Computer Vision 강의
1. 컴퓨터 비전의 시작
Computer Vision이란?
인공지능의 reference = 인간
Computer Vision = Inverse rendering
Computer Graphics = Rendering
- Machine Learning 과 Deep Learning의 차이
Machine Learning은 사람이 처음부터 직접 feature를 찾아내 필요한 부분은 넣고 필요하지 않는 부분은 빼는, 다시 말하면 처음부터 끝까지 사람이 추출하는 방법임
Deep Learning은 Computer가 처음부터 끝까지 특징을 추출하고 학습하기에 성능이 좋아짐
Image Classification(1) : 개념
Input : 영상
Output : 카테고리, 클래스
K Nearest Neighbors(K-NN) : 최근접 이웃 알고리즘
-> 사용했을 시 좋지만 큰 데이터를 담기에는 힘듦
데이터가 많을 시 시스템 복잡도가 올라감
Convolutional Neural Networks(CNN)
- Fully connected neural networks : 하나의 특징을 뽑아내기 위해 모든 픽셀을 고려
- Local connected neural networks : 하나의 특징을 영상의 공간적인 특징을 활용해서 국부적인 영역만 고려
Alexnet(8 layers)
VGGNet(19layers)
2.컴퓨터 비전과 딥러닝
Data Augmentation
우리가 카메라로 찍은 이미지는 real data가 아님(편향되어 있음)
sampled data와 real data 사이의 gap을 줄이기 위한 노력 = Data Augmentation
Augmentation하는 방법 -> 학습 데이터를 여러 장으로 늘리는 것
ex) 밝기 조절, 뒤집기 등
-
영상 밝기 조절하는 법
-일정 숫자 더해주기 + 이미지가 255를 넘지 않도록 하기
-적당한 값을 곱해주기

-
상하 좌우 바꾸는 법
각도를 넣어줌

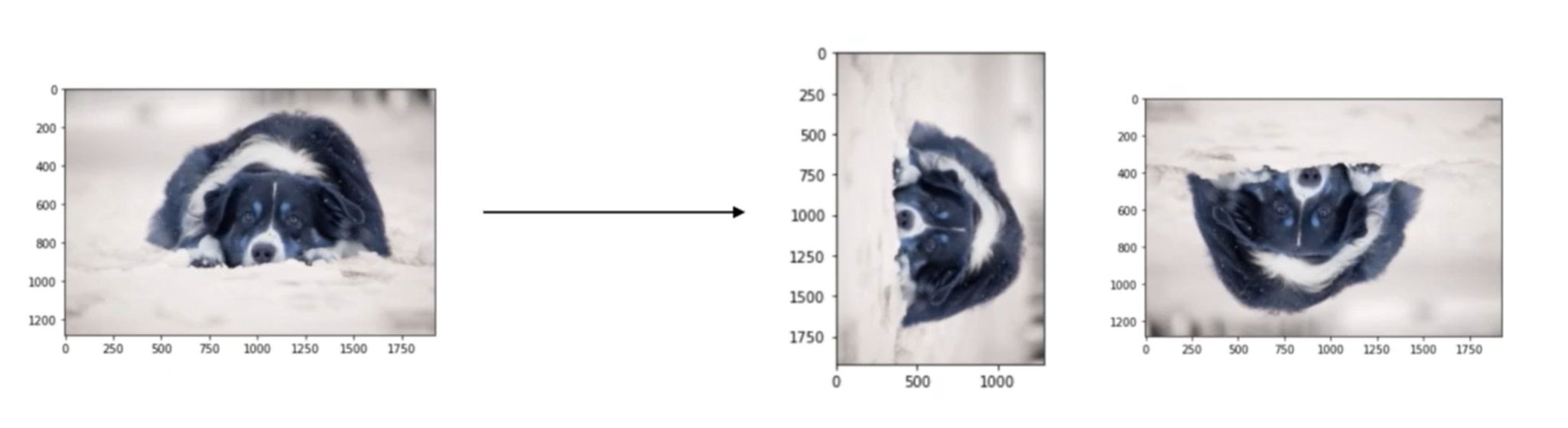
- Crop(중요한 부분을 더 잘 학습할 수 있도록 함)


- Affine transformation
-> 변환 전 후에도 선은 선으로 유지, 길이의 비율 유지, 평행관계 유지
입력 이미지의 3개의 점을 선택하고 변환 후의 점 3개를 선택하여 대응하는 쌍을 만들어 이미지를 변환함(pts1의 점의 위치를 pts2의 점의 위치로 옮긴다고 생각)
getAffineTransform : 6개의 점들과 마지막 행에 0 0 1을 넣은 3X3의 변환행렬이 나옴
warpAffine : 변환행렬을 넘겨줘 이미지를 변환함(영상의 픽셀 위치 옮겨줌)

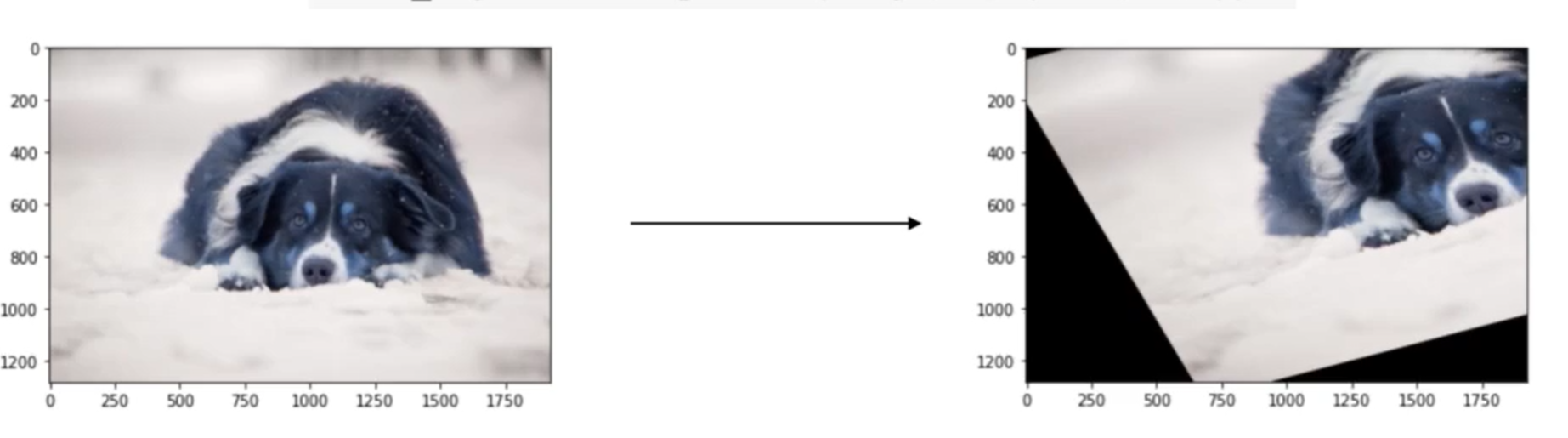
