
Hugging Face Community에서는 다양한 Learning Course를 제공하는데, 한국어로 제공되는 코스 중 자연어 처리 코스를 요약해 보았다. Huggingface에서는 예제 코드도 제공한다.
✅ 트랜스포머 기능
📌 트랜스포머 기본 기능
트랜스포머 라이브러리는 자연어 처리와 관련하여 공유한 모델을 사용하고 구축하는 기능들을 제공한다. 트랜스포머 라이브러리의 기본 객체는 pipeline() 함수다. 이 함수는 전처리와 후처리 과정을 모델과 연결하여 텍스트 입력을 하면 결과를 도출한다. Classifier 객체를 생성하면 모델이 다운로드 되고 캐싱이 이루어져서 코드를 재실행 할 때는 모델을 다시 다운로드 하지 않는다.
from transforemers import pipeline
classifier("I've been waiting for a HuggingFace course my whole life.")현재 huggingface에서 사용 가능한 파이프라인은 다음과 같다.
feature-extraction : 특징 추출 (텍스트에 대한 벡터 표현 추출)
fill-mask : 마스크 채우기
ner : 개체명 인식 (named entity recognition)
question-answering : 질의 응답
sentiment-analysis : 감정 분석
summarization : 요약
text-generation : 텍스트 생성
translation : 번역
zero-shot-classification : 제로샷 분류 (레이블 분류)
📌 트랜스포머 사용법
각 파이프라인은 아래와 같이 적용할 수 있다. 다음 예제는 기본 모델을 사용하는 경우를 다룬다.
from transformers import pipeline
generator = pipeline("text-genenration")
generator("In this course, we will learn how to",
num_return_sequences = 2,
max_length = 15)
# num_return_sequences : 서로 다른 출력 결과 개수 설정
# max_length : 출력 텍스트의 총 길이 설정다음은 Huggingface Hub에서 원하는 모델을 선택하여 파이프라인을 구성하는 예제이다.
from transformers import pipeline
generator = pipeline("text-generation", model = "distilgpt2")Hub에서 원하는 모델은 Models 메뉴에서 선택할 수 있다. 모델을 선택한 뒤에는 모델명을 복사-붙여넣기 하여 model 자리에 넣어주면 된다.
✅ 트랜스포머 동작 방식
📌 트랜스포머 모델의 역사
트랜스포머 모델의 역사를 간단히 정리하면 다음과 같다.
이후 2022년 ChatGPT, 2024년 GPT4 등 새로운 모델들이 많이 나왔다. 넓은 관점에서 트랜스포머 모델은 세 가지로 범주화 할 수 있다.
- GPT 계열
- BERT 계열
- BART/T5 계열
이들은 언어모델로서 스스로 지도하는 자가 지도 학습(self-supervised learning)으로 학습 되었다. 그 결과, 학습한 언어에 대해 통계 기반의 방식으로 이해하지만 실생활 문제에 적합하지 않은 경우도 발생한다. 따라서 사전 학습된 모델은 전이 학습(transfer learning)을 거친다. 사람이 레이블을 추가한 데이터를 사용하여 미세 조정(fine-tuning)하는 것이다.
📌 전이 학습
사전 학습을 위해서는 모델 가중치를 랜덤하게 초기화하고 사전 지식 없이 밑바닥부터 학습시켜야 한다. 이 경우 방대한 양의 코퍼스 데이터와 긴 학습 시간이 필요하기도 하다.
반면 파인튜닝은 사전 학습 이후 이루어지는 학습을 의미한다. 사전 학습된 언어 모델을 가져와 하고자 하는 작업에 특화된 데이터셋을 이용해 추가 학습을 수행한다. 이 경우 원하는 성능을 얻기 위해 적은 시간과 리소스를 필요로 한다.
📌 트랜스포머 일반 구조
모델은 기본적으로 인코더와 디코더, 두 개의 블럭으로 이루어져 있다.
