- Basic SQL
- SQL은 관계형 데이터베이스가 상업적으로 성공할 수 있었던 주요 이유 중 하나
<SQL 언어의 주요 기능>
- 데이터 정의(Data Definition)
: 테이블과 스키마를 생성하고 구조를 정의 (e.g., CREATE TABLE) - 데이터 조작(Data Manipulation)
: 데이터를 삽입, 수정, 삭제, 조회하는 기능을 제공 (e.g., INSERT, UPDATE, DELETE, SELECT) - 트랜잭션 제어(Transaction Control)
: 트랜잭션의 시작과 종료를 제어하고, 커밋 또는 롤백을 수행 (e.g., COMMIT, ROLLBACK) - 인덱싱(Indexing)
: 검색 성능을 향상시키기 위해 인덱스를 생성 (e.g., CREATE INDEX) - 보안 명세(Security Specification)
: 접근 권한과 사용자 인증을 설정 (e.g., GRANT, REVOKE) - 액티브 데이터베이스(Active Databases)
: 트리거와 이벤트 처리 기능을 제공 (e.g., CREATE TRIGGER) - 멀티미디어 지원(Multi-media)
: 이미지, 동영상 등 멀티미디어 데이터를 관리 - 분산 데이터베이스 지원(Distributed Databases)
: 여러 위치에 분산된 데이터베이스를 관리하고 동기화

-> Schema 생성 및 사용자에게 특정 작업에 대한 접근 권한을 부여
- CREATE TABLE Command
-
스키마 지정(선택 사항)

-
Base Table(Base Relation)
: 기본 테이블은 실제로 DBMS에 의해 생성되며, 테이블과 그 튜플들은 물리적 파일로 저장됨 -
Virtual relation(view)
: 뷰는 물리적 파일에 저장되지 않으며, 실제 데이터가 아닌 기존 테이블의 논리적 표현

