PNP AI 기초반(2024-1)
데이터 사이언스 시작하기
데이터 사이언스란?
데이터 사이언스 단계
1. 문제 정의하기 - 목표설정, 기간 설정, 평가 방법 설정, 필요한 데이터 설정
2. 데이터 모으기 - 웹 크롤링, 자료 모으기, 파일 읽고 쓰기
3. 데이터 다듬기 - 데이터 관찰하기, 데이터 오류 제거, 데이터 정리하기
4. 데이터 분석하기 - 데이터 파악하기, 데이터 변형하기, 통계 분석, 인사이트 발견, 의미 도출
5. 데이터 시각화 및 커뮤니케이션 - 다양한 시각화, 커뮤니케이션, 리포트
Jupyter Notebook
단축키
셀 실행 : Ctrl + enter
새로운 셀 추가 : a(위), b(아래) //커맨드 모드일때만
셀 삭제 : dd //커맨드 모드일때만
여러 개 선택 : shift + cell 클릭 //커맨드 모드일때만
셀 실행 + 새로운 셀 추가 : Alt + enter
현재 셀 실행 + 다음 셀 선택 : shift + enter
실행이 독립적으로 되기에 실행 순서에 따라 출력이 달라짐
Markdown : 설명글 작성
(#) : 가장 큰 제목
(##) : 두 번째 큰 제목
( 글 ) 또는 ( 글 ): 글을 두껍게
( 글 ) 또는 ( 글 ): 글을 기울임
(* 글) : 리스트를 만들 수 있음
(space 2번) : 줄바꿈
(enter 2번) : 문단바꿈
(~~ 글 ~~ ) : 취소선
(이름) : 링크
() : 이미지
'''python
print('hello world')
for i in range(10):
print(i)
'''
: 코드 블록 추가
' 코드 ' : 인라인 코드 추가
(---) : 구분선
Numpy
numpy : 숫자와 관련한 파이썬 도구
numpy array
numpy.array : numpy모듈의 array메소드에 파라미터로 파이썬 리스트를 넘겨줌
numpy.full(개수, 숫자) : 모든 값이 같은 numpy array
numpy.zeros(개수, dtype=타입) : 0으로 이루어진 numpy array
numpy.ones(개수, dtype=타입) : 1로 이루어진 numpy array
numpy.random.random(숫자) : 랜덤한 값들로 numpy array
numpy.arange(m) : 0부터 m-1까지의 값들이 담긴 numpy array
numpy.arange(n, m) : n부터 m-1까지의 값들이 담긴 numpy array
numpy.arange(n, m, s) : n부터 m-1까지 간격이 s인 numpy array
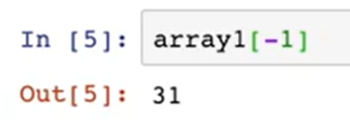
-1인덱스는 마지막 인덱스

하나씩 건너 뛰면서 출력(2, 4, 6, 8, 10 인덱스 출력)
array 2 : array의 모든 원소에 2를 곱함
나머지 사칙연산들도 마찬가지*
계산들을 저장해주지 않으면 원래 array임
boolen연산

