https://arxiv.org/pdf/2406.18665
https://github.com/anyscale/llm-router?tab=readme-ov-file
- 전반 요약 논문 "RouteLLM: Learning to Route LLMs with Preference"는 다양한 언어 모델(LLM) 간의 효율적 라우팅을 통해 비용 절감과 성능 유지 간의 균형을 맞추는 방안을 다룹니다. 이 논문의 주요 내용과 방법론을 요약하면 다음과 같습니다:
1. 문제 정의와 목적
LLM의 사용에서 성능이 높은 모델은 비용이 많이 들지만, 저비용 모델은 성능이 떨어지는 문제가 있습니다. 이 논문에서는 사용자의 요청에 따라 적절한 LLM을 선택하는 라우팅 모델을 제안하여, 저렴한 비용으로 높은 성능을 유지하고자 합니다. 이를 위해 복잡한 질의는 성능이 높은 모델로, 간단한 질의는 저비용 모델로 전달하는 방식으로 설계되었습니다.2. 방법론
2.1 선호 데이터 및 증강
-
선호 데이터: 라우터는 Chatbot Arena에서 수집된 약 80,000개의 쌍별 비교 데이터를 사용하여 학습됩니다. 이 데이터는 사용자가 여러 모델 중 선호하는 모델을 선택하여 생성된 선호도 데이터입니다.
-
데이터 증강: 라우팅의 일반화 성능을 높이기 위해, MMLU 벤치마크와 같은 골든 레이블 데이터와 GPT-4를 심판으로 활용한 비교 데이터를 추가하여 증강합니다. 이 과정은 비용이 들지만 모델 성능 향상에 큰 도움을 줍니다.
2.2 라우팅 접근법
-
유사도 가중치 순위: 브래들리-테리(Bradley-Terry) 모델을 사용하여 각 질의의 유사도에 기반한 가중치를 통해 라우팅을 수행합니다.
-
행렬 분해: 추천 시스템의 행렬 분해 기법을 이용해 모델과 질의 간의 내재된 품질 점수를 학습합니다.
-
BERT 분류기: BERT 모델을 활용하여 텍스트 분류기를 학습하여, 강한 모델이 선택될 확률을 예측합니다.
-
Causal LLM 분류기: Llama 모델을 사용해 다음 토큰 예측 방식으로 강한 모델의 선택 확률을 예측합니다.
3. 실험과 결과
각 라우팅 모델은 MMLU, MT Bench, GSM8K 벤치마크에서 평가되었습니다. 실험 결과는 아래와 같습니다:
-
데이터 증강을 적용하지 않았을 때, 모든 라우터의 성능이 낮았지만, 증강된 데이터로 학습한 후 성능이 크게 향상되었습니다.
-
MT Bench에서 증강 데이터로 학습한 라우터가 비용 절감(최대 75%)과 성능 유지 간의 이상적인 균형을 보여줬습니다.
-
새로운 모델 조합에서도 라우터는 추가 학습 없이도 일반화 성능을 유지했습니다.
4. 비용 분석과 라우팅 오버헤드
비용 절감 측면에서, 강한 모델 호출 횟수를 줄여 GPT-4 대비 최대 3.66배의 비용 절감을 이루었으며, 라우팅 오버헤드는 LLM 생성 비용에 비해 무시할 수 있을 정도로 적었습니다.
결론
이 논문은 효율적인 LLM 라우팅을 통해 높은 품질의 응답을 제공하면서도 비용을 절감하는 방법을 제시합니다. 데이터 증강의 효과와 벤치마크-데이터 유사성 점수를 통해 라우터의 성능을 향상시키는 방법도 설명되어 있으며, 미래 연구 방향으로는 멀티 모델 라우팅과 데이터셋-모델 조합 간 성능 편차 분석이 제시됩니다.
이 논문은 실질적인 응용에서 LLM을 효율적으로 활용할 수 있는 유용한 접근 방안을 제공하며, 특히 대규모 LLM 배포에 있어 중요한 비용 문제를 해결하려는 노력이 돋보입니다【6†source】.
-
초록
대형 언어 모델(LLMs)은 다양한 작업에 걸쳐 인상적인 능력을 보여주지만, 어느 모델을 사용할지 선택하는 것은 성능과 비용 간의 균형을 고려해야 하는 과제를 동반합니다. 더 강력한 모델은 일반적으로 더 효과적이지만 더 높은 비용이 수반되고, 반대로 덜 강력한 모델은 더 비용 효율적입니다. 이러한 문제를 해결하기 위해, 우리는 효율적인 라우터를 설계하여 강력한 LLM과 약한 LLM 간에 작업을 할당하면서 성능과 비용 간의 균형을 최적화하는 방법을 제시합니다. 우리는 이러한 라우터를 훈련하기 위해 인간의 선호도 데이터와 데이터-증강 기술을 활용하는 프레임워크를 개발합니다. 우리의 평가 결과는 이러한 라우팅이 특정 경우에 비용을 상당히 줄일 수 있음을 보여줍니다. 이는 성능의 저하 없이 가능한 것입니다. 흥미롭게도, 우리의 라우터 모델은 강력한 전이 학습 능력을 보여주며, 이는 라우터가 강력한 모델과 약한 모델이 시간이 지남에 따라 변경될 때도 잘 작동함을 나타냅니다. 이는 LLM을 배치하는 데 있어 비용 효율적이고 고성능인 솔루션을 제공할 수 있는 라우터의 잠재력을 강조합니다.
