HTTP
1. Http와 Https 통신 방식의 차이에 대해 설명해주세요. 레퍼런스
: HTTP(Hyper Text Transfer Protocol)란 인터넷에서 하이퍼텍스트를 교환하기 위한 통신 규약이다. HTTP는 애플리케이션 레벨의 프로토콜로 TCP/IP 위에서 작동한다. HTTP는 상태를 가지고 있지 않는 Stateless 프로토콜이며 Method, Path, Version, Headers, Body 등으로 구성된다. 하지만 HTTP는 암호화가 되지 않은 평문 데이터를 전송하는 프로토콜이였기 때문에, HTTP로 비밀번호나 주민등록번호 등을 주고 받으면 제3자가 정보를 조회할 수 있었다. 이러한 문제를 해결하기 위해 HTTPS가 등장하게 되었다.
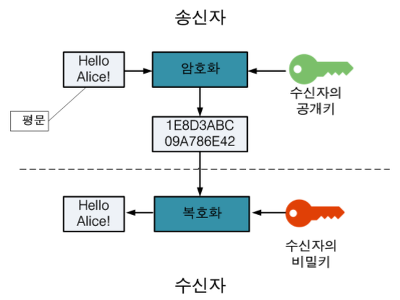
HTTPS는 HTTP에 데이터 암호화가 추가된 프로토콜이다. HTTPS는 네트워크 상에서 중간에 제3자가 정보를 볼 수 없도록 공개키 암호화를 지원하고 있다. HTTPS는 공개키/개인키 암호화 방식을 이용해 데이터를 암호화하고 있다. 공개키와 개인키는 서로를 위한 1쌍의 키이다.
공개키: 모두에게 공개가능한 키
개인키: 나만 가지고 알고 있어야 하는 키
공개키와 개인키로 암호화하면 다음과 같은 효과를 얻을 수 있다.
공개키 암호화: 공개키로 암호화를 하면 개인키로만 복호화할 수 있다. -> 개인키는 나만 가지고 있으므로, 나만 볼 수 있다.
개인키 암호화: 개인키로 암호화하면 공개키로만 복호화할 수 있다. -> 공개키는 모두에게 공개되어 있으므로, 내가 인증한 정보임을 알려 신뢰성을 보장할 수 있다.
HTTP는 암호화가 추가되지 않았기 때문에 보안에 취약한 반면, HTTPS는 안전하게 데이터를 주고받을 수 있다. 하지만 HTTPS를 이용하면 암호화/복호화의 과정이 필요하기 때문에 HTTP보다 속도가 느리다.(오늘날에는 거의 차이를 못느낄 정도) 또한 HTTPS는 인증서를 발급하고 유지하기 위한 추가 비용이 발생한다. 개인 정보와 같은 민감한 데이터를 주고 받아야 한다면 HTTPS를 이용해야 하지만, 단순한 정보 조회 등만을 처리하고 있다면 HTTP를 이용하면 된다.
2. HTTP 프로토콜에 대해 설명해주세요. 레퍼런스
: 인터넷에서 데이터를 주고 받기 위한 통신 규약이다. 서버(서비스 제공)/클라이언트(서비스 요청) 모델을 모델을 따르는 프로토콜이고, 애플리케이션 레벨의 프로토콜로 TCP(데이터의 정확성 확인)/IP(패킷을 목적지까지 전송)위에서 작동한다.
웹브라우저에서 클라이언트가 요청(request)을 보내면 서버가 요청을 처리해서 응답(response)한다.
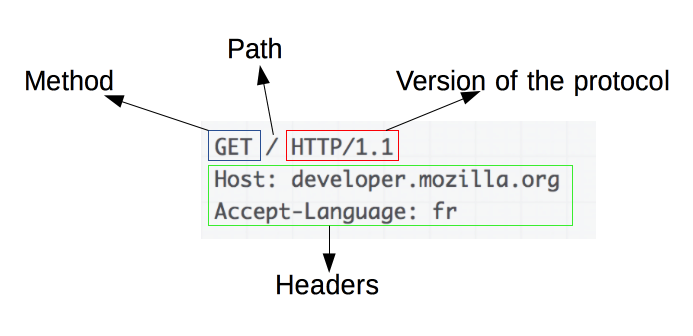
요청 데이터는 "HEADER"와 "BODY"로 구성된다.
- 요청 메서드 : GET, PUT, POST, PUSH, OPTIONS 등의 요청 방식이 온다.
- 요청 URI : 요청하는 자원의 위치를 명시한다.(URI > URL, URL은 자원의 위치를 나타내 주는 것이고 URI는 자원의 식별자이다)
- HTTP 프로토콜 버전 : 웹 브라우저가 사용하는 프로토콜 버전이다.
