
학부 수업 회귀분석 과목에서 진행한 중고차 가격예측 프로젝트이며 해당내용 코드는 모두 깃헙에 올려놓았습니다.
https://github.com/sobin98/used_car_prediction
프로젝트를 진행하려는데 적절한 데이터셋이 따로없어서 보배드림 사이트에서 크롤링 하는것부터 시작했다.
데이터 크롤링은 프로젝트를 위해 데이터셋이 급하게 필요해 유튜브 강의를 참고했는데 https://www.youtube.com/watch?v=yQ20jZwDjTE&t=4196s
이 강의에서 정리가 정말 잘되어있어서 앞쪽 두시간만 학습하고 코드를 짤 수 있었다.
데이터크롤링
파이썬 BeautifulSoup를 이용해 웹크롤링을 했다. 데이터선정은 국산차기준으로 했다. 22년 5월 19일기준 아래 모델명에 따라 페이지수는 각자 다음과 같다. 보배드림 사이트가 실시간으로 중고차가 올라오기때문에 사이트접속마다 페이지수가 다를 수 있다.
현대 그랜저- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=5&page=1&order=S11&view_size=20 페이지수 : 11
현대 스타렉스 그랜드스타렉스- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=17&page=1&order=S11&view_size=20 페이지수 : 5
현대 아반떼- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=22&page=1&order=S11&view_size=20 페이지수 : 6
현대 에쿠스- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=25&page=1&order=S11&view_size=20 페이지수 : 3
현대 포터- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=42&page=1&order=S11&view_size=20 페이지수 : 5
제네시스 G80- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=1010&group_no=893&page=1&order=S11&view_size=20 페이지수 : 4
기아 K7- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=45&page=1&order=S11&view_size=20 페이지수 : 5
기아 봉고- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=59&page=1&order=S11&view_size=20 페이지수 : 4
기아 카니발- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=76&page=1&order=S11&view_size=20 페이지수 : 10
기아 K5- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=44&page=1&order=S11&view_size=20 페이지수 : 5
제네시스 EQ900- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=1010&group_no=879&model_no%5B%5D=1699&page=1&order=S11&view_size=20 페이지수 : 2
현대 쏘나타- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=21&page=1&order=S11&view_size=20 페이지수 : 7
현대 제네시스- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=30&page=1&order=S11&view_size=20 페이지수 : 6
현대 펠리세이드- https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=960&model_no%5B%5D=1953&page=1&order=S11&view_size=20 페이지수 : 2
웹크롤링할 링크를 모으기 위해 위 링크에서 모든 페이지들을 가져와야한다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
totalurl=[("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=5&page={}&order=S11&view_size=20",11),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=17&page={}&order=S11&view_size=20",5),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=22&page={}&order=S11&view_size=20",6),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=25&page={}&order=S11&view_size=20",3),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=42&page={}&order=S11&view_size=20",5),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=1010&group_no=893&page={}&order=S11&view_size=20",4),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=45&page={}&order=S11&view_size=20",5),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=59&page={}&order=S11&view_size=20",4),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=76&page={}&order=S11&view_size=20",10),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=3&group_no=44&page={}&order=S11&view_size=20",5),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=1010&group_no=879&model_no%5B%5D=1699&page={}&order=S11&view_size=20",2),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=21&page={}&order=S11&view_size=20",7),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=30&page={}&order=S11&view_size=20",6),
("https://www.bobaedream.co.kr/mycar/mycar_list.php?gubun=K&maker_no=49&group_no=960&model_no%5B%5D=1953&page={}&order=S11&view_size=20",2)]
df_cars=[]
urls=[]
for i in totalurl:
pagenum=i[1]
for j in range(pagenum):
url=i[0].format(str(j))
urls.append(url)필요한 패키지 임포트 후에 이와 같이 링크들을 모았다.
웹크롤링을 하기전에 어떤 데이터들을 가져올지 정해야 하는데 중고차 가격에 영향을 미칠만한 아래와 같은 정보를 사용하기로 했다.
중고차의 기본적인 정보들
- 모델,연식,주행거리,연료,배기량,색상,보증정보
판매되는 가격과 신차대비 가격(추후에 반응변수로 사용할 예정)
- 가격,신차대비가격
옵션들도 가격을 미친다고 생각하여 기본적인 옵션들과 가격에 영향을 미친다고 생각하는 옵션들 추가
- 선루프,파노라마선루프,열선앞좌석,열선뒷좌석,전방센서,후방센서,전방캠,후방캠,어라운드뷰,네비게이션(순정)
중고차의 사고내역과 보험내역의 횟수와 가격
- 보험이력등록,소유자변경횟수,사고상세전손,사고상세침수전손,사고상세침수분손,사고상세도난,보험내차피해(횟수),보험내차피해(가격),사고상세타차가해(횟수),보험내차피해(가격)
사용할 정보들이 정해졌으니 컬럼명으로 두어 데이터프레임 형식으로 데이터를 받아오면 다음과 같다.
info=["이름","차량번호","링크","연식","주행거리","연료","배기량","색상","보증정보","가격","신차대비가격"]
coloptions=["옵션_선루프","옵션_파노라마선루프","옵션_열선앞","옵션_열선뒤","옵션_전방센서"
,"옵션_후방센서","옵션_전방캠","옵션_후방캠","옵션_어라운드뷰","옵션_네비순정"]
findoptions=["선루프","파노라마선루프","열선시트(앞좌석)","열선시트(뒷좌석)","전방센서"
,"후방센서","전방카메라","후방카메라","어라운드뷰","네비게이션(순정)"]
colacci_info1=["보험이력등록","소유자변경횟수","사고상세_전손","사고상세_침수전손","사고상세_침수분손","사고상세_도난","보험_내차피해(횟수)","보험_내차피해(가격)","사고상세_타차가해(횟수)","보험_타차피해(가격)"]
cols=info+coloptions+colacci_info1 #분석과정에서 아웃라이어의 판별여부를 위해 링크추가
#옵션이름 받아서 확인여부하는 함수
def option_check(soupobject,option_name):
check = soupobject.find("button", text=option_name).find_parent().find_previous_sibling().get_attribute_list('checked')
if check[0]=='':
return '유'
else:
return '무'
for url in urls:
res=requests.get(url)
res.raise_for_status()
requests.adapters.DEFAULT_RETRIES = 10
soup=BeautifulSoup(res.text,"lxml")
cars=soup.find_all("li",attrs={"class":"product-item"})
links=[]
#한 url마다 들어있는 모든 차들에 대해 실행
for car in cars:
link = "https://www.bobaedream.co.kr" + car.a["href"]
links.append(link)
for link in links:
print(link)
res2=requests.get(link,timeout=5)
res2.raise_for_status()
soup2 = BeautifulSoup(res2.text, "lxml")
infobox = soup2.find("div", attrs={"class": "info-util box"})
try:
ratiopr = infobox.find("b")
except:
