- Relational Model Concepts
- 관계(Relation)는 집합의 개념에 기반한 수학적 개념
- 이 모델은 IBM 연구소의 Dr. E.F. Codd에 의해 처음 제안되었으며, 다음 논문에서 소개됨
"A Relational Model for Large Shared Data Banks," Communications of the ACM, 1970년 6월. - 이 논문은 데이터베이스 관리 분야에서 혁신적인 변화를 불러일으켰으며, Dr. Codd는 이러한 공로로 ACM 튜링상을 수상
- Informal Definitions
-
각 행(row)의 데이터 요소들은 현실 세계의 개체(entity)나 관계(relationship)에 해당하는 특정 사실들을 나타냄
-> 형식적 모델에서는 행(row) = 튜플(tuple) -
각 열(column)에는 열 제목(column header)이 있어 해당 열의 데이터 항목들이 무엇을 의미하는지 나타냄
-> 형식적 모델에서는 열 제목 = 속성 이름(attribute name) 또는 간단히 속성(attribute)
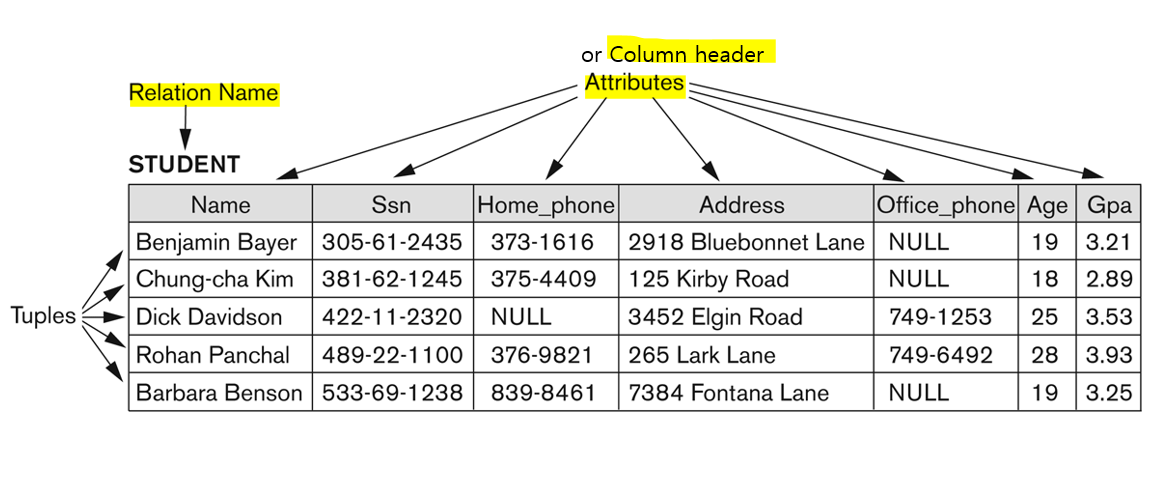
* Key
: 해당 테이블 내에서 해당 행을 고유하게 식별할 수 있는 데이터 항목 값
<형식적 정의>
- 스키마(or description)의 형식적 정의
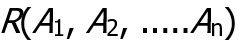
- R은 관계의 이름
- A₁, A₂, ..., Aₙ은 관계의 속성들(attributes)을 의미
ex) CUSTOMER(Cust-id, Cust-name, Address, Phone#)
- Tuple의 형식적 정의
- 값들이 순서대로 나열된 집합(ordered set)

-> 4-tuple
- 관계의 차수(Degree) or Arity는 관계 스키마에 포함된 속성의 개수(n)을 의미
-> n-tuple로 표현
-> 관계는 튜플들의 집합으로 구성됨(튜플 간에는 순서 X)
- Domain의 형식적 정의
- Logical 정의를 가짐
