
한 해가 가기 전, 6월에 마친 부트캠프 최종 프로젝트 내용을 정리합니다. 6월에 글을 적다가 이제야 마무리해서 글에 시차가 느껴질 수 있습니다 😆 최종 프로젝트를 통해서도 정말 큰 성장을 이루었다고 느꼈는데, 데이터 사이언티스트로서 앞으로 로드맵을 그리고 있는 현 시점에서 이때를 돌아보며 인사이트를 정리해 보았습니다.
(사내 자료가 포함된 발표 자료와 코드는 공개가 어려워 제외하거나 가려둔 점 양해 부탁드립니다.)
✅ 진행 기간 및 역할
- 진행 기간 : 2024/4/29 ~ 6/17
- 주요 업무 : 팀장, 서비스 개발, 배포, 발표
✅ 프로젝트 요약
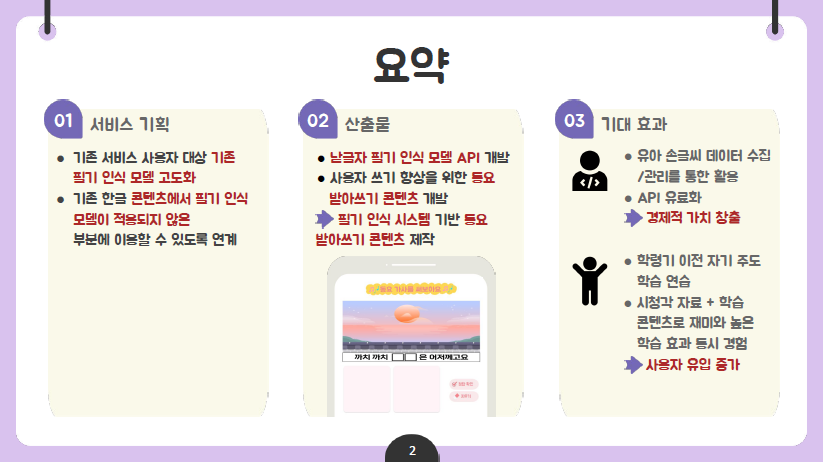
필기 인식 시스템 구현을 통해 만 5~6세 사용자를 대상으로 하는 한글 동요 받아쓰기 콘텐츠를 제작하였다. 제안 요청서를 바탕으로 세부 프로젝트로 나누어 개발을 진행하였으며, 두 가지 산출물을 도출하였다.
1. 낱글자 필기 인식 모델 API 개발
고도화된 모델을 API로 제공함으로써 본 콘텐츠 뿐만 아니라 낱글자 인식을 요하는 자사 콘텐츠의 질을 향상할 수 있다.
2. 한글 받아쓰기 콘텐츠 개발
기존 한글 콘텐츠 중 필기 인식 모델이 적용되지 않았던 동요 콘텐츠와 한글 받아쓰기 콘텐츠를 통합함으로써 사용자의 한글 쓰기 실력을 더욱 향상할 수 있을 것으로 기대한다.
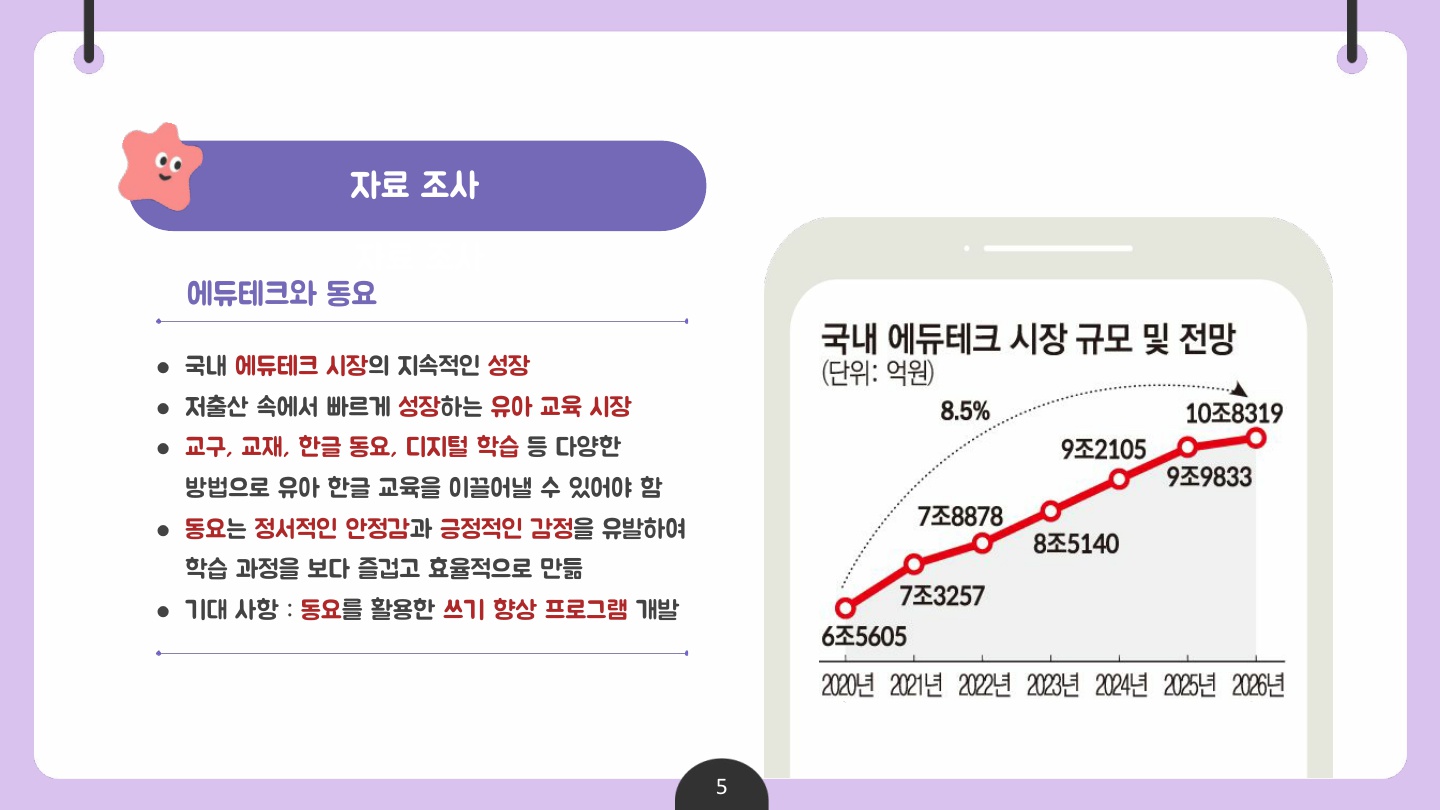
✅ 기획 의도
 |  |
✅ 산출물 1 : 낱글자 필기 인식 API
딥러닝에서 이미지 인식 및 분류 작업에 널리 사용되는 신경망 구조인 ResNet을 바탕으로 진행하였다.
