혼공머신 요약
01 나의 첫 머신러닝
인공지능 : 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
머신러닝 : 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
사이킷런 : 대표적인 머신러닝 라이브러리
딥러닝(인공 신경망) : 머신러닝 알고리즘 중 인공 신경망을 기반으로 한 방법
분류 : 하나를 구별해 내는 문제
이진 분류 : 2개의 클래스 중 하나를 고르는 문제
맷플롯립(matplotlib) : 파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지
-> scatter : matplotlib에서 산점도를 그리는 함수
[ [변수1, 변수2] for 변수1, 변수2 in zip(변수1 리스트, 변수2 리스트) ]
: 변수1리스트와 변수2리스트에서 하나씩 원소를 꺼내오는 역할
[ 변수1, 변수2 ]가 하나의 원소가 되는 리스트를 만듦
k-최근접 이웃 알고리즘 : 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 하는 알고리즘
02 데이터 다루기
머신러닝 알고리즘
- 지도 학습
- 비지도 학습
지도 학습
-> 입력(데이터)와 타깃(정답)이 있음
-> 입력과 타깃을 훈련 데이터라고 함
비지도 학습
-> 타깃 없이 입력 데이터만 사용
훈련 세트 : 훈련에 사용
테스트 세트 : 평가에 사용
샘플링 편향 : 훈련 세트와 테스트 세트가 한쪽으로 골고루 섞이지 않아서 샘플링이 한쪽으로 치우치는 현상
넘파이 : 파이썬의 대표적인 배열 라이브러리
arange : 매개변수로 정수 N을 넘겨주면 0부터 N-1까지 1씩 증가하는 배열을 만듦
random.shuffle : 주어진 배열을 무작위로 섞음
column_stack : 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결
-> 두 개의 일차원 리스트를 매개변수로 받으면 두 일차원 리스트의 원소를 하나의 원소로 하여 이차원 리스트로 만듦
-> 튜플은 수정할 수 없음
np.ones, np.zeros : 매개변수로 정수를 넣으면 그 수만큼의 1., 0.으로 채워진 리스트를 만듦
np.concatenate : 첫 번째 차원을 따라 배열을 연결하는 함수
train_test_split : 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어줌
->train_test_split의 매개변수 : stratify = 타깃 데이터 : 클래스 비율에 맞게 데이터를 나눔
kn.kneighbors : 이웃까지의 거리와 이웃 샘플의 인덱스를 반환(기본값은 5이므로 5개의 이웃이 반환)
xlim((0, 1000)) : x축의 범위를 동일하게 0~1000으로 맞춤
표준점수(z점수) : 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냄
np.mean : 평균
np.std : 표준편차
표준점수 = (데이터 - 평균) / 표준편차
03 회귀 알고리즘과 모델 규제
회귀 : 임의의 어떤 숫자를 예측하는 문제
reshape : 바꾸려는 배열의 크기를 지정
결정계수(R^2) = 1 - (타깃 - 예측)^2의 합 / (타깃 - 타깃의 평균)^2의 합
-> 예측과 평균이 비슷해지면 결정계수는 0에 가까움
-> 예측이 타깃에 비슷해지면 결정계수는 1에 가까움
=> 1에 가까우면 좋은 회귀모델임
mean_absolute_error : 평균 절댓값 오차
과대적합 : 훈련 세트에만 잘 맞는 모델
과소적합 : 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 모델
선형 회귀 : 데이터에 가장 적합한 직선을 찾는 것
다항 회귀 : 다항식을 사용한 선형 회귀
다중 회귀 : 여러 개의 특성을 사용한 선형 회귀
규제 : 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것(과대적합을 막는 것)
-> 선형 회귀 모델의 경우 특성에 곱해지는 계수(또는 기울기)의 크기를 작게 만드는 일
릿지 : 선형 모델의 계수를 작게 만들어 과대적합을 완화
