99클럽 코테 스터디
1기 때는 월,목 위주로 참여하고 그 이외에는 가끔만 풀었는데, 2기는 매일 안끊기고 TIL(Today I Learned)을 작성하도록 노력해 보려고 한다.
오늘 문제는 딱 적당했다. 푸는 데 엄청 오래 걸리진 않았지만, 깊게 생각하면 생각할 게 많은 문제다. 그리고 문제의 조건에도 세심한 면이 있다. 그리고 그걸 다 글로 풀어서 적느라 TIL 적는 게 문제 푸는것보다 훨씬 더 오래 걸렸다...
1번 문제 디스크 컨트롤러 : https://school.programmers.co.kr/learn/courses/30/lessons/42627
출처 : 프로그래머스
1번 문제 디스크 컨트롤러
풀이 접근
코드를 아무 생각 없이 짜면(=요청이 들어온 순서대로 실행하면) 문제의 입출력 예시에 자세히 설명된 예시에서 정답인 9초가 아닌 10초를 return하게 된다. 나도 첫 코드실행 때 10초로 오답이 나왔다...
실행의 우선순위에 대해 고찰이 좀 필요하다.
요청이 여러 개 쌓여 있으면서 앞선 요청의 작업이 딱 종료되는 시점(=다음 작업 시작 시점)에 어떤 작업을 실행해야 할까?
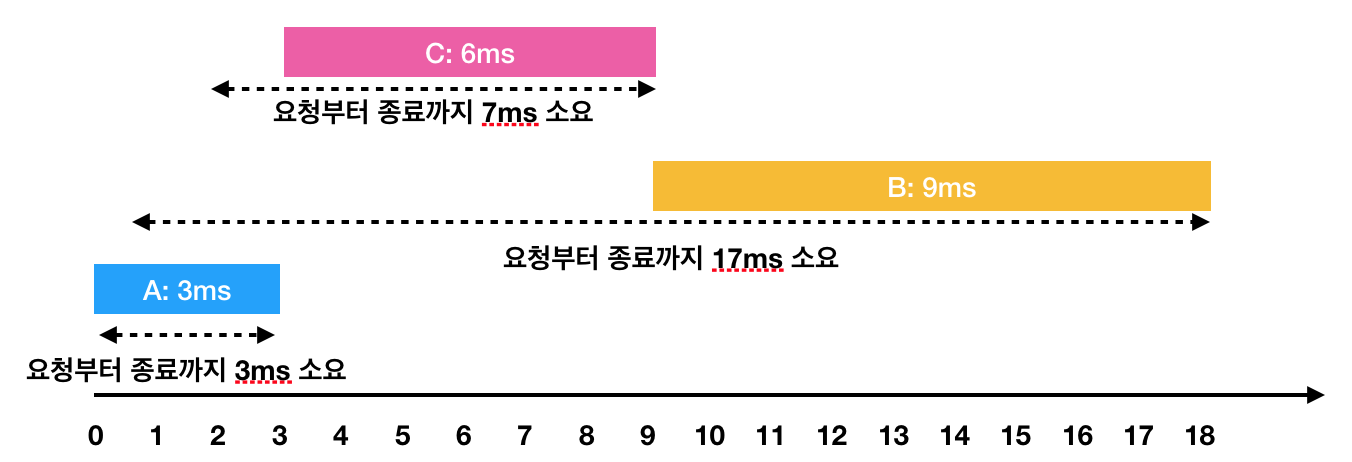
문제의 입출력 예시에 좋은 예시와 그림도 있다. 0ms에 들어온 A 작업은 반드시 실행되므로, 3ms까지는 A 작업을 진행하는 것이 확정된다. 그리고 A 작업이 종료되기 전에 B와 C 두 요청이 들어오는데, 3ms에 A 작업이 끝나면 어떤 작업을 먼저 해야 할까?
