Deep contextualized word representations논문에 대해 공부한 내용 정리한 포스팅입니다.
잘못된 부분에 대한 의견 환영합니다 공부를 위해 댓글에 달아주시면 감사하겠습니다!!
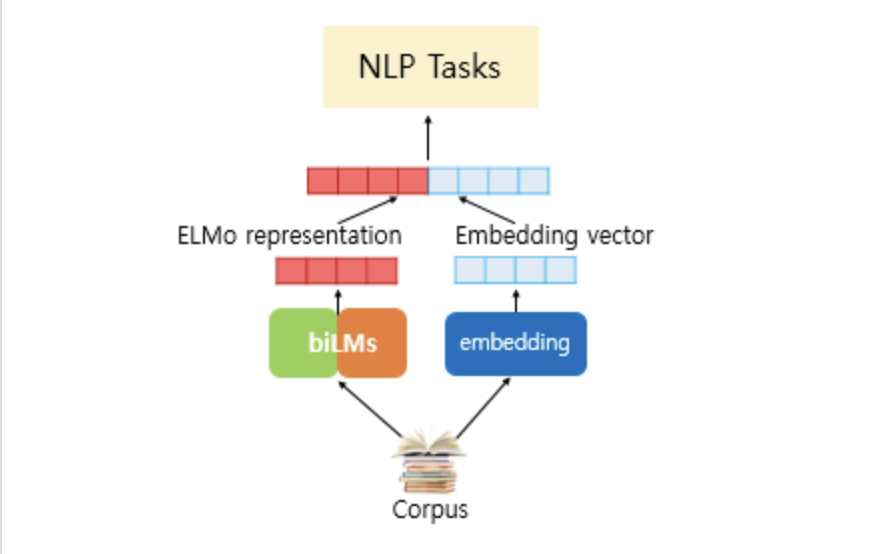
논문소개
언어모델로 하는 임베딩으로 사전 훈련된 언어모델을 사용한다.
RNN계열의 LSTM을 sequential한 임베딩으로 순방향 언어모델과 역방향 언어모델을 가중치 공유없이 따로 학습시킨다.
순방향,역방향으로 학습된 언어모델을 이용해 각 벡터를 concat후 문맥이나 구문중 어디에 가중치를 둘지 목적에 맞게 사용한다.
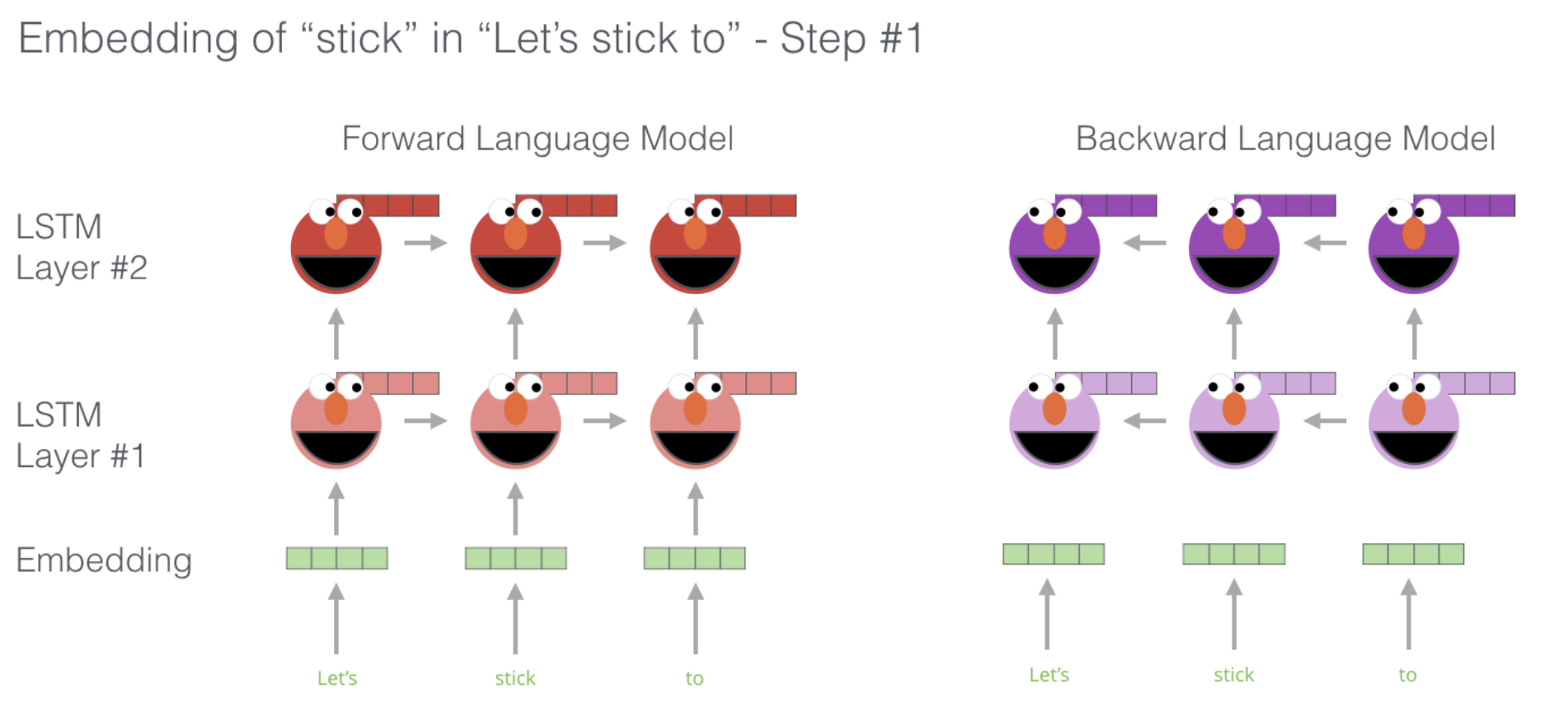
예를 들어 문장이 Let's stick to라면 LSTM을 이용해 순뱡향과 역방향으로 따로 학습시키며 가중치를 공유 하지 않는다.
