
조코딩님 60만 구독자 기념으로 진행된 해커톤에 발 살짝 담궈보았습니다.
사실 피자 받으려고 한 거지만 Gemini API를 활용해 보았다는 점에 의의가 있었다.
주제는 "Gemini API를 활용한 AI 웹/앱 서비스 만들기"
https://youtu.be/rzd1CccBIGE?si=Femf76Za-6hZ8wb7
📌 준비
✅ API 발급
https://aistudio.google.com/app/prompts/new_chat?pli=1
구글 AI 스튜디오에 접속하여 좌측 상단 Get API key 선택
API 키 만들기 선택 후 Generative Language Client로 프로젝트 선택하여 API 발급
✅ 주요 모델 및 무료 사용량
주요 모델 및 무료 사용량은 다음과 같습니다.
| 모델 | 입력 | 출력 | 기능 | 컨텍스트 윈도우 | 무료 사용량 |
|---|---|---|---|---|---|
| Gemini 1.5 Pro | 오디오, 이미지, 텍스트 | 텍스트 | 멀티모달 LLM | 1M | 분당 2회 요청/분당 32K 토큰 1일 50회 요청 |
| Gemini 1.5 Flash | 오디오, 이미지, 텍스트 | 텍스트 | 멀티모달 LLM | 1M | 분당 15회 요청/분당 1M 토큰 1일 1,500회 요청 |
| Gemini 1.0 Pro | 텍스트 | 텍스트 | LLM | 32K | 분당 15회 요청/분당 32K 토큰 1일 1,500회 요청 |
✅ 환경변수 등록 및 불러오기
발급받은 키는 환경변수로 등록합니다.
저의 경우 윈도우를 사용하기에 .env 파일에 다음과 같이 저장한 후
MY_KEY = "발급받은 API KEY"메인 코드에서 불러와 주었습니다.
load_dotenv()
my_key = os.getenv('MY_KEY')
genai.configure(api_key=my_key)✅ 파이썬 및 구글 제미나이 SDK 설치
- 제미나이 SDK 사용을 위해 파이썬 3.9 이상 설치
- 구글 제미나이 SDK 설치
pip install google-generativeai📌 Gemini 살펴보기
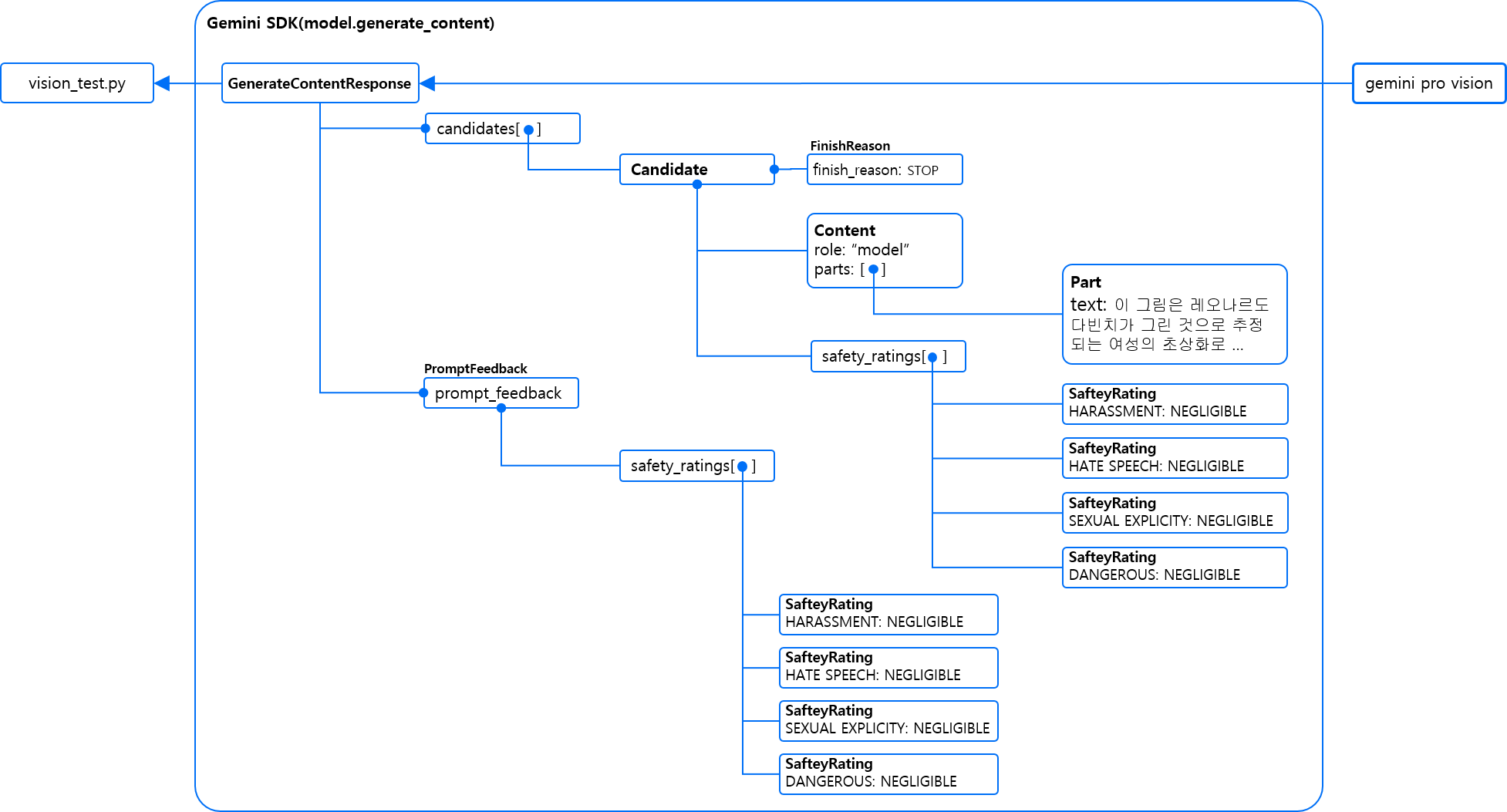
Gemini API 응답 구조 다이어그램은 다음과 같습니다.
✅ 매개변수 설정
| 매개변수명 | 의미 | 초기 값 | 범위 |
|---|---|---|---|
| candidate_count | 생성할 응답 후보 건수. 현재는 1만 가능 | 1 | 1 |