1. 도입
최근 대형 언어 모델(LLMs)의 발전은 다양한 자연어 작업에서 놀라운 능력을 보여주고 있습니다. 대화식 상호작용부터 질문 응답 및 텍스트 요약에 이르기까지, LLM은 유창하고 이해력 있는 언어 생성 능력을 입증했습니다. 이러한 빠른 발전은 주로 트랜스포머 아키텍처와 데이터 처리 및 학습 인프라의 확장 덕분에 이루어졌습니다.
그러나 모든 LLM이 동일하게 만들어진 것은 아닙니다. LLM은 모델의 크기와 데이터 훈련의 양에서 큰 차이를 보입니다. 이로 인해 모델의 강점, 약점 및 능력에 상당한 차이가 발생하게 됩니다. 일반적으로 큰 모델은 더 강력하지만 더 높은 비용이 드는 반면, 작은 모델은 능력은 떨어지지만 비용 측면에서 더 효율적입니다.
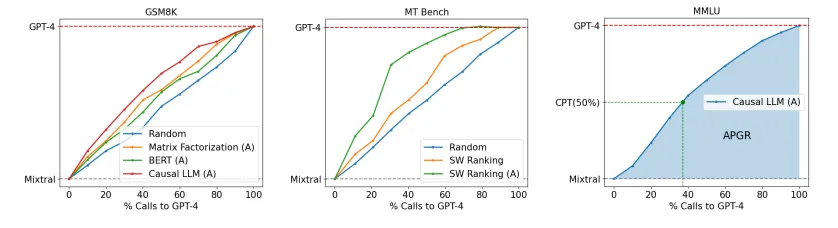
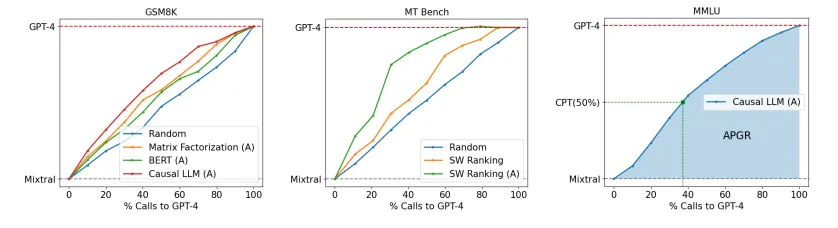
그림 1: GPT-4와 Mistral-7B 간의 비용-성능 상충 관계를 설명하는 그림입니다. 우리는 OOD 데이터와 MSMARCO에서의 라우팅이 어떻게 달성되는지를 보여줍니다. 중앙 그래프에서는 데이터-증강 기술의 사용 여부에 따른 라우팅 성능을 보여주며, 오른쪽 그래프는 여러 벤치마크에서의 LLM 라우팅을 보여줍니다.
이러한 이질적인 환경은 실제 세계에서 LLM(대형 언어 모델)을 배포하는 데 있어 딜레마를 초래합니다. 사용자는 고품질 응답을 보장하기 위해 가장 큰 모델을 사용하는 것을 원하지만, 이는 비용이 높아질 가능성이 큽니다. 반대로 작은 모델을 사용하면 비용은 50배 이상 절감될 수 있지만(예: LLaMA-7B 대 GPT-4 또는 Claude-3 대 Haiku 등), 그 결과 응답의 품질이 낮아질 수 있습니다. 따라서 더 작은 모델이 모든 쿼리를 처리할 수 없게 될 수 있습니다.
이를 해결하기 위해, 우리는 사용자 쿼리별로 모델을 라우팅하는 효율적인 솔루션을 제안합니다. 우리의 방법은 LLM 라우팅 문제를 해결하기 위해 비용과 응답 품질 간의 상충 관계를 최적화하는 라우터를 설계하는 것입니다. 여기서 우리의 목표는 비용을 줄이면서 강력한 모델의 응답 품질에 가까운 성능을 유지하는 것입니다. 라우터는 인간 선호도 레이블과 데이터 증강 기법을 활용하여 이러한 문제를 해결합니다.
우리는 이를 위해 원칙 기반의 프레임워크를 제안하고, 이를 MT-Bench와 같은 최신 벤치마크에서 실험했습니다. 실험 결과, 우리의 프레임워크는 비용을 2배 이상 절감하면서도 응답 품질에는 큰 영향을 미치지 않았습니다.