일반적인 딥러닝 네트워크와 달리 ResNet은 입력값과 출력값 사이의 차이를 의미하는 잔차를 학습하여 깊은 네트워크에서도 기울기 소실 문제를 완화할 수 있다. ‘ResNet’의 다양한 버전의 특정 레이어를 추출하고, 추가 레이어를 쌓으며 필기 인식을 위한 모델 고도화를 진행하였다.
이를 바탕으로 웹 프레임워크 ‘FastAPI’를 활용하여 사용자가 낱글자 손글씨 이미지를 업로드하면 그 이미지에 해당하는 낱글자를 인식하여 반환하는 한글 필기 인식 API를 개발하였다.





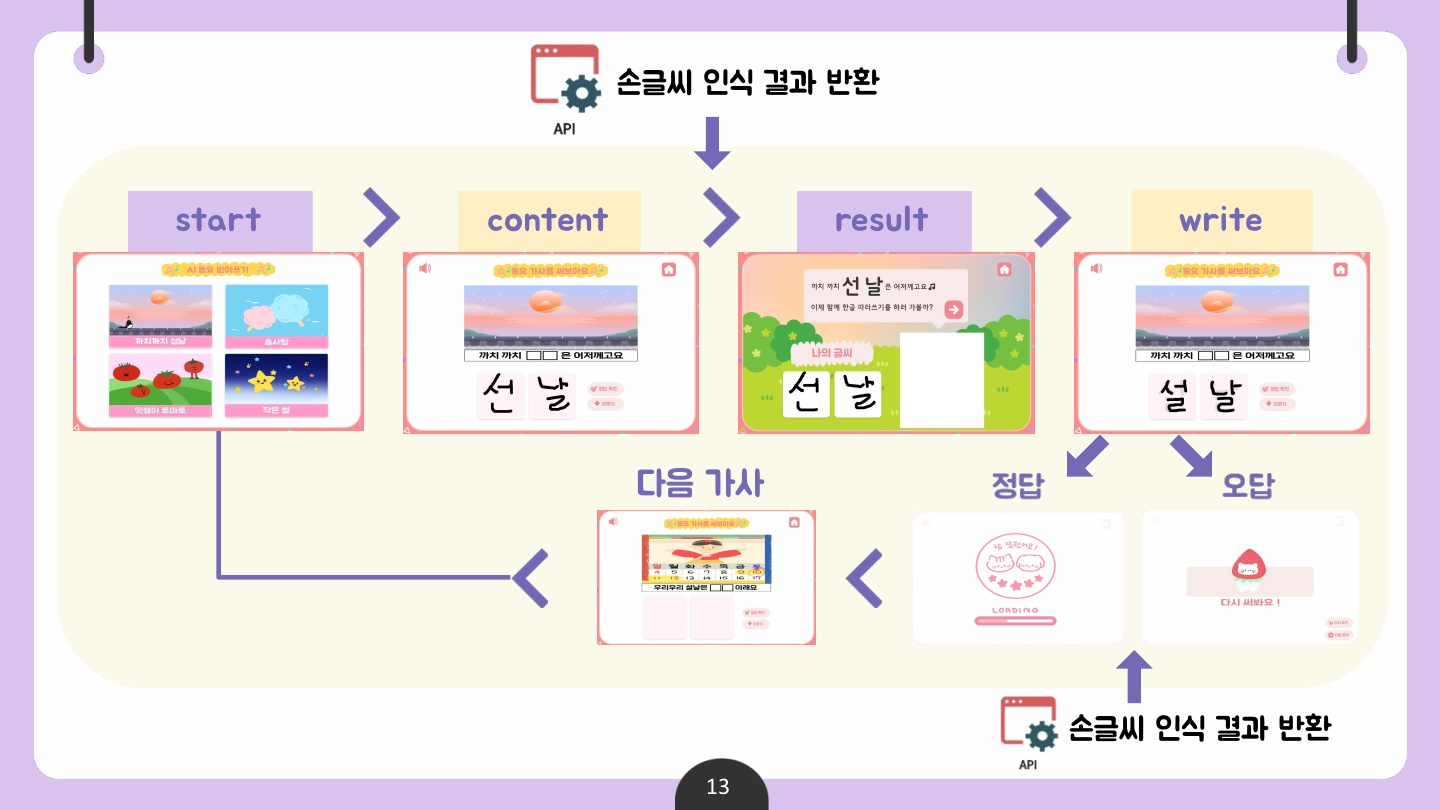
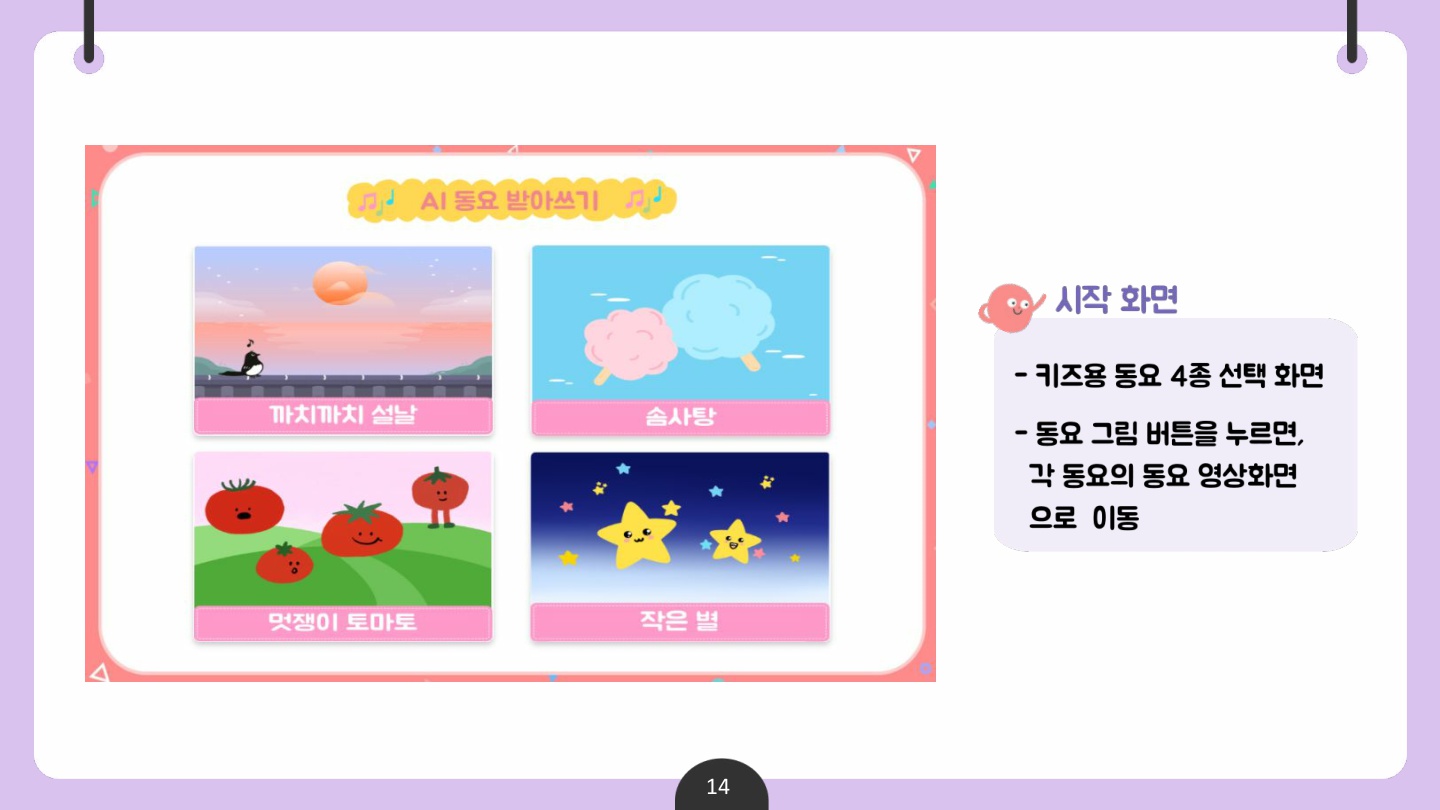
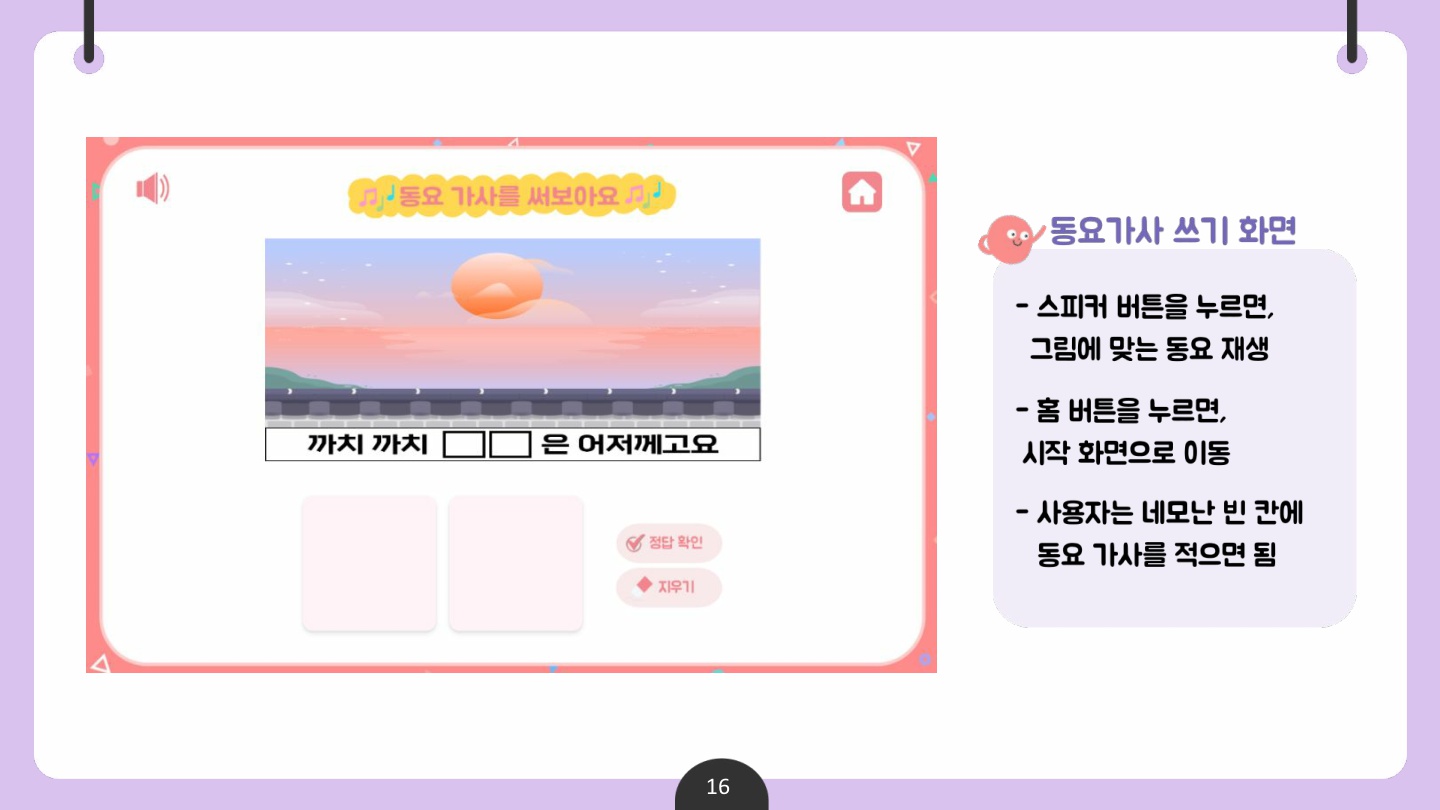
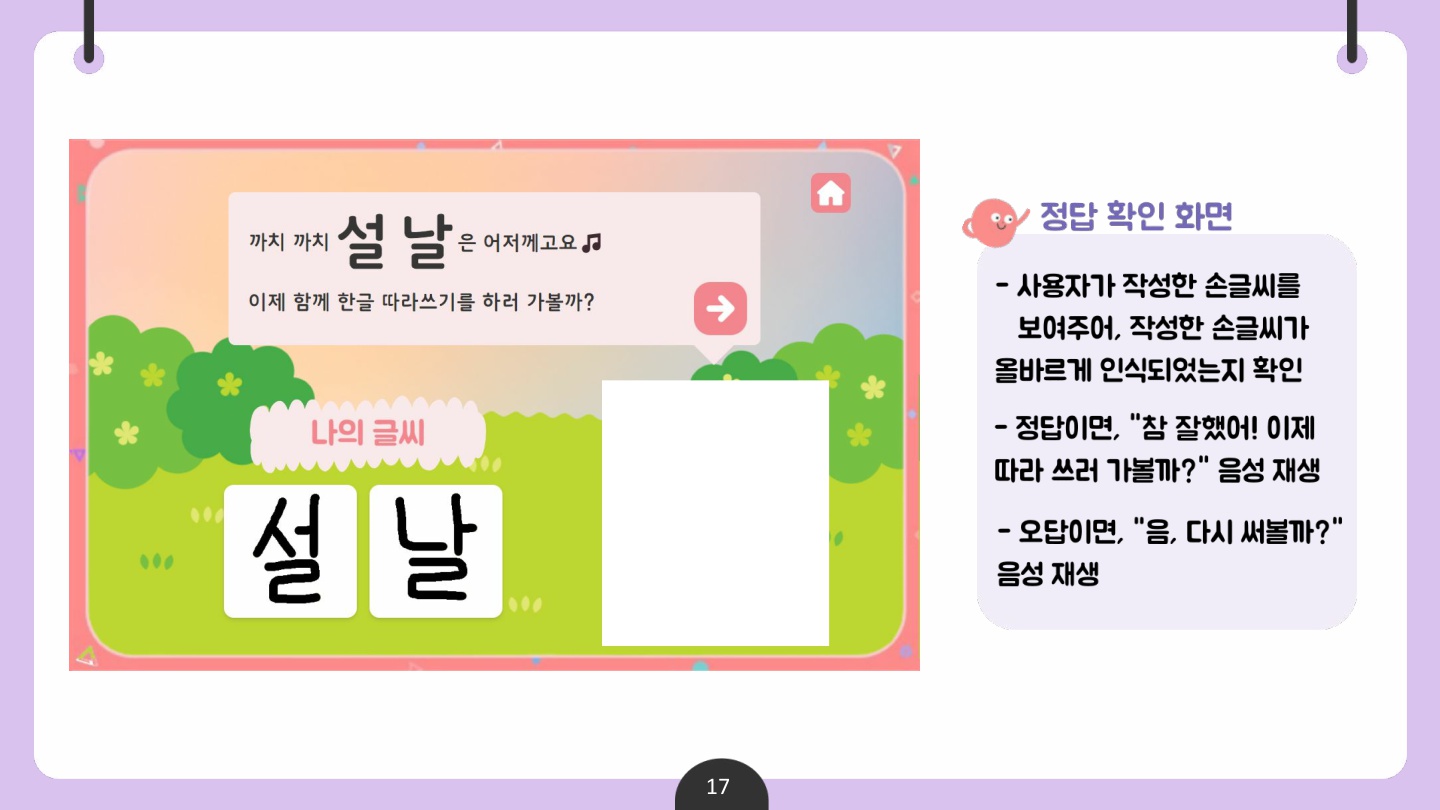
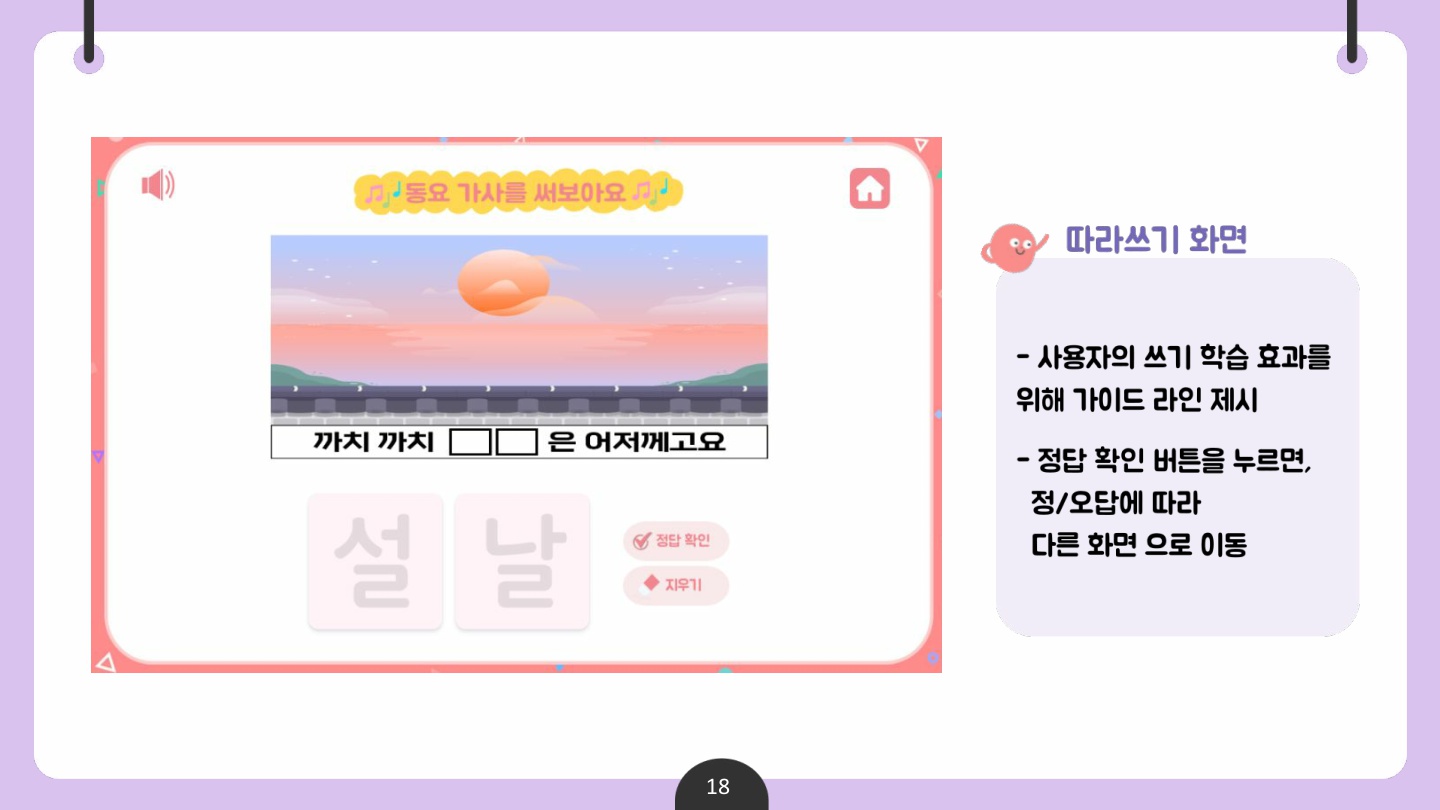