라쏘 : 릿지와 달리 계수 값을 아예 0으로 만들 수 있음
04 다양한 분류 알고리즘
다중 분류 : 타깃 데이터에 2개 이상의 클래스가 포함된 문제
round : 반올림함
확률적 경사 하강법 : 훈련 세트에서 샘플 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 법
에포크 : 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미
SGDClassifier : 확률적 경사 하강법을 사용한 분류 모델
loss : 손실 함수 지정(로지스틱 회귀는 log를 loss로 사용)
penalty : 규제의 종류 지정할 수 있음
max_iter : 에포크 횟수 지정(기본값 1000)
tol : 반복을 멈출 조건
alpha(규제) 높 : 과소
alpha(규제) 낮 : 과대
epoch 높 : 과대
epoch 낮 : 과소
시그모이드 함수 : 선형 방정식의 출력을 0과 1 사이의 값으로 압축하며 이진 분류를 위해 사용
소프트맥스 함수 : 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만듦
predict_proba : 메서드는 예측 확률을 반환
decision_function : 모델이 학습한 선형 방정식의 출력을 반환
05 트리 알고리즘
info() : 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인
describe() : 각 열에 대한 간략한 통계를 출력(최소, 최대, 평균 등)
transform : 입력받은 데이터의 각 특성의 스케일을 조정하여 모델이 각 특성을 공정하게 학습할 수 있도록 함
결정 트리 : 질문을 통해 분류해나가는 방법
=>DecisionTreeClassifier
plot_tree : 결정 트리를 눈으로 확인할 수 있음
매개변수 예시
: dt, max_depth = 1, filled=True, feature_names=['alcohol', 'sugar', 'pH']
max_depth : 루트 노드 제외한 깊이
filled : 양수 클래스와 음수 클래스에 맞게 색칠(어떤 클래스의 비율이 높아지면 색이 진해짐)
feature_names : 특성의 이름을 전달
gini : 지니불순도를 의미, DecisionTreeClassifier의 criterion매개변수의 기본값
지니불순도 계산 : 1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)
지니불순도가 0이면 순수노드
entropy : 엔트로피 불순도
엔트로피 불순도 계산 : -음성 크래스 비율 log2(음성 클래스 비율) - 양성 클래스 비율 log2(양성 클래스 비율)
정보이득 : 부모와 자식 노드 사이의 불순도 차이
특성값의 스케일은 결정 트리 알고리즘에 아무런 영향을 미치지 않기에 표준화 전처리를 할 필요가 없음
featureimportances : 특성 중요도
검증 세트 : 테스트 세트를 제일 마지막에 한 번만 검사하기 위해 사용
교차 검증 : 검증 세트를 너무 조금 떼어 놓으면 검증 점수가 불안정할 것이기에 이를 보안하기 위함, 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복 -> 이 점수들의 평균하여 최종 검증 점수를 얻음
3-폴드 교차 검증 : 휸련 세트를 세 부분으로 나누어 교차 검증을 수행
cross_validate : 교차 검증 함수이고, 첫번째 매개변수에는 모델을, 두번째 매개변수에는 검증 세트를 떼지 않은 훈련 세트를 전달(기본적으로 5폴드 교차 검증 => cv매개변수로 바꿀 수 있음)
=> 회귀 모델일 경우 KFold 분할기, 분류 모델일 경우 타킷 클래스를 골고루 나누기 위해 StratifiedKFold를 사용
모델을 훈련하는 시간(fit_time), 검증하는 시간(score_time), 교차 검증의 최종 점수(test_score)를 의미하는 키 3개를 가진 딕셔너리를 반환함
StratifiedKFold의 매개변수로 n_splits(몇 폴드 교차 검증할지 결정), shuffle, random_state가 있음
