RAG
1.Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
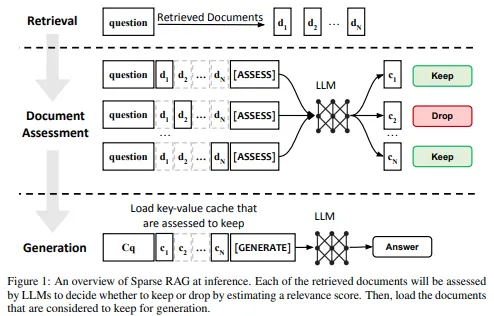
Fusion-in-Decoder (FiD)와 Parallel Context Windows (PCW) 같은 기존 연구를 기반으로 Sparse RAG 내용 정리 및 번역
2.Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting

Speculative RAG 방법과 내용 요약 Speculative RAG는 기존의 Retrieval-Augmented Generation(RAG) 방식의 한계를 보완하고, 특히 정보 집약적인 질문에서 더 높은 정확도와 효율성을 제공하는 방법. 정리 및 번역
3.LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
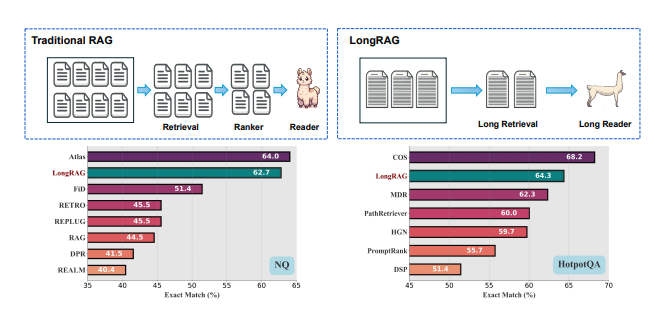
LongRAG을 제안. 이는 '긴 검색기'와 '긴 독자'로 구성됩니다. 단위를 기존보다 30배 길게(4,000 토큰 단위) 처리하여 검색기에서 필요한 총 단위 수를 줄이고, 단 몇 개의 상위 단위(8개 미만)를 사용하여 강력한 검색성능을 달성합니다.
4.RPO: Retrieval Preference Optimization for Robust Retrieval-Augmented Generation
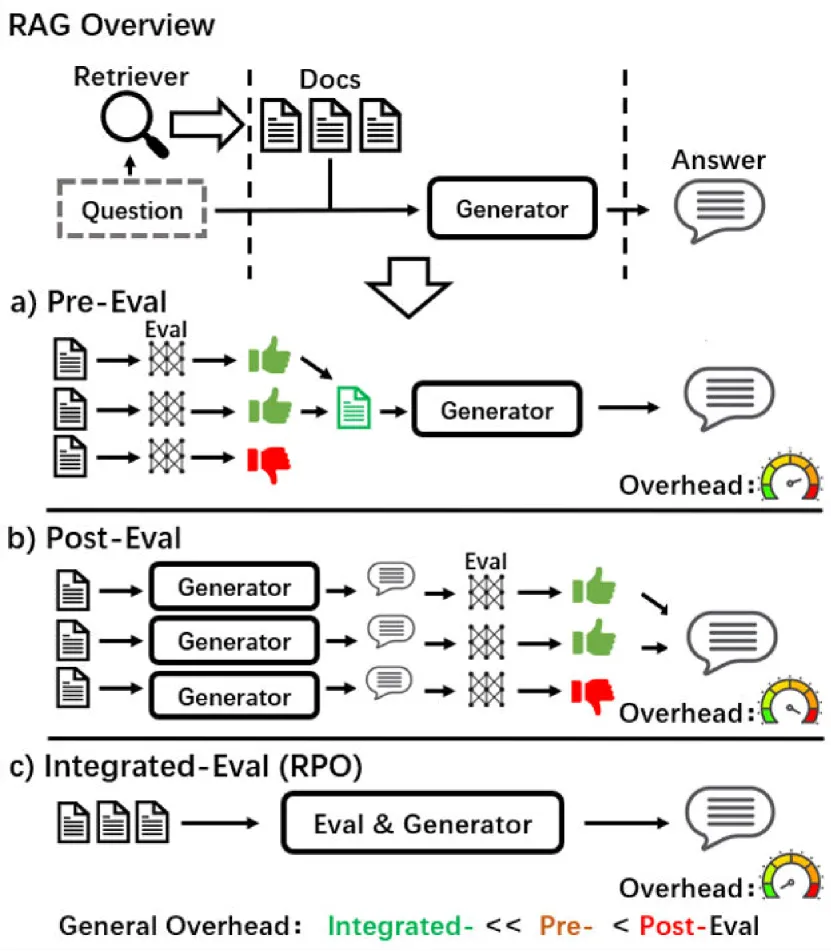
내부 암기와 다를 때 외부에서 검색된 비모수적 지식의 정확성을 평가하는 데 어려움을 겪기 때문에 응답 생성 중에 *지식 충돌이* 발생합니다. 이를 위해 검색 관련성을 기반으로 다중 소스 지식을 적응적으로 활용하기 위한 가볍고 효과적인 정렬 방법인 RPO를 제안합니다.