continue
name=soup2.find("h3",attrs={"class":"tit"})
state=soup2.find("div",attrs={"class":"tbl-01 st-low"})
galdata=soup2.find("div",attrs={"class":"gallery-data"})
carnumber=galdata.find("b")
year=state.find("th",text='연식').find_next_sibling("td")
km=state.find("th",text='주행거리').find_next_sibling("td")
fuel=state.find("th",text='연료').find_next_sibling("td")
amount=state.find("th",text='배기량').find_next_sibling("td")
color=state.find("th",text='색상').find_next_sibling("td")
guarn=state.find("b",text='보증정보').find_next("td")
price=soup2.find("span",attrs={"class":"price"})
option_table=soup2.find("div",attrs={"class":"tbl-option"})
checkoptions=[]
if option_table.find("th",text='외관')!=None:
for option in findoptions:
checkoptions.append(option_check(option_table,option))
else:
checkoptions=['']*len(coloptions)
if infobox.find("span",attrs={"class":"round-ln insurance"}).find_next("i").find_next("em")==None:
acc1 = '미등록'
else:
acc1 = '등록'
findacci_info1=[]
try:
if acc1=='등록':
acc1table=soup2.find("div",attrs={"class":"info-insurance"})
insurdt1=acc1table.find("th",text="차량번호/소유자변경").find_next_sibling("td").get_text()[-2]
insuraccis1 = acc1table.find("th", text="자동차보험 특수사고").find_next_sibling("td").get_text().split('/')
insurdt2=insuraccis1[0][-2]
insurdt3 = insuraccis1[1][-2]
insurdt4 = insuraccis1[2][-2]
insurdt5 = insuraccis1[3][-1]
insuraccis2=acc1table.find("th", text="보험사고(내차피해)").find_next_sibling("td").get_text().split('회')
insurdt6=insuraccis2[0]
insurdt7=insuraccis2[1][2:-2]
insuraccis3=acc1table.find("th", text="보험사고(타차가해)").find_next_sibling("td").get_text().split('회')
insurdt8=insuraccis3[0]
insurdt9=insuraccis3[1][2:-2]
findacci_info1=[insurdt1,insurdt2,insurdt3,insurdt4,insurdt5,insurdt6,insurdt7,insurdt8,insurdt9]
else:
findacci_info1=['']*(len(colacci_info1)-1)
except IndexError:
findacci_info1 = ['']*(len(colacci_info1)-1)
temp=[name.get_text(),carnumber.get_text(),link,year.get_text(),km.get_text(),fuel.get_text(),amount.get_text(),
color.get_text(),guarn.get_text(),price.get_text(),ratiopr.get_text()]+checkoptions+[acc1]+findacci_info1
df_cars.append(temp)
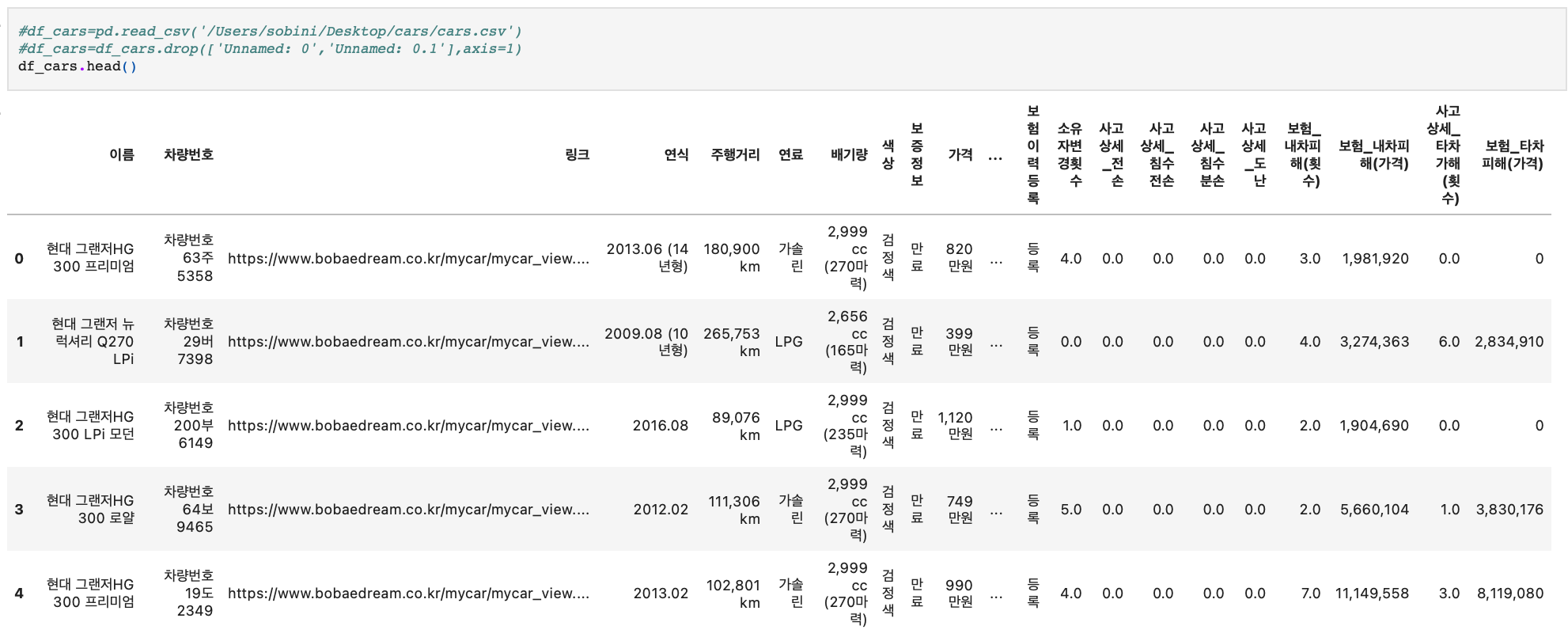
df_cars=pd.DataFrame(data=df_cars,columns=cols)df_cars의 데이터프레임에 저장한 값을 보면 다음과 같은 결과를 얻을 수 있다. 31개의 컬럼으로 이루어진 데이터셋이다.
데이터전처리
분석에만 사용할 피쳐들로 정리하기
이름: 모델명
등급제외하고 제조사-모델-세부모델명으로 바꾼다.
ex> 현대 그랜저HG 300 프리미엄->현대 그랜저HG 300
def changemodel(str1):
index1=str1.find(' ')
index2=str1.find(' ',index1+1)
index3=str1.find(' ',index2+1)
return str1[:index3]
def changemodelname(str1):
if '그랜져' in str1:
str1=str1.replace("그랜져","그랜저")
return str1
else:
return str1
df_cars['이름']=df_cars['이름'].apply(changemodel).apply(changemodelname)
세부모델명 제외를 위해 공백을 세번찾은후 그 뒤로는 잘라낸다.
현대 그랜저모델의 경우 그랜저와 그랜져 두개로 표기되어 하나로 통일시킨다.
연식: 숫자
개월수로 바꿔
ex> 2013.01->201301, 2018.11(19년형)->201811
def changeyear(string):
year=int(string[:4])
month=int(string[5:7])
n=12*(2022-year)+month
return n
df_cars['연식']=df_cars['연식'].apply(changeyear)yyyy.mm~의 형태로 되어있어 문자열 1번째부터 4번째와 6번째부터 7번째만 가져오는 함수를 적용시킨다.
주행거리(km): 숫자
숫자로만 표현한다.
ex> 76,579km->76579
df_cars['주행거리']=df_cars['주행거리'].apply(lambda x:x.replace(",","")[:-2].rstrip())문자열에서 쉼표를 모두 제거해주고 뒤에 km를 제외시키기 위해 뒤에서 두번째까지만 가져온 뒤 공백을 모두 잘라준다.
연료종류: 숫자
디젤, LPG, 가솔린을 각 0,1,2로 매핑시킨다.
{디젤:0, LPG:1, 가솔린:2}
matchfuel={'디젤':0, 'LPG':1, '가솔린':2}
df_cars['연료']=df_cars['연료'].replace(matchfuel)배기량(cc): 숫자
단위는 cc로 숫자형태로 표현한다.
ex> 2,497 cc(175마력)->2479
def engine(str1):
index=str1.find('cc')
return str1[:index].replace(',','').rstrip()
df_cars['배기량']=df_cars['배기량'].apply(engine)문자열에서 cc이전까지의 문자열만 가져온 후 쉼표를 제거한 뒤 공백을 모두 잘라준다.
보증정보: 숫자
컬럼을 가능여부, 기간, 거리를 추가해서 표현한다.
가능여부: 0 or 1 (만료거나 불가이면 0, 가능하면 1, 정보가 없으면 결측치로 둔다.)
기간(개월): 가능여부가 1인경우 해당하는 기간을 표현한다.
거리(km): 가능여부가 1인경우 해당하는 거리를 표현한다.
def guar(str1):
if str1=='만료' or str1=='불가':
return pd.Series([0,0,0])
elif str1=='정보없음':
return pd.Series([np.nan,np.nan,np.nan])
else:
index=str1.find('/')
if index==-1:
time=0
else:
time=int(str1[:index-3].strip())
km=str1[index+1:].replace(",","")[:-2].strip()
return pd.Series([1,time,km])
guartable=df_cars['보증정보'].apply(guar)
guartable.columns=['보증여부','보증기간','보증거리']
df_cars=pd.concat([df_cars,guartable],axis=1`
df_cars=df_cars.drop(['보증정보'],axis=1)옵션: 숫자
있으면 0, 없으면1로 표현한다.
선루프, 파노라마 선루프, 열선앞좌석, 열선뒷좌석, 전방센서, 후방센서, 전방카메라, 후방카메라, 어라운드뷰, 네비게이션(순정)
matchop={'무':0,'유':1}
df_cars=df_cars.replace(matchop)사고내역
보험이력등록: 숫자
전손: 숫자
침수전손: 숫자
침수분손: 숫자
도난: 숫자
내차피해횟수: 숫자
내차피해가격: 숫자
타차가해횟수: 숫자
타차가해가격: 숫자
insurinfo={'미등록':0,'등록':1}
df_cars['보험이력등록']=df_cars['보험이력등록'].replace(insurinfo)
df_cars['보험_내차피해(가격)']=df_cars['보험_내차피해(가격)'].apply(lambda x: x.replace(",","") if isinstance(x,str) else np.nan)
df_cars['보험_타차피해(가격)']=df_cars['보험_타차피해(가격)'].apply(lambda x: x.replace(",","") if isinstance(x,str) else np.nan)
가격: 숫자
반응변수로 둘중 하나를 선택한다.
가격: 숫자
신차대비가격: 숫자
df_cars['가격']=df_cars['가격'].apply(lambda x:x.replace('만','0000').replace(',','')[:-1])
df_cars['신차대비가격']=df_cars['신차대비가격'].apply(lambda x: np.nan if x=='준비중' else x)
신차대비가격: 정보가 없는 '준비중'인 데이터들은 결측치로 변환
df_cars=df_cars.loc[:,['이름','연식', '주행거리', '연료', '배기량', '색상', '옵션_선루프', '옵션_파노라마선루프',
'옵션_열선앞', '옵션_열선뒤', '옵션_전방센서','옵션_후방센서', '옵션_전방캠', '옵션_후방캠', '옵션_어라운드뷰', '옵션_네비순정',
'보험이력등록','소유자변경횟수', '사고상세_전손', '사고상세_침수전손', '사고상세_침수분손', '사고상세_도난',
'보험_내차피해(횟수)', '보험_내차피해(가격)', '사고상세_타차가해(횟수)', '보험_타차피해(가격)','가격','신차대비가격','링크']]
df_cars.to_csv('cars_processed.csv')저장 후 R에서 이 데이터를 이용해 분석을 진행한다.
