Spring AI, OpenAI Embeddings, PGVector(PostgreSQL)를 활용해
PDF 문서를 업로드하면 자동으로 임베딩하여 벡터 DB에 저장하고,
사용자가 질문을 하면 관련 문서를 검색해 LLM이 참조하도록 하는
RAG(Retrieval-Augmented Generation) 시스템을 실습을 통해 익혀보자.
- 사용자가 PDF 업로드
- PDF → 텍스트 추출 → Chunk(TokenTextSplitter)
- Chunk를 OpenAI Embedding 모델로 벡터화4.
- PGVector DB에 저장
- 질문 입력
- 질문을 임베딩 → 벡터 검색(similaritySearch)
- 연관 문서를 LLM Prompt에 삽입
의존성 설정
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
compileOnly 'org.projectlombok:lombok'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
}
dependencyManagement {
imports {
mavenBom "org.springframework.ai:spring-ai-bom:${springAiVersion}"
}
}application.properties
spring.application.name=spring_AI_8_rag
server.port=8090
spring.ai.openai.api-key=${OPENAI_API_KEY}
# postgresql 과 pgvector 설정
spring.datasource.url=jdbc:postgresql://localhost:5432/regdb
spring.datasource.username=user
spring.datasource.password=${postgre_password}
spring.datasource.driver-class-name=org.postgresql.Driver
# PGVector 설정
# 기본값 - 벡터검색에 사용할 인덱스의 유형 고성능 근사 근접 이웃 검색을 위한 익덱스 방식
spring.ai.vectorstore.pgvector.index-type=HNSW
# 기본값 - 벡터간의 유사도를 측정할 때 사용할 거리 계산 방식 (코사인 유사도 - 값이 작을 수록 유사하다)
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
# 기본값 - 벡터의 차원수 - 1536은 OpenAI의 GPT모델에서 생성도니 임베딩의 기본 벡터 차원
spring.ai.vectorstore.pgvector.dimensions=1536
spring.ai.vectorstore.pgvector.initialize-schema=true
#jpa 설정
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=truePGVector 설정 설명
- HNSW : 대규모 문서에서 빠른 근사 검색 제공
- distance-type=COSINE : 임베딩 비교 시 가장 많이 사용하는 방식
- dimensions=1536 : OpenAI embeddings model 기준
- initialize-schema=true : 자동으로 pgvector 테이블 생성
service
package kr.or.kosa.service;
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import lombok.RequiredArgsConstructor;
@Service
@RequiredArgsConstructor
public class EmbedingService {
private final VectorStore vectorStore; // lombok 자동주입
// 문서, txt를 read해서 숫자화된 배열로
public void processUploadPdf(MultipartFile file) throws IOException {
// 사용자가 업로드한 pdf를 바로 읽으면 성능이 떨어진다.
// 임시파일로 만들어서 로컬 tamp 폴더 안에 uploadxxxx.pdf로 자동 생성
File tmpFile = File.createTempFile("upload", "pdf");
file.transferTo(tmpFile);
Resource fileResource = new FileSystemResource(tmpFile);
try {
// PDF 문서를 읽을건데 형식(옵션)을 정의할게. ex) 제목이랑 공백은 제거하라는 환경설정
PdfDocumentReaderConfig config = PdfDocumentReaderConfig
.builder()
.withPageTopMargin(0) // PDF 페이지 상단 여백 0
.withPageExtractedTextFormatter( // 객체들어감
ExtractedTextFormatter // 페이지에서 추출한 텍스트 포맷팅 방식
.builder()
.withNumberOfBottomTextLinesToDelete(0) //상단이나 하단에서 지울 줄 수
.build()
)
.withPagesPerDocument(1) // 한번에 처리할 페이지 수
.build();
PagePdfDocumentReader pdfDocumentReader =
new PagePdfDocumentReader(fileResource, config);
List<Document> documents = pdfDocumentReader.get();
// 벡터화(float 배열 생성)
TokenTextSplitter splitter = new TokenTextSplitter(1000,400,10,5000,true);
List<Document> spDovuments = splitter.apply(documents);
// PGvector store 저장
vectorStore.accept(documents);
} catch (Exception e) {
e.printStackTrace();
} finally {
// IO자원 해제 임시 파일 삭제
tmpFile.delete();
}
}
}
TokenTextSplitter 동작 원리와 권장 설정 설명
문서를 임베딩하기 위해서는 원본 텍스트를 일정 크기의 조각(Chunk)으로 나누어야 한다.
