PNP AI 공부(3)
04-1 로지스틱 회귀
 CSV파일을 데이터프레임으로 변환한 다음 head()메서드로 처음 5개 행을 출력한다.
CSV파일을 데이터프레임으로 변환한 다음 head()메서드로 처음 5개 행을 출력한다.
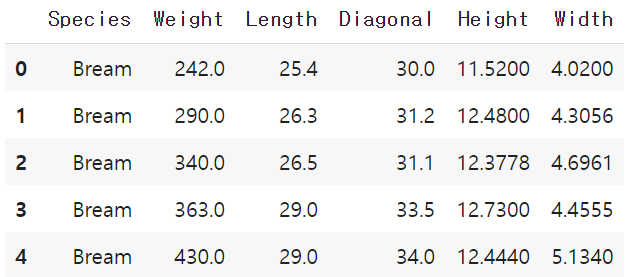 출력하면 왼쪽에는 행 번호(인덱스)가 자동으로 나오고 판다스는 CSV 파일의 첫 줄을 자동으로 인식해 열 제목으로 만들어 준다.
출력하면 왼쪽에는 행 번호(인덱스)가 자동으로 나오고 판다스는 CSV 파일의 첫 줄을 자동으로 인식해 열 제목으로 만들어 준다.
- 판다스 unique()함수는 지정한 열에서 고유한 값을 추출할 수 있는 함수이다.
다중 분류는 타깃 데이터에 2개 이상의 클래스가 포함된 문제이다.- 사이킷런에서는 문자열로 된 타깃값을 그대로 사용할 수 있고 모델을 사이킷런 모델에 전달하면 알파벳 순으로 순서가 매겨진다. 이렇게 매겨진 타깃값들은 classes속성에 저장되어 있다. predict_proba()메서드는 클래스별 확률값을 반환한다. 이때 출력 순서는 classes속성과 같다.
- round()함수는 기본으로 소수점 첫째 자리에서 반올림을 하는데 decimals매개변수로 소수점을 지정할 수 있다.
- predict_proba()함수를 사용해 확률값을 출력하면 5행7열의 2차원 리스트가 출력된다. 여기서 행은 샘플이고 열은 각각의 클래스에 대한 확률을 나타낸다. 예를 들어 1행1열은 첫 번째 샘플이 첫 번째 클래스일 확률을 나타낸 것이다.
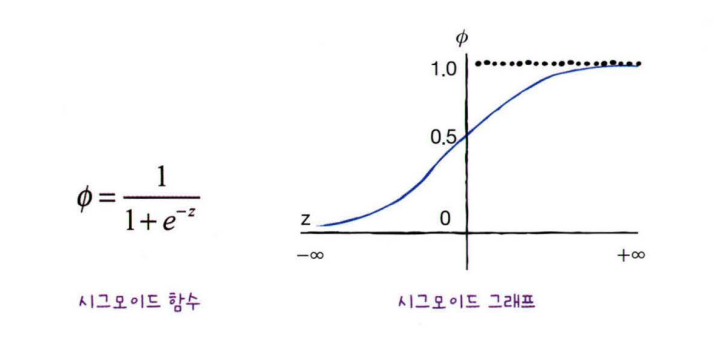
- 로지스틱 회귀는 시그모이드 함수를 사용해 0~1 사이의 값으로 만들어 0.5보다 크면 양성, 0.5보다 작으면 음성으로 분류하는 분류 모델이다.
- np.exp()는 지수 함수 계산을 하는 함수이다.
 로지스틱 회귀는 LogisticRegression클래스로 만들 수 있다. 넘파이 배열은 True, False로 값을 전달하여 행을 선택할 수 있는데 이를 불리언 인덱싱이라고 한다.
로지스틱 회귀는 LogisticRegression클래스로 만들 수 있다. 넘파이 배열은 True, False로 값을 전달하여 행을 선택할 수 있는데 이를 불리언 인덱싱이라고 한다.

이렇게 원하는 행만 전달하면 이진 분류에 필요한 데이터만 고를 수 있다.
도미와 빙어의 데이터만 가진 배열을 만들 수 있다.
- 이진 분류일 경우에는 시그모이드 함수의 출력이 0.5보다 크면 양성 클래스, 0.5보다 작으면 음성 클래스로 판단한다.
LogisticRegression 객체를 만들고 훈련 세트로 훈련을 한 뒤 predict()함수를 사용해 처음 5개의 샘플을 예측한다.

predictproba()함수를 사용해 예측 확률을 출력한다.