2 LLM 라우팅
2.1 문제 정의
N개의 서로 다른 LLM(대형 언어 모델) 집합 )을 고려합니다. 각 모델 )는 쿼리 에 대한 응답을 매핑하는 함수로 추상화될 수 있습니다. 라우팅 함수 는 N방향 분류자이며 쿼리 를 받아 응답할 모델을 선택하고 결과를 로 나타냅니다. LLM 라우팅 문제의 핵심 과제는 성능과 비용 간의 균형을 유지하면서 고품질의 응답을 제공하는 것입니다.
우리는 인간의 선호도 데이터 를 활용하여 라우팅을 개선할 수 있습니다. 여기서 는 쿼리 에 대한 선호도 레이블을 나타냅니다. 목적은 쿼리별로 최적의 모델을 식별하는 것입니다.
본 연구에서는 LLM 라우팅 문제에서 두 가지 모델 클래스에 초점을 맞춥니다:
- 강력한 모델 : 높은 품질의 응답을 생성할 수 있지만 비용이 많이 드는 모델입니다(예: GPT-4).
- 약한 모델 : 저렴한 비용으로 응답을 생성할 수 있지만 품질은 낮은 모델입니다(예: LLaMA 기반 모델).
우리는 강력한 모델과 약한 모델 간에 쿼리를 효율적으로 분배하는 방법을 찾는 것이 목적입니다.
이 연구에서 라우팅 문제는 비용과 응답 품질의 상충 관계를 해결하면서 모델 간에 균형을 맞추는 작업을 의미합니다.
- 선호도 데이터 학습: LLM이 선호도 데이터에서 확률을 학습하도록 하는 것은 모델의 강점과 약점을 활용하는 데 도움이 됩니다.
- 비용 임계값: 쿼리에 대한 응답을 라우팅할 때 강력한 모델과 약한 모델 사이의 임계값을 설정하여 모델을 선택하는 기준으로 사용합니다.
2.2 메트릭 (Metrics)
이 섹션에서는 LLM 라우팅 문제에서 비용과 품질 간의 상충 관계를 포착하는 평가 메트릭을 정의합니다. 먼저 품질과 비용 효율성을 독립적으로 평가하는 메트릭을 제시한 다음, 실험적 평가에 사용된 복합 메트릭을 소개합니다.
비용 효율성
비용 효율성을 위해서는 강력한 모델에 대한 호출 비율을 측정합니다:
여기서 모델은 비용이 상당히 높기 때문에 c 는 가능한 한 낮게 유지되어야 합니다.
품질 측정
품질은 평가 세트 Q 에서 평균 응답 품질을 측정합니다:
여기서 는 해당 응답의 품질 점수를 나타냅니다. 이는 사전 정의된 지표나 사람의 평가를 기반으로 하는 점수일 수 있습니다.
평균 성능 격차 회복 (PGR)
강력한 모델과 약한 모델의 성능 차이를 감안하여, 라우터의 성능을 두 모델 간의 성능 격차 대비 회복 정도로 측정하는 메트릭을 정의합니다:
평균 성능 격차 회복 비율 (APGR)
PGR 자체는 특정 상황에 대해 충분하지 않을 수 있습니다. 예를 들어, 한계 비용이 증가함에 따라 어떻게 APGR이 변화하는지에 대한 정보를 얻기 위해, 다음과 같이 평균화된 버전의 APGR을 사용합니다:
실제 응용에서의 중요성
실제 세계 응용에서는 특정 품질 수준에 도달하기 위해 필요한 비용을 이해하는 것이 중요합니다. 이를 위해 특정 품질 임계값(PCT)을 고려하여 품질을 유지하면서 필요한 비용 수준을 측정합니다.
3 방법론 (Methodology)
3.1 선호도 데이터 (Preference Data)
먼저 라우팅 기능을 학습시키기 위해 선호도 데이터를 어떻게 얻을 수 있는지에 대해 설명합니다. 우리는 주로 Chatbot Arena 플랫폼에서 80k의 전투 데이터를 사용합니다. 이 플랫폼에서 사용자는 챗봇 인터페이스와 상호 작용하며 자신이 선택한 프롬프트를 제출합니다. 제출 후, 두 개의 익명의 모델로부터 응답을 받고 어느 모델이 더 나은지 또는 동점인지 투표하게 됩니다.
결과적으로 생성된 데이터셋은 으로 구성되며, 여기서 는 사용자 쿼리, 는 두 개의 모델, 그리고 는 인간 판단을 기반으로 한 페어와이즈 비교 결과입니다.