그 외의 키값
- Host : 요청을 보내는 Host
(예) www.google.co.kr - Content-Type : 요청에 바디가 있는 경우 그 파일 포맷
(예) Content-Type: application/json - Cookie : 웹 브라우저에 저장된 쿠키들
- User-Agent : 클라이언트의 정보, 이를 통해 사용하는 브라우저 감지
HTTP 응답은
- 프로토콜과 응답코드 : 웹 브라우저가 사용하는 프로토콜, 서버의 응답 상태 (1xx~5xx, 2xx (성공), 4xx (요청 오류), 5xx (서버 오류)), 응답 메시지를 보여준다
- Set-Cookie : 웹 브라우저에게 쿠키 생성을 요청
(예) Set-Cookie: UserID=tester; Max-Age=3600; Version=1 - Content-Type : 응답에 바디가 있는 경우 그 포맷
(예) Content-Type: text/html; charset=utf-8
로 구성된다.
웹브라우저의 통신 과정은 URL 분석 및 접속 - Request 헤더 전송 - Request 바디 전송 - Response 헤더 해석 - Response 바디 해석으로 이루어진다.
i. 무상태(Stateless)와 비연결성(Connectless)에 대해 설명해주세요.
: HTTP는 Connectless & Stateless 방식으로 작동한다. 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다(Connectless). 불특정 다수를 대상으로 하는 서비스에 적합한 방식이지만, 클라이언트의 이전 상태를 알 수가 없다(Stateless)는 단점이 있다.
3. REST API에 대해 설명해주세요.
레퍼런스 레퍼런스2 레퍼런스3
: REST(REpresentational State Transfer)란 어떤 자원에 대해 CRUD를 수행하기 위해 URI(Resource)로 요청을 보내는 것으로, 요청을 위한 자원이 특정한 형태(Representation of Resource)로 표현된다. 요청을 위한 Resource(자원, URI)와 이에 대한 Method(행위) 그리고 Representation of Resource(자원의 형태, JSON)로 구성된다.
구성요소
- Resource
서버는 Unique한 ID를 가지는 Resource를 가지고 있으며, 클라이언트는 이러한 Resource에 요청을 보냅니다. 이러한 Resource는 URI에 해당합니다.
- Method
서버에 요청을 보내기 위한 방식으로 GET, POST, PUT, PATCH, DELETE가 있습니다. CRUD 연산 중에서 처리를 위한 연산에 맞는 Method를 사용하여 서버에 요청을 보내야 합니다.(GET과 POST의 차이는 여기를 참고해주세요!)
- Representation of Resource
클라이언트와 서버가 데이터를 주고받는 형태로 json, xml, text, rss 등이 있습니다. 최근에는 Key, Value를 활용하는 json을 주로 사용합니다.
RESTful API가 되기 위한 REST 아키텍쳐의 특징
-
Uniform Interface(일관된 인터페이스)
Uniform Interface란, Resource(URI)에 대한 요청을 통일되고, 한정적으로 수행하는 아키텍처 스타일을 의미합니다. 이것은 요청을 하는 Client가 플랫폼(Android, Ios, Jsp 등) 에 무관하며, 특정 언어나 기술에 종속받지 않는 특징을 의미합니다. 이러한 특징 덕분에 Rest API는 HTTP를 사용하는 모든 플랫폼에서 요청가능하며, Loosely Coupling(느슨한 결함) 형태를 갖게 되었습니다. -
Stateless(무상태성)
서버는 각각의 요청을 별개의 것으로 인식하고 처리해야하며, 이전 요청이 다음 요청에 연관되어서는 안됩니다. 그래서 Rest API는 세션정보나 쿠키정보를 활용하여 작업을 위한 상태정보를 저장 및 관리하지 않습니다. 이러한 무상태성때문에 Rest API는 서비스의 자유도가 높으며, 서버에서 불필요한 정보를 관리하지 않으므로 구현이 단순합니다. 이러한 무상태성은 서버의 처리방식에 일관성을 부여하고, 서버의 부담을 줄이기 위함입니다.
- Cacheable(캐시 가능)
Rest API는 결국 HTTP라는 기존의 웹표준을 그대로 사용하기 때문에, 웹의 기존 인프라를 그대로 활용할 수 있습니다. 그러므로 Rest API에서도 캐싱 기능을 적용할 수 있는데, HTTP 프로토콜 표준에서 사용하는 Last-Modified Tag 또는 E-Tag를 이용하여 캐싱을 구현할 수 있고, 이것은 대량의 요청을 효울척으로 처리할 수 있게 도와줍니다.
