https://arxiv.org/pdf/2505.21600

1) 논문이 풀려는 문제: “SLM은 빠른데, 추론 경로가 자꾸 엇갈린다”
LLM(대형 모델)은 CoT 기반 장문 추론에서 성능이 좋지만 추론 비용/지연이 너무 큼.
SLM(증류된 소형 모델)은 빠르지만, LLM과 달리 추론 경로(reasoning path)가 조금씩 어긋나면서 결과가 크게 망가집니다.
논문 핵심 관찰은 매우 강력합니다:
- SLM과 LLM의 토큰 단위 next-token 예측은 대부분 일치하거나,
- 달라도 의미가 유지되는 “중립적(neutral) 차이”인 경우가 많고,
- 실제로 추론 경로를 갈라버리는 “발산(divergent) 토큰”은 소수라는 점입니다.
즉, “전체를 LLM으로 돌릴 필요 없이, 발산 토큰만 LLM으로 교정하면 된다”가 출발점입니다.
2) R2R의 핵심 아이디어: “토큰 단위 라우팅 + 발산 토큰만 LLM 호출”
(1) 토큰을 3종류로 분류
SLM과 LLM이 같은 prefix(지금까지 생성된 토큰들)에서 다음 토큰을 예측할 때:
- Identical: next token 동일
- Neutral: next token 다르지만 의미/추론 흐름에 영향 없음 (표현 차이, 약어 등)
- Divergent: next token 차이가 의미·논리·결론을 바꿔 이후 reasoning path를 갈라버림
R2R는 Divergent 토큰만 LLM으로 생성(혹은 교정)하고, 나머지는 SLM이 계속 생성합니다.
3) 방법론 #1: “Divergent 토큰 라벨을 자동으로 만드는” 데이터 생성 파이프라인
논문의 실질적인 기여는 토큰 라벨을 인간 없이 자동 생성하는 전략입니다.
왜냐하면 토큰 라우팅을 학습하려면 (SLM 토큰을 LLM로 바꿔야 하는지) 정답 라벨이 필요하기 때문입니다.
(1) Token-level routing을 최적화 문제로 공식화
각 디코딩 step (i)에서 라우터가 선택한 모델 (m_i \in {\theta_s, \theta_l})로 다음 토큰을 생성합니다.
- 목표: 총 비용 최소화
- 제약: LLM-only 결과와 동등한 품질 유지
이때 품질 비교는 verifier (V) (동등하면 1)로 표현합니다.
(2) Path-following 라벨링 전략 (핵심)
전역적으로 “최적 라우팅 시퀀스”를 찾으면 경우의 수가 ()이라 불가능합니다.
그래서 R2R는 LLM의 reasoning path를 정답 경로로 고정하고, SLM이 그 경로를 따라가도록 라벨을 만듭니다.
Step A. LLM이 먼저 “정답 reasoning path”를 생성
- 각 문제에 대해 LLM(예: R1-32B)이 CoT 포함 응답을 생성합니다.
Step B. SLM prefill로 “다른 토큰” 후보만 추림
- SLM이 LLM 응답 prefix를 따라가며 next-token 예측을 하고
- LLM next-token과 다르면 후보(different token)로 마킹
- 이 단계에서 약 90% 토큰은 identical이라 바로 SLM로 확정할 수 있어 매우 싸게 걸러집니다.
Step C. 다른 토큰이 나오면 “중립 vs 발산” 판별을 위해 LLM continuation 수행
“SLM 토큰을 채택했을 때 vs LLM 토큰을 채택했을 때” 이후가 어떻게 달라지는지 봅니다.
- (S_s): SLM 토큰을 붙인 뒤 LLM으로 문장(또는 EOS)까지 continuation
- (S_l): LLM 토큰을 붙인 뒤 LLM으로 문장(또는 EOS)까지 continuation
Step D. Verifier LLM이 두 continuation을 비교해 Neutral/Divergent 판정
논문에서는 full-response 검증 대신 문장 단위(sentence-level) 검증으로 비용을 줄입니다.
즉, “이 차이가 지금 문장 의미를 바꿔서 추론 경로가 갈라지나?”를 다른 강한 LLM(예: Qwen2.5-72B)로 판정합니다.
✅ 결론 라벨:
- identical 또는 neutral → SLM 사용 라벨
- divergent → LLM 사용 라벨
이렇게 해서 토큰 단위 supervision 데이터(7.6M labels)를 자동 생성합니다.
(3) 데이터 규모와 비용
- 총 2,094개 쿼리에서 7.6M 토큰 라벨
- 8×A800 GPU에서 약 2.3일(논문 본문 기준) 수준으로 생성했다고 보고합니다.
4) 방법론 #2: Divergence 예측용 “Neural Token Router” 설계
라벨링은 오프라인에서 LLM을 잔뜩 써도 되지만, 실제 서빙에서는 매 토큰마다 continuation/검증을 할 수 없습니다.
