지난 포스팅에서는 Huggingface에서 다양한 문장 유사도 모델들을 테스트 해보고 Gradio로 간단한 유사도 기반 챗봇을 구현해 보았습니다. 이번에는 LLM에서 Langchain retriever의 한 방법으로 앙상블 방법을 활용하는 데서 착안하여 유사도 기반 챗봇에서도 BM25와 임베딩 모델을 결합한 앙상블 모델로 답변을 출력하도록 만들어 보았습니다. 또한, 지난 포스팅에서 사용자의 질문과 데이터셋의 질문 간 유사도를 측정한 것과 달리 이번에는 데이터셋의 답변과의 유사도를 측정하였습니다.
BM25와 임베딩 모델의 장점은 다음과 같습니다.
- BM25: 텍스트의 정확한 단어 일치를 기반으로 한 전통적인 정보 검색 모델로, 검색된 텍스트의 관련성을 평가
- 임베딩 모델: 텍스트의 의미적 유사성을 평가하여, 단어가 정확히 일치하지 않더라도 의미적으로 유사한 내용 도출
앙상블 모델을 활용하면 다음 두 가지를 원하는 비율로 설정하여 도출한 결합 점수를 바탕으로 최종 답변을 도출할 수 있게 됩니다.
- 사용자 질문의 키워드를 데이터셋의 답변에 포함 여부
- 사용자의 질문과 데이터셋의 답변의 코사인 유사도 (맥락 파악 가능)
전체 코드는 코랩을 확인해 주세요. 코랩 실행 시에는 GPU를 활용하서야 에러가 나지 않습니다. 저는 T4 GPU를 사용하였습니다.
앙상블 모델 유사도 기반 챗봇 만들기 실습 코랩
실습에서 사용한 데이터셋은 아래 링크 json 파일입니다.
유사도 기반 챗봇 데이터셋
- 필요한 패키지 설치
pip install rank_bm25 konlpy sentence_transformers gradio- 데이터 불러와서 질문과 답변 리스트 생성
50개씩 만든 줄 알았는데 과학만 68개네요 😳
import json
# JSON 파일 경로 지정
file_path = 'science_data.json'
# JSON 파일 읽기
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 질문과 답변 리스트 생성
questions = [item['instruction'] for item in data]
answers = [item['output'] for item in data]
print("총 질문 개수:", len(questions))
----------
총 질문 개수: 68- BM25 상위 3개 답변 확인
from rank_bm25 import BM25Okapi
from konlpy.tag import Okt
import numpy as np
# 형태소 분석기를 통한 한국어 토큰화
okt = Okt()
tokenized_answers = [okt.morphs(question) for question in answers]
# BM25 모델 생성
bm25 = BM25Okapi(tokenized_answers)
# 사용자 질문 입력
query = "전도가 뭐야?"
tokenized_query = okt.morphs(query)
# BM25 점수 계산 및 가장 관련성 높은 질문 찾기
doc_scores = bm25.get_scores(tokenized_query)
# 상위 3개의 인덱스 찾기
top_3_indices = np.argsort(doc_scores)[-3:][::-1]
# 결과 출력
print("사용자 질문:", query)
print("\n상위 3개 질문 및 답변:")
for idx in top_3_indices:
print(f"질문: {questions[idx]}")
print(f"답변: {answers[idx]}")
print()
----------
사용자 질문: 전도가 뭐야?
상위 3개 질문 및 답변:
질문: 열전달의 세 가지 방법을 설명해 주세요.
답변: 열전달의 세 가지 방법은 전도, 대류, 복사입니다. 전도는 열이 물질을 통해 직접 전달되는 과정, 대류는 유체의 이동을 통해 열이 전달되는 과정, 복사는 열이 전자기파의 형태로 전달되는 과정입니다.
질문: 기체의 밀도와 온도 사이의 관계를 설명해 주세요.
답변: 기체의 밀도는 온도에 반비례합니다. 기체의 온도가 상승하면 기체 분자들이 더 빠르게 움직여 부피가 커지므로 밀도가 감소합니다. 반대로 온도가 낮아지면 밀도가 증가합니다.