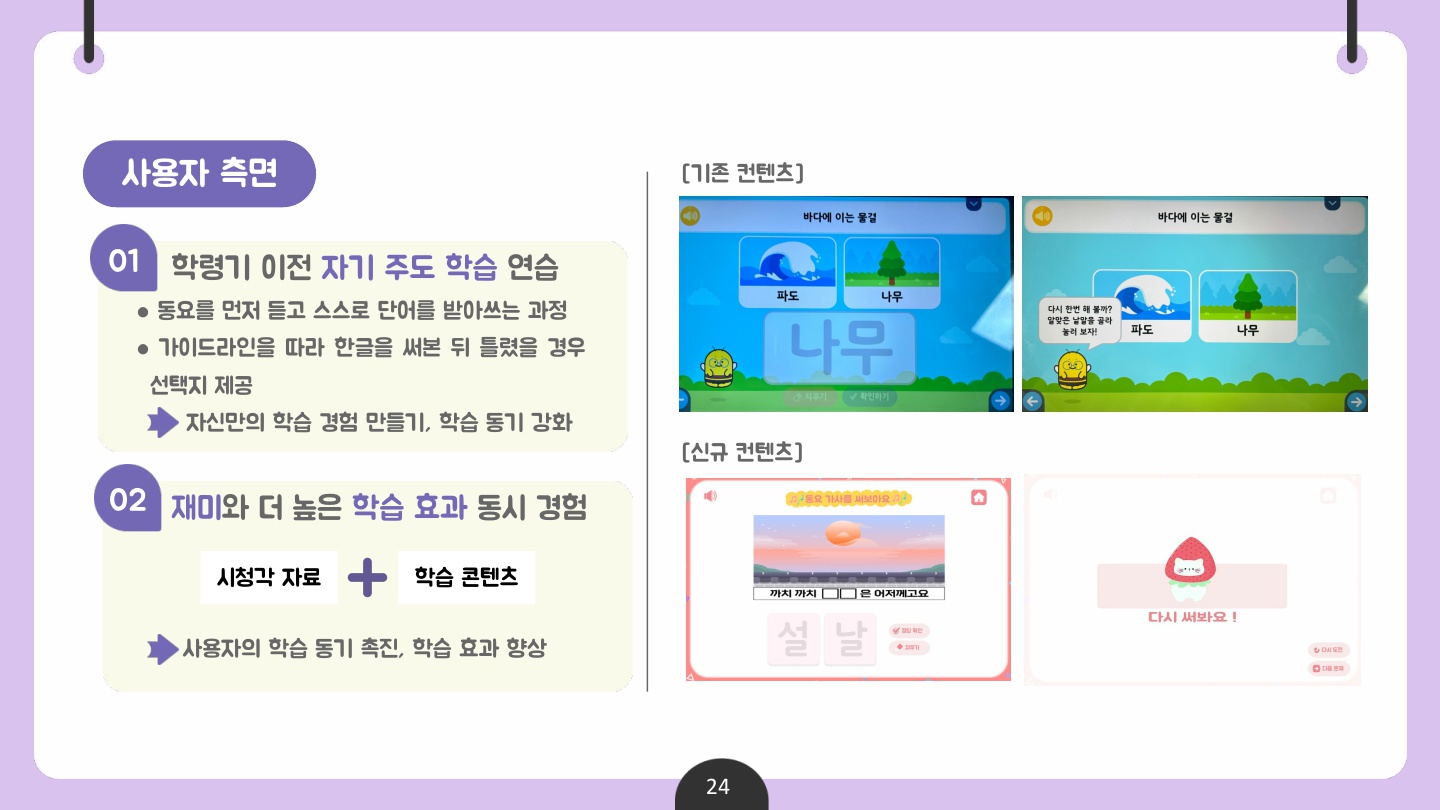
✅ 산출물 2 : 동요 받아쓰기 콘텐츠
동요 받아쓰기 콘텐츠 개발은 기존에 존재하는 동요 듣기 서비스와 연계하여 진행하였다.
음악은 사용자의 감정을 자극하고 뇌 활동을 촉진시켜 학습의 효율을 높인다. 특히, 동요는 정서적인 안정감과 긍정적인 감정을 유발하여 학습 과정을 보다 즐겁고 효율적으로 만들어준다.