ex) “USA_phone_numbers”는 미국에서 유효한 10자리 전화번호들의 집합 - 데이터 타입 or format이 정의됨
ex) USA_phone_numbers는 (ddd)ddd-dddd 형식을 가질 수 있으며, 여기서 각 d는 십진 숫자(0~9)
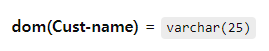
-> varchar(25) = 최대 길이 25의 문자 문자열(character string)
- State의 형식적 정의
-
state(상태)란, 특정 순간에 데이터가 어떻게 저장되어 있는지를 의미(데이터베이스의 현재 값이나 내용을 나타냄)
-
관계 상태(Relation State) 또는 관계 인스턴스(Relation Instance)는 각 속성의 도메인들의 데카르트 곱(Cartesian product)의 부분 집합
-> 각 도메인(domain)은 해당 속성이 가질 수 있는 모든 가능한 값들의 집합을 포함

-> r(R) : 관계 R의 특정 state(or "value" or "population")를 의미, 튜플의 집합
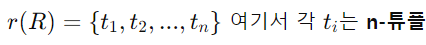

Example)
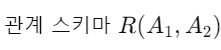
가 있다고 가정
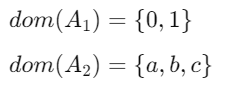
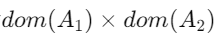
는 가능한 모든 조합의 집합
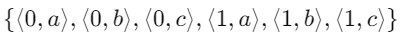
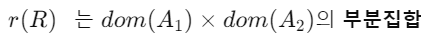
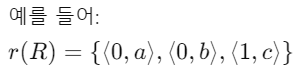
-> 관계 R의 하나의 가능한 상태(or population(인구)* or extension(확장))
-> 이 state에서는 2-tuple 3개가 포함됨
*Population (인구)
: 데이터베이스에서 "인구"라는 표현은 테이블(관계)에 저장된 실제 데이터의 집합을 의미
: 마치 특정 지역의 인구 수가 변할 수 있는 것처럼, 관계의 인스턴스(상태)도 데이터가 추가되거나 삭제됨에 따라 변함
