https://export.arxiv.org/pdf/2502.01976
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
1. 개요
대형 언어 모델(LLM)은 다양한 자연어 처리(NLP) 작업에서 뛰어난 성능을 보이지만, 추론 과정에서 높은 연산 비용이 발생한다. 이는 실시간 또는 자원이 제한된 환경에서의 활용을 어렵게 만든다.
이 문제를 해결하기 위해 CITER (Collaborative Inference with Token-Level Routing) 프레임워크를 제안한다. CITER는 작은 언어 모델(SLM)과 대형 언어 모델(LLM) 간의 협력적인 추론(collaborative inference) 을 통해 토큰 수준에서 라우팅(token-level routing) 을 수행하는 새로운 접근법이다.
CITER의 핵심 아이디어는 다음과 같다:
- 비핵심(non-critical) 토큰은 SLM에서 처리하여 연산 비용 절감
- 핵심(critical) 토큰은 LLM에서 처리하여 높은 품질 유지
- 라우터(router)는 정책 최적화(policy optimization)를 통해 최적의 라우팅을 학습
- 보상 함수(reward function) 최적화를 통해 비용과 성능 균형 유지
- 학습 비용을 줄이기 위해 보상 평가 과정 가속화(shortcut mechanism) 도입
이러한 접근 방식을 통해 최대 30% 연산 비용 절감 혹은 동일한 비용으로 최대 25% 정확도 향상 을 달성하였다.
2. 기존 연구와 한계
기존 연구는 주로 다음과 같은 방식으로 LLM 추론 속도를 개선하려 했다:
- 쿼리 수준 라우팅(Query-Level Routing)
- 전체 쿼리를 LLM 또는 SLM 중 하나로 전달하는 방식
- 특정한 질문 유형에서만 효과적이며, 불필요한 LLM 호출이 많아 비용이 높아짐
- 토큰 수준 라우팅(Token-Level Routing)
- Co-LLM(Shen et al., 2024) 같은 방법은 일부 토큰을 SLM에서 처리
- 하지만, 현재 토큰만 고려하여 결정을 내리므로 장기적인 영향을 반영하지 못함
- 추론 속도를 높이는 기타 기법
- Speculative Decoding(Leviathan et al., 2023) 등의 방식은 작은 모델을 활용해 예측한 토큰을 LLM이 검증하는 방식이지만, 실패한 예측이 많을 경우 연산 비용 증가
CITER는 기존 토큰 수준 라우팅의 한계를 극복하여 장기적인 성능 최적화를 고려하는 점이 차별점이다.
3. CITER 프레임워크
3.1. 문제 정의
- 주어진 입력 프롬프트 X에 대해, 각 토큰 을 LLM (Large Language Model) 또는 SLM (Small Language Model)에서 생성할지 결정하는 라우터(πθ) 를 학습하는 것이 목표
- 보상 함수는 성능(정확도)과 비용(연산량) 간의 균형을 맞추도록 설계됨
3.2. 라우터 학습 과정
라우터는 강화 학습(RL)을 활용하여 학습되며, Markov Decision Process(MDP) 로 정의됨:
- 상태(state): 현재까지 생성된 프롬프트 및 응답 토큰들
- 행동(action): 현재 토큰을 LLM에서 생성할지, SLM에서 생성할지 선택
- 보상(reward): 응답 정확도와 연산 비용을 반영
라우터는 선호도 기반 정책 최적화(preference-based policy optimization) 를 활용하여 LLM과 SLM의 선택을 최적화함.
3.3. 보상 평가 가속화 (Shortcut Mechanism)
- 모든 토큰에 대해 최종 응답을 평가하는 것은 비용이 크므로, 보상 평가를 가속화하는 단축(shortcut) 기법을 도입
- SLM이 생성한 토큰이 정답과 일치하면 즉시 SLM을 선호하는 보상을 할당
- SLM이 실패할 경우 LLM 결과를 확인하고, LLM이 맞으면 LLM을 선택
- 두 모델 모두 틀릴 경우 전체 문장을 평가하여 라우팅 결정
이러한 방법을 통해 80~90%의 토큰에 대해 빠르게 라우팅 결정을 수행할 수 있음.