Spring AI에서는 이 작업을 TokenTextSplitter가 담당하며,
아래와 같은 파라미터로 세밀하게 청크를 제어할 수 있다:
TokenTextSplitter(
int chunkSize,
int chunkOverlap,
int minChunkSize,
int maxChunkSize,
boolean keepSeparators
)청크란?
긴 문서를 일정한 크기로 잘라서 만든 ‘텍스트 조각(덩어리)’입니다.
RAG, 임베딩, 벡터 검색 등을 할 때
문서를 그대로 전체로 사용하지 않고 청크 단위로 나누어 처리합니다.
chunkSize: 청크 크기(토큰 기준)
예를 들어 chunkSize를 1000으로 설정하면
한 번에 최대 1000 토큰을 하나의 청크로 생성한다.
여기서 1000 토큰은 1000 단어가 아니라,
- 한국어 기준: 약 500~800 단어
- 영어 기준: 약 700~900 단어
정도에 해당하며, A4 기준 1~2페이지 분량이라고 보면 된다.
chunkOverlap: 청크 간 중복 포함 토큰 수
문맥 유지를 위해 이전 청크의 일부 내용을 다음 청크에 중복 포함할 수 있다.
예를 들어 chunkOverlap = 400이라면:
Chunk1: A B C D E F G
Chunk2: E F G H I J K이런 식으로 앞쪽의 400 토큰이 다음 청크에도 포함된다.
왜 필요한가?
- 문맥 단절 방지
- 질문과 관련된 정보를 다음 청크에서도 참조 가능
- 결과적으로 RAG 정확도 상승
단점은,
- 중복되는 만큼 임베딩 처리량 증가
- 비용 상승
실제 RAG 구조에서는
chunkSize=800~1200 / chunkOverlap=200~400 조합이 가장 안정적이다.
minChunkSize / maxChunkSize
- minChunkSize: 너무 작은 청크는 제거
- maxChunkSize: 특정 크기 이상이면 강제로 분할
문서가 너무 짧거나, 불필요한 단문이 들어오는 상황을 방지하기 위해 필요하다.
keepSeparators: 구분자 포함 여부
구분자는 다음과 같은 것들이다:
- 개행(\n)
- 마침표(.)
- 문장 부호
구분자 포함 여부는 청크의 자연스러움에 크게 영향을 준다.
keepSeparators = true (권장)
- 문장 단위가 자연스럽게 이어짐
- 문맥 유지에 유리
- 검색 시 내용 이해가 더 명확함
keepSeparators = false
- 구분자 제거
- 임베딩 데이터 크기 약간 감소
- 문맥 흐름이 다소 끊길 수 있음
대부분의 RAG 시스템에서는 true를 사용해
청크 단위를 최대한 자연스럽게 유지하는 것을 권장한다.
controller
Controller는 PDF 업로드 API와 RAG 질의 API 두 가지를 제공한다.
package kr.or.kosa.controller;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import kr.or.kosa.service.EmbedingService;
import lombok.RequiredArgsConstructor;
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/documents")
public class DocumentUploadController {
private final ChatModel chatModel;
private final EmbedingService embedingService;
private final VectorStore vectorStore;
@PostMapping("/upload")
public ResponseEntity<String> puliadPdf(@RequestParam("file") MultipartFile file) {
try {
embedingService.processUploadPdf(file);
return ResponseEntity.ok("PDF 파일 업로드 임배딩 처리 완료");
} catch (Exception e){
return ResponseEntity.status(
HttpStatus.INTERNAL_SERVER_ERROR).body("오류 : " + e.getMessage());
}
}
// LLM질의 > 벡터데이터 참조 > 유사도 기반으로 > LLM질의 > 결과
private String promptTempate = """
다음 문서를 참고하여 질문에 대해 답변해 주세요.