행은 각각의 샘플들이고 1열은 음성(도미)이고 2열은 양성(빙어)이다. 알파벳 순서이기 때문에 도미가 먼저이다. coef, intercept_로 계수를 확인하고 z값을 구한다. 특성이 5개이기 때문에 총 6개의 계수가 나온다.
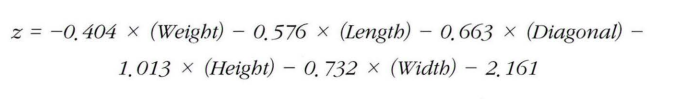
이러한 z값은 decision_function()메서드로 출력할 수 있다. decision_function()메서드의 매개변수로 위에서 도미와 빙어의 데이터만 받은 배열을 5번째 값까지로 해서 넘겨주면 5개의 z값을 출력할 수 있다. - expit는 z값을 시그모이드 함수에 통과시켜 확률을 얻게 하는 함수이다.
expit()메서드로 얻은 값은 predict_proba()메서드로 출력한 2번째 열의 값과 동일하다. 이 말은 즉 decision_function()메서드는 양성 클래스에 대한 z값을 반환한다는 것을 알 수 있다.
다중 분류
그렇다면 다중 분류는 어떻게 하는지 알아보자.
LogisticRegression클래스의 maxiter 매개변수는 반복 횟수를 지정하고 기본값은 100이다. 또한 LogisticRegression클래스는 계수의 제곱을 규제하는데 규제를 제어하는 매개변수는 C이다. C는 alpha와 반대로 작을수록 규제가 커진다. 기본값은 1이다.
다중 분류도 이진 분류과 같이 fit()메서드와 score()메서드를 사용해 훈련하고 predict()메서드를 사용해 예측값을 출력한다. 그리고 predict_proba()메서드로 확률을 출력하는데 5행 7열로 각각의 샘플이 행이고 각각의 클래스가 열이 된다. 이진 분류의 경우 2개의 열(도미, 빙어)만 있었는데 다중 분류는 7개의 열이 있다. 여기서도 클래스는 마찬가지로 알파벳 순서이다.
계수의 크기를 보기 위해 shape함수를 써서 coef와 intercept_의 크기를 보면 (7,5) (7,)이라고 나온다. 이는 즉 7개의 선형함수가 있음을 말하고 여기서 7개의 선형함수를 각각의 샘플이 다 통과해 나온 값중 가장 큰 값이 예측 클래스가 되는 것이다. 이진 분류는 시그모이드 함수를 사용해 z값을 0에서 1사이의 값으로 변환했다면 다중 분류는 소프트맥스 함수(정규화된 지수 함수)를 사용하여 7개의 z값을 확률로 변환한다.
