https://openreview.net/pdf?id=X4jyt8DWHN
🔥 StepRoute: Step-wise Reflective Routing 정리
“Cost-aware LLM routing을 step 단위에서 수행하는 방법”
1. 📌 Problem Setting
LLM 기반 추론에서의 목표는 다음과 같다:
정확도를 유지하면서 비용을 최소화하는 것
Model Pool 정의
M=M1,M2,…,MK
- ( M1 ): Small Language Model (SLM)
- ( M2,…,MK ): Large Language Models (LLMs)
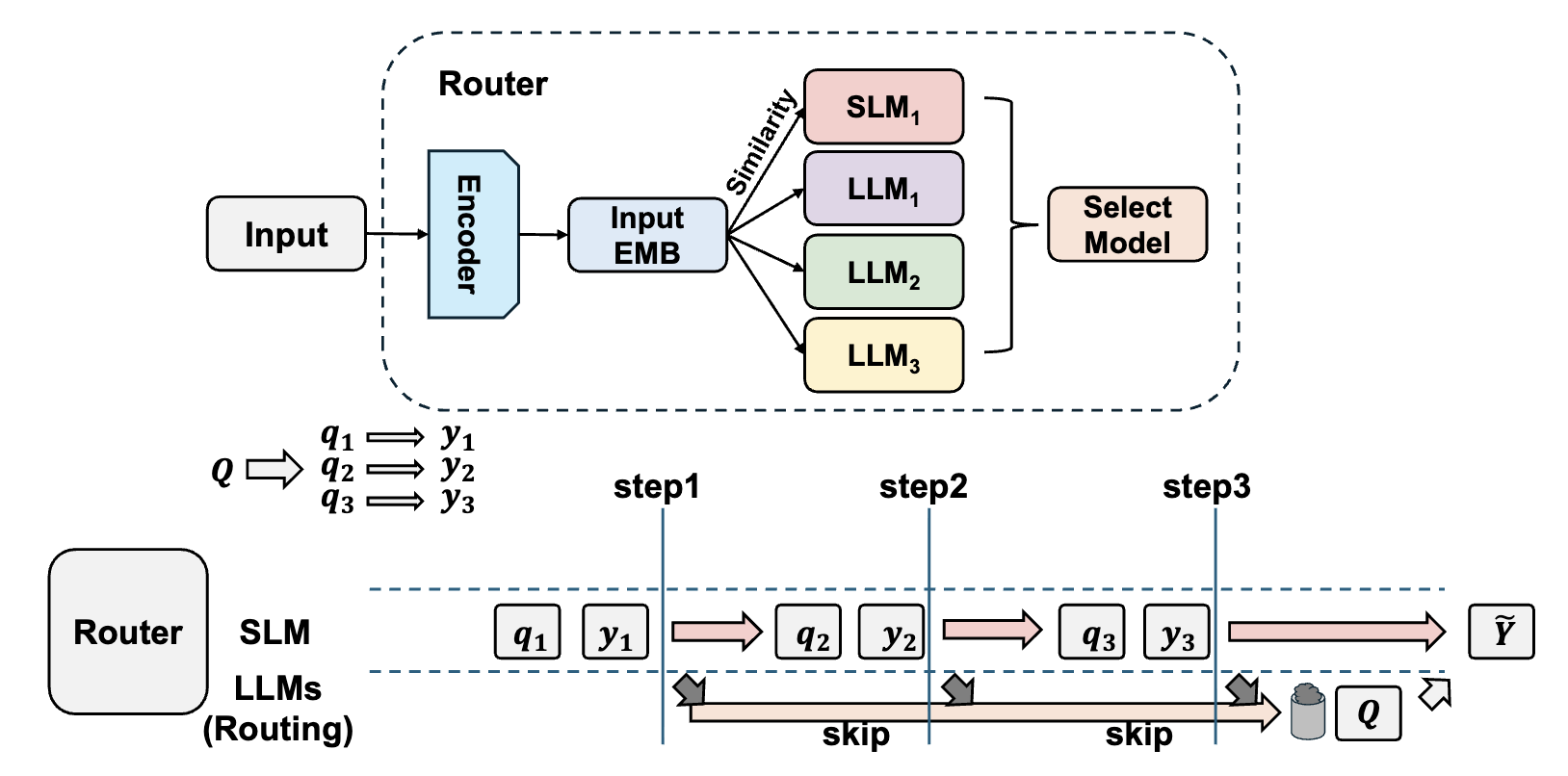
2. 🧠 Inference Pipeline
StepRoute는 3단계로 구성된다.