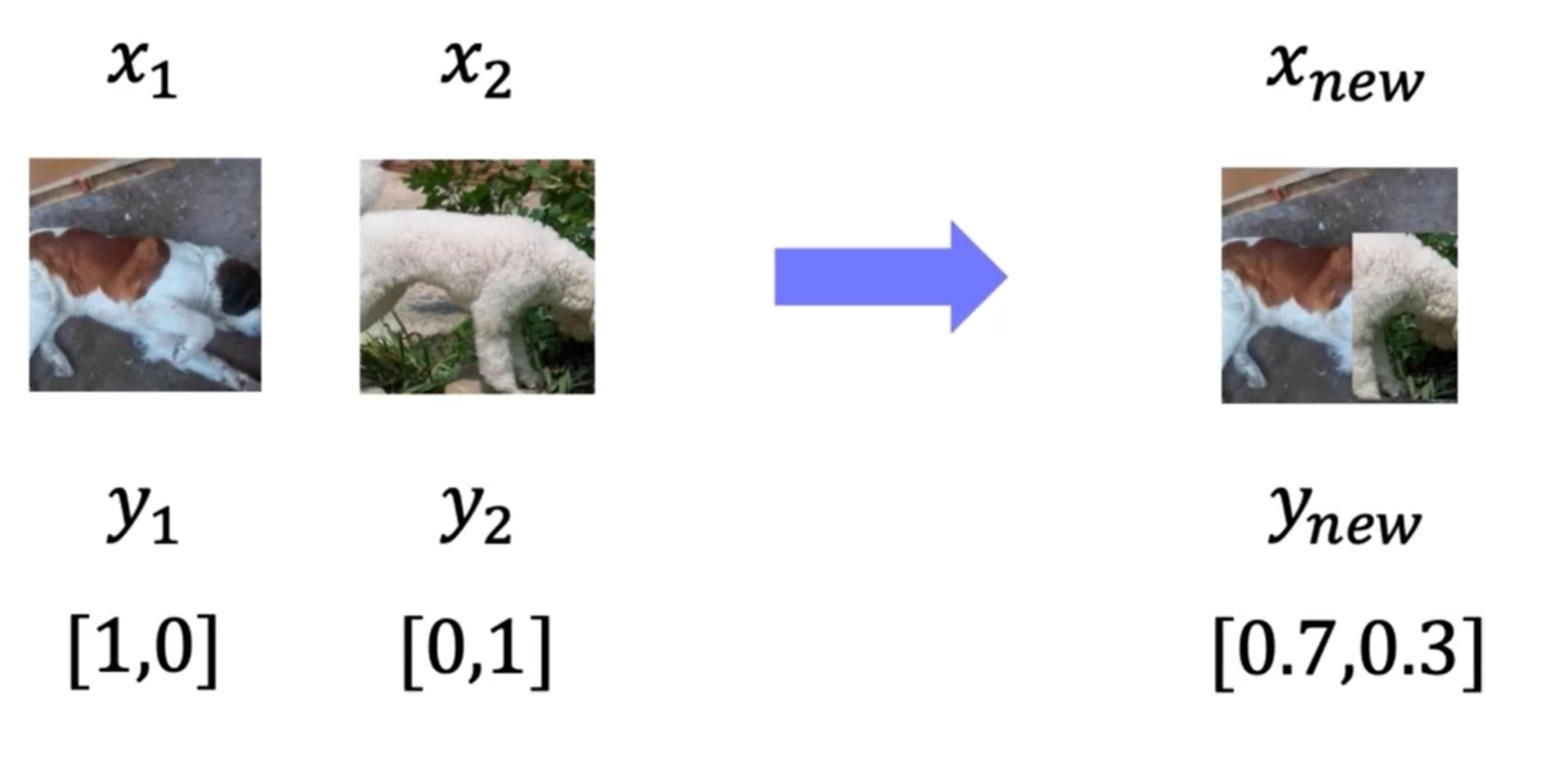
- CutMix
-> 영상의 일부를 잘라 다른 영상에 합성
강아지의 종류가 다르면 label도 비율에 따라 합성해줌
RandAugment : 랜덤하게 augmentations 기법들을 샘플링해서 수행해본 뒤, 성능이 잘 나오는 것을 가져다 쓰는 방법
2개의 parameter
- Which augmentation to apply
- Magnitude of augmentation to apply(how much to augment)
Policy : 하나의 Augmentation기법들의 sequence
Sample a policy : n개의 augmentation의 sequence을 샘플링함
각각의 augmentation에 2개의 파라미터가 있기에 2*N개의 파라미터를 샘플링함
-> 성능 평가
Annotation Efficient Learning
Transfer learning : 미리 학습된 지식을 활용해서 연관된 새로운 태스크에 높은 성능에 도달 가능(한 데이터셋에서 배운 지식을 다른 데이터셋에 적용)
방법 1) Transfer learning
하나의 데이터셋에 미리 학습한 모델을 준비
