학부 수업중에 진행한 프로젝트로 대용량의 친구정보가 있는 아이디쌍이 들어왔을때 시간을 효율적으로 활용해서 친구를 찾아주는 알고리즘이다.
입력데이터
친구관계를 나타내는 graph가 입력으로 주어진다.
입력은 아이디 두개 사이에 공백으로 주어진다.
0 1
0 2
2 3
4 5입력이 이런식으로 있으면 0과 2은 친구이고 2와 3도 친구이지만 0과 3은 친구일 수도 아닐 수도 있다.
일정 threshold를 넘는 친구찾기 알고리즘이다.
친구가 아닌 모든 사용자 쌍들중 threshold를 만족하는 아이디쌍을 찾아보자.
데이터셋은 http://snap.stanford.edu/data/egonets-Facebook.html 이곳에서 다운받을수 있다.
유사도 분석
http://www.cse.unsw.edu.au/~lxue/WWW08.pdf
본 논문을 통해 Jaccard similarity와 overlap similarity의 관계를 알 수 있습니다.
x와 y의 레코드가 각각 있고 Jaccard similarity와 overlap similarity가 다음과 같이 정의 될때,
- =>
- =>
우리는 일정 treshold값인 를 넘는 아이디 쌍을 찾는 것이 목표이다. 따라서, 를 만족하는 아이디 쌍을 찾으면 된다.
논문의 식을 통해 일때 이다.
유사도조인은 유사도의 제약조건인 를 두고 측정하며 이는 다양한 식으로 변형될 수 있다.
이제 유사도 조인을 위한 다양한 방법을 고려해보자.
Naive algorithm
이 경우는 모든 경우의 수를 brute-force하게 다 탐색을 해 의 복잡도를 가진다. 하지만 지금 대용량의 데이터셋을 다룬다는 가정이기때문에 이 경우는 생각하지 않는다.
PreFix Filtering Based Methods
사전에 필터링을 거쳐 제거하는 방법이다. 두가지 방법이 있다.
Inverted list + Overlap constraint
inverted list로 바꾸어 inverted index는 토큰 w와 매핑이 된다.
이제 w에서 가능한 후보군들을 전부 고려한뒤 중복이 되는만큼 더해주면 overlap이 계산된다.
