TL;DR
SLM이 먼저 초안(draft)을 만들고, 각 서브쿼리 단계에서 Retain / Revise / Rewrite를 고르는 반추(reflective) 라우팅.
토큰-레벨 스위칭 없이 소수의 재검토 지점만 사용해 LLM 호출 최소화 + 정확도 유지/향상.
목차
- 1) 한눈에 요약
- 2) 왜 필요한가?
- 3) 방법론
- 4) 실험 설정
- 5) 결과 요약
- 6) Ablation & 민감도
- 7) 한계 & 향후 과제
- 8) 구현 메모
- 9) 내 역할
- 부록 A: 프롬프트 예시
- 부록 B: 표(예시 포맷)
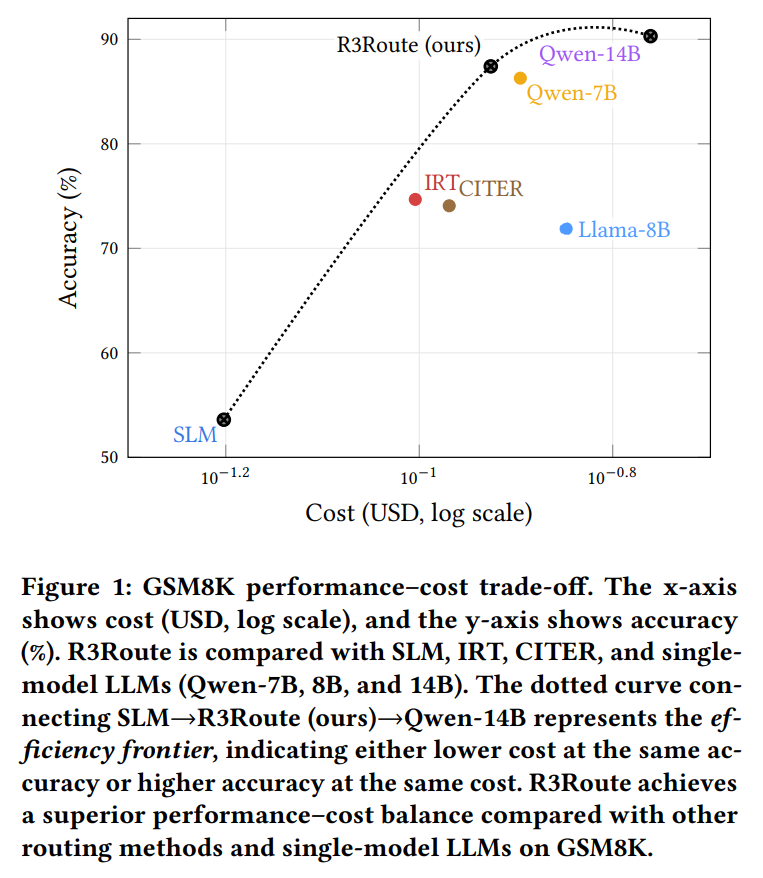
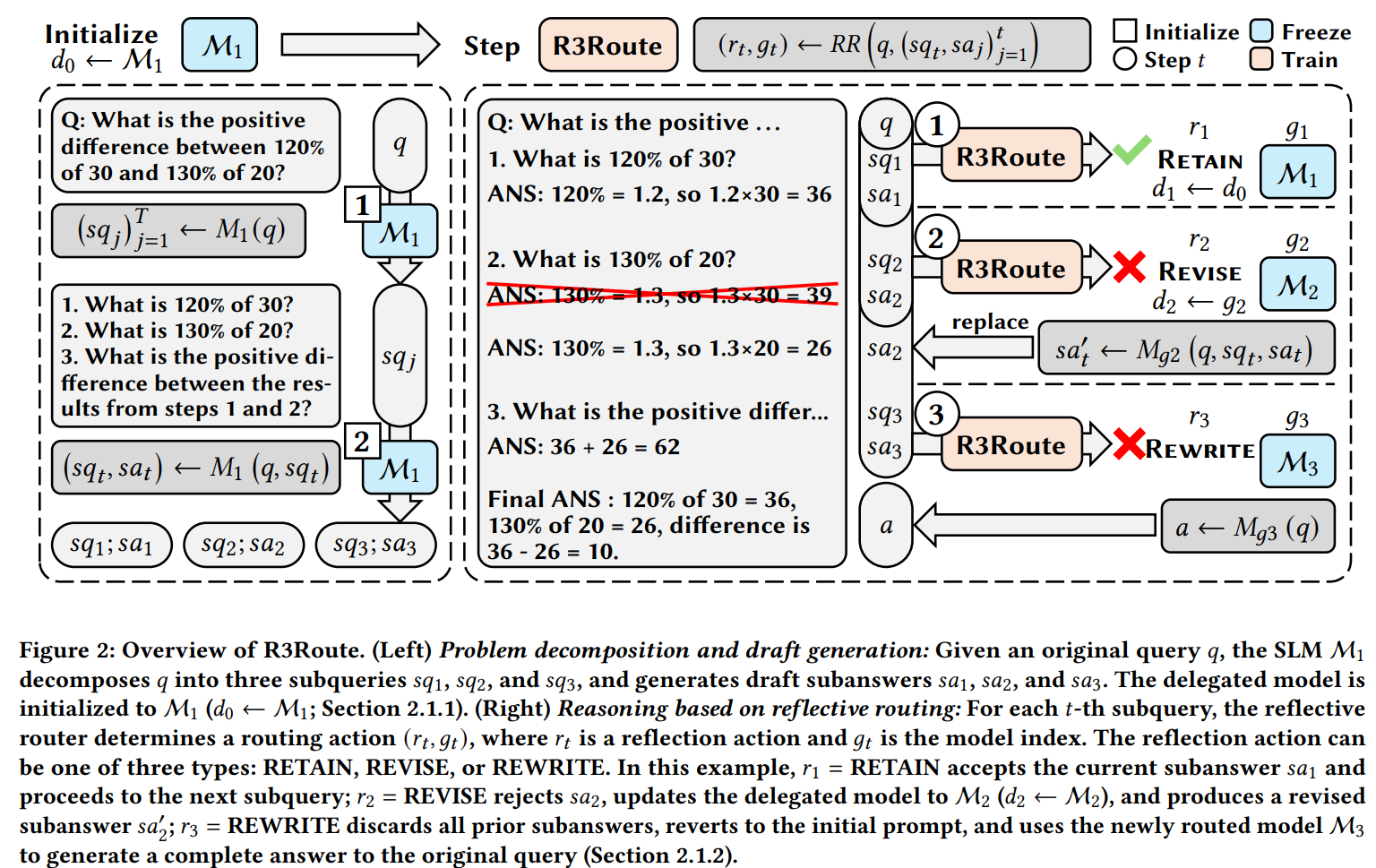
1) 한눈에 요약 (Abstract in 5 lines)
- 문제: 쿼리-레벨 1회 결정은 복잡 질의에 취약; 토큰-레벨 라우팅은 스위칭/KV 재계산 오버헤드가 큼.
- 아이디어: SLM이 문제를 서브쿼리로 분해하여 초안을 만들고, 각 단계에서 Retain/Revise/Rewrite를 선택.
- 라우터: 경량 GRU가 초안 품질·임베딩·간단 신뢰 신호를 받아 행동과 모델을 동시 예측.
