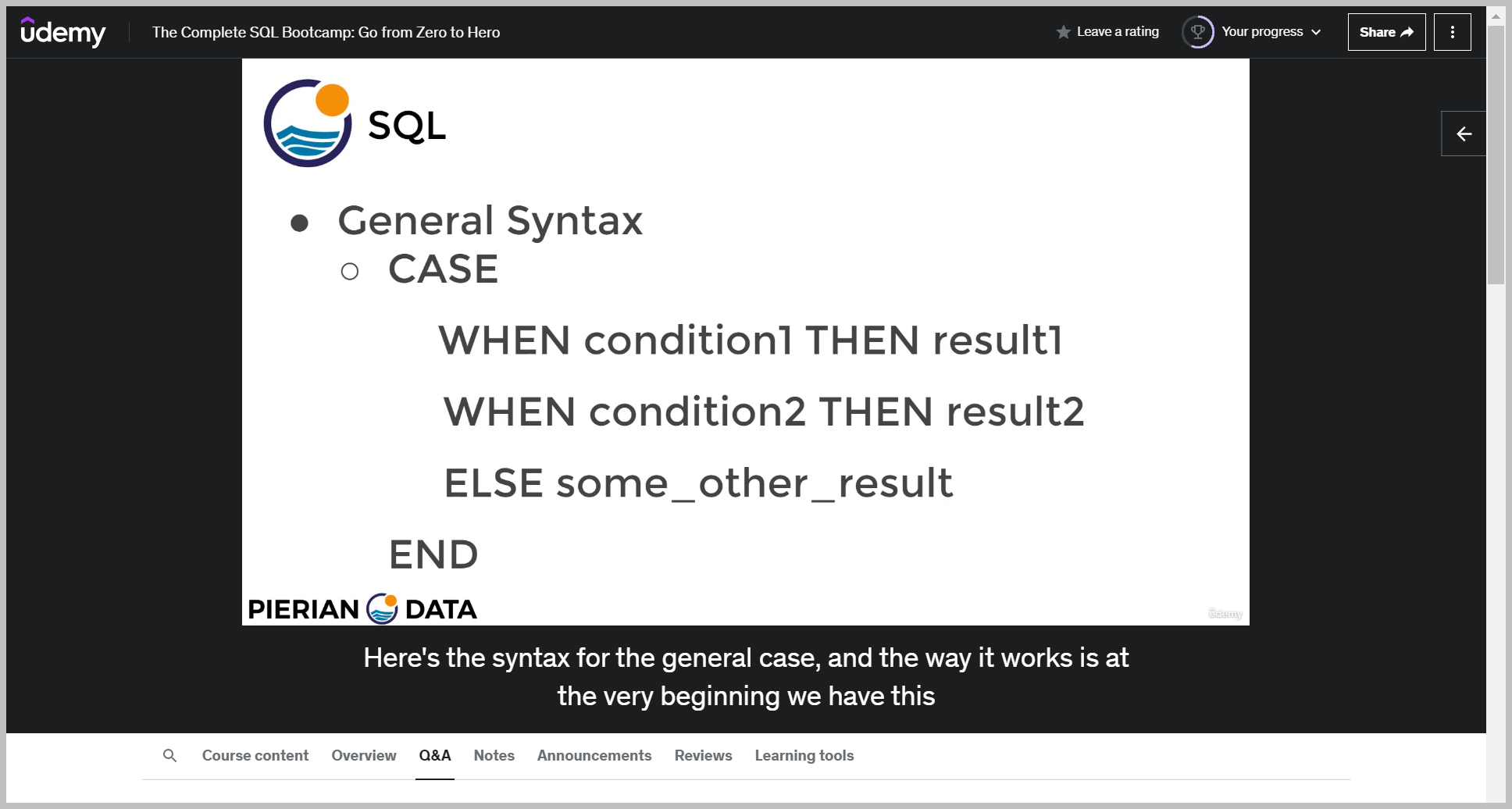
CASE 문
기본 문법
예제

We can see that this is actually going to be more flexible because the expression syntax essentially just checks for equal or equality to the provided expression, which can be as simple as a single column provided the general case syntax allows us to do all kinds of conditional checks.
So case for the general syntax allows us to do a bunch of conditions individually and uniquely right after those when calls.
