PNP AI 공부(4)
05-1 결정 트리
head() : 처음 5개의 샘플 확인하는 메서드
info() : 데이터프레임의 각 열의 데이터 타입, 누락된 데이터가 있는지 확인할 수 있는 메서드
describe() : 열에 대한 간략한 통계를 출력하는 메서드
결정 트리
: 질문을 계속하면서 샘플을 분류하는 알고리즘

-> 과대 적합(깊이를 제한하지 않아 순수노드가 될때까지 분할)

max_depth : 높이 제한(1은 루트노드 제외 1개)
filled=True : 양성, 음성 다르게 표현
지니 불순도 = 1 - ((음성클래스의 비율)^2 + (양성클래스의 비율)^2)
최대 0.5(클래스의 비율이 정확히 1/2), 최소 0(하나의 클래스만! = 순수 노드)
정보 이득 : 부모 노드와 자식 노드 사이의 불순도 차이
가지치기

깊이를 제한하여 과대적합을 막는 방법
결정 트리는 표준화 전처리 과정이 필요 없음 그 이유는 특성값의 스케일은 결정 트리 알고리즘에 아무런 영향을 미치지 않기 때문(결정 트리는 선형함수를 훈련하는 알고리즘이 아니기 때문)
feature_importances _ : 특성 중요도를 나타내는 메서드
05-2 교차 검증과 그리드 서치
검증 세트 : 모델이 과대적합인지 과소적합인지 판단할 때 쓰이는 데이터(보통 20 ~30%)
훈련 세트, 테스트 세트, 검증 세트를 나눌 때는 먼저 훈련 세트와 테스트 세트로 나눈 뒤, 훈련 세트를 다시 훈련 세트와 검증 세트로 나눔
-> 훈련 세트와 검증 세트로 모델을 만들고 평가
-> 훈련 세트에 과대 적합
> 교차검증
교차 검증 : 안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용할 수 있는 방법, 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복하고 이 점수를 평균하여 최종 검증 점수를 얻음
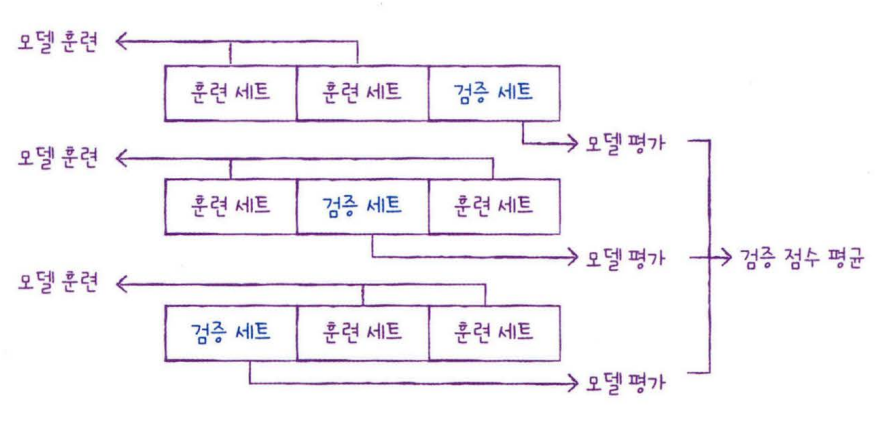
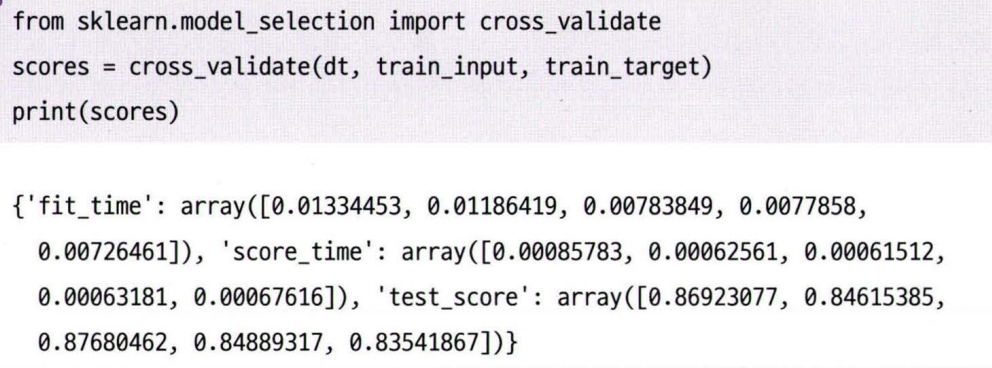
cross_validate : 교차 검증 함수(기본적으로 5-폴드 교차 검증을 수행)
+cv매개변수에서 폴드 수를 바꿀 수도 있음
fit_time : 모델을 훈련하는 시간
score_time : 검증하는 시간
- 교차 검증의 최종 점수는 test_score 키에 담긴 5개의 점수를 평균한 값임
- test_score는 검증 폴드의 점수이니 혼동하지 않게 조심
cross_validate는 훈련 세트를 섞어 폴드를 나누지X
-> 교차 검증을 할 때 훈련 세트를 섞으려면 분할기 지정해야 함
회귀 모델일 경우 KFlod
분류 모델일 경우 StratifiedKFlod(타깃 클래스를 골고루 나누기 위함)

훈련 세트를 섞은 후 10-폴드 교차 검증을 수행하려면 n_splits = 10하면 됨

10-폴드 교차 검증 : 훈련 세트를 열 부분으로 나눠서 교차 검증을 수행하는 것
하이퍼파라미터 튜닝
모델 파라미터 : 머신러닝 모델이 학습하는 파라미터
하이퍼파라미터 : 사용자가 지정해야만 하는 파라미터
모델마다 여러 개의 매개변수가 있을 텐데 이 매개변수를 바꿔가며 모델을 훈련하고 교차 검증을 수행해야 함 max_depth의 최적값은 min_samples_split 매개변수의 값이 바뀌면 달라지기에 두 매개변수를 동시에 바꿔가며 최적의 값을 찾아야 함
- cv 매개변수는 폴드 수를 바꾸는 매개변수
- n_jobs 매개변수는 CPU 코어 수를 지정(기본값 1, -1로 지정하면 시스템에 있는 모든 코어를 사용)
사이킷런의 GridSearchCV 클래스(cv 매개변수의 기본값은 5)는 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행함 -> cross_validate 함수를 호출할 필요 없음
그리드 서치는 모델들을 훈련한 후, 모델들 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련시킴
gs.best_estimator_은 일반 결정 트리처럼 사용할 수 있음
gs.best_params_속성에 최적의 매개변수가 저장되어 있음
cv_results_속성의 'mean_test_score'에 각 매개변수에서 수행한 교차 검증의 평균 점수가 저장되어 있음
np.argmax함수는 가장 큰 값의 인덱스를 추출할 수 있음
randint : 주어진 범위에서 고르게 정숫값을 뽑는 클래스
uniform : 주어진 범위에서 고르게 실숫값을 뽑는 클래스
랜덤 서치

min_impurity_decrease는 0.0001부터 0.001까지 실숫값을 샘플링하고 max_depth, min_samples_split, min_samples_leaf는 정숫값을 샘플링함

n_iter 매개변수는 샘플링 횟수를 지정함
위의 코드는 100번을 샘플링하고 교차 검증을 수행하여 최적의 매개변수 조합을 찾음
그리드 서치보다 훨씬 교차 검증 수를 줄이면서 넓은 영역을 효과적으로 탐색할 수 있음