위 에서 정의 한것처럼 jaccard similarity는 overlap similarity로 변형이 가능하기 때문에, overlap을 이용해 를 만족하는 쌍들을 구할 수 있다.
Prefix filtering principle
논문의 LEMMA1에 따르면 만약 일때 의 앞쪽 시퀀스 개 그리고 의 앞쪽 시퀀스 개는 반드시 적어도 하나의 토큰을 공유한다.
이 lemma를 통해 만족하지 않는 후보군들을 미리 제거할 수 있다. 이때 계산의 효율적을 높이기 위해 x와 y의 시퀀스는 빈도수 역순으로 하는게 좋다.
구현
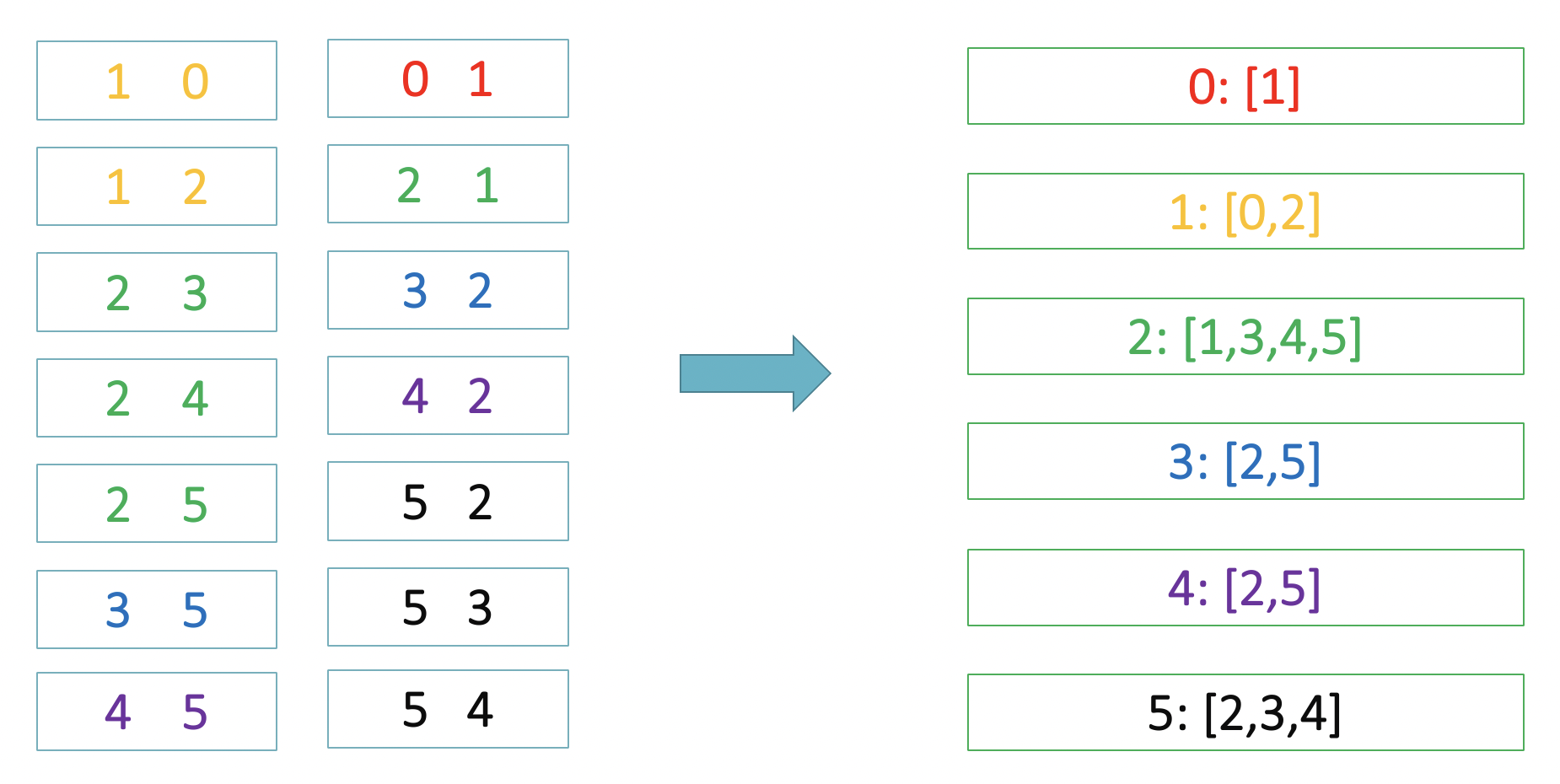
아이디 쌍들을 받아 단방향인 아이디를 양방향으로 만들기 위해 뒤집어서 더해야 한다.
그 후,전체 데이터에서 한사람의 아이디별로 친구인 상태를 리스트로 묶어 저장한다.
구현코드는 아래와 같다.
def flatten(x):
tmp=[]
for i in x[0]:
for j in i:
tmp.append(j)
for i in x[1]:
for j in i:
tmp.append(j)
return tmp
data_1_t_g=data.groupByKey().mapValues(list) #아이디를 키로해서 친구들 리스트
inv_data_1_t_g=data.map(lambda x:(x[1],x[0])).groupByKey().mapValues(list) #undirected로 구성되있어서 반대의 경우로도 생성
#생성한 두개의 rdd합쳐서 cogroup
total=data_1_t_g.cogroup(inv_data_1_t_g).mapValues(lambda t:(list(t[0]),list(t[1]))).map(lambda x:(x[0],flatten(x[1])))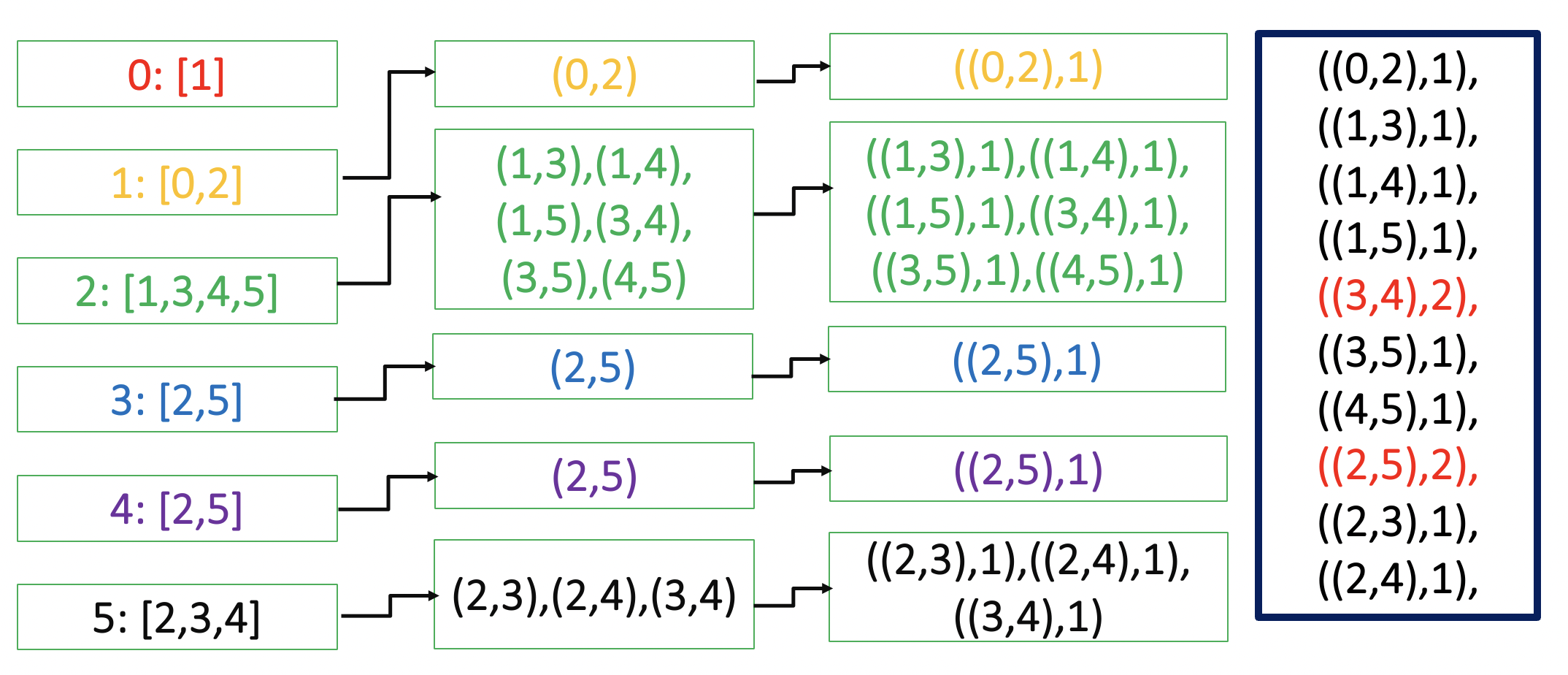
친구상태의 그룹들에서 순열조합을 만들면 또다른 아이디 쌍들이 나오게 된다. 이를 조합연산을 통해 나온 아이디쌍들을 아이디쌍,1인 튜플로 바꾼후 아이디쌍을 키로 만들어 같은 키를 가진것들 끼리 더하는 방식으로 줄인다. 이 과정이 overlap을 구하는 과정이다.
