
이전 Velog에서 단일 퍼셉트론에 대해서 실습해보고 공부해보았다!
중간에 잠깐 다층 퍼셉트론의 필요성에 대해서만 살펴보았는데 이번 Velog에서 구체적으로 다루어 볼 것이다 :)
1. MLP(다층 퍼셉트론)
다층 퍼셉트론은 입력층과 출력층 사이에 은닉층(Hidden Layer)를 가지고 있는 신경망 구조를 띈다.
MLP에는 입력층, 은닉층, 출력층이 존재한다!
이는 역전파 알고리즘(Back-propagation)을 적용하는데 이 알고리즘의 흐름에 대해서 알아보자.
-
순방향 패스: 입력이 주어지면 입력을 순방향으로 전파시켜서 출력을 계산한다. -
신경망의 출력과 정답 간의 오차를 계산한다.
-
역방향 패스: 오차를 줄이는 방향으로 신경망의 가중치와 바이어스 값을 변경한다.
2. 활성화 함수
활성화 함수란 입력의 총합을 받아서 출력값을 계산하는 함수이다.
이전에 우리는 활성화 함수로 계단 함수(Step Function)을 사용했었다. 일반적으로 사용되는 활성화 함수에 대해서 알아보자.
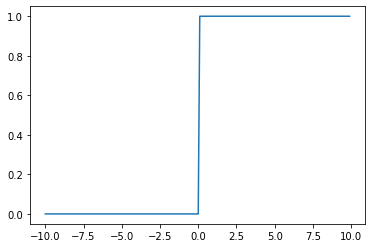
계단 함수(Step Function)
입력 신호의 총합이 0을 넘으면 1,
안넘으면 0을 출력하는 함수이다.
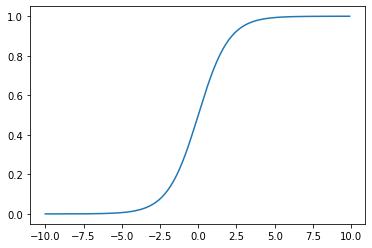
시그모이드 함수(Sigmoid Function)
S자 형태를 가지는 함수이다.
Step Function과의 차이점이 있다면, x=0에서 급격하게 변하지 않고 부드럽게 변해서 시그모이드 함수의 경우 어디서나 미분이 가능하다.
뒤에 경사 하강법이라는 최적화 기법이 나오는데, 여기서 기울기를 구하는 과정이 있어 나중에 필요할 예정!😊
또한 Step Function과 달리 0과 1이라는 이진출력값이 아니라 0.0~1.0까지 연속적인 실수 출력값을 가져서 좀 더 정밀한 출력이 가능하다.
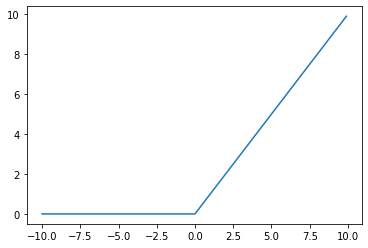
ReLU 함수(Rectifed Linear Unit Function) ⭐⭐
가장 많이 사용되는 활성화 함수다.
출력값이 0보다 크면 그대로 출력되고, 0보다 작으면 0으로 출력하는 함수이다.
ReLU함수는 미분도 간단하고, 심층 신경망에서 나타나는 Gradient 감소가 잘 일어나지 않아서 많이 사용된다!
Gradient감소는 뒤에서 또 배울 것이다 :)
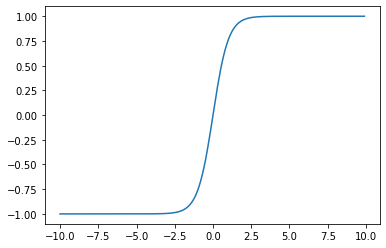
tanh 함수
tanh()는 넘파이에서 제공하고 있다.
고등학교 졸업을 했다면 시그모이드 함수와 거의 비슷하다는 것을 알 것이다ㅎㅎ
차이점이 있다면 출력값이 -1에서 1까지라는 점이다!
해당 함수는 순환 신경망에서 주로 사용된다.
각 활성화 함수들을 구현했을 때 사용한 코드들은 아래와 같다.
import numpy as np
import matplotlib.pyplot as plt
# 계단함수
def step(x):
result = x>0.00001
return result
# 시그모이드 함수
def sigmoid(x):
return 1.0/(1.0+np.exp(-x))
# ReLU 함수
def relu(x):
return np.maximum(x,0)
# tanh 함수
def tanh(x):
return np.tanh(x)3. MLP의 순방향 패스
1번에서 언급했던 MLP의 첫 번째 과정인 순방향 패스에 대해서 알아보자.