그리드 서치(GridSearchCV) : 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행(crossvalidate할 필요 없음)
best_estimator : 검증 점수가 가장 높은 모델의 매개변수 조합을 가리킴
bestparams : 최적의 매개변수
cv_results['mean-test_score'] : 5개의 입력값에 따른 각각의 교차 검증 평균 점수
argmax : 넘파이의 함수로, 인덱스가 가장 큰 값을 추출
랜덤 서치 : 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달
싸이파이(scipy) : 파이썬의 핵심 과학 라이브러리
=> uniform(주어진 범위에서 균등하게 실숫값을 뽑음), randint(주어진 범위에서 균등하게 정수값을 뽑음)클래스 등이 있음
랜덤 포레스트 : 결정 트리가 나무이고 이 결정 트리들의 예측을 사용해 최종 예측을 만드는 것
부트스트랩 샘플 : 전체 훈련세트에서 1개씩 뽑고 다시 넣고 다시 뽑고를 반복하여 중복된 값이 뽑힐 수도 있는 샘플(기본적으로 훈련 세트와 같은 크기)
cross_validate의 매개변수 중 return_train_score를 True로 넘겨주면 검증 점수 뿐 아니라 훈련 세트에 대한 점수도 반환 => 검증 점수와 훈련 세트 점수를 비교하면 과대적합인지 파악할 수 있음(기본값은 False)
OOB샘플 : 부트스트랩 샘플에 포함되지 않은 샘플
=> 검증 세트 역할 할 수 있음
엑스트라 트리(ExtraTreesClassifier) : 랜덤 포레스트와 비슷하지만 엑스트라 트리는 부트스트랩 샘플을 사용하지 않고 전체 훈련 세트를 사용
그레이디언트 부스팅(GradientBoostingClassifier) : 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보안(기본적으로 깊이가 3인 결정 트리 100개 사용)
=> 경사하강법을 사용하여 결정 트리를 앙상블에 추가
- 분류는 로지스틱 손실 함수, 회귀는 평균 제곱 오차 함수
- subsamle은 그레이디언트 부스팅의 매개변수로, 기본값은 1이다. 트리 훈련에 훈련 세트의 비율을 정하는 것으로, 1보다 작게 설정하면 훈련 세트의 일부를 사용
- n_jobs매개변수 없음
히스토그램 기반 그레이디언트 부스팅(HistGradientBoostingClassifier) : 입력 특성을 256개의 구간으로 나눔, 256개의 구간에서 하나를 떼어 놓고 누락된 값을 위해 사용 => 입력에 누락된 특성이 있더라도 전처리를 따로 하지 않아도 됨
- 부스팅 반복 횟수 = max_iter
permutation_importance() : 히스토그램 기반 그레이디언트의 특성 중요도
=> 특성 중요도, 평균, 표준 편차를 줌
XGBoost 라이브러리도 그레이디언트 부스팅 알고리즘을 구현함
=> XGBClassifier를 import하여 tree_method매개변수를 hist로 지정하면 히스토그램 기반 그레이디언트 부스팅 알고리즘을 지원
LightGBM또한 마찬가지로 히스토그램 부스팅 알고리즘 구현 가능한 라이브러리
=> LGBMClassifier를 import하면 됨
06 비지도 학습
비지도 학습 : 타깃이 없을 때 사용하는 알고리즘
np.load : npy파일을 로드하는 메서드
imshow : 이미지를 그릴 수 있음
=> cmap='gray'를 하면 흑백 반전된 이미지를 받을 수 있음, 'gray_r'를 하면 흑백 이미지를 받을 수 있음
mean 함수에서 매개변수 axis=0을 하면 행 방향으로 계산하고 axis=1을 하면 열 방향으로 계산함
hist : 히스토그램을 그리는 메서드
=> alpha는 투명도를 나타낼 수 있으며 1보다 작은 수를 넘겼을 때 투명도를 줄 수 있음
legend : 매개변수로 요소들의 이름을 담은 리스트를 넘겨주면 표를 출력했을 때 구별할 수 있음
subplots : 첫번째 매개변수는 행, 두번째 매개변수는 열을 나타냄, figsize는 이미지의 크기를 나타냄
+ fig, axs 두가지로 subplots의 값을 받는데 fig는 전체 그림을 나타내는 객체, axs는 개별 서브플롯을 나타내는 객체임
