
✅ Assistants API란?
2023년 11월 6일 진행된 OpenAI Dev Day에서 발표된 Assistants API는 Chat Completions API를 발전시킨 것인데요. 코드 인터프리터(코드 실행), 문서 검색, 기능 호출 및 실행의 세 가지 도구로 개발자의 보조자 역할을 수행합니다. 현재 Playground와 코드 모두 활용 가능합니다.
2024년 10월 현재 Beta 버전으로 사용 가능합니다.
✅ 구성
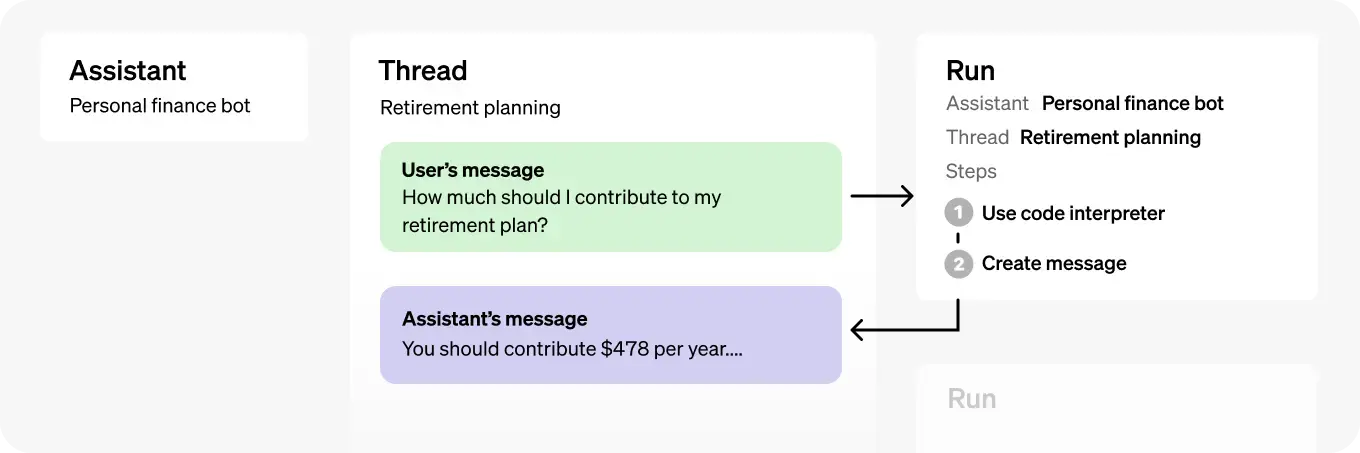
| 객체 | 설명 |
|---|---|
| Assistant | OpenAI의 모델을 사용하고 도구를 호출하는 목적으로 설계된 AI |
| Thread | - 어시스턴트와 사용자 간의 대화 세션 - 메시지를 저장하고 콘텐츠를 모델의 컨텍스트에 맞게 자동으로 잘라냄 |
| Message | - 어시스턴트나 사용자가 생성한 메시지 - 메시지는 텍스트, 이미지 및 기타 파일을 포함할 수 있음 - 메시지는 스레드에 리스트로 저장됨 |
| Run | - 스레드에서 어시스턴트를 호출하는 과정 - 어시스턴트는 설정과 스레드의 메시지를 사용하여 모델과 도구를 호출 - Run의 일환으로 어시스턴트는 메시지를 스레드에 추가 |
| Run Step | - Run의 일환으로 어시스턴트가 수행한 세부 단계 목록 - 어시스턴트는 도구를 호출하거나 메시지를 생성할 수 있음 - Run Steps를 검사하면 어시스턴트가 최종 결과에 도달하는 방법을 살펴볼 수 있음 |
📌 Assistant, Thread, Message 예시
# Assistant : AI에 부여한 역할
수학 선생님
# Thread
사용자(학생): "피타고라스의 정리를 설명해줄 수 있어요?"