입력층의 값은 연결선을 통하여 은닉층의 유닛으로 전달된다.
이때 가중치가 곱해지고 바이어스 값이 더해진다.
입력의 총합에 활성화 함수가 적용되어서 은닉층 유닛의 출력이 결정된다.
또 다시 은닉층의 출력이 출력층의 입력이 되어서 또 다시 출력층을 계산한다.
이러한 과정을 아래와 같이 표현할 수 있을 것이다.
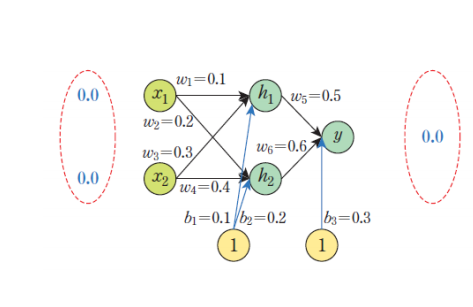
활성화 함수로 시그모이드 함수를 사용하여 계산해보겠다.
z1 = x1 w1 + x2 w3 + b1
= 0.0 0.1 + 0.0 0.3 + 0.1
= 0.1
a1 = 1 / (1 + e^(-z1))
= 0.524979
=> 첫 번째 유닛(h1)에 대한 계산 결과
z2 = x1 w2 + x2 w4 + b2
= 0.0 0.2 + 0.0 0.4 + 0.2
= 0.2
a2 = 1 / (1 + e^(-z2))
= 0.549834
=> 두 번째 유닛(h2)에 대한 계산 결과
최종적으로 y의 값을 구해보자.
zy = h1 w5 + h2 w6 + b3
= 0.524979 0.5 + 0.549834 0.6 + 0.3
= 0.892389
ay = 1 / (1 + e^(-zy))
= 0.709389
최종적으로 도출된 값 0.709389는 우리가 원하는 출력값 0.0과 차이가 매우 크다.
즉, 오차가 큰 좋지 않은 모델이라는 것을 알 수 있다.
따라서 각각에 대해 가중치(w)와 바이어스(b)를 업데이트해주어야 할 것이다.
이러한 전체 과정을 수식으로 표현할 수 있다.
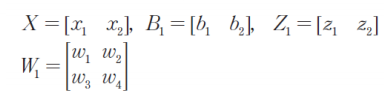
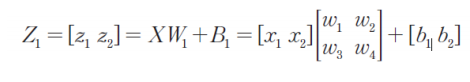
4. 손실함수 계산(오차 계산)
이제 다음으로 MLP의 두 번째 단계인 오차 계산 단계에서 사용되는 손실함수에 대해서 알아볼 것이다!
손실함수는 신경망에서 학습을 시킬 때 실제 출력과 원하는 출력 사이의 오차를 계산하는 함수이다.
손실함수의 종류에도 여러가지가 있지만 여기서는 MSE(Mean Squared Error)에 대해서만 살펴볼 것이다.
이는 평균 제곱 오차로 아래와 같이 계산된다.
말 그대로 오차의 제곱의 평균값이다!👍(단순)
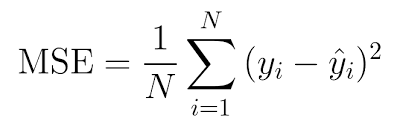
여기서 yi는 출력층 i번째 유닛의 값이고,
y^i는 실제 i번째 유닛의 값이다.
5. 경사 하강법
이제 우리에게 남은 미션은 손실함수로 구해진 값을 최소로 만들어주는 가중치를 찾는 것이다.🤔
이 때 오차값을 최소화하는 가중치를 찾는 데 일반적으로 사용되는 알고리즘 중 하나가 경사 하강법(Gradient-Descent Method)이다.
이전 velog에서 다루었던 바 있는 기법이다!
경사 하강법이란, 함수의 1차 미분값(그래디언트)를 사용하는 반복적인 최적화 알고리즘이다.
만약 이 미분값이 양수라면, 가중치를 감소시켰을 때 손실함수 값이 감소한다는 의미이다.
반대로 미분값이 음수라면, 가중치를 증가시켰을 때 손실함수 값이 감소한다는 의미이다.
따라서 미분값이 양수라면, 가중치를 감소시키고
음수라면, 가중치를 증가시켜야 한다.⭐⭐⭐
이번엔 살짝 이전에 다루었던 내용과 중첩되어서 이해가 쉬웠던 것같다.
다음 velog부터는 역전파 학습 알고리즘 등 MLP의 마지막 과정에 대해서 다루어볼 것이다 ㅎㅎ
으 너무 짧은 시간에 하려고 해서 그런지 머리아프다😅
조급하지 않게 천천히 해봐야지🥹
