초록
검색 기능이 추가된 대형 언어 모델(LLMs)은 외부 맥락을 통합하여 강력한 성능과 다양한 활용성을 보여줍니다. 그러나 입력 길이가 선형적으로 증가하면 LLM의 추론 지연이 크게 증가하여 효율성이 저하됩니다. 이 논문에서는 Sparse RAG라는 효율적인 추론 방식을 제안합니다. Sparse RAG는 토큰 레벨의 선택적 집중을 통해 LLM의 계산 비용을 줄이는 것을 목표로 합니다. 특히, Sparse RAG는 검색된 문서의 중요 정보에 주의할 수 있도록 LLM 디코더에 선택적 점검 토큰을 도입하여 효율성을 향상시킵니다. 이 방식은 모델의 디코딩 동안 불필요한 정보의 고려를 방지하고 중요 정보에만 집중하여 계산을 최적화합니다. 결과적으로 Sparse RAG는 다양한 검색 방법과 문서 평가 단계에 활용 가능하며, 짧고 긴 입력 길이 모두에 대해 일반화된 성능을 보여줍니다.
1. 서론
대형 언어 모델(LLMs)은 최근 주목받으며 다양한 작업에 놀라운 능력을 보여주었습니다. 그러나 LLM은 여전히 사실적인 오류를 줄이는 데 어려움을 겪으며, 이에 따라 검색-증강 생성(RAG)이라는 방법이 널리 사용되고 있습니다. RAG는 검색된 문서를 이용하여 외부 지식을 LLM에 통합하는 방식으로 사실적인 오류를 줄입니다. 그러나 RAG의 가장 큰 문제점은 입력 길이가 길어질 때 모델의 추론 시간이 급격히 증가한다는 점입니다.
이에 대해 이 논문에서는 Fusion-in-Decoder (FiD)와 Parallel Context Windows (PCW) 같은 기존 연구를 기반으로 Sparse RAG를 제안하며, 생성 품질과 계산 효율성 간의 최적 균형을 찾고자 합니다.
그림 설명
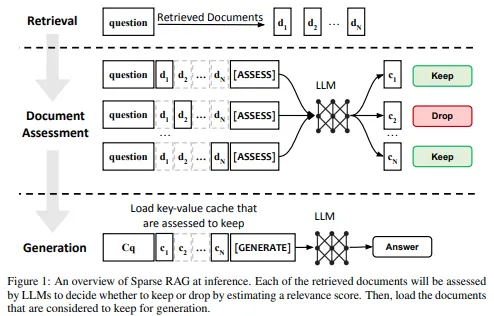
그림 1: Sparse RAG 추론 개요입니다. 각 검색된 문서가 LLM에 의해 평가되고, 관련성 점수에 따라 필요한 문서만 선택되어 생성 단계에서 활용됩니다.
이러한 문제를 해결하기 위해 우리는 Sparse RAG라는 새로운 패러다임을 제안합니다. 이 접근 방식은 LLM 디코딩 시점에서 적절한 정보를 효율적으로 활용하여 중요하지 않은 정보에 대한 처리 시간을 줄입니다. 기존 RAG 시스템의 일부 요소를 차용하면서도 비효율적인 문서 평가 방식을 개선하고, 각 토큰이 디코딩되는 동안 중요한 정보에 집중할 수 있도록 설계되었습니다. 이 방식은 특히 짧은 맥락뿐만 아니라 긴 맥락에서도 우수한 성능을 보여줍니다.
효율적인 RAG 추론에 대한 연구는 최근 검색 영역에서 광범위하게 이루어졌습니다. 몇몇 연구는 가속화 기법을 적용했고, 다른 연구들은 모델 구조에 효율적인 통합 방법을 적용했습니다. 예를 들어, FiD [12]와 PCW [28]는 검색된 문서의 관련성에 따라 토큰을 선택적으로 주목합니다. 그러나 이러한 기존 방법은 LLM의 디코딩 과정에 주목하지 않았기 때문에 효율성 측면에서 한계가 있었습니다. 우리는 Sparse RAG를 통해 이러한 한계를 극복하고자 합니다.