모델링
데이터분석
VIF
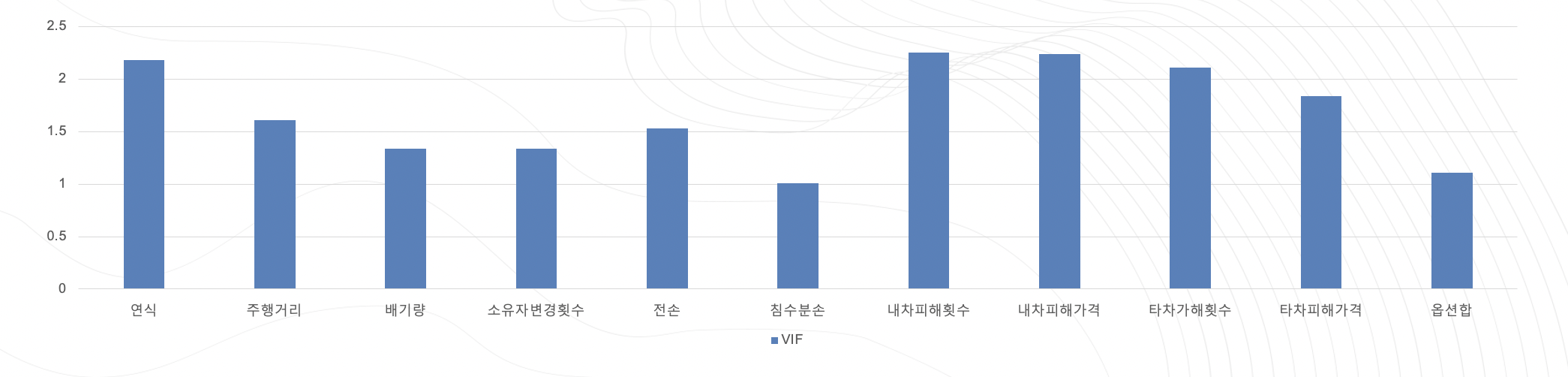
다중공선성 체크를 위해 VIF를 확인해 보았는데 모두 1~2사이의 값으로 나왔습니다.
상관관계
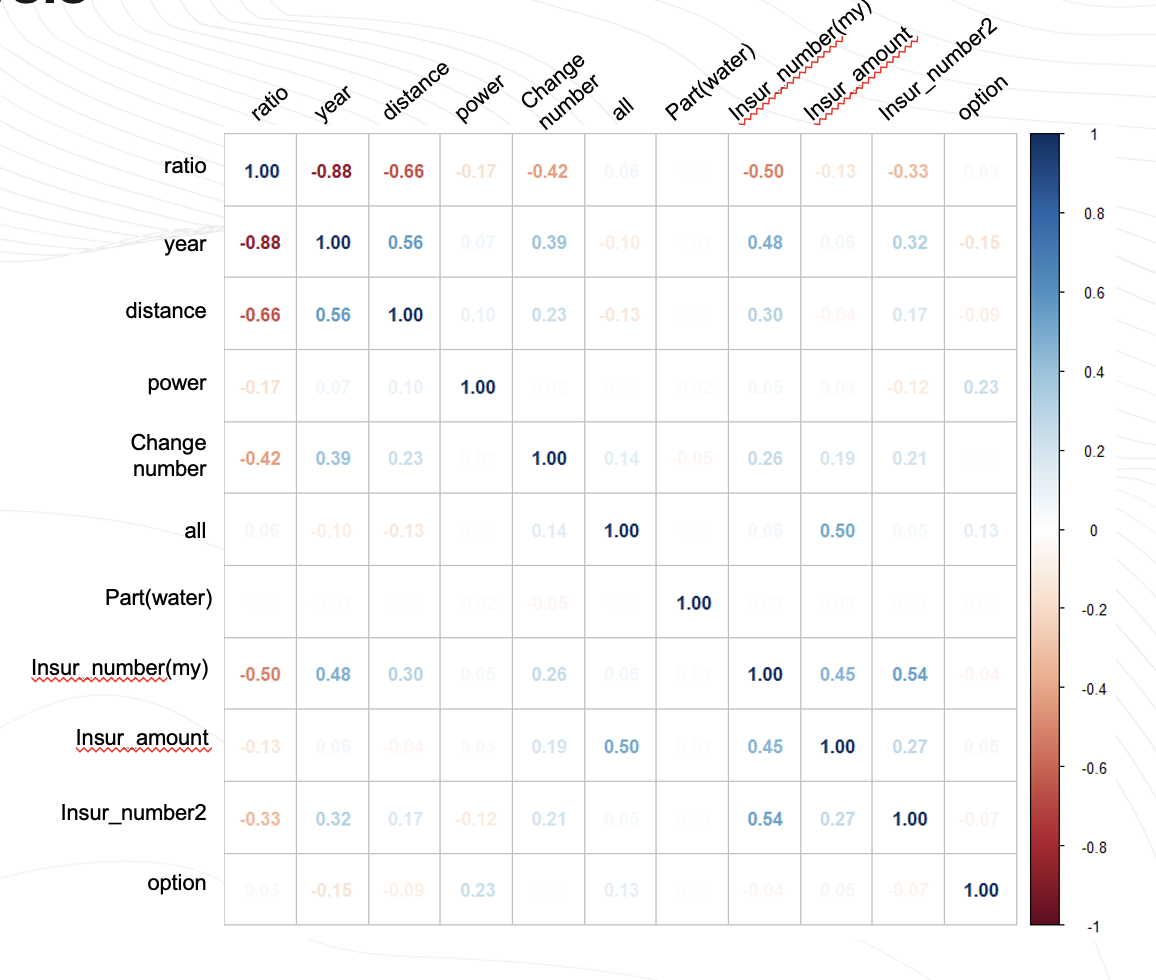
피쳐들간의 상관계수를 나타낸 시각화입니다.
연식이 신차대비 가격에 영향을 크게 미치고, 주행거리가 그 다음이였습니다.
또한 소유자변경횟수와 연식도 상관관계를 가지고
내차피해와 타차가해에 대한 사고들도 신차대비가격과 상관관계가 있는것으로 분석했습니다.
그래프 확인
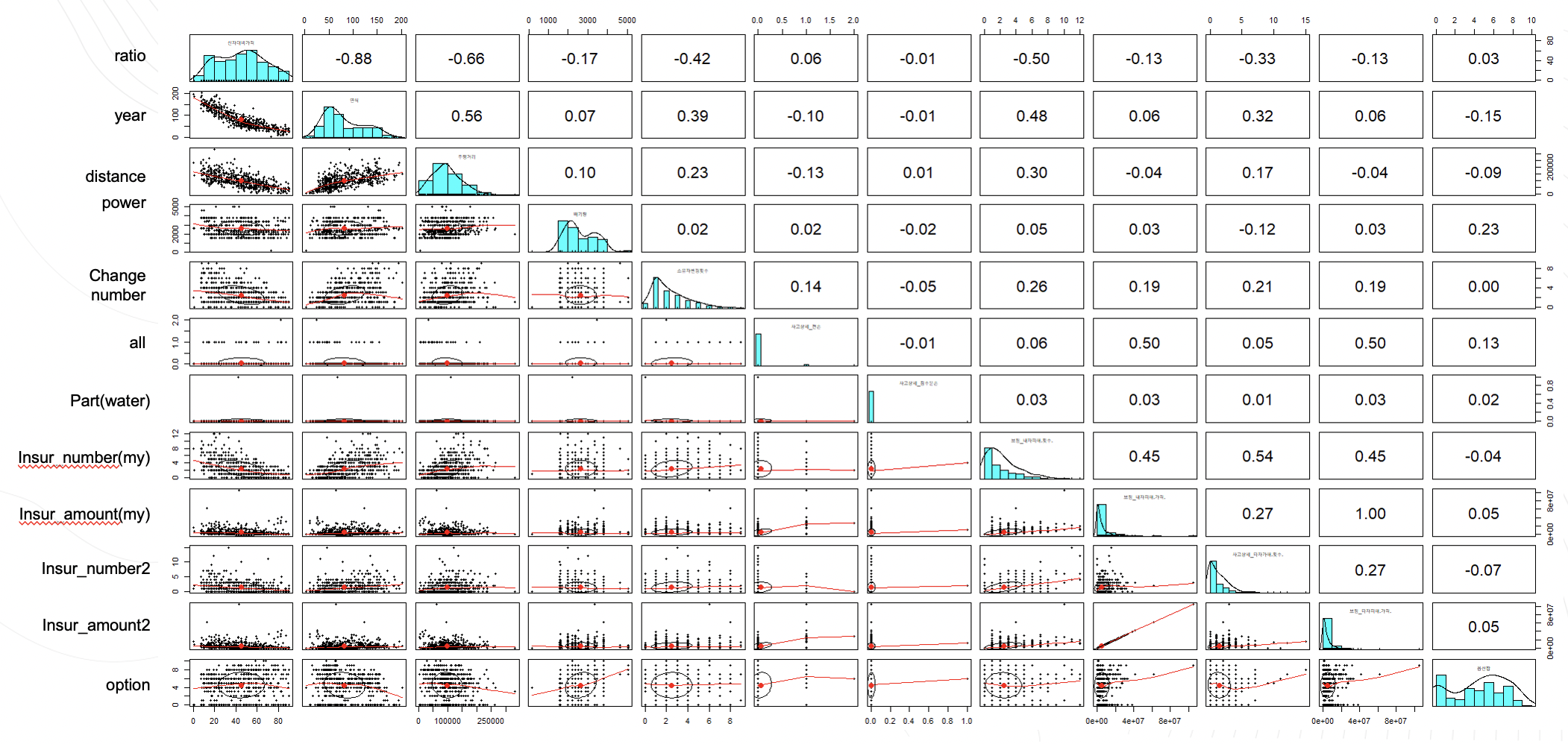
다음은 산포도를 그린 시각화 자료입니다.
