매일 수없이 업데이트 되는 AI 관련 논문들, 어떻게 팔로업 하고 계신가요?
매일 아침 arXiv에 업데이트된 AI 논문을 자동으로 수집하고 핵심 내용을 요약/번역하여 메일로 보내주는 자동화 시스템을 구축했습니다.
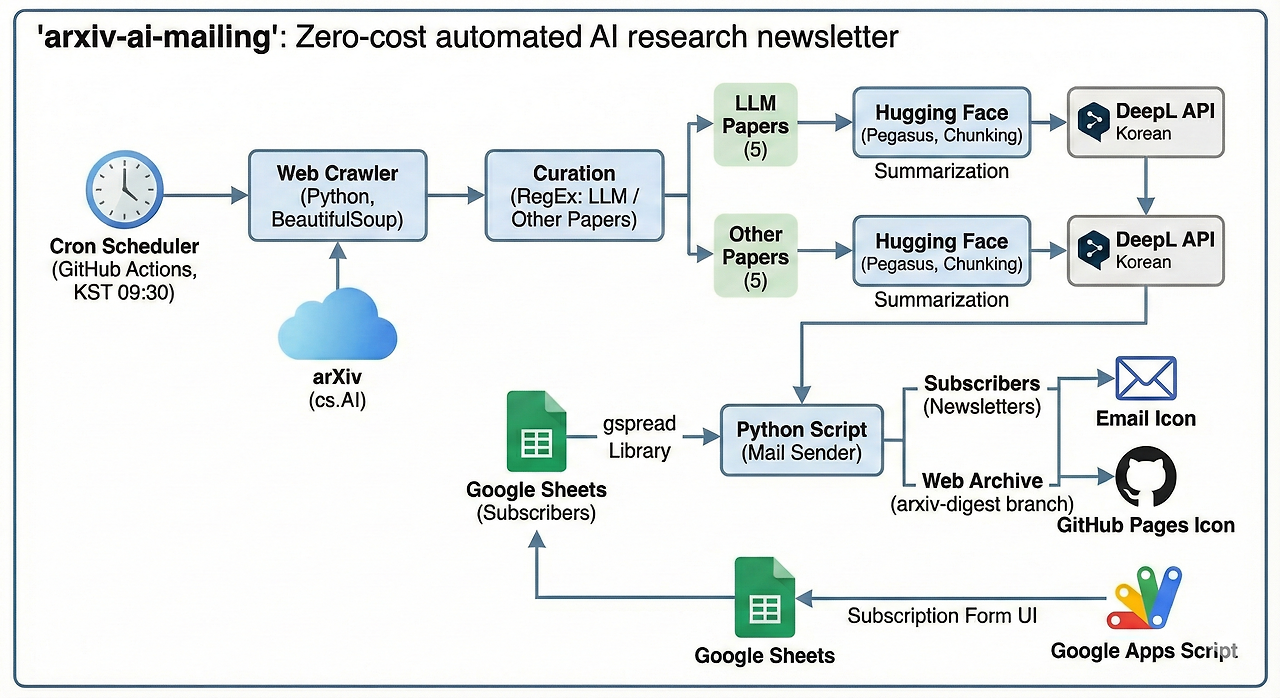
오늘은 이 프로젝트(arxiv-ai-mailing)의 핵심 기술인 크롤링/요약 로직부터 GitHub Actions를 활용한 자동화, 그리고 전 과정을 무료로 실현하기 위한 고민까지 자세히 공유하려 합니다.
목차
💌 뉴스레터 소개
⚙️ 핵심 로직 및 기술 스택 상세 분석
✅ 앞으로의 과제
🌟 마치며
💌 뉴스레터 소개
이 프로젝트의 핵심은 '0원으로 완전 자동화'입니다.
매일 오전 GitHub Actions는 다음과 같은 일을 수행합니다.
- arXiv 탐색: cs.AI 분야의 최신 논문 리스트를 확인합니다.
- 요약: 논문의 초록(Abstract)을 읽고 핵심 내용을 요약합니다.
- 한글 번역: 영문 요약본을 자연스러운 한국어로 번역합니다.