질문: 화학에서 반응 속도에 영향을 미치는 요소를 설명해 주세요.
답변: 화학 반응 속도에 영향을 미치는 요소로는 온도, 반응물의 농도, 촉매, 압력(기체 반응의 경우) 등이 있습니다. 온도가 높아지면 반응 속도가 증가하며, 농도가 높을수록 반응 속도가 빨라집니다.- Embedding 모델 상위 3개 답변 확인
from sentence_transformers import SentenceTransformer, util
import torch
# Hugging Face 임베딩 모델 로드
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
# 질문 임베딩 생성
answer_embeddings = model.encode(answers, convert_to_tensor=True)
# 사용자 질문 입력 및 임베딩 생성
query = "전도가 뭐야?"
query_embedding = model.encode(query, convert_to_tensor=True)
# 코사인 유사도 계산
cosine_scores = util.pytorch_cos_sim(query_embedding, answer_embeddings)
# 상위 3개의 인덱스 찾기
top_3_indices = torch.argsort(cosine_scores, descending=True)[0][:3].tolist()
# 결과 출력
print("사용자 질문:", query)
print("\n상위 3개 질문 및 답변:")
for idx in top_3_indices:
print(f"질문: {questions[idx]}")
print(f"답변: {answers[idx]}")
print()
----------
사용자 질문: 전도가 뭐야?
상위 3개 질문 및 답변:
질문: 열전달의 세 가지 방법을 설명해 주세요.
답변: 열전달의 세 가지 방법은 전도, 대류, 복사입니다. 전도는 열이 물질을 통해 직접 전달되는 과정, 대류는 유체의 이동을 통해 열이 전달되는 과정, 복사는 열이 전자기파의 형태로 전달되는 과정입니다.
질문: 전기 회로에서 전압의 역할을 설명해 주세요.
답변: 전기 회로에서 전압은 전류를 흐르게 하는 원동력입니다. 전압은 전하를 전도체를 통해 이동시키는 힘을 제공하며, 전기 회로에서 전류의 흐름을 결정합니다.
질문: 전기 회로에서 전류의 정의를 설명해 주세요.
답변: 전류는 전하가 전도체를 통해 흐르는 속도를 나타내는 물리량입니다. 전류의 단위는 암페어(A)이며, 전압에 의해 전하가 이동하면서 회로를 통해 흐릅니다.- Ensemble 모델 상위 3개 답변 확인
이 경우 BM25로 검색했을 때와 같은 결과가 나옵니다. BM25 모델 생성시 설정하는 하이퍼파라미터로는 k1과 b가 있는데 k1은 용어 빈도, b는 문서 길이에 따른 정도를 조절합니다. alpha는 BM25점수와 코사인 유사도 결합 비율이며, alpha 값이 커질수록 BM25 점수의 비율이 커집니다.
import json
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer, util
import numpy as np
import torch
from konlpy.tag import Okt
# JSON 파일 경로 지정
file_path = 'science_data.json'
# JSON 파일 읽기
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 질문과 답변 리스트 생성
questions = [item['instruction'] for item in data]
answers = [item['output'] for item in data]
# 형태소 분석기를 통한 한국어 토큰화
okt = Okt()
tokenized_answers = [okt.morphs(answer) for answer in answers]
# BM25 모델 생성
bm25 = BM25Okapi(tokenized_answers, k1=1.5, b=0.75)
# Hugging Face 임베딩 모델 로드
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
# 답변 임베딩 생성
answer_embeddings = model.encode(answers, convert_to_tensor=True)
# 사용자 질문 입력
query = "전도가 뭐야?"
# BM25 검색
tokenized_query = okt.morphs(query)
bm25_scores = bm25.get_scores(tokenized_query)
# 임베딩 검색
query_embedding = model.encode(query, convert_to_tensor=True)
cosine_scores = util.pytorch_cos_sim(query_embedding, answer_embeddings).squeeze().tolist()
# 점수 결합
alpha = 0.5 # BM25 점수와 코사인 유사도의 결합 비율
combined_scores = [(alpha * bm25_score + (1 - alpha) * cosine_score) for bm25_score, cosine_score in zip(bm25_scores, cosine_scores)]
# 상위 3개의 결과 인덱스 찾기
top_3_indices = np.argsort(combined_scores)[::-1][:3]
# 결과 출력
print("검색어:", query)
print("\n상위 3개 질문 및 답변:")
for idx in top_3_indices:
print(f"질문: {questions[idx]}")
print(f"답변: {answers[idx]}")
print(f"BM25 점수: {bm25_scores[idx]}")
print(f"임베딩 유사도: {cosine_scores[idx]}")
print(f"결합 점수: {combined_scores[idx]}")
print()
----------
검색어: 전도가 뭐야?
