운영체제는 하드디스크 같은 저장장치에 파일을 저장하기 위해 파일 시스템을 운영한다.
개념
운영체제에서 저장장치에서는 파일 관리자가 파일 테이블을 이용하여 파일의 CRUD등을 수행한다.
사용자가 특정파일에 접근하기 위해서는 파일 관리자로부터 권한(키)를 획득해야 하는데, 이를 파일 디스크립터(file descriptor)이라고 한다.
파일 시스템은 윈도우의 경우 NTFS(New Technology File System) 유닉의 경우 아이노드(I ndex node) 파일시스템을 활용한다.
기능
- 파일 및 디렉터리 구성 : 사용자 요구에 따른 파일과 디렉토리 생성
- 파일 및 디렉터리 관리 : 파일 및 디렉토리의 CRUD등을 관리한다.
- 접근 방법 제공 : 파읽과 디렉터리에서 읽고 쓰고 실행할 수 있도록 사용자에게 접근 방법을 제공
- 접근 권한 관리 : 다른 사용자에게서 파일 및 디렉터리를 보호하기 위해 접근 권한을 제한한다.
- 무결성 보장 : 파일 내용이 손상되지 않도록 무결성을 보장한다.
- 백업과 복구 : 파일을 보호하기 위해 백업과 복구작업을 한다.
- 암호화 : 파일을 암호화하여 악의적인 접근으로부터 파일을 보호한다.
블록과 파일 테이블
저장장치에서는 파일을 일정한 크기로 묶어서 관리하는데 이를 블록이라고 한다.
메모리의 단위는 바이트이지만 저장장치의 단위는 블록이다.
파일 테이블엔 파일명과 저장된 블록 번호가 담기게 된다.
파일 작업
프로세서 입장에서 내용을 변경하므로 주로 함수의 형태로 이루어짐
open(): 파일을 연다
write(): 파일에 새로운 내용을 쓴다
create(): 새로운 파일을 생성한다
close(): 파일을 닫는다
read(): 파일 내용을 읽는다
update(): 파일 내용 중 일부를 변경한다
insert(): 파일에 새로운 내용을 추가한다.
delete(): 파일 내용중 일부를 지운다.
파일헤더
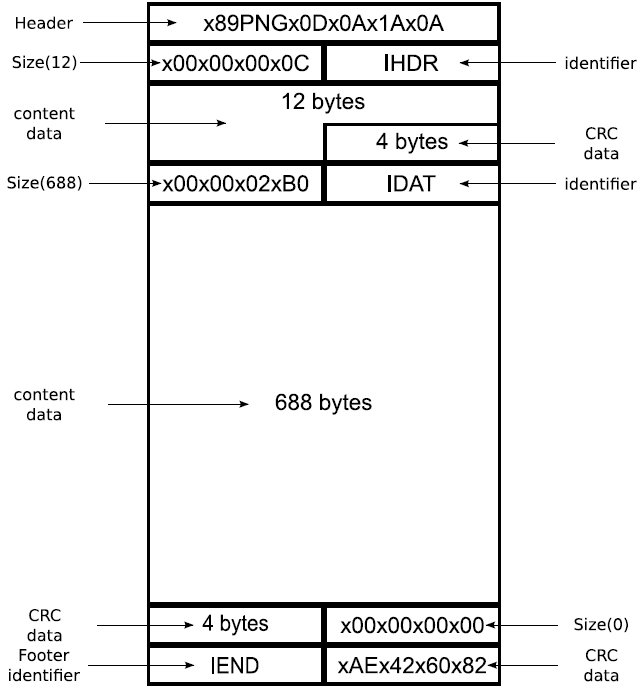
파일크기, 만든 날짜, 접근 권한과 같은 파일 속성은 모든 파일에 공통적으로 적용된다. 파일 속성과 달리 파일마다 자신에게 필요한 정보를 따로 정의하여 사용할 수 있는데, 이는 파일 헤더에 기록된다.
저장장치관리 기법
파티션

파티션: 디스크를 논리적으로 분할하는 작업
유닉스의 경우 여러개의 파티션을 통합하는 기능이 있다. 저장장치가 100개더라도 파일시스템이 하나라 1개의 저장장치처럼 보인다. 이를 마운트라고 한다.
포맷
포맷: 저장장치의 파일 시스템을 초기화하는 작업
빠른 포맷: 데이터는 그대로 둔채 파일 테이블만 초기화하는 방식
느린 포맷: 파일 테이블을 초기화 할 뿐 아니라 블록의 모든 데이터를 0으로 만든다. 즉 불량 섹터를 찾는 것도 가능하다.