'3ms 시점에 B와 C 작업 중 어떤 것을 실행해야 하는가?'라는 질문 자체도 중요하다.
왜냐면, A 작업이 끝나기 전에 들어온 요청은 무조건 3ms까지 대기되므로, B와 C 요청이 들어온 순서나 정확한 시점은 어떤 작업을 실행할지를 결정하는 데에 전혀 중요하지 않게 되기 때문이다. B 요청이 2ms를 대기하고 C 요청이 1ms를 대기하는 것까지는 이미 확정된 상황이고, 현 시점을 3ms라고 생각하는 쪽이 편하다.
따라서 3ms 시점에는 answer에 A의 실행시간인 3 + B의 대기시간 2 + C의 대기시간 1을 더한 6으로 두는 것이다(끝까지 다 더한 뒤에 3으로 나누면 된다).
반대로, 4ms 시점에 들어오는 작업이 있어도 A 작업이 끝난 시점에는 실행할 수 없으므로, 이미 실행된 작업이 딱 끝나는 시점까지 들어온 작업들끼리만 비교하면 된다.
그래서 뭘 먼저 실행하는데? -> 작업의 소요 시간이 짧은 것부터 실행한다.
생각의 흐름이 여기까지 왔다면 거의 푼 셈이다.
힙 자료구조에 아직 실행되지 않은 작업 요청의 소요 시간을 넣어놓고
-> 소요 시간이 제일 짧은 걸 꺼내 실행하고
-> 시점을 해당 작업이 끝날 때로 옮긴다.
-> 그리고 그 작업이 끝나기 전에 들어오는 추가 작업들도 힙에 넣어준다.
-> 그리고 다음 작업이 끝날 때 또 힙에서 제일 짧은 작업을 꺼내 실행한다.
이런 과정을 거치면 된다(밀린 작업이 없는 상황도 따로 고려하여 코드로 짜준다).
풀이 접근 2 - 약간의 사족
반례 찾기에 감각이 있는 사람이라면 몇 가지 반례가 될 만한 상황이 떠오를 수도 있을 텐데(위의 그림에서 10ms 시점에 1ms짜리 작업 D가 들어와서 B를 먼저 실행해야 C보다 D를 먼저 실행할 수 있다던가), 여기에 설명을 다 적기엔 복잡하지만 논리적으로 Greedy하게 소요 시간이 짧은 것부터 실행하면 반드시 최선의 상황이 된다.
또한, 제한 사항 중 마지막 '하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.' 라는 조건도 (보통은 별 생각 없이 넘기겠지만) '당연한 거 아닌가?' 라는 의문이 들 수 있다.
하지만 이런 조건이 없다면, 요청이 들어온 작업이 있는데도 실행을 안 하고 미뤄두는 게 더 나은 상황이 있을 수도 있다.
만약 문제의 입출력 예시에서 4ms 시점에 1ms가 소요되는 작업 D의 요청이 들어온다면, 그리고 5번째 제한 사항이 없다면 3ms 시점에 아무 작업도 실행하지 않고 4ms에 D를 실행하는 게 최선이다.
이 예시에서 ACDB 순으로 쭉 이어서 실행 시 A 3, C 7, D 6, B 18 총 34ms 소요, ADCB 순으로(A 실행 후 1ms 쉬고 DCB 연달아) 실행 시 A 3, D 1, C 9, B 19 총 32ms 소요된다. 4로 나누고 버림해서 평균하면 8초로 똑같지만, B와 C의 실행 시간을 늘리면 정수 평균값이 달라질 만큼 차이가 벌어지게 된다.
왜 이렇게 되는가?
-> 어느 시점에 몇ms짜리 작업 요청이 들어올 지 다 알고 있는 상태라서 그렇다. 현실의 상황이라면 미래에 어떤 요청이 들어올 지 알 수 없으므로 적용하기 어렵기 때문에 이러한 조건을 넣은 것 같다.