- 효과: 여러 벤치마크에서 정확도–비용 절충(ΔAcc/ΔCost)이 단일 LLM·기존 라우터 대비 우수.
- 포지셔닝: 토큰-레벨(CITER) 대비 오버헤드↓, 쿼리-레벨(IRT-Router/RouterDC) 대비 정답 유지력↑.
2) 왜 필요한가? (Motivation)
- 쿼리-레벨 1회 결정은 중간 산출물을 보지 못해 되돌리기 어려운 오판이 생김.
- 토큰-레벨 협업은 세밀하지만 전환마다 프리필·KV 캐시 초기화 등 숨은 비용이 큼.
- 실제로는 몇몇 핵심 단계만 어려운 경우가 많아, 단계(서브쿼리) 수준에서 LLM을 선택적으로 투입하는 전략이 합리적.
3) 방법론 (Methods)
3.1 문제 분해 & 초안 생성
SLM M1이 원 쿼리 q를 서브쿼리 시퀀스 (sq_t)로 만들고, 각 단계의 초안 서브답 (sa_t)를 생성한다.
표기(블록 수식은 Velog 규칙에 따라 $$ … $$)
3.2 반추(Reflection) 라우팅
각 단계 t에서 라우팅 모듈 RR이 행동 r_t∈{retain, revise, rewrite}와 (필요 시) 모델 인덱스 g_t를 예측한다.
