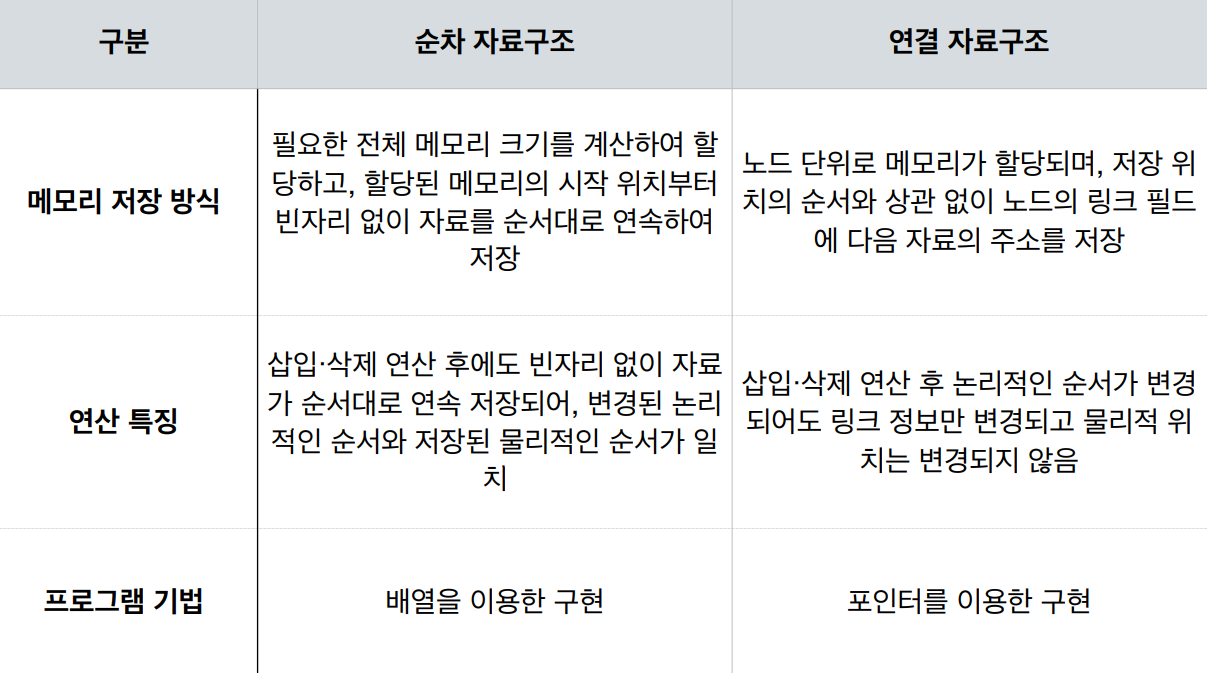
💻순차 자료구조와 연결 자료구조의 차이
순차 자료구조-배열 이용
연결 자료구조 -포인터 이용
노드 단위
링크 필드
개념적인거랑 구현하는 건 좀 다르다.
리스트는 중간에 비면 안된다.
논리적,물리적이 다르기 때문에 맞춰줘야한다.
늘 일치하도록.
연결자료구조는 메모리상의 위치는 다르나 이를 링크를 이용해서 노드를 연결해 배열처럼 사용할 수 있게 해주는데에서 시작했다.
🔽순차 자료구조
문제점
삽입연산, 삭제연산 후에 연속적인 물리 주소를 유지하기 위해 원소들을 이동시키는 추가적 작업,시간이 소요된다.
- 원소들의 이동작업으로 ->오버헤드 발생.
오버헤드는 원소의 개수가 많고 삽입, 삭제 연산이 많이 발생하는 경우에 성능상의 문제 발생.
배열을 이용하기 때문에 배열이 갖고 있는 메모리 사용의 비효율성 문제를 그대로 가짐
- 배열의 크기 > 데이터 수 : 메모리 공간의 낭비
- 배열의 크기 < 데이터 수 : 추가 데이터 저장 X
--> 동적 배열로 할당이 가능하다 이 또한 메모리가 낭비 된다.