문서에서 답을 찾을 수 없다면, "관련 정보를 찾을 수 없습니다." 라고 답변해 주세요
[문서]
{context}
[질문]
{question}
""";
// 파일로 만들고 싶으면 st 파일로
@PostMapping("/rag")
public String regChat (@RequestParam("question") String question) {
PromptTemplate template = new PromptTemplate(promptTempate);
Map<String, Object> promptParameters = new HashMap<>();
promptParameters.put("question", question);
promptParameters.put("context", "");
// VectorStore 에서 유사도가 높은 문서 n개를 검색
List<Document> similartyDocuments = vectorStore.similaritySearch(SearchRequest
.builder()
.query(question)
.topK(2)
.build());
// 검색된 문서 내용을 하나의 문자열로 결합하여 출력
String documents = similartyDocuments
.stream()
.map(document -> document.getFormattedContent().toString())
.collect(Collectors.joining("\n"));
promptParameters.put("context", documents);
// 유사도 높은 문장 결합해서 최종적으로 질의
return chatModel.call(template.create(promptParameters)).getResult().getOutput().getText();
}
}
결과
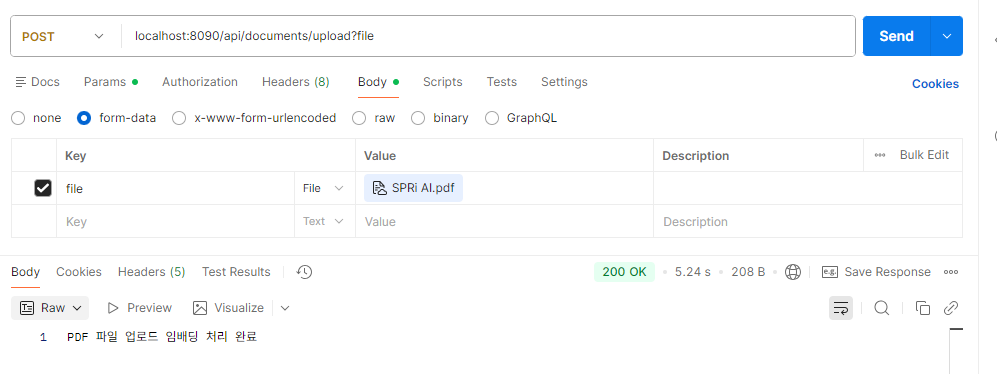
→ body에 form-data의 value에 SPRi(지능정보사회진흥원)에서 매달 발행하는 공식 보고서 총 25p의 PDF파일을 넣었다.