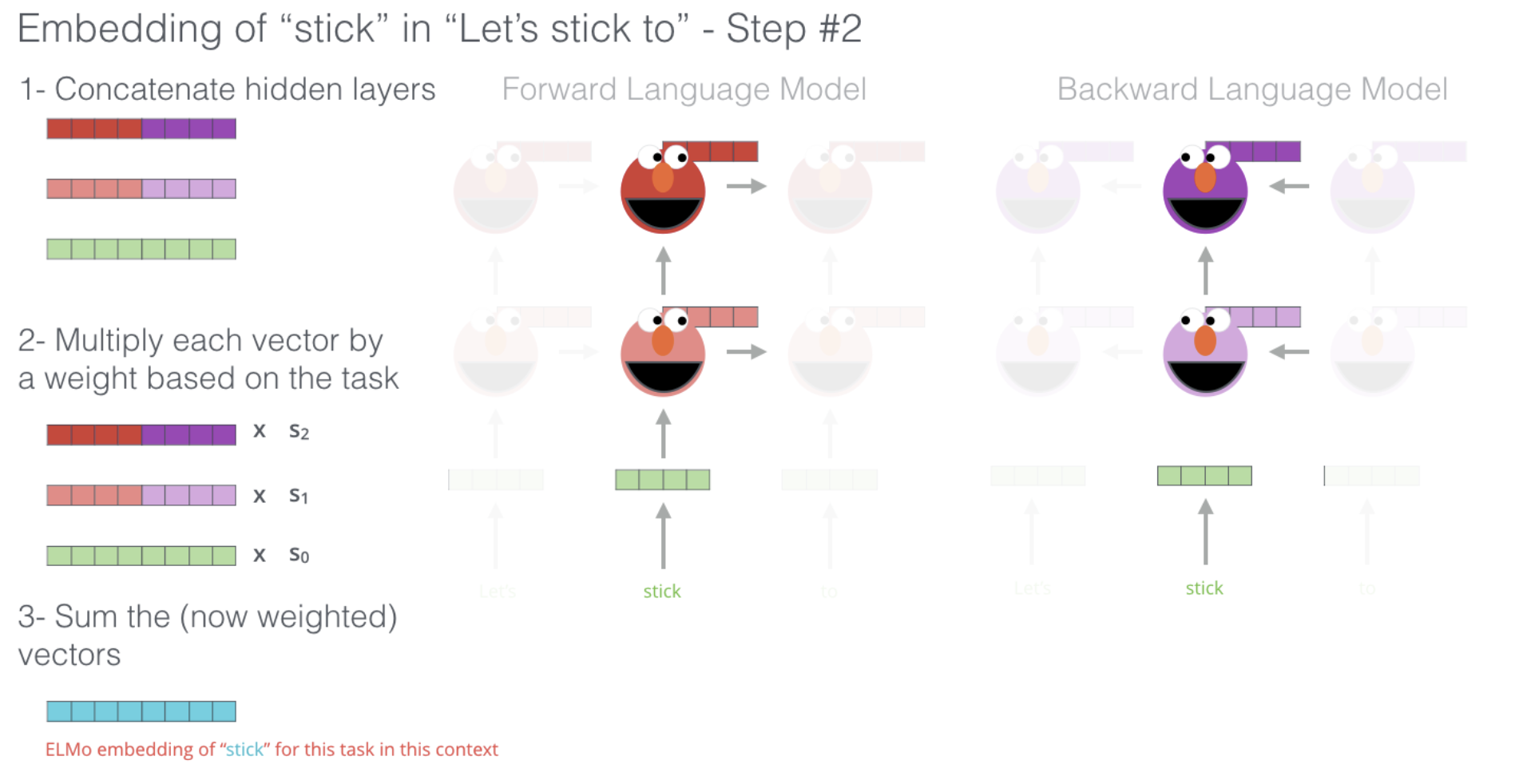
1- 단어 stick의 임베딩을 만들기 위해서 순방향과 역방향으로 학습되었던 벡터를 각 hidden layer에서 가져와 concat을 통해 만들어낸다.
2- 이때, higher-level 레이어는 문맥적으로 lower-level 레이어는 구문적으로 학습이 되어있다.
목적에 맞게 가중치를 둔다.
3- 가중치에 따라 합해 벡터를 구한다.
논문요약
ELMo: Embeddings from Language Models
한 문장안에 N개의 토큰이 있고 다음과 같이 표현한다.
Bidirectional language models
forward
순방향 모델에서는 k번째 토큰의 확률을 이전 을 이용해 모델링 확률을 이용해 계산한다.
따라서 문장에 대한 확률 은 다음과 같다.
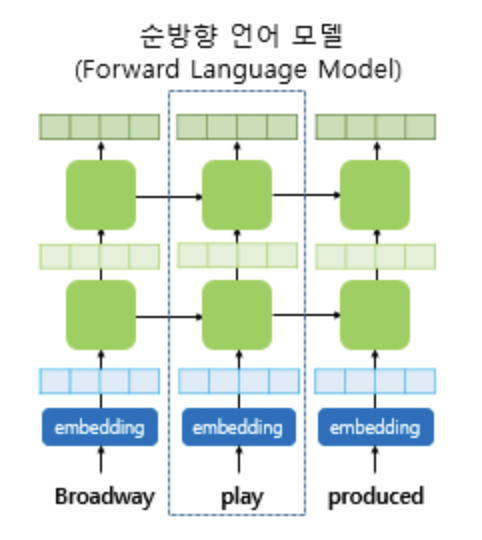