4. 실험 및 결과
4.1. 데이터셋 및 평가 방법
- 5개 벤치마크 데이터셋 사용: Commonsense QA, ARC-Challenge, MMLU-Professional Psychology, GSM8k, MATH
- 평가 지표: 정확도(Accuracy)와 연산 비용(FLOPs)
- CITER는 Qwen2-1.5B (SLM)과 Qwen2-72B (LLM) 모델을 활용하여 실험 수행
4.2. 주요 실험 결과
- 쿼리 수준 라우팅보다 토큰 수준 라우팅이 효율적
- CITER 및 Co-LLM(토큰 수준 라우팅)이 RouteLLM(쿼리 수준 라우팅)보다 비용 대비 성능이 우수
- CITER는 최대 30% 연산 비용 절감하면서도 동일한 성능 유지
- 장기적인 영향 고려가 성능 향상에 기여
- 기존 Co-LLM은 현재 토큰만 고려하여 최적화했지만, CITER는 장기적인 영향(long-term impact)까지 고려하여 더 나은 성능 달성
- Co-LLM 대비 동일한 비용에서 최대 17% 정확도 향상
- 반복 학습(iterative training)의 효과
- CITER는 첫 번째 학습 반복보다 두 번째 반복에서 5% 비용 절감 또는 2~3% 정확도 향상을 달성하며 빠르게 수렴
- 모델 크기 변화에 따른 성능 분석
- SLM 크기 증가(Qwen2-1.5B → Qwen2-7B) 시 연산 비용이 10% 감소하면서도 동일한 정확도 유지
- 실제 사례 분석
- CITER는 중요한 개념어(critical tokens)를 올바르게 식별하고 LLM에서 처리하여 높은 품질 유지
- Co-LLM 대비 CITER가 문맥적으로 중요한 단어를 LLM에서 생성하도록 학습됨
5. 결론 및 향후 연구 방향
5.1. 결론
- CITER는 SLM과 LLM 간의 협력적인 추론(collaborative inference) 구조를 활용하여 비용 효율적인 LLM 추론을 가능하게 함
- 기존 Co-LLM 대비 장기적인 영향을 고려하여 최대 30% 연산 비용 절감 또는 동일한 비용에서 최대 25% 성능 향상 달성
- 실험 결과, 쿼리 수준이 아닌 토큰 수준 라우팅이 효율적이며, 장기적인 영향을 고려하는 것이 중요함을 입증
5.2. 향후 연구 방향
- 온라인 학습 도입: 실시간 피드백을 반영하여 동적 정책 개선
- 더 정교한 보상 함수 설계: 현재 평가 방법보다 더욱 세밀한 라우팅 최적화 연구
- 추론 속도 향상: KV 캐시 활용 최적화 및 기타 연산 최적화 기법 도입
📌 요약
CITER는 대형 언어 모델(LLM)과 작은 언어 모델(SLM) 간의 협력적인 추론을 수행하여 연산 비용을 줄이면서도 성능을 유지하는 토큰 수준 라우팅 기법이다. 기존 Co-LLM 대비 최대 30% 비용 절감 또는 25% 정확도 향상 을 달성하였으며, 향후 온라인 학습 및 추론 최적화를 통해 더욱 향상된 성능을 기대할 수 있다.
Co-LLM (Collaborative LLM)란?
CITER 논문에서 언급하는 Co-LLM(Shen et al., 2024)은 토큰 수준 라우팅(token-level routing)을 수행하는 기존 연구 중 하나이다. 이는 CITER와 유사하게 작은 언어 모델(SLM)과 대형 언어 모델(LLM)을 협력적으로 사용하는 방식이지만, 몇 가지 한계점이 존재한다.