- Client-Server Architecture (서버-클라이언트 구조)
Rest API에서 자원을 가지고 있는 쪽이 서버, 자원을 요청하는 쪽이 클라이언트에 해당합니다. 서버는 API를 제공하며, 클라이언트는 사용자 인증, Context(세션, 로그인 정보) 등을 직접 관리하는 등 역할을 확실히 구분시킴으로써 서로 간의 의존성을 줄입니다.
- Self-Descriptiveness(자체 표현)
Rest API는 요청 메세지만 보고도 이를 쉽게 이해할 수 있는 자체 표현 구조로 되어있습니다. 아래와 같은 JSON 형태의 Rest 메세지는 http://localhost:8080/board 로 게시글의 제목, 내용을 전달하고 있음을 손쉽게 이해할 수 있습니다. 또한 board라는 데이터를 추가(POST)하는 요청임을 파악할 수 있습니다.
HTTP POST , http://localhost:8080/board
{
"board":{
"title":"제목",
"content":"내용"
}
}- Layered System(계층 구조)
Rest API의 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 등을 위한 계층을 추가하여 구조를 변경할 수 있습니다. 또한 Proxy, Gateway와 같은 네트워크 기반의 중간매체를 사용할 수 있게 해줍니다. 하지만 클라이언트는 서버와 직접 통신하는지, 중간 서버와 통신하는지 알 수 없습니다.
(얄코: 각 요청이 어떤 동작이나 정보를 위한 것인지를 그 요청의 모습 자체로 추론 가능, 요청을 보내는 주소만으로도 대략 뭘 하는 요청인지 파악가능, 자원을 구조와 함께 나태내는 형태의 구분자 --> URI, REST API요청을 보낼 때는 HTTP형식에 따라, POST,PUT,PATCH는 BODY > GET, DELETE, 목적에 따라 구분해서 사용, 명사형, HTTP요청을 보낼 때 어떤 URI에 어떤 메소드를 사용하지 개발자들 사이의 약속(형식))
4. GET 메서드와 POST 메서드의 차이점에 대해 설명해주세요. 레퍼런스
: GET은 서버의 리소스에서 데이터를 요청할 때, POST는 서버의 리소스를 새로 생성하거나 업데이트할 때 사용한다. GET은 URL에 요청하는 데이터를 담아 보내기 때문에 HTTP 메시지에 body가 없지만, POST는 body에 데이터를 담아 보내기 때문에 HTTP 메시지에 body가 존재한다. GET 요청은 리소스를 조회하기 때문에 연산을 여러 번 적용하더라도 결과가 달라지지 않는다. 하지만 POST는 리소스를 새로 생성하거나 업데이트할 때 사용되기 때문에 여러번 요청하면 서버가 변경될 수 있다.
5. PUT 메서드와 PATCH 메서드의 차이점에 대해 설명해주세요. 레퍼런스 레퍼런스2
: PUT은 리소스의 모든 것을 업데이트하고, PATCH는 리소스의 일부를 업데이트한다. PUT은 자원의 전체를 보내지않고 일부분만 보내게되면 보내지지 않은 정보에 대해서는 null값으로 업데이트하지만, PATCH는 기존 데이터를 유지하는 방식으로 대응한다.
6. Expires, Date, Age, If-Modified-Since의 차이점에 대해 설명해주세요. 레퍼런스
: 캐시 처리 단계 중 응답 생성 단계에서 캐시는 캐시 된 서버 응답 헤더를 토대로 응답 헤더를 생성한다. 이 기저 헤더들은 캐시에 의해 수정되고 늘어난다. 캐시는 클라이언트에 맞게 이 헤더를 조정해야 하는 책임이 있다. 캐시는 캐시 신선도 정보를 삽입하며(Cache-Control, Age, Expires(절대 유효기간) 헤더) 요청이 프락시 캐시를 거쳐갔을 경우 Via 헤더를 포함시킨다. Date 헤더는 그 객체가 원서버에서 최초로 생겨난 일시이기 때문에 조정해서는 안된다.
HTTP는 캐시가 서버에게 조건부 GET이라는 요청을 보낼 수 있도록 해준다. 이 요청은 서버가 갖고 있는 문서가 캐시가 갖고 있는 것과 다를 경우에만
객체 본문을 보내달라고 하는 것이다. 신선도 검사와 객체를 받아오는 것은 하나의 조건부 GET으로 결합된다. 조건부 GET은 GET 요청 메세지에 특별한 조건부 헤더를 추가함으로써 시작된다. 웹 서버는 조건이 참인 경우에만 객체를 반환한다.
HTTP는 캐시 재검사 시 가장 유용한 2가지 조건부 요청 헤더를 정의한다.