SO, 순차 자료구조에서의 연산 시간에 대한 문제와 저장 공간에 대한 문제를 개선한 자료 표현 방법 필요
선형 리스트
🔽연결 자료구조
자료의 논리적인 순서와 물리적인 순서가 일치하지 않는 자료구조
- 각 원소애 저장 되어 있는 다음 원소의 주소에 의해 순서 연결
- 물리적인 순서를 맞추기 위한 오버헤드가 발생 X
- 여러 개의 작은 공간 연결로 하나의 전체 자료구조를 표현
- 크기 변겨이 유연하고 더 효율적으로 메모리 사용
+)자료가 들어올 때 생성하고 나갈 때 빼주면 되니까 메모리를 더 효율적으로 사용 가능.
연결 리스트
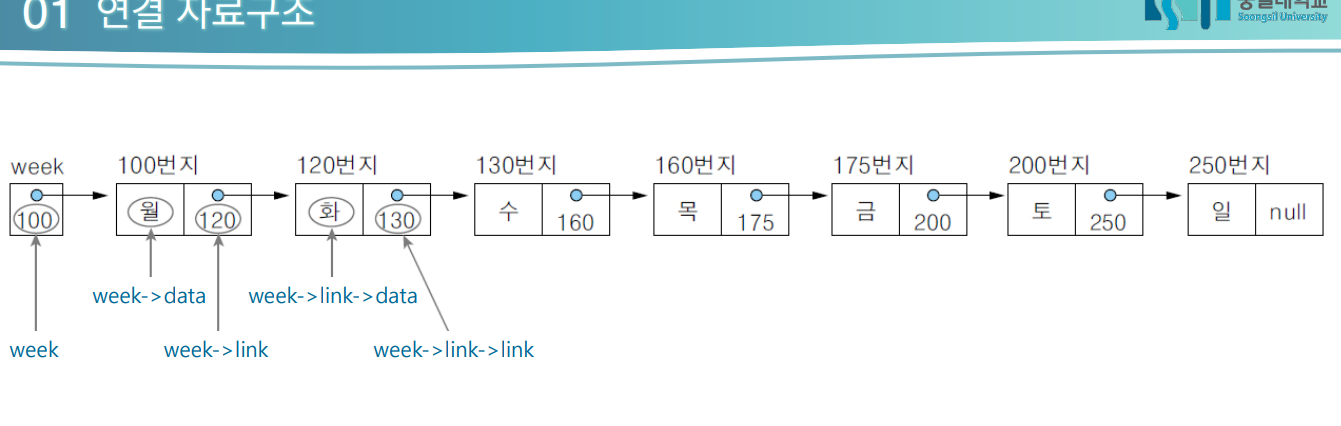
리스트를 연결 자료구조로 표현한 구조
-네모 전체가 노드
-Link는 포인터

TIP -포인터는 화살표로 쓰는거 습관들자! '->' 이거 사용해보자.



💻선형 리스트와 연결 리스트의 비교
연결리스트 .물리주소가 떨어져있더라도 논리구조는 링크로 연결되어있다.