신경망모델에서 문맥에 상관없이 임베딩한 k번째 토큰에 대한 representation을 라 두고
이 을 순방향 LSTM의 L개의 layer들을 통해 계산한다. 이때 토큰을 임베딩한 신경망 모델은 토큰 임베딩, 문자별로 수행한 CNN,Word2vec,GloVe등등 이 있는데 이중하나를 사용한다.
k번째 위치에서 각 LSTM 레이어는 이제 문맥을 반영한 representation 을 내보낸다. 이때 j= 1,2,3,....,L 이고, L은 레이어개수로 하이퍼파라미터이다.
제일 위쪽의 레이어 LSTM의 아웃풋은 로 softmax레이어와 함께 다음 토큰 을 예측하는데 사용된다.
backward
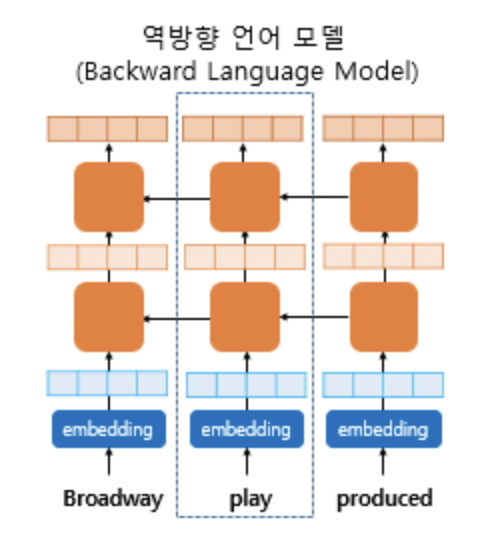
forward 언어모델과 비슷한 식으로 순서만 역방향이되어 주어진 미래 문맥들을 이용해 이전의 토큰을 예측한다.