np.where(booleans) : boolean array에서 true인 index만 출력
numpy 예약어
array.max() : 최댓값
array.min() : 최솟값
array.mean() : 평균값
median(array) : 중앙값
array.std() : 표준 편차
array.var() : 분산
Pandas
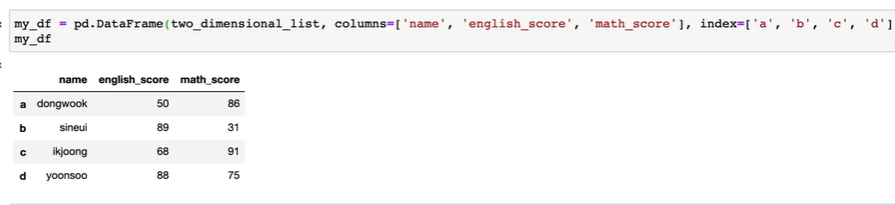
pandas는 다양한 자료형을 담을 수 있음
pandas에서는 row를 index로 부름
df이름.dtypes : 각각 column의 타입을 출력(같은 column 내에서는 같은 자료형이여야 함)
python의 dictionary로도 DataFrame을 만들 수 있음
-> key는 column이름이 됨
csv : '값들이 쉼표로 나눠져있다'라는 뜻
read_csv(파일 경로) : csv파일 읽어드림 -> DataFrame을 return함
csv의 첫 번째 줄은 header로 들어감
header=None : 첫 번째 줄에 header가 없을 때
특정 column을 row 이름으로 할 수 있음
-> index_col = 0 : 0번째 column이 row의 이름이 됨
완료!
DataFrame 다루기
DataFrame 인덱싱 문법 정리
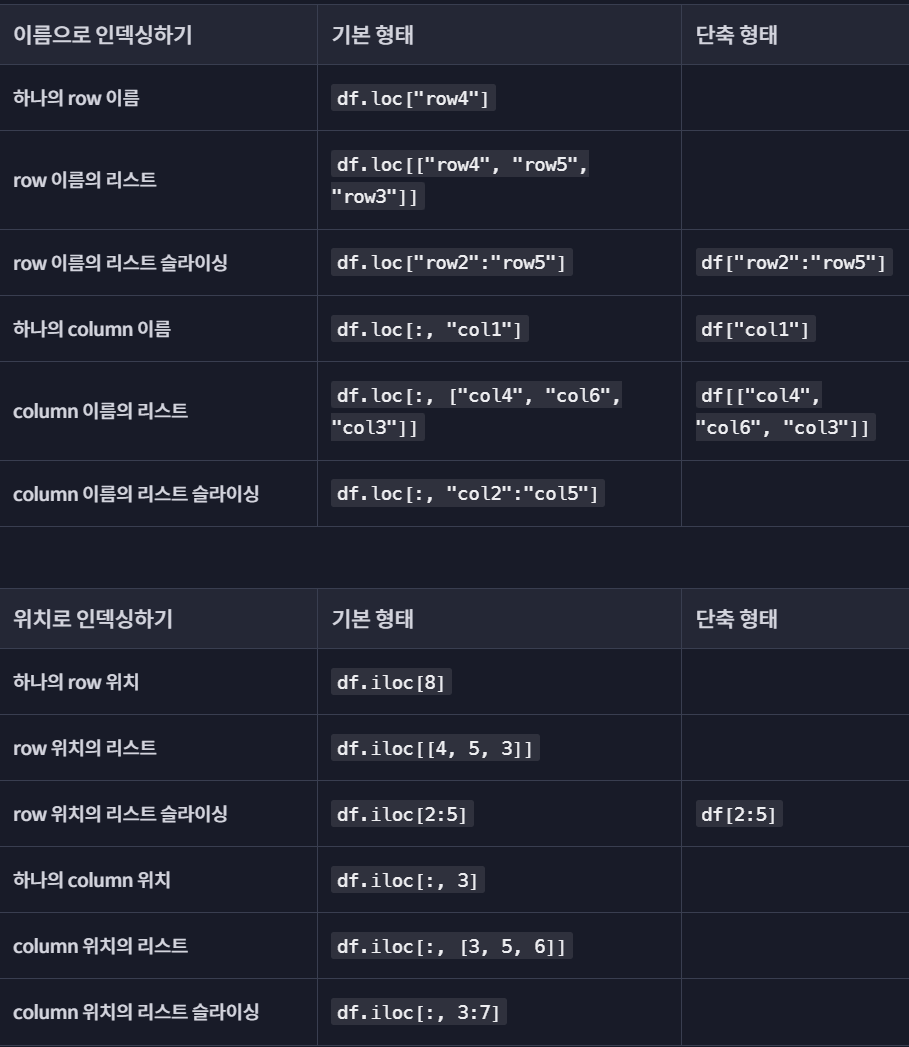
데이터 변형하기
dataframe 이름.drop('row 또는 column 이름', axis='index 또는 columns', inplace=True 또는 False)
: dataframe 삭제
: True = 기존의 DataFrame 수정
:False = 기존의 DataFrame 수정X
dataframe 이름.rename(columns={'column 원래 이름' : 'column 새로운 이름'}, inplace=True)
: column 이름 수정
DataFrame 이름.index.name = 'column 이름'
: 인덱스 이름을 만들어줌
DataFrame 이름.set_index('column 이름', inplace=True)
: index의 값을 바꿈
큰 데이터 살펴보기
큰 DataFrame 살펴보기
DataFrame 이름.head(숫자) : 위에서 숫자만큼의 index 출력
DataFrame 이름.tail(숫자) : 아래에서 숫자만큼의 index 출력
DataFrame 이름.info() : columns 정보
DataFrame 이름.describe() : 통계 정보
DataFrame 이름.sort_values(by='column 이름') : column을 기준으로 sort
DataFrame 이름.sort_values(by='column 이름', ascending=False) : column을 기준으로 큰것부터 sort
-> 기존의 DataFrame을 수정하고 싶으면 inplace=True
큰 Series 살펴보기