따라서 R2R는 “지금 토큰이 divergent인지”를 즉시 예측하는 경량 라우터를 학습합니다.
(1) Router가 보는 입력 피처 (중요)
논문이 “왜 이 라우터가 되는가”를 보여주는 부분이 바로 지표 분석입니다.
1) SLM 불확실성(Entropy 등)
- divergent 토큰에서 SLM logits의 엔트로피가 크게 증가
- 즉 SLM이 “확신이 없을 때” 발산 가능성이 큽니다
2) Token rarity (빈도 낮은 토큰일수록 발산 확률↑)
- 희귀 토큰(롱테일)은 SLM이 잘 모델링 못해 발산 가능성이 큼
그래서 router 입력으로 다음을 사용합니다:
- top-100 logits 값
- 예측 토큰 embedding
- SLM last-layer hidden state(문맥 의미 피처)
(2) Router 아키텍처
- 약 56M 파라미터
- 5~6 layer FFN(Residual 포함) 기반의 binary classifier
- 출력: “이 토큰은 divergent인가?” 확률 (p_{\text{div}})
학습은 class imbalance(발산 토큰이 적음) 때문에 가중치 부여한 BCE/CE loss를 사용합니다.
5) 방법론 #3: 실제 추론(inference) 라우팅 스킴
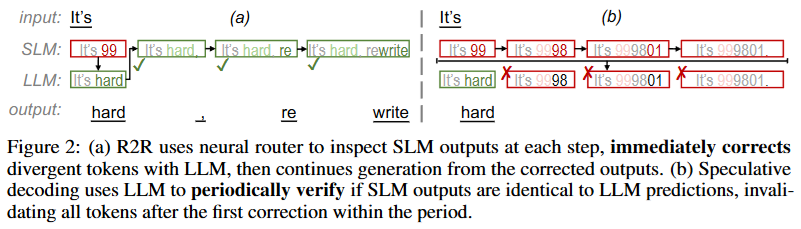
Speculative Decoding처럼 “몇 토큰 뽑고 검사하고 rollback”이 아니라, R2R는:
- SLM이 1토큰 생성
- Router가 즉시 divergent 확률 판단
- divergent면 그 “현재 토큰만” LLM이 생성해서 교정
- 이후 생성은 교정된 prefix로 SLM이 계속 진행
즉, rollback이 없고, “토큰 하나 단위로 즉시 수정”합니다.
Threshold로 비용-성능 트레이드오프 조절
Router threshold (p_{th})를 올리면:
- LLM 호출 ↓ → 비용/지연 ↓
- divergent recall ↓ → 성능 ↓
내리면 반대로 성능은 올라가지만 LLM을 더 쓰게 됩니다.
6) 실험 세팅 및 비교 대상
사용 모델
- SLM: DeepSeek-R1-Distill-Qwen-1.5B
- LLM: DeepSeek-R1-Distill-Qwen-32B
- 비교: 중간 증류 모델(R1-7B, R1-14B) + Query-level routing(RouteLLM 계열) + SpecDec(EAGLE2, HASS)
벤치마크
- AIME (수학)
- GPQA-Diamond (고난도 QA)
- LiveCodeBench (코딩)
7) 결과 요약: “5.6B 평균 활성 파라미터로 14B급을 넘김”
논문이 강조하는 효율 지표는:
- Average Activated Parameters per Token (토큰당 평균적으로 몇 B 파라미터를 “쓴 셈”인지)
결과:
- R2R 평균 활성 파라미터 약 5.6B
- 성능은 R1-7B 평균 대비 1.6×, 심지어 R1-14B도 평균적으로 상회
- R1-32B 대비 벽시계 속도 2.8× 가속, 성능은 거의 유지
이게 의미 있는 이유는,
query-level routing은 “한 문제를 통째로” SLM/LLM 중 하나로 보내서 혼합 난이도(중간에 어려운 부분만 있는 경우)에서 비효율이 생기는데,
R2R는 딱 필요한 토큰만 LLM을 쓰므로 Pareto frontier를 당겼다는 주장입니다.
8) Ablation에서 드러난 핵심 포인트
(1) “different 토큰” 전체를 LLM으로 보내면 오히려 성능이 떨어짐
핵심은 neutral을 허용해야 비용을 최소화하면서 경로만 유지할 수 있다는 것.
(2) Router 입력 피처 제거 시 성능 하락
- logits / token embedding이 divergence 예측에 중요함을 확인합니다.
9) 이 논문이 기존과 다른 점 (정리)
Query-level routing vs R2R
- Query-level: “한 문제 통째로 큰 모델”
- R2R: “문제 내부에서도 추론이 갈리는 토큰만 큰 모델” → 더 미세하고 더 효율적인 배분
Speculative decoding vs R2R
- SpecDec: “LLM과 출력이 동일해야 통과” → acceptance rate 낮고, rollback 비용 큼
- R2R: “neutral 차이 허용 + divergent만 즉시 교정” → rollback 없음