먼저 원은 상관관계 타원형으로 상관관계의 정도를 시각화한것이고 타원형 중심의 포인트는 x와 y축 변수에 대한 평균값 지점을 나타내며 두 변수간 상관관계는 원모양으로 나타납니다.
원이 타원형태로 늘어날수록 두 변수간의 상관관계가 강하다고 판단할 수 있습니다.
또한 빨간 곡선은 뢰스곡선으로 x축과 y축 변수 사이에 일반적인 관계를 나타냅니다.
반응변수에 영향을 크게 미치지만 데이터의 분포가 일정하지 않은 연식,주행거리,소유자변경횟수,내차피해횟수,내차피해가격,타차피해횟수,타차피해가격의 피쳐를 확인할 수 있습니다.
범주형 변수처리
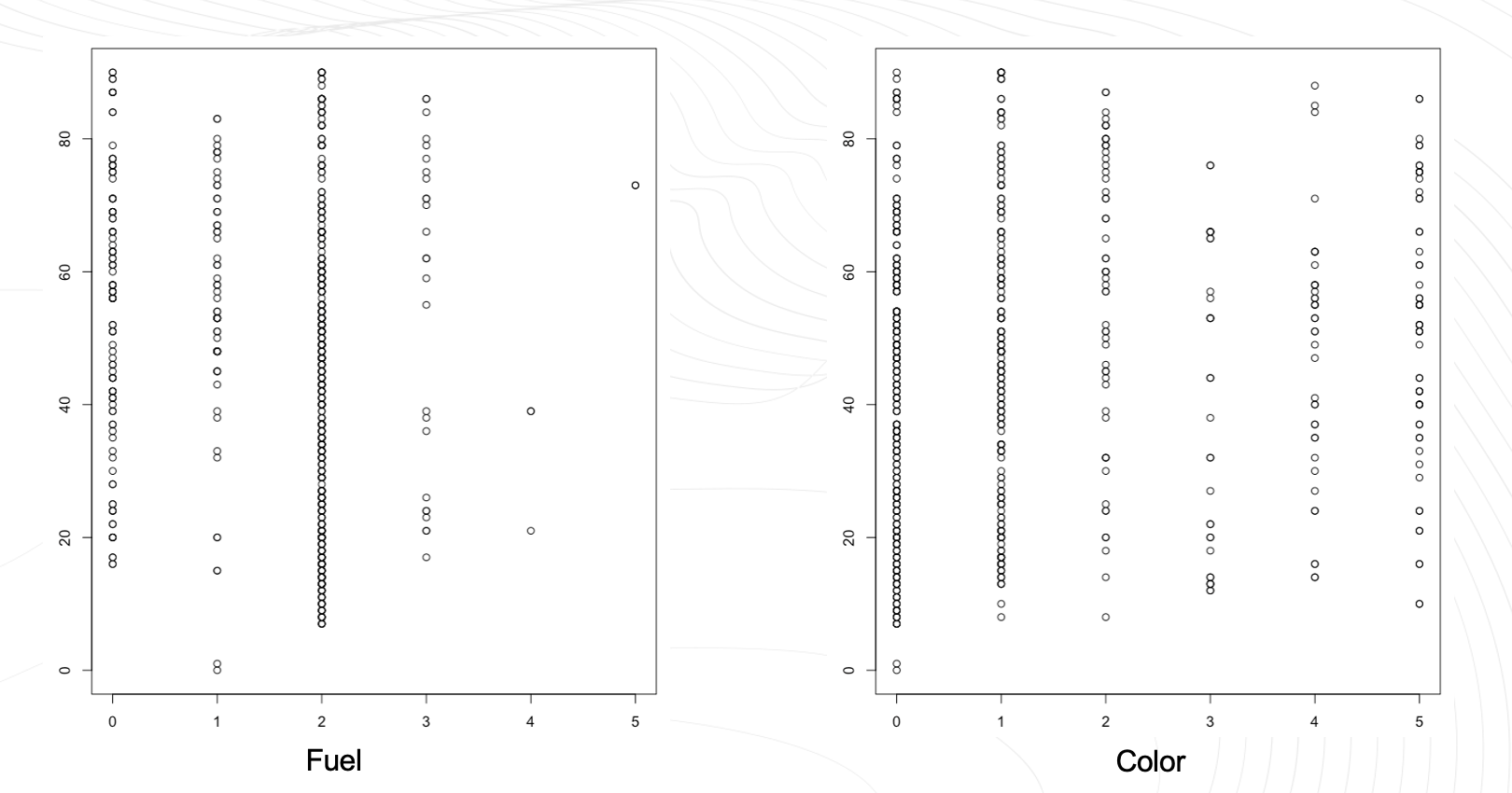
범주형 변수인 연료와 색상은 모두 랜덤하게 나와 interation 변수를 사용하지 않기로 결정했습니다.
#기존모델
reg<-lm(가격~주행거리+연료+연식+배기량+옵션_선루프+옵션_열선앞+옵션_열선뒤+옵션_전방센서+옵션_후방센서+옵션_전방캠+옵션_후방캠+옵션_어라운드뷰+옵션_네비순정+소유자변경횟수+사고상세_전손+사고상세_침수분손+보험_내차피해.횟수.+보험_내차피해.가격.+사고상세_타차가해.횟수.+보험_타차피해.가격.,data=used_car)
#더미변수로 바꾸는 코드
install.packages("mltools")
library(mltools)
library(data.table)
used_car$색상<-as.factor(used_car$색상)
used_car$연료<-as.factor(used_car$연료)
newdata<-one_hot(as.data.table(used_car))
#개선된모델
regnewdata<-lm(신차대비가격~주행거리+연료_0+연료_1+연료_2+ +연식+ 배기량+색상_0+색상_1+색상_2+색상_3+색상_4+색상_5+옵션_선루프+옵션_열선앞+옵션_열선뒤+옵션_전방센서+옵션_후방센서+옵션_전방캠+옵션_후방캠+옵션_어라운드뷰+옵션_네비순정+소유자변경횟수+사고상세_전손+사고상세_침수분손+보험_내차피해.횟수.+보험_내차피해.가격.+사고상세_타차가해.횟수.+보험_타차피해.가격.,data=newdata)범주형 변수인 색상과 연료는 더미변수로 바꾸어서 모델의 성능을 확인해보니 개선된 것을 볼 수 있습니다.