- Retain: 초안을 수용하고 다음 단계로 진행
- Revise: 선택 모델
M_{g_t}로 해당 단계만 국소 수정 - Rewrite: 선택 모델
M_{g_t}로 전체 답 전면 재생성 - 단계 종료 후 Aggregate(요약/정리)
3.3 라우터 구조 (GRU + Heads)
입력 특징 x_t → MLP → GRU → MLP(행동/모델) 두 갈래.
주요 입력 특징 x_t
- 문장 임베딩:
emb(sq_t),emb(sa_t), 누적 컨텍스트emb(H_{1:t-1}) - 신뢰 신호: 엔트로피/마진(1–2위 로그확률 차), 괄호/숫자 비율 등 간단 품질 지표
- 모델 대리 임베딩과의 유사도(간이 모델 적합도)
3.4 학습 (SFT → RL)
- 라벨링: 가능한 라우팅 궤적(trajectory) 중 정답을 달성하는 집합에서 최소비용 궤적을 gold로 선택
- SFT: hard CE + soft CE(라벨 스무딩), margin(hinge), consistency(R-Drop) 보조항
- RL(그룹 상대/LOO): SFT 정책으로 샘플링한 행동을 leave-one-out 기준선으로 보상화해 정책 경사(초기 KL/Entropy 정규화로 안정화)
3.5 추론

4) 실험 (Setup)
벤치마크
- 산술/추론/상식 혼합:
GSM8K,MATH,CSQA,OpenBookQA,RACE-Middle(추가:P3,SCAN)
모델 풀(예)
- SLM: Qwen2.5-1.5B-Instruct
- LLM: Qwen2.5-7B / Llama-3.1-8B / Qwen2.5-14B-Instruct
비교군
- 단일 모델(7B/8B/14B)
- 라우팅: CITER(토큰-레벨), RouterDC(대조학습 쿼리-레벨), IRT-Router(IRT 기반), R2-Reasoner(분해·할당 강화)
지표 & 비용