상위 3개 질문 및 답변:
질문: 열전달의 세 가지 방법을 설명해 주세요.
답변: 열전달의 세 가지 방법은 전도, 대류, 복사입니다. 전도는 열이 물질을 통해 직접 전달되는 과정, 대류는 유체의 이동을 통해 열이 전달되는 과정, 복사는 열이 전자기파의 형태로 전달되는 과정입니다.
BM25 점수: 5.245804106134422
임베딩 유사도: 0.38906535506248474
결합 점수: 2.8174347305984533
질문: 기체의 밀도와 온도 사이의 관계를 설명해 주세요.
답변: 기체의 밀도는 온도에 반비례합니다. 기체의 온도가 상승하면 기체 분자들이 더 빠르게 움직여 부피가 커지므로 밀도가 감소합니다. 반대로 온도가 낮아지면 밀도가 증가합니다.
BM25 점수: 1.6201333766383752
임베딩 유사도: 0.07426438480615616
결합 점수: 0.8471988807222657
질문: 화학에서 반응 속도에 영향을 미치는 요소를 설명해 주세요.
답변: 화학 반응 속도에 영향을 미치는 요소로는 온도, 반응물의 농도, 촉매, 압력(기체 반응의 경우) 등이 있습니다. 온도가 높아지면 반응 속도가 증가하며, 농도가 높을수록 반응 속도가 빨라집니다.
BM25 점수: 1.4968180981192423
임베딩 유사도: 0.1477956622838974
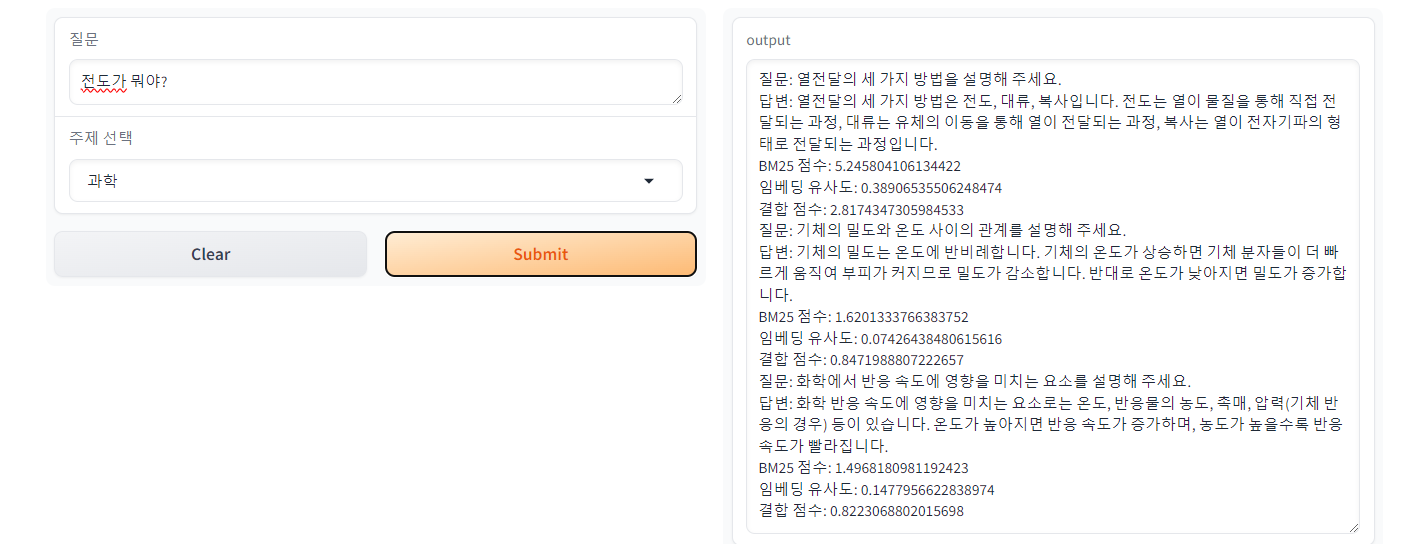
결합 점수: 0.8223068802015698- Ensemble 모델 Gradio로 챗봇 구현
답변은 이전보다 만족스러우나 답변 출력 속도가 느립니다.