연결 리스트의 노드
7이가지고 있던걸 8로 연결한다 (9를 끊어내고)
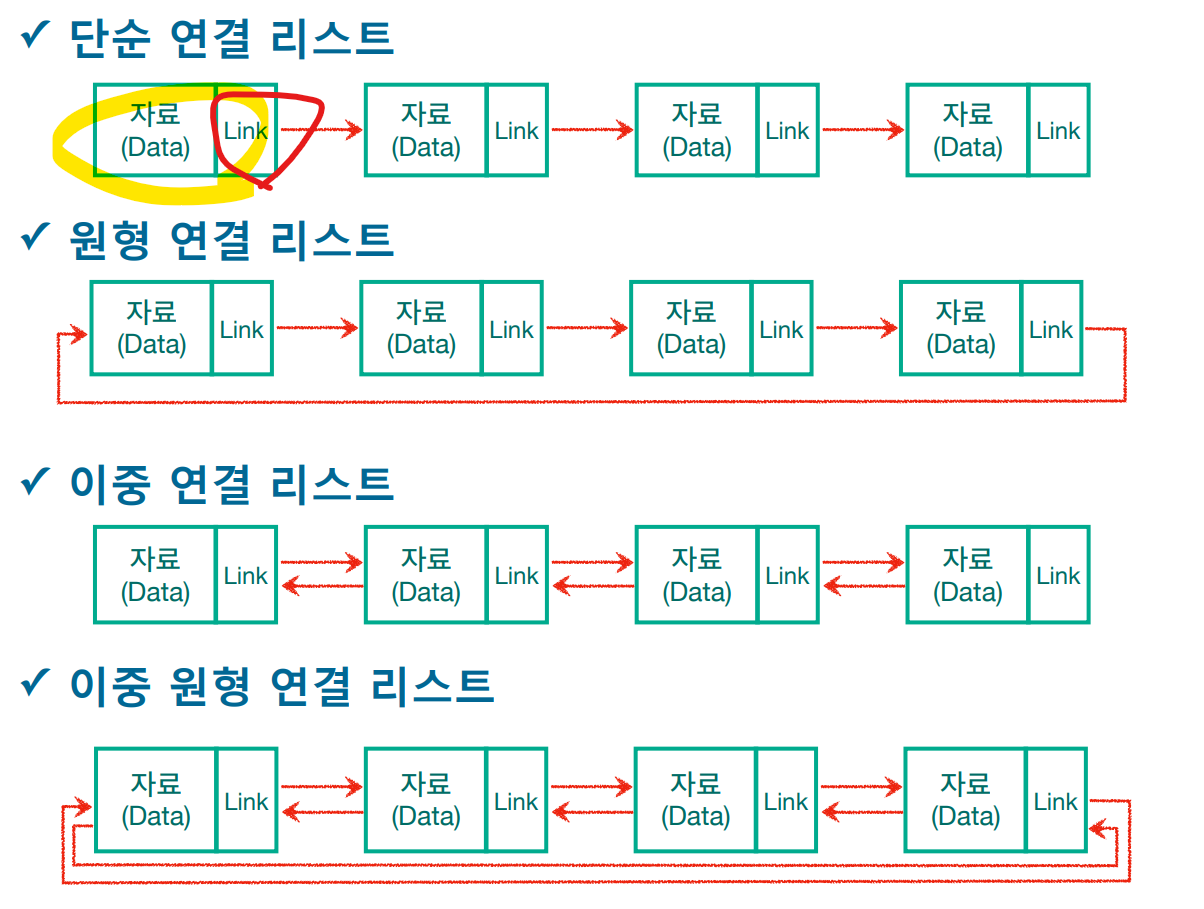