- 메일 발송 : 구독 신청자 이메일로 발송하고, GitHub Pages에 기록을 남깁니다.
결과적으로 매일 오전 뉴스레터를 확인하여 업데이트된 논문을 빠르게 훑고 관심 가는 논문은 전체 리딩을 함으로써 효율적으로 AI 트렌트 파악을 할 수 있게 되었습니다.

⚙️ 핵심 로직 및 기술 스택 상세 분석
① 워크플로우 자동화 : GitHub Actions & Cron으로 무료 서버 구축하기
별도의 서버 비용을 들이지 않기 위해 GitHub Actions를 활용했습니다.
daily-arxiv-digest.yml 설정을 통해 평일(월~금) 아침에 자동으로 스크립트가 실행됩니다.
- 스케줄링 : KST(한국 시간) 기준 오전 9:30부터 30분 간격으로 실행되도록 설정했습니다. ArXiv의 논문 업데이트 시점과 시차를 고려하여, 논문이 확실히 올라온 시점에 데이터를 잡기 위함입니다.
- 중복 실행 방지 : 단순히 시간마다 도는 것이 아니라 check_status 단계를 두어 "오늘 이미 메일을 보냈는지", "오늘 자 데이터가 생성되었는지"를 체크합니다.
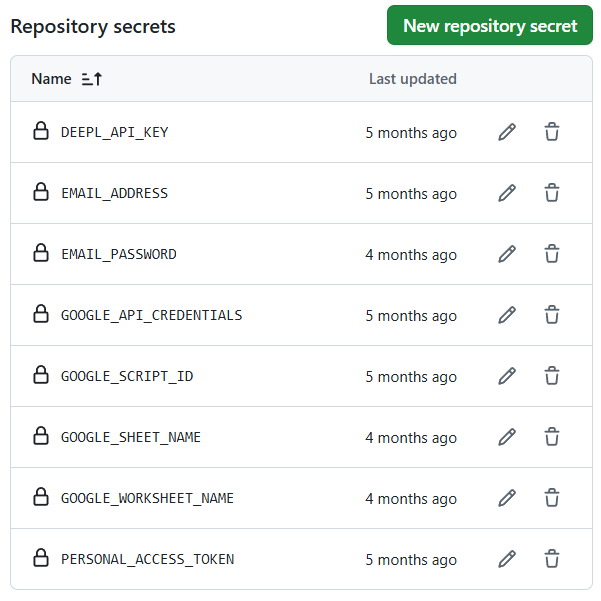
이 작업을 위해서는 Github Secrets 설정이 필요합니다. (Settings ▶️ Secrets and variables ▶️ Actions)
- 구글 연동 : Google_API_CREDENTIALS, GOOGLE_SHEET_NAME, GOOGLE_WORKSHEET_NAME, GOOGLE_SCRIPT_ID
- 이메일 발송 : EMAIL_ADDRESS, EMAIL_PASSWORD
- 번역 : DEEPL_API_KEY
- Github 권한 설정 : PERSONAL_ACCESS_TOKEN
 |  |
|---|
② 데이터 수집 : 맞춤 크롤러 만들기
arXiv는 매일 논문이 업데이트되는데, "정확히 오늘 올라온 논문만" 골라내는 것이 핵심입니다.
- 날짜 섹션 파싱: BeautifulSoup을 이용해 arXiv 리스트 페이지의 날짜 헤더(
<h3>)를 감지하고 해당 날짜 섹션에 속한 논문들만 수집합니다. 이전 날짜가 나오면 즉시 중단합니다. - 초록 수집: 리스트 페이지의 잘린 초록 대신 각 논문의 상세 URL로 진입하여 온전한 전체 텍스트를 가져옵니다.
🚨 RSS 피드가 아닌 크롤링을 선택한 이유
arXiv에서는 분야별로 RSS 피드를 제공하고 있습니다.
관련 내용 ▶️ https://info.arxiv.org/help/rss.html
하지만 이번 프로젝트에서 RSS를 그대로 쓰지 않고 직접 크롤링 로직을 짠 이유는 다음과 같습니다.
