LLM에 도메인을 적용하는 방법으로는 Full Fine-Tuning, PEFT, Prompt Engineering, RAG가 주로 사용되는데요. 이 네 가지 방법을 각각 살펴보고 어떤 방법을 적용하는 게 좋을지 알아보겠습니다.
✅ Full Fine-Tuning
Full Fine Tuning은 도메인 특정 데이터를 사용하여 pre-trained model의 모든 파라미터를 조정합니다. Full Fine Tuning은 다음과 같은 순서로 진행됩니다.
- 데이터셋 생성
- 데이터 전처리
- 모델 구성
- 모델 훈련
- 성능 평가
- 추가 훈련
👍 장점
- Pre-trained model을 fine-tuning 하는 것은 처음부터 모델 layer를 쌓는 것보다 적은 학습 데이터를 필요로 합니다.
- 특정 도메인이나 사례에 직면했을 때 더 높은 정확도와 연관성을 가진 출력을 생성할 가능성을 높입니다.
👎 단점
- LLM의 모든 파라미터를 업데이트하므로 수십 억 또는 수천 억 개의 파라미터 수를 갖는 LLM은 훈련에 높은 계산 비용과 큰 메모리 용량을 갖춘 하드웨어를 필요로 합니다.
- 새로운 정보를 학습할 때 과거 학습을 유지하지 못하고 새로운 데이터에만 최적화되어 기존에 학습한 일부 지식에 대해 망각하게 되는 현상(Castographic Forgetting)이 발생할 수 있습니다.
✅ PEFT(Parameter Efficient Fine Tuning)
PEFT는 pre-trained model의 전체 파라미터 중 일부 파라미터만 파인튜닝하여 효율성을 높이는 방식으로 파라미터를 조정합니다. 이미 많은 정보를 보유한 LLM의 모든 파라미터를 fine tuning 하는 것은 오히려 불필요하고 비효율적일 수 있기 때문에 PEFT로 효율적인 fine tuning을 할 수 있습니다. 자세한 내용은 아래 포스팅을 참고해 주세요.
PEFT | 도메인 특화 LLM을 위한 효율적인 방법론
👍 장점
- Full Fine-Tuning에 비해 효율적이고 빠른 훈련이 가능합니다.
- Castographic Forgetting 위험도가 감소합니다.
✅ Prompt Engineering
모델 입력을 세분화하여 출력을 안내합니다. 다음은 각각 예시 없는 zero-shot prompting, 하나의 예시로 하는 one-shot prompting, 여러 예시로 하는 few-shot prompting의 예입니다.
| Zero-Shot | One-Shot | Few-shot | |
|---|---|---|---|
| Prompt | What is the capital of France? | What is the capital of France? | What is the capital of France? |
| Example | Q: What is the capital of Germany? A: Berlin | Q: What is the capital of Germany? A: Berlin Q: What is the capital of Italy? A: Rome Q: What is the capital of Spain? A: Madrid | |
| Response | Paris | Paris | Paris |
Prompt Engineering 중 산술 문제나 상식 추론 능력 개선을 위한 Chain-of-Thought Prompting이라는 방법도 있습니다. '문제-정답'이 아니라 '문제-풀이-답' 구성으로 프롬프트를 구성합니다.