10개의 카테고리에 대해 미리 학습 -> 마지막 FC layers(Fully Connected Layers)를 잘라내고 새로운 FC layers를 붙임 -> 새로 정의된 100개의 카테고리에 대한 새로운 태스크를 등록 -> 데이터셋에 대해 학습(원래 있던 Convolution layers들은 fix시키고 새로운 FC layers만 업데이트)
학습해야 할 데이터의 양이 줄어듦
데이터가 정말 작을 때 유용
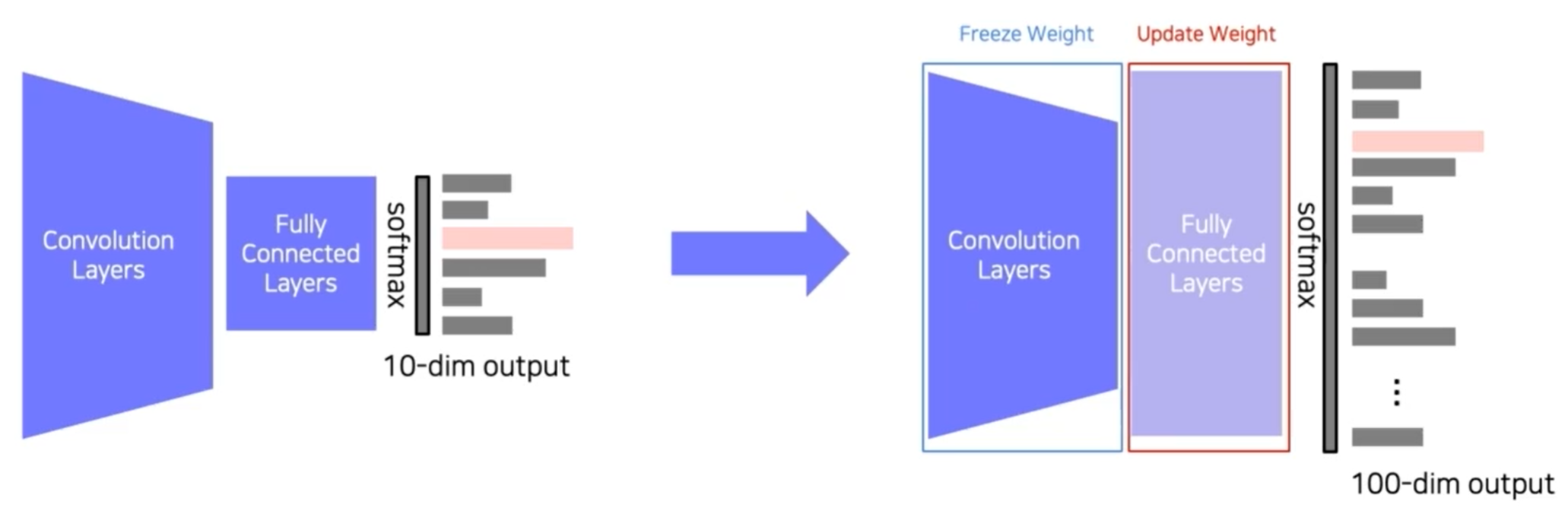
방법 2) Transfer learning
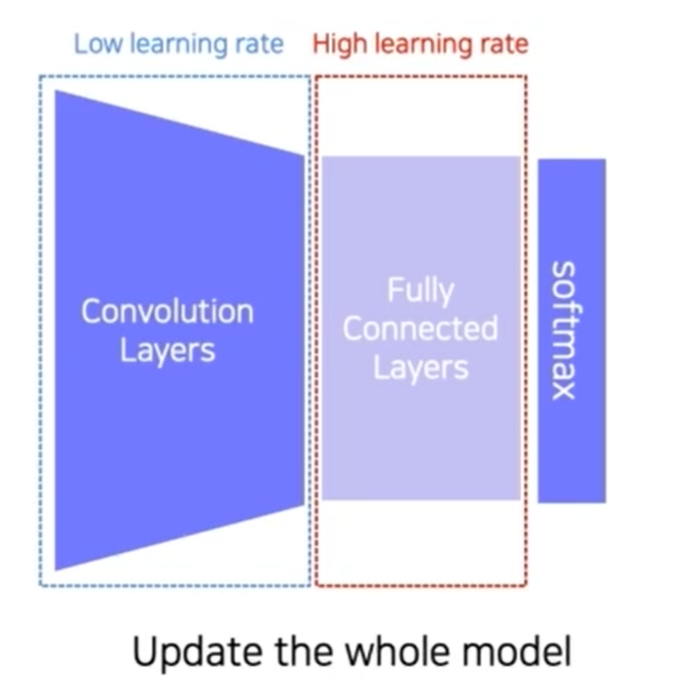
하나의 데이터셋에 미리 학습한 모델을 준비 -> 마지막 layer를 잘라냄 -> 새로운 FC layers를 붙임 -> Convolution Layers를 learning rate를 낮게 잡고 FC layers는 learning rate를 높게 하여 같이 학습함(FC layers의 학습을 더 빠르게 하여 새로운 데이터에 적응을 빨리 할 수 있도록)
방법 1에 비해 성능이 높음
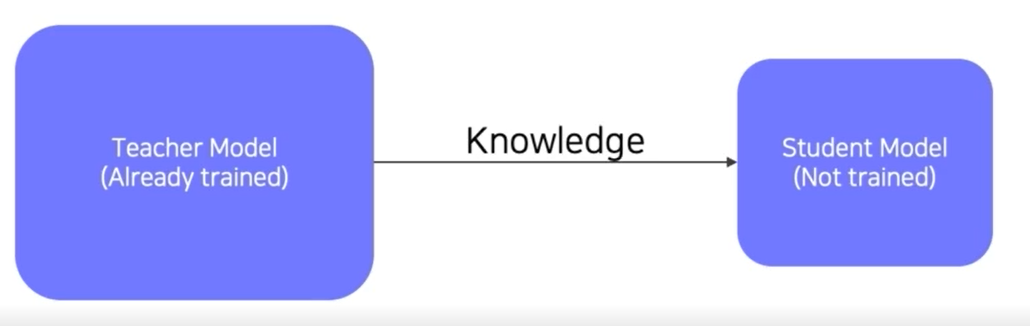
방법 3) Knowledge distillation
이미 학습된 Teacher network의 지식을 작은 모델인 Student model에 주입하여 학습
모델 압축에 유용
Teacher모델에서 나온 출력을 unlabeled 데이터에 pseudo-label로 자동 생성하는데 사용