이러한 데이터에서 가장 큰 문제 중 하나는 두 모델 간의 승리율이 불균형하다는 것입니다. 평균적으로 이기거나 지는 비율은 10% 미만입니다. 따라서 우리는 아래와 같은 절차를 통해 선호도 데이터의 편향성을 줄였습니다. 먼저 의 모델을 10개의 다른 티어로 클러스터링하고(자세한 내용은 부록 A 참고), 각 모델의 Elo 점수를 사용하여 Chatbot Arena 리더보드에 기반하여 티어 내의 변동성을 최소화하도록 했습니다. 그 결과, 상위 두 티어의 모델은 강력한 모델 로 간주하고, 하위 티어의 모델은 약한 모델 로 분류하였습니다.
3.1.1 데이터 증강 (Data Augmentation)
모델을 계층화한 이후에도 사람의 선호 신호는 여전히 다양한 모델 클래스에 걸쳐 희소할 수 있습니다. 4.1절에서 설명하듯이, 이는 특히 많은 파라미터를 가진 모델에서 일반화를 방해할 수 있습니다. 따라서 우리는 다음의 두 가지 데이터 증강 방법을 탐구합니다:
- 골든 라벨 데이터셋(Golden-labeled datasets): 우리는 훈련 데이터를 다음 형식의 데이터셋으로 증강합니다.
여기서 는 모델 응답 에 대해 자동으로 계산되는 골든 라벨입니다. 예를 들어, 다중 선택형 답변의 경우 MMLU 벤치마크 [17]가 이에 해당합니다. 우리는 약 1500개의 질문이 포함된 MMLU 검증 세트를 사용하여 비교 라벨 를 생성하고 와 의 응답을 비교하여 선호 데이터셋 을 생성합니다.
- LLM-judge 라벨 데이터셋(LLM-judge-labeled datasets): 우리는 대화형 도메인에서 LLM 심판을 사용하는 선호 라벨을 얻는 방식을 탐색합니다. 이는 사람의 판단과 높은 상관관계를 보입니다 [16, 20]. 사용자 쿼리 모음을 받으면, 우리는 강력한 모델 과 약한 모델 로부터 응답을 생성하고, GPT-4를 심판으로 사용하여 쌍별 비교 라벨 을 생성합니다. 이 방법의 주요 과제는 GPT-4로부터 대량의 비교 응답을 얻는 데 드는 높은 비용입니다. 다행히도 Nectar 데이터셋 [34]은 다양한 쿼리와 이에 상응하는 모델 응답을 제공합니다. 우리는 비용 절감을 위해 GPT-4 응답을 의 대표로, Mixture-8x7B 모델을 의 대표로 사용하여 비교 라벨을 생성합니다. 최종적으로, 우리는 약 12만 개의 샘플을 포함한 데이터셋을 약 700달러의 비용으로 수집했습니다.
3.2 라우팅 접근법 (Routing Approaches)
여기서는 선호 데이터 에서 승리 예측 모델 을 학습하는 방법을 설명합니다. 우리는 D 로 샘플을 정의하며, 여기서 와 는 각각 이기는 모델과 지는 모델을 나타냅니다.
유사성 가중 순위화(Similarity-weighted (SW) ranking)
우리는 Bradley-Terry (BT) 모델 [7]을 사용하며, 이는 [12]와 유사합니다. 사용자 쿼리 가 주어졌을 때, 우리는 훈련 세트의 각 쿼리 에 대해 유사성에 기반한 가중치 를 계산합니다. 여기서 는 다음과 같이 정의됩니다:
여기서 는 쿼리 임베딩을 나타내며, 은 바이너리 크로스 엔트로피 손실입니다. BT 계수 는 다음과 같은 최적화 문제를 통해 학습됩니다:
이 최적화 문제를 풀면, 승리 확률 P() 을 다음과 같이 추정할 수 있습니다:
이 라우팅 모델은 훈련이 필요하지 않으며 추론 시간에 해결됩니다.
Matrix Factorization
사용자-아이템 상호작용의 저차원 구조를 포착하기 위해 추천 시스템에서 자주 사용되는 행렬 분해(matrix factorization) 모델을 참조하여, 우리는 선호 데이터를 학습하는 데 이 접근법을 사용합니다. 핵심은 숨겨진 스코어 함수 를 찾아내는 것입니다. 여기서 ) 는 쿼리 에 대한 모델 의 응답 품질을 나타냅니다. 만약 모델 가 모델 보다 더 나은 응답을 제공하면, 가 됩니다. 우리는 이 관계를 BT 관계식을 통해 승리 확률을 모델링하여 다음과 같이 강제합니다:
여기서 우리는 선호 데이터를 기반으로 이 관계를 최적화합니다. 스코어 함수 는 모델 의 아이덴티티를 -차원 벡터 과 쿼리 를 -차원 벡터 에 임베딩하는 이중선형(bilinear) 함수로 모델링합니다:
여기서, 는 Hadamard 곱을 나타내며, 및 는 v_q 와 v_m 의 차원을 맞추기 위한 투영(projection) 레이어입니다. 는 최종 스칼라 출력을 예측하기 위한 선형 회귀 레이어입니다. 이 방법은 기본적으로 집합 의 스코어 행렬을 학습하는 행렬 분해 방식입니다. 우리는 8GB GPU에서 약 10 에폭 동안 이 모델을 훈련하며, 배치 크기 64, 학습률 , 가중치 감쇠(weight decay) 로 설정하였습니다.