AI(수학 선생님): "네, 피타고라스의 정리는 직각삼각형에서 a² + b² = c²라는 공식으로 표현됩니다."
사용자(학생): "그럼 예를 들어 계산해볼 수 있을까요?"
# Message
- 스레드의 대화 각각 한 줄이 모두 Message
- role과 content로 구성📌 Run
Run은 Assistants API와 Chat Completions API 사이의 주요 차이점으로, 어시스턴트가 스레드에서 사용자 메시지를 처리하고 응답을 생성하는 과정입니다. 각 Run은 어시스턴트의 설정과 스레드의 메시지로 모델이나 도구를 호출하면 수행됩니다.
Run의 세부 단계는 Run Step으로 기록됩니다. 각 Run Step은 어시스턴트가 특정 작업을 수행하는 과정을 세부적으로 설명하며, 이를 통해 개발자는 어시스턴트의 동작을 분석할 수 있습니다. 예를 들어, 어떤 도구를 호출했는지, 어떤 메시지를 생성했는지에 대한 정보를 포함합니다.
Run의 특성은 Assistants API의 특징인 비동기 방식과 상태 관리를 가능하게 합니다.
✅ 비동기 방식을 통한 상태 관리 (상태 저장, Stateful)
스레드에 메시지를 넣은 뒤 run 실행 전까지는 실행되지 않고 비동기 상태인 Queue에 머뭅니다. 즉, 스레드에 메시지를 쌓아두고 원하는 시점까지는 대기하도록 한 뒤, 필요한 시점에 run 객체를 만들어서 실행하면 메시지가 전송되면서 답변을 도출할 수 있습니다.
이 특징은 Chat Completions API와 Assistants API를 비교하여 보면 이해하기 쉽습니다. 먼저 ChatGPT Completions API입니다.
- Chat Completions API는 상태 저장 X
- 매번 전체 대화 기록 API 호출 시 전송 필요
- 아래 코드처럼 이전 대화 ("오늘 날씨 어때?", "그리고 내일은?")를 모두 포함해서 보내야 모델이 대화의 맥락을 이해하고 올바른 답변 제공
import openai
# 이전 대화 기록을 모두 포함하여 매번 API 호출 시 전송해야 함
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "오늘 날씨 어때?"},
{"role": "assistant", "content": "오늘은 맑습니다."},
{"role": "user", "content": "그리고 내일은?"}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
print(response['choices'][0]['message']['content'])다음은 Assistants API입니다.
- 대화의 문맥을 API가 알아서 기억하고 관리하기 때문에, 개발자가 대화 내역을 직접 저장하거나 다시 보낼 필요 X
- 사용자가 "오늘 날씨 어때?"라고 물어본 후 "그리고 내일은?"이라고 물어보면, Assistants API는 첫 번째 질문을 기억하고 있기 때문에 두 번째 질문에서도 자연스럽게 맥락을 이해하고 "내일 날씨"에 대한 답변 제공 가능
import openai
# 처음 대화 시작 시에는 대화 기록이 필요
response = openai.Assistant.start_chat(
model="gpt-4-turbo",
user_message="오늘 날씨 어때?"
)
# Assistants API는 대화 상태를 자동으로 관리함
response = openai.Assistant.send_message(
session_id=response['session_id'],
message="그리고 내일은?"
)
print(response['choices'][0]['message']['content'])이런 상태관리 기능 덕분에 Assistants API는 복잡한 대화 흐름을 더 쉽게 처리할 수 있으며, 개발자가 대화 데이터를 관리하는 부담을 줄여줍니다.