*Extension (확장)
: "확장(extension)"은 테이블의 현재 데이터 집합이 구조(스키마)를 확장하는 것을 의미
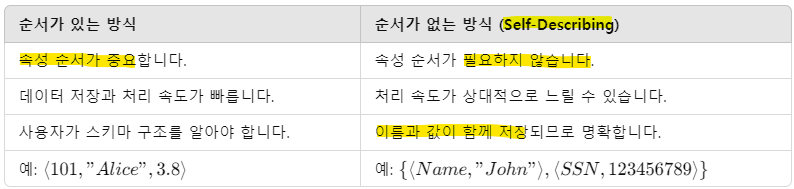
- Relation의 특징
- 관계 스키마 R(A1, A2, A3...)의 속성들과 튜플 ti = <v1, v2, ...>의 값들은 순서가 있는 것으로 간주됨
-> 속성 A1에 대한 값은 v1 으로 순서가 중요
* Self-Describing 방식
- 하지만! 관계에 대한 더 일반적인 정의에서는 순서 X -> 각 속성의 name과 value가 함께 포함되는 구조를 사용
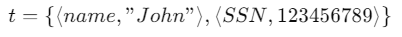
- Tuple의 값
-
모든 값은 원자적(atomic)으로 간주됨(더 이상 나눌 수 없는 단일 값) , 1NF(1st Normal Form)
-
NULL값
: 특수한 NULL 값은 알 수 없거나, 사용할 수 없거나, 또는 적용할 수 없는(정의되지 않은) 값을 나타내기 위해 사용 -
표기법

- 여러 속성들의 값으로 구성된 부분 튜플(subtuple) 표현법
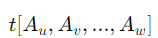
-> 튜플 t에서 속성 Au, Av, ...., Aw 에 해당하는 값을 포함하는 부분 튜플
- Constraints, 제약 조건
- 데이터베이스에서 허용되는 값과 허용되지 않는 값을 결정
1) Inherent or Implicit Constraints, 내재적 or 암묵적 제약
- 데이터 모델 자체의 특성에 의해 자동으로 부과되는 제약 조건
- 데이터베이스 사용자가 명시적으로 정의하지 않아도 자동으로 적용
ex) 관계형 모델은 속성에 리스트 형태의 값을 허용하지 않음
2) Schema-based or Explicit Constraints, 스키마 기반 or 명시적 제약
- 모델이 제공하는 기능을 사용하여 스키마에서 명시적으로 표현되는 제약
- 사용자가 데이터 모델의 기능을 사용해 제약 조건을 표현하며, 관계형 데이터베이스에서는 기본 키, 외래 키, 도메인 제약 등으로 구현