→ 정상적으로 임베딩 처리 완료
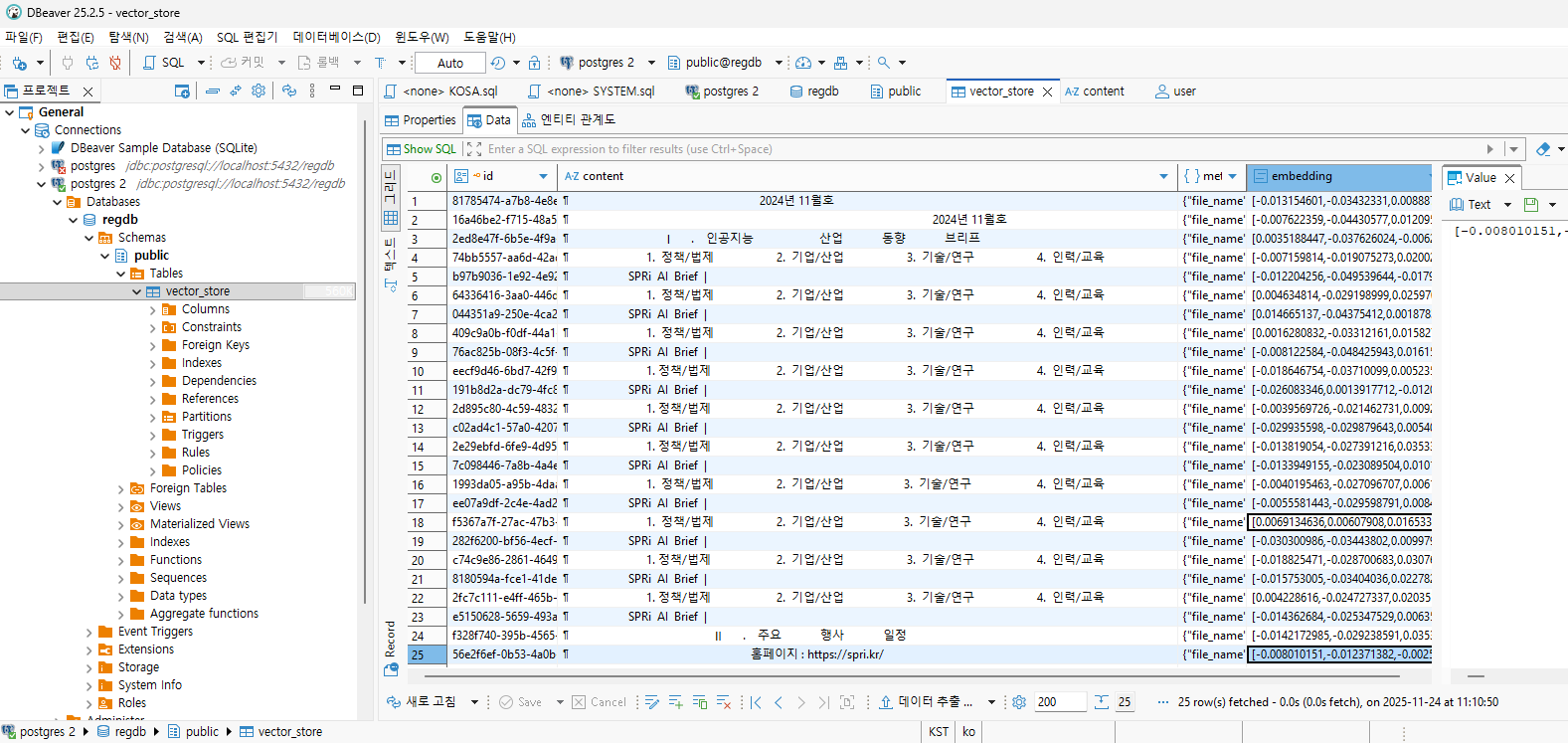

→ PDF가 성공적으로 청크 분리됨
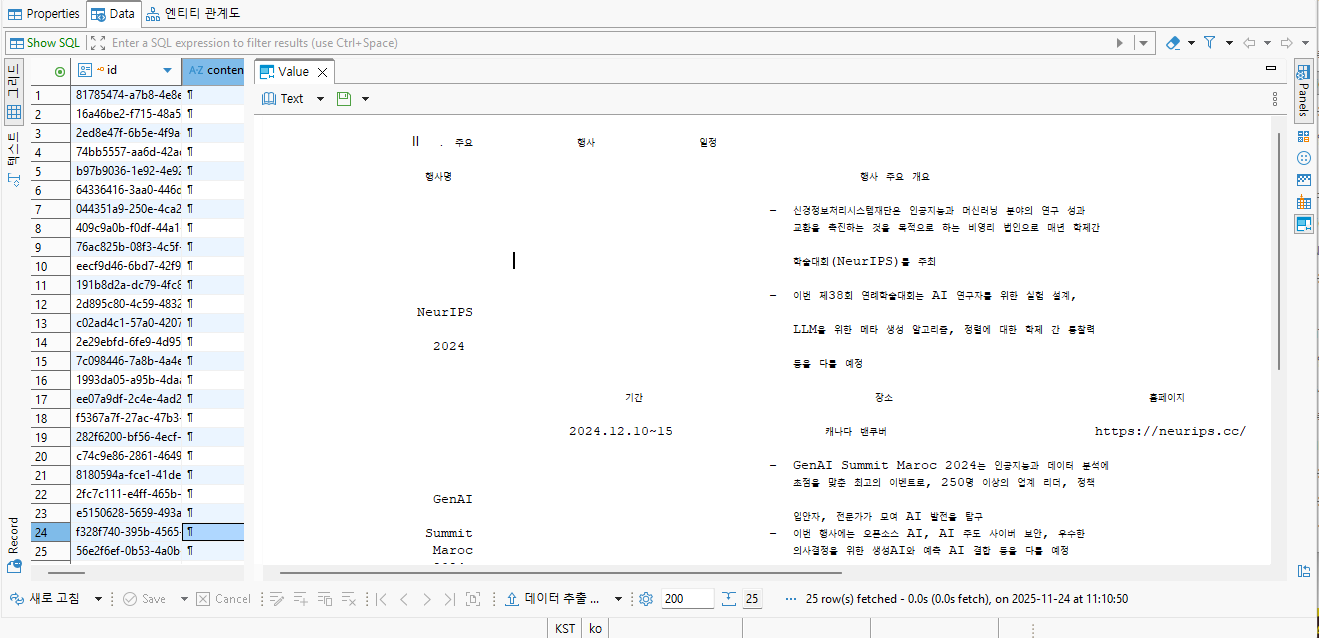
TokenTextSplitter로 잘려진 청크(Chunk)