✅ Assistants API vs Chat Completions API
두 API를 비교하면 다음과 같습니다.
| 특성 | Chat Completions API | Assistants API |
|---|---|---|
| 상태 관리 | 상태 비저장 (Stateless) | 상태 저장 (Stateful) |
| 작업 방식 | 요청 시 전체 대화 기록을 전송해야 함 | 대화의 맥락을 자동으로 관리함 |
| 사용 사례 | 단순한 Q&A, 짧은 대화, 초기 개발 | 복잡한 대화 흐름, 고객 지원, 개인 비서 |
| 비동기 처리 | 비동기 지원 없음 | 비동기 처리 가능 |
| 응답 처리 | 매번 전체 대화 기록을 포함해야 하므로 불편할 수 있음 | 이전 대화를 기억하므로 더 자연스러운 대화 가능 |
| 개발 용이성 | 간단한 애플리케이션에 적합 | 복잡한 애플리케이션에 적합 |
✅ 업데이트 내역
본 포스팅에서는 업데이트 내역을 위주로 다루기 때문에 코드 인터프리터(코드 실행), 문서 검색, 기능 호출 및 실행의 세 가지 도구 각각에 대해 자세히 다루지는 않습니다. 세 도구에 대한 자세한 내용은 테디노트님의 영상 참고해 주세요.
EP02. #openai 의 새로운 기능 #assistant API 3가지 도구 활용법
2024년 4월, OpenAI는 Assistants API의 새로운 버전인 OpenAI-Beta: assistants=v2를 발표하며 여러 가지 새로운 기능과 개선 사항을 소개했습니다. 주요 내용은 다음과 같습니다.
1. 개선된 검색 도구인 file_search 출시
최대 10,000개의 파일을 각 어시스턴트가 수용할 수 있으며, 이전보다 500배 증가했습니다. 속도가 빨라지고 다중 스레드 검색을 통해 병렬 쿼리를 지원하며, reranking 및 쿼리 재작성 기능이 향상되었습니다.
2. 벡터 스토어 도입
파일이 벡터 스토어에 추가되면 자동으로 구문 분석되고 조각화되어 임베딩됩니다. 이를 통해 검색할 준비가 된 상태가 되며, 벡터 스토어는 어시스턴트와 스레드 간에 사용 가능하여 파일 관리와 청구를 단순화합니다.
3. 토큰 사용 관리 기능 추가
Assistants API에서 각 실행에서 사용할 최대 토큰 수를 제어할 수 있어 토큰 사용 비용을 관리할 수 있습니다. 또한 각 실행에서 사용되는 이전/최근 메시지 수에 대한 제한을 설정할 수 있습니다.
4. tool_choice 매개변수 지원
특정 실행에서 file_search, code_interpreter 또는 함수와 같은 특정 도구를 강제로 사용할 수 있습니다.
5. 사용자 정의 대화 기록 생성
assistant 역할을 가진 메시지를 생성하여 스레드에서 사용자 정의 대화 기록을 만들 수 있습니다.
6. 모델 구성 매개변수 지원
Assistant 및 Run 객체는 이제 온도, 응답 형식(JSON 모드) 및 top_p와 같은 인기 있는 모델 구성 매개변수를 지원합니다.
7. Fine-tuned 모델 사용 가능
현재 fine-tuned gpt-3.5-turbo-0125 버전만 지원되지만, Assistants API에서 fine-tuned 모델을 사용할 수 있습니다.