import json
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer, util
import numpy as np
import gradio as gr
from konlpy.tag import Okt
from functools import lru_cache
# 데이터 파일 경로 설정
data_files = {
'국어': 'korean_data.json',
'수학': 'math_data.json',
'영어': 'english_data.json',
'사회/역사': 'social_data.json',
'과학': 'science_data.json'
}
# 형태소 분석기와 임베딩 모델 로드
okt = Okt()
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
@lru_cache(maxsize = None)
def load_data(topic):
# 선택된 주제에 맞는 데이터 파일 로드
file_path = data_files.get(topic)
if not file_path:
return [], [], [], []
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
questions = [item['instruction'] for item in data]
answers = [item['output'] for item in data]
# 형태소 분석을 통한 한국어 토큰화
tokenized_answers = [okt.morphs(answer) for answer in answers]
# BM25 모델 생성
bm25 = BM25Okapi(tokenized_answers, k1=1.5, b=0.75)
# 답변 임베딩 생성
answer_embeddings = model.encode(answers, convert_to_tensor=True)
return questions, answers, bm25, answer_embeddings
def get_answer(query, topic):
questions, answers, bm25, answer_embeddings = load_data(topic)
if not questions:
return "데이터를 로드할 수 없습니다. 주제를 선택하세요."
# BM25 검색
tokenized_query = okt.morphs(query)
bm25_scores = bm25.get_scores(tokenized_query)
# 임베딩 검색
query_embedding = model.encode(query, convert_to_tensor=True)
cosine_scores = util.pytorch_cos_sim(query_embedding, answer_embeddings).squeeze().tolist()
# 점수 결합
alpha = 0.5
combined_scores = [(alpha * bm25_score + (1 - alpha) * cosine_score)
for bm25_score, cosine_score in zip(bm25_scores, cosine_scores)]
# 상위 3개의 결과 인덱스 찾기
top_3_indices = np.argsort(combined_scores)[::-1][:3]
# 결과 구성
results = []
for idx in top_3_indices:
results.append({
"질문": questions[idx],
"답변": answers[idx],
"BM25 점수": bm25_scores[idx],
"임베딩 유사도": cosine_scores[idx],
"결합 점수": combined_scores[idx]
})
return results
# Gradio 인터페이스 설정
def gradio_interface(query, topic):
results = get_answer(query, topic)
if isinstance(results, str):
return results
return "\n".join([f"질문: {result['질문']}\n답변: {result['답변']}\nBM25 점수: {result['BM25 점수']}\n임베딩 유사도: {result['임베딩 유사도']}\n결합 점수: {result['결합 점수']}"
for result in results])
iface = gr.Interface(
fn=gradio_interface,
inputs=[
gr.Textbox(label="질문", placeholder="여기에 질문을 입력하세요."),
gr.Dropdown(choices=list(data_files.keys()), label="주제 선택")
],
outputs="text",
title="학습 챗봇",
description="과목을 선택하고 궁금한 걸 물어보세요!"
)
iface.launch()- 앙상블 모델 Gradio 챗봇 구현 (pkl 파일로 속도 향상)
피클 파일을 활용하면 속도가 굉장히 빨라집니다. 또한lru_cache를 사용하여 피클 파일에서 데이터를 읽는 작업을 최적화하여 속도를 높였습니다.