구현코드는 아래와 같다.
#각 키를 기준으로 모든 순열조합을 생성해 overlap rdd생성
overlap=total.map(lambda x:x[1]).flatMap(lambda x:list(itertools.combinations((x),2))).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)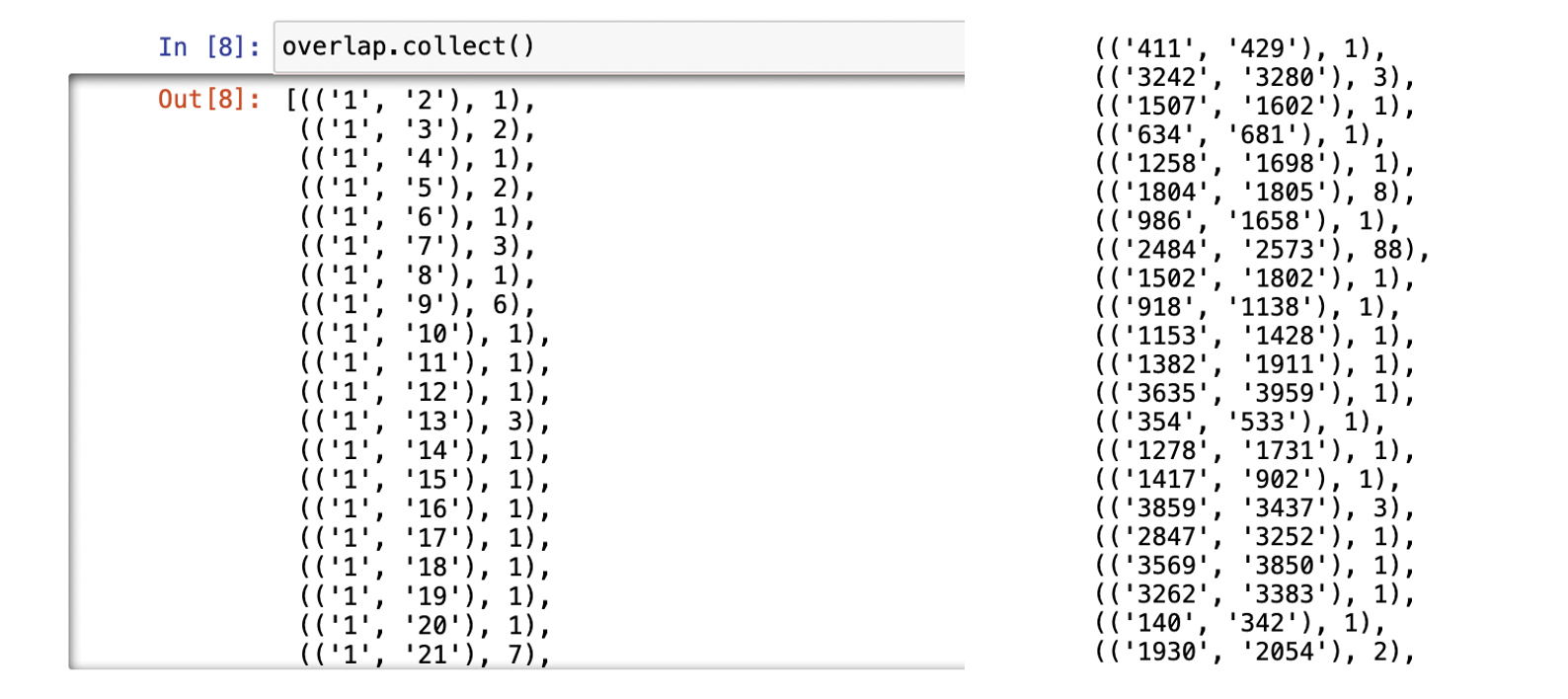
overlap의 데이터를 보면 아이디쌍과 둘 사이의 overlap이 있는것을 볼 수 있다.
친구정보를 전체 포함하는 broadcasting생성 후
dictionary=dict(total.map(lambda x:list(x)).collect())
bbc=sc.broadcast(dictionary)이제 유사도를 확인해보자.
jaccard similarity를 사용하면 두 집합 사이의 합집합, 교집합을 따로 구해야 하지만
동치관계식인 overlap을 이용한다면 구하지 않아도 된다.
- Jaccard 일때
threshold=0.9
#braodcasting이용해서 jaccard coefficient계산을 위해 합집합,교집합이 필요해 각 키에대한 모든 리스트정보 불러온 rdd생성
all_list=overlap.map(lambda x:(x[0],x[1],bbc.value[x[0][0]],bbc.value[x[0][1]]))
#교집합/합집합 이용해 jaccard구현 교집합은 overlap이용
final=all_list.map(lambda x:[x[0],x[1],len(union(x[2],x[3]))])
#threshold 바꿔가며 결과값 도출
upper_th=final.filter(lambda x:x[1]/x[2]>=threshold).map(lambda x:(x[0],x[1]/x[2]))- Overlap 일때
threshold=0.9
all_list=overlap.map(lambda x:(x[0],x[1],bbc.value[x[0][0]],bbc.value[x[0][1]]))