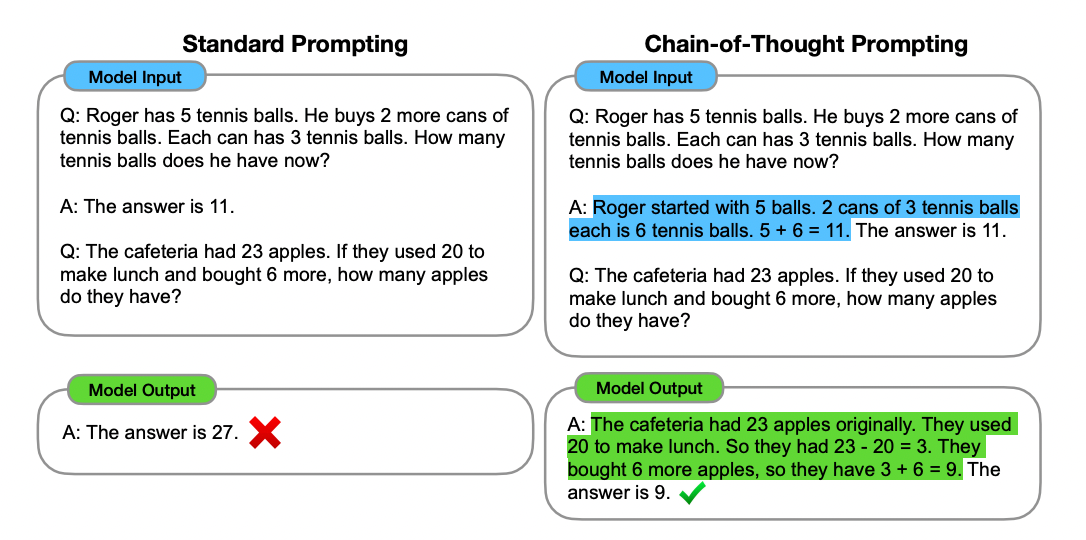
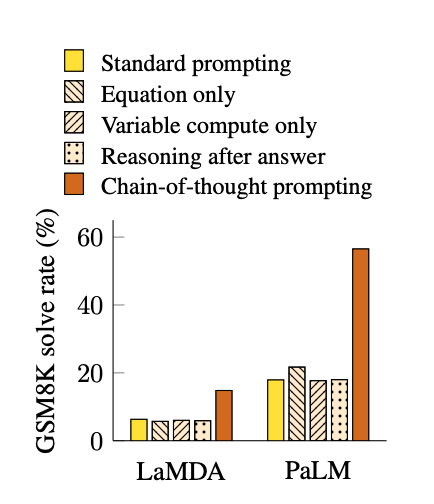
논문에 소개된 다양한 예제와 성능 개선은 다음과 같습니다.

✅ RAG(Retrieval Augmented Generation)
풍부한 답변을 위해 프롬프트 엔지니어링과 데이터베이스 쿼리를 병합합니다. RAG는 LLM이 방대한 문서에 기반하여 응답을 제공해야 할 때 특히 유용합니다. 예를 들어, 기업 내부 문서를 기반으로 답변을 제공해야 하는 경우가 있습니다. 또한, LLM 훈련 데이터셋에는 포함되지 않은 최신 정보와 문서를 사용해야 할 때 유용합니다. RAG 방법은 다음과 같습니다.
- Vector Database : 데이터셋을 벡터화 시켜 벡터 DB에 저장합니다.
- 질의 입력 : 프롬프트에서 사용자 쿼리를 가져옵니다.
- 문서 검색 : 사용자의 쿼리를 바탕으로 벡터 DB를 스캔하여 쿼리와 의미론적 유사성을 갖는 정보 청크를 식별합니다. 이를 사용하여 LLM에 추가 컨텍스트를 제공함으로써 보다 정확하고 컨텍스트에 맞는 응답을 생성합니다.
- 정보 추출 : 검색된 문서는 응답을 생성하기 위한 추가 컨텍스트를 제공하는 프롬프트로 원래 쿼리와 연결됩니다.
- 답변 생성 : 연결된 쿼리와 검색된 문서를 포함하는 프롬프트는 LLM에 입력되어 최종 출력을 생성합니다.
👍 장점
- LLM에 나타날 수 있는 Hallucinations(환각, 모델이 거짓말 또는 오답 등 잘못된 답변을 하는 경우) 가능성을 낮춘 더 정확한 결과를 생성합니다.