- 데이터의 완전성 : RSS 피드는 요약된 정보만 제공하고 있습니다. 저는 전체 초록 데이터가 필요했기에 상세 페이지까지 접근하는 크롤러를 구현했습니다.
- 커스텀 필터링 : RSS는 제공하는 대로 받아야 하지만 크롤러를 이용하면 제가 원하는 시점에 맞춰 '오늘의 논문'을 정확하게 정의할 수 있습니다.
직접 크롤러를 구현하며 웹사이트 구조 분석과 파이프라인 설계 측면에서 많이 공부할 수 있었습니다.
③ 큐레이션 : LLM 논문만 분류하기
AI 분야 중에서도 관심을 가지고 있는 LLM 논문을 별도 섹션으로 보고 싶었습니다. 이를 위해 정규표현식을 활용하여 제목과 초록에 LLM 키워드가 있는지 검사합니다.
④ 요약 및 번역 : Pegasus 모델과 DeepL API로 무료 이용하기
처리 속도와 뉴스레터라는 프로젝트 특성을 고려하여 크롤링 한 논문 중 LLM 논문 5건, 그 외 논문 5건에 대해서만 요약 및 번역을 수행하고 뉴스레터를 발송하고 있습니다. 전체 크롤링 결과는 Github Pages에 적재해 두어 언제든지 다시 확인할 수 있습니다.
🌐 https://2shin0.github.io/arxiv-ai-mailing/
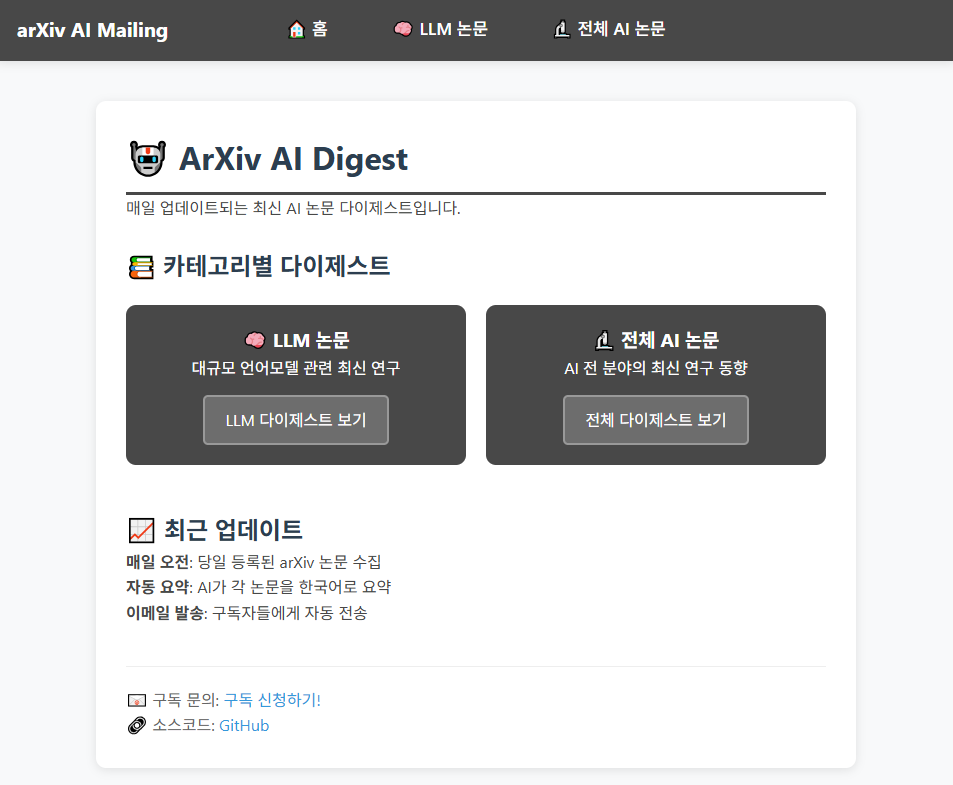
- 요약 모델 (Google Pegasus) : 프로젝트 안정성과 무료 모델을 활용을 위해 GPT, GEMINI API가 아닌 HUGGINGFACE 오픈 소스를 사용했습니다. 논문과 유사하다고 판단한 뉴스 기사 데이터로 학습한 google/pegasus-cnn_dailymail 모델을 활용하여 논문 초록 요약 성능을 향상하고자 했습니다.