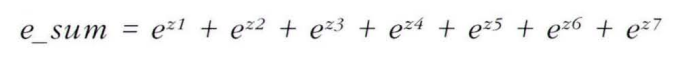
위아래 두 그림처럼 소프트맥스 함수가 구현된다.
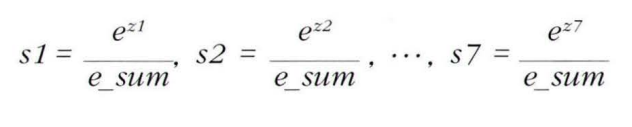
7개의 생선에 대한 확률의 합은 1이다.
소프트맥스 함수의 매개변수 axis는 소프트맥스를 계산할 축을 지정한다. axis를 1로 지정하면 각 샘플에 대해 소프트맥스를 계산하고 만약 axis값을 지정해 주지 않는다면 배열 전체에 대해 소프트맥스를 계산한다.
코드링크텍스트
04-2 확률적 경사 하강법
확률적 경사 하강법은 대표적인 점진적 학습 알고리즘이다. 여기서 점진적 학습이란 훈련에 사용한 데이터를 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 방식이다. 확률적이라는 말은 무작위로, 랜덤하게 라는 뜻이고 경사 하강법은 가장 가파른 경사를 따라 조금씩 내려가는 것이다. 확률적이라는 말이 랜덤하다는 의미라고 했는데 이는 전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련 세트에서 랜덤하게 골라 가장 가파른 길을 찾기 때문에 확률적이라고 하는 것이다.
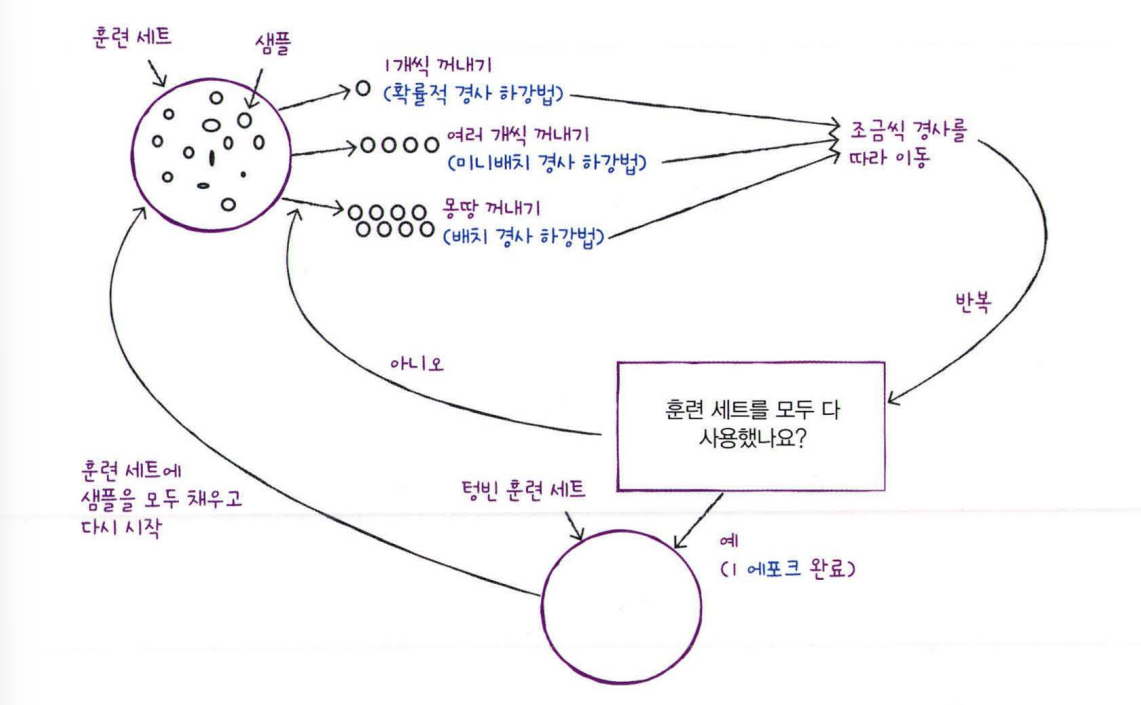
에포크는 훈련 세트를 한 번 모두 사용하는 과정을 말한다.
미니배치 경사 하강법은 1개씩 랜덤하게 고르는 확률적 경사 하강법과 달리 여러 개를 골라 경사를 이동하는 방식을 말한다.
배치 경사 하강법은 모든 샘플들을 다 꺼내 경사를 이동하는 것을 말한다.
- 손실함수는 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이다. 이름 그대로 손실함수이기 때문에 크면 클수록 안좋은 머신러닝이라는 것을 의미한다.
- 손실함수는 미분을 해야 하기 때문에 연속된 수가 아닌 분류의 정확도는 사용할 수 없다. (경사 하강법은 조금씩 하강하는데 정확도가 이렇데 듬성듬성하다면 경사 하강법을 이용해 조금씩 움직일 수 없다.)
-> (해결방법)로지스틱 회귀에서 확률은 0~1사이의 어떤 값도 될 수 있었다. 그렇다면 로지스틱 회귀는 손실함수로 만들 수 있는 것이다.(z값에 대한 그래프 생각하면 된다.)