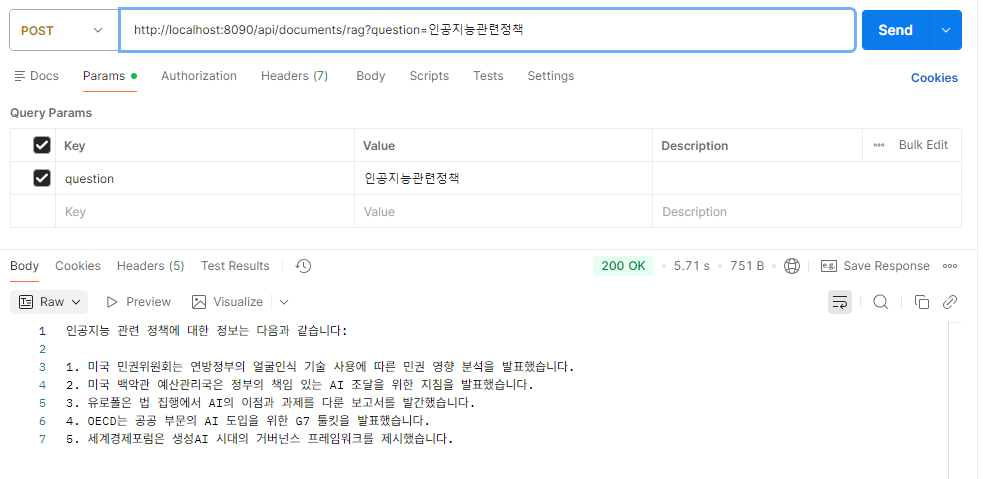
사용자가 질문 → 질문을 Embedding(1536차원 벡터) →
PGVector DB에서 가장 가까운 문서 벡터 검색(similaritySearch) →
상위 문서 n개(topK) 반환 →
LLM에게 문서 + 질문을 던져 답변 생성