그에 따라 사용자가 대중적으로 많이 알려진 동요 영상을 시청하고, 동요를 들으면서 가사 속 빈칸을 직접 받아 써보며 한글 학습에 흥미를 가지기를 기대한다.
📌 서비스 설계도

📌 서비스 화면
 |  |
 |  |
 |  |
✅ 배포
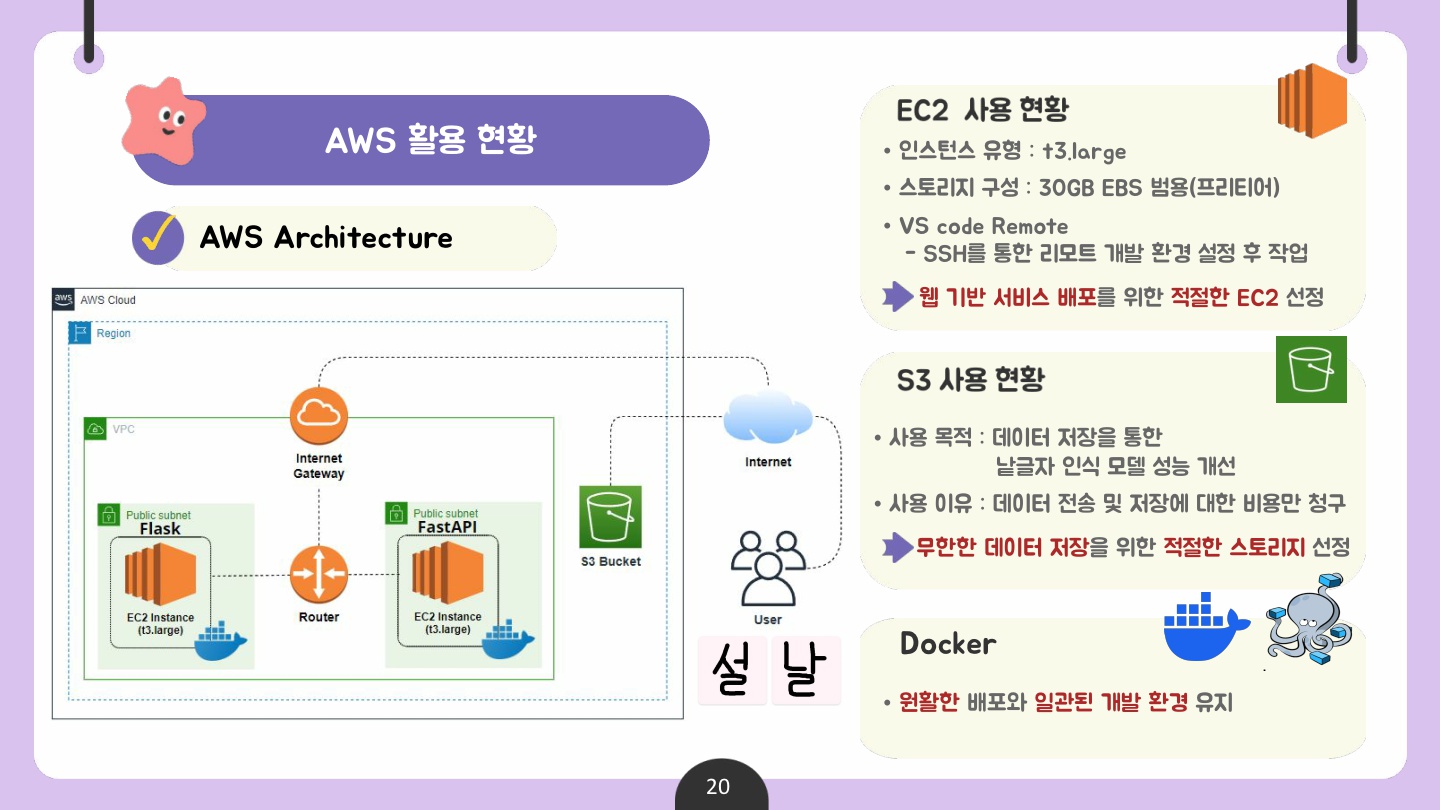
앞선 두 산출물은 AWS EC2를 활용하여 독자적인 서비스로 배포함으로써 유연하게 활용할 수 있도록 하였다.