BERT Classifier
여기서는 파라미터 수가 더 많은 표준 텍스트 분류 방법을 탐구합니다. 우리는 사용자 쿼리의 컨텍스트화된 임베딩을 제공하기 위해 BERT 기반 아키텍처 [14]를 사용하며, 승리 확률을 다음과 같이 정의합니다:
여기서 는 입력 쿼리 를 요약하는 특수 분류 토큰(CLS)에 대응되는 임베딩입니다. 는 각각 파라미터 행렬, 바이어스, 그리고 로지스틱 회귀 헤드의 시그모이드 활성화 함수입니다. 우리는 선호 데이터 에 대해 전체 파라미터 미세 조정을 수행합니다. 이 모델은 2xL4 24GB GPU에서 배치 크기 16, 최대 시퀀스 길이 512, 학습률 , 가중치 감쇠 0.01로 약 2000 스텝 동안 훈련됩니다.
Causal LLM Classifier
마지막으로, 우리는 라우터의 용량을 확장하기 위해 Causal LLM 분류기로 파라미터화합니다. 여기서 Llama 3 8B 모델을 사용합니다. 우리는 명령-따르기(instruction-following) 패러다임 [31]을 사용하여 입력 쿼리를 포함하는 문장을 모델에 제공하고, 다음 토큰 예측 방식으로 승리 확률을 출력합니다. 이 방식에서는 별도의 분류 헤드를 사용하지 않으며, 모델에 비교 라벨을 추가하여 각 클래스 레이블 위에서 승리 확률을 소프트맥스로 출력합니다. 이 모델은 8xA100 80GB GPU에서 약 2000 스텝 동안 배치 크기 8, 최대 시퀀스 길이 2048, 학습률 1 으로 훈련됩니다.
4 실험 (Experiments)
훈련 데이터 (Training data):
3.1절에서 언급했듯이, 우리는 주로 80k Chatbot Arena 데이터를 사용하여 모델을 훈련하고, 5k 샘플을 검증용으로 보류했습니다. 모든 프롬프트 샘플에서 16자 미만의 텍스트를 제거하여 6개의 언어로 된 16k 페어와이즈 비교 샘플을 얻었습니다. 영어(65.1%), 중국어(13.6%), 러시아어(2.2%) 등이 포함됩니다. 10개 클래스로 데이터를 분류하여 비교 라벨링의 희소성을 해결하였고, 추가로 MNLI에서 추출한 데이터를 포함하여 추가 훈련을 수행했습니다.
평가 벤치마크 (Evaluation benchmarks):
우리는 라우터 성능을 3개의 널리 사용되는 벤치마크에서 평가했습니다:
- MNLI (Multi-Genre Natural Language Inference),
- MT Bench (5.7 서브테스트, 57개 주제),
- GSM8K (1,000개 이상의 수학 문제를 포함).
또한, 우리는 일반적으로 라우터 성능을 평가하기 위해 공용 벤치마크에서 벗어난 결과를 보고하여 라우터의 범용성을 검토했습니다.
4.1 결과 (Results)
라우터(Routers): 행렬 분해 라우터와 유사성 가중 순위 라우터 모두에서, 우리는 입력 쿼리를 임베딩하기 위해 OpenAI의 임베딩 모델인 text-embedding-ada-002를 사용합니다. 우리는 BERT와 Causal LLM 모두에서 전체 파라미터 미세 조정을 수행하고, 모델 선택을 위해 검증 세트를 사용합니다. gpt-4-1106-preview [23]를 의 대표 모델로, Mixtal 8x7B [19]를 의 대표 모델로 선택하여 라우터 성능을 구체적으로 평가합니다. 우리는 또한 비용 제약 하에서 무작위로 라우팅하는 무작위 라우터를 기준선으로 사용합니다.
표 1: MT Bench 결과
| Training data | Method | CPT(50%) | CPT(80%) | APGR |
|---|---|---|---|---|
| Random (95% CI) | - | 49.03(±4)% | 78.08(±3)% | 0.500(±0.02) |
| BERT | 78.09% | 87.64% | 0.391 (-21.8%) | |
| Causal LLM | 28.82% | 77.35% | 0.537 (+6.6%) | |
| Matrix Factorization | 25.32% | 74.26% | 0.580 (+16%) | |
| SW Ranking | 37.85% | 58.99% | 0.610 (+22.1%) | |
| BERT | 19.58% | 34.02% | 0.751 (+50.2%) | |
| Causal LLM | 31.50% | 48.75% | 0.679 (+35.8%) | |
| Matrix Factorization | 13.40% | 31.31% | 0.802 (+60.4%) | |
| SW Ranking | 23.21% | 36.04% | 0.759 (+51.8%) |
해석: CPT(50%)에서의 점수 8.8은 GPT-4 성능(9.3)의 95%에 해당합니다. 우리 라우터는 에서 훈련된 경우 MT Bench에서 강력한 성능을 보이며, 로 데이터셋을 증강하면 추가적인 개선이 이루어집니다. 이는 무작위 라우터와 비교할 때 비용을 최대 75%까지 절감할 수 있음을 나타냅니다.