위 그림과 같이 1,2번째는 양성클래스가 타깃이고 예측값에 정답을 곱하고 그 값을 음수로 바꾼 것이 손실이 된다. 음수를 붙이는 이유는 손실의 값이 작아야 하기 때문이다. 3,4번째는 음성클래스가 타깃인데 이는 1에서 예측값을 빼고 0을 1로 바꾸어 타깃이 1이었던 것처럼 바꾼 뒤, 음수로 만들어 주면 손실이 된다.

로그로도 바꿀 수 있다.
이렇게 바꾼 손실 함수를 로지스틱 손실 함수(크로스엔트로피 손실 함수)라고 부른다.
+회귀에서는 평균 제곱 오차를 많이 사용한다.
확률 경사 하강법을 제공하는 클래스는 SGDClassifier이다. (추가적으로 회귀는 SGDRegression이다.) SGDClassifier은 배치, 미니배치는 지원하지 않는다. SGDClassifier은 2개의 매개변수가 있는데 loss는 손실 함수의 종류를 지정하는 매개변수이고 max_iter은 에포크 횟수를 지정한다. 여기서 loss매개변수로 손실 함수의 종류를 지정하는 이유는 SGDClassifier은 머신러닝 모델을 최적화하는 방법 중 하나(머신러닝 모델이 아님)이기에 어떤 모델을 최적화할지를 지정해줘야 한다.

이런 식으로 하면 과소적합이 나오는 것을 볼 수 있다. partial_fit()메서드를 사용해서 추가로 1에포크씩 훈련을 시키면 아래 그림과 같이 정확도가 올라가는 것을 볼 수 있다.

하지만 이런 식으로 한다면 얼마나 더 훈련해야 하는지를 알 수 없다. 적절한 에포크를 찾기 위한 코드를 작성하여 그래프를 그려야 한다. 여기서 에포크에 대해서 설명하자면 alpha(규제)는 클수록 과소적합, 작을수록 과대적합이었다. 에포크는 반대로 클수록 과대적합, 작을수록 과소적합이다. 에포크는 alpha와 달리 훈련 횟수를 늘리는 것이기 때문이다.
- 조기 종료는 과대적합이 시작하기 전에 훈련을 멈추는 것을 말한다.

300번의 에포크 동안 훈련을 반복하여 각각의 반복마다 훈련 세트와 테스트 세트의 점수를 계산항 train_score, test_score리스트에 추가한다. 이 값들을 가지고 그래프를 출력한다.
(추가로 partial_fit()메서드에서 매개변수 classes=classes로 되어있는데 이는 앞에 fit()메서드 없이 partial_fit()메서드를 쓸 때는 클래스 개수를 전달해줘야 되기 때문이다.)
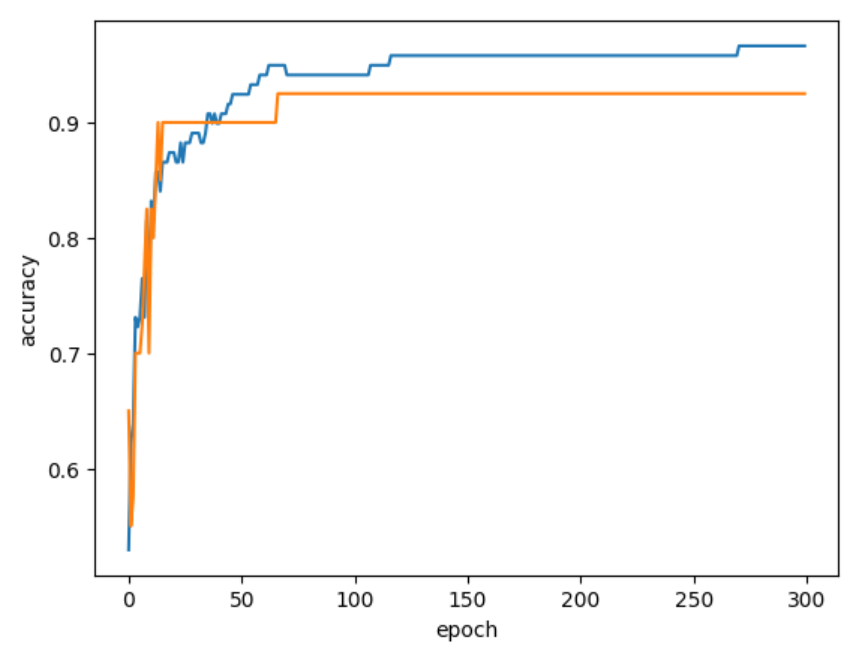
위의 그림과 같이 그래프가 나왔다. 약 100정도의 에포크가 적당하다는 것을 알 수 있다.

적당한 에포크를 넣어 다시 모델을 훈련하니 정확도 점수가 비교적 높게 나온 것을 볼 수 있다.
hinge
loss 매개변수의 기본값은 hinge이다. 힌지 손실은 서포트 벡터 머신이라 불리는 또 다른 머신러닝 알고리즘을 위한 손실 함수이다.
아래는 힌지 손실을 사용한 모델이다.

코드링크텍스트