- Accuracy, Cost(USD/토큰), ΔAcc/ΔCost(SLM 대비 1달러당 정확도 이득)
- 비용 회계: 프리필/핸드오프 포함, SLM 분해/초안 비용 포함, 통일된 프롬프트 정책/가격표
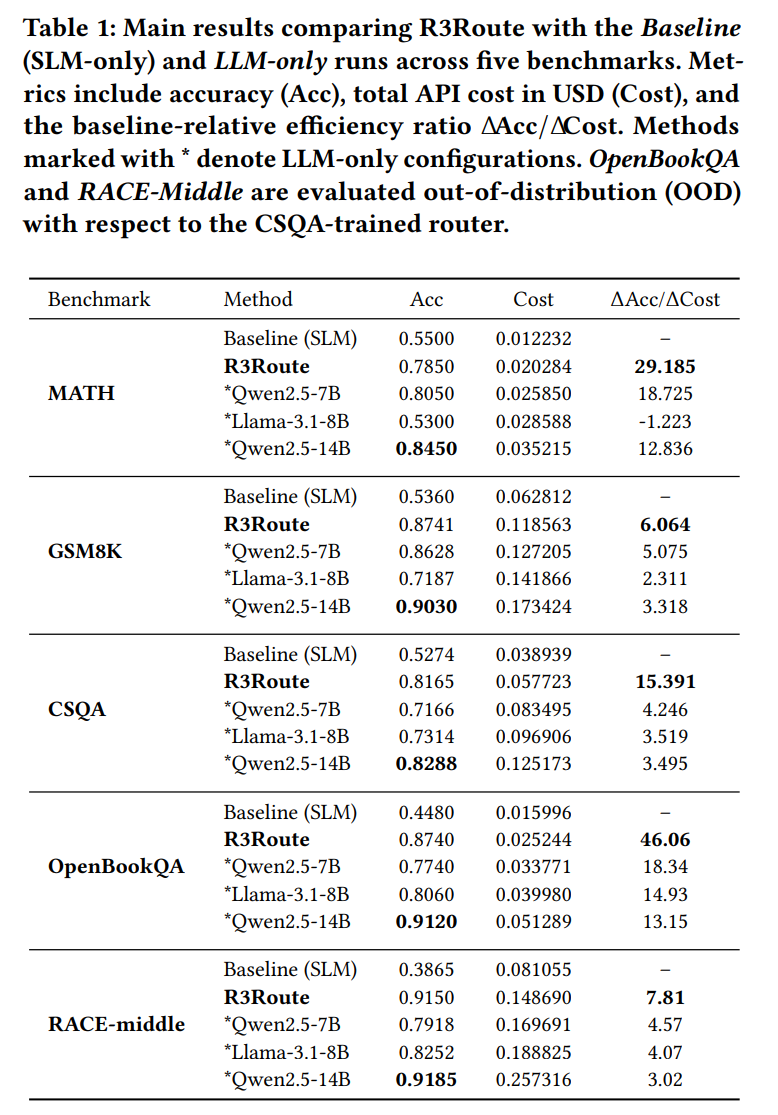
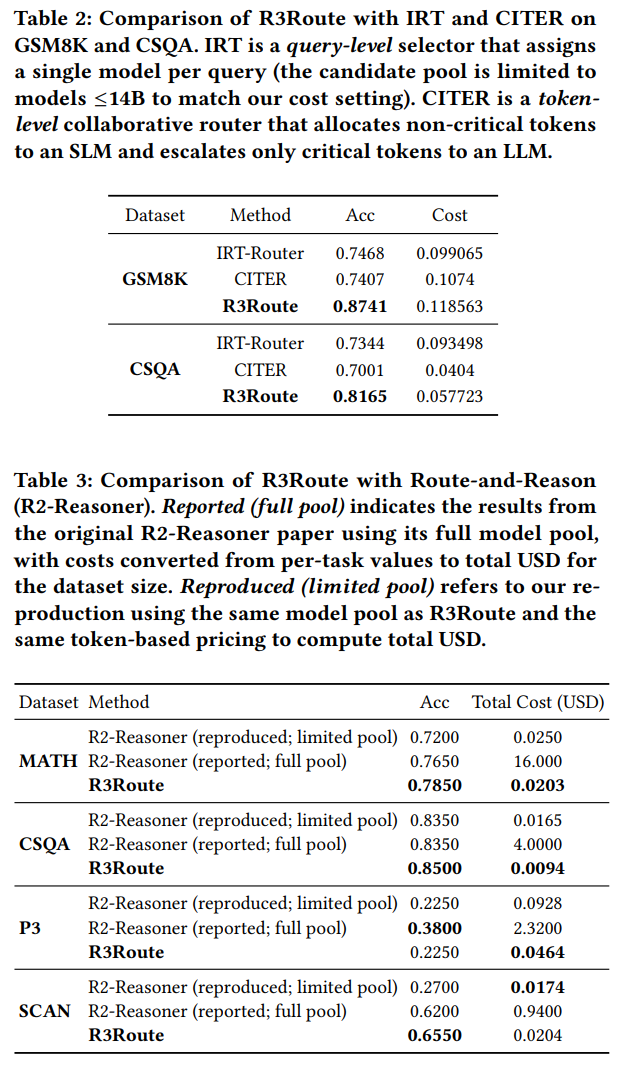
5) 결과 요약 (Highlights)
- 단일 모델 vs R3Route: 복잡 질의에서 14B-only에 근접한 정확도, 비용은 유의미하게 절감
- 라우팅 비교
- CITER 대비: 스위칭/프리필 오버헤드 없음 → 시간·비용 안정성↑
- RouterDC 대비: 중간 산출물을 보고 단계별 재결정 가능 → 정답 유지력↑
- IRT-Router 대비: 난이도 기반 1회 결정 대신 서브쿼리별 선택 → 복잡 문제 대응력↑
- R2-Reasoner 대비: 실행 전 고정 분해가 아니라 초안 이후 반추 → 호출 수↓로 유사 성능
핵심: 필요한 순간에만 큰 모델을 쓰고, 나머지는 SLM 초안을 유지/부분 수정해 ΔAcc/ΔCost가 높다.
6) Ablation & 민감도
- Revise vs Rewrite 비중: Rewrite↑ → 정확도↑/비용↑, Revise 중심 → 비용↓/정확도 소폭↓
- GRU 은닉 차원/윈도우: 작은 차원으로도 충분(경량); 창이 너무 크면 잡음↑
- 신뢰 신호(엔트로피·마진 등) 제거 시 라우팅 임계 판단 흐려져 효율 저하
- SLM 분해 품질이 좋을수록 Retain 비율↑ → 전체 비용↓
7) 한계 & 향후 과제
- 다중 턴/툴 호출 시나리오로의 확장(상태 의존 라우팅)
- 비용 회계 민감성: 가격표·프롬프트 길이·핸드오프 포함 여부에 따라 순위가 달라질 수 있음(재현용 스크립트 공개 권장)
- 학습형 스팬/검증기 결합으로 Revise 타겟 구간 자동 정밀화

NLP 공부합니당