표 1: 기존 RAG 관련 작업과의 비교
| 접근 방식 | 교정 여부 | 무 추가 필요 | 프리필 효율성 | 디코드 효율성 |
|---|---|---|---|---|
| RAG [19] | 아니요 | 아니요 | 아니요 | 아니요 |
| Corrective RAG [36] | 네 | 아니요 | 아니요 | 아니요 |
| PCW RAG [28] | 아니요 | 네 | 아니요 | 아니요 |
| Sparse RAG | 네 | 네 | 네 | 네 |
2. 관련 연구 (Related Work)
Retrieval-Augmented Generation: RAG는 검색된 인접 구조를 참조하여 출력 구조를 생성하는 데 사용되는 기술로, 일반적으로 두 가지 단계를 포함합니다:
- 검색: 입력에 대한 가장 관련성 있는 문서를 검색합니다.
- 생성: 검색된 정보를 바탕으로 문장을 생성합니다.
기존 연구에서는 RAG와 FiD, Corrective RAG 등의 여러 변형 모델을 제안하였으며, 이를 통해 검색 및 생성 단계를 최적화하려고 노력했습니다.
표 1은 기존 RAG 관련 작업과의 비교를 보여줍니다. Sparse RAG는 이들 작업과 달리 효율적인 디코딩 과정을 통해 성능을 향상시켰습니다.
3. Sparse RAG (계속)
Sparse RAG는 디코더 전용 모델 아키텍처에 최적화되어 있습니다. 그림 1은 Sparse RAG 추론의 개요를 보여주며, 문맥에 따라 키워드와 관련성이 낮은 토큰을 효율적으로 처리하는 방법을 제시합니다. 이는 LLM이 중요한 정보에만 집중할 수 있도록 돕는 동시에 불필요한 계산을 줄여줍니다.
3.1 훈련 과정 (Training Process)
우리는 RAG 훈련 데이터가 일정 수준에서 접근 가능하다는 가정 하에 연구를 진행하였습니다. 이 가정 아래에서, 모델이 더 다양한 상황에 대응할 수 있도록 "Per Context Assessment (PCA)" 작업을 기존의 RAG 훈련 데이터와 함께 활용했습니다. 이는 모델이 각 문맥의 관련성을 평가하고 그에 따라 반응하는 능력을 강화하는 데 도움을 줍니다.
LLM을 활용한 데이터 증강 (Data Augmentation with LLMs)
일반적인 RAG 데이터의 경우, 하나의 질문-답변 쌍은 여러 검색된 문맥에 매핑될 수 있습니다. 데이터 증강을 위해, 우리는 MNLI에서 추출된 문장들과 다양한 모델로부터의 생성된 데이터를 결합하였으며, PALM-2 및 Gemini와 같은 고성능 LLM을 사용하여 각 문맥에 대한 평가를 수행했습니다. 이러한 과정을 통해 가장 적합한 라벨을 선택하고, 데이터 증강의 효과를 최대화했습니다.
멀티태스킹 데이터 형식 (Multitasking Data Format)
LLM은 두 가지 유형의 작업에 대해 동시에 훈련됩니다: "Rate" 평가 작업과 "생성" 작업. 데이터의 입력과 출력은 다음과 같이 구조화됩니다:
- 평가 작업: ([질문 | 문맥 | 평가 | 점수])
- 생성 작업: ([질문 | 문맥_1 | ... | 문맥_N | 생성 | 답변])
여기서 '평가'와 '생성'이라는 제어 토큰을 사용하여 LLM이 두 가지 작업을 구분할 수 있도록 하였습니다.
Parallel Contexts
각 문맥이 PCA 작업에서 독립적으로 처리되기 때문에, 우리는 이 독립성을 주요 RAG 작업에 도입하여 추론 과정에서 두 개의 작업이 동일한 KV 캐시를 재사용할 수 있도록 합니다. 이를 위해 Parallel Context Windows [28]을 따라 두 개의 문맥이 서로 교차 주의를 적용하지 않도록 훈련했습니다. 훈련 중에 우리는 각 문맥의 위치 정보를 "독립적인 위치 정보"로 유지했습니다.
- Control_Assessment와 Control_Generation: 질문, 문맥, Control_Assessment 토큰이 주어졌을 때, Control_Generation 토큰의 위치를 조정하여 모든 문맥이 고려될 수 있도록 합니다.
3.2 추론 과정 (Inference Process)
질문과 검색된 문맥이 주어지면 Sparse RAG는 평가 및 생성 작업을 하나의 단계에서 수행합니다.
- Per Context Assessment: 훈련 프로세스와 유사하게, KV 캐시를 채울 때 각 검색된 문맥은 독립적으로 처리됩니다. 각 문맥은 평가 점수에 사용되며, "Good" 토큰의 출현 확률은 해당 토큰의 중요성을 나타냅니다.