1. Co-LLM의 핵심 개념
Co-LLM은 문장을 생성할 때 일부 토큰을 SLM에서 생성하고, 나머지는 LLM에서 생성하는 방식을 적용한다. 이를 통해 LLM의 계산 비용을 줄이면서도 성능을 유지하려고 한다.
Co-LLM의 주요 특징:
- 토큰 수준에서 모델 선택: 각 토큰이 SLM 또는 LLM에서 생성될지 결정됨
- 현재 토큰 중심 라우팅: 현재 토큰의 정보를 기반으로 즉각적인 결정을 내림
- 정적인 학습 방식: 사전에 정의된 방식으로 라우팅을 결정하고, 장기적인 영향은 고려하지 않음
하지만 Co-LLM은 현재 토큰만을 고려하여 SLM과 LLM을 선택하기 때문에, 장기적인 영향을 반영하지 못하는 문제가 있다.
2. Co-LLM과 CITER의 차이점
(1) 라우팅 방식
| Co-LLM | CITER | |
|---|---|---|
| 라우팅 단위 | 토큰 수준 | 토큰 수준 |
| 의사 결정 기준 | 현재 토큰만 고려 | 현재 토큰 + 미래 영향 고려 |
| 라우팅 최적화 방법 | 지도 학습(Supervised Learning) | 강화 학습(Reinforcement Learning) |
| 보상 평가 방식 | 현재 토큰 정답 여부만 반영 | 전체 문맥 및 미래 영향을 반영 |
📌 핵심 차이점:
- Co-LLM은 단기적인 토큰 예측 성능만을 고려하여 LLM 또는 SLM을 선택함
- CITER는 장기적인 성능 및 비용 균형을 고려하여 더 최적화된 라우팅을 수행
(2) 강화 학습(RL) 기반 최적화
CITER는 강화 학습(Reinforcement Learning, RL)을 사용하여 토큰 수준 라우팅을 최적화한다.
반면, Co-LLM은 지도 학습(Supervised Learning)을 기반으로 모델을 학습하여, 각 토큰에 대해 정해진 규칙을 적용하는 방식이다.
이로 인해 Co-LLM은 새로운 문장에 대한 일반화 능력이 떨어지고, 라우팅 결정을 즉흥적으로 내리는 문제가 발생한다.
3. 실험 결과에서 Co-LLM과 CITER 비교
논문 실험 결과를 보면, CITER는 Co-LLM 대비 27~30% 연산 비용 절감을 이루면서도 동일한 성능을 유지하거나 최대 17% 성능 향상을 달성했다.
- Co-LLM의 문제점:
- 현재 토큰의 정보만 보고 LLM/SLM을 결정하기 때문에, 문맥적으로 중요한 토큰을 LLM에서 생성해야 하는 경우에도 잘못된 결정을 내릴 수 있음
- 장기적인 성능 최적화를 고려하지 않음 → 최적의 성능을 내기 어려움
- CITER의 개선점:
- 강화 학습을 통해 장기적인 문맥까지 반영하여 라우팅 수행
- 토큰별 보상 함수 최적화를 통해 더욱 정교한 라우팅 결정 가능
- 추론 비용 최적화(최대 30% 비용 감소) 효과가 큼
4. 결론
Co-LLM은 기본적인 토큰 수준 라우팅 모델이지만, 현재 토큰의 정보만 고려하는 한계가 있다.
반면, CITER는 강화 학습 기반의 정책 최적화를 통해 장기적인 문맥까지 고려한 라우팅을 수행하여 더 나은 성능과 효율성을 제공한다.
