자연어처리를 공부하고 있다고 하지만 자꾸 기초와 기본지식을 자주 잊어버리는 것 같아 다시 복습하려고 합니다
책은 딥러닝을 이용한 자연어처리 입문을 사용하여 기본지식부터 모델링 까지 해보겠습니다
프레임워크와 라이브버리 설치
텐서플로우 (Tensorflow)
- 구글에서 공개한 머신러닝 오픈소스 라이브러리
pip install tensorflowIn [1]: import tensorflow as tf
In [2]: tf.__version__
Out[2]: '2.18.0'케라스(Keras)
- 텐서플로우에 대한 추상화된 api 제공
pip install kerasIn [1]: import keras
In [2]: keras.__version__
Out[2]: '3.9.0'젠심(Gensim)
- 머신러닝을 사용하여 토픽 모델링과 자연어 처리를 수행할 수 있게 해주는 오픈소스 라이브러리
pip install gensimIn [1]: import gensim
In [2]: gensim.__version__
Out[2]: '4.3.3'사이킷런(Scikit-learn)
pip install sklearnIn [1]: import sklearn
In [2]: sklearn.__version__
Out[2]: '1.5.1'
전처리 패키지 설치
NLTK와 NLTK Data 설치
- NLTK는 자연어 처리를 위한 파이썬 패키지
- 아나콘다를 설치하였다면 기본적으로 설치 되어 있음-> 그래서 나는 뛰어넘겠음
KoNLPy 설치
- 코엔엘파이는 한국어 자연어 처리를 위한 형태소 분석기 패키지
pip install konlpyIn [1]: import konlpy
In [2]: konlpy.__version__
Out[2]: '0.6.0'윈도우에서 KoNLPy 에러가 나는 경우
- jdk 오류나 jpype 오류에 부딪히는 경우가 있어서 jdk 1.7 이상의 버전과 jpype가 설치되어 있어야 함
JDK설치
설치 주소 : https://www.oracle.com/technetwork/java/javase/downloads/index.html
설치 경로를 찾아서 환경변수 설정을 해봅시다
JDK 환경변수
제어판 > 시스템 및 보안 > 시스템 > 고급 시스템 설정 > 고급 > 환경 변수
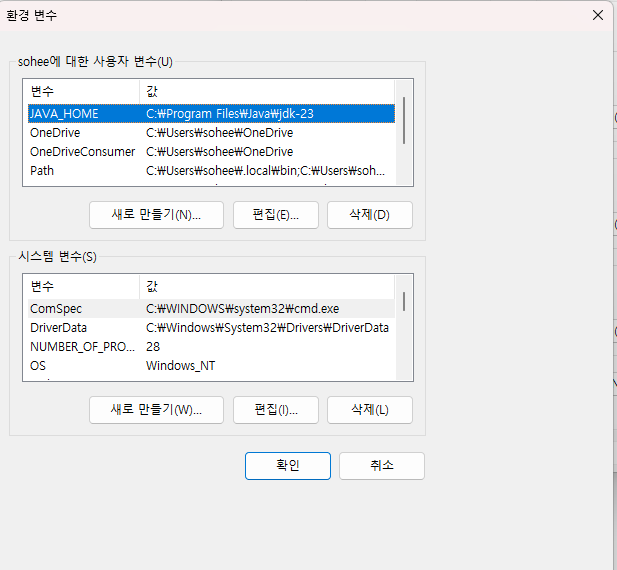
JPype 설치
- JPype는 JAVA와 Python을 연결해주는 역할
설치 주소 : https://github.com/jpype-project/jpype/releases
이제 JPype의 설치가 완료되었다면, KoNLPy를 사용할 준비가 되었습니다.