- 생성 (Generation): 생성 과정에서는 KV 캐시가 필터링되어 N개의 문맥 중 K개의 문맥만이 최종적으로 로드됩니다. 각 문맥의 점수가 특정 임계값 이하일 때 해당 문맥은 제거됩니다. 그런 다음 Control_Generation이 최종 생성 단계에 사용됩니다.
표 2: 자동 평가지와 실제 레이블 비교
| 자동 라벨링 방법 | 평균 F1 | F1 레이블 0 | F1 레이블 1 |
|---|---|---|---|
| PALM2 XL | n/a | 0.729 | 0.765 |
| PALM2 XL | PALM2 XL | 0.781 | 0.820 |
| Gemini Ultra | n/a | 0.761 | 0.801 |
| Gemini Ultra | Gemini Ultra | 0.764 | 0.747 |
| PALM2 XL | Gemini Ultra | 0.728 | 0.776 |
| Gemini Ultra | PALM2 XL | 0.821 | 0.861 |
표 2는 자동 평가지와 실제 레이블 간의 F1 점수를 보여줍니다. PALM2 XL와 Gemini Ultra가 평가에서 상호 비교될 때 가장 높은 성능을 보였습니다.
4. Per Context Assessment 평가
4.1 새로운 벤치마크: Natural Question Per Context Assessment
우리는 Natural Questions 데이터셋에서 10개의 검색된 문맥을 가진 50개의 질문을 선정했습니다. 7명의 평가자가 각각 질문-문맥 쌍을 평가하도록 하였으며, 섹션 2.2에 언급한 지침을 제공했습니다.
평가자들의 응답을 종합하여 각 문맥에 대해 다수결을 통해 0(관련 없음) 또는 1(관련 있음)을 결정했습니다. 평가 결과, 문맥의 70%에 대해 평가자 전원이 일치된 판단을 내렸고, 351개의 문맥이 '관련 있음'으로 판단되었습니다. 명확한 결정이 내려지지 않은 경우, 전문가 심사를 거쳐 추가 평가를 수행했습니다. 이러한 추가 검토로 인한 관련 문맥이 31% 증가하였으며, 자동 평가자 간의 일관성도 향상되었습니다.
4.2 LLM 평가자의 비교
우리는 여러 LLM 기반 자동 라벨링 방법을 테스트했습니다. 각 방법의 장단점을 비교하면서 표 2에 있는 방법들을 활용하였습니다. 이러한 비교를 통해 Gemini Ultra가 PALM2 XL보다 약간 더 나은 성능을 보이는 것을 확인했습니다.
5. Sparse RAG 평가
5.1 벤치마크와 지표
- PopQA: 이 데이터셋은 대규모의 공개 도메인 질문 응답(QA) 데이터셋으로, 14,000개의 엔티티 중심의 QA 쌍을 포함합니다. Gemini + PALM2 조합을 사용하여 학습 라벨을 생성했습니다. EM (Exact Match)과 F1 점수를 보고합니다.
- QMSum: 이 데이터셋은 쿼리 기반 다중 문서 요약 작업을 위한 벤치마크로, 다양한 도메인의 1,808개의 쿼리-요약 쌍을 포함합니다. 목표 데이터가 더 길기 때문에 ROUGE-LSum과 F1 점수를 보고합니다.
5.2 베이스라인
- RAG: 우리는 표준 RAG 방법을 사용했습니다.
- PCW RAG: RAG 프로세스에 Parallel Context Windows [28] 방법을 적용했습니다.
- Corrective RAG: 외부 T5-XXL 분류기를 사용하여 문서를 평가하고 순위를 매기는 방식을 채택했습니다.
이러한 다양한 방법과 비교하면서 Sparse RAG의 성능을 평가했습니다.
5.3 실험 구성
기본 LLM은 Gemini [34]를 사용했습니다. 우리는 Sparse RAG와 RAG 베이스라인 모두에 동일한 LoRA 튜닝을 적용하였고, 기본 랭크는 8로 설정했습니다. 기본적으로 XXS 사이즈 모델을 사용하며, 훈련에는 TPU V3 칩을 사용했습니다. 학습률은 0.05로 설정하고, 검증을 통해 최적의 체크포인트를 선택했습니다.