표 1은 MT Bench에서의 라우터 성능을 나타냅니다. 데이터셋에서 훈련된 라우터의 경우, 행렬 분해 및 유사성 가중 순위 방법이 강력한 성능을 보여주며 모든 지표에서 무작위 라우터를 능가합니다. 특히, 행렬 분해는 50% CPT를 달성하기 위해 무작위 대비 더 적은 GPT-4 호출 수를 요구합니다. 그러나 에서 훈련된 BERT와 causal LLM 분류기는 무작위에 가까운 성능을 보이는데, 이는 데이터가 적은 환경에서 고용량 접근 방식이 잘 작동하지 않는 것을 설명합니다.
GPT-4 심판을 사용하여 선호 데이터를 증강하면 모든 라우터에서 주목할 만한 개선이 나타납니다. BERT와 causal LLM 라우터는 무작위 기준선보다 훨씬 나은 성능을 보여주며, BERT 분류기는 무작위에 비해 50% 이상의 APGR 개선을 달성합니다. 이 증강된 데이터셋에서 행렬 분해는 CPT(80%)에서 최상의 성능을 나타내며, 무작위 대비 거의 절반의 GPT-4 호출을 필요로 합니다.
표 2: 5-shot MMLU 결과
| Training data | Method | CPT(50%) | CPT(80%) | APGR |
|---|---|---|---|---|
| Random (95% CI) | - | 50.07(±0)% | 79.93(±0)% | 0.500(±0) |
| BERT | 49.43% | 77.80% | 0.502 (+0.5%) | |
| Causal LLM | 48.88% | 77.93% | 0.499 (-0.2%) | |
| Matrix Factorization | 45.00% | 76.86% | 0.524 (+4.9%) | |
| SW Ranking | 55.82% | 80.85% | 0.473 (-5.4%) | |
| BERT | 41.30% | 72.20% | 0.572 (+14.4%) | |
| Causal LLM | 35.49% | 70.31% | 0.600 (+19.9%) | |
| Matrix Factorization | 35.40% | 71.40% | 0.597 (+19.5%) | |
| SW Ranking | 35.40% | 71.55% | 0.603 (+20.7%) |
해석: 5-shot MMLU 결과에서, CPT(50%)에서의 점수 75는 GPT-4 성능(81)의 92%입니다. 에서만 훈련된 라우터는 대부분의 질문에서 잘 작동하지 못하지만, 로 데이터셋을 증강하면 5% 이상의 성능 개선이 나타납니다.
위의 표는 MT Bench와 MMLU에서 각 라우터의 성능을 비교하여, 다른 라우팅 시스템 대비 우리의 라우터가 달성한 상당한 개선을 보여줍니다.
MMLU(Table 2)에서, 모든 라우터는 Arena 데이터셋만으로 훈련되었을 때 무작위 라우터와 비슷한 성능을 보입니다. 이는 대부분의 MMLU 질문이 분포 밖(out-of-distribution)에 속하기 때문으로 보입니다(4.2절 참조). 그러나 MMLU 검증 세트에서 골든 라벨 데이터로 훈련 데이터셋을 증강하면, 모든 라우터에서 MMLU 성능이 크게 향상됩니다. 이 경우, 모든 라우터는 CPT(50%)를 달성하기 위해 무작위 대비 약 20% 적은 GPT-4 호출을 필요로 합니다. 중요한 점은, 약 1500개의 샘플을 포함하는 골든 라벨 데이터셋이 전체 훈련 데이터의 2% 미만을 차지하지만, 데이터셋 증강이 샘플 수가 적을 때에도 효과적임을 보여준다는 것입니다.
표 3: 8-shot GSM8K 결과
| Training data | Method | CPT(50%) | CPT(80%) | APGR |
|---|---|---|---|---|
| Random (95% CI) | - | 50.00(±2)% | 80.08(±1)% | 0.497(±0.01) |
| BERT | 58.78% | 83.84% | 0.438 (-11.8%) | |
| Causal LLM | 56.09% | 83.56% | 0.461 (-7.3%) | |
| Matrix Factorization | 53.59% | 85.24% | 0.4746 (-4.5%) | |
| SW Ranking | 54.43% | 82.11% | 0.4753 (-4.3%) | |
| BERT | 44.76% | 79.09% | 0.531 (+6.9%) | |
| Causal LLM | 33.64% | 63.26% | 0.622 (+25.3%) | |
| Matrix Factorization | 38.82% | 72.62% | 0.565 (+13.8%) | |
| SW Ranking | 41.21% | 72.20% | 0.568 (+14.3%) |
해석: CPT(50%)에서의 점수 75는 GPT-4 성능(86)의 87%에 해당합니다. 에서만 훈련된 라우터는 다시 질문이 분포 밖에 있어서 성능이 좋지 않지만, 로 증강하면 라우터 성능이 크게 향상됩니다.