Docker Compose를 활용하여 각 서비스가 격리된 환경에서 실행되도록 보장했으며 이러한 설정은 제공하게 될 서비스의 가용성과 안정성을 극대화할 수 있을 것으로 기대된다.
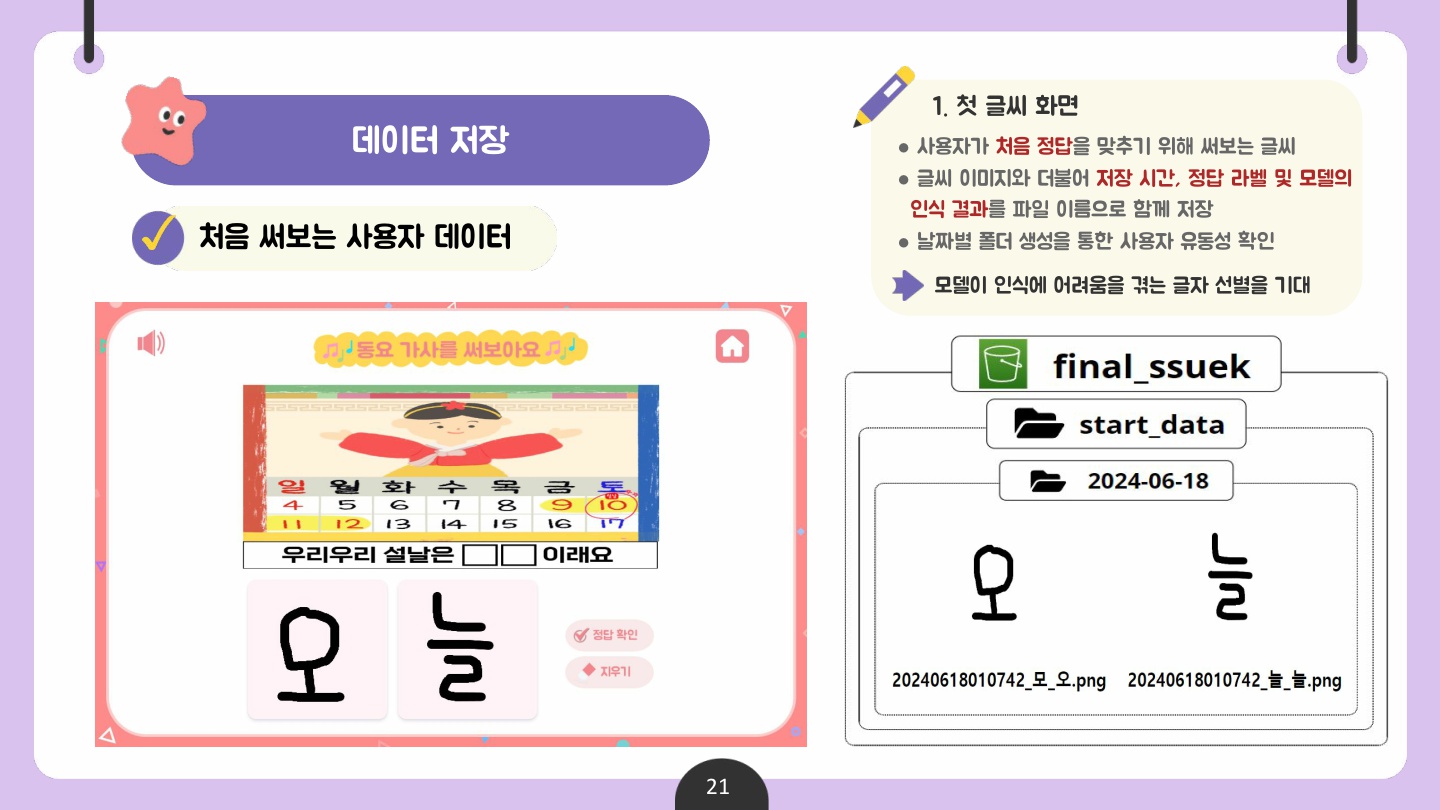