CASE 표현식
기본 문법
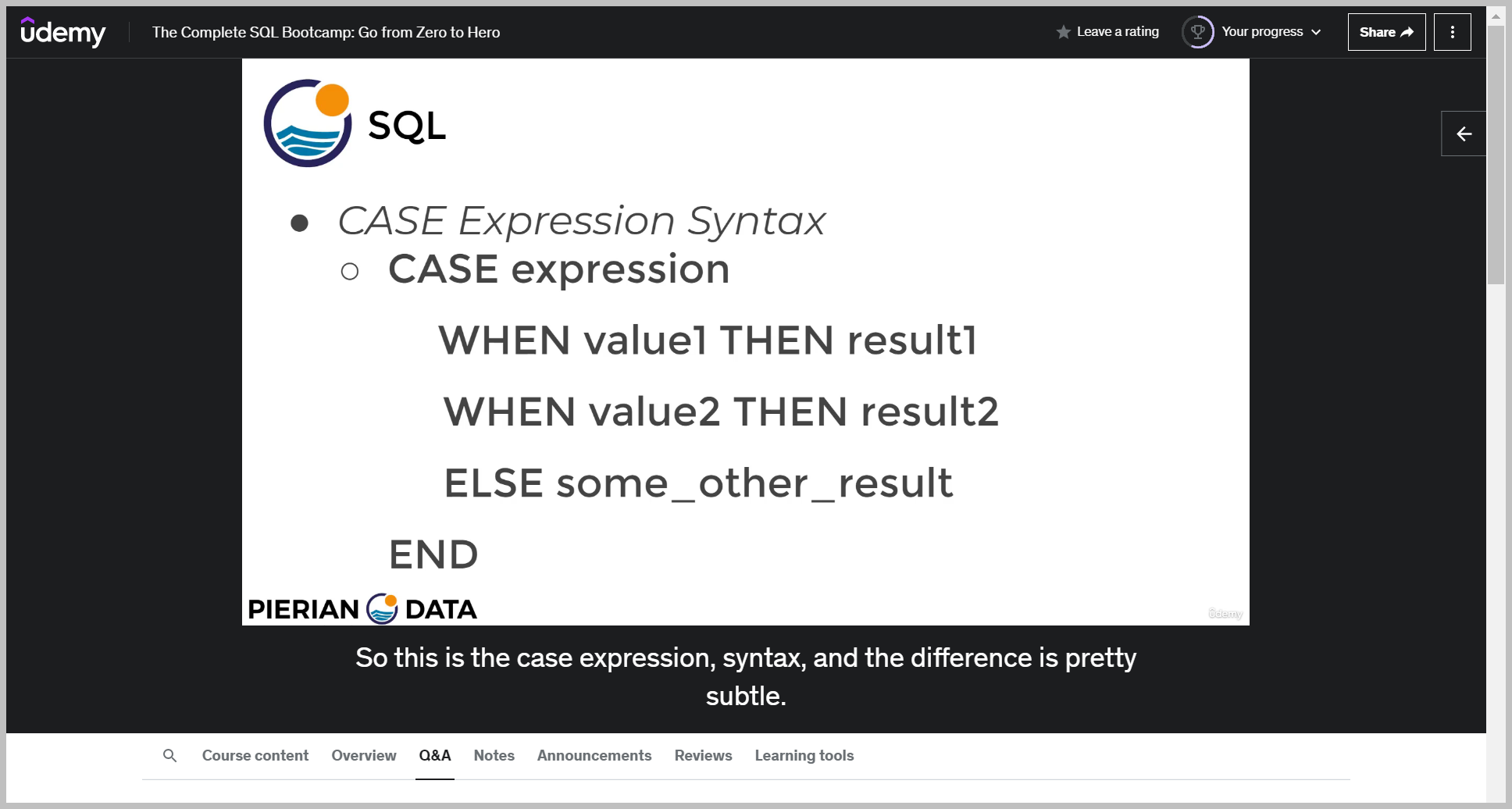
But you'll see here that right in front of the case, we're actually going to evaluate an expression
예제