→ similaritySearch 검색 결과가 정상적으로 출력됨
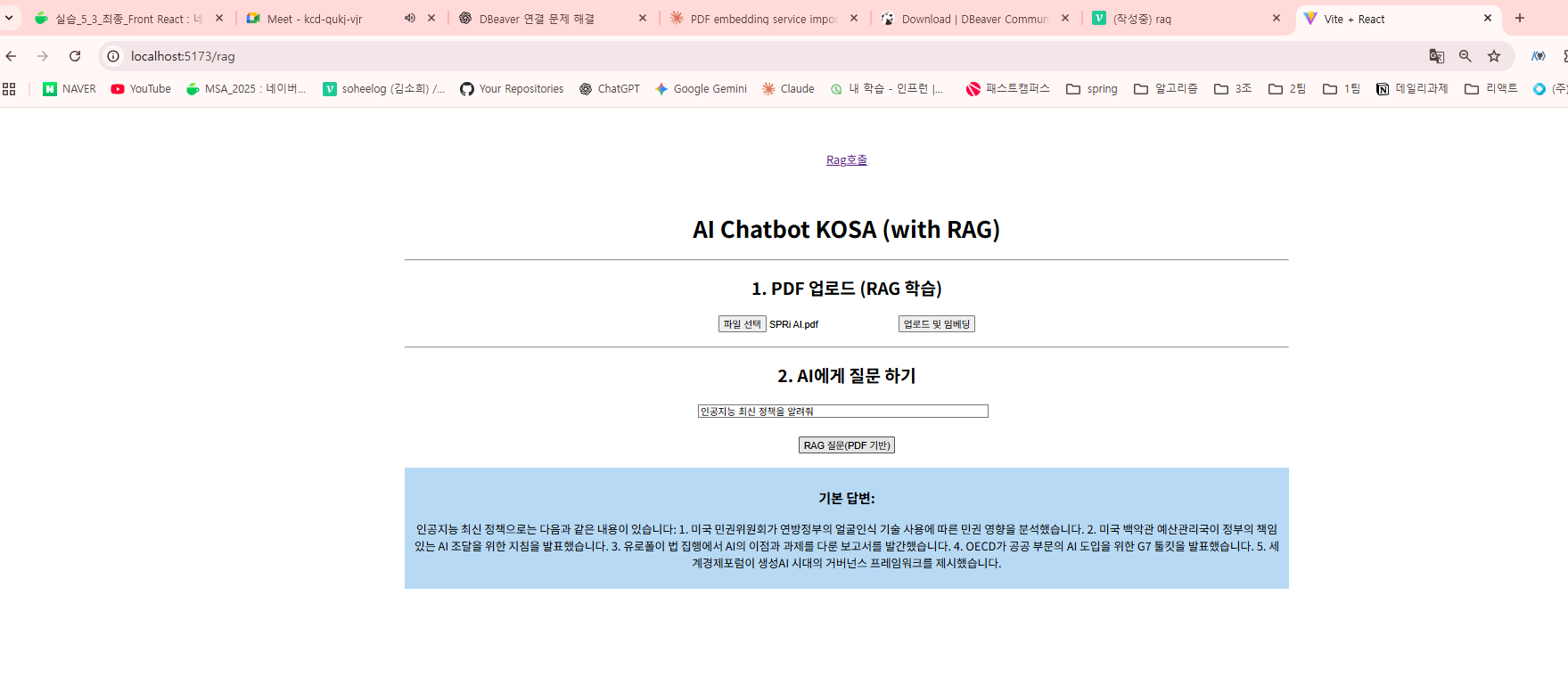

리액트로 간단한 프론트를 생성하여 테스트하였다.
ChatModel이 context + question 기반으로 응답 생성
참고자료