데이터분석 패키지 설치
판다스(Pandas)
- 파이썬 데이터 처리를 위한 라이브버리
링크 : http://pandas.pydata.org/pandas-docs/stable/
pip install pandasIn [1]: import pandas as pd
In [2]: pd.__version__
Out[2]: '2.2.2'Pandas의 세가지 데이터 구조
- 시리즈 (Series)
- 데이터프레임 (Dataframe)
- 패널(Panel)
시리즈(Series)
- 1차원 배열의 값에 각 값에 대응하는 인덱스를 부여할 수 있음
sr = pd.series([17000, 18000, 1000, 5000],
index =["피자","치킨","콜라","맥주"])
print('시리즈 출력 : ')
print('-'*15)
print(sr)데이터프레임(DataFrame)
- 2차원 리스트를 매개변수로 전달
- 열(columns), 인덱스(index), 값(values)으로 구성
values = [[1,2,3],[4,5,6],[7,8,9]]
index = ['one,','two','three',]
columns = ['A','B','C']
df = pd.DataFrame(values, index=index, columns=columns)
print('데이터프레임 출력 : ')
print('-'*18)
print(df데이터프레임 출력 :
------------------
A B C
one 1 2 3
two 4 5 6
three 7 8 9
데이터프레임 생성
- 리스트로 생성하기
data = [
['1000', 'Steve', 90.72],
['1001', 'James', 78.09],
['1002', 'Doyeon', 98.43],
['1003', 'Jane', 64.19],
['1004', 'Pilwoong', 81.30],
['1005', 'Tony', 99.14],
]
df = pd.DataFrame(data)
print(df) 0 1 2
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14# 열 지정
df = pd.DataFrame(data, columns=['학번', '이름', '점수'])
print(df)
학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14- 딕셔너리로 생성하기
# 딕셔너리로 생성하기
data = {
'학번' : ['1000', '1001', '1002', '1003', '1004', '1005'],
'이름' : [ 'Steve', 'James', 'Doyeon', 'Jane', 'Pilwoong', 'Tony'],
'점수': [90.72, 78.09, 98.43, 64.19, 81.30, 99.14]
}
df = pd.DataFrame(data)
print(df) 학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14데이터프레임 조회하기
- df.head(n) : 앞 부분을 n개만 보기
- df.tail(n): 뒷 부분을 n개만 보기
- df['열이름'] : 해당되는 열을 확인
# 앞 부분을 3개만 보기
print(df.head(3))
# 뒷 부분을 3개만 보기
print(df.tail(3))
# '학번'에 해당되는 열을 보기
print(df['학번'])외부 데이터 읽기
- pandas는 csv,text,excel,sql,html,json등 다양한 데이터 파일을 읽고 데이터 프레임을 생성
# csv파일 읽기
df = pd.read_csv('example.csv')넘파이(Numpy)
- 수치를 다루는 파이썬 패키지
- 다차원 행렬 자료구조인 ndarray를 통해 행렬 계산
pip install numpyIn [1]: import numpy as np
In [2]: np.__version__
Out[2]: '1.16.5'np.array()
- 차원 배열 만들기
vec = np.array([1,2,3,4,5])- 2차원 배열 만들기
mat = np.array([[10,20,30],[60,70,80]])ndim : 축의 개수
shape : 크기
print('vec의 축의 개수 :',vec.ndim) # 축의 개수 출력
print('vec의 크기(shape) :',vec.shape) # 크기 출력
vec의 축의 개수 : 1
vec의 크기(shape) : (5,)print('mat의 축의 개수 :',mat.ndim) # 축의 개수 출력
print('mat의 크기(shape) :',mat.shape) # 크기 출력
mat의 축의 개수 : 2
mat의 크기(shape) : (2, 3)ndarray의 초기화
- np.zeros(): 배열의 모든 원소에 0을 삽입
- np.ones(): 배열의 모든 원소에 1을 삽입
- np.full(): 배열에 사용자가 지정한 값 삽입
# 모든 값이 특정 상수인 배열 생성. 이 경우 7.
same_value_mat = np.full((2,2), 7)
print(same_value_mat)
[[7 7]
[7 7]]- np.eye() : 대각선으로 1이고 나머지는 0인 2차원 배열 생성
# 대각선 값이 1이고 나머지 값이 0인 2차원 배열을 생성.
eye_mat = np.eye(3)
print(eye_mat)
[[1. 0. 0.]