: 겹치는 것 없이 브랜드만 나옴

: 브랜드별로 몇개씩 있는지 출력
데이터 분석과 시각화
시각화와 그래프
df.plot() : 선 그래프
df.plot(kind='bar') : 막대 그래프
df.plot(kind='pie') : 막대 그래프
df.plot(kind='hist') : 히스토그램
Seaborn 시각화
df.plot(kind='box') : 박스 플롯
df.kdeplot(df) : 커널 밀도 추정 플롯
df.violinplot(x=df) : 바이올린 플롯
catplot(kind='플롯') : 시각화 다목적 함수
통계 기본 상식
DataFrame의 corr() 메소드를 사용하면, 숫자 데이터 사이의 상관 계수를 보여 줌
-> 각 column들 사이에서 상관 관계를 보여줌
sns.heatmap(df.corr())
: heatmap에서 색이 밝을수록 상관 계수가 더 높음
sns.heatmap(df.corr(), annot=True)를 하면 색상과 함께 숫자도 보여줌
Exploratory Data Analysis

df에서 gender가 F인 index만 뽑아서 넣을 수 있음

female에서 occupation만 빼서 value_counts를 하여 값을 알 수 있고 sort_values를 하고 ascending=False를 넣어주면 내림차순으로 정렬됨

getting up이라는 column의 값들을 넣을 수 있음
클러스터 분석
데이터들을 몇가지 분류로 나누는 것을 말함
새로운 인사이트 발견하기
문자열 필터링
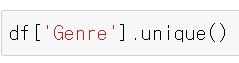
장르들을 다 모아서 볼 수 있음

Blues라는 이름이 포함된 장르들을 다 넣을 수 있음
- contains 대신 startswith를 넣으면 Blues로 시작하는 장르들이 모임
카테고리로 분류

brand_nation이라는 사전을 만들어서

아래와 같이 넣으면 사전의 왼쪽에 있는 값을 오른쪽의 값으로 바꿈
groupby

groupby에 brand_nation column을 넣어서 변수를 만듦
nation_groups.count() : 각각의 column에 대해 나라별로 갯수를 나타냄
nation_groups.max() : 최댓값
nation_groups.mean() : 평균값
nation_groups.first() : 가장 처음 값
nation_groups.plot(kind='hist', y='price')를 하면 각 나라별로 히스토그램이 나옴
데이터 합치기
innder Join : A와 B 중 겹치는 부분
left outer Join : A 와 B 중 A의 모든 부분
right outer Join : A와 B 중 B의 모든 부분
Full outer Join : A와 B 모두
pd.merge(DataFrame1, DataFrame2, on='기준이 되는 것') -> inner join
pd.merge(DataFrame1, DataFrame2, on='기준이 되는 것', how='left') -> left outer join
pd.merge(DataFrame1, DataFrame2, on='기준이 되는 것', how='outer') -> full outer join
머신 러닝 기본기
머신 러닝이란?
머신러닝 : 프로그램이 특정 작업을 하는 데 있어서 경험을 통해 작업의 성능을 향상시키는 것
지도학습 : 컴퓨터에게 답을 알려주고 학습시키는 것
-분류 : 특정 값 (ex.스팸메일 분류)
-회귀 : 무수히 많은 연속적인 값 (ex.아파트 값 예측)
비지도 학습 : 답을 알려주지 않고 컴퓨터가 스스로 비슷한 값끼리 묶는 것
(ex. 뉴스들을 주고 비슷한 것끼리 묶게 하는 것)
KNN(K-최근접 이웃 알고리즘) : 가장 가까운 이웃 데이터 K개를 찾아서 K개에서 더 많은 결과로 예측하는 것
선형대수학
행렬(Matrix)