ex) ER 모델에서 최대 카디널리티 비율 제약(max. cardinality ratio constraint)
3) Application based or Semantic Constraints, 애플리케이션 기반 or 의미적 제약
- 모델의 표현력을 초과하는 제약(데이터베이스 모델의 표현력으로는 표현할 수 없는 제약 조건)로, 애플리케이션 프로그램에서 지정하고 강제해야 함
- 경우에 따라, 이러한 제약은 SQL에서 어서션(assertions)으로 지정할 수 있음
ex) 학생의 나이는 반드시 18세 이상이어야 한다는 제약
- Relational Integrity Constraints
- 제약 조건은 모든 유효한 관계 상태에서 반드시 만족되어야 하는 조건
<관계형 모델에서 표현할 수 있는 명시적 스키마 기반 제약(explicit schema-based constraints) ****
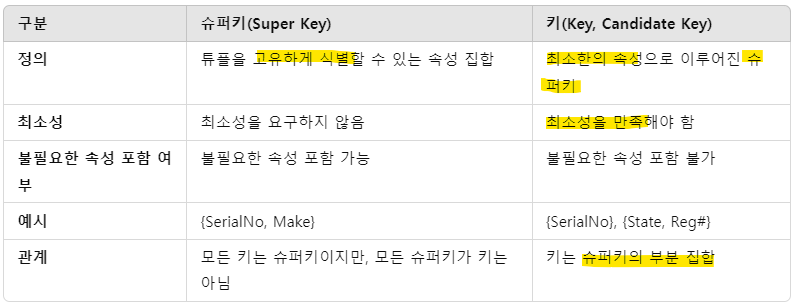
1) 키 제약(Key Constraints)
- Superkey
: 슈퍼키(Superkey)는 관계 R의 속성 집합 SK
-> 어떤 유효한 관계 상태 r(R)에서도 두 개의 서로 다른 튜플이 동일한 SK값을 가질 수 X (Unique!)
- Key
: Key는 최소한의 슈퍼키를 의미
-> Key는 슈퍼키이지만, 슈퍼키는 항상 Key는 아님 (더 이상 속성을 제거하면 uniqueness를 잃게 되는 슈퍼키가 Key임)
ex) Key1 = {State, Reg#}
- Primary Key
: 관계에 여러 후보 키(candidate keys)가 있는 경우, 임의로 하나를 선택하여 기본 키(primary key)로 지정
-> 기본 키 속성은 밑줄로 표시2) 엔터티 무결성 제약(Entity Integrity Constraints)
- 데이터베이스 스키마 S 내의 각 관계 스키마 R의 PK는 해당 관계 r(R)의 어떤 튜플에서도 NULL값을 가질 수 X
3) 참조 무결성 제약(Referential Integrity Constraints)