5.Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
기존 다중 벡터 검색(Multi-Vector Retrieval) 모델의 비효율성을 해결하고자 **XTR(Contextualized Token Retriever)**이라는 새로운 접근 방식을 제안합니다.
6.RARR: Researching and Revising What Language Models Say, Using Language Models
근거 없는 정보(hallucination)나 잘못된 정보(misleading content)를 생성하는 문제가 존재한다. 이러한 문제를 해결하기 위해 RARR 제안
7.Unveiling and Consulting Core Experts in Retrieval-Augmented MoE-based LLMs
본 논문은 **Mixture-of-Expert (MoE) 기반 LLM의 전문가 활성화(Expert Activation)**를 분석하여 RAG 개선 방안을 탐색함.
8.ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents
ViDoSeek이라는 새로운 데이터셋을 도입하여 **시각적 요소가 포함된 문서(Visually Rich Documents, VRD)**에서 RAG 성능을 평가하고자 함.
9.Corrective Retrieval Augmented Generation
기존 RAG 모델들은 검색된 문서를 무조건적으로 활용하는 문제가 있으며, 검색된 문서의 일부만이 실제로 유용한 정보를 포함하고 있음에도 불구하고 전체 문서를 참조한다. 이러한 문제를 해결하기 위해 제안.
10.Retrieval-Augmented Visual Question Answering via Built-in Autoregressive Search Engines
ReAuSE는 이 두 가지 기능을 하나의 Autoregressive Search Engine (자동 회귀 검색 엔진) 기반의 Generative Multi-modal Large Language Model (MLLM) 에 통합하여 동작하는 방식을 제안
11.DIRAS: Efficient LLM Annotation of Document Relevance in Retrieval Augmented Generation
도메인 특화 Relevance 정의를 반영하는 대규모 자동 어노테이션 파이프라인 제안
12.PIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation
PIKE-RAG는 다음을 강조합니다: 1. *특화된 지식(specialized knowledge)**의 추출과 이해 2. *합리적 추론(rationale)**의 구성 3. 과업의 난이도에 따라 **문제 유형 분류 및 단계적 시스템 발전 전략**
13.RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
질문에 따라 외부 지식 검색(retrieval)의 필요 여부를 동적으로 판단하는 Adaptive RAG (ARAG) 모델의 성능을 평가하고 개선하기 위한 새로운 벤치마크 RetrievalQA를 제안하고, 새로운 방법인 TA-ARE 도입
14.DRoC: Elevating Large Language Models for Complex Vehicle Routing via Decomposed Retrieval of Constraints
복잡한 제약 조건이 있는 차량 경로 문제(Vehicle Routing Problems, VRPs)를 해결하기 위해 대형 언어 모델(LLMs)의 성능을 향상시키는 새로운 RAG 기반 프레임워크를 제안
15.AutoRAG-HP: Automatic Online Hyper-Parameter Tuning for Retrieval-Augmented Generation
LLM 기반의 RAG(Retrieval-Augmented Generation) 시스템에서 하이퍼파라미터를 온라인 환경에서 자동으로 튜닝하는 방법을 제안한 최신 연구입니다.
16.Multi-Source Knowledge Pruning for Retrieval-Augmented Generation: A Benchmark and Empirical Study
다중 지식 소스를 활용하는 RAG(Retrieval-Augmented Generation) 환경에서 불필요하거나 혼란을 주는 정보를 줄이고, 정확한 지식 활용을 통해 환각(hallucination)을 감소시키는 PruningRAG 프레임워크를 제안
17.Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
(RAG)의 대표적인 문제인 불완전한 검색 결과와 내부/외부 지식 간 충돌 문제를 해결하고자 제안된 새로운 프레임워크
18.RuleRAG: Rule-Guided Retrieval-Augmented Generation with Language Models for Question Answering
기존 RAG (Retrieval-Augmented Generation) 방식의 한계를 극복하기 위해 **"규칙 기반의 검색 및 생성"**을 도입한 새로운 프레임워크를 제안
19.Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
검색 엔진과 상호작용하는 능력을 강화하기 위해 **강화학습(RL)**을 이용해 LLM이 자율적으로 검색 쿼리를 생성하고 추론할 수 있도록 훈련하는 프레임워크인 SEARCH-R1을 제안
20.InfoGain-RAG: Boosting Retrieval-Augmented Generation via Document Information Gain-based Reranking and Filtering
“검색된 문서가 실제로 답변에 얼마나 기여하는지”**를 **DIG**라는 새로운 척도로 수치화하고, 이를 바탕으로 **멀티태스크 reranker**를 학습시켜 **효율적이고 효과적인 RAG 문서 선택·정렬 방법**을 제안