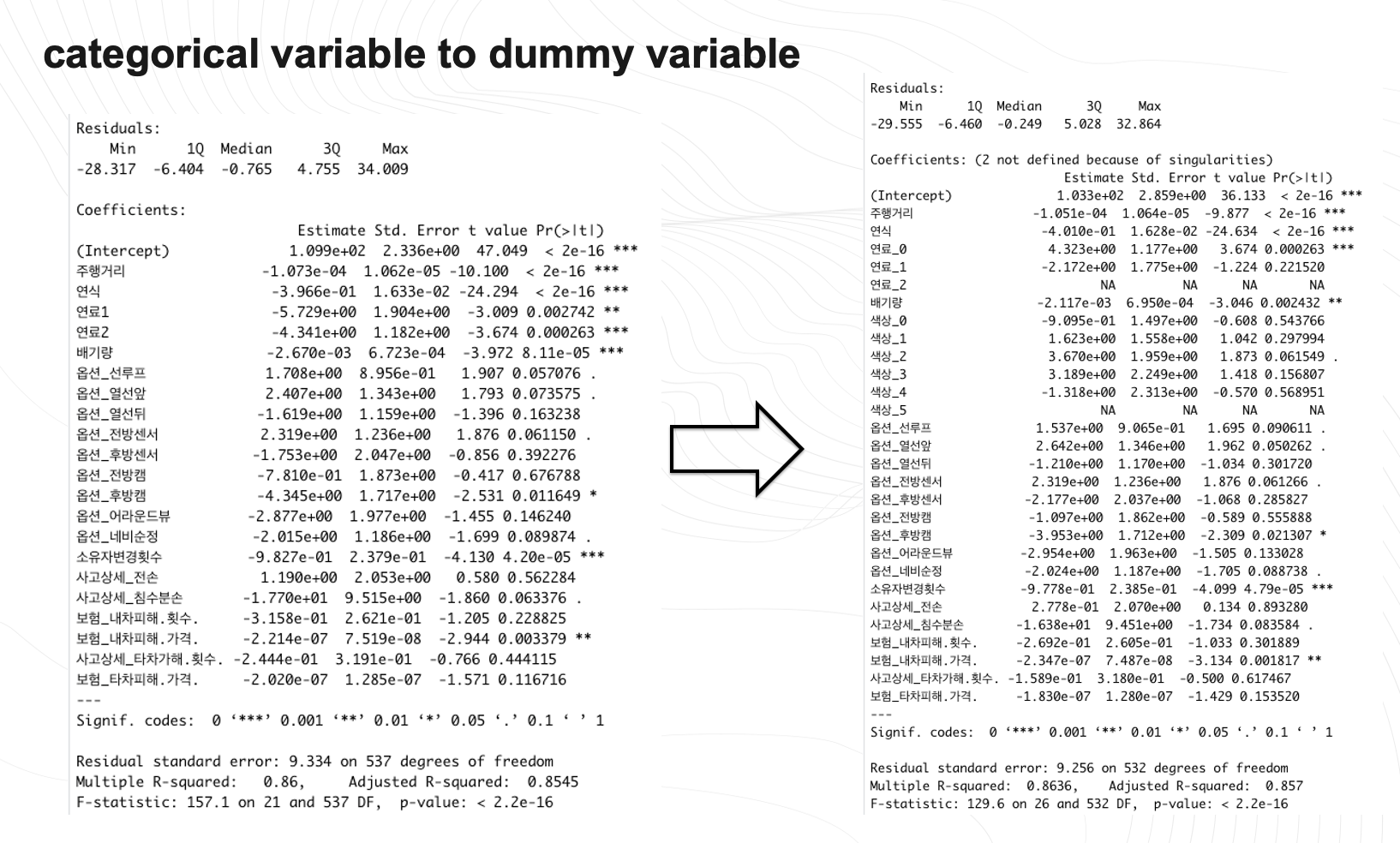
옵션값들 처리
#stepwise 사용
regnewdata<-lm(신차대비가격~주행거리+연료_0+연료_1+연료_2+배기량+색상_0+색상_1+색상_2+색상_3+색상_4+색상_5+옵션_선루프+옵션_열선앞+옵션_열선뒤+옵션_전방센서+옵션_후방센서+옵션_전방캠+옵션_후방캠+옵션_어라운드뷰+옵션_네비순정+소유자변경횟수+사고상세_전손+사고상세_침수분손+보험_내차피해.횟수.+보험_내차피해.가격.+사고상세_타차가해.횟수.+보험_타차피해.가격.,data=newdata)
#전진선택법
forward<-step(regnewdata,direction = "forward")
summary(forward)
#후진선택법
backward<-step(regnewdata,direction = "backward")
summary(backward)
#단계적선택법
stepwise<-step(regnewdata,direction = "both")
summary(stepwise)step function을 사용해 전진선택법,후진선택법,단계적선택법을 하나씩 적용해 보았고, 후진 선택법과 단계적 선택법이 0.8576으로 전보다 개선되었음을 확인할 수 있습니다.

아웃라이어 처리
library(gridExtra)
library(olsrr)
library(ggrepel)
Row<-c(1:559)
re.dat<-cbind(1:559,newdata[,])
res.influence.dat<-cbind(re.dat,cooks.distance(backward),dffits(backward),ols_hadi(backward)$hadi)
colnames(res.influence.dat)[c(40,41,42)]<-c("C_i","DFITs_i","H_i")
p2<-ols_plot_dffits(backward)
p3<-ggplot(res.influence.dat,aes(x=Row,y=H_i))+geom_point()+geom_text_repel(data = filter(res.influence.dat, H_i>0.2),aes(label=Row))
grid.arrange(p2,p3,nrow=1) 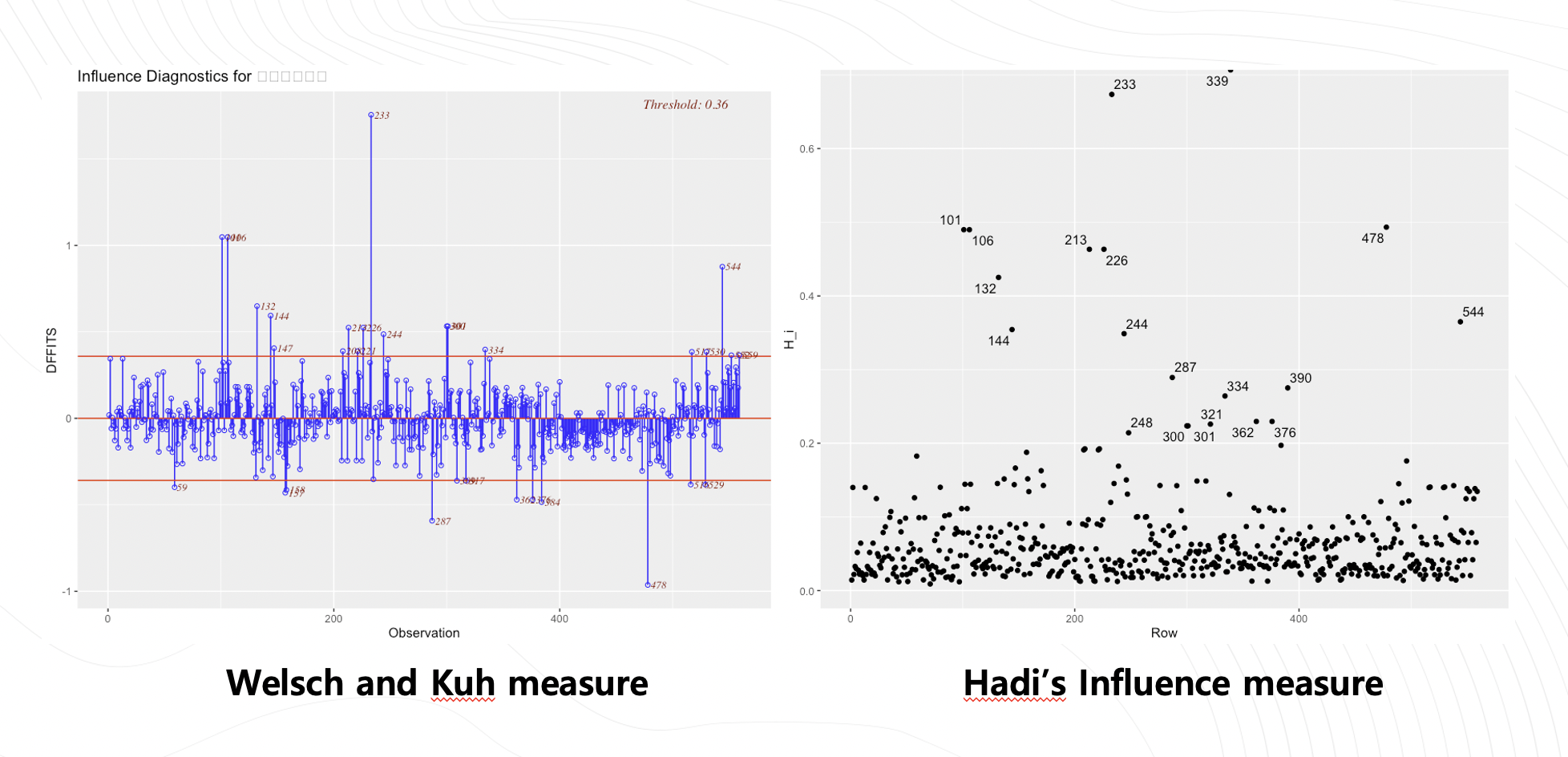
다른 샘플들에 비해 비정상적이게 상대적으로 큰 영향을 주는 샘플을 알아보기 위해 Welsch and Kuh measure을 사용하고
Response variable과 predictor들에서의 아웃라이어를 같이 확인하기 위해 Hadi’s Influence measure을 사용했습니다.
두가지 기법을 통해 약 20개의 영향점들을 찾았습니다.
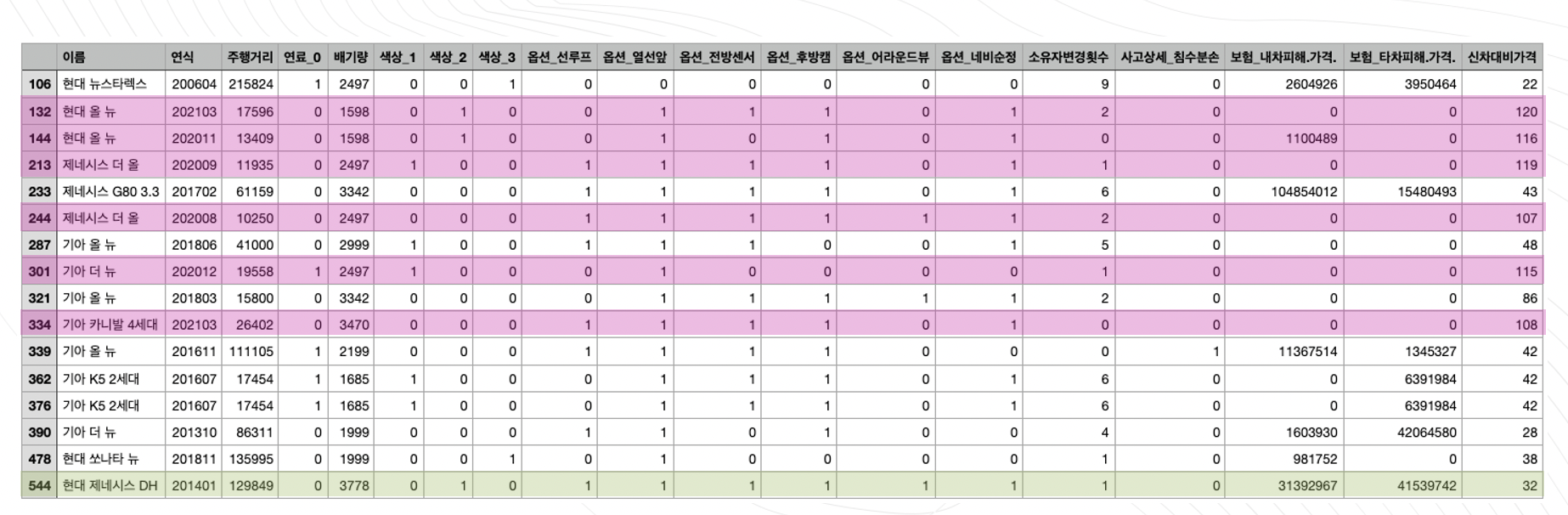
아웃라이어 이거나 영향점인 이유를 찾기위해 하나씩 조사해봤을때
분홍색부분은 연식이 얼마 되지않았고 무사고여서 신차대비가격이 100이상이고
연두색부분은 사고피해가격이 특히 더 큰 샘플입니다. 두부분에 속한 샘플들을 영향점이라 생각했고
나머지는 특별한 특징이 없기때문에 아웃라이어로 판단해 데이터를 삭제했습니다.