Python Snippets_pickle을 사용해서 데이타 저장하고 불러오기
이번 경우에는 데이터셋과 사용자 질문을 각각 다른 형태소 분석기를 적용했습니다. 사실 하나로 적용하는 게 좋다고 생각되나 여러 질문을 던져 보았을 때 데이터셋은 okt, 사용자 질문은 komoran으로 했을 때 세 가지 질문과 답변이 사용자의 질문과 연관성이 있게 나왔고 가장 만족스러운 답변을 얻을 수 있었습니다. 형태소 분석기 관련은 독스 내용을 참고해 주세요.
딥 러닝을 이용한 자연어 처리 입문_토큰화
import json
import pickle
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
from konlpy.tag import Okt
# 데이터 파일 경로 설정
data_files = {
'국어': 'korean_data.json',
'수학': 'math_data.json',
'영어': 'english_data.json',
'사회역사': 'social_data.json',
'과학': 'science_data.json'
}
# 형태소 분석기와 임베딩 모델 로드
okt = Okt()
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
def save_pickle_file(topic):
# 선택된 주제에 맞는 데이터 파일 로드
file_path = data_files.get(topic)
if not file_path:
print(f"{topic}의 데이터 파일을 찾을 수 없습니다.")
return
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
questions = [item['instruction'] for item in data]
answers = [item['output'] for item in data]
# 형태소 분석을 통한 한국어 토큰화
tokenized_answers = [okt.morphs(answer) for answer in answers]
# BM25 모델 생성
bm25 = BM25Okapi(tokenized_answers, k1=1.5, b=0.75)
# 답변 임베딩 생성
answer_embeddings = model.encode(answers, convert_to_tensor=True)
# 피클 파일로 저장
pickle_file_path = f"{topic}_data.pkl"
with open(pickle_file_path, 'wb') as f:
pickle.dump((questions, answers, bm25, answer_embeddings), f)
print(f"{topic}의 피클 파일이 저장되었습니다: {pickle_file_path}")
# 모든 주제에 대해 피클 파일 저장
for topic in data_files.keys():
save_pickle_file(topic)json 데이터셋 각 파일을 pkl 파일로 저장 완료했다.
이후 Gradio로 챗봇을 실행하였다.
import pickle
import gradio as gr
import numpy as np
from sentence_transformers import SentenceTransformer, util
from konlpy.tag import Okt, Komoran
from functools import lru_cache
# 형태소 분석기와 임베딩 모델 로드
# okt = Okt()
komoran = Komoran()
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
@lru_cache(maxsize=None)
def load_data(topic):
pickle_file_path = f"{topic}_data.pkl"
print(f"Trying to load: {pickle_file_path}")
try:
with open(pickle_file_path, 'rb') as f:
questions, answers, bm25, answer_embeddings = pickle.load(f)
return questions, answers, bm25, answer_embeddings
except FileNotFoundError:
return [], [], [], []
except Exception as e:
print(f"Error loading data: {e}")
return [], [], [], []
def get_answer(topic, query):
questions, answers, bm25, answer_embeddings = load_data(topic)
if not questions:
return "데이터를 로드할 수 없습니다. 주제를 선택하세요."
