✅ 이전 포스팅
지난 번 문서 유사도 검사 원리와 여러 기법들에 대해 포스팅했습니다.
문서 유사도 검사ㅣBoW, TF-IDF, Word2Vec, FastText, GloVe, 코사인 유사도
✅ 임베딩의 개념과 유사도 기반 챗봇 구현
이번 포스팅은 지난 포스팅과 이어집니다. 이번에는 간단히 임베딩의 개념에 대해 다시 한 번 정리하고 Huggingface의 세 가지 한국어 문장 유사도 모델을 테스트 해본 뒤 하나를 골라 유사도 기반 챗봇 구현을 해보겠습니다. 상세 코드는 아래 링크를 참고해 주세요. 데이터셋은 Github를 통해 다운로드 해주세요.
임베딩의 개념과 유사도 기반 챗봇 구현 colab
simmilarity_education_chatbot
데이터셋은 제 친구 GPT에게 부탁했고 추후 추가 활용할 가능성도 있다고 판단하여 instruction tuning에 사용할 수 있는 instruction, input, output 키로 json 파일을 만들었습니다. Instruction Tuning 관련하여 궁금하신 분은 아래 포스팅을 참고해 주세요.
Instruction Tuningㅣ프롬프트 엔지니어링, 파인튜닝과의 차이, 데이터셋, 예제 코드
upskyy/bge-m3-korean, sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2, jhgan/ko-sroberta-multitask 세 모델을 코사인 유사도로 테스트 해보았고 몇 가지 질문을 던져 보았을 때 가장 답변을 잘 뱉어낸다고 판단된upskyy/bge-m3-korean 모델로 Gradio를 활용해 간단한 챗봇을 만들어 보았습니다. 챗봇은 사용자의 질문과 데이터셋의 질문 간 유사도를 측정합니다.
✅ 챗봇 테스트 결과
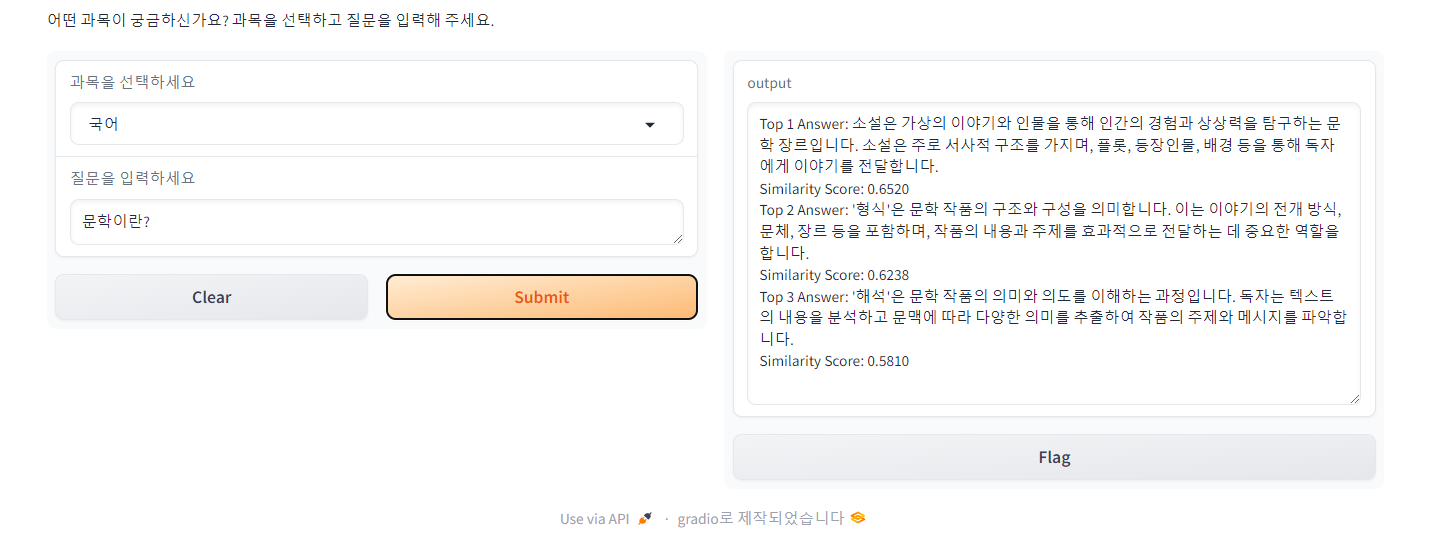
📌 Case 1
국어 데이터셋에 '문학'이라는 단어가 많이 등장해서 문학의 개념을 물었을 때 잘 알려줄지 궁금했는데 가장 높은 유사도로 뱉어냈습니다.