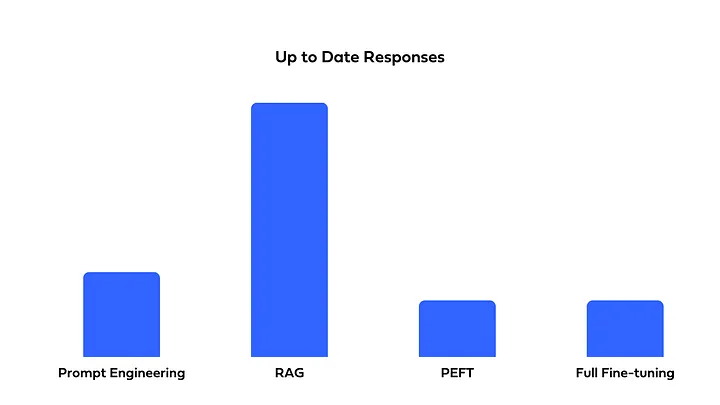
- 최신 정보가 필요한 응답을 생성하는 데 유용합니다.
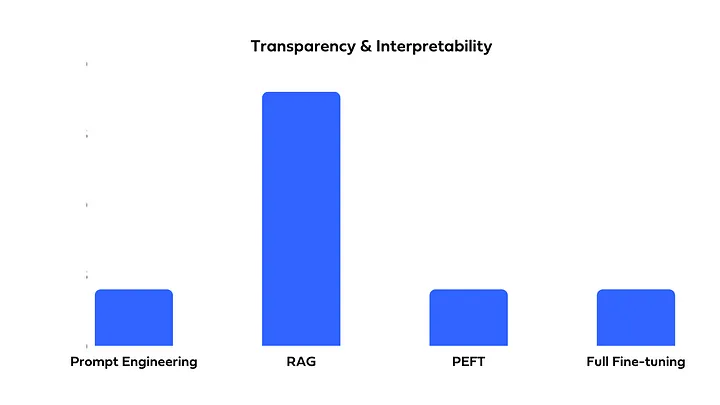
- LLM 답변의 출처를 정확히 파악할 수 있습니다.
- Fine-tuning보다 비용 효율적입니다.
👎 단점
- 데이터 요약, 통찰력 도출 등에서는 추가 문서만으로는 한계가 있기에 fine-tuning이 더 적합할 수 있습니다.
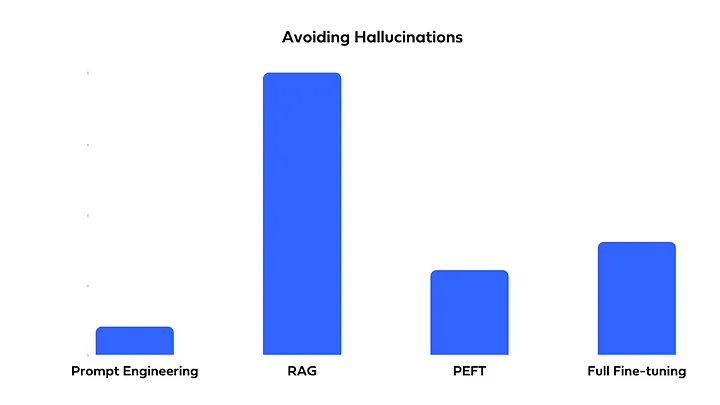
❓ 어떤 방법을 선택해야 할까
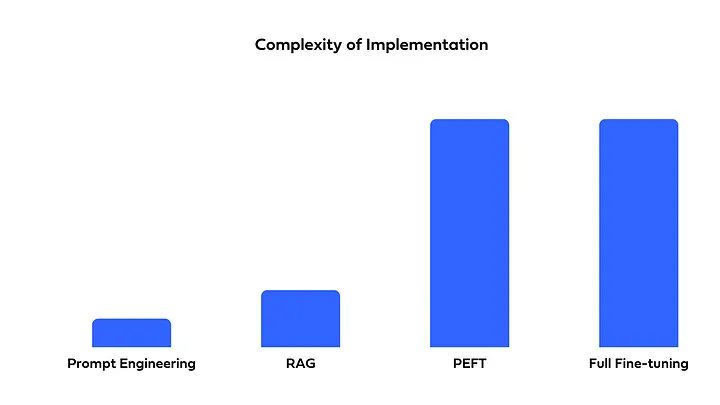
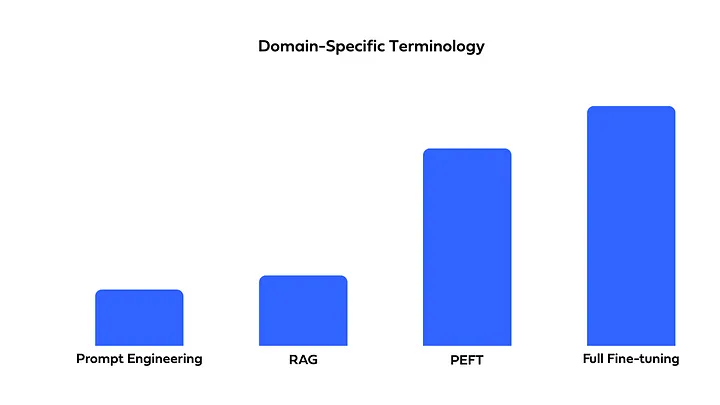
비용, 구현의 복잡성, 정확도를 고려하여 필요에 맞게 선택 및 혼합하여 사용할 수 있어야 합니다. Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?에서는 위에서 소개한 네 가지 방법을 다음과 같이 비교하였습니다.
- 비용
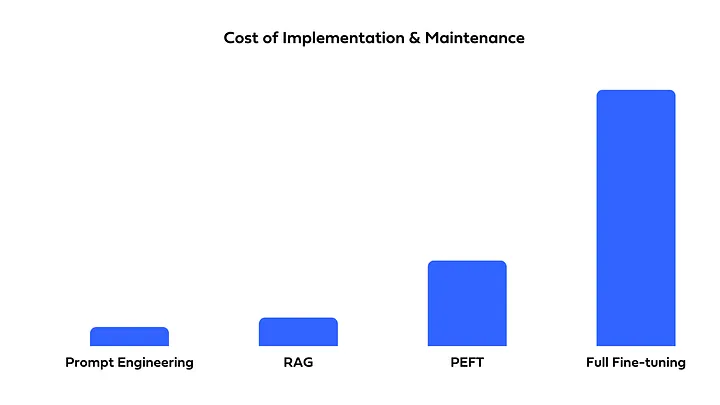