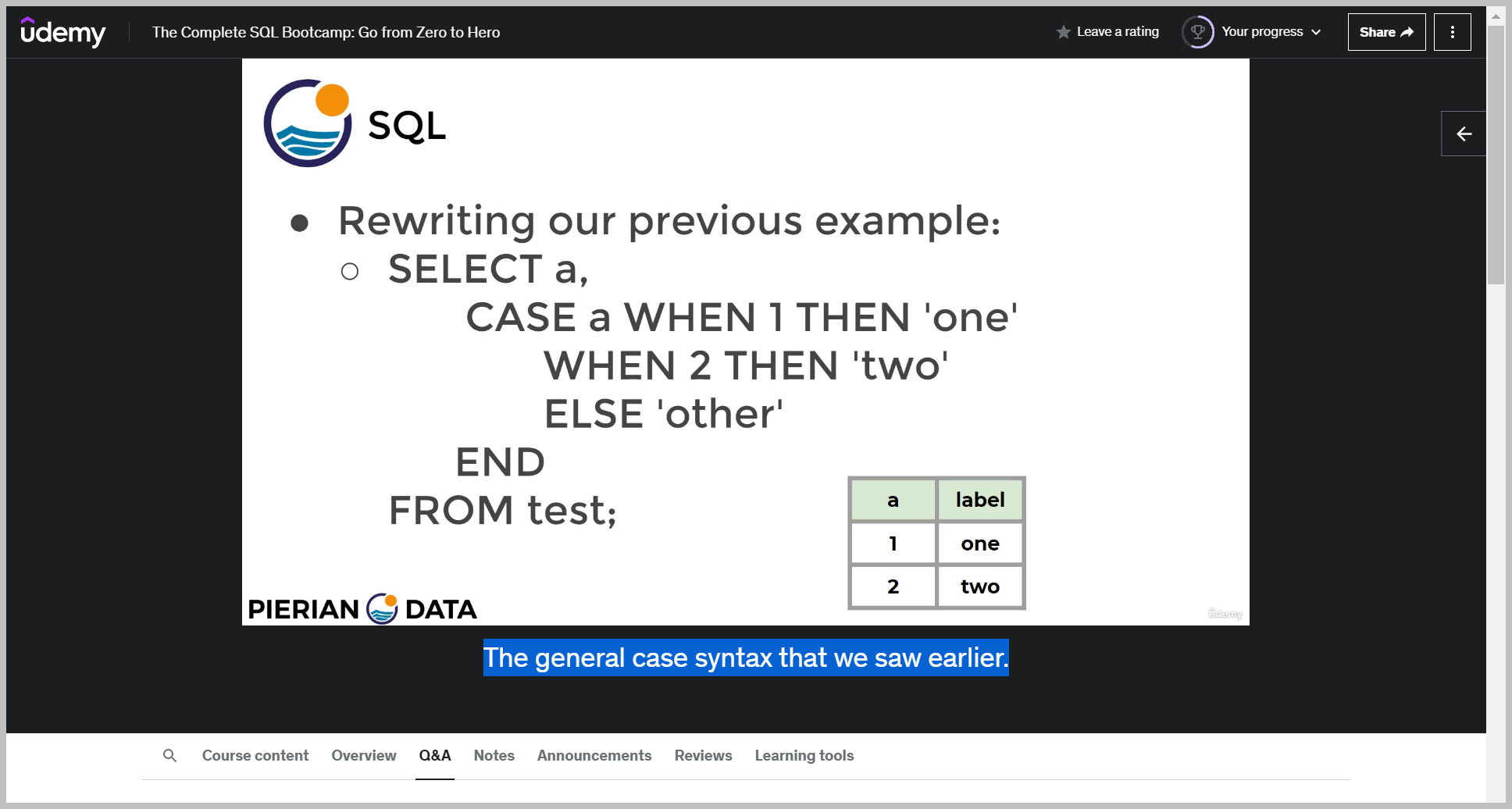
The case expression syntax is essentially just evaluating one expression and then you're listing the possible values to be equal to that expression.