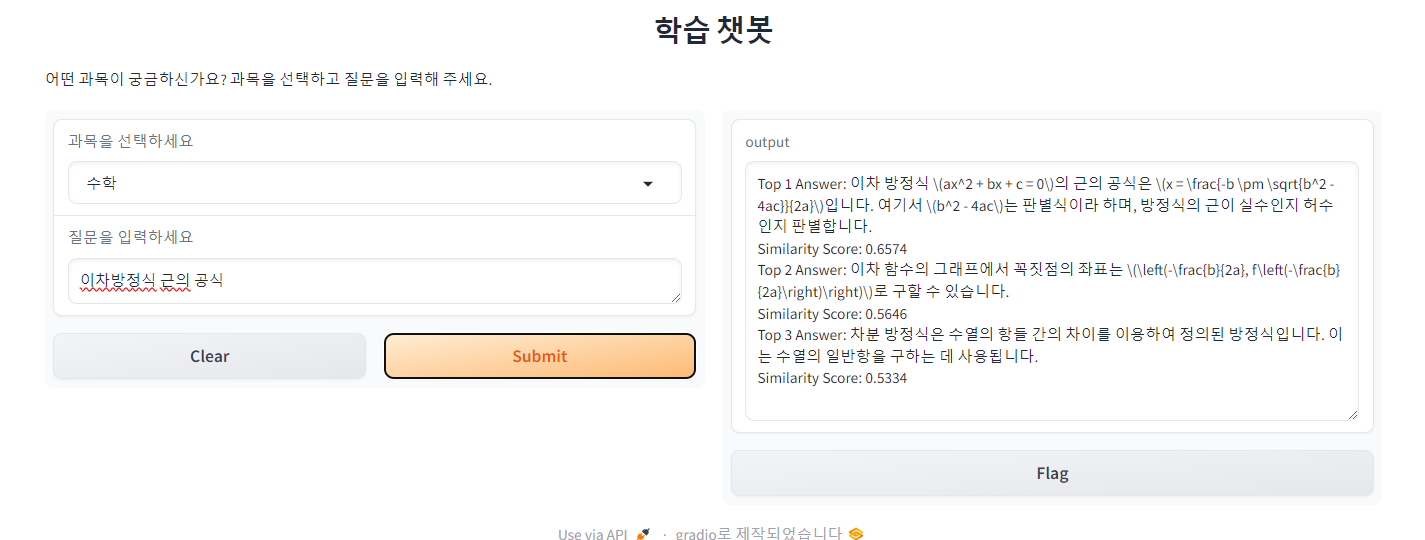
📌 Case 2
Latex를 제대로 처리하지 못해 보기에는 안 좋지만 잘 찾아내 답변해 주었습니다. 이번에는 Top2 Answer와도 0.1 가까의 유사도에서 차이를 보였습니다.
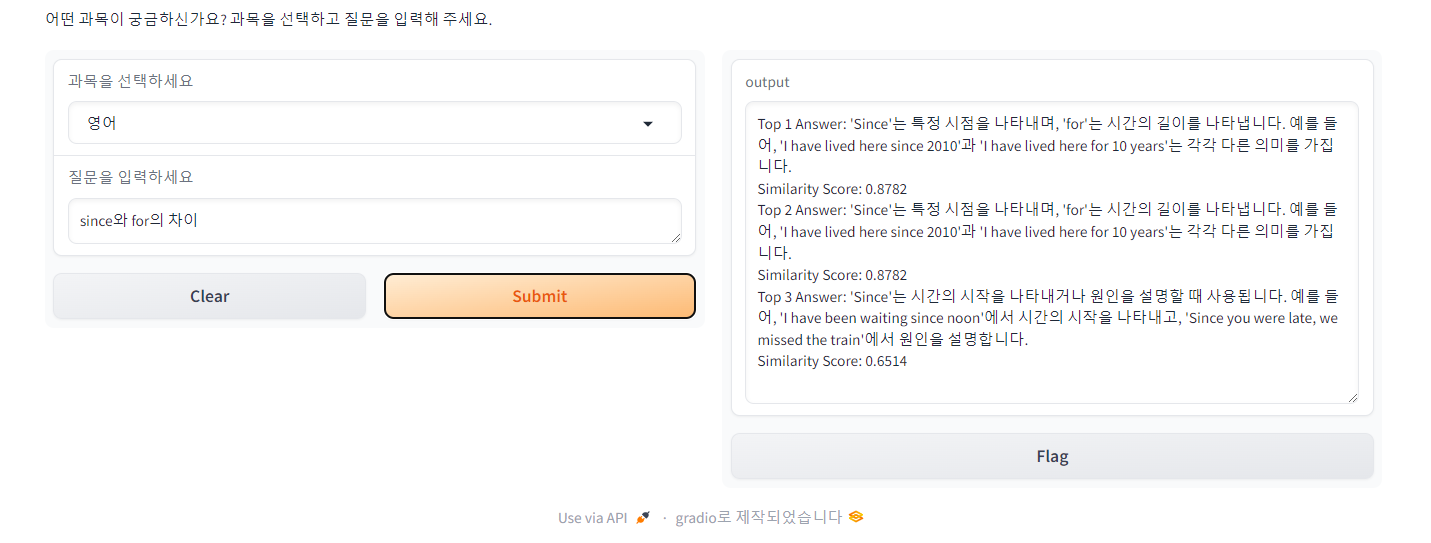