단순 연결 리스트
- 마지막 값이 NULL
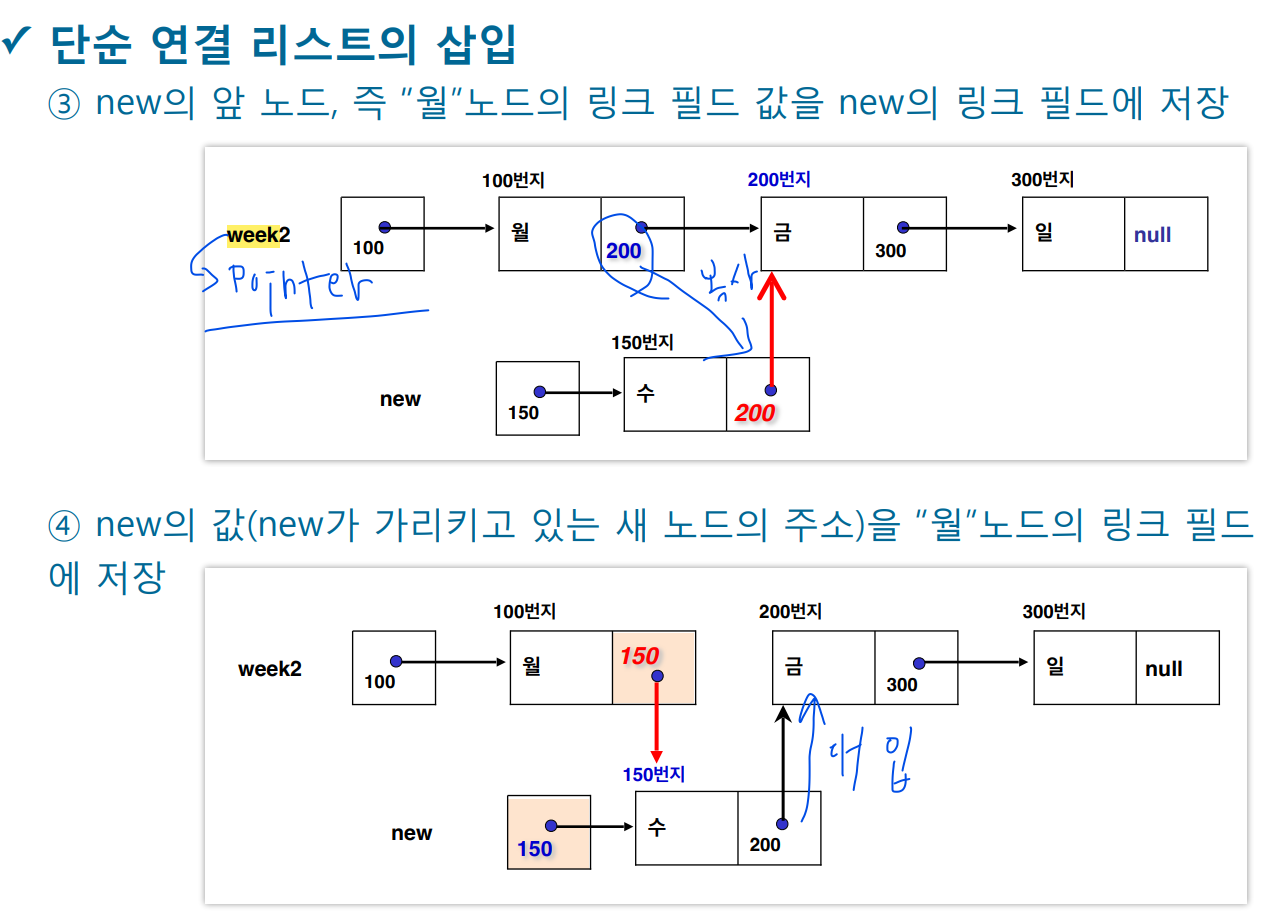