(1) Step Decomposition
SLM이 입력을 여러 step으로 분해:
(st)t=1T=M1(Idec(q))
(2) SLM Chain Generation
ychain=M1(Ichain(q,(st)t=1T))
- step별 chunk ( ct )
- SLM 답 ( a^SLM )
(3) Step-wise Routing
각 step에서 routing 수행:
3. 🎯 Routing Decision Space
각 step에서 action:
p=(g,m)
- ( g∈0,1 )
- ( g=0 ): SLM 유지
- ( g=1 ): LLM 호출
- ( m∈1,…,K )
Action Space
P=(0,1)∪(1,m):m∈2,…,K
4. 🧩 Routing Context
각 step에서의 입력:
Xt=(q,st,Ht,ct)
- ( Ht ): 이전 step 요약
- ( ct ): 현재 reasoning chunk
5. 🧠 Router Parameterization
Context Embedding
ht=Pool(EncSLM(ser(Xt))),qt=norm(Wht)
Pair Scoring
s(p∣Xt)=⟨qt,eg(g)⟩+bg(g)
- ⟨qt,em(m)⟩+bm(m)
- bp(p)
Policy
πθ(p∣Xt)=softmax([s(p∣Xt)]p∈P)
6. 🎯 Supervised Learning
Soft Target
y~t(p)=(1−ρs)e(pt∗)(p)
- ρs,ut(p)
Loss
LSFT=CE(st,y~t)
7. 🚀 Reinforcement Learning (GRPO)
StepRoute의 핵심은 routing을 policy optimization 문제로 보는 것이다.
Sampling
pt(j)j=1G∼πθ(⋅∣Xt)
Reward 구성
(1) Base Reward
R(j)base=Igate
- γ1Imodel
- γ2Imiss
- γ3Istay
(2) Contrastive Reward
Δt=sim(pt∗)−maxp=pt∗sim(p)
Rctr(j)={max(0,Δt)p=pt∗ −max(0,Δt)otherwise
Total Reward
Rt(j)=Rbase(j)+λctrRctr(j)
Advantage (LOO)
Ab(j)=Var(Rb)+ϵRb(j)−Rˉb,∖j