조각모음
단편화난 공간을 모아서 넓직한 여유공간을 만드는 것
파일구조
파일은 하나의 데이터 덩어리이다 이 덩어리를 어떻게 구성하냐에 따라 아래와 같이 나뉜다.
순차 파일 구조
파일 내용이 하나의 긴 줄로 늘어선 형태
ex 카세트테이프에 저장하는 데이터
장점
- 낭비되는 부분이 없음
- 구조가 단순하다
- 순서대로 데이터를 읽거나 저장하면 매우 빠름
단점
- 파일에 새로운 데이터를 삽입하거나 삭제할때 시간이 오래걸림
- 특정 데이터로 이동할때 탐색시간 김
인데스 파일 구조
인텍스 테이블을 추가해 순차 접근과 직접 접근이 모두 가능하게 만든 것.
직접 파일 구조
저장하려는 데이터의 특정 값에 어떤 관계를 정의하여 물리적인 주소로 바로 변환하는 파일 구조.
해시 함수를 이용하여 주소를 변환하는데 해시 함수에 따라 효율성이 매우 갈린다.
디렉터리
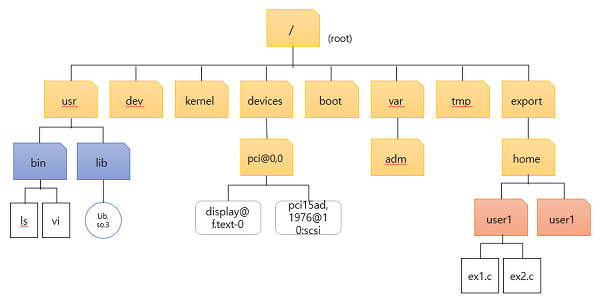
개념
파일을 모아서 관리는 방법이다.
최상위에 있는 디렉터리를 루트 디렉터리로서 여러 층으로 구성된 트리형태이다.
바로가기 링크를 포함하여 도식화하면 순환이 생긴다.
디렉터리를 이동할때 cd(change directory) 명령어를 사용한다.
마운트의 경우 디렉터리의 관점에서 보면 다른 파티션의 디렉터리를 하나의 디렉터리에 하위로 넣는 기능이다.
디스크 파일 할당
디스크상에 파일 시스템이 어떻게 구성되는지 알아보자.
할당방식
연속할당: 파일을 구성하는 데이터를 디스크상에 연속적으로 배열하는 간단한 방식 실제로 사용되지는 않는다.
불연속 할당: 비어있는 블록에 데이터를 분산하여 저장하고 이에 관한 정보를 파일 시스템이 관리하는 방식
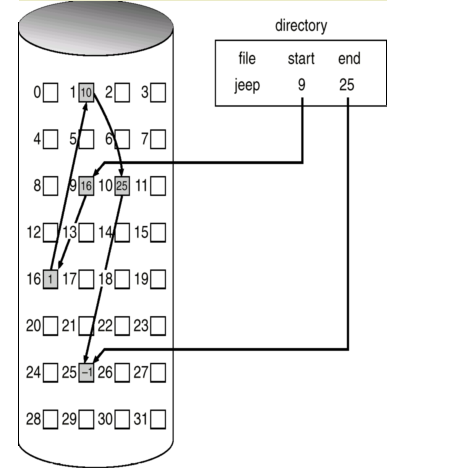
연결 할당: 연결리스트 구조로서 블록마다 다음 블록 링크를 담아 연결한다.
비어있는 여유블록 또한 연결리스트로 연결해 필요할때 떼어 사용하고 남을때 붙이며 관리한다.
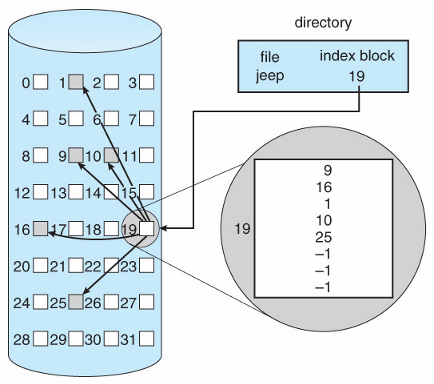
인덱스 할당: 연결리스트로 줄줄히 연결하는데에는 크기가 제한이 있기에 인덱스 블록을 정의해 확장한다. 인덱스 블록은 위 이미지에 19번 블록으로 여러 데이터의 인덱스를 담고 있다.

아이노드의 경우 인덱스 블록을 다중으로 확장해 사실상 무한히 확장 가능하다. 위에 포인터들이 인덱스 블록이다.