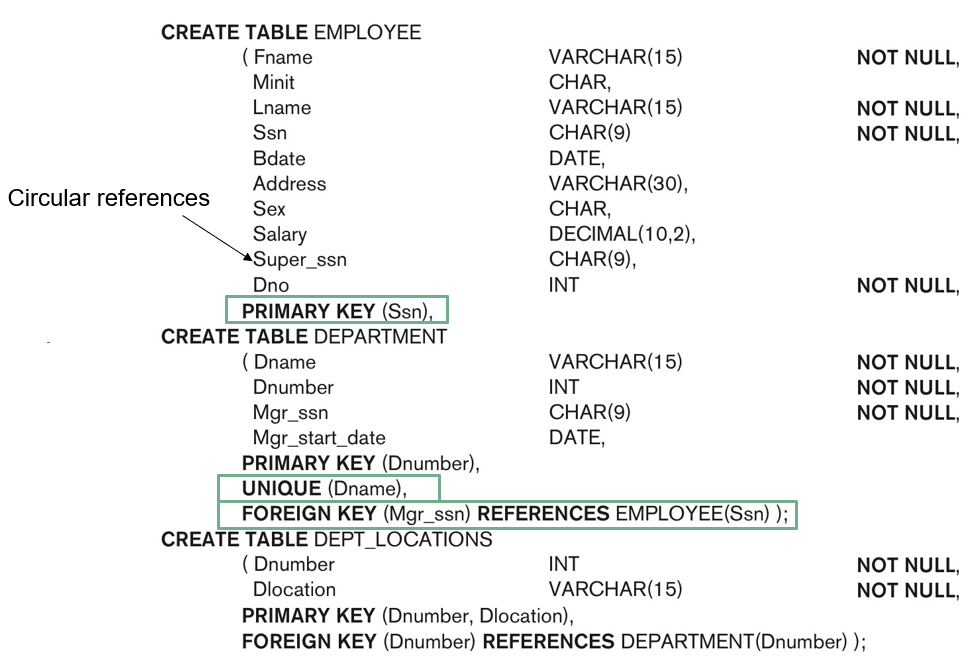
<외래 키로 인해 발생 가능한 error>
- 순환 참조(Circular References)
: 두 테이블이 서로를 외래 키로 참조할 때 발생 - 아직 생성되지 않은 테이블(ghost table)을 참조
: 외래 키가 존재하지 않는 테이블을 참조할 경우
<해결 방법>
- DBA(DB관리자)가 처음에는 외래 키를 명시하지 않고, 나중에 ALTER TABLE 문(수정 명령어)을 사용해서 외래키 추가
- Attribute Data Types and Domains
< Basic Data types>
- 숫자 데이터 타입(Numeric data type)
- 정수(Integer) 타입: INTEGER, INT, SMALLINT
- 실수(Floating-point) 타입: FLOAT 또는 REAL, DOUBLE PRECISION
- 문자열 데이터 타입(Character-string data type)
- 고정 길이 문자열(Fixed Length): CHAR(n), CHARACTER(n)
-> 정확히 n개의 문자로 구성된 문자열 (빈 공간은 공백으로 채워짐) - 가변 길이 문자열(Varying Length): VARCHAR(n), CHAR VARYING(n), CHARACTER VARYING(n)
-> 최대 n개의 문자를 저장할 수 있으며, 실제 문자열의 길이에 따라 저장 공간이 달라짐
- 비트 문자열 데이터 타입(Bit-String data type)
- 고정 길이 비트 문자열(Fixed Length): BIT(n)
-> 정확히 n개의 비트를 저장 - 가변 길이 비트 문자열(Varying Length): BIT VARYING(n)
-> 최대 n개의 비트를 저장하며, 비트 수에 따라 길이가 달라짐
- Boolean data type
- TRUE, FALSE, 또는 NULL 값을 가짐
- 날짜 데이터 타입(Date data type)
- 10자리로 구성
- user defined type의 개념을 가짐
구성 요소: YEAR(년), MONTH(월), DAY(일)이며, YYYY-MM-DD 형식으로 저장
< Additional Data Types>
- Timestamp data type
- DATE와 TIME 필드를 포함하며, 최소 6자리 소수 초까지 포함
ex) TIMESTAMP '2014-09-27 09:12:47.648302'
- INTERVAL data type
- 두 시간 또는 날짜 간의 차이를 나타내거나, 상대적인 시간 값을 지정하며, 이를 사용해 날짜(Date), 시간(Time), 타임스탬프(Timestamp)의 절대 값을 증가 또는 감소시킬 수 있음
-> DATE, TIME, TIMESTAMP, INTERVAL 데이터 타입은 문자열 형식으로 변환(cast or convert)하여 비교에 사용할 수 있음
- Domain
: 스키마의 가독성을 높여줌
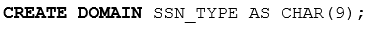
- User Defined Types, UDTs
: 객체 지향 애플리케이션에서 사용자 정의 타입을 지원

-> MySQL에서는 지원X
- Specifying Constraints in SQL
<관계형 모델의 3가지 기본 제약 조건>
1) 키 제약 (Key Constraint): 기본 키(primary key) 값은 중복될 수 없음
2) 엔터티 무결성 제약 (Entity Integrity Constraint): 기본 키 값은 NULL일 수 없음
3) 참조 무결성 제약 (Referential Integrity Constraint): 외래 키(Foreign Key) 값은 이미 존재하는 기본 키 값이어야 하며, 또는 NULL일 수 있음
<Attribute Domains에 대한 기타 제약>
-
DEFAULT
: 속성에 대한 기본값을 지정함

-
NOT NULL
: 특정 속성에 NULL값이 허용X -
CHECK 절
: 속성 값이 특정 조건을 만족해야 함

-
PRIMARY KEY 절

-
UNIQUE 절
: 대체 키(Candidate Key, Secondary Key) 지정

- FOREIGN 절
: 기본 동작: 제약 조건 위반 시 갱신(UPDATE)을 거부
: 참조 무결성 제약에 대해 트리거된 액션 절(referential triggered action clause)을 추가
사용 가능한 옵션: SET NULL, CASCADE, SET DEFAULT
- CONSTRAINT 키워드
: CONSTRAINT 키워드를 사용하면 제약 조건에 이름을 지정할 수 있음, 추후 제약 조건을 수정하거나 삭제할 때 유용