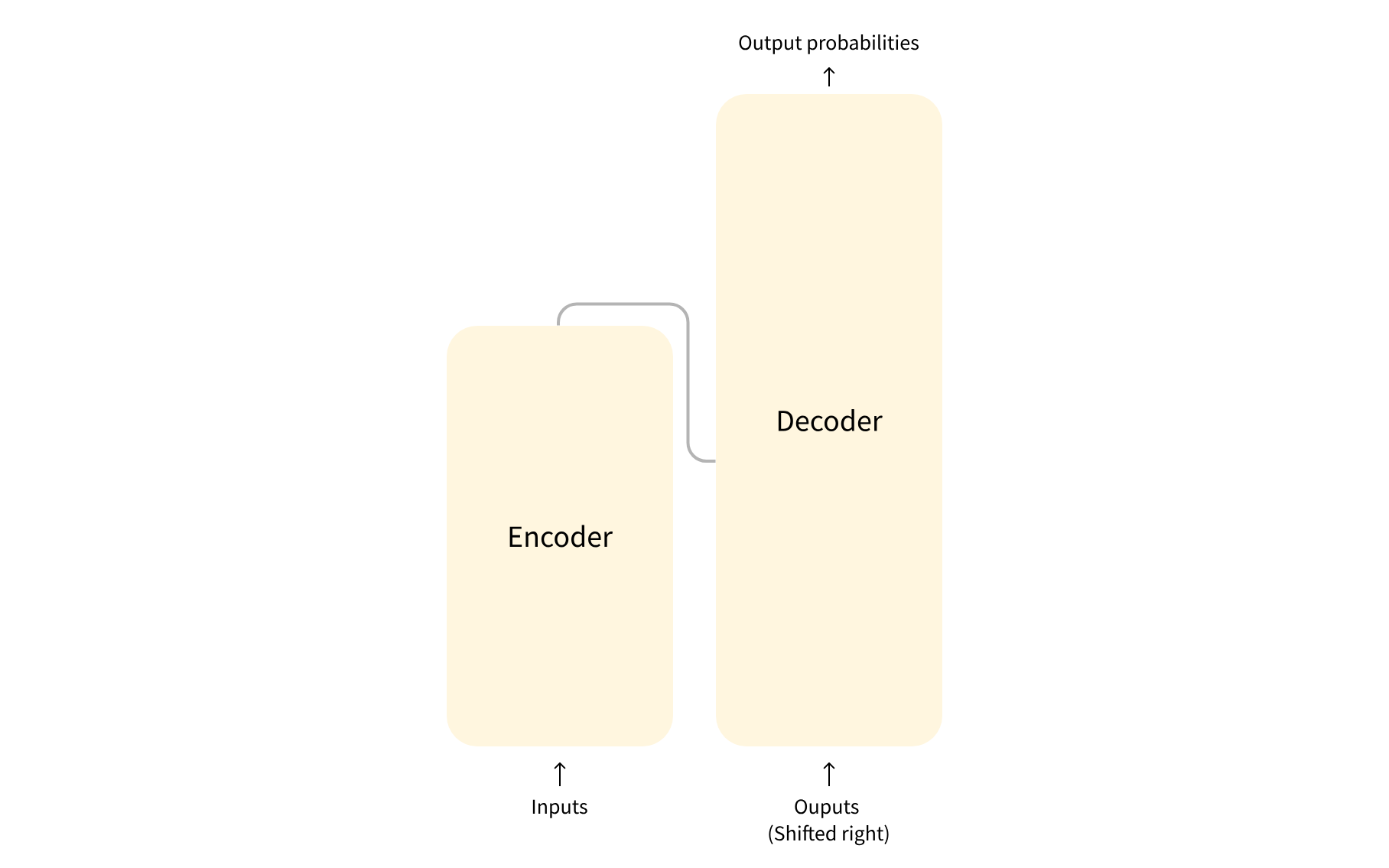
각 블럭은 다음과 같이 개별적으로 쓰일 수도 있다.
- 인코더 모델 : 문장 분류, 개체명 인식과 같이 입력에 대한 높은 이해를 요구하는 작업에 특화
- 디코더 모델 : 텍스트 생성과 같이 생성 관련 작업에 특화
- 인코더-디코더 모델 또는 시퀀스-투-시퀀스 모델 : 번역, 요약과 같이 입력을 필요로 하는 생성 관련 작업에 특화
📌 어텐션 레이어
트랜스포머 모델의 주요 특징 중 하나는 어텐션 레이어라는 특수 레이어로 구성되어 있다는 점이다. 이 레이어는 단어의 표현을 다룰 때 입력으로 넣어준 문장의 특정 단어에 어텐션(주의)를 기울이고 특정 단어는 무시하도록 알려준다.