tmp<-newdata[-c(101,106,226,233,248,287,300,321,339,362,376,390,478),]
tmp1<-lm(신차대비가격 ~ 주행거리 + 연료_0 + 연식 +
배기량 + 색상_1 + 색상_2 + 색상_3 + 옵션_선루프 +
옵션_열선앞 + 옵션_전방센서 + 옵션_후방캠 +
옵션_어라운드뷰 + 옵션_네비순정 + 소유자변경횟수 + 보험_내차피해.가격. +
보험_타차피해.가격., data = tmp)
summary(tmp1)
plot(backward,2)
plot(tmp1,2)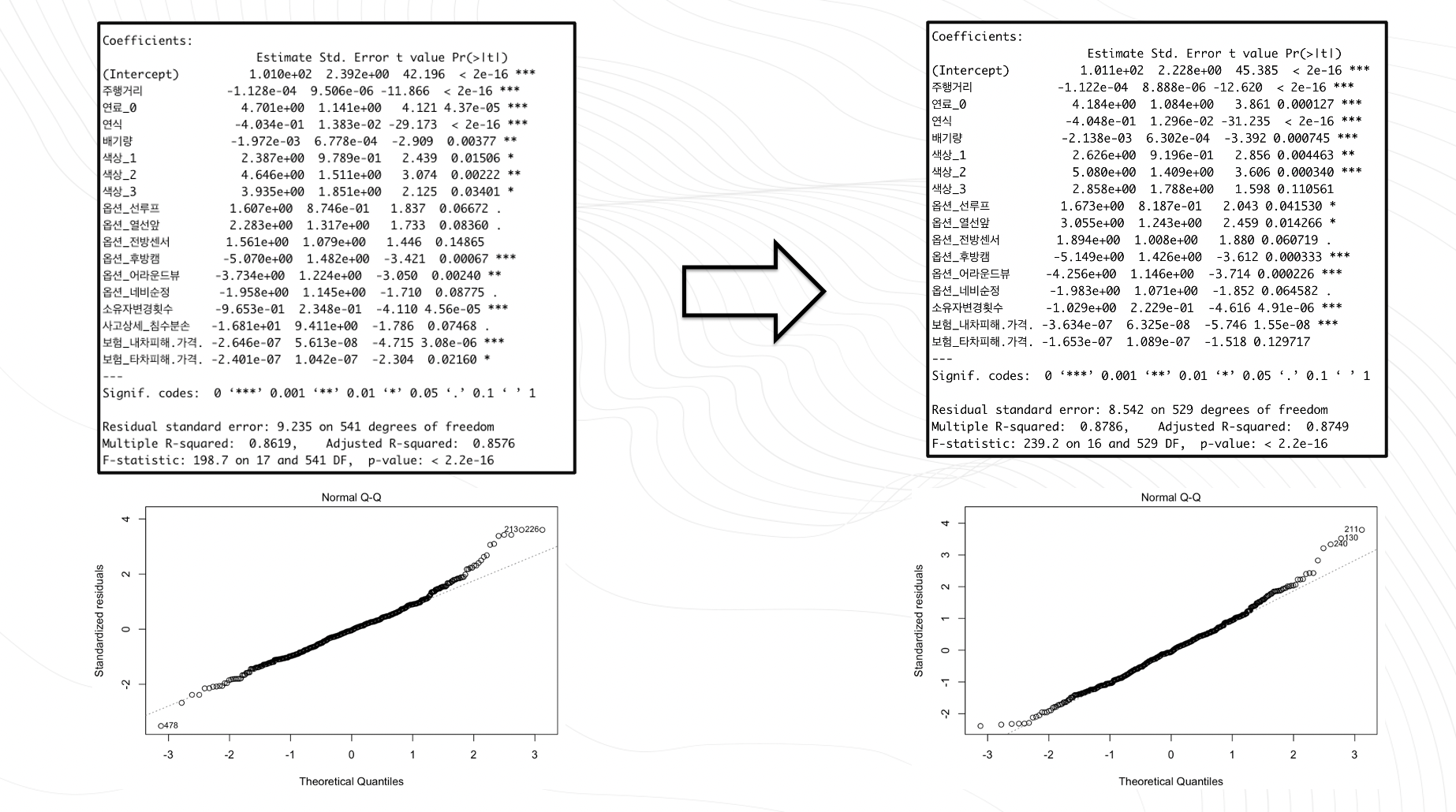
아웃라이어를 삭제한후 성능비교를 해보면 R^2값도 0.8576에서 0.8749로 성능이 좋아졌고 qqplot을 통한 잔차분석에서도 더 선형적인 그래프를 확인할 수 있습니다.
데이터변형
로그변형 공식과 이분산성제거 공식을 아래와 같이 세웠다.
로그변형
이분산성제거
ggplot(tmp,aes(x=주행거리,y=신차대비가격))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("distance driven")+ylab("price ratio")
ggplot(tmp,aes(x=주행거리,y=log(신차대비가격)))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("distance driven")+ylab("price ratio")
ggplot(tmp,aes(x=연식,y=신차대비가격))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("year")+ylab("price ratio")
ggplot(tmp,aes(x=연식,y=log(신차대비가격)))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("year")+ylab("price ratio")
ggplot(tmp,aes(x=보험_내차피해.가격.,y=신차대비가격))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("car damage price (mine)")+ylab("price ratio")
s1_dam1<-data.frame(damp1=tmp$보험_내차피해.가격.,priceratio=tmp$신차대비가격)
s4lm<-lm(priceratio~damp1,data=s1_dam1)
summary(s4lm)
s1_dam1$damp1<-ifelse(s1_dam1$damp1==0,1,s1_dam1$damp1)
s1_dam1$Y_new<-s1_dam1$priceratio/s1_dam1$damp1
s1_dam1$X_new<-1/s1_dam1$damp1
lm_dam1<-lm(Y_new~X_new,data=s1_dam1)
summary(lm_dam1)
ggplot(s1_dam1,aes(x=X_new,y=Y_new))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("car damage price (mine)")+ylab("price ratio")