마찬가지로 역방향 LSTM레이어에서 k번째 토큰 j레이어에서 나온 아웃풋은 이다.
이제 순방향과 역방향에 두가지 모두에 대해 log likelihood를 최대화 하는 방향으로 학습한다. 식은 다음과 같다.
- 는 연결된 토큰 representation과 소프트맥스 레이어의 파라미터이다.
ELMo
ELMo는 위 모델인 biLM에서 처리하려는 task에 맞게 중간단계 레이어들의 합을 반영한 representation이다. task가 문맥을 더 잘 반영해야하는 task인지, 구문을 더 잘 반영해야하는 task인지, 이외에도 다양한 task들이 있고 그에 맞게 중간단계의 layer들에 가중치를 두어서 specific하게 합을 구한다.
각 토큰 에 대해서 L개의 레이어를 가진 biLM은 2L+1개의 representation을 가진다. L개는 순방향 모델에서(), L개는 역방향 모델에서(), 1개는 단어임베딩이다().
하나의 집합인 로 표현하면 다음과 같다.
에서 j=0이면 와 같다. 차원을 맞추기 위해 이렇게 사용한다.
각 레이어에서 순방향 모델과 역방향 모델에서 나온 벡터들을 concat시킨다.
그 후 ELMo를 모든 레이어들에 대한 정보를 가진 일차원 벡터로 만들기 위해 각 레어어들에 대한 가중치인 를 부여해 가중합을 만들고 scale-vector인 를 통해 값을 조절해준다. 가중치 는 레이어별로 다르게 부여되며 softmax를 통해 정규화된 가중치이다.
k번째 토큰에 대한 ELMo의 식은 다음과 같다.
Using biLMs for supervised NLP tasks
이제 자연어 처리에서 이 ELMo벡터가 어떻게 사용되는지 설명한다.
biLM을 실행시키고 각 단어에대해 모든 레이어에서의 representation을 기록한다.
그리고 나서 마지막에 이 representation들의 선형결합을 통해 구한다.
자세한건 아래와 같다.
기존 representation
먼저, N개의 토큰으로 이루어진 한 시퀀스가 이다.
문맥을 고려하지 않은 토큰 하나에 대한 k번째 representation은 이다.
representation은 사전에 학습된 워드임베딩을 사용했다.
그 후, 양방향 모델인 RNN,CNN,FFN등을 사용해 문맥을 고려하는 representation 를 만든다.
ELMo를 더한 representation
우선 가중치를 freeze하는것 부터 알아보자면,
Finetuning vs Freezing
task 진행하면서 임베딩된 토큰들을 바꾸는지 아닌지에 대한 여부이다.
Word2Vec나 GloVe등으로 학습된 임베딩 매트릭스가 있을때, 처리하려는 문장은 로 이루어져있다.
임베딩 매트릭스를 통해 토큰들은 word vector들로 바꿔진다. 이를 예를들어 라고 하자.
Finetuning: task를 진행하면서 그에 맞게 도 바꾸면서 training시킨다.
Freezing: 임베딩 매트릭스를 통해 바뀐 는 언어모델에서 학습을 시키면서 고정시켜놓는다.
이제, ELMo를 더하기 위해, biLM의 가중치를 freeze하고 ELMo벡터와 k번째 임베딩된 벡터를 concat한다.
그러면 벡터가 RNN으로 들어간다.
RNN으로 들어갈때 뿐만 아니라 output에 대해서도 ELMo벡터를 더해주면 더 좋은 성능을 낼 수 있다.
즉, ELMo벡터를 사용해 나온 결과값 와 를 또 concat시켜 구한다.
그리고 이 벡터를 사용해 output을 구한다.
dropout
마지막으로 dropout을 이용해 ELMo가중치들을 regularization을 할 수 있다.
로스에 을 더해주면 ELMo가중치에 bias값을 주면서 biLM레이어들의 평균값에 가까이 유지되게 해준다.