예를 들어, 단어마다 성별을 고려하는 프랑스어를 번역한다고 해보자. “You like this course”라는 문장에서 동사 "this"는 문맥에 따라 다른 의미로 해석되기 때문에 모델은 "course"라는 단어에 주의를 기울인다. 하지만 나머지 단어들은 "this" 의미 해석에 크게 중요하지 않으므로 무시해도 된다.
📌 원본 구조
트랜스포머 모델은 처음에 번역을 위해 만들어졌다.
학습 시에 인코더는 특정 언어의 입력 문장을 받고, 동시에 디코더는 타겟 언어로 된 동일한 의미의 문장을 받는다. 인코더에서 주어진 단어의 번역은 문장의 전후를 살펴보아야 하기 때문에 어텐션 레이어는 문장 내의 모든 단어를 활용할 수 있다.
반면, 디코더는 순차적으로 작동하기 때문에 문장 내에서 현재 생성(번역)되고 있는 단어 앞의 이미 생성된 단어들만 이용할 수 있다. 예시로, 번역된 타겟의 처음 세 단어를 예측해 놨을 때, 이 결과를 디코더로 넘기면 디코더는 인코더로부터 받은 모든 입력 정보를 함께 이용해 네 번째 올 단어를 예측한다.
처음 트랜스포머의 구조는 아래와 같이 왼쪽에는 인코더, 오른쪽에는 디코더가 있는 형태를 지닌다.
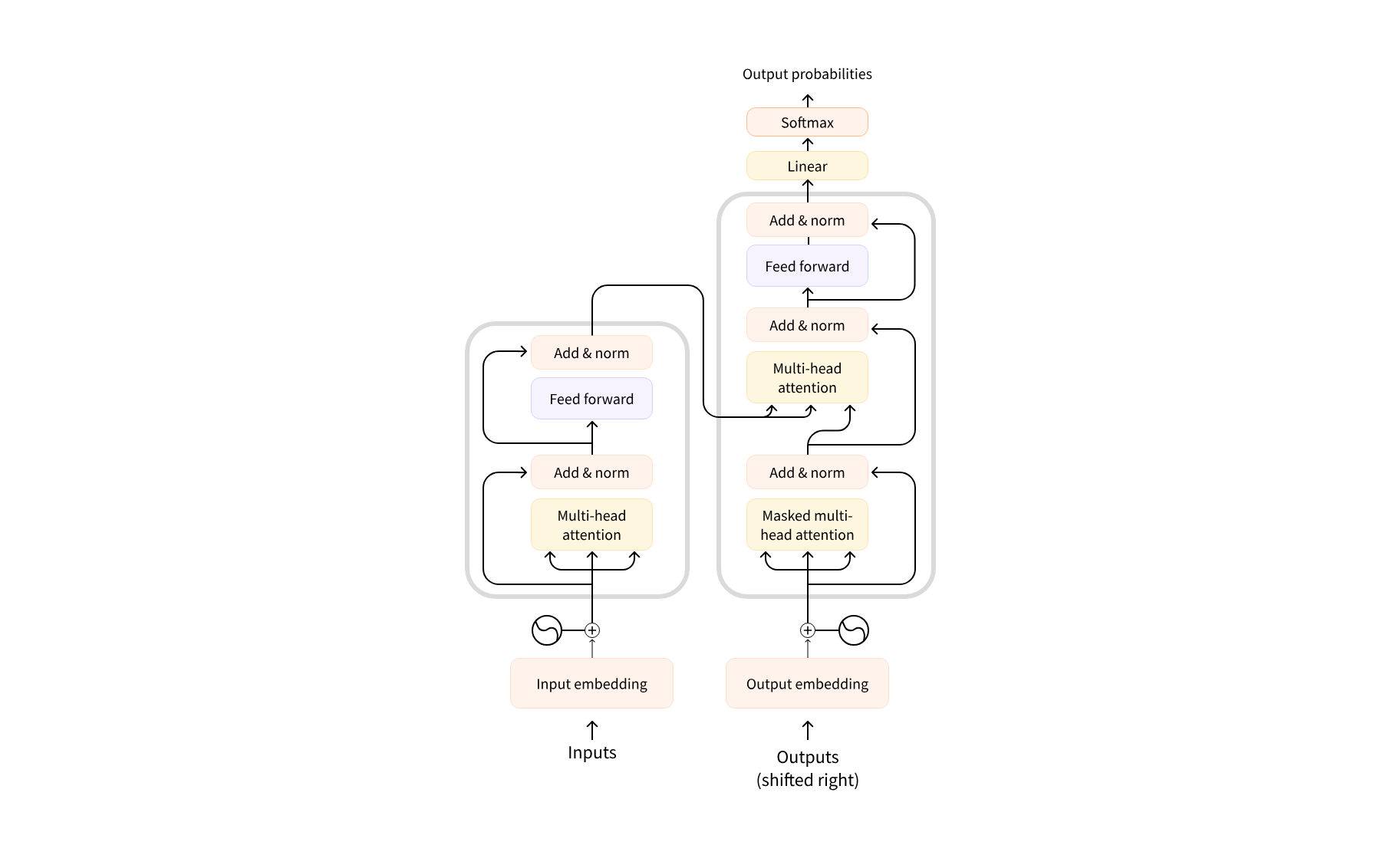
디코더 블럭의 첫 번째 어텐션 레이어는 이전의 모든 디코더 입력에 주의를 기울이지만 두 번째 어텐션 레이어는 인코더의 출력만 사용한다. 따라서 디코더는 전체 입력 문장에 액세스하여 다음에 올 단어를 잘 예측할 수 있는 것이다.