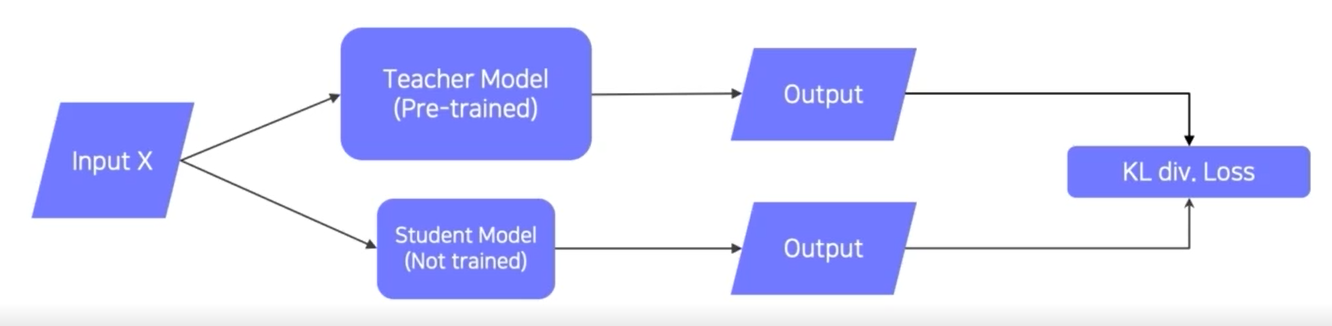
Teacher Model과 Student Model을 준비하고 같은 입력을 넣어 출력을 생성함 -> 출력의 차이를 KL div.Loss를 통해서 측정 -> backpropagation을 사용하여 Student만 업데이트시킴
(Student Model이 Teacher Model의 행동을 따라하게 하는 학습법)
+label을 전혀 사용하지 않아 unsupervise learning이라 생각할 수 있음
임의의 데이터 사용 가능
방법 4) Knowledge distillation
label이 있는 데이터를 가지고 있을 때
Truth label(one-hot)을 사용한 loss = Student loss
Teacher를 따라하게 하는 loss = Distillation loss
Soft Precidtion사용
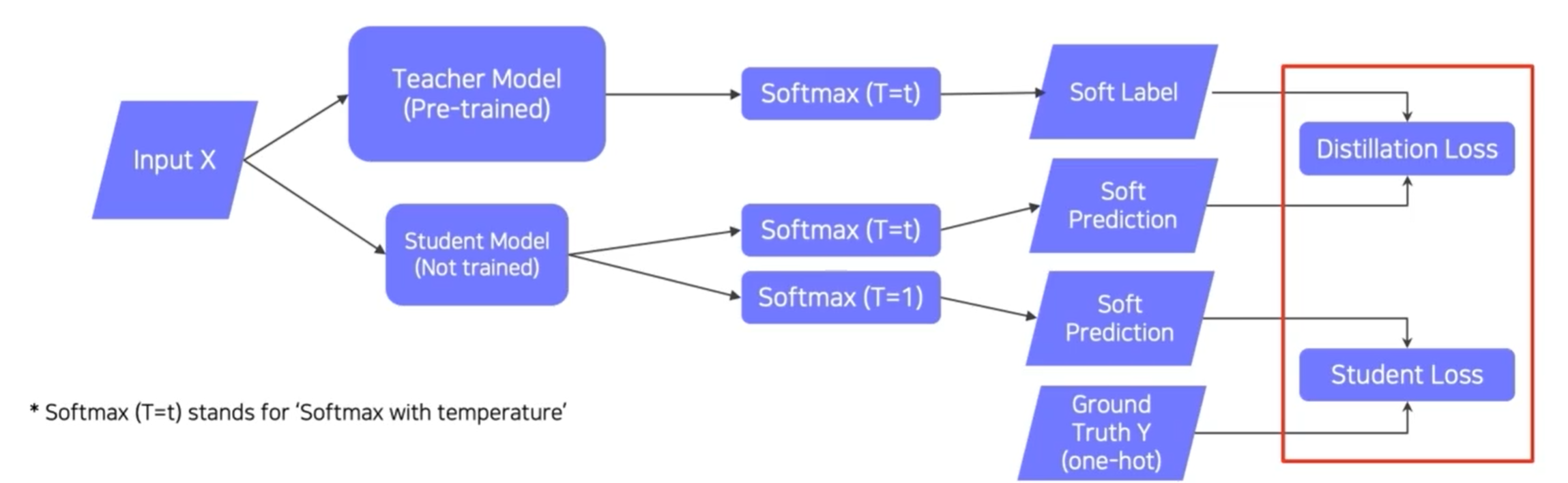
Hard label(One-hot vector)
-> n개의 클래스 중에 정답 레이블은 1개라는 것을 의미하게 하기 위해 one-hot vector 사용(0, 1 로 표시)
Soft label
-> 0과 1 사이의 값으로 표시
Softmax(T=t)에서 T는 Softmax의 출력값이 극단적이지 않게 하기 위해 사용(중간값들로 인해 변화에 더 민감하게 반응할 수 있음)
