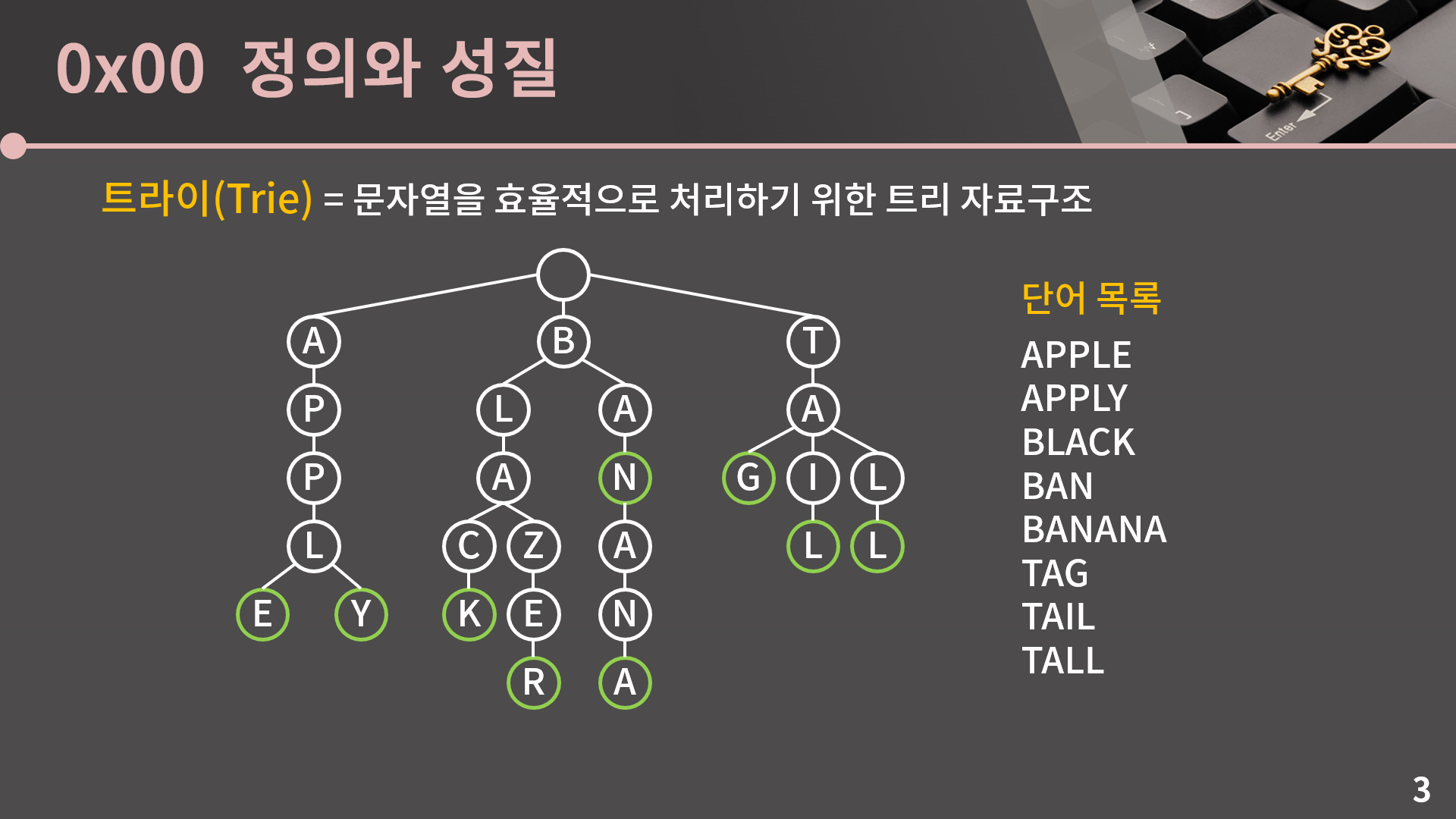
Trie란?
출처 바킹독 유튜브
트라이는 컴색 트리의 일종으로 일반적으로 키가 문자열인, 동적 배열 또는 연관 배열을 저장하는 데 사용되는 정렬된 트리(search tree) 자료구조의 일종이다.
search tree는 집합 내의 특정 키를 찾는데 사용되는 tree를 이야기한다.
실무에서 상당히 유용히 사용되는 자료구조이며, 자연어 처리(NLP) 분야에서 문자열 탐색을 위한 자료구조로 널리 쓰인다. HashSet과 비교되는 점은 접두사나 접미사와 관련된 탐색을 지원하는 활용성이나, 실질적인 연산 속도에서 우수하다.
주요 특징
- binary tree가 아닌 m-ary tree(다진 트리)의 형태를 띈다.
- 패턴 매칭: 원하는 접두사의 문자열 집합 조회가능
- dfs탐색 = 사전순 정렬이다.
- 압축: 공통 접두사 공유를 통한 공간 절약
연산
- void insert(s) : 트라이가 해당 문자열을 추가한다.