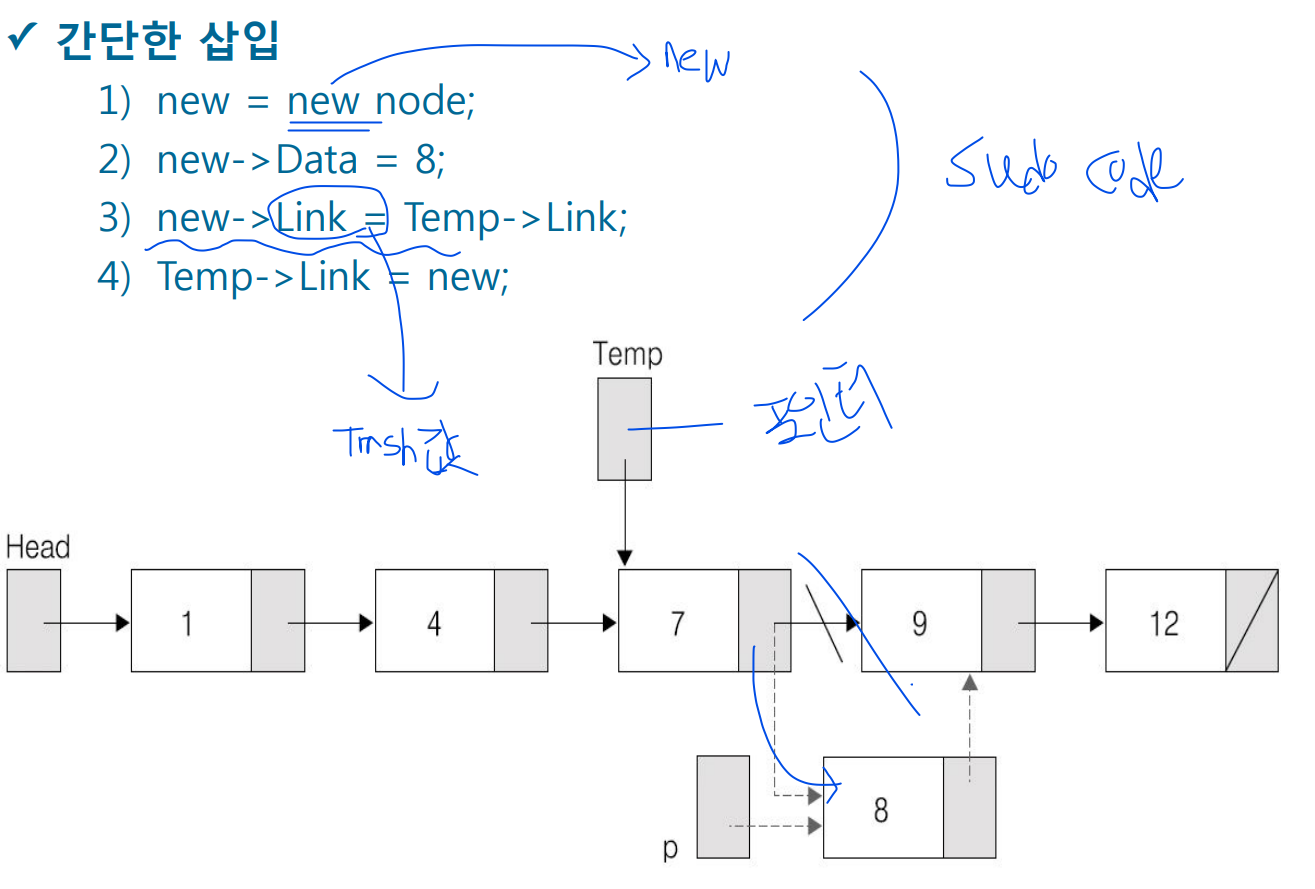
-new라고 하는건 노드의 포인터 주소
-초기화는 선언할 때 하고 대입은 그 이후로 하는게 대입이다.