- 참조 관계 R1에 있는 튜플들은 FK(외래 키 속성)을 가지며, 이는 참조되는 관계 R2의 PK(기본 키 속성)을 참조함
FK -> PK로 화살표 표시
4) 도메인 제약(Domain Constraints)
- 튜플의 모든 값은 해당 속성의 도메인에 속해야 함 (다만, 해당 속성에서 NULL 값이 허용된다면 NULL도 가능)
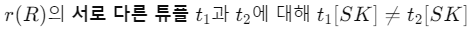
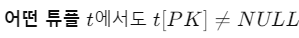
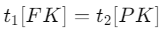
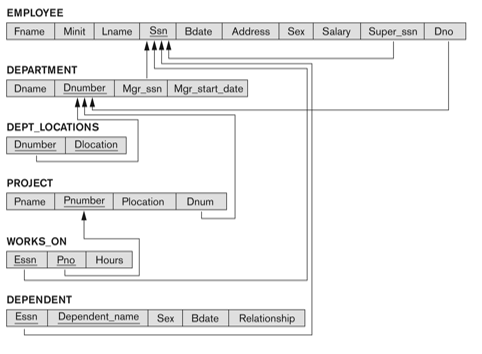
* Relational Database Schema, 관계형 데이터베이스 스키마
-
S: 전체 데이터베이스 스키마의 이름
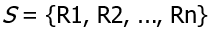
-
S = {R1, R2, ..., Rn}과 무결성 제약 집합 IC로 구성됨
-> R1, R2, ..., Rn은 데이터베이스 S 내의 개별 관계 스키마들의 이름
* Relational Database State, 관계형 데이터베이스 상태 (= Snapshot, = Instance)
- S의 관계형 데이터베이스 상태 DB는 관계 상태들의 집합으로 정의됨
-> 각 ri는 Ri의 상태
-> 이 ri 관계 상태들은 IC에 지정된 무결성 제약을 만족해야함
- 인스턴스(instance)라는 용어는 단일 튜플에도 적용될 수 있으므로, 여기서는 이 용어를 사용하지 않음
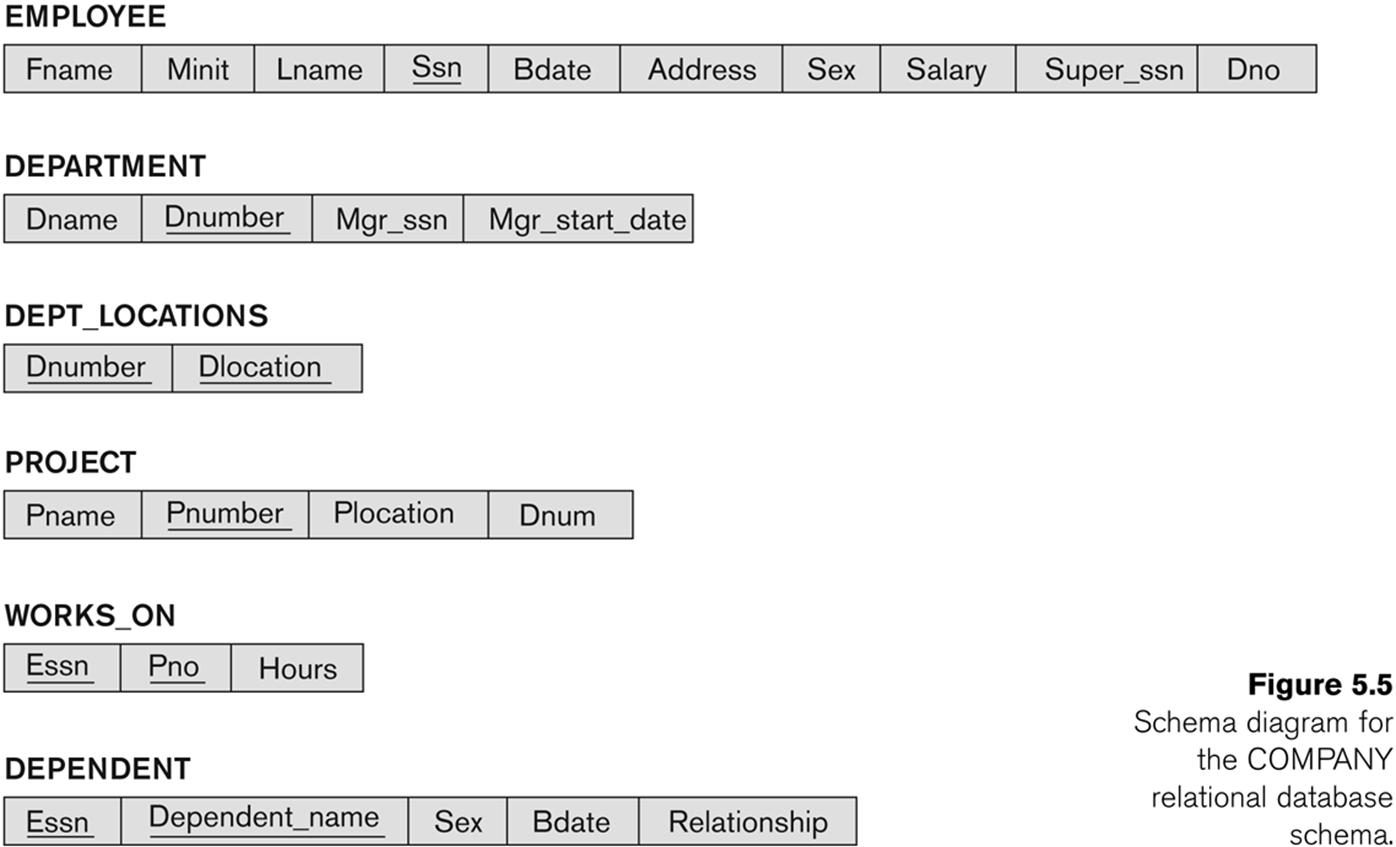
-> COMPANY Database Schema
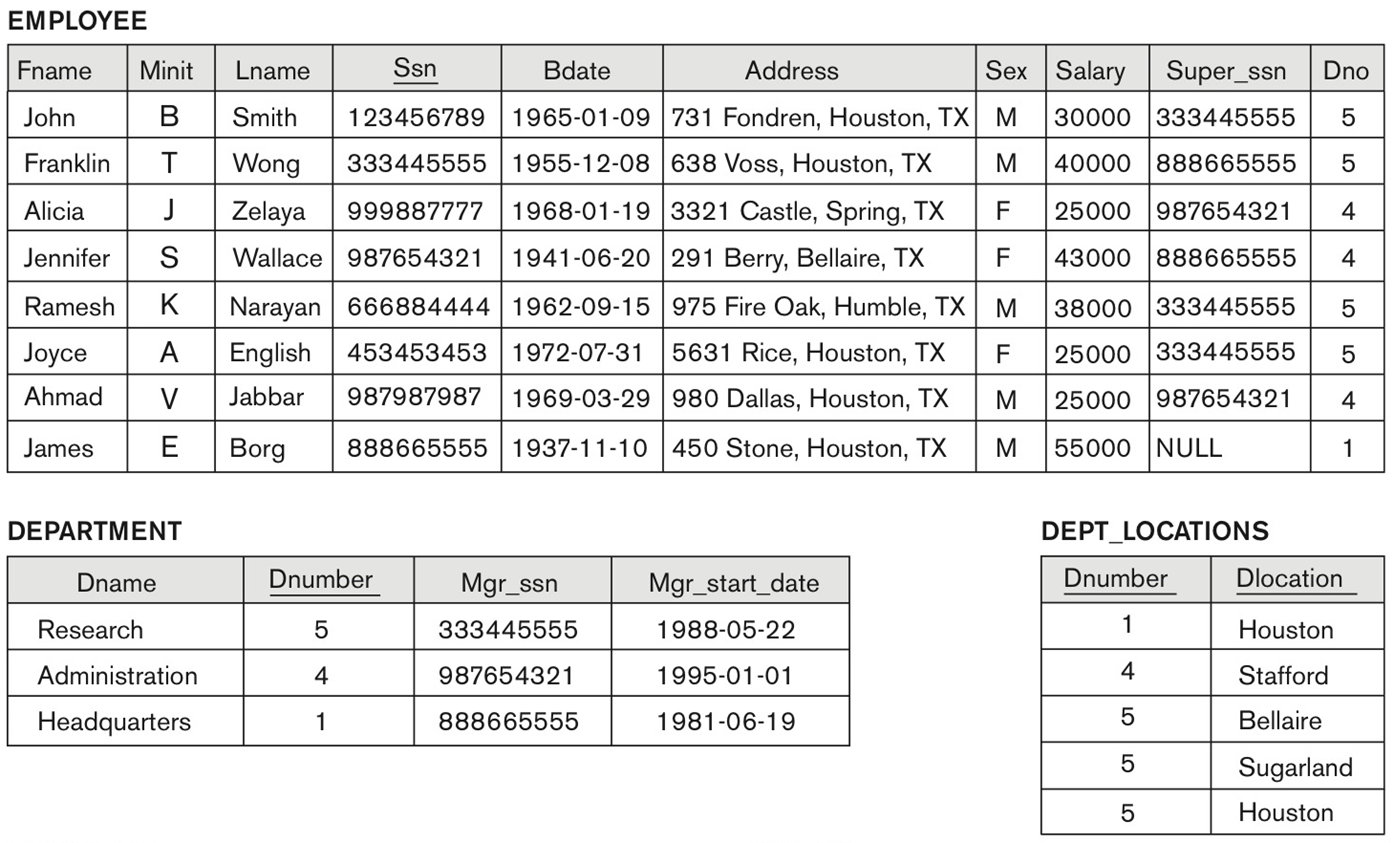
-> Populated database state for COMPANY
- Other Types of Constraints
- Semantic Integrity Constraints, 의미적 무결성 제약
- 애플리케이션의 의미에 기반한 제약
ex) "한 직원이 담당하는 모든 프로젝트의 주당 총 근무 시간은 최대 56시간으로 제한된다."