And often that expression is just a simple column call, such as case a11, then one, when two, then
예제
case 표현식
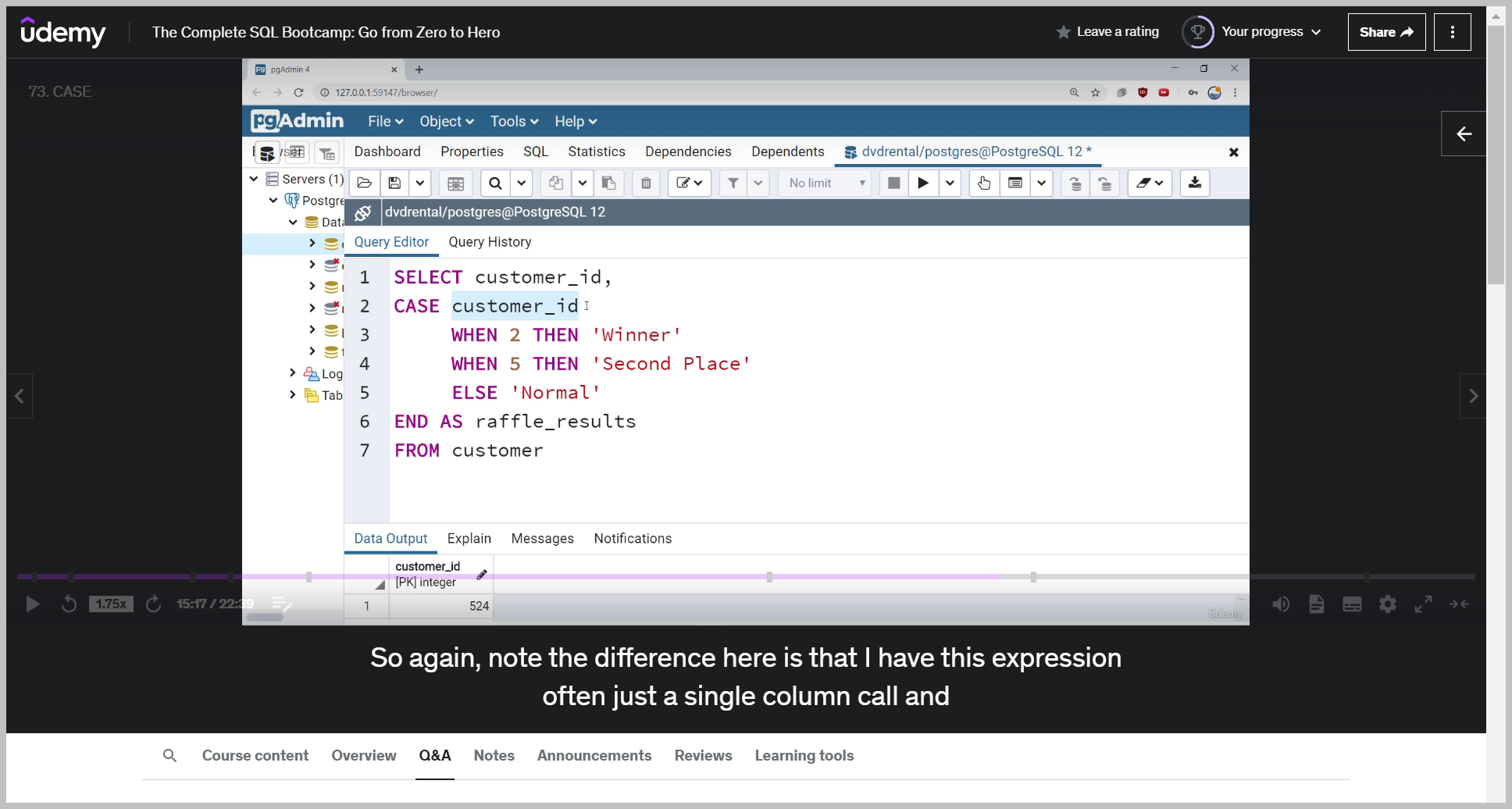
So again, note the difference here is that I have this expression often just a single column call and