bar : 막대그래프 그리는 메서드
abs : 절댓값 계산
argsort : 작은 것부터 순서대로 나열한 배열의 인덱스를 반환
군집 : 비슷한 샘플끼리 그룹으로 모으는 작업
클러스터 : 군집 알고리즘에서 만든 그룹
k-평균 군집 알고리즘 : 평균값을 자동으로 찾아줌
평균값 == 클러스터 중심 == 센트로이드
k-평균 알고리즘 순서
1. 무작위로 k개의 클러스터 중심을 정함
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경
4. 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복
labels : KMeans클래스 객체이며 군집된 결과를 저장, labels배열의 길이는 샘플 개수
+ KMeans의 n_clusters매개변수는 클러스터의 개수를 의미
unique : 중복된 요소 제거하고 고유한 요소로 이루어진 배열
+ unique의 return_counts=True는 각 고유 요소가 몇 개 있는지를 보여줌
클러스터 중심 : KMeans클래스의 clustercenters 속성에 저장
transform : 훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환
niter : 반복된 횟수
엘보우 방법 : 클러스터 개수를 사전에 지정해야 할 때 몇 개의 클러스터가 있는지 모를 경우 사용하는 방법
이너셔 : 클러스터 중심과 클러스터에 속한 샘플 사이의 거리의 제곱 합
클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기에 이너셔도 줄어듦
엘보우 방법은 클러스터 개수를 증가시키면서 이너셔를 그래프로 그리는 것으로 그래프에서 꺾이는 지점이 있음 이 꺾이는 지점이 최적의 클러스터 개수임(꺾여있는 그래프가 팔꿈치와 비슷하다고 해서 엘보우 방법임)
차원 = 특성
+ 1차원 배열(벡터)에서 차원 = 원소의 개수
+ 2차월 배열에서 차원 = 행과 열
+ 다차원에서 차원 = 배열의 축 개수
차원 축소 : 데이터를 가장 잘 나타내는 일부 특성을 선택하여 데이터 크기를 줄이고 지도 학습 모데의 성능을 향상시킬 수 있는 방법 + 차원을 다시 복원도 가능
주성분 분석(PCA) : 대표적인 차원 축소 알고리즘, 데이터에 있는 분산이 큰 방향을 찾는 것
=> 분산이 큰 방향으로 벡터를 그리고 이 벡터를 주성분이라고 부름
주성분은 원본 차원과 같고 주성분으로 바꾼 데이터는 차원이 줄어듦
첫 번째 주성분은 데이터에 가장 잘 맞는 벡터이고 두 번째 주성분은 첫 번째 주성분에 수직이고 분산이 가장 큰 다음 방향을 의미함
+ 일반적으로 주성분은 원본 특성 개수만큼 찾을 수 있음
PCA : sklearn.decomposition 모듈 아래에 있는 클래스로 주성분 분석 알고리즘을 제공
=> ncomponents 매개변수에 주성분의 개수를 지정해야 함
=> components : PCA 클래스가 찾은 주성분을 저장, 배열의 첫 번째 차원은 지정한 주성분의 개수, 두 번째 차원은 원본 데이터의 특성 개수
transform을 사용해서 차원을 줄일 수 있음
inverse_transform은 원본 데이터를 복원할 수 있음
설명된 분산 : 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값
explainedvariance_ratio에 각 주성분의 설명된 분산 비율이 기록되어 있음
=> 모둔 분산 비율을 더하면 총 주성분으로 표현하고 있는 총 분산 비율을 얻을 수 있음
n_components 매개변수에 주성분의 개수 대신 설명된 분산의 비율을 입력할 수도 있음
PCA 클래스는 지정된 비율에 도달할 때까지 자동으로 주성분을 찾음
=> n_components에 0~1 사이의 비율을 실수로 입력
ex) 만약 설명된 분산의 50%에 달하는 주성분을 찾고 싶으면 n_components = 0.5 입력하면 됨
07 딥러닝을 시작합니다
load_data : 훈련 데이터와 테스트 데이터를 나누어 반환
인공 신경망
입력층 : 픽셀값(입력 데이터가 있는 층), x1, ..., x784