✅ 트랜스포머 모델
어떤 문제를 풀고 싶은지에 따라 전체 모델 구조를 사용하거나 인코더 또는 디코더만 사용할 수 있다.
| 모델 | 예시 | 작업 |
|---|---|---|
| 인코더 | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 문장 분류, 개체명 인식, 추출 질의 응답 |
| 디코더 | CTRL, GPT, GPT-2, Transformer XL | 텍스트 생성 |
| 인코더-디코더 | BART, T5, Marian, mBART | 오약, 번역, 생성 질의 응답 |
📌 인코더 모델
인코더 모델은 트랜스포머 모델의 인코더만 사용한다. 각 단계에서 어텐션 레이어는 초기 문장의 모든 단어에 액세스할 수 있다. 인코더 모델은 주어진 문장의 단어에 랜덤 마스킹을 하는 방법 등으로 훼손시킨 뒤 모델이 원본 문장을 찾아 재구성하게 하는 식으로 사전 학습을 진행한다.
- 특화 작업 : 문장 분류, 개체명 인식(더 넓은 범위에서 단어 분류), 추출 질의 응답 등과 같이 전체 문장에 대한 이해를 요구하는 작업
- 대표 모델
ALBERT
BERT
DistilBERT
ELECTRA
RoBERTa
📌 디코더 모델
디코더 모델은 트랜스포머 모델의 디코더만 사용한다. 각 단계마다 어텐션 레이어는 주어진 단어에 대해 문장 내에서 해당 단어 앞에 위치한 단어들에 대해서만 액세스할 수 있다. 디코더 모델의 사전 학습은 보통 문장 내 다음 단어 예측을 반복하는 방식으로 이루어져 있다.
- 특화 작업 : 텍스트 생성
- 대표 모델
CTRL
GPT
GPT-2
Transformer XL
📌 시퀀스-투-시퀀스 모델
인코더-디코더 모델은 트랜스포머 구조의 인코더와 디코더를 모두 사용한다. 각 단계마다 인코더의 어텐션 레이어는 초기 문장의 모든 단어에 액세스 할 수 있는 반면, 디코더의 어텐션 레이어는 주어진 단어 앞에 위치한 단어들에만 액세스 할 수 있다.
이러한 모델의 사전 학습은 조금 더 복잡하다. 예를 들어 T5는 임의의 텍스트 범위를 하나의 특수 마스크 토큰으로 바꾸고 마스크 단어를 대체할 텍스트를 예측하는 방식으로 사전 학습 되었다.
- 특화 작업 : 요약, 번역, 생성 질의 응답과 같이 주어진 입력을 기반으로 새로운 문장을 생성하는 작업
- 대표 모델
BART
mBART
Marian
T5
✅ 사전 학습 모델 사용 시 주의점
사전 학습 시 무수히 많은 양의 데이터를 수집하면서 양질의 데이터 외에도 수집했을 가능성이 있다. 어떤 모델은 편향된 데이터로 인해 혐오 표현을 할 가능성도 있는데, 이 경우 파인튜닝을 해도 내재된 편향성을 없애지 못하므로 주의해야 한다.
더 자세한 내용 참고
트랜스포머(Transformer)와 어텐션 매커니즘(Attention Mechanism)이란 무엇인가?
ChatGPT에서 제작한 transformer를 시각적으로 설명해주는 사이트