5.4 추론 설정 및 지표
Sparse RAG의 평가에는 삼성 S21 Ultra를 사용하여 실제 모바일 환경에서의 성능을 테스트했습니다.
- Prefill 단계: RAG 모델의 사전 로드 단계에 걸리는 시간을 측정합니다.
- Encoding 단계: 각 문맥이 토큰화된 후 디코딩되는 속도를 측정합니다.
- Decoding 단계: 생성된 출력의 정확성과 디코딩 속도를 측정합니다.
우리는 디코딩 속도 (DS)를 토큰당 초(t/s)로 측정했습니다.
5.5 주요 결과
| PopQA (단답형) | QMSum (장문) | |
|---|---|---|
| F1 | EM | |
| RAG [19] | 65.5 | 65.4 |
| PCW-RAG [28] | 66.3 | 65.7 |
| CRAG [36] | 66.5 | 65.8 |
| Sparse RAG | 71.6 | 67.7 |
표 3: 품질과 효율성의 균형 비교. Sparse RAG는 기존의 "dense" RAG 접근 방식보다 더 높은 품질과 효율성을 보여주었습니다. 특히, 20개의 검색 문맥 중 Sparse RAG는 PopQA에서 7.84의 컨텍스트를 사용하여 7.84의 F1 점수를, QMSum에서는 4.45의 컨텍스트로 23.96의 RougeL 점수를 달성했습니다.
5.6 분석
5.6.1 신뢰도 임계값의 영향
다른 임계값에 따른 메트릭의 변화를 보여주기 위해 Sparse RAG의 성능을 다양한 임계값으로 평가했습니다. 임계값이 높아지면 시스템은 더 많은 문맥을 필터링하여 추론 중 불필요한 정보의 양을 줄입니다.
임계값이 증가할수록 Sparse RAG의 성능이 향상되는 것을 확인할 수 있었습니다. 처음에는 불필요한 문맥을 제거하는 과정에서 성능이 크게 향상되었지만, 이후에는 약간의 하락 또는 안정화가 나타났습니다.
| 임계값 (Threshold) | PopQA EM | PopQA F1 | PopQA K | PopQA DS | QMSum F1 | QMSum RougeLSum | QMSum K | QMSum DS |
|---|---|---|---|---|---|---|---|---|
| 0.05 | 66.84 | 70.97 | 9.65 | 10.21 | 22.88 | 19.49 | 9.72 | 9.91 |
| 0.1 | 66.74 | 70.66 | 8.72 | 10.85 | 19.95 | 5.77 | 10.10 | 4.31 |
| 0.15 | 67.07 | 71.14 | 7.84 | 12.28 | 23.96 | 20.10 | 4.45 | 16.05 |
| 0.3 | 63.88 | 62.82 | 5.98 | 10.38 | 23.84 | 19.99 | 3.93 | 16.38 |
표 4: PopQA와 QMSum에 대한 다양한 신뢰도 임계값의 영향. 높은 신뢰도 임계값은 더 많은 문맥을 필터링함을 의미합니다.
5.6.2 Silver 라벨과 LLM 라벨 비교
Corrective RAG에서 T5 모델은 Silver 라벨로 훈련되었고, 우리는 동일한 Silver 라벨을 사용하여 LLM 라벨을 대체한 후 새로운 데이터셋으로 모델을 학습시켰습니다.
| 접근 방식 | F1 | EM | K | DS |
|---|---|---|---|---|
| Sparse RAG | 67.77 | 71.16 | 7.84 | 12.28 |
| Silver 라벨 비교 (Yan et al.) | 66.97 | 71.05 | 8.26 | 11.99 |
표 5: PopQA에서 Silver 라벨과 LLM 라벨 비교. LLM 라벨보다 Silver 라벨의 품질이 다소 더 나았지만, Sparse RAG는 더욱 일관되고 정확한 라벨링을 제공했습니다.
5.6.3 사전 로드 문서의 영향 (Ablation of Prefill Documents)
일부 사람들은 더 나은 성능이 "대량"의 사전 로드 문서에 의존할 수 있다고 생각할 수 있지만, 실제 상황에서는 훨씬 적은 수의 문맥이 필요합니다. 이를 확인하기 위해 PopQA에서 사전 로드 문서의 수를 10개와 20개로 비교했습니다.