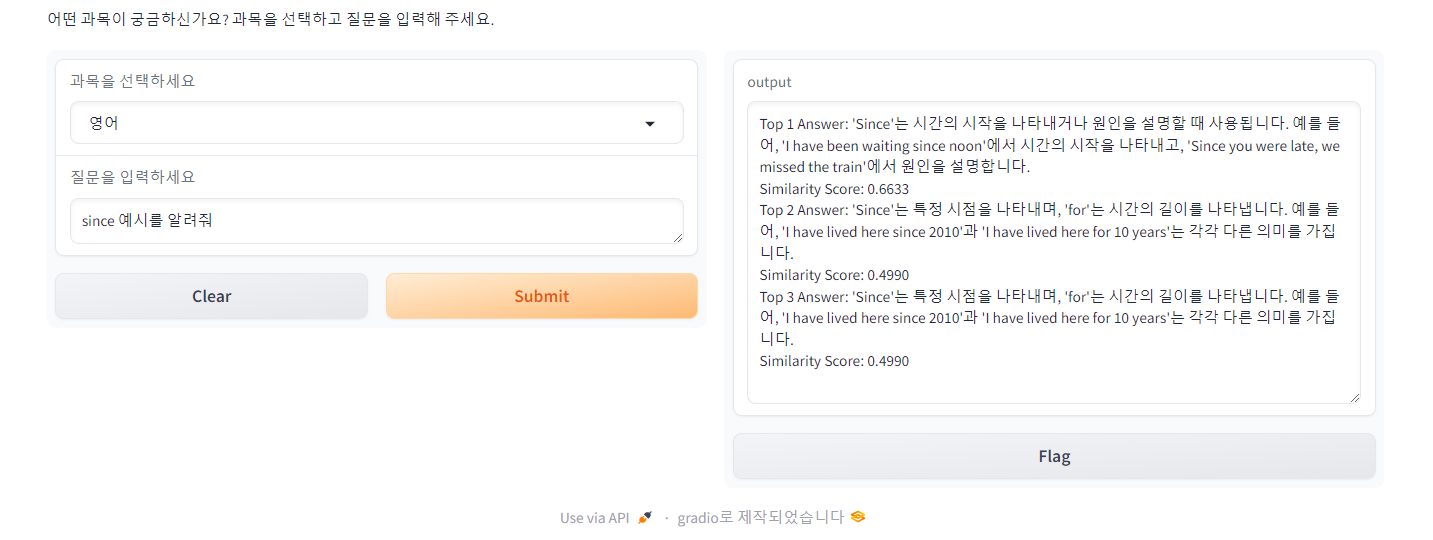
📌 Case 3
since와 for의 차이를 물었을 때는 차이를 설명하는 답변을 1순위로, since의 예시를 묻는 질문에는 since의 용법과 예시를 담고 있는 답변을 1순위로 뱉어냈습니다. Top1과 Top2 결과가 같은 걸 보니 중복 응답이 있었나 보네요.