즉, Co-LLM은 기존의 정적인 토큰 라우팅 모델,
CITER는 이를 개선한 동적 강화 학습 기반 토큰 라우팅 모델이다. 🚀
본문
초록 (Abstract)
대규모 언어 모델(LLM)은 다양한 작업에서 주목할 만한 성공을 거두었지만, 추론 시 높은 계산 비용 때문에, 자원 제약이 있는 애플리케이션에서는 배포에 어려움이 있습니다. 이러한 문제를 해결하기 위해, 본 논문에서는 Token-LEvel Routing을 통한 협력 추론(Collaborative Inference with Token-LEvel Routing, CITER) 프레임워크를 제안합니다. CITER는 소형 언어 모델(SLM)과 대형 언어 모델(LLM) 간의 효율적인 협력을 가능하게 합니다. 구체적으로, CITER는 중요하지 않은 토큰은 효율성을 위해 SLM으로 라우팅하고, 중요한 토큰은 생성 품질을 위해 LLM으로 라우팅합니다.
우리는 라우터 학습을 정책 최적화(policy optimization)로 공식화하며, 라우터는 예측 품질과 생성 비용(inference cost)을 모두 고려한 보상을 바탕으로 훈련됩니다. 이로 인해 라우터는 현재 토큰과 미래 영향까지 고려하여 토큰 단위 라우팅 점수를 예측하고, 어느 모델이 각 토큰을 생성할지 결정할 수 있습니다.
또한 우리는 보상 추정 비용을 줄이기 위한 단축(shortcut) 방식을 제안합니다. 이 방식은 보상 추정 및 라우팅 판단 비용을 획기적으로 절감하여 실제 환경에서의 적용성을 높입니다. 다섯 개의 벤치마크 데이터셋에 대한 실험 결과, CITER는 생성 품질을 유지하면서도 LLM의 추론 비용을 줄일 수 있음을 보여줍니다. 본 프레임워크는 실시간 및 자원 제약 애플리케이션에서의 고품질 생성(high-quality generation)을 위한 유망한 해결책을 제공합니다. 코드 및 데이터는 https://github.com/aimag-lab/CITER 에서 확인할 수 있습니다.
1. 서론 (Introduction)
대규모 언어 모델(LLM)은 자연어 처리, 기계 번역, 텍스트 요약, 질의응답 등의 작업에서 큰 성과를 보여왔습니다 (Cohen et al., 2023; Kamalloo et al., 2024; He et al., 2024). 그러나 이러한 성능은 상당한 계산 비용을 동반하며, 특히 추론 단계에서 심각한 병목 현상이 되어 실시간 애플리케이션에서는 모델 배포의 장벽이 됩니다. 따라서 생성 품질을 손상시키지 않으면서 추론 비용을 줄이려는 요구가 커지고 있습니다.
이를 해결하기 위해, 기존의 많은 연구들 (Dao et al., 2022; Sahn et al., 2020; Kou et al., 2024; Anagnostidis et al., 2024)은 서로 다른 리소스와 복잡도를 가진 모델에 입력 쿼리를 다르게 분배하여 추론 비용을 줄이려고 했습니다. 직관적으로, SLM은 계산 자원이 적은 간단한 작업에, LLM은 복잡한 작업에 사용됩니다. 그러나 대부분의 기존 연구는 쿼리 전체를 하나의 모델(LLM 또는 SLM)에게만 전달합니다. 이로 인해, 쿼리 내 대부분의 토큰은 SLM으로 처리할 수 있음에도 불구하고, 소수의 중요한 토큰 때문에 전체를 LLM에 맡기는 문제가 발생합니다.
따라서 우리는 쿼리 내 각 토큰마다 다르게 라우팅할 수 있는 새로운 프레임워크인 CITER를 제안합니다. 이 프레임워크는 다음과 같은 전략을 따릅니다:
- SLM으로 처리할 수 있는 토큰은 효율성을 위해 SLM으로 전송.
- 생성 품질에 중요한 토큰만 LLM으로 전송.
이를 통해 생성 품질은 유지하면서도 추론 비용을 크게 절감할 수 있습니다.
그러나 이러한 구조에서는 중요한 문제 두 가지가 발생합니다:
- 어떤 토큰을 LLM에 보낼 것인지 결정하는 정책을 학습해야 함.
- 학습과정에서 정확한 보상 추정이 어렵기 때문에 보상 신호가 불안정함.