ggplot(tmp,aes(x=보험_타차피해.가격.,y=신차대비가격))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("car damage price (others)")+ylab("price ratio")
s1_dam2<-data.frame(damp2=tmp$보험_타차피해.가격.,priceratio=tmp$신차대비가격)
s5lm<-lm(priceratio~damp2,data=s1_dam2)
summary(s5lm)
s1_dam2$damp2<-ifelse(s1_dam2$damp2==0,1,s1_dam2$damp2)
s1_dam2$Y_new<-s1_dam2$priceratio/s1_dam2$damp2
s1_dam2$X_new<-1/s1_dam2$damp2
lm_dam2<-lm(Y_new~X_new,data=s1_dam2)
summary(lm_dam2)
ggplot(s1_dam2,aes(x=X_new,y=Y_new))+
geom_point()+
geom_smooth(method=lm,se=F)+xlab("car damage price (others)")+ylab("price ratio")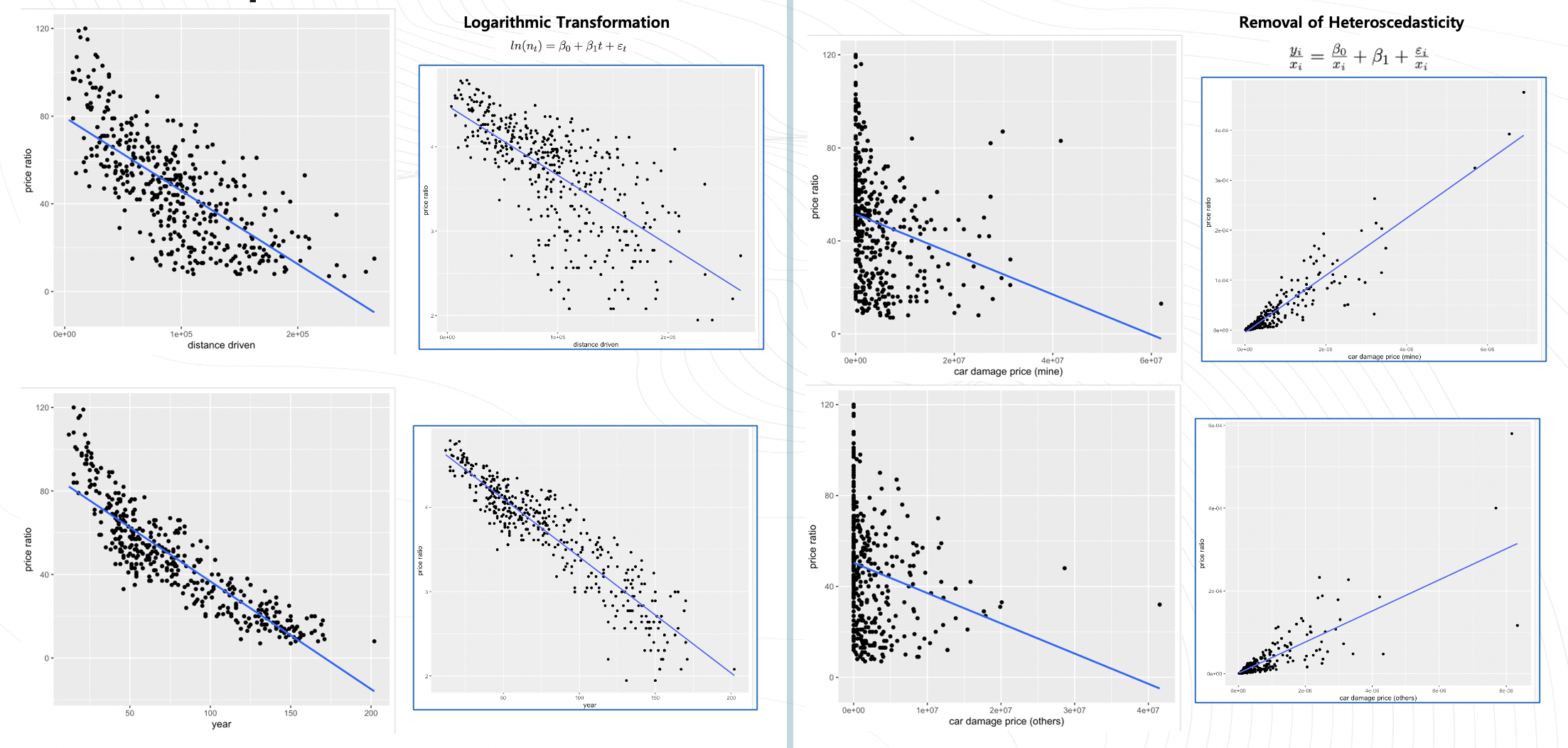
serial 변수들에 대한 산점도 입니다. 주행거리와 연식을 선형그래프로도 표현가능하지만 data transformation을 통해 지수함수로 표현하면 더 명확해 질 것이고
나머지 2개의 산점도에 대해서도 약간의 이분산성을 보여 이분산성 제거를 위해 함수를 변형시켰습니다. 변형시킨데이터가 선형성을 좀더 따르는거 처럼 보입니다.
datatrv<-data.frame(tmp[,-c(8,36,34,32)])
damp2tmp<-ifelse(tmp$보험_타차피해.가격.==0,1,tmp$보험_타차피해.가격.)
datatrv$신차대비가격<-tmp$신차대비가격/damp2tmp
datatrv$사고상세_타차가해.가격.<-1/damp2tmp
damp1tmp<-ifelse(tmp$보험_내차피해.가격.==0,1,tmp$보험_내차피해.가격.)
datatrv$사고상세_내차피해.가격.<-1/damp1tmp
datatrv$배기량<-1/tmp$배기량
names(datatrv)
datatr<-lm(log(신차대비가격)~주행거리 + 연료_0 + 연식 +
배기량 + 색상_1 + 색상_2 + 색상_3 + 옵션_선루프 +
옵션_열선앞 + 옵션_전방센서 + 옵션_후방캠 +
옵션_어라운드뷰 + 옵션_네비순정 + 소유자변경횟수 + 사고상세_내차피해.가격. +
사고상세_타차가해.가격.,data=datatrv)
summary(datatr)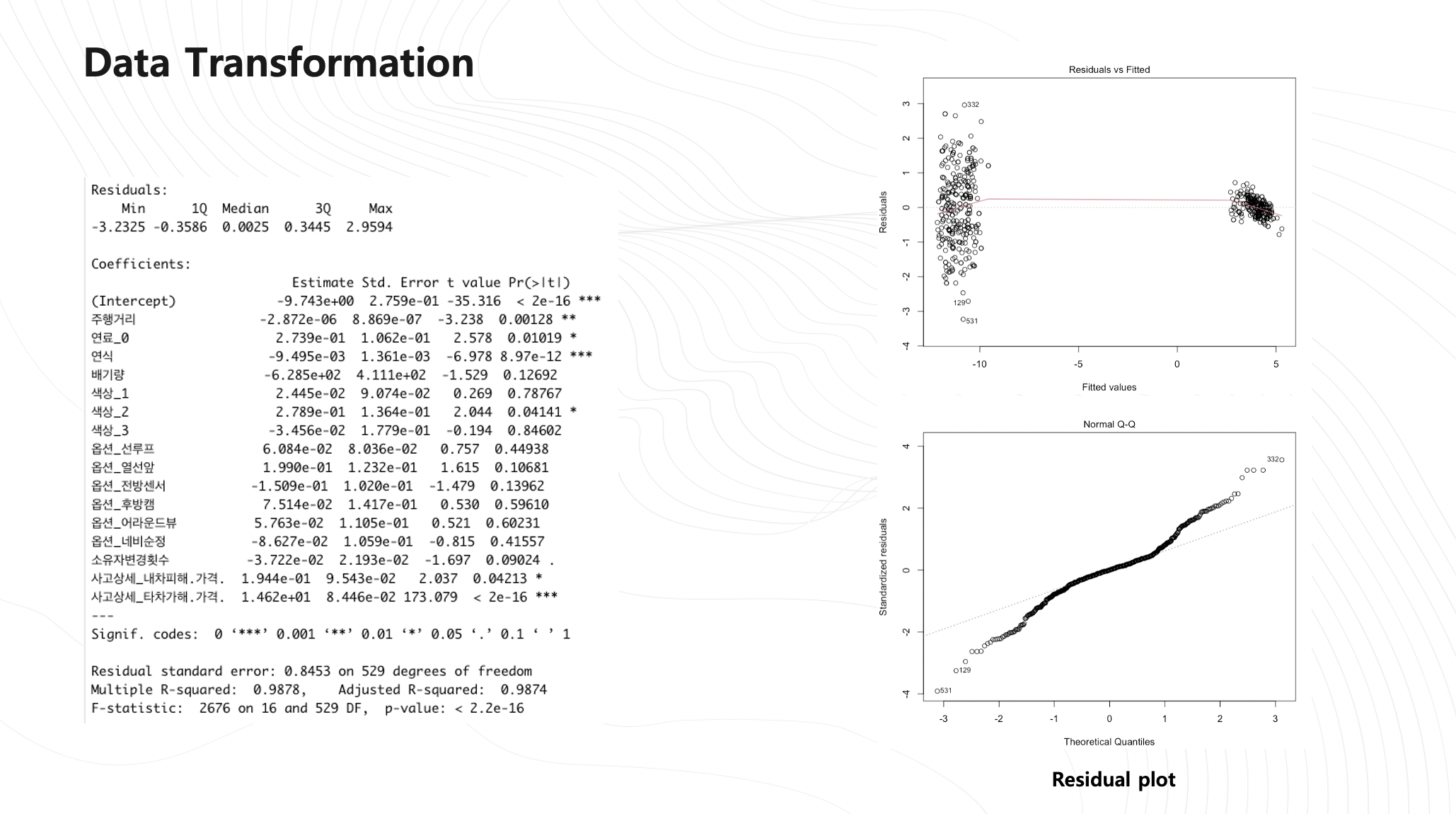
데이터를 변형시킨 후 회귀분석을 진행하였는데 R^2가 0.9872까지 개선되었는데 잔차분석을 해보니 좋은 모델이 아니였습니다.