출력층 : 클래스(패션 MNIST에서 옷 종류가 있는 층), z1, ..., z10
z = x1 w1 + x2 W2 + ... x784 * w784 + b
w : 가중치
b : 절편
w1.2 : z2를 만들기 위해 x1에 곱해지는 가중치
케라스(keras) : 딥러닝 라이브러리, GPU 사용(벡터, 행렬 연산 최적화)
+ 직접 GPU를 수행하지 않고 GPU를 수행하는 다른 라이브러리(백엔드)를 사용
=> 텐서플로가 케라스의 백엔드 중 하나
인공 신경망에서는 교차 검증을 잘 사용하지 않고 검증 세트를 덜어내 사용함
=> 데이터가 많아 검증 점수 안정적
Dense : 밀집층을 만드는 클래스, 매개변수는 뉴런 개수, 뉴런의 출력에 적용할 함수, 입력의 크기
Sequential : 신경망 모델을 만드는 클래스
compile : 케라스 모델이 훈련하기 전 설정하는 클래스
=> 매개변수로 loss='sparse_categorical_crossentropy'
텐서플로는 정수로 된 타깃을 그대로 사용할 수 있음
sparse_categorical_crossentropy는 정숫값 하나만 사용하는 것을 의미
타깃값을 원-핫 인코딩으로 준비했다면 loss='categorical_crossentropy'로 지정
이진 분류 : 'binary_crossentropy'
다중 분류 : 'categorical_crossentropy'
metrics 매개변수는 정확도를 출력하기 위해 metrics='accuracy'로 지정
이진 분류에서는 출력층의 뉴런이 하나 -> 확률값 a
=> 양성 클래스 = a
음성 클래스 = 1-a
다중 분류에서는 출력층의 뉴런이 여러 개
=> 원-핫 인코딩
샘플이 1번째일 경우, [1, 0, 0, ..., 0] 배열로 만들어서 확률값 [a1, a2, ..., a10]과 곱하여 1번째 샘플의 값만 남기고 나머지는 다 0이 되게 함
활성화 함수 : 소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수
은닉층 : 입력층과 출력층 사이에 있는 모든 층
출력층에 적용하는 활성화 함수는 종류가 제한되어 있음
- 이진 분류 => 시그모이드 함수
- 다중 분류 => 소프트맥스 함수
+ 은닉층의 활성화 함수는 비교적 자유로움 => 대표적으로 시그모이드 함수, 볼 렐루 함수 등
분류 문제에서는 클래스에 대한 확률값을 얻기 위해 활성화 함수를 사용
회귀 문제의 출력은 임의의 어떤 수이기에 활성화 함수 적용할 필요 없음
회귀 문제는 계산 그대로 출력함 => Dense 층의 activation에 아무런 값도 지정 안함
은닉층에서 선형적인 산술계산은 은닉층의 수행이 의미 없어지는 셈
=> 은닉층의 선형 계산을 비선형적으로 비틀어 주어야 함
모든 신경망의 은닉층에는 항상 활성화 함수가 있음
keras에서 신경망의 첫 번째 층은 input_shape 매개변수로 입력의 크기를 반드시 지정해야 함
keras.layers.Dense(뉴런 개수, activation='활성화 함수', input_shape(입력의 크기, ))
=> 뉴런의 개수는 정해지지 않았지만 출력층의 뉴런 개수보다 은닉층의 뉴런 개수가 더 많아야 함
summary : 층에 대한 정보 출력
케라스 모델의 fit메서드는 데이터를 잘게 나누어 여러 번에 걸쳐 경사 하강법 수행
= 미니배치 경사 하강법
미니배치 경사 하강법 : 기본 크기는 32개이고 batch_size 매개변수로 바꿀 수 있음
샘플 개수를 고정하지 않고 None으로 설정하면 어떤 배치 크기에도 유연하게 대응할 수 있음
+ 신경망 층에 입력 or 출력되는 배열의 첫 번째 차원을 배치 차원이라 함
모델 파라미터 개수는 입력 픽셀 784개와 100개의 은닉층의 모든 조합 + 뉴런마다 1개씩 있는 절편을 더한 값 => 784 * 100 + 100 = 78500개
add : sequential은 층을 추가할 수 없음 이때 사용되는 메서드
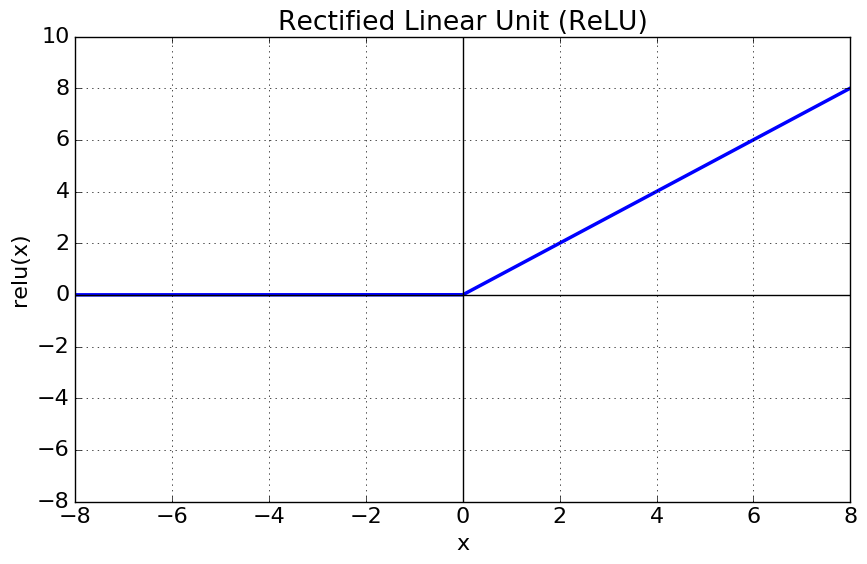
렐루 함수(max(0, z)) : 입력이 양수일 경우 그냥 입력을 통과시키고 음수일 경우 0으로 만듦
Flatten : 배치차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할