이를 해결하기 위해, 우리는 정책 훈련을 위한 보강학습(RL)과 단축 경로 기반 보상 추정(shortcut-based reward estimation)을 결합한 방식을 제안합니다. 이로 인해 라우터는 SLM과 LLM의 협력을 최적화하면서 각 토큰마다 라우팅 결정을 내릴 수 있습니다.
2. Token-Level Routing 기반 협력 추론 (Collaborative Inference with Token-LEvel Routing, CITER)
이 섹션에서는 CITER 프레임워크를 상세히 설명합니다. 이 프레임워크는 각 토큰을 LLM 또는 SLM에 라우팅함으로써 추론 비용을 줄이는 데 목적이 있습니다.
2.1 라우터 최적화를 위한 강화학습
우리는 마르코프 결정 과정(MDP)을 통해 이 문제를 모델링합니다. 상태(state)는 입력 및 출력 시퀀스이며, 행동(action)은 LLM 또는 SLM을 선택하는 것입니다. 보상은 모델 선택에 따라 달라지는 응답 품질과 계산 비용을 고려한 값으로 정의됩니다. 이로써 각 토큰의 상태-행동 가치 함수(state-action value function) 를 다음과 같이 정의합니다:
최적 정책은 다음과 같이 얻을 수 있습니다:
여기서 는 prior policy (보통 LLM/SLM 선택 확률)이고, KL은 Kullback-Leibler divergence입니다.
2.2 선호 기반 토큰 레벨 정책 최적화
일반적으로, 상태-행동 가치 함수 와 최종 보상 는 모델이 액션 를 선택한 후 받는 보상 값이며, 이는 정책 학습 시 중요한 피드백 신호입니다. 그러나 이러한 보상 신호는 라우터 학습의 각 단계에서 발생할 수 있는 편향(bias)을 완화하기 위해 안정적으로 추정되어야 합니다.
이를 해결하기 위해, 우리는 Bradley-Terry 모델 (Bradley & Terry, 1952)을 사용하여 다음과 같이 선호 확률을 정의합니다:
📌 식 (3):
- 여기서 는 시그모이드 함수입니다.
- 이 식은 SLM이 LLM보다 더 선호되는 경우의 확률을 의미합니다.
- 는 "SLM이 LLM보다 우선이다"라는 선호 관계를 나타냅니다.
이제 위의 확률을 좀 더 해석하기 위해 Rafailov et al. (2024)의 접근을 따릅니다. 이들은 상태 sis_i에서 각 행동 aa에 대해 다음과 같은 선호 기반 보상 함수를 정의합니다:
📌 식 (4):
- 여기서:
- 는 현재 학습 중인 정책 (라우팅 분포)
- 는 사전 정책(prior policy), 예: 균등 분포
- 는 trade-off를 조절하는 하이퍼파라미터입니다
📌 식 (3)을 식 (4)에 대입하면, 다음과 같이 확률을 다시 표현할 수 있습니다:
📌 식 (3)을 다시 쓰면 → 식 (수정된 3):
- 이 식은 SLM이 LLM보다 선호될 확률을 정책 분포와 사전 분포의 비율로 나타낸 것입니다.
따라서 주어진 상태 와 선호 레이블 가 존재할 경우, 라우터는 다음의 cross-entropy loss를 최소화하도록 학습됩니다:
📌 식 (5): 최종 손실 함수
- 이 손실 함수는 선호되는 행동에 높은 확률을 할당하도록 라우팅 정책을 훈련합니다.
- 는 indicator 함수이며, 특정 행동이 선호되는지를 나타냅니다.