final=all_list.filter(lambda x:x[1]>=treshold/(1+threshold)*x[2])
#threshold 바꿔가며 결과값 도출
upper_th=final.filter(lambda x:x[1]/x[2]>=threshold).map(lambda x:(x[0],x[1]/x[2]))시간비교
Overlap이 훨씬 효율적임을 볼 수 있다.
Final rdd 를 정의하고 jaccard식을 계산해 upper th에서 필터링을 한 방식보다
합집합 연산도 필요없고 Final rdd 정의할때 한번에 필터링을 거친 이 방식이
훨씬 더 간단하고 시간도 효율적으로 절약할 수 있었다.
이제 마지막 단계는 이미 친구인 아이디들을 제거하는것이다.
upper_th.filter(lambda x: x[0][1] not in bbc.value[x[0][0]]).collect()
제거 후 값을 보면 1.0이 많음을 알 수 있는데, 이렇게 유사도가 100% 나오는 이유는 정말 모든친구가 같은 경우가 있고 혹은 서로 전체 친구가 한명 뿐인데 딱 한명이 겹치는 경우도 있다.
이때 겹치는 한명이 유명인이라면 이같은 경우는 친구찾기 알고리즘에 적합하지 않다고 생각해
더 의미있고 실용적인 데이터가 필요하다고 생각하여 이경우는 제외하기로 했다.
# 친구가 한명이여서 1나온경우 제외하면
notonefinal=final.filter(lambda x:[x[1],x[2]]!=[1,1])
upper_th=notonefinal.filter(lambda x:x[1]/x[2]>=threshhold).map(lambda x:(x[0],x[1]/x[2]))
upper_th.map(lambda x:(x[0])).filter(lambda x: x[1] not in bbc.value[x[0]]).collect()데이터를 필터링 후 값을 확인하면 다음과 같은 결과를 얻을 수 있다.
threshold가 0.9일때 아이디 쌍이다.

파이스파크를 이용해 친구찾기 알고리즘을 진행해 보았다.