코드(Python3, 통과, 최대 0.62ms, 10.3MB)
파이썬의 sort는 참 편하다. 풀이 접근 2에서 반례가 될 만한 예시를 여러 가지 생각해 볼 수 있다고 했는데, 그 중 하나인 '실행 시간이 서로 다른 요청이 동시에 들어오는 경우'도 깔끔하게 정리해주기 때문이다.
무슨 말이냐면, jobs를 [[1,4],[1,2]]로 주더라도, sort 한번 긁어주면 알아서 2초짜리 요청부터 실행하게 된다는 것이다. 그리고 애초에 jobs의 원소를 요청 시각 순으로 준다는 조건도 없기 때문에, sort 안하고 돌리면 채점 케이스 대부분이 오답으로 나온다.
will_end_at은 현재 실행 중인 작업이 끝나는 시각이다.
answer에 총 소요 시간을 다 더하고, 끝나고 n으로 나눈다.
while문에 걸려 있는 조건은, 현재 실행 중인 작업이 끝나는 시각보다 다음 요청이 들어오는 시각이 나중이면서, 밀린 작업이 있다는 조건이다.
그래서 이 때 힙에 저장된 밀린 작업들 중 제일 소요 시간이 짧은 작업을 실행하고, will_end_at에 그 실행 시간을 더해준다. 그리고 그 실행 시간 동안 다른 밀린 작업들도 대기하므로, answer에는 그 실행 시간에 힙에 원래 있던 작업의 개수를 곱해서 더해줘야 한다.
if가 아니고 while문인 이유는, 밀린 작업을 하나 실행하고 나서도 다음 요청이 아직 안 들어왔을 수도 있어서, 밀린 작업을 여러 개 실행해야 될 수도 있기 때문이다.
if문에 걸려 있는 조건은, while문을 통과한 뒤에 도달한 것이므로, 현재 실행 중인 작업이 끝나는 시각보다 다음 요청이 들어오는 시각이 나중이면서, 밀린 작업이 없다는 조건이다.
이 때는 당연히 현재 실행 중인 작업이 끝나고 다음 요청이 들어오기까지 아무 작업도 하지 않다가, 다음 작업이 들어오자마자 실행하게 된다. 따라서 대기 시간 없이 answer에 실행 시간을 더해주고, will_end_at의 값은 다음 작업이 끝나는 시점이 된다.
else의 경우는 현재 실행 중인 작업이 끝나기 전에 다음 요청이 들어온 것이다.
따라서 heap에 그 요청의 소요 시간을 넣어주고, 현재 실행 중인 작업이 끝날 때까지 기다리는 것은 확정이므로 answer에 will_end_at - 요청시각을 더해준다.
이렇게 작업을 전부 순회하면서 바로 실행하거나, 힙에 넣거나, 힙에 넣어둔 걸 실행하는데, 다 끝난 뒤에도 힙에 작업이 남아있을 수 있으므로, 남은 작업들은 소요 시간이 짧은 순서대로 꺼내서 실행하면 된다. 실행할 때마다 해당 작업의 실행 시간 뿐만 아니라 나머지 대기 작업들의 대기 시간도 똑같이 더해줘야 하므로, 힙의 개수만큼 곱해서 answer에 더해준다. 그리고 이 때는 will_end_at을 알 필요가 더 이상 없어서 갱신을 안 했다.
import heapq
def solution(jobs):
jobs.sort()
n = len(jobs)
will_end_at = 0
answer = 0
heap = []
for i in range(n):
requested, time = jobs[i]
while will_end_at <= requested and heap:
shortest_request = heapq.heappop(heap)
answer += (len(heap) + 1) * shortest_request
will_end_at += shortest_request
if will_end_at <= requested:
will_end_at = requested + time
answer += time
else:
heapq.heappush(heap, time)
answer += will_end_at - requested
while heap:
answer += len(heap) * heapq.heappop(heap)
answer //= n
return answer