8. 스트리밍 지원
9. Node 및 Python SDK에 스트리밍 및 폴링 헬퍼 추가
10. 마이그레이션 가이드 제공
✅ 요청 구조 (업데이트 반영)
📌 Assistant
| 필드 이름 | 타입 | 필수 여부 | 설명 |
|---|---|---|---|
| model | string | 필수 | 사용할 모델의 ID |
| name | string or null | 선택 | 어시스턴트의 이름 (최대 길이: 256자) |
| description | string or null | 선택 | 어시스턴트에 대한 설명 (최대 길이: 512자) |
| instructions | string or null | 선택 | 어시스턴트를 위한 시스템 지침 (최대 길이: 256,000자) |
| tools | array | 선택 | 어시스턴트에 대해 활성화된 도구 목록 (최대: 128개 도구; code_interpreter, file_search, function 등) |
| tool_resources | object or null | 선택 | 어시스턴트 도구에 사용되는 자원 (도구 유형에 따라 다름) |
| metadata | map | 선택 | 추가적인 구조화된 정보를 위한 키-값 쌍 (최대: 16쌍; 키 최대 길이: 64자; 값 최대 길이: 512자) |
| temperature | number or null | 선택 | 샘플링 온도 (범위: 0 ~ 2; 기본값: 1), 높은 값일수록 출력이 더 무작위적 |
| top_p | number or null | 선택 | nucleus 샘플링 매개변수 (범위: 0 ~ 1; 기본값: 1), 상위 p 확률 질량을 가진 토큰만 고려, temperature과 top_p 중 하나만 조정하는 것 권장 |
| response_format | "auto" or object | 선택 | 출력 형식 지정, 구조화된 출력을 활성화하거나 JSON 모드를 사용할 수 있지만 JSON 모드에서는 JSON 출력을 명시적으로 지시해야 함 |
📌 Thread
| 필드 이름 | 타입 | 필수 여부 | 설명 |
|---|---|---|---|
| messages | array | 선택 | 스레드의 메시지 목록 (role + content) |
| tool_resources | object or null | 선택 | - 스레드에서 어시스턴트 도구에 사용할 수 있는 리소스 세트 - 도구 유형에 따라 다름 (code_interpreter의 경우 파일 ID 목록, file_search의 경우 벡터 스토어 ID 목록) |
| metadata | map | 선택 | 추가적인 구조화된 정보를 위한 키-값 쌍 (최대: 16쌍; 키 최대 길이: 64자; 값 최대 길이: 512자) |
📌 Message
| 필드 이름 | 타입 | 필수 여부 | 설명 |
|---|---|---|---|
| role | string | 필수 | 메시지를 생성하는 엔터티 역할 - user : 사용자의 메시지 - assistant : AI의 메시지 |
📌 Run
| 필드 이름 | 타입 | 필수 여부 | 설명 |
|---|---|---|---|
| assistant_id | string | 필수 | assistant id |
| model | string | 선택 | 모델 종류 |
| instructions | string or null | 선택 | 어시스턴트의 기본 동작을 설정하는 주 지침, 이전의 모든 지침을 덮어씀 |
| additional_instructions | string or null | 선택 | 어시스턴트의 행동을 세부 조정, 기존 지침을 변경하지 않고 보완적인 정보 제공 |
| additional_messages | array or null | 선택 | 실행을 생성하기 전에 스레드에 메시지 추가 |
| tools | array or null | 선택 | 어시스턴트가 사용 가능한 도구 정의 |
| metadata | map | 선택 | - 객체에 연결할 수 있는 16개의 키-값 쌍의 집합 - 객체에 대한 구조화된 추가 정보 저장 (키 최대 길이 64자, 값 최대 길이 512자) |
| temperature | number or null | 선택 | 샘플링 온도 (범위: 0 ~ 2; 기본값: 1), 높은 값일수록 출력이 더 무작위적 |
| top_p | number or null | 선택 | - nucleus 샘플링 매개변수 (범위: 0 ~ 1; 기본값: 1) - 상위 p 확률 질량을 가진 토큰만 고려 - temperature과 top_p 중 하나만 조정하는 것 권장 |
| stream | boolean or null | 선택 | true인 경우 실행 중 발생하는 이벤트 스트림을 서버 전송 이벤트로 반환하며, 실행이 터미널 상태에 들어가면 종료 |
| max_prompt_tokens | integer or null | 선택 | - 실행 과정에서 사용할 수 있는 최대 프롬프트 토큰 수 - 여러 번의 실행에서 지정된 수의 프롬프트 토큰만 사용하도록 시도 - 초과 시 실행은 완료되지 않음 |
| max_completion_tokens | integer or null | 선택 | - 실행 과정에서 사용할 수 있는 최대 완료 토큰 수 - 여러 번의 실행에서 지정된 수의 완료 토큰만 사용하도록 시도 - 초과 시 실행은 완료되지 않음 |
| truncation_strategy | object | 선택 | - 실행 전에 스레드를 잘라내는 방법을 제어 - 실행의 초기 컨텍스트 창을 제어하는 데 사용됨 - 기본값: 자동 - last_messages로 설정하면 스레드의 최근 메시지 n개로 잘라짐 - auto으로 설정하면 스레드 중간에 있는 메시지가 모델의 컨텍스트 길이인 max_prompt_tokens에 맞게 삭제됨 |