instead of checking for conditions within the when, I'm just checking for equality. So checking when customer ID when it's two customer ID, when it's five.
COALESCE
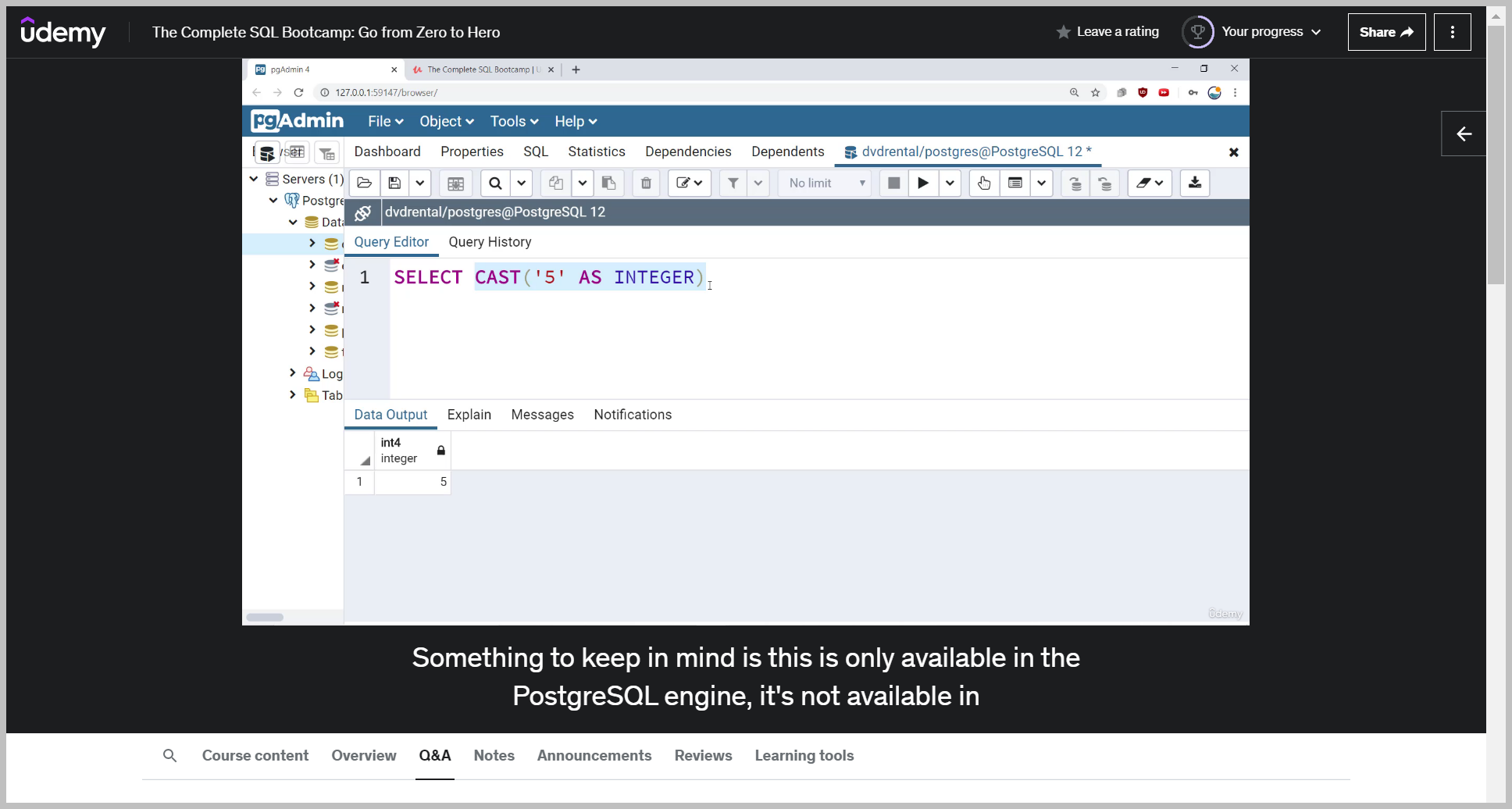
CAST
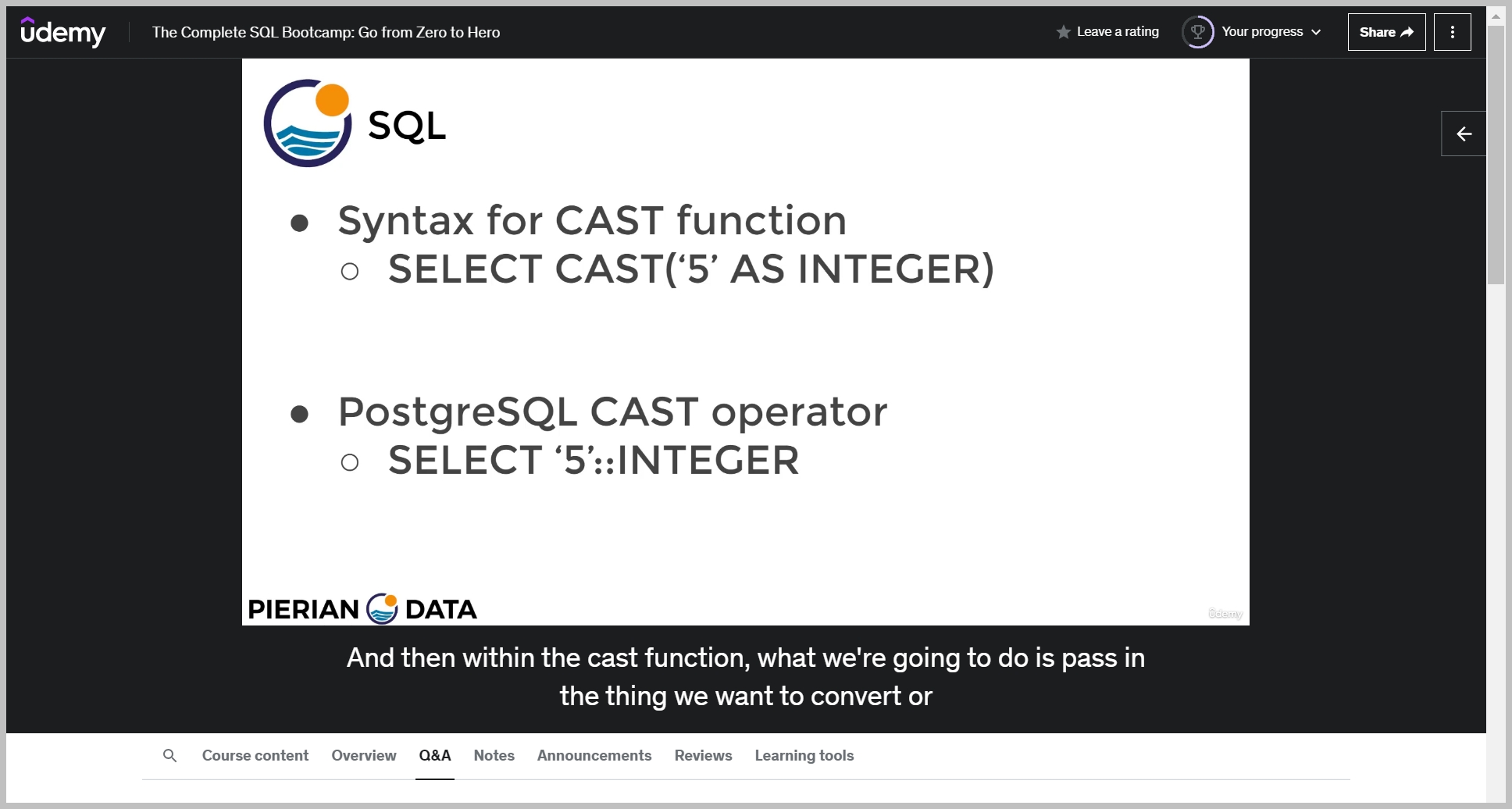
예제