- If-Modified-Since
- If-None-Match
7. If-Modified-Since와 If-None-Match의 차이점에 대해 설명해주세요.
: If-Modified-Since(날짜 재검사)
줄여서 IMS 요청으로 불린다. 서버에게 리소스가 특정 날짜 이후로 변경된 경우에만 요청한 본문을 보내달라고 한다. 만약 문서가 주어진 날짜 이후에 변경되지 않았다면, 조건은(If-Modified-Since) 거짓이고 서버는 304 Not Modified 응답메세지를 클라에게 돌려준다. 효율을 위해 본문은 보내지 않는다. 응답 헤더들을 포함하지만, 원래 돌려줘야 할 것에서 갱신이 필요한 것만을 보내준다. (보통 새 만료 날짜만 보내준다.) If-Modified-Since 헤더는 Last-Modified 헤더와 함께 동작한다.
원서버는 제공하는 문서에 최근 변경 일시를 붙인다.- 마지막 배포 시간이 Last-Modified로 내려온다.
캐시가 캐시 된 문서를 재검사하려고 할때, 캐시 된 사본이 마지막으로 수정된 날짜가 담긴 If-Modified-Since헤더를 포함한다. 몇몇 웹서버는 If-Modified-Since를 실제 날짜 비교로 구현하지 않는다. 대신 IMS 날짜와 최근 변경일 간의 문자열 비교를 수행한다. 정확히 이 날짜에 마지막 변경이 일어난 것이 아니라면 이라는 의미로 동작한다. GET 또는 HEAD에서만 사용 가능하다.
일반적인 사용예) ETag가 없는 캐시 된 엔티티로 업데이트한다. If-None-Match와 함께 사용 시 무시된다.
If-None-Match(엔터티 태그 재검사)
서버는 무서에 대한 일련번호와 같이 동작하는 특별한 태그를 제공할 수 있다.(ETag) 캐시 된 태그가 서버에 있는 문서의 태그와 다를 때만 요청을 처리한다.
최근 변경일시 재검사가 행해지기 어려운 상황이 있다.
- 일정 시간 간격으로 다시 쓰여지지만, 같은 데이터를 포함한다. (내용변화가 없음)
- 어떤 문서들의 변경은 다시 읽어들이기엔 사소한 것 (철자나 주석)
- 어떤 서버들은 그들이 갖고 있는 페이지에 대한 최근 변경 일시를 정확하게 판별할 수 없다.
- 1초보다 작은 간격으로 갱신되는 문서를 제공하는 서버들에게는,
변경일에 대한 1초의 정밀도는 충분하지 않을 수 있다.
8. 브라우저 저장소에 대해서 설명해주세요. 레퍼런스
: 브라우저 저장소로 Cookie와 Web Storage가 있다. Cookie와 Web Storage 모두 해당 도메인과 관련된 데이터를 클라이언트 웹브라우저에 저장할 수 있도록 해준다. 둘 다 사이트의 도메인 단위로 접근이 제한된다. 예를 들면, A 도메인에서 저장한 데이터는 B 도메인에서 접근할 수 없는 것이다.
Cookie는 매번 서버로 전송되고, 문자열만 저장이 가능하며, 용량에 제한이 있고, 만료 일자가 존재한다. 이러한 부분들을 Web Storage를 사용함으로써 극복할 수 있다.
Web Storage는 데이터를 클라이언트에 저장만 할 뿐 서버로 전송되지는 않는다. 그리고 문자열 외에도 구조화된 객체를 저장할 수 있어 개발 편의성을 제공해주고, 하나의 사이트에서 저장할 수 있는 용량이 제한되어있지 않다. 또한, Web Storage에 한 번 저장한 데이터는 영구적으로 존재하게 된다.
WebStorage는 지속성에 따라 LocalStorage와 SessionStorage로 구분할 수 있다.
LocalStorage는 저장한 데이터를 명시적으로 지우지 않는한 영구적으로 보관이 가능하다. 도메인마다 별도로 LocalStorage가 생성되며, 도메인만 같다면 전역적으로 공유가 가능하다.
SessioniStorage는 데이터의 지속성과 액세스 범위에 특수한 제한이 존재한다. 도메인마다 별도로 생성되는 점은 LocalStorage와 같지만, 같은 사이트의 도메인이라도 브라우저가 다르면 서로 다른 영역이 된다. 이는 브라우저 컨텍스트가 다르기 때문이다.
이처럼 Web Storage는 영구저장소(LocalStorage)와 임시저장소(SessionStorage)가 구분되기 때문에, 데이터의 지속성에 따라 선택이 가능하다.