-
이러한 제약을 표현하기 위해 제약 명세 언어(Constraint Specification Language)가 필요할 수 있음
-> SQL-99에서는 이러한 의미적 제약을 표현하기 위해 CREATE TRIGGER와 CREATE ASSERTION 명령을 제공 -
기본 키(Keys), NULL 값 허용 여부, 후보 키(Unique in SQL), 외래 키(Foreign Keys), 참조 무결성(Referential Integrity) 등은 SQL의 CREATE TABLE 문을 통해 표현함
- Update Operations on Relations
-
INSERT a tuple
-
DELETE a tuple
-
MODIFY a tuple
-
Update operations(데이터 삽입, 삭제, 수정)은 Integrity Constraints, 무결성 제약 조건을 위반해서는 안됨
<무결성 위반이 발생한 경우 가능한 조치>
1) 제약을 위반하는 연산을 취소하기 (RESTRICT 또는 REJECT 옵션)
-> 위반을 유발하는 연산을 아예 실행하지 않음
2) 연산을 수행하되, 사용자에게 위반 사실을 알리기(inform)
-> 연산은 실행하지만 무결성 위반을 사용자에게 알림으로 전달
3) 위반을 수정하기 위해 추가 갱신을 트리거하기
-> CASCADE 옵션: 참조된 데이터가 삭제되거나 수정될 때, 연관된 데이터도 자동으로 갱신
-> SET NULL 또는 SET DEFAULT 옵션: 삭제나 수정 시, 해당 외래 키 값들을 NULL 또는 기본값(default)으로 설정4) 사용자가 지정한(user-specified) 오류 수정 루틴 실행하기
-> 위반 상황에 대해 사용자 정의 오류 수정 루틴을 실행하여 문제를 해결
<INSERT 연산이 위반할 수 있는 제약 조건>
1) 도메인 제약(Domain Constraint)
: 새 튜플에 제공된 속성 값이 해당 속성의 도메인(domain)에 속하지 않으면 발생
2) 키 제약(Key Constraint)
: 새 튜플의 키 속성 값이 이미 관계 내의 다른 튜플에 존재할 경우 발생
3) 참조 무결성(Referential Integrity)
: 새 튜플의 외래 키 값이 참조된 관계의 기본 키(primary key)에 존재하지 않을 때 발생
4) 엔터티 무결성(Entity Integrity)
: 새 튜플의 기본 키 값이 NULL일 경우 발생
<DELETE 연산이 위반할 수 있는 제약 조건>
- 참조 무결성(Referential Integrity)
: 삭제되는 튜플의 PK값이 데이터베이스 내 다른 튜플의 외래 키에서 참조되는 경우
-> 각 외래 키 제약에 대해 DB 설계 시 RESTRICT / CASCADE / SET NULL 중 하나를 지정해야 함
<MODIFY 연산이 위반할 수 있는 제약 조건>
-
기본 키(PK) 수정 시
: 기본 키를 수정하는 것은 DELETE 연산 후 INSERT 연산과 비슷하게 동작함
-> 이 경우 참조 무결성(Referential Integrity) 위반이 발생 가능
-> DELETE와 동일한 옵션을 지정해야 함 -
외래 키(FK) 수정 시
: 외래 키 값이 참조된 관계의 기본 키와 일치하지 않을 경우 참조 무결성을 위반 가능 -
일반 속성 수정 시(PK, FK아닌 속성)
-> 도메인 제약(Domain Constraint)만 위반 가능