| tool_choice | string or object | 선택 | - 모델이 호출할 도구 제어 - none은 모델이 도구를 호출하지 않고 메시지를 생성함을 의미 - auto는 모델이 메시지 생성 또는 도구 호출을 선택할 수 있음을 의미 |
| parallel_tool_calls | boolean | 선택 | - 기본값 : true - 도구 사용 중 병렬 함수 호출을 활성화할지 여부 결정 |
| response_format | "auto" or object | 선택 | 모델이 출력해야 하는 형식을 지정 |
status 목록
- queued: 아직 실행이 되지 않고 대기중인 상태
- in_progress: 처리중
- requires_action: 사용자 입력 대기중
- cancelling: 작업 취소중
- cancelled: 작업 취소 완료
- failed: 실패(오류)
- completed: 작업 완료
- expired: 작업 만료
✅ 예제 (문서 검색)
1. Assistant 생성
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="Financial Analyst Assistant",
instructions="You are an expert financial analyst. Use you knowledge base to answer questions about audited financial statements.",
model="gpt-4o",
tools=[{"type": "file_search"}],
)2. 파일 업로드 & 벡터 스토어에 추가
vector_store = client.beta.vector_stores.create(name="Financial Statements")
file_paths = ["edgar/goog-10k.pdf", "edgar/brka-10k.txt"]
file_streams = [open(path, "rb") for path in file_paths]
file_batch = client.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id, files=file_streams
)
print(file_batch.status)
print(file_batch.file_counts)3. assistant가 파일에 접근할 수 있도록 assistant의 tool_resource를 새로운 vectore_store.ID로 업데이트
assistant = client.beta.assistants.update(
assistant_id=assistant.id,
tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}},
)4. thread 생성
message_file = client.files.create(
file=open("edgar/aapl-10k.pdf", "rb"), purpose="assistants"
)
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "How many shares of AAPL were outstanding at the end of of October 2023?",
# Attach the new file to the message.
"attachments": [
{ "file_id": message_file.id, "tools": [{"type": "file_search"}] }
],
}
]
)5. run을 생성하고 모델이 파일 검색 도구를 사용하여 사용자의 질문에 대한 응답을 제공하는 것 확인 (스트리밍 ver)
from typing_extensions import override
from openai import AssistantEventHandler, OpenAI
client = OpenAI()
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text) -> None:
print(f"\nassistant > ", end="", flush=True)
@override
def on_tool_call_created(self, tool_call):
print(f"\nassistant > {tool_call.type}\n", flush=True)
@override
def on_message_done(self, message) -> None:
# print a citation to the file searched
message_content = message.content[0].text
annotations = message_content.annotations
citations = []
for index, annotation in enumerate(annotations):
message_content.value = message_content.value.replace(
annotation.text, f"[{index}]"
)
if file_citation := getattr(annotation, "file_citation", None):
cited_file = client.files.retrieve(file_citation.file_id)
citations.append(f"[{index}] {cited_file.filename}")
print(message_content.value)
print("\n".join(citations))
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
instructions="Please address the user as Jane Doe. The user has a premium account.",
event_handler=EventHandler(),
) as stream:
stream.until_done()참고자료
OpenAI Platform
[테디노트] EP01. #openai 의 새로운 기능 #assistant API 완벽히 이해해보기
