
1. 순환 신경망이란?
순차 데이터🎏
순차 데이터(Sequence Data) 또는 시계열 데이터(Time Series Data)는 순서가 있는 데이터를 말한다.
시간적인 순서도 가능하며, 공간적인 순서도 가능하다.
예를 들어 주식 가격이나, 텍스트 데이터, 오디오 데이터 등은 모두 데이터 간에 순서가 있다.

이러한 순차 데이터는 어떻게 처리하면 좋을까?
순차 데이터를 처리하여 정확한 예측을 하려면, 과거의 데이터를 어느 정도 기억하고 있어야 한다.
순환 신경망(RNN)은 시계열 또는 자연어와 같은 Sequence 데이터를 모델링하는 데 강력한 신경망이다. RNN은 시계열 데이터나 시퀀스 데이터를 잘 처리할 수 있다.
순환 신경망의 응용 분야😯
- 음성 인식
- 주식 거래 패턴 감지
- 염기 서열 분석
- 언어 모델링
- 번역
- 비디오 동작 인식
- 사용자 감정 분석
일반적으로 RNN은 다음과 같은 기능을 가져야 한다.
- 가변 길이의 입력을 처리할 수 있어야 한다.
- 장기 의존성을 추적할 수 있어야 한다.
- 순서에 대한 정보를 유지해야 한다.
- 시퀀스 전체의 파라미터를 공유할 수 있어야 한다.
2. 순환 데이터의 이해
어떤 사람이 빵을 제조하는 공장을 운영한다고 해보자.🍞
빵의 수요량을 예측한다면 버려지는 빵의 개수를 최소로 줄일 수 있을 것이다.
사업가는 딥러닝 기술을 이용하여 예측을 해보기로 결심하였다.
기업가는 3년동안 매일 같이 빵의 판매량을 기록하여 3년x365 = 1095길이의 데이터를 확보하고 있다.
RNN을 학습하기 위해서는 위의 데이터를 일정한 길이로 잘라서 여러 개의 훈련 샘플을 만들어야 한다.
이 훈련 샘플들은 부분적으로 중첩된다. 이 훈련 샘플을 가지고 RNN을 훈련시키게 되며, 이 샘플의 크기를 윈도우라고 한다.
예를 들어 윈도우가 3이라면 이전 3일동안 판매량 패턴을 가지고 다음 날의 판매량을 예측할 수 있도록 하는 것이다.
예제. 삼성전자 주가 예측
- 라이브러리 설치
activate deep
pip install BeautifulSoup4
pip install finance-datareader- 데이터 불러오기
import FinanceDataReader as fdr
import numpy as np
import matplotlib.pyplot as plt
# 데이터 다운로드
# 삼성전자 코드: 005930
# 2020년도부터 가져옴
samsung = fdr.DataReader('005930','2020') - 데이터 형태 확인
아래와 같이 불러온 데이터 samsung이 데이터프레임 형태이므로 이 중에서 Open 열의 값만 불러와서 사용한다.
print(samsung.head())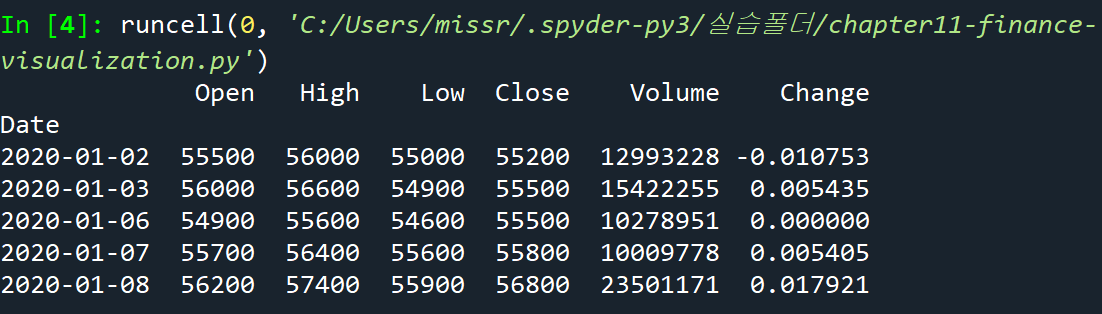
- 시계열 데이터 시각화
# 시작가 취하기
seq_data = (samsung[['Open']]).to_numpy()
# 그래프 출력
plt.plot(date, seq_data, color='blue')
plt.title("Samsung Electronics Stock Price")
plt.xlabel("days")
plt.xticks(rotation=90)
plt.show()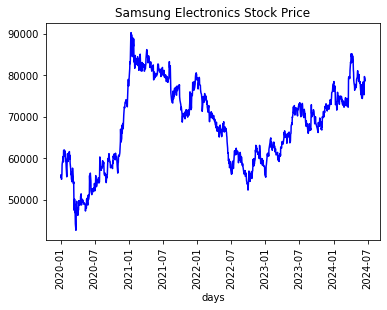
시계열 그래프로 나타내기 위해서는 데이터 프레임에서 추출해온 열 값을 넘파이 배열 형식으로 바꿔서 저장해야 한다.
최근에 학교 전공 수업인 '데이터마이닝'을 통해서 시계열 그래프를 활용하는 방법을 배웠었는데, 곧바로 이 내용을 다루니까 뭔가 익숙한 것같다 ㅎㅎ
내 분야가 시계열 쪽은 아니지만 RNN 모델도 중요하니까 공부해봐야지~!😋