tokenized_answers = [komoran.morphs(answer) for answer in answers]
tokenized_query = komoran.morphs(query)
bm25_scores = bm25.get_scores(tokenized_query)
# 임베딩 검색
query_embedding = model.encode(query, convert_to_tensor=True)
cosine_scores = util.pytorch_cos_sim(query_embedding, answer_embeddings).squeeze().tolist()
# 점수 결합
alpha = 0.5
combined_scores = [(alpha * bm25_score + (1 - alpha) * cosine_score)
for bm25_score, cosine_score in zip(bm25_scores, cosine_scores)]
# 상위 3개의 결과 인덱스 찾기
top_3_indices = np.argsort(combined_scores)[::-1][:3]
# 결과 구성
results = []
for idx in top_3_indices:
results.append({
"질문": questions[idx],
"답변": answers[idx],
"BM25 점수": bm25_scores[idx],
"임베딩 유사도": cosine_scores[idx],
"결합 점수": combined_scores[idx]
})
return results
# Gradio 인터페이스 설정
def gradio_interface(topic, query):
results = get_answer(topic, query)
if isinstance(results, str):
return results
return "\n".join([f"질문: {result['질문']}\n답변: {result['답변']}\nBM25 점수: {result['BM25 점수']}\n임베딩 유사도: {result['임베딩 유사도']}\n결합 점수: {result['결합 점수']}"
for result in results])
iface = gr.Interface(
fn=gradio_interface,
inputs=[
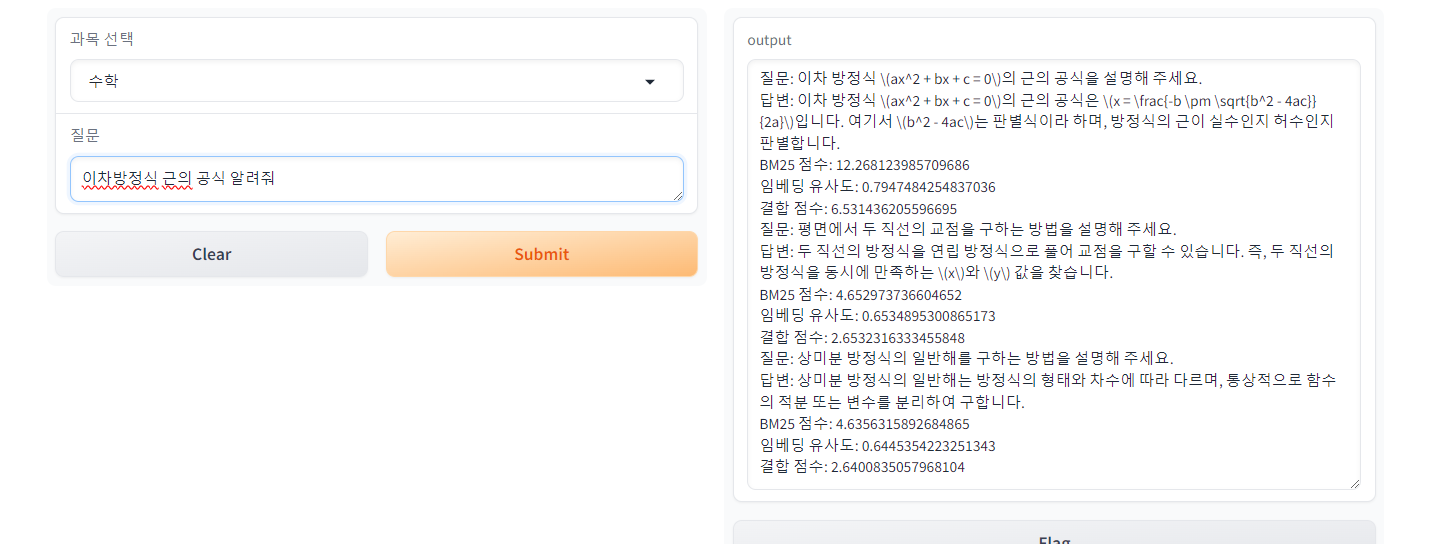
gr.Dropdown(choices=list(data_files.keys()), label="과목 선택"),
gr.Textbox(label="질문", placeholder="여기에 질문을 입력하세요.")
],
outputs="text",
title="학습 챗봇",
description="과목을 선택하고 궁금한 걸 물어보세요!"
)
iface.launch(debug = True)데이터셋의 한계가 있지만 꽤 만족스러운 답변을 얻을 수 있습니다.
사실 최근에는 LLM의 장점이 굉장히 커서 LLM으로 챗봇을 만들고자 하는 시도가 대부분이지만 교육 업계에서는 아이들이 사용하는 도구이다 보니 LLM을 도입하기 조심스러운 경향이 있는 듯 합니다. 이러한 관점에서 LLM뿐 아니라 유사도 기반의 챗봇의 성능을 높일 수 있는 다양한 시도도 해보고자 하는 요즘입니다. 이번 포스팅에서는 키워드 기반의 랭킹 알고리즘인 BM25와 임베딩 모델을 결합한 앙상블 모델에 형태소 분석기를 바꿔가며 유사도 측정의 정확도를 높이기 위한 실험을 해보았습니다. 앞으로도 사용자 경험을 향상하기 위한 다양한 시도를 더욱 깊이 있게 해나가 보고자 합니다.