벡터 : 열이 1개이거나 행이 1개인 것
(보통 벡터라고만 하면 열이 1개인 벡터를 의미함)
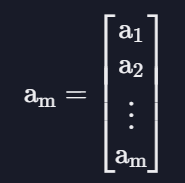
기본 지도 학습 알고리즘들
선형 회귀
선형 회귀 : 데이터를 가장 잘 대변해 주는 선을 찾아내는 것
목표 변수(target variable) : 맞추려고 하는 값
입력 변수(input variable = Feature) : 목표 변수를 맞추기 위해 사용하는 값
m : 학습 데이터의 개수
x : 입력 변수
y : 목표 변수
-> x^(1) : 1번 입력 변수
-> y^(1) : 1번 목표 변수
가설 함수 : 최적선을 찾아내기 위해 다양한 함수를 시도하는데 이 함수 하나하나를 가설 함수라고 함
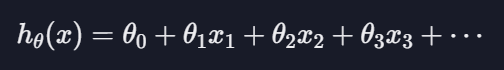
선형 회귀의 임무는 가장 적절한 세타 값을 찾는 것임
세타 0은 상수항임
평균 제곱 오차(MSE)
: 가설 함수가 얼마나 좋은지 평가하는 방법으로, 데이터들이 가설 함수와 평균적으로 얼마나 떨어져 있는지를 나타냄
데이터와 가설 함수 사이의 거리를 구하고 제곱한 값을 다 더하고 m으로 나누는 것
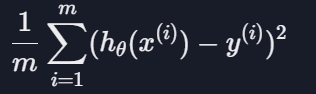
손실 함수
: 가설 함수를 평가하기 위한 함수
손실 함수가 작을수록 손실이 작은 것이기에 좋은 가설 함수라 할 수 있음
인풋이 세타값인데 이는 세타값을 조정하여 어떤 세터값이 가장 좋은 가설 함수를 만들 수 있는지를 알 수 있음
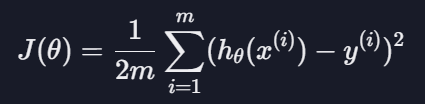
경사 하강법 계산
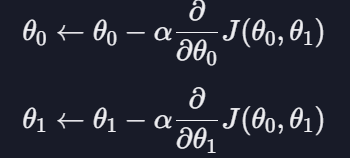
세타0 업데이트
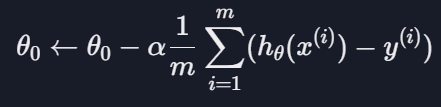
세타1 업데이트
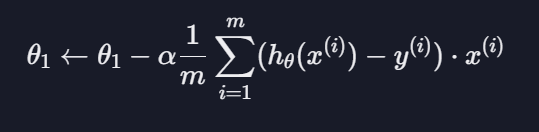
학습률 알파
: 산을 내려갈 때의 보폭이라고 생각하면 쉬움
일반적으로 1.1~0.0 사이의 숫자로 정하고 여러 개를 실험해 보면서 경사 하강을 제일 적게 하면서 손실이 잘 줄어드는 학습률을 찾아야 함