=> 가중치, 절편 없음 -> 인공 신경망의 성능을 위한 기여 안함
=> 입력층 바로 뒤에 추가
=> reshape할 필요 없음
=> 입력값의 차원을 짐작할 수 있음
옵티마이저 : 예측값과 결과값 사이의 차이를 줄이기 위해 조정하는 값
확률적 경사 하강법(SGD)의 학습률을 바꾸고 싶다면 learning_rate 매개변수를 사용하면 됨
SGD클래스 매개변수
momentum 매개변수 : 기본값 0, 0보다 큰 값으로 지정하면 이전의 그레이디언트를 가속도처럼 사용하는 모멘터머 최적화 사용, 보통 0.9이상 적용
nesterov 매개변수 : 기본값 False, True로 바꾸면 네스테로프 모멘텀 최적화(모멘텀 최적화 2번 반복)를 사용
적응적 학습률 : 모델이 최적점에 가까워질수록 낮아지는 학습률로, 대표적인 옵티마이저는 Adagrad, RMSprop, Adam가 있음
케라스의 fit메서드는 History클래스 객체를 반환함
History는 훈련과정에서의 계산한 지표(혼공머신의 코드상 손실과 정확도를 의미)가 저장됨
fit메서드의 결과를 변수에 담으면 변수에 history 딕셔너리가 담기게 되고 history 딕셔너리는 손실과 정확도를 순서대로 가지고 있는 단순한 리스트임
손실과 정확도에 대한 그래프를 그릴 수 있음
에포크가 늘어날수록 손실은 낮아지고 정확도는 올라감
=>과대적합이 된 것일 수 있음
fit메서드에서 validation_data=(val_scaled, val_target)을 넣어 검증 세트를 전달함
훈련 세트와 검증 세트의 손실을 한 그래프로 그려내면 검증 세트의 손실이 떨어졌다가 다시 올라가는 것을 확인할 수 있음 => 과대적합
optimizer=Adam으로 다시 검사 => 아까보단 덜 과대적합이지만 여전히 과대적합
드롭아웃 : 층에 있는 일부 뉴런의 출력을 0으로 만드는 것
=> 몇 개의 뉴런을 드롭할 지는 하이퍼파라미터임
=> 어떤 샘플을 처리할 때는 h1을 드롭하고 또 다른 샘플을 처리할 때는 h2를 드롭하는 등 랜덤하게 뉴런이 드롭아웃됨
=> 앙상블(여러 개의 모델을 훈련)과 같은 효과로 과대적합을 막을 수 있음
드롭아웃 객체를 model_fn(모델을 만들고 인수가 있으면 모델에 층을 더하는 함수(직접 구현))에 넘겨 층을 추가함
드롭아웃은 훈련되는 모델 파라미터가 없고 입력과 출력의 크기에도 변화를 주지 않음(전체 출력 배열의 크기를 바꾸지는 않음)
훈련이 끝난 뒤, 평가나 예측을 할 때는 드롭아웃을 적용하면 안됨 텐서플로와 케라스는 평가나 예측을 할 때 자동으로 드롭아웃을 하지 않아서 층을 없앨 필요 없음
save_weights : 훈련된 모델의 파라미터를 저장하는 메서드
save : 모델 구조와 모델의 파라미터를 함께 저장하는 메서드
load_weights : 저장된 모델 파라미터를 적재하는 메서드
evaluate : 손실을 계산하기 위해 반드시 먼저 compile메서드를 실행해야 함
load_model : 모델에 저장된 파일을 읽을 때 사용
콜백 : 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체
fit메서드에서 callbacks 매개변수에 리스트로 전달함
ModelCheckpoint : 에포크마다 모델을 저장함, save_best_only=True 매개변수는 최상의 검증 점수를 낸 모델을 저장함
load_model을 사용해 최상의 검증 점수를 낸 모델을 읽어서 수행
조기 종료 : 검증 점수가 상승하기 시작하면 과대적합이 커지기 때문에 과대적합이 되기 전에 훈련을 미리 중지하는 것
EarlyStopping : 콜백으로, 조기 종료할 수 있음, patience 매개변수는 검증 점수가 향상되지 않더라도 참을 에포크 횟수로 지정(patience=2 => 2번 연속 검증 점수가 향상되지 않을 시 훈련 중지)
restore_best_weights : True로 지정하면 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌림
early_stopping_cb 객체의 stopped_epoch 속성 : 몇 번째 에포크에서 훈련이 중지되었는지 알 수 있음