GSM8K (Table 3)에서, MMLU와 유사하게 Arena 데이터셋만으로 훈련된 모든 라우터의 성능은 무작위와 비슷합니다. 그러나 LLM 심판으로 생성된 데이터로 증강된 데이터셋에서 훈련하면, 라우터의 성능이 크게 향상되어 무작위보다 더 높은 APGR을 기록합니다. 증강된 데이터셋에서 Causal LLM 분류기가 라우터 중에서 가장 우수한 성능을 나타내며, CPT(50%) 및 CPT(80%)를 달성하기 위해 무작위보다 약 17% 적은 GPT-4 호출만 필요합니다.
4.2 데이터셋과 벤치마크 유사성 정량화 (Quantifying dataset and benchmark similarity)
우리는 동일한 데이터셋에서 훈련된 라우터의 성능 차이를 각 벤치마크-데이터셋 쌍에서 평가 데이터와 훈련 데이터의 분포 차이로 돌립니다. 각 벤치마크-데이터셋 쌍에 대해, 우리는 벤치마크-데이터셋 유사성 점수(benchmark-dataset similarity score)를 계산하여, 평가 데이터가 훈련 데이터에서 얼마나 잘 대표되는지를 나타냅니다. 이 점수는 Appendix C에 자세히 설명되어 있습니다.
표 4: 벤치마크-데이터셋 유사성 점수
| Arena | Arena + | Arena + | |
|---|---|---|---|
| MT Bench | 0.6078 | 0.6525 | - |
| MMLU | 0.4823 | - | 0.5678 |
| GSM8K | 0.4926 | 0.5335 | - |
해석: 벤치마크-데이터셋 유사성 점수는 이 점수와 벤치마크에서의 라우터 성능 간의 강한 상관관계를 보여주며, 라우터 성능 개선을 정량적으로 평가할 수 있는 방법을 제공합니다.
더 높은 벤치마크-데이터셋 유사성 점수는 해당 벤치마크에 대해 해당 데이터셋에서 훈련된 라우터의 강력한 성능과 상관관계가 있습니다. 예를 들어 4.1절에서 언급한 것처럼, 데이터셋 증강을 통해 및 골든 라벨 데이터셋을 사용하면 전체 선호 데이터 분포를 벤치마크와 더 유사하게 만들어 벤치마크-데이터셋 유사성 점수가 증가하고, 이는 성능 향상으로 이어집니다.
4.3 다른 모델 쌍에 대한 일반화 (Generalizing to other model pairs)
우리는 gpt-4-1106-preview [23]와 Mixtal 8x7B [19]를 강력한 모델과 약한 모델의 대표로 선택하여 앞선 실험을 수행했습니다. 그러나, 본 섹션에서는 Claude 3 Opus [6]와 Llama 3 8B [5]로 라우팅할 때 MT Bench에서의 라우터 성능을 통해 프레임워크의 일반화 가능성을 보여줍니다. 중요한 점은 재훈련 없이 동일한 라우터를 사용하고, 단지 라우팅된 강력한 모델과 약한 모델만 교체한다는 것입니다. 이 두 모델은 훈련 데이터에 존재하지 않습니다.
표 5: Claude 3 Opus / Llama 3 8B에 대한 MT Bench 결과
| Train Set | Method | CPT(50%) | CPT(80%) | APGR |
|---|---|---|---|---|
| Random (95% CI) | - | 47.23(±5)% | 77.08(±5)% | 0.494(±0.03) |
| BERT | 60.61% | 88.39% | 0.475 (-3.9%) | |
| Causal LLM | 31.96% | 59.83% | 0.645 (+30.5%) | |
| Matrix Factorization | 24.84% | 85.73% | 0.605 (+22.5%) | |
| SW Ranking | 33.54% | 80.31% | 0.553 (+12%) | |
| BERT | 36.28% | 50.83% | 0.618 (+25.2%) | |
| Causal LLM | 40.46% | 55.83% | 0.625 (+26.5%) | |
| Matrix Factorization | 30.48% | 41.81% | 0.703 (+42.2%) | |
| SW Ranking | 31.67% | 48.39% | 0.667 (+35%) |
해석: 표 5는 Claude 3 Opus와 Llama 3 8B에 대한 MT Bench 결과를 보여줍니다. 우리의 라우터는 재훈련 없이 다양한 강력한 모델과 약한 모델 쌍에 걸쳐 매우 잘 일반화됩니다.