- boolean search(s) : 트라이가 해당 문자열을 포함하고 있는지 판단한다.
- delete(s) : 해당 문자열을 트라이에서 제외한다.
모든 연산은 O(m)이다. (m:문자열의 길이) 물론 자식노드의 개수만큼 엄밀하게는 탐색 시간이 길어질 수 있다.
Hash Table을 통해 구현된 Hash Map이나 Hash Set은 최적의 경우 O(1)이지만 해시충돌 가능성이 있다. 이 경우 O(N)까지 늘어날 수 있다.(N: 삽입될 문자열의 개수)
insert(s)
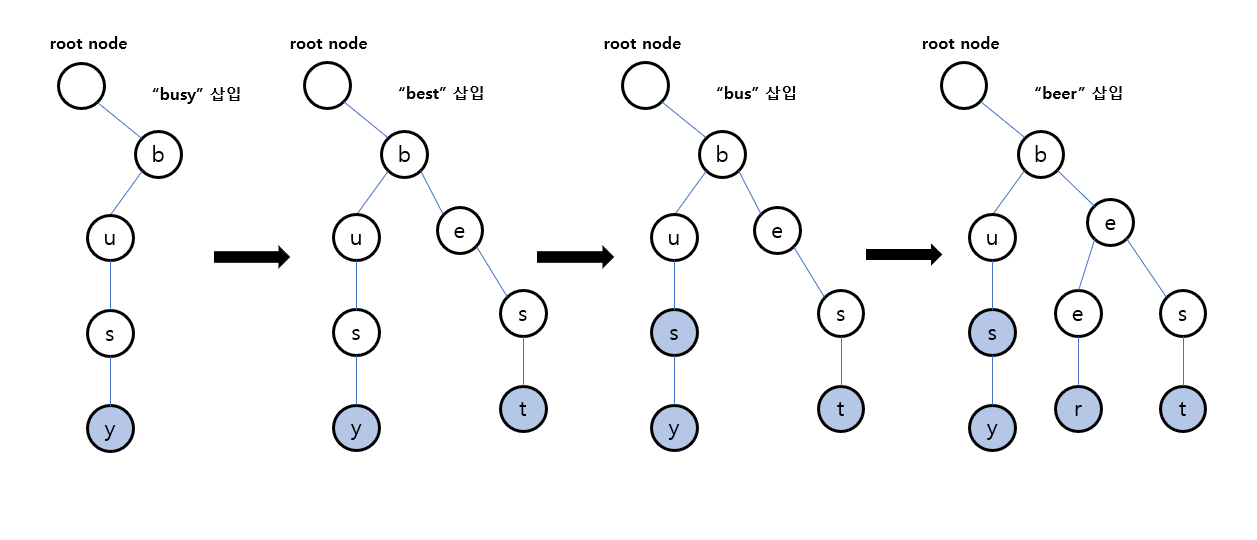
루트(빈문자열)부터 s를 구성하는 문자를 하나씩 탐색하며 트리를 탐색한다. 자식 노드 목록에 다음 문자가 없다면 추가하는 방법으로 문자열을 추가한다.
단. 문자가 끝나면 문자열이 끝나는 지점이라는 표시가 필요하다. 이걸 무시하면 search(s)가 s를 부분문자열로 시작하는 문자열에 대해서도 true를 반환한다. (즉 역으로 접두사 검사로도 쓸 수 있다.)
위 그림에서 문자열은 bus와 busy 두개를 모두 포함하는 경우다. 끝나는 지점이 2개인걸 확인할 수 있다.
search(s)
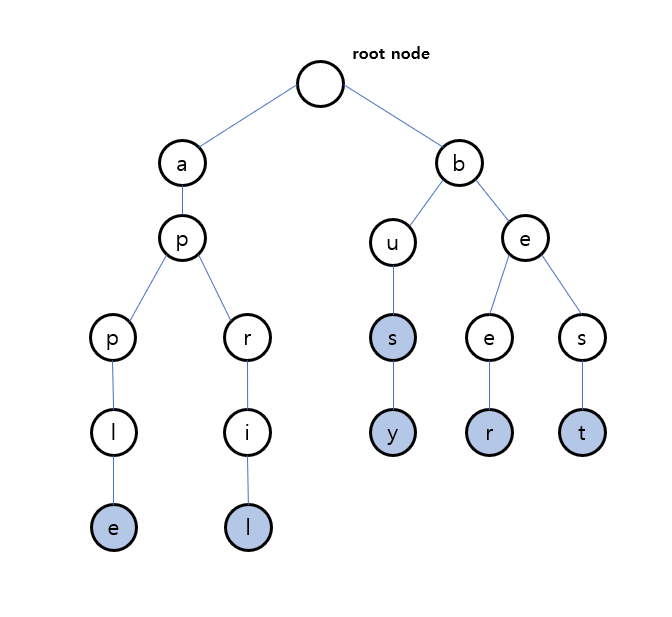
루트로부터 s를 구성하는 문자를 하나씩 탐색하며 트리를 탐색한다. 문장의 마지막 문자와 일치할때 문장이 끝나는 지점(insert할때 표시했던)이라면 true를 반환하며 나머지는 false를 반환한다.