[0. 1. 0.]]
[0. 0. 1.]]- np.random.random() : 임의의 값을 가지는 배열 생성
np.arange()
- np.arange(n) : 0 부터 n-1까지의 값을 가지는 배열 생성
# 0부터 9까지
range_vec = np.arange(10)
>>> [0 1 2 3 4 5 6 7 8 9]- np.arange(i,j,k) : i부터 j-1까지 k씩 증가하는 배열을 생성
# 1부터 9까지 +2씩 적용되는 범위
n = 2
range_n_vec = np.arange(1,10,n)
>>> [1 3 5 7 9]np.reshape()
- np.reshape() : 내부 데이터는 변경하지 않으면서 배열의 구조를 바꿈
# 0부터 29까지의 숫자 생성후
# 5행 6열 행렬로 변경
reshape_mat = np.array(np.arrange(30)).reshape(5,6))
>>>
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]Numpy 슬라이싱
mat = np.array([[1,2,3][4,5,6]])
>>>
[[1 2 3]
[4 5 6]]
# 첫번째 행 출력
slicing_mat = mat[0,:]
>>> [1 2 3]
# 두번재 열 출력
slicing_mat = mat[:,1]
>>> [2 5]Numpy 연산
- 덧셈, 뺄셈, 곱셈, 나눗셈을 위해서는 연산자
+, -, *, /사용 - 또는
np.add(), np.subtract(), np.multiply(), np.divide()사용 - *를 통해 수행한 것은 요소별 곱. Numpy에서 벡터와 행렬곱 또는 행렬곱을 위해서는 dot()을 사용
mat1 = np.array([[1,2],[3,4]])
mat2 = np.array([[5,6],[7,8]])
mat3 = np.dot(mat1, mat2)
print(mat3)
>>>
[[19 22]
[43 50]]맷플로립(Matplotlib)
- 데이터를 차트나 plot으로 시각화하는 패키지
pip install matplotlib
In [1]: import matplotlib as mpl
In [2]: mpl.__version__
Out[2]: '2.2.3'라인 플롯 그리기
- plot() : 라인 플롯을 그리는 기능
- title() : 제목 지정
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.show()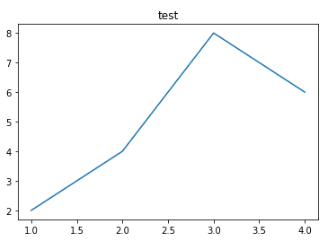
축 레이블 삽입하기
- xlabel,ylabel('넣고 싶은 축이름')
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.xlabel('hours')
plt.ylabel('score')
plt.show()
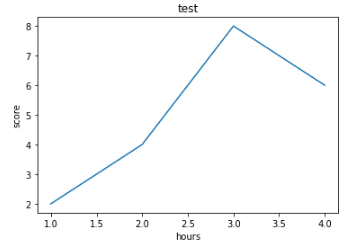
라인 추가와 범례 삽입하기
- legend() : 범례 삽입
plt.title('students')
plt.plot([1,2,3,4],[2,4,8,6])
plt.plot([1.5,2.5,3.5,4.5],[3,5,8,10]) # 라인 새로 추가
plt.xlabel('hours')
plt.ylabel('score')
plt.legend(['A student', 'B student']) # 범례 삽입
plt.show()
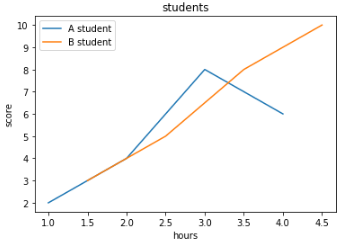

인공지능.관심 있습니다.