Teacher model의 soft label과 student의 label은 다를 수 있으나 내부의 element들이 중요한 것이 아닌 Teacher model의 행동 자체를 따라하도록 만드는 것이 중요함
Distillation Loss
- KLdiv(Soft label, Soft prediction) 두 개의 distribution의 차이를 잼
- loss = teacher과 student의 inference 결과의 차이
Student Loss
- CrossEntropy(Hard label, Soft prediction)
- student network's inference와 true label이 일치하도록 하는 것
- 맞는 답을 찾을 수 있도록 학습
두개의 loss의 weighted sum을 통해 학습하고 backpropagation을 하여 student model만 학습
방법 5) Leveraging unlabeld dataset for training
Semi-supervised learning
-> unlabeled dataset + labeled dataset(적은 수의 데이터셋)
labeled dataset로 model이 pretrained함 -> unlabeled dataset의 pseudo-label을 pretrained한 model을 사용해 많이 만듦 -> pseudo-label된 dataset 얻게 됨 -> labeled dataset과 pseudo-labeled dataset을 사용해 model을 re-trained함
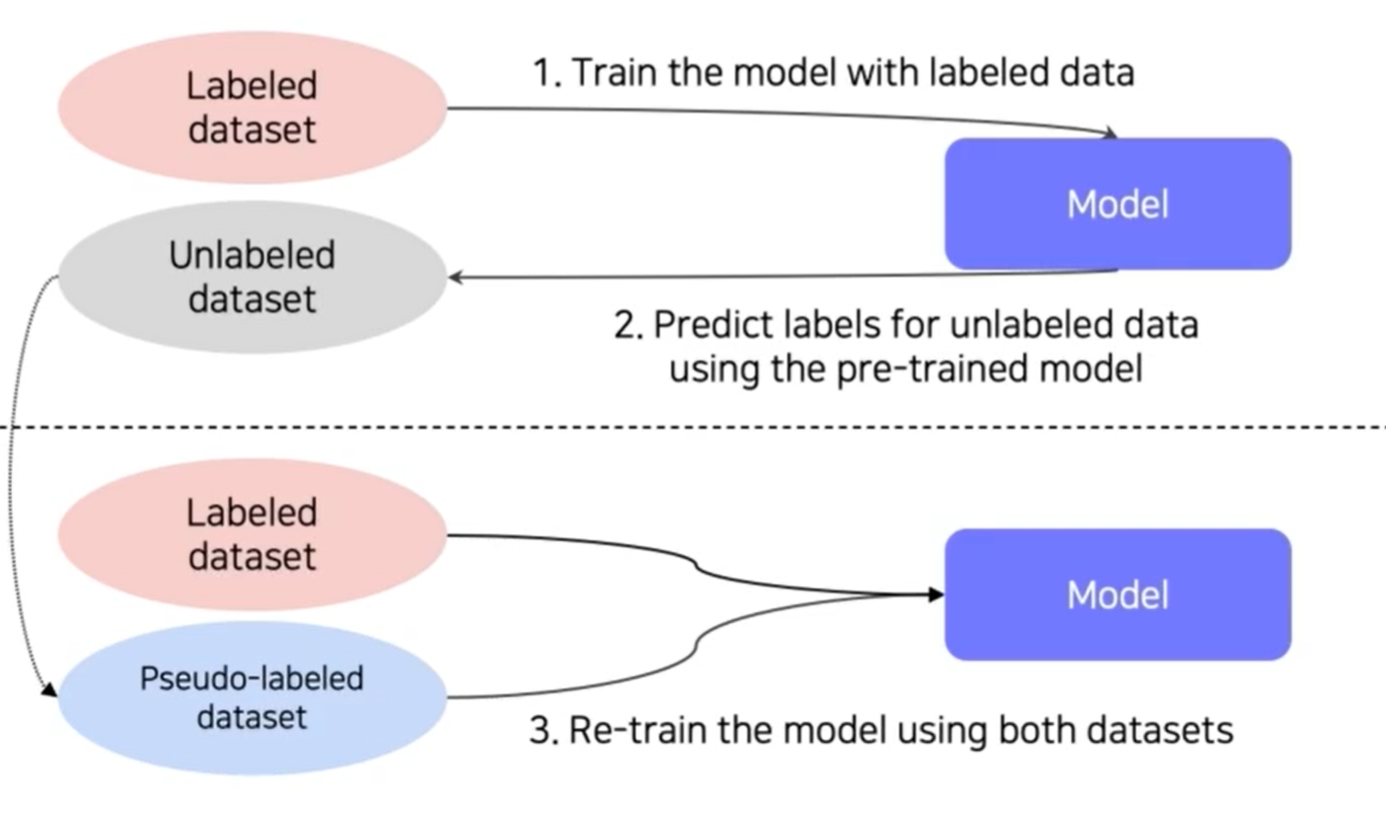
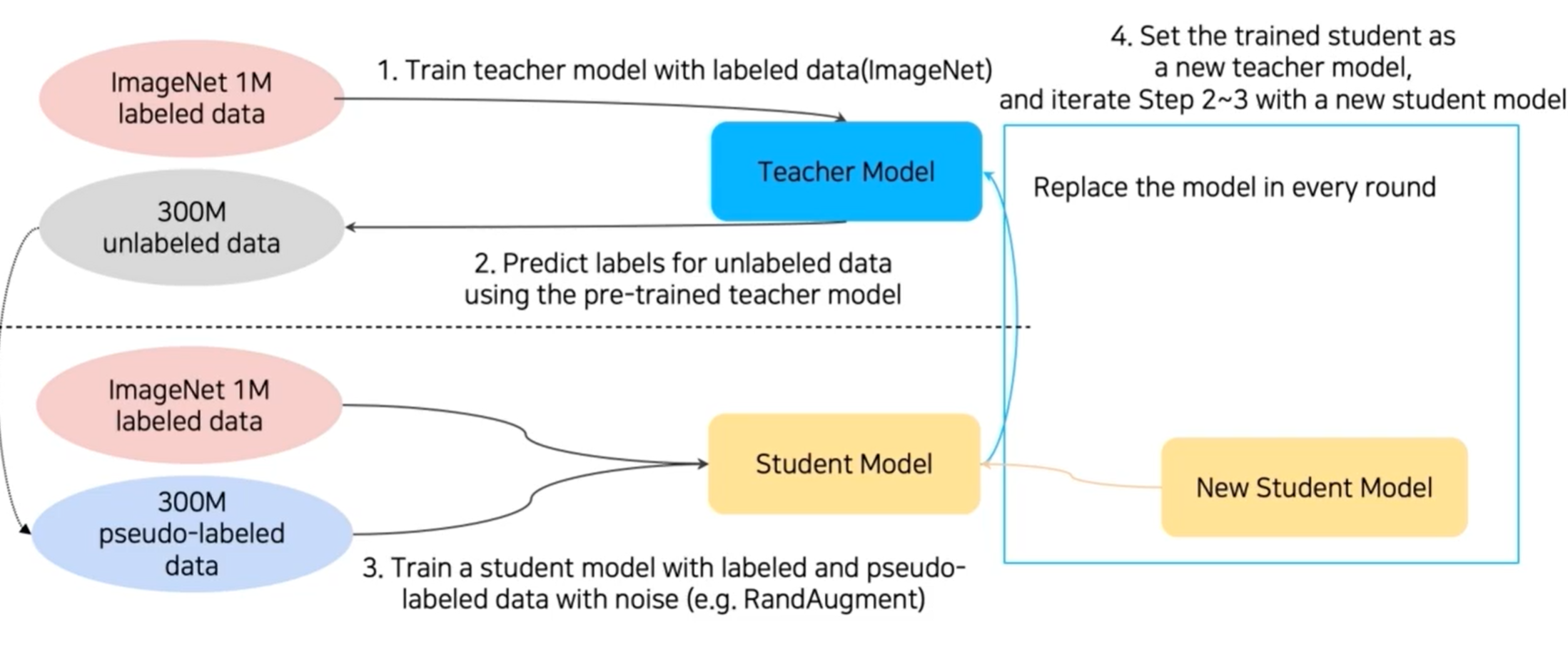
방법 6) Leveraging unlabeld dataset for training
Self-training = Augmentation + Teacher-Student networks + semi-supervised learning
ImageNet labeled data로 Teacher model 학습 -> Teacher model을 사용해 unlabeled data를 pseudo-labeled data로 바꿈 -> 두 개의 data를 합쳐서 Student model을 학습(RandAugment를 사용해서 더 방대한 양의 데이터를 학습) -> Teacher model을 없애고 학습한 Student model을 Teacher model로 하여 다시 unlabeled data를 pseudo-labeled data로 바꿈 -> 새로운 Student model을 도입해 두 개의 data로 다시 학습 -> 반복
Student model은 점점 커지게 됨
자세한 표현