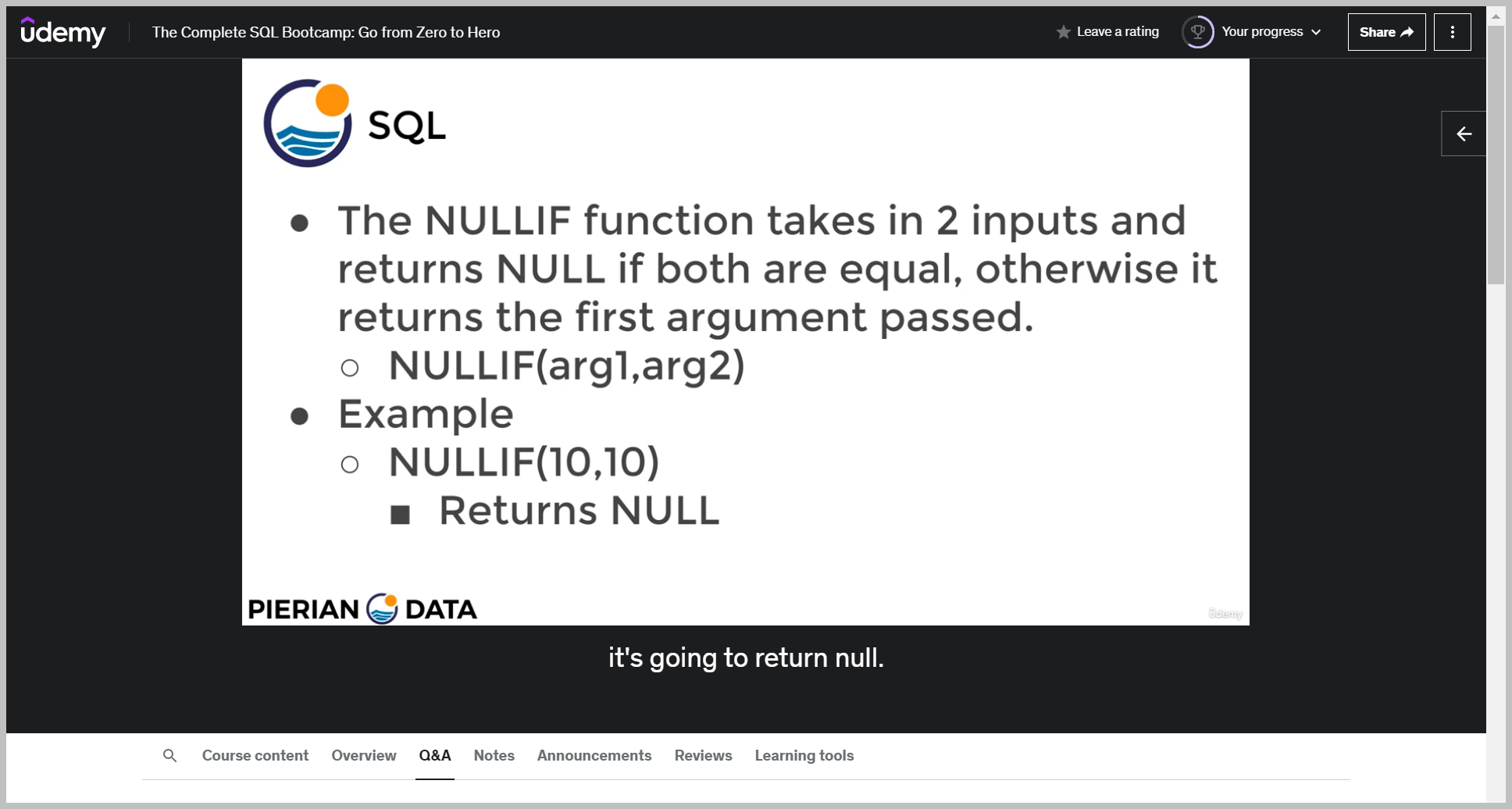
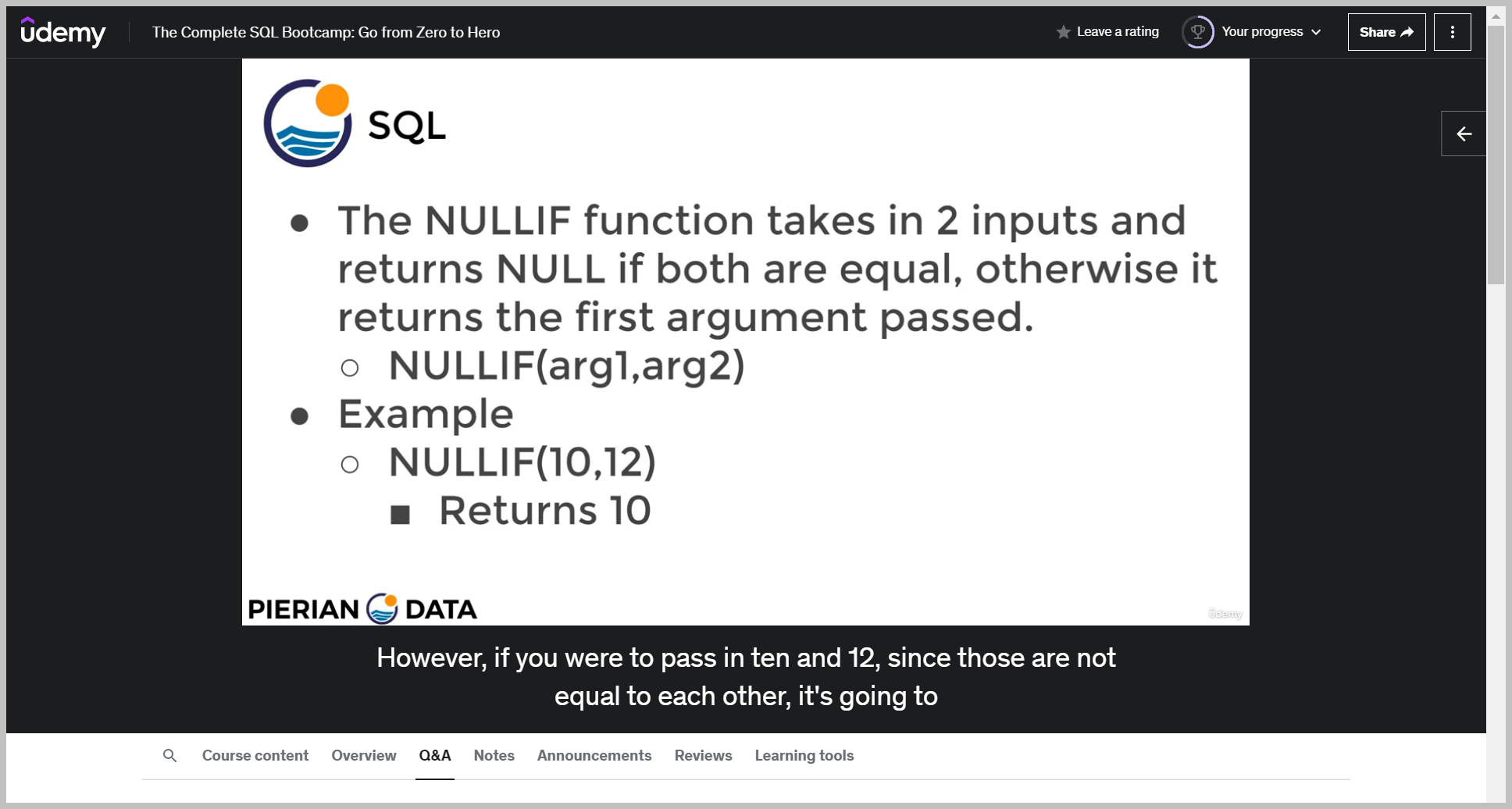
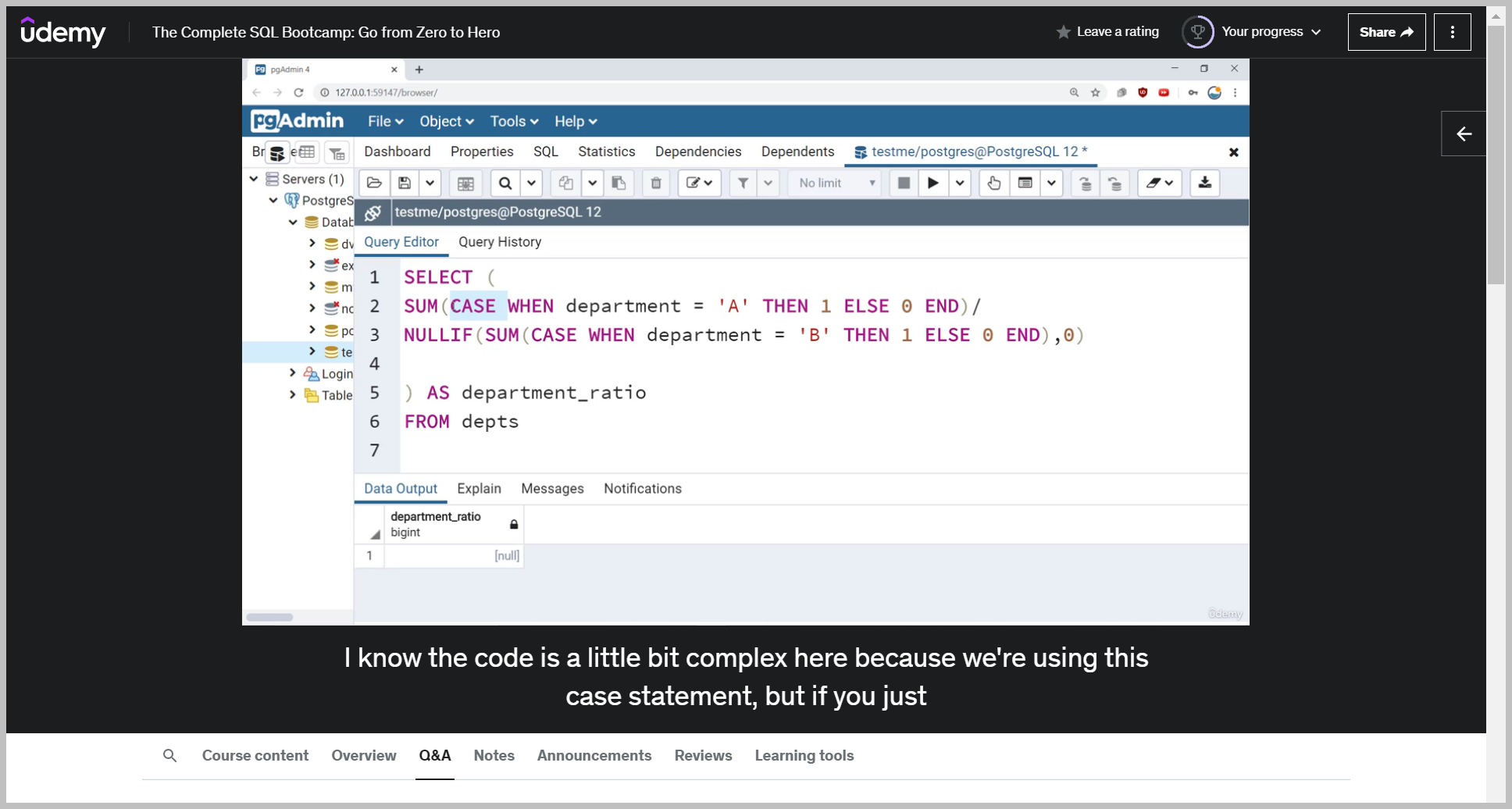
NULLIF