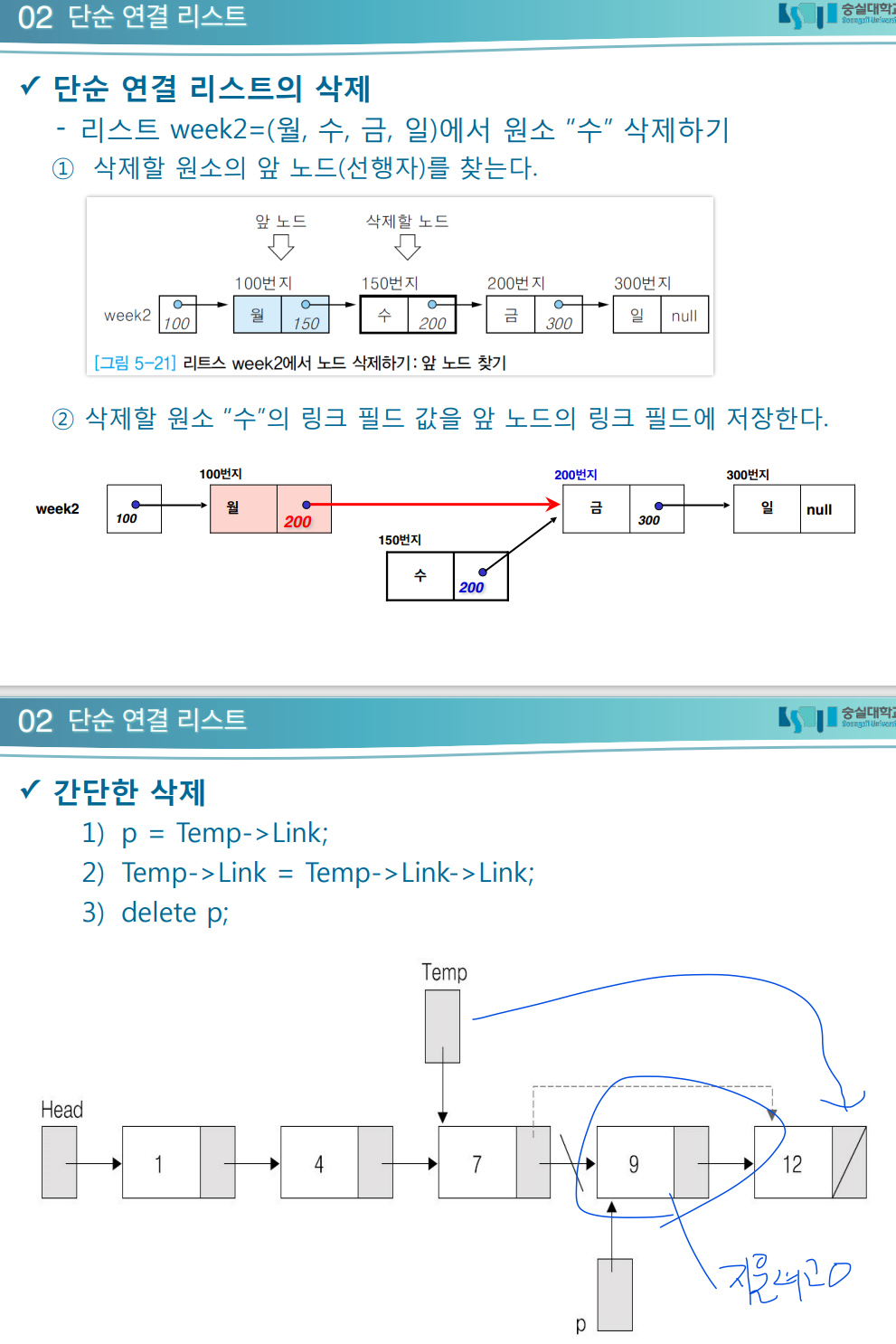
단순 연결 리스트의 삭제
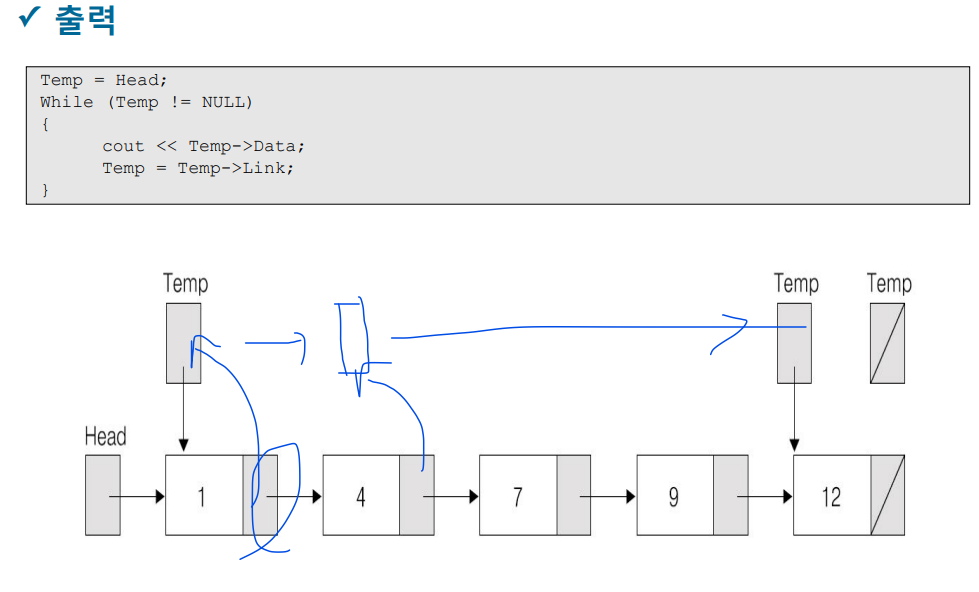
-NULL까지 도는 것
-TEMP 계속 이동 ~
-for문도 가능한데 따로 저장해야해서 복잡해짐(?)