delete(s)
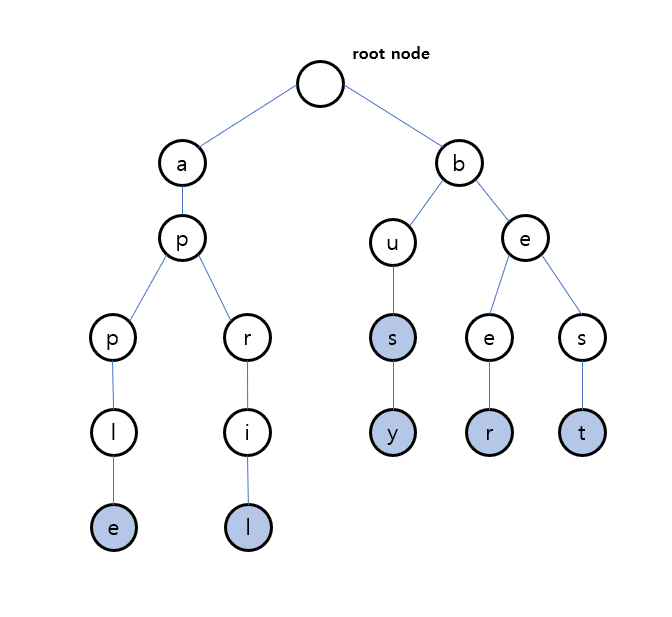
만약 apple을 삭제하고 싶다면 다른 단어로 이어지는 마지막 분기를 제외하고 나머지 노드를 트리에서 제거한다. 즉 두 번째 p부터 노드를 삭제해주면 된다.
자바 전체 구현
Array 활용
import java.util.*;
class Trie {
private Node root;
{
root = new Node();
}
private static class Node {
public boolean word;
public Node[] children; // 해당 자료구조를 HashMap으로 바꾸는 것도 가능
private Node() {
children = new Node[26];
word = false;
}
}
public void insert(String word) {
Node cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null) {
cur.children[c - 'a'] = new Node();
}
cur = cur.children[c - 'a'];
}
cur.word = true;
}
public boolean search(String word) {
Node cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null) return false;
cur = cur.children[c - 'a'];
}
if (!cur.word) return false;
return true;
}
public boolean startsWith(String prefix) {
Node cur = root;
for (char c : prefix.toCharArray()) {
if (cur.children[c - 'a'] == null) return false;
cur = cur.children[c - 'a'];
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/HashMap 활용
class Trie {
private static class Node {
boolean isEnd = false;
Map<Character, Node> children = new HashMap<>();
}
Node root;
public Trie() {
root = new Node();
}
public void insert(String word) {
Node cur = root;
for (char c : word.toCharArray()) {
Node child = cur.children.getOrDefault(c, new Node());
cur.children.put(c, child);
cur = child;
}
cur.isEnd = true;
}
public boolean search(String word) {
Node cur = root;
for (char c : word.toCharArray()) {
if (!cur.children.containsKey(c))
return false;
cur = cur.children.get(c);
}
return cur.isEnd;
}
public boolean startsWith(String prefix) {
Node cur = root;
for (char c : prefix.toCharArray()) {
if (!cur.children.containsKey(c))
return false;
cur = cur.children.get(c);
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/Trie vs HashMap 비교
https://school.programmers.co.kr/learn/courses/30/lessons/60060
해당 문제를 해쉬 테이블과 Trie로 풀어보았다.
둘 다 HashMap을 사용했기에 문제 특성상 시간복잡도와 공간복잡도 자체는 동일했지만, Trie만 제대로 문제가 풀렸다.
원인 분석
1. 해쉬 충돌로 인한 체이닝 : 시간이 상대적으로 살짝 더 걸릴 수 있다. 실제로 큰 의미는 아니지만 30% 정도 Trie가 빨랐다.
2. 해쉬 테이블 더블링 : Trie의 경우 해시테이블이 훨씬 작은 테이블로 분산된다. 반면 HashMap 풀이는 모든 경우의 수를 하나의 테이블에 저장한다. 이는 동적으로 버킷 사이즈를 더블링할때 훨씬 낭비되는 빈 공간이 커질 수 있음을 의미한다.
첫 번째 코드는 사실 메모리 부족으로 몇가지 테스트케이스를 통과하지 못했다. 이는 2번 요인으로 인한 것으로 보인다.
그 외에 접두사와 관련된 응용면에서 Trie를 선택할 수 밖에 없는 경우도 있다.
참고
https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%9D%BC%EC%9D%B4_(%EC%BB%B4%ED%93%A8%ED%8C%85)
https://innovation123.tistory.com/116
https://the-dev.tistory.com/2