Objective
LRL=−E[A⋅logπθ]+λKLKL+λCECE+λHH
8. ⚙️ Execution Rule
- 모든 step에서 ( g = 0 ) → SLM 결과 사용
- 최초 ( g = 1 ) 발생 시:
a^=Mm(Illm(q))
👉 Early termination
9. 📊 Cost Model
Cost=∑mcmout⋅Tmout
👉 output token 기준 비용 계산
10. 📈 Key Results
핵심 성능
- SLM 대비 큰 성능 향상
- LLM 대비 비용 절감
Main results comparing StepRoute with theBaseline (SLM-only) and LLM-only
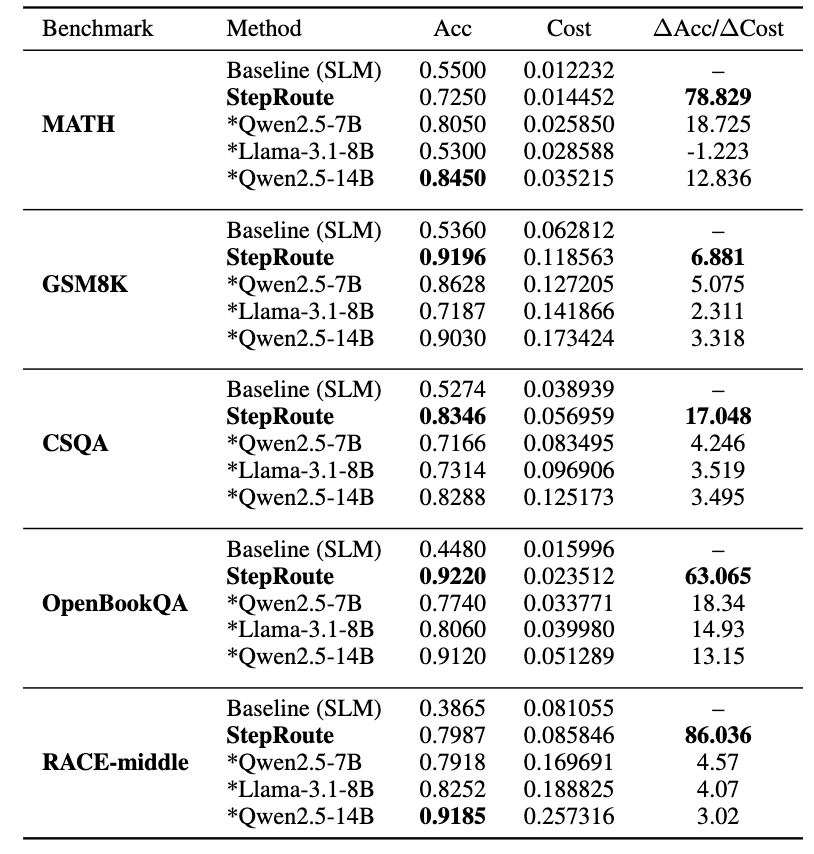
OOD 성능
- OpenBookQA: 0.448 → 0.922
- RACE-middle: 0.387 → 0.7987
👉 강한 generalization
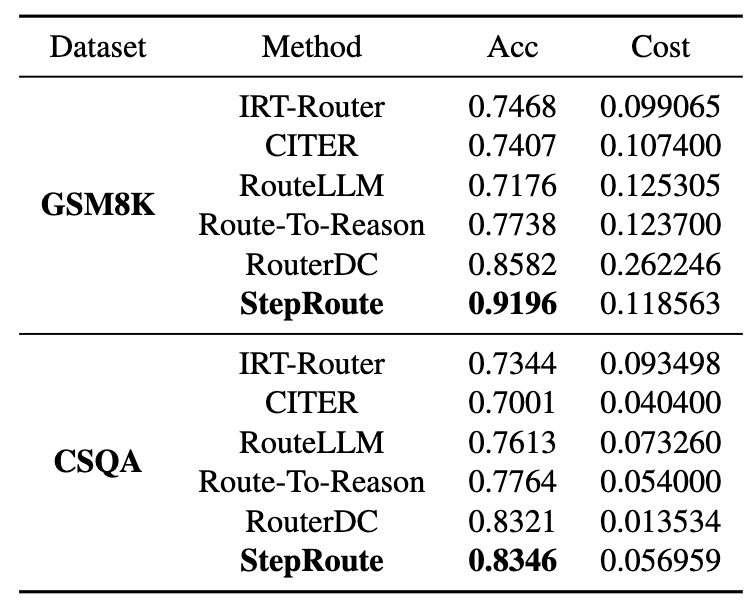
Comparison of another routing methods
11. 🔍 핵심 해석
StepRoute가 효과적인 이유:
- Intermediate context 활용
- Step-level granularity
- Early stopping
- Cost-aware RL optimization
12. 📌 Summary
StepRoute는 step 단위에서 routing policy를 학습하여
accuracy–cost trade-off를 최적화하는 방법이다.
13. 💭 Insight
기존 방법:
- Query-level → 정보 부족
- Token-level → 비용 과다
👉 StepRoute:
정보와 효율성 사이의 optimal point
14. 🚀 Extension Ideas
- entropy-based routing
- KV-cache-aware routing
- confidence-based fallback
- projection-based routing (ProRouter)
📎 Reference
- StepRoute: Step-Wise Reflective Routing with Contrastive Reward Shaping