- 구현의 복잡성
- 정확도
 |  |
 |  |
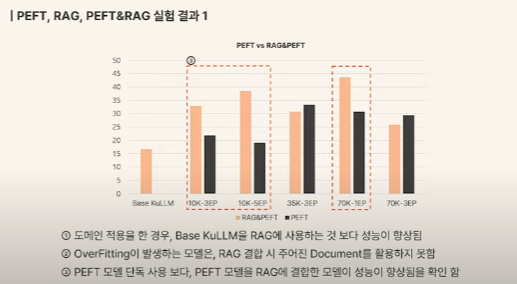
관련하여 두 가지 방법을 함께 사용하는 방법을 고려한 사례를 소개해 드립니다. 지난 해 12월 SK TECH SUMMIT 2023에서 발표된 내용입니다. 보안, 비용, domain adaptation 이슈로 오픈소스 sLLM을 활용한 사내 데이터 적용 PoC 관련이었는데요. PEFT와 RAG PoC를 각각 진행한 결과, PEFT 단독 사용 시 데이터 수가 많아질수록 정답 비율이 증가하는 경향을 확인했지만 지속적인 fine-tuning이 필요하고 망각 대응이 어려우며 원본 위치나 첨부파일 제공이 어렵다는 한계로 RAG 결합이 필요하다는 결과가 도출되었다고 합니다. 관련 상세 내용은 아래 영상을 확인해 주세요.
[SK TECH SUMMIT 2023] LLM 적용 방법인 RAG VS PEFT, Domain 적용 승자는?
LLM은 배울수록 더 많은 고민을 하게 되는 분야인 것 같습니다. 그래서 더 재미있고 좋은 답변을 내기 위한 여러 시도들을 해보고 싶네요. 오늘 포스팅은 여기서 마칩니다🙌