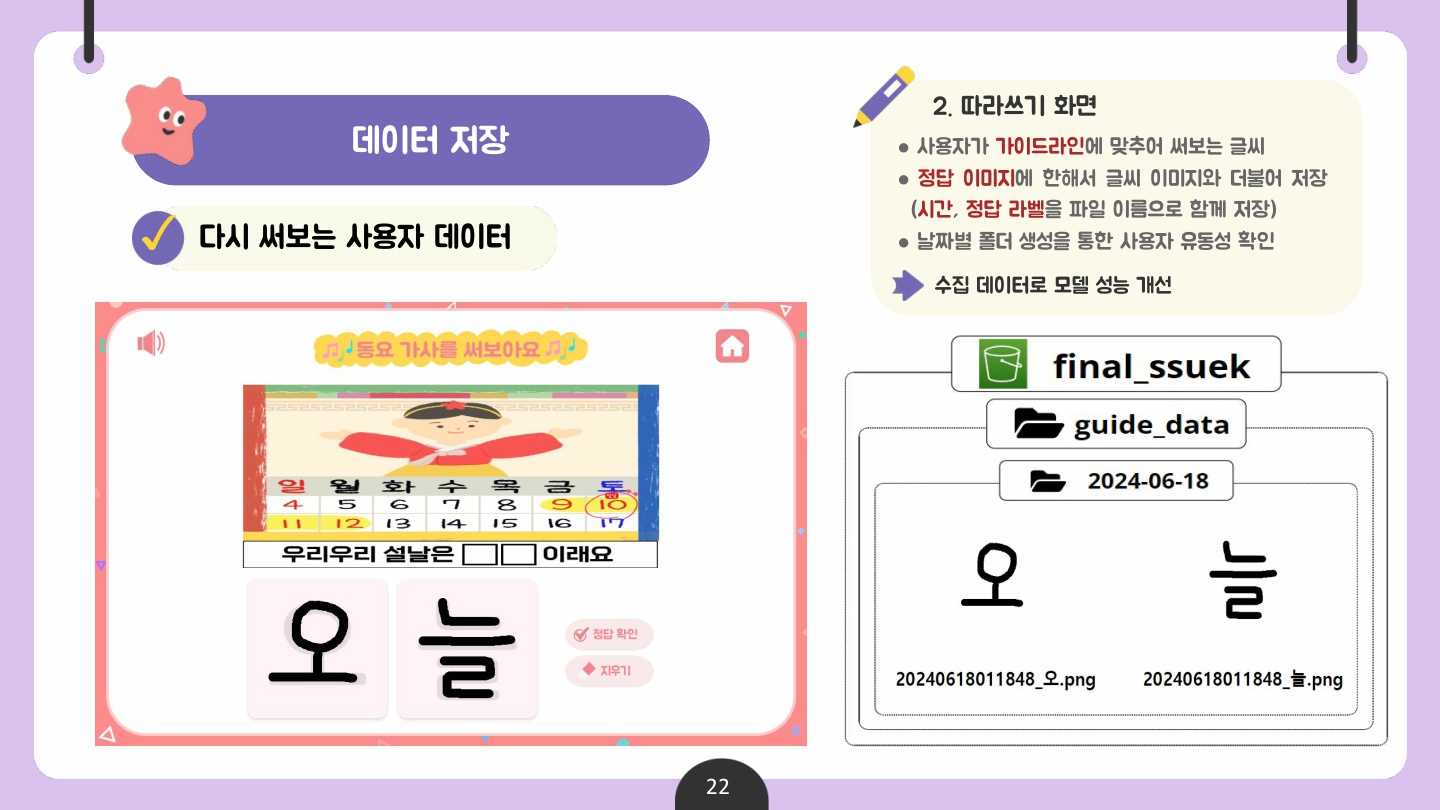
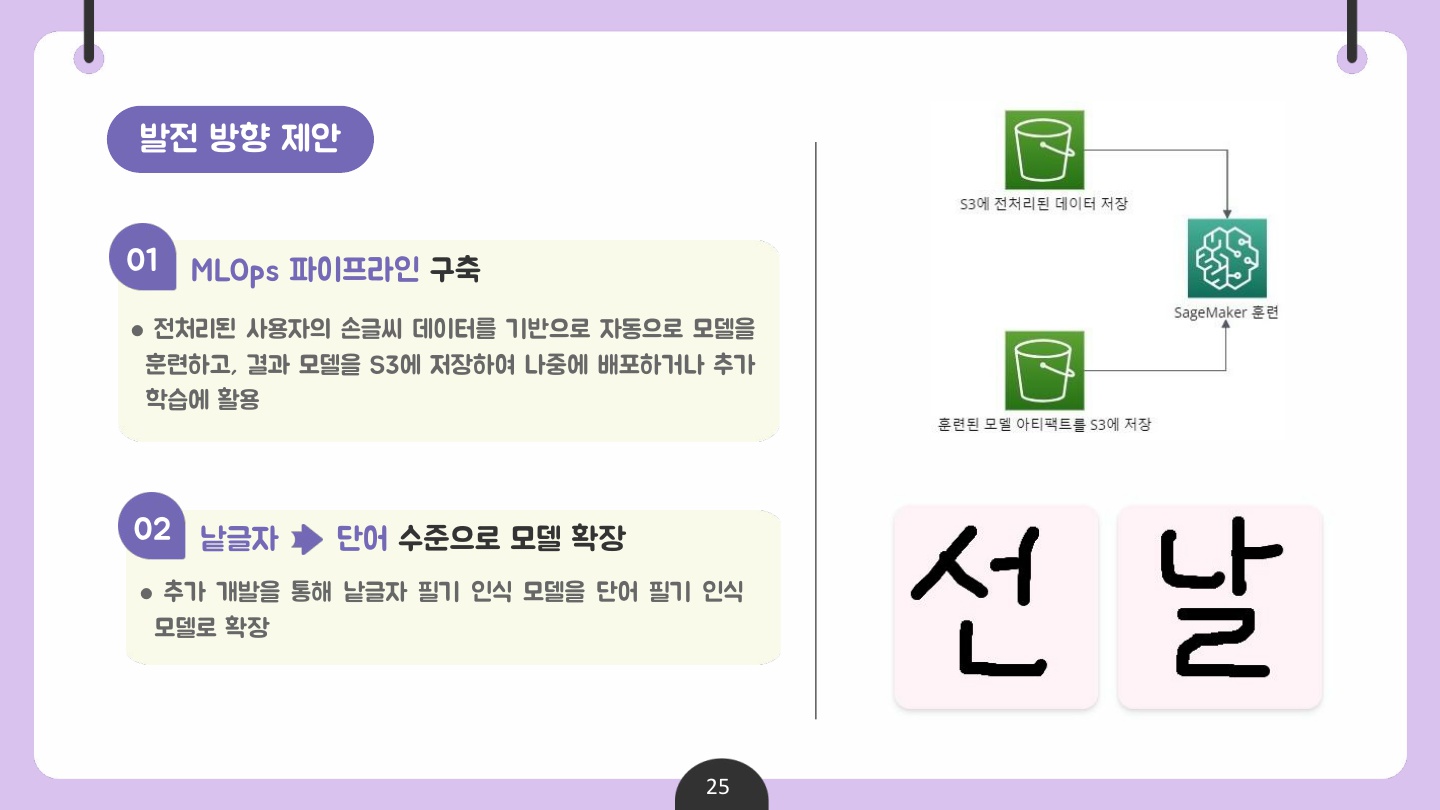
서비스 사용 중에 사용자가 쓴 낱글씨 데이터는 AWS S3에 저장하여 본 서비스뿐만 아니라, 추후 사내 낱글자 필기 인식 모델 추가 학습에 쓰일 수 있기를 기대한다.