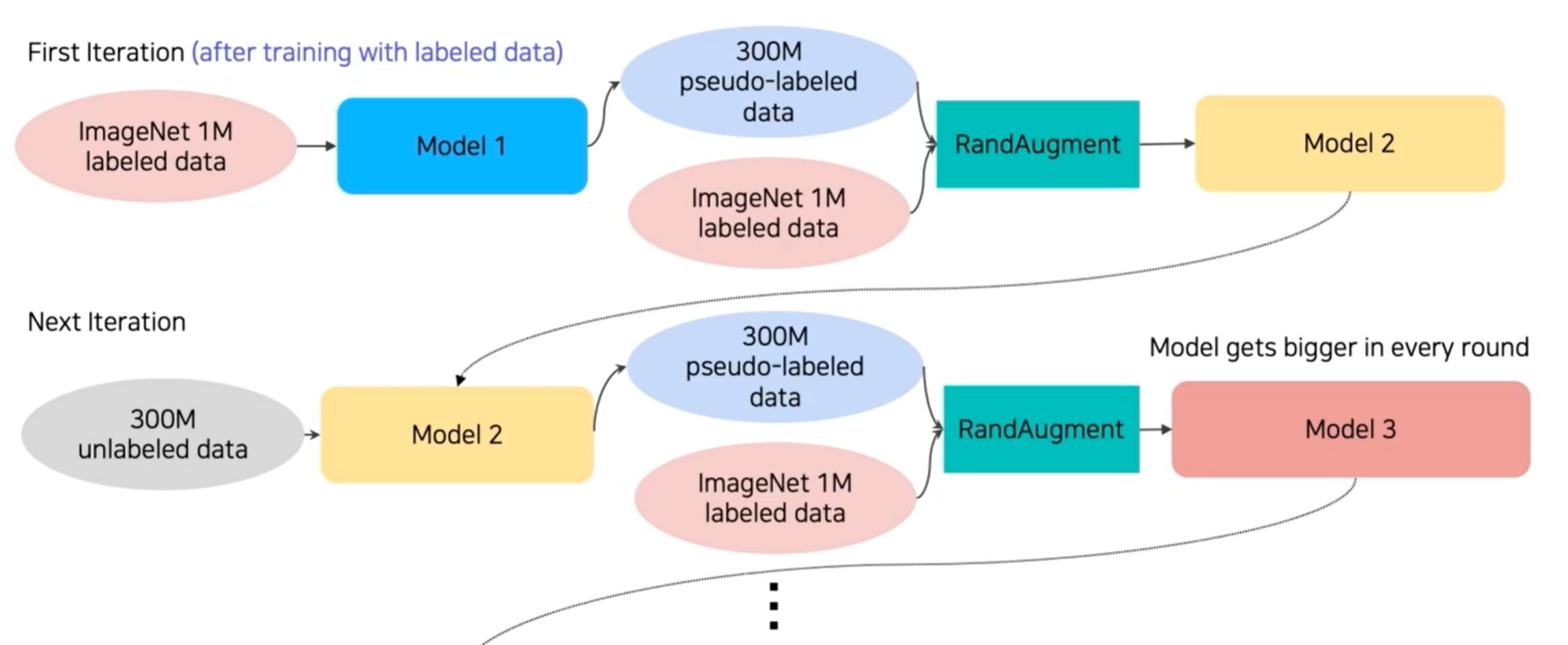
Image Classification
심층 신경망(deep neural networks)에서 레이어가 많아질수록
1.Gradient Explosion이 발생할 가능성이 높아짐. 역전파(backpropagation)를 통해 기울기를 계산하는 과정에서 각 레이어의 기울기 값이 반복적으로 곱해지면서 특정 레이어에서 값이 크게 증폭되는 경우가 발생함. -> 기울기 값이 커짐
2. 또는 기울기의 값이 너무 작아져 Gradient Vanishing이 발생하게 됨.
3. Computationally complex(계산 복잡도가 올라감)
4. Degradation problem(성능 저하 문제)
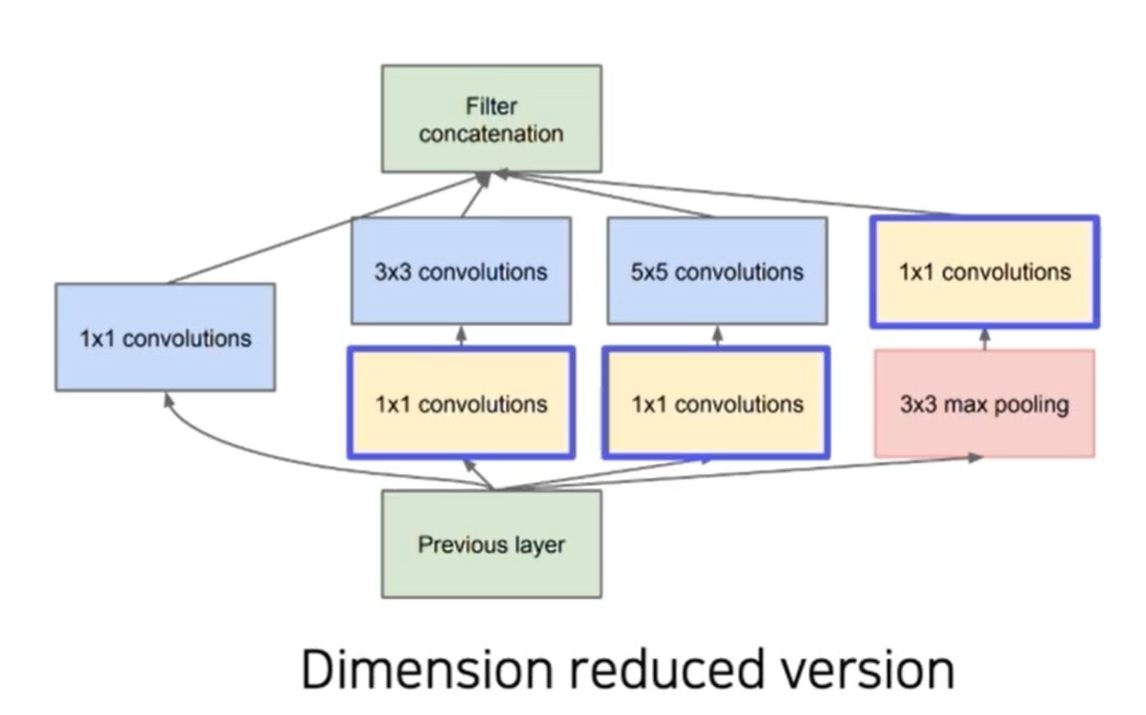
GoogleNet
Inception module
수평 확장(한 층에 여러 필터) -> 계산 복잡도, 용량 커짐 -> 1X1 convolution으로 개선
다른 크기의 convolution에 적용하기 전에 1X1 convolutions을 통해 줄여준 다음, 좀 더 큰 convolutions을 적용함(압축을 하고 연산)
maxpooling(차원을 줄이고 연산량을 줄이는 역할)을 할 때도 1X1 convolution을 통해 channel dimension(데이터의 깊이나 채널 수를 나타내는 차원을 의미)을 바꿈