모델 평가
RMSE : 평균 제곱근 오차의 줄임말로, 평균 제곱 오차에 루트를 한 것임 제곱한 것을 루트를 씌워 다시 원래 단위로 바꾸는 것임
다중 선형 회귀
다중 선형 회귀 : 입력 변수 여러 개인 선형 회귀
다중 선형 회귀 가설 함수
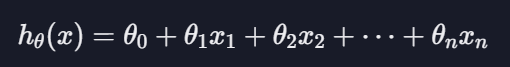
다중 선형 회귀 경사 하강법
다중 선형 회귀 손실 함수는 선형 회귀 손실 함수와 똑같이 생김
- 세타0, 세타1 업데이트
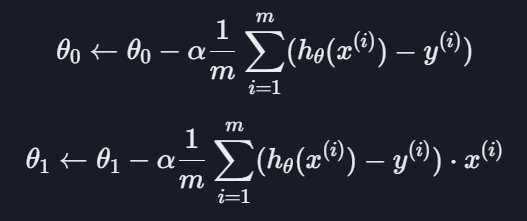
입력 변수가 n개 있다고 하면 세타0부터 세타n까지 쭉 업데이트를 해야, 경사 하강을 한 번 한 것임
j에 0을 넣어 업데이트를 하고 1을 넣어 업데이트를 하고 n까지 업데이트를 하는 것임
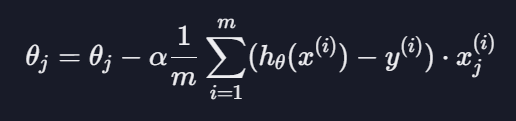
이 과정을 한 번 거치면 손실을 최대한 빨리 감소시키는 방향으로 세타 값들이 업데이트되는 것임
-경사 하강법 공식-
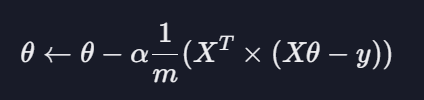
경사 하강법 vs 정규 방정식
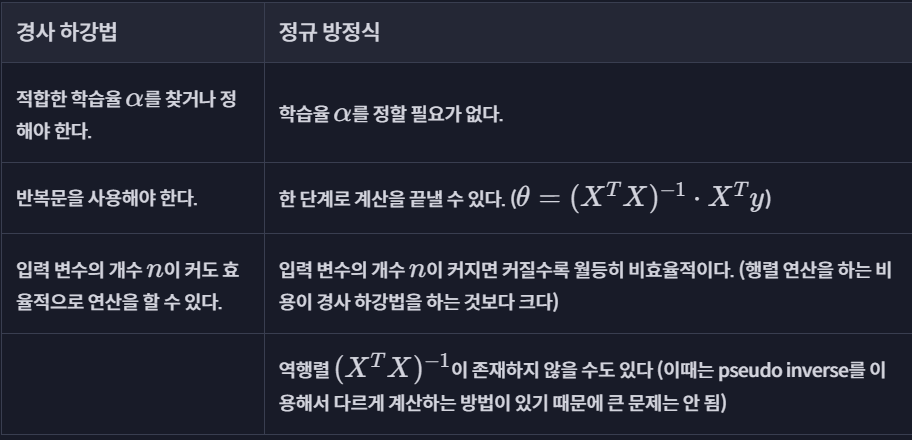
다항 회귀(polynomial regression)
: 다항식이나 곡선을 구하여 학습하는 방식
다항 회귀 가설 함수
-> 가설 함수가 3차 함수일 때
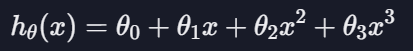
다항 회귀의 장점 : 다양한 속성들을 서로 곱해서 차항을 높여주면 속성들 사이에 있을 수 있는 복잡한 관계들을 학습시킬 수 있음
로지스틱 회귀
: 데이터에 가장 잘 맞는 시그모이드 함수를 찾는 것
시그모이드 함수 : 0과 1 사이의 결과를 리턴함
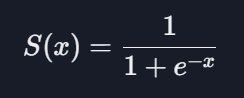
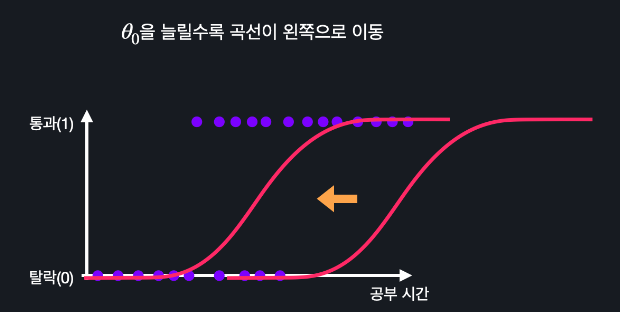
시그모이드 함수에서 세타0의 값을 늘리면 왼쪽으로 움직이고 줄이면 오른쪽으로 움직임
세타1의 값을 늘리면 s모양의 곡선이 조여지고 줄이면 늘어짐
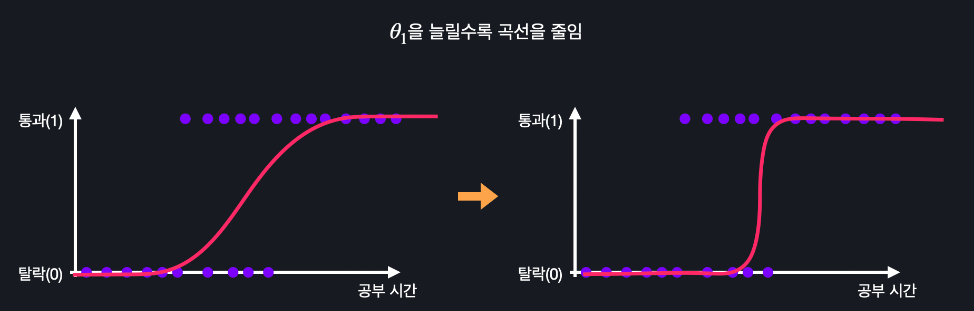