✅ 요약
| 구성 요소 | 설명 |
|---|---|
| 라우팅 정책 함수 (SLM vs. LLM) | |
| 사전 분포 (보통 균등분포) | |
| 보상과 KL regularization의 trade-off를 조정하는 하이퍼파라미터 | |
| 선호 기반 교차 엔트로피 손실 함수 | |
| ( ) | |
| 상태 에서의 행동 aa의 보상 기대값 (value function) |
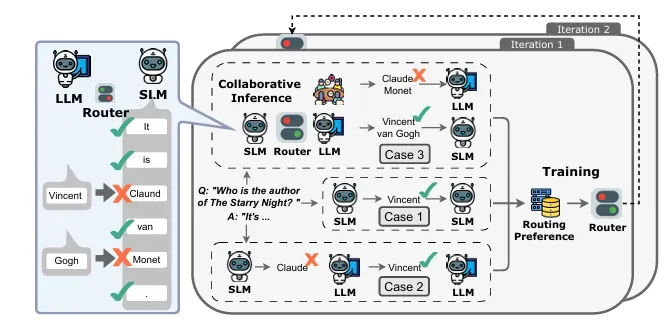
Figure 1 설명
그림 1: CITER의 개요. 라우터는 SLM과 LLM 간의 협업 추론을 수행하기 위해 사용됩니다. 라우터는 세 가지 경우에 따라 토큰을 라우팅합니다.
- Case 1: SLM이 정답을 예측하면 해당 토큰은 SLM에 라우팅됩니다.
- Case 2: SLM이 오답을 예측하고, LLM이 정답을 예측하면 해당 토큰은 LLM에 라우팅됩니다.
- Case 3: SLM과 LLM 모두 오답을 예측한 경우, 전체 응답 생성을 통해 추론 정확도를 평가하고 그 결과를 라우팅 결정에 사용합니다.
2.3 라우팅 선호도 획득 (Acquiring Token-Level Routing Preference)
이 절에서는 상태 에서의 선호 레이블 을 얻는 전략을 설명합니다. 우선, SLM으로 다음 토큰 을 생성하게 하여 문장을 완성시킨 후, 생성이 끝날 때까지 전체 응답을 생성합니다. 이 응답을 기반으로, 현재 시점에서 SLM이 정답을 생성한 경우에는 SLM이 더 적절한 선택으로 간주됩니다.
하지만, 전체 응답 생성을 통한 평가 방식은 계산 비용이 높기 때문에, 최종 응답 sHsH를 직접 생성하는 대신 단축(shortcut) 방법을 사용합니다. 구체적으로, 다음 토큰 $y{i+1}$이 ground truth와 일치하면 SLM이 선호되고, 그렇지 않으면 LLM이 선호됩니다.
이때 두 모델 모두 오답을 예측한 경우에만 전체 응답 생성을 수행하여 판단을 내립니다. 이를 통해 전체 응답 생성을 줄이고 효율적인 라우팅 선호도 수집이 가능해집니다.
2.4 제안된 알고리즘 (Proposed Algorithm)
우리는 알고리즘 1에서 CITER의 정책 학습 과정을 요약합니다. 이 알고리즘은 라우팅 정책 를 반복적으로 업데이트하며, 각 라운드마다 라우팅 선호 를 수집합니다.
- 약 80% ~ 90%의 토큰은 SLM 또는 LLM 중 하나가 정답을 맞출 수 있으므로, shortcut 방법을 통해 효과적으로 보상을 추정할 수 있습니다.
- 정책은 cross-entropy loss를 통해 학습되며, 다음 식으로 정의됩니다:
Algorithm 1: CITER의 라우터 최적화 (Preference-based Router Optimization)
- 학습 데이터 및 모델 초기화
- 정책 와 선호도 집합 초기화
- 각 라운드마다:
- 프롬프트-응답 쌍에 대해
- SLM과 LLM의 다음 토큰 예측 비교
- SLM이 정답 →
- LLM이 정답 →
- 둘 다 실패 → 전체 응답 생성 후 더 나은 모델 판단
- 판단 결과 저장
- 선호 집합 업데이트
- 프롬프트-응답 쌍에 대해
- 정책 업데이트
- 최종 라우팅 정책 반환
Algorithm 2: 토큰 단위 라우팅 기반 협력 추론 (Collaborative Inference with Token-Level Routing)
- 입력 토큰 x에 대해, 각 토큰에 대해 정책 가 SLM 또는 LLM 중 하나를 선택하여 응답 생성
- SLM이
<EOS>를 생성하면 종료 - 라우팅은 반복적으로 수행됨
3. 실험 (Experiments)
이 절에서는 다음 질문에 답하기 위한 실험을 설계합니다:
- 기존 연구에 비해 LLM 추론 효율성을 얼마나 향상시키는가?