표 6: PopQA에 대한 사전 로드 문서 수에 따른 성능 비교
| 접근 방식 | 사전 로드 문서 | EM | F1 | K | ES | DS |
|---|---|---|---|---|---|---|
| RAG | 10 | 64.66 | 68.67 | 10 | 80.74 | 10.31 |
| PCW RAG | 10 | 63.99 | 68.58 | 10 | 147.85 | 10.18 |
| Sparse RAG | 10 | 65.44 | 69.99 | 7.84 | 12.28 | 23.96 |
| RAG | 20 | 65.04 | 69.95 | 20 | 147.58 | 6.65 |
| PCW RAG | 20 | 63.86 | 68.92 | 20 | 147.83 | 6.60 |
| Sparse RAG | 20 | 67.77 | 71.16 | 7.84 | 12.28 | 23.96 |
Sparse RAG는 적은 수의 사전 로드 문서를 사용해도 성능이 뛰어나며, 가장 효율적인 방식으로 모든 문서를 처리할 수 있었습니다.
5.6.4 추론 효율성에 대한 분석 (Inference Efficiency Ablations)
디코딩 단계에서 문맥의 수와 길이를 변경하여 성능 차이를 분석했습니다. 분석 결과, RAG 접근 방식이 50% 이상의 디코딩 단계 시간을 필요로 하는 것을 발견했습니다. 반면에 Sparse RAG는 불필요한 문맥을 효과적으로 필터링하여 디코딩 효율을 크게 향상시켰습니다.
5.6.5 기본 모델 크기에 대한 영향 (Ablation on Foundation Model Size)
우리는 다양한 LLM 크기에서 Sparse RAG의 성능을 확인했습니다. Gemini XS와 Gemini XXL을 사용하여 실험한 결과, Sparse RAG는 다양한 크기의 모델에서도 우수한 성능을 보여주었습니다.
이러한 결과는 Sparse RAG가 여러 LLM 구성에서 적응할 수 있는 유연성과 효율성을 가지고 있음을 보여줍니다.
5.6.6 추론 시 골든 컨텍스트 라벨 사용
QMSum은 각 문맥에 대한 골든 라벨을 제공하므로, 우리는 이를 활용하여 각 문맥 평가가 완벽하게 이루어질 경우의 상한선 성능을 평가했습니다.
이를 통해 최고 품질의 라벨을 사용할 때의 잠재적 성능을 확인할 수 있었으며, 이 결과는 표 8에 요약되어 있습니다. 이를 통해 Sparse RAG의 최대 성능을 이해하고 그 한계에 대한 통찰력을 얻을 수 있었습니다.
| 접근 방식 | F1 | RougeL-Sum | K | DS |
|---|---|---|---|---|
| Sparse RAG | 23.96 | 20.1 | 4.45 | 16.05 |
| + 골든 라벨 적용 | 26.76 | 21.93 | 1.13 | 21.66 |
표 8: QMSum에서 골든 라벨을 사용한 Sparse RAG의 성능 비교.
그림 2: 추론 효율성 비교
(a) 각 메모리 수에 따른 디코딩 속도 (b) 다른 토큰 수를 디코딩하는 데 걸리는 E2E 지연 시간
5.6.5 다양한 LLM 모델 크기에서의 성능 비교
| 접근 방식 | 모델 크기 | EM | F1 | K |
|---|---|---|---|---|
| RAG | XS | 65.52 | 70.87 | 20 |
| PCW RAG | XS | 65.75 | 70.37 | 20 |
| Sparse RAG | XS | 68.26 | 72.26 | 6.27 |
| RAG | XXS | 65.49 | 69.99 | 20 |
| PCW RAG | XXS | 65.04 | 69.95 | 20 |
| Sparse RAG | XXS | 67.77 | 71.16 | 7.84 |
표 7: 다양한 LLM 모델 크기에서의 성능 비교. Sparse RAG는 모든 모델 크기에서 뛰어난 효율을 보여주었습니다.
6 결론
이 논문은 입력 길이 및 지연 증가 문제를 해결하기 위한 Sparse RAG를 소개합니다. Sparse RAG는 검색된 문서의 키-값 캐시를 효과적으로 관리하여 중요한 정보에 집중할 수 있게 함으로써 LLM의 효율성을 향상시켰습니다. PopQA와 QMSum에서 높은 품질의 결과를 얻으며 기존 방법에 비해 뛰어난 성능을 입증했습니다. 이 방법은 LLM의 효율적인 관리와 추론을 위한 잠재력을 보여주었습니다.