Evaluation
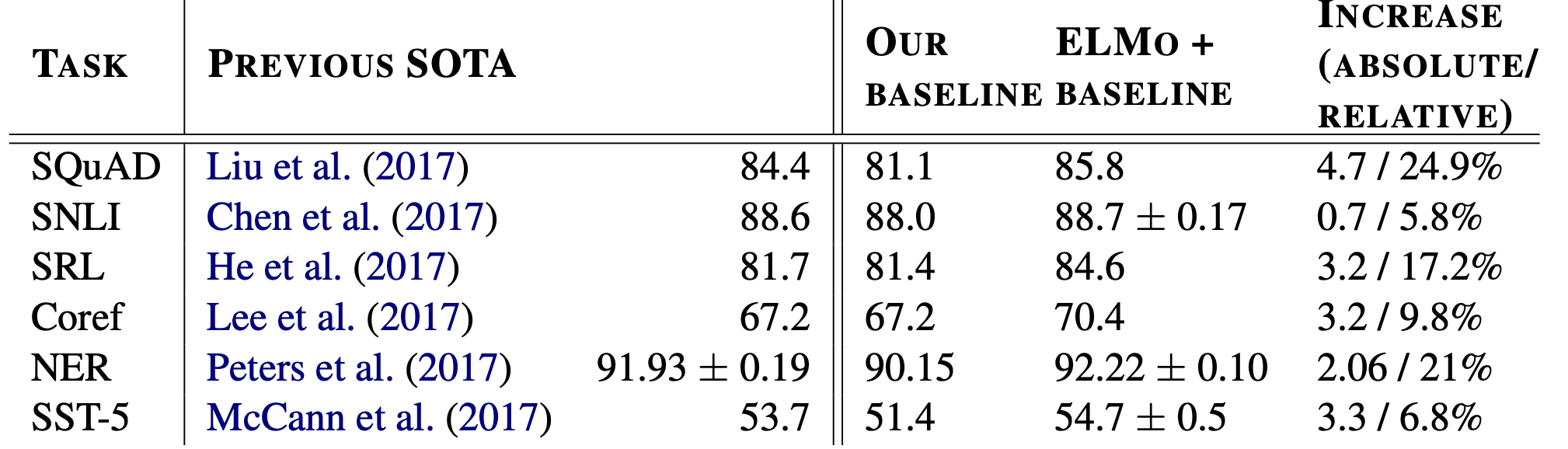
다양한 downstream task에서 ELMo를 사용해 성능이 좋아진걸 볼 수 있다.
Analysis
Alternate layer weighting schemes
ELMo벡터를 구할때 각 레이어에 대한 가중치인 를 부여해 가중합을 통해 구한다고 했는데, 이때 가중치를 어떻게 두어야 성능에 좋을지에 대한 분석이다.
가장좋은 방법은 task에 맞게 weight를 조정하는것
그다음으로 모두 동등한 weight를 주는것
그다음으로 high-level레이어에 가중치를 크게 주는것
마지막으로 low-level 레이어에 가중치를 크게 주는것
이 순서대로 성능이 나빠졌다.
Where to include ELMo?
앞내용에 ELMo를 더한 representation 부분에서 input과 output두 곳 모두에서 ELMo벡터를 concat시켜야 성능이 더 좋아진다고 했는데, 과연 한곳에서만 사용해도 성능이 좋아지는지에대한 분석이다.
가장 좋은 방법은 input, output 두 곳 모두에서 사용하는것
그다음으로 input부분에서만 사용하는것
그다음으로 output부분에서만 사용하는것
마지막으로 사용하지 않는것
이 순서대로 성능이 나빠졌다.
What information is captured by the biLM’s representations?

GloVe에서 play에 대해서 문맥이 아닌 단어에 대해서만 구별한다. 스포츠에 관련된 단어들만을 nearest neighbors로 가지는데 반면에 biLM을 사용한다면 play가 스포츠관련이 아닌 연극의 의미를 가지는 것에 대해서도 구별할 수 있다.
결론
biLM로부터 문맥을 고려하는 representation을 접근할 수 있었다. 이는 훨씬 더 좋은 성능을 내며 다양한 NLP task에 적용 할 수 있다.
이번 논문을 통해 언어모델뿐만 아니라 word representation에 대해서도 중요하다는 걸 알게된거 같다.
참고
논문링크
https://arxiv.org/pdf/1802.05365.pdf
논문요약부분
https://wikidocs.net/33930
http://jalammar.github.io/illustrated-bert/
개념공부
https://www.youtube.com/watch?v=zV8kIUwH32M&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=18