- 긴 텍스트 처리 (Chunking): 논문 초록이 모델의 입력 제한(512토큰)을 넘길 경우 텍스트를 잘라(Chunking) 각각 요약한 뒤 합치는 방식을 구현했습니다.
- 고품질 번역 (DeepL API) : 요약된 초록 텍스트는 DeepL API를 통해 자연스러운 한국어로 번역했습니다. DeepL API는 월간 500,000자까지 무료 번역을 제공합니다.
⑤ 구독자 관리 및 UI : Google Sheets와 GAS로 무료 구축하기
개인 프로젝트에서 고민되는 부분 중 하나가 DB 관리와 UI입니다. 이 문제를 Google Sheets와 Google Apps Script로 해결했습니다.
- 파이썬 gspread 라이브러리를 사용해 Google Sheets에 등록된 구독자 이메일 리스트를 recipients 변수로 가져옵니다.
- Google Apps Script로 구독 신청 사이트를 디자인하고 Google Sheets와 연동해 두었습니다.
⑥ 브랜치 전략으로 데이터 관리하기
이 프로젝트에서는 main 브랜치 외에 arxiv-digest라는 별도 브랜치를 만들어 데이터 저장소 및 상태 관리용으로 사용하고 있습니다. 브랜치를 나눈 이유는 다음과 같습니다.
-
Code vs Data 오염 방지 : 매일 생성되는 JSON 데이터와 마크다운 파일이 소스 코드(main)와 섞이면 커밋 히스토리가 매우 지저분해집니다. arxiv-digest 브랜치는 결과물 저장 역할만을 수행합니다.
-
상태 관리 : 오늘 메일을 보냈는가를 확인하는 플래그 파일을 이 브랜치에 저장합니다. GitHub Actions가 실행될 때마다 이 브랜치를 조회하여 중복 발송을 막는 일종의 DB 역할을 수행합니다.
-
배포 자동화 : GitHub Pages 배포 시 완성된 데이터가 있는 arxiv-digest 브랜치의 내용만 깔끔하게 웹으로 띄울 수 있어 관리가 용이합니다.
✅ 앞으로의 과제
① 뉴스레터 형식 개선
현재는 각 논문의 초록을 요약해서 나열하는 방식입니다. 정보를 빠르게 훑기는 좋지만 읽는 재미는 다소 부족합니다. 따라서 단순 요약을 넘어 전체 맥락을 짚어주는 스토리텔링 형식을 도입하려 합니다.
② 구독자수 증가를 고려한 DB 및 이메일 서비스 개선
현재는 소수 인원 대상으로만 운영하고 있기에 Spreadsheet와 SMTP로 운영이 가능합니다. 하지만 상용화된 서비스를 운영하려면 분명한 한계가 있습니다. 이 서비스로 경험할 수는 없겠지만, 서비스 규모가 커질수록 비용 효율적으로 서비스를 운영할 수 있는 방법을 고민하고 그에 따른 개선이 필요할 것입니다.
🌟 마치며
사실 이 프로젝트는 AI 트렌드 캐치업의 효율화를 위해 시작되었습니다.
개인 프로젝트이다 보니 서버나 유료 API 없이 서비스를 구축하고자 했고, 그 과정에서 생각보다 오랜 기간이 소요되기도 했습니다. 프로젝트를 완성하고 나니 많은 걸 배울 수 있었습니다. GitHub Actions, 오픈소스 AI 모델, Google Sheets와 같은 도구들을 연결해 보는 경험과 제한된 리소스 안에서 효율적으로 서비스를 운영하기 위한 코드 최적화 과정은 그 어떤 알고리즘 공부보다 값진 경험이었습니다.
전체 코드는 아래 레포지토리에서 확인하실 수 있습니다.
🔗 https://github.com/2shin0/arxiv-ai-mailing
이슈 제보 및 인사이트 나눔 환영합니다 🙌🏻
