머신러닝 워크플로우(Machine Learning Workflow)
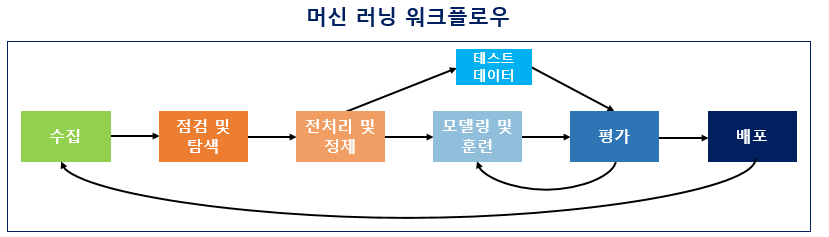
수집 (Acquisition)
- 머신런닝을 하기 위해서는 기계에 학습시켜야 할 데이터가 필요
- 텍스트 데이터의 파일 형식은 txt,csv,xml 파일 등 댜양
점검 및 탐색(Inspection and exploration)
- 데이터의 구조, 노이즈 데이터, 머신러닝 적용을 위해서 데이터를 어떻게 정제할지 파악
- 탐색적 데이터 분석(EDA)단계라고도 함. 이 과정에서 시각화와 간단한 통계 테스트 진행
전처리 및 정제(Modeling and Training)
- 토큰화, 정제, 정규화, 불용어 제거 등의 단계
모델링 및 훈련 (Modeling and Training)
- 적절한 머신러닝 알고리즘을 선택하여 모델링이 끝났다면, 전처리가 완료된 데이터를 알고리즘을 통해 기계에게 학습(trainig)시킴
- 훈련이 제대로 되었다면 기계는 우리가 원하는 task인 기계번역, 음성 인식, 텍스트 분류 등의 자연어 처리 작업을 수행할 수 있게 됨
여기서 주의할 점
- 모든 데이터를 기계에 학습시키면 안 된다
- 데이터 중 일부는 테스트용, 훈련용 데이터로 구분해야함
- 오버피팅을 막을 수 있다 - 최선의 방법은 훈련용, 검증용, 테스트용으로 세가지 나누고 훈련용 데이터만 훈련에 사용하기

검증용과 테스트용 차이?
-
검증용 데이터는 현재 모델의 성능 즉 기계가 훈련용 데이터로 얼마나 제대로 학습이 되었는지를 판단하는 용
-
테스트 데이터는 모델의 최종 성능을 평가하는 데이터로 모델의 성능을 개선하는 일에 사용되지X
훈련용: 학습지
검증용: 모의고사
테스트용: 수능시험
-> 와 이거 정말 정확한 비유
평가(Evaluation)
- 기계가 학습이 되었다면 테스트용으로 성능을 평가하게 된다
- 평가 방법은 기계가 예측한 데이터가 테스트용 데이터의 실제 정답과 얼마나 가까운지를 측정
배포 (Deployment)
- 평가 단계에서 기계가 성공적으로 훈련이 된 것으로 판단되면 모델이 배포되는 단계

인공지능.관심 있습니다.