📌 Case 4
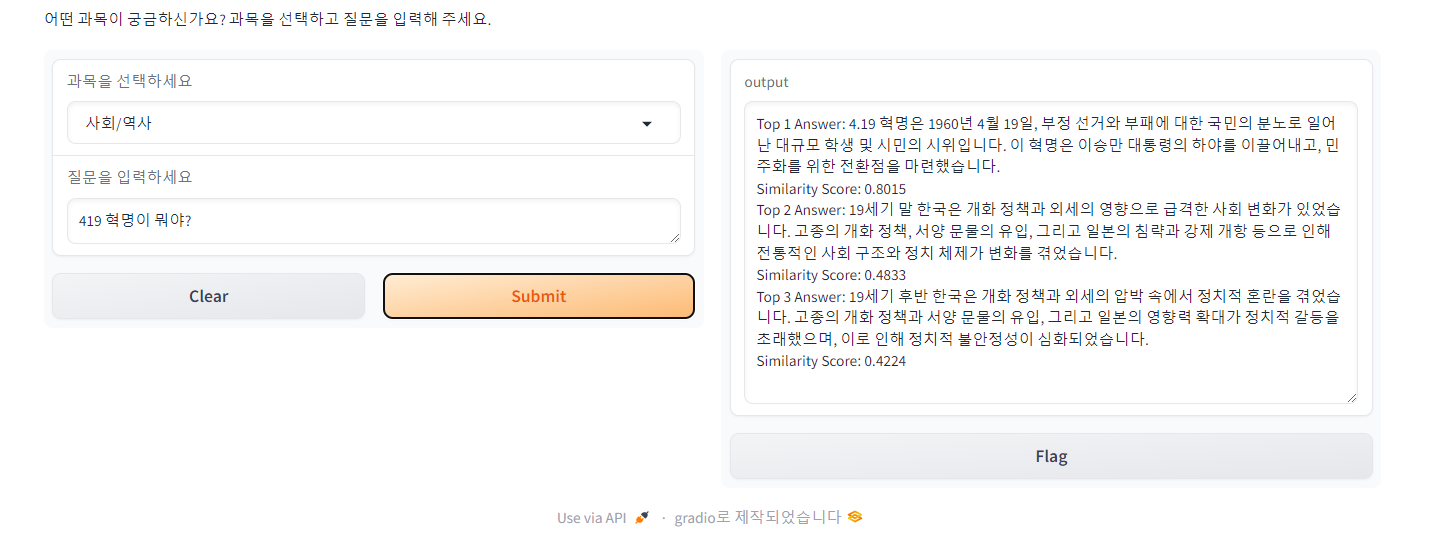
4.19 혁명을 물었고 Top2와 Top3는 4.19 혁명 관련 답변은 아니지만 19에 꽂혀서 답변해 주는 모습입니다. 다만 유사도는 0.5 이하로 낮게 측정했습니다.
📌 Case 5
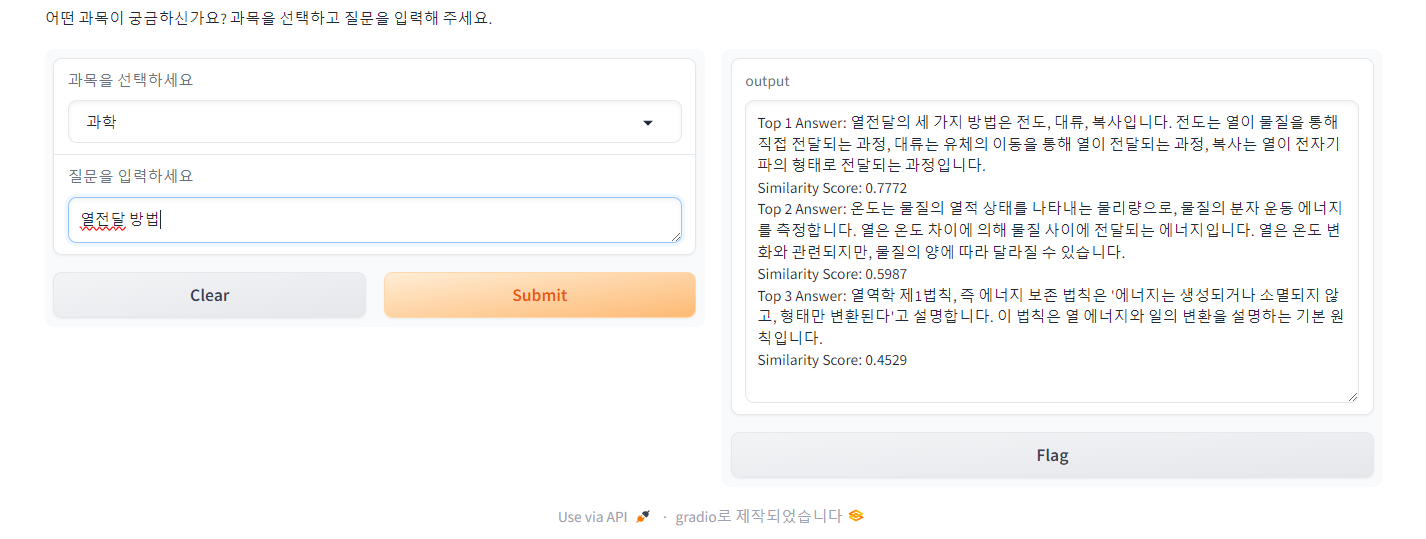
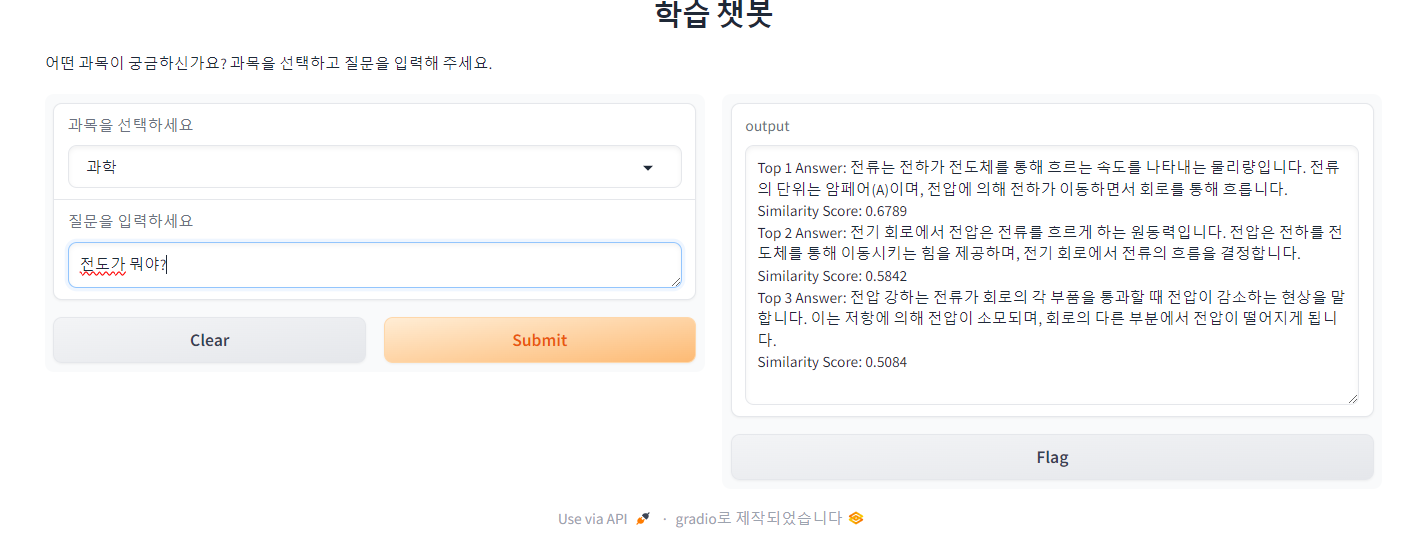
이번에는 제대로 답변하지 못한 경우입니다. 먼저 열전달 방법에 물어보았을 때는 전도, 대류, 복사가 있다는 답변을 주었습니다. 그러나 전도가 뭔지 물어보았을 때는 열전달에서의 전도보다는 전도체의 전도를 더 잘 잡아냅니다. 심지어 전도라는 단어가 포함되어 있지 않은 답변을 Top2와 Top3로 꼽았습니다.
✅ 정리
이번에는 아주 간단한 유사도 기반 챗봇을 만들어 보았습니다. 유사도 기반 챗봇은 사전에 정의된 문장이나 패턴에 의존하여 답변을 제공하기 때문에 데이터셋의 양이 중요하고 사용자가 예상치 못한 방식으로 질문을 하거나 새로운 주제를 제시할 경우 적절한 응답을 생성하기 어렵습니다. 또한 복잡한 대화나 깊이 있는 질문에 대해 적절한 응답을 제공하는 데 한계가 있고 응답의 유사성만을 비교하여 문맥을 충분히 이해하지 못할 수 있습니다.
그러나 오픈소스라 하더라도 대형 언어 모델을 사용하면 파인튜닝하는 데 시간과 비용이 많이 들고, 환각 현상을 막는 데 노력이 필요하기 때문에 간단한 챗봇은 유사도 기반 챗봇을 사용하는 게 낫다는 생각이 듭니다. 유사도 기반 챗봇의 성능을 높이는 다양한 방법과 예제도 추후 포스팅 해보려 합니다.