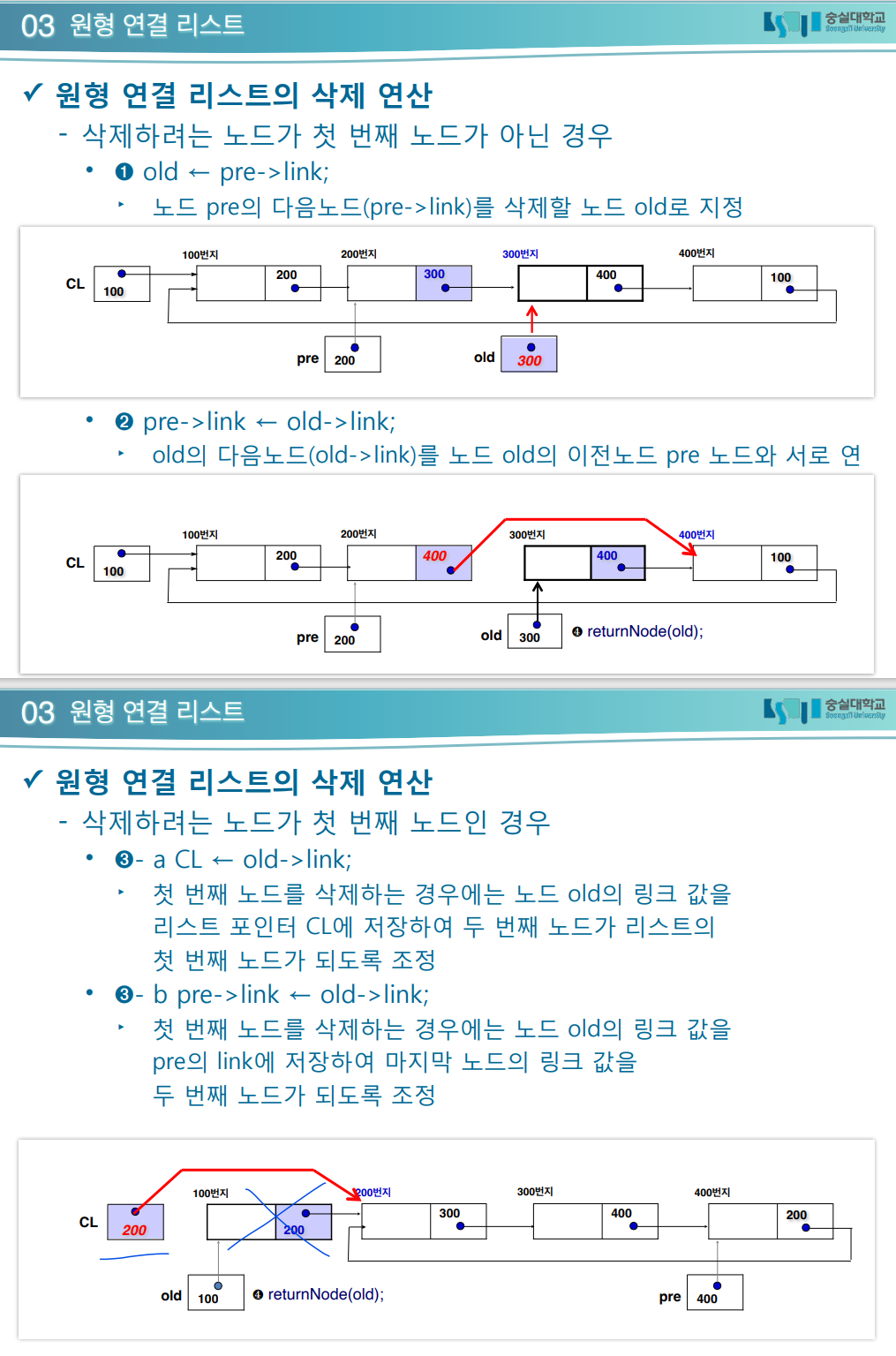
원형 연결 리스트
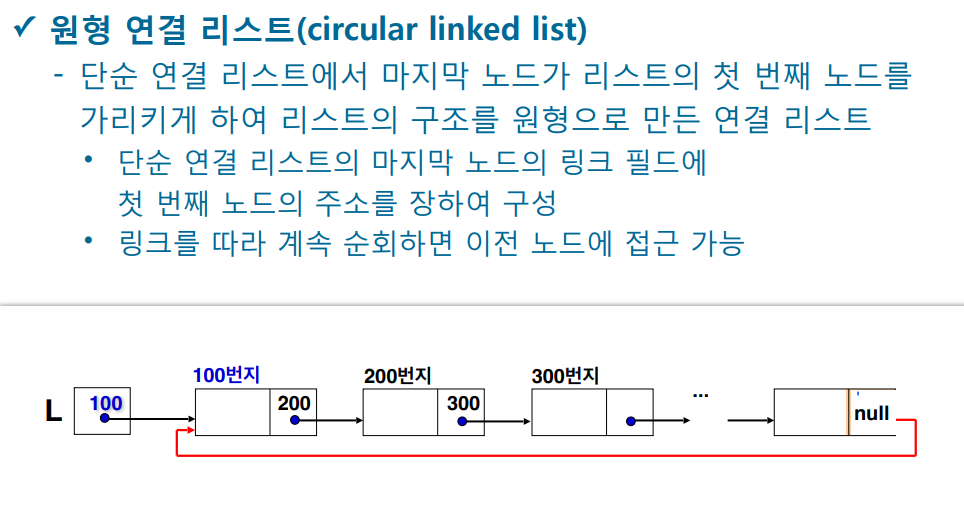
- 마지막 값은 맨 첫번 째 노드 가르킨다.
- while구문으로 탐색하기 힘들다. -왜? 널 값이 없기에 무한루프를 돈다.
삽입 연산
- 마지막 노드의 링크를 첫 번째 노드로 연결하는 부분만 제외하고
는 단순 연결 리스트에서의 삽입 연산과 같은 연산
삭제 연산
이중 연결 리스트
(삽입 및 삭제 과정 다시보기)

- 이전의 자료까지 포인팅을 한다. 그래서 링크를 표현하는 자료가 2개가 된다.
- 백워드 가능 즉 , 후방향 ,전방향 다 가능하다.
TIP - 변수명 설정할 때 잘하기.
현업에서는 보통 struct라고 안 사용 -typedef사용함.보통.
이중 원형 연결 리스트
- 다음 값이 NULL인데 단일 연결 리스트와 비슷하지만, 포인터 공간이 두 개가 있고 각각의 포인터는 앞과 뒤의 노드를 가리킨다.

상상을 현실로