- 각 구성 요소는 프레임워크 성능에 어떤 영향을 미치는가?
- 라우터 훈련 과정이 성능 향상에 기여하는가?
- 최종 응답의 품질은 SLM만 사용했을 때보다 향상되는가?
- 중요 토큰과 비중요 토큰을 구별할 수 있는가?
3.1 실험 설정
- 데이터셋: Commonsense QA, GSM8K, MATH 등 총 5개의 벤치마크 데이터셋 사용
- 정확도 및 FLOPs 기준으로 평가
- 비교 대상:
- RouteLLM (쿼리 레벨 라우팅)
- Co-LLM (토큰 레벨 라우팅)
- Speculative Decoding (비 라우팅 기반)
3.2 전체 성능 (Overall Performance)
- Figure 2는 정확도 대비 FLOPs(연산량) 성능 곡선을 보여줌
- CITER는 모든 데이터셋에서 Co-LLM과 함께 RouteLLM보다 높은 효율성과 정확도를 달성함
- CommonsenseQA, GSM8K에서 최대 30% 연산량 절감, 또는 같은 연산량에서 12% 정확도 향상
- Speculative Decoding은 오히려 FLOPs 증가
- CITER는 최대 27% 연산량 감소 또는 17% 정확도 향상 가능
3.3. 장기 영향력 분석 (Analysis of Long-Term Influence)
이 절에서는 라우팅 결정의 장기적인 영향이 CITER 성능에 미치는 효과를 분석하기 위해 CITER-S라는 제거 실험(ablative variant)을 설계했습니다. CITER-S는 SLM과 LLM 모두 라우팅 선호도 수집 과정에서 잘못된 예측을 했을 경우에도 이를 그대로 반영하며, 라우팅 결정의 장기적인 영향을 무시합니다.
- 결과는 Figure 3에 나와 있습니다.
- CITER는 모든 데이터셋에서 CITER-S보다 훨씬 우수한 성능을 보였습니다.
- 연산 비용을 최대 42%까지 절감
- 동일한 연산량으로 정확도 최대 23% 향상
이는 라우팅 결정에서 장기적인 영향을 고려하는 것이 얼마나 중요한지를 보여줍니다.
3.4. 반복 학습의 효과 (Analysis of Iterative Training Process)
라우터의 반복 학습 효과를 강조하기 위해, 우리는 CITER의 반복 라운드별 성능을 Figure 5에서 보여줍니다.
- 첫 번째에서 두 번째 반복으로 넘어가며 성능이 향상됨
- 예: 동일한 정확도에서 연산 비용 5% 절감
- 혹은 동일한 연산 비용에서 정확도 2~3% 향상
이 결과는 CITER가 반복 학습을 통해 라우팅 정책을 점차 개선해 간다는 점을 보여주며, 빠른 수렴 속도 또한 확인됩니다.
3.5. 다양한 모델 간 호환성 (Compatibility Analysis)
우리는 CITER가 다른 모델에도 적용 가능한지를 확인하기 위해 LLaMA 3.1 시리즈를 사용한 실험을 진행했습니다.
- LLaMA 3.1-70B → LLM
- LLaMA 3.1-8B → SLM
Figure 6의 결과에서 알 수 있듯, 다른 모델에서도 CITER는:
- 최대 32% 연산 절감
- 동일 연산량에서 최대 5% 정확도 향상
이는 CITER가 다양한 모델 쌍에서도 효과적임을 보여줍니다.