위에 그래프도 랜덤하게 분포되어있지 않고 qqplot도 직선을 잘 따르지 않아 이분산성이 있다고 가정한게 틀린것 같아 로그함수만 추가할 예정입니다.
tmp3<-lm(신차대비가격 ~ log(주행거리) + 연료_0 + log(연식) +
배기량 + 색상_1 + 색상_2 + 색상_3 + 옵션_선루프 +
옵션_열선앞 + 옵션_전방센서 + 옵션_후방캠 +
옵션_어라운드뷰 + 옵션_네비순정 + 소유자변경횟수 + 보험_내차피해.가격. +
보험_타차피해.가격., data = tmp)
summary(tmp3)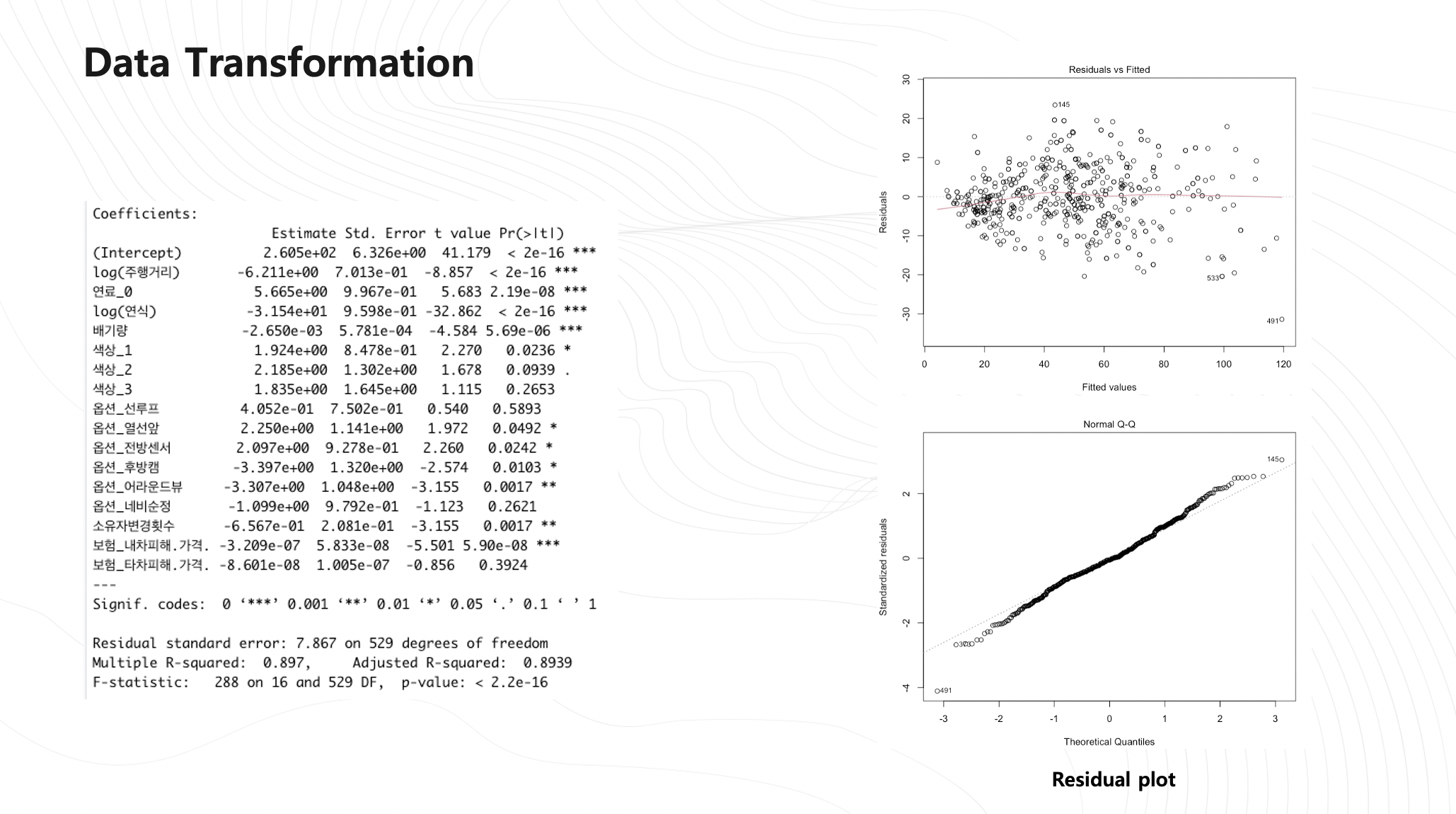
로그변환만을 진행했을때 이전 0.8749에 비해 0.8939로 개선되었고 잔차플롯도 위 그림이 랜덤한 분포를 보이고 qqplot도 직선을 잘 따르는것으로 보입니다.
테스트
테스트를 위해 보배드림에서 50개 국산차로 데이터를 새로 크롤링하여 사용했습니다.
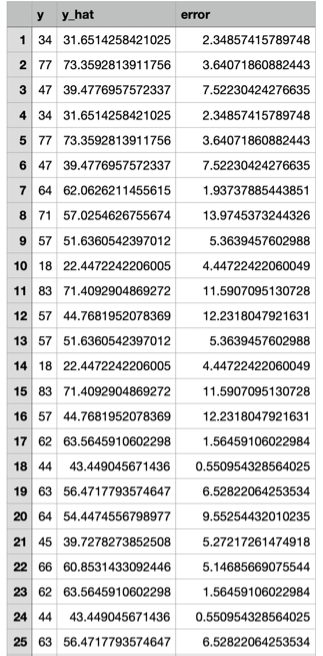
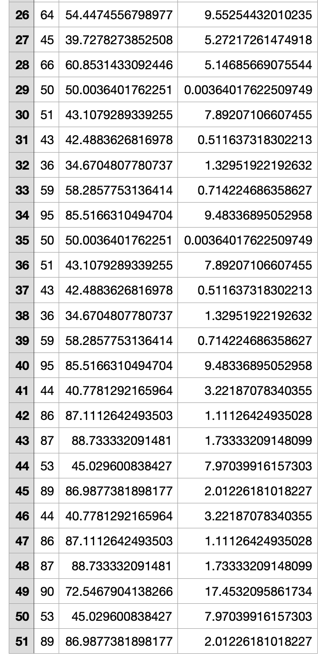
y는 실제값 y_hat은 예측값 error는 오차를 나타낸표이며 다음 그래프를 통해 분포를 잘 따르는지 알아보겠습니다.
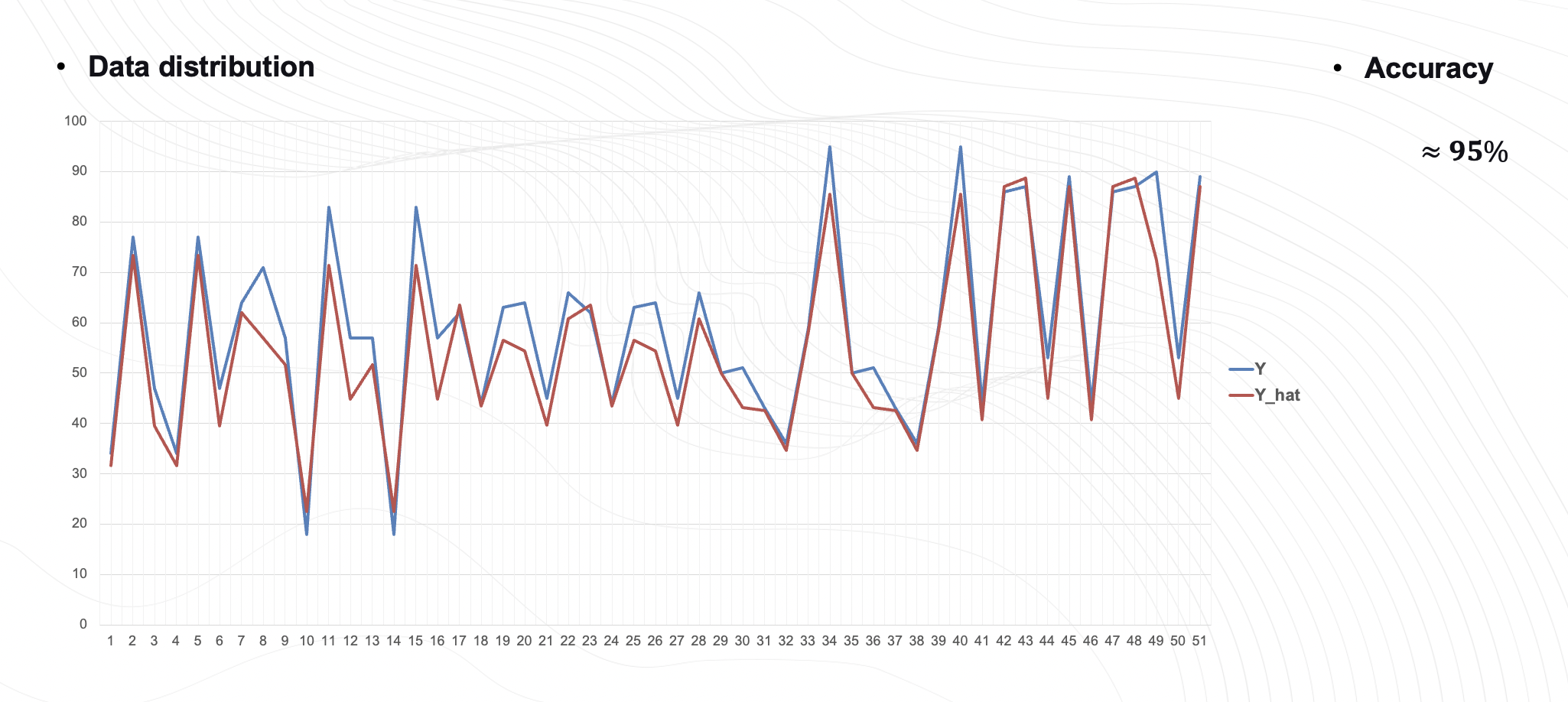
그래프에서 데이터분포를 통해 y_hat이 y의 분포를 대체로 잘 따르는것을 볼수있고 정확도는 약 95%입니다.