우리는 모델 쌍이 교체되더라도 MT Bench에서 모든 기존 라우터가 강력한 결과를 보이는 것을 다시 확인할 수 있었습니다. 모든 라우터의 성능은 원래 모델 쌍과 비교해도 유사합니다. 새로운 모델 쌍과 원래 모델 쌍에 대한 결과 모두 무작위 라우터보다 여전히 상당히 강력하며, CPT(80%)를 달성하기 위해 무작위보다 최대 30% 적은 GPT-4 호출이 필요합니다. 이러한 결과는 라우터가 강력한 모델과 약한 모델을 구별할 수 있는 문제의 공통 특성을 학습했음을 시사하며, 이는 추가 훈련 없이 새로운 모델 쌍에도 일반화된다는 것을 보여줍니다.
4.4 비용 분석 (Cost analysis)
| CPT 50% | CPT 80% | |
|---|---|---|
| MT Bench | 3.66x (at 95% GPT-4 quality) | 2.49x |
| MMLU | 1.41x (at 92% GPT-4 quality) | 1.14x |
| GSM8K | 1.49x (at 87% GPT-4 quality) | 1.27x |
표 6: 최고의 라우터가 GPT-4 대비 달성한 비용 절감 비율. 우리 라우터는 품질을 유지하면서도 상당한 비용 절감을 달성할 수 있습니다.
우리는 GPT-4와 Mixtal 8x7B를 사용하는 평균 비용을 백만 토큰당 각각 $24.7와 $0.24로 추정합니다(자세한 내용은 부록 D 참조). 표 6은 우리의 접근 방식을 통해 달성된 비용 절감 결과를 정량화한 것입니다. 우리는 최상의 성능을 보이는 라우터의 GPT-4 호출 비율을 무작위 기준선과 비교하여 계산합니다. 분석에 따르면, GPT-4의 비용이 지배적인 요소로 작용합니다. 우리의 라우터는 최대 3.66배의 비용 절감을 달성하여, 라우팅을 통해 품질을 유지하면서도 비용을 상당히 줄일 수 있음을 입증합니다.
4.5 라우팅 오버헤드 (Routing Overhead)
| 백만 요청당 비용 | 초당 요청 수 | VM 시간당 비용 | |
|---|---|---|---|
| SW Ranking | $37.46 | 2.9 | $0.39 |
| Matrix Factorization | $1.42 | 155.16 | $0.8 |
| BERT | $3.19 | 69.62 | $0.8 |
| Causal LLM | $5.23 | 42.6 | $0.8 |
표 7: 다양한 라우터의 비용 및 오버헤드입니다. LLM 생성 비용과 비교하면, 라우터를 배포하는 데 필요한 비용은 훨씬 적어 실제 작업을 지원하는 데 유용함을 보여줍니다.
LLM 라우팅의 중요한 부분 중 하나는 단일 모델을 사용하는 것에 비해 오버헤드가 발생한다는 점입니다. 이는 여러 모델을 효율적으로 관리하면서도 라우팅 비용을 최적화하는 데 있습니다. 특히, 우리의 라우터는 사용 중인 GPU를 최대한 효율적으로 활용하여 적은 비용으로도 실질적인 비용 절감 효과를 제공합니다.
5 결론 (Conclusion)
우리는 다양한 벤치마크에서 라우터가 강력한 라우팅 성능을 보여주었으며, 이에는 열린 질문 응답, 인문학, 수학 문제가 포함됩니다. 강력한 모델과 약한 모델 간의 쿼리를 지능적으로 라우팅함으로써, 우리의 라우터는 높은 응답 품질을 유지하면서도 상당한 비용 절감을 달성할 수 있었습니다.
또한 우리의 결과는 라우터 성능을 향상시키는 데 있어 데이터 증강의 효과가 크다는 것을 강조합니다. 아레나 데이터만으로 라우터를 훈련하면 MMLU 및 GSM8K에서 성능이 저조하지만, LLM을 사용한 증강 데이터나 도메인별 데이터 증강을 통해 라우터는 모든 벤치마크에서 무작위 기준보다 뛰어난 성능을 보였습니다. 가장 큰 성능 향상은 데이터셋이 평가 데이터와 일치할 때 발생하였으며, 이는 벤치마크-데이터셋 유사성 점수로 확인할 수 있었습니다. 우리는 이러한 프레임워크가 특정 사용 사례에서 라우터 성능을 향상시키는 데 명확하고 확장 가능한 경로를 제공한다고 믿습니다.
하지만 우리의 연구는 몇 가지 제한점이 있습니다. 첫째, 실제 응용 사례의 분포는 벤치마크와 크게 다를 수 있습니다. 둘째, 우리는 실험에서 다양한 모델 쌍을 사용하였지만, 향후 연구는 이 작업을 다중 모델 설정으로 확장하는 것이 유망한 방향입니다. 마지막으로, 동일한 벤치마크에서 서로 다른 라우터의 성능이 일관되지 않은 이유는 명확하지 않았으며, 이는 추가 연구가 필요한 부분입니다.