| stop_sequences | 언어 생성을 중지시킬 문자 시퀀스 | 없음 | 0 ~ 5 |
| max_output_tokens | 출력할 최대 토큰 수 | 2048 | 1 ~ 2048 |
| temperature | 출력의 무작위성을 제어 *온도 높을수록 텍스트 예측 가능성 ↓ 독창성 ↑ 온도 낮을수록 안정적, 일관된 텍스트 생성 | 0.9 | 0.0 ~ 1.0 |
| top_p | 확률 내림차순으로 정렬 후 누적 확률 기준으로 선택할 단어(토큰)의 범위를 설정 | 1.0 | 0.0 ~ 1.0 |
| top_k | 확률 내림차순으로 정렬 후 건수 기준으로 선택할 단어(토큰)의 범위를 설정 *자연스러운 텍스트 생성을 위해 초기 값 조정 권장되지 않음 | 1 | 0보다 큰 정수 |
매개변수 초기 값 확인 명령은 다음과 같습니다.
import google.generativeai as genai
print(genai.get_model("models/gemini-pro"))max_output_tokens를 지정할 때 도움이 되는 토큰 수 확인 코드입니다.
tokens = model.count_tokens("원하는 문장을 넣어주세요.")
print(tokens)✅ 안전성 점검 체계
개인적으로 Gemini API를 만져보면서 재밌다고 생각했던 부분입니다. Gemini API를 활용하면 4가지 카테고리로 안전성 위반 여부를 점검할 수 있습니다.
| 카테고리 | 내용 |
|---|---|
| HARASSMENT (괴롭힘) | 성별, 성적지향, 종교, 인종 등 보호받는 개인의 특성에 대해 부정적이거나 해로운 언급을 하는 행위 |
| HATE SPEECH (증오심 표현) | 무례하거나 존중하지 않는 태도 또는 저속한 발언 |
| SEXUAL EXPLICITY (음란물) | 성행위 또는 성적으로 노골적인 내용 |
| DANGEROUS (위해성) | 해로운 행위를 야기하는 내용 |
각 카테고리에 대해 4가지 위반 확률을 둡니다.
| 확률 | 내용 |
|---|---|
| NEGLIGIBLE | 내용이 안전하지 않을 가능성이 거의 없음 |
| LOW | 내용이 안전하지 않을 가능성이 낮음 |
| MEDIUM | 내용이 안전하지 않을 가능성이 중간 |
| HIGH | 내용이 안전하지 않을 가능성인 높음 |
각 위반 확률에 대해 4단계로 기준점을 설정할 수 있습니다. 초기 값은 "BLOCK_MEDIUM_AND_ABOVE"입니다.