📌 데이터 저장 방식 (ERD 대체)
 |  |
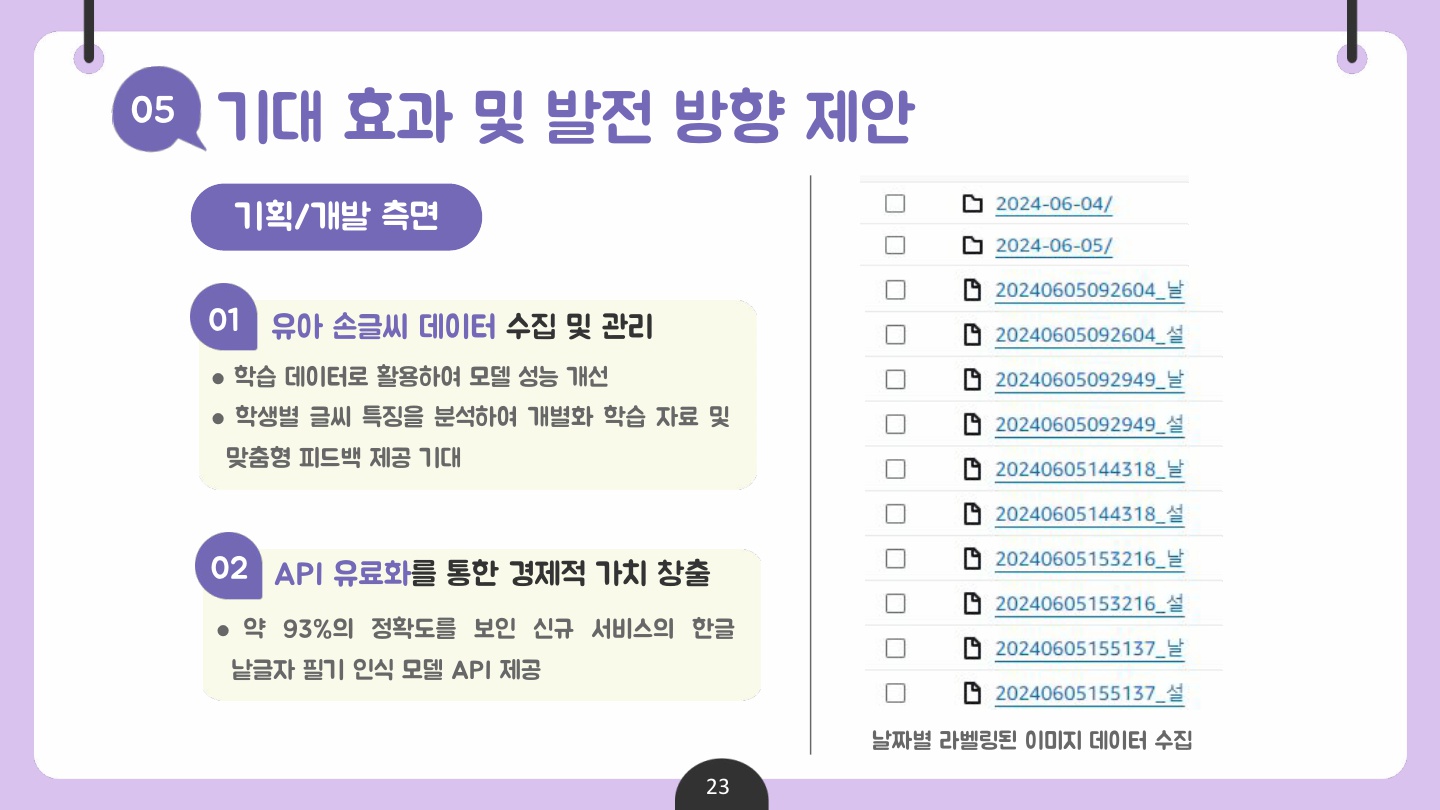
✅ 기대 효과
 |  |
✅ 발전 방향 제안
💡 인사이트 (2024.11 작성)
-
API
개발 노베이스로 공부를 시작한 지 4개월 차부터 시작한 최종 프로젝트, 이 프로젝트를 진행하며 API가 뭔지 처음 알게 되었고 API를 만들기까지 했다. 보통 백엔드가 담당한다는 서버와 데이터베이스 관리는 AI 빅데이터 부트캠프 커리큘럼에도 포함되어 있었다. 그러나 API는 생소했는데, API 또한 백엔드 직무에 포함되어 있다.
백엔드에서 시작하여 데이터사이언티스트로 커리어를 발전시키는 경우가 많은 만큼 데이터사이언티스트는 백엔드로서 알아야 하는 내용은 알고 있어야 한다고 생각한다. 본 프로젝트에서 이렇게 꼭 알아야 하는 API가 뭔지, 왜 필요한지 제대로 알고 직접 설계 및 제작해 볼 수 있어서 얻어가는 게 많은 최종 프로젝트가 될 수 있었다. -
프론트엔드
제안을 주신 부서는 기획 부서였기에 내부에서 돌아가는 것만큼 보여지는 것도 중요한 최종 프로젝트였다. 그래서 부트캠프 커리큘럼에 없었지만 팀원들끼리 프론트엔드(HTML, JS, CSS) 독학을 처음부터 진행하여 완성하였다. AI 빅데이터 부트캠프인데 프론트엔드를 독학하여 프로젝트를 완성해야 한다는 점에 의문을 갖기도 했었다. 그러나 프로젝트 종료 5개월이 지난 현재, 당시 프론트를 조금이라도 맛본 게 귀한 경험이라는 생각이 든다.
최근에는 자바스크립트 라이브러리인 React도 조금씩 공부하고 있다. 데이터사이언티스트가 다양한 직무의 교집합에 위치한 만큼 기본적인 프론트 지식을 갖고 있으면 협업 시 원활한 커뮤니케이션을 이끌어내고 원하는 결과물에 가깝게 완성시킬 수 있겠다는 생각이 든다. -
도커 컴포즈
멘토님이 제안하신 도커 컴포즈 활용 방식을 직접 구현한 점이 뿌듯했다. 본 프로젝트에서는 도커 컴포즈의 힘이 크게 드러나지는 않지만 추후 현업에서 분명 필요한 순간이 있을 것이기에 최종 프로젝트에서 경험해 본 의의가 크다고 생각한다. 도커와 쿠버네티스의 중요성은 교육을 들을 때도 익히 들었는데 현재 직무에서는 사용할 기회가 아직 없었다. 하지만 데이터 사이언티스트로서 반드시 알아야 하는 내용이기에 앞으로도 틈 날 때마다 스터디를 이어가야겠다. -
ERD
본 프로젝트에서는 ERD를 간략히 작성하였고 발표 자료에서는 간단한 구조도로 대체하였다. ERD의 중요성을 실감하고 있는데 ERD를 정말 제대로 작성하는 경우가 현업에서 어느 정도 비중을 작성하는지 궁금하다. ERD를 잘 작성하는 것만으로도 데이터 쪽에서 경쟁력을 지닐 수 있는 것 같다.
최근 VSCode의 'ERD editor'라는 extension을 경험해 보게 됐는데 간단한 그래프 DB부터 ERD 작성까지 간편하고 꽤 체계적이어서 감탄했다. 관련 포스팅도 남겨보아야겠다.