예외적인 데이터에 민감하게 반응하지 않아 분류 문제에 적합함
로지스틱 회귀 가설 함수
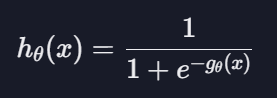
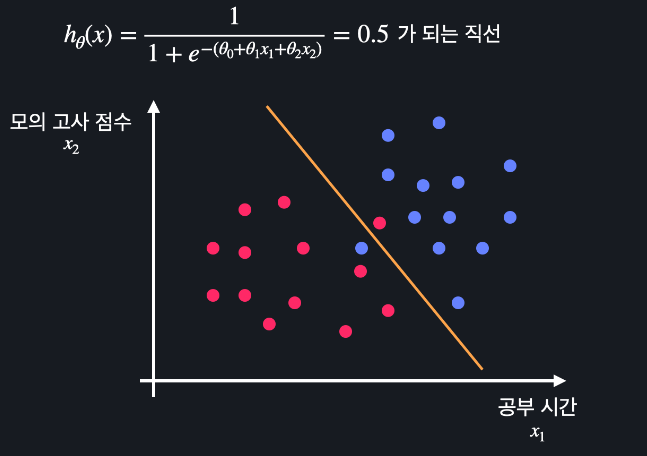
결정 경계
Decision Boundary : 속성이 2개일 때는 로지스틱 회귀 가설 함수로 시각화하는 것은 힘들기에 이를 보안하는 것임. 결정 경계선으로 분류하는 문제들에 적용할 수 있는 개념
로그 손실
h(x)는 입력 변수에 대한 가설 함수의 예측값
y는 실제 값
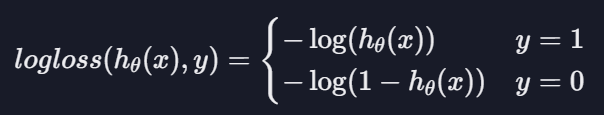
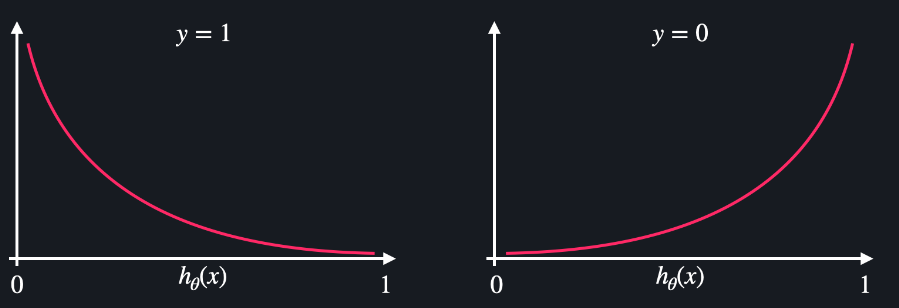
h(x)가 1인 경우, 100% 확률로 아웃풋이 1일 거라 예측
실제 결과가 1이기에 손실이 0
h(x)가 0.8인 겨우, 80% 확률로 아웃풋이 1일 거라 예측
실제 결과가 1이기에 손실이 조금 있음
h(x) 0인 경우, 아웃풋이 1일 확률이 0%라 예측
실제 결과가 0이기에 손실이 0
h(x) 0.2인 경우, 20%의 확률로 아웃풋이 1일 거라 예측
실제 결과가 0이기에 손실이 조금 있음
h(x)가 0에서 멀어질수록 못하고 있는 것이라 손실을 엄청나게 키우는 것
로지스틱 회귀 손실 함수
로그 손실
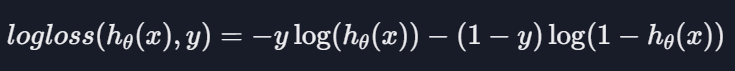
로지스틱 회귀 손실 함수

로그 손실 대입

로지스틱 회귀 경사 하강법
-> 선형 회귀랑 같음
-> j에 0, 1, 2, ...을 넣어서 업데이트를 각각 해주면 됨
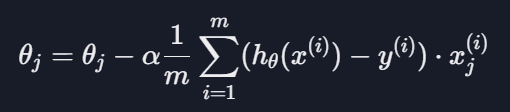
로지스틱 회귀에서 가설 함수는 시그모이드이고 아래와 같이 나타냄
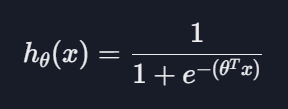
h에 시그모이드 함수를 대입하여 각 세터값을 업데이트하면 됨
분류가 3개 이상일 때
분류가 3개일 경우는 1개 옵션과 나머지로 2개로 분류하여 가설 함수를 구함
각각 3개의 가설 함수에 데이터를 넣고 나온 확률에서 제일 높은 확률로 분류함