3.6. SLM 크기의 영향 분석 (Analysis of the Impact of SLM Model Size)
우리는 SLM 모델 크기를 변화시키며 CITER의 성능을 측정했습니다:
- SLM: Qwen-1.5B ~ Qwen-7B로 실험
- LLM은 Qwen-7B로 고정
결과 (Figure 4):
- SLM이 클수록 정확도는 올라가고, 연산 비용은 줄어듦
- 예: Qwen-7B 사용 시, Qwen2-1.5B보다 최대 11% 더 높은 정확도, 최대 10% 연산 절감
단, 일정 크기 이상부터는 성능 향상이 둔화되며 비용 대비 이점이 사라집니다. 이는 SLM이 너무 커지면 오히려 비효율적일 수 있음을 의미합니다.
3.7. 사례 연구: 라우팅 분석 (Case Study Analysis on the Router)
CITER가 어떻게 중요한 토큰과 중요하지 않은 토큰을 구분하는지 실례를 통해 보여줍니다.
- 문장: "The first occurrence of the answer 'Midwest' and the word 'fertile'..."
- CITER는 "fertile"을 LLM에, 그 외 토큰은 SLM에 라우팅하여 정답 도출
- 반면, Co-LLM은 시간 관련 단어 "morning"을 SLM으로 잘못 보냄
- "afternoon meal" → Co-LLM은 "day"를 LLM으로 보내고 "has already eaten"을 놓침
- CITER는 해당 문장을 적절히 LLM에 전달하여 올바른 응답 생성
➡️ 요약: CITER는 중요한 토큰과 중요하지 않은 토큰을 효과적으로 구별하며, SLM과 LLM을 조합하여 최종 생성 품질을 높입니다.
4. 관련 연구 (Related Work)
이 절에서는 기존의 LLM 추론 가속화 방법에 대해 다룹니다.
1) 쿼리 수준 라우팅 (Query-Level Routing Mechanisms)
- RouteLLM (Ong et al., 2024): 전체 쿼리를 LLM이나 SLM 중 하나에 통째로 전달
- 문제점: 중요하지 않은 토큰까지 LLM에 전달하여 비효율 발생
- 해결책: CITER처럼 토큰 단위 세밀한 제어가 필요
2) 토큰 수준 라우팅 (Token-Level Routing Mechanisms)
- CITER와 같은 방식
- 기존 방식(Pfeiffer et al., 2021; Xu et al., 2024 등)은 토큰을 다양한 전문가 모델에 라우팅
- 하지만 대부분 연산 비용 고려 X → CITER는 연산 효율성도 함께 고려
다른 추론 가속화 기법들 (Other Methods for LLM Inference Acceleration)
- Speculative Decoding (Leviathan et al., 2023): SLM이 후보 토큰 여러 개를 생성 → LLM이 검증
- 단점: FLOPs는 줄지 않고 오히려 증가
- LoRA 기반 전문가 혼합: 여러 LoRA를 활용해 추론 중 동적으로 선택 (Chen et al., 2024)
- CITER와 달리 현재 토큰 외의 장기 영향 미고려
➡️ CITER는 토큰별 예측 결과뿐만 아니라 라우팅 결정의 장기 영향까지 반영하여 더 정확하고 효율적인 추론 가능
5. 결론 (Conclusion)
본 논문에서는 Token-Level Routing 기반 협력 추론 프레임워크인 CITER를 제안했습니다. CITER는 다음과 같은 특징을 가집니다:
- 비중요 토큰은 SLM으로 라우팅하여 효율성 확보
- 중요 토큰은 LLM으로 라우팅하여 고품질 생성 유지
- 라우터는 품질과 비용을 모두 고려한 정책 최적화 방식으로 훈련
- 보상 추정 단축 방법을 도입하여 학습 효율 향상
- 벤치마크 데이터셋 전반에서 연산량 최대 42% 절감, 정확도 최대 23% 향상
➡️ CITER는 실시간 및 자원 제약 환경에서 고성능 LLM을 보다 효율적으로 사용할 수 있는 실용적이고 강력한 방법임을 입증했습니다.