| 기준점 | 의미 | 내용 |
|---|---|---|
| BLOCK_NONE | 차단 안함 | 차단하지 않음 |
| BLOCK_ONLY_HIGH | 소수의 경우만 차단 | 안전하지 않은 확률이 “높음”일 경우만 차단 |
| BLOCK_MEDIUM_AND_ABOVE | 일부 차단 | 안전하지 않을 확률이 “중간” 이상일 경우 차단 |
| BLOCK_LOW_AND_ABOVE | 대부분 차단 | 안전하지 않을 확률이 “낮음” 이상일 경우 차단 |
사용자 프롬프트가 안전성 기준을 위반할 경우 candidates 필드 자체가 만들어지지 않고, 모델의 응답 메시지가 안전성 기준을 위반할 경우 candidates 필드는 생성되지만 모델의 메시지를 담고 있는 content 필드가 생성되지 않습니다.
안전성을 위배했을 때 아래와 같이 기준점(threshold)를 조정하면 정상적으로 응답 메시지를 받을 수 있습니다. 그러나 모델의 응답 메시지를 받기 위해 적절한 사유 없이 BLOCK_NONE으로 설정하면 서비스 이용 약관에 위배되어 사용이 제한될 수 있으니 안전성을 적절히 조정하여 운영하는 것이 바람직합니다. 한편, 아동의 안전 위협 등의 핵심 유해 요소에 대해서는 항상 차단되어 있으며 기준점 조정을 통해 우회할 수 없습니다.
import google.generativeai as genai
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
]
model = genai.GenerativeModel('gemini-pro', safety_settings)
response = model.generate_content("나는 네가 싫어!")
if response.prompt_feedback.block_reason:
print(f"사용자 입력에 다음의 문제가 발생하여 응답이 중단되었습니다: {response.prompt_feedback.block_reason.name}")
else:
print(response.text)📌 결과물
아주 아주 간단한 결과물이지만 만지작대다 보니 3시간은 걸린 것 같습니다. 이름은 "핏멘토"로 사용자가 기초 정보를 입력하면 맞춤 운동 계획을 제공해 주고, 개인 멘토와 채팅을 통해 궁금한 점을 해결할 수 있도록 프롬프트를 지정하였습니다. 웹프레임워크는 Streamlit을 활용하였고 Streamlit Cloud를 활용하여 배포하였습니다. 아래 링크를 통해 체험해 보실 수 있습니다.
https://fit-mento.streamlit.app/
관련 간단 코드 리뷰입니다.
# 역할 특성상 안정된 답변 제공을 위해 temperature 초기 값보다 낮게 설정
generation_config = genai.GenerationConfig(temperature=0.5)
# 안전성 점검 체계 설정
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_LOW_AND_ABOVE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_LOW_AND_ABOVE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_LOW_AND_ABOVE",
},
{
"category": "HARM_CATEGORY_DANGEROUS",
"threshold": "BLOCK_LOW_AND_ABOVE",
},
]
# Streamlit 캐싱 매커니즘을 적용하여 파라미터나 구현 내용이 달라진 경우에만 함수 재실행하도록 설정함으로써 대기 시간 줄임
@st.cache_resource
def load_model():
model = genai.GenerativeModel('gemini-1.5-flash-latest', generation_config=generation_config, safety_settings=safety_settings)
print("Model loaded...")
return model
# 사용자 편의를 위해 응답 생성 spinner 추가 및 스트리밍 응답 방식 적용
with st.chat_message("ai"):
with st.spinner("🏃♀️ AI 멘토가 답변 중입니다 🏃♂️"):
response_placeholder = st.empty()
response = st.session_state.chat_session.send_message(full_prompt)
response_text = response.text
for i in range(len(response_text) + 1):
response_placeholder.markdown(response_text[:i])
time.sleep(0.02)
st.markdown(response.text)Gemini API 활용 경험은 처음인데 재밌었습니다. 무료로 사용 가능하니 더욱 좋네요!

안녕하세요 신영님! 글 너무 잘 보았습니다. 저도 스트림릿으로 제미나이 프롬프트를 구현해보고 싶은데 혹시 전체 코드 레포지토리 링크를 받아볼 수 있을까요?