- Basic Retrieval Queries in SQL
- SELECT 문
: DB의 정보를 조회하는 기본 명령문
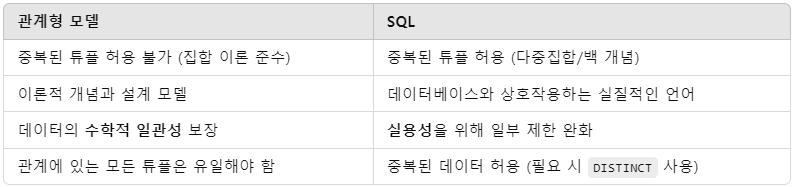
<관계형 모델과 SQL의 차이점>
-
SQL: 하나의 테이블에 모든 속성 값이 동일한 2개 이상의 튜플 존재 가능
-> SQL에서는 Multiset or bag 동작을 지원하여 중복 데이터를 허용함
-> 테이블에서 중복 튜플을 구분하기 위해 Tuple-id를 key로 사용할 수 있음 -
관계형 모델: Set Theory(집합 이론)에 기반하므로 중복된 튜플은 허용 X
- SELECT-FROM-WHERE Structure

-
논리 비교 연산자
: =, <, <=, >, >=, and <>(다르다) -
Projection Attributes, 프로젝션 속성
: 조회할 때 가져올 속성들의 값
ex) SELECT Name, Age FROM EMPLOYEE;
여기서 Name과 Age가 프로젝션 속성 -
Selection Condition, 선택 조건
: 조회된 튜플이 선택되기 위해 참이어야 하는 boolean 조건
: join condition도 포함
ex) WHERE ~~~(선택 조건)



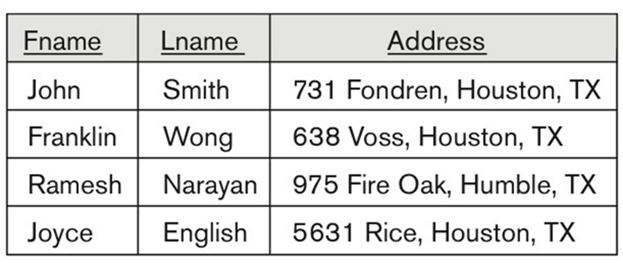


- Ambiguous Attribute Names
- 서로 다른 테이블에서 동일한 이름의 속성을 사용할 수 있음
- 단, 모호함(ambiguity)을 방지하기 위해 테이블 이름과 함께 속성 이름을 명시해야 함
-> 테이블이름.속성이름

* Aliases(= tuple variables)
- Aliases(별칭) 또는 Tuple Variables(튜플 변수)를 사용하면, 쿼리에서 동일한 테이블을 여러번 참조할 때 대체 이름을 선언 가능
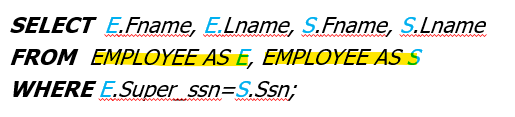
- Attribute name 또한 Alias(별칭)을 통해 별칭 부여 가능
-> 대부분의 SQL 구현체에서는 AS 키워드를 생략해도 작동

- Missing WHERE Clause, WHERE 절 생략
- WHERE 생략 시 튜플 선택에 대한 조건이 없음을 의미
-> 모든 가능한 튜플 조합이 반환됨
-> 교차곱(CROSS PRODUCT) 또는 데카르트 곱(Cartesian Product)의 결과와 동일

- Specify an asterisk ( * )
- 별표*를 사용하면 선택된 튜플의 모든 attribute 값을 조회함
-> 여러 테이블을 참조할 경우, 테이블 이름.* 형태로 사용하면 명확한 데이터 조회가 가능

- Tables as Sets in SQL
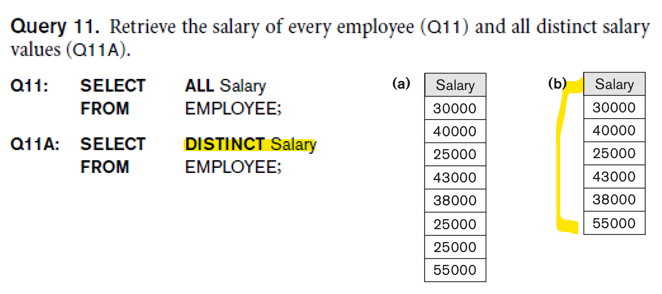
- DISTINCT 키워드
- SQL은 쿼리 결과에서 중복된 튜플을 자동으로 제거하지 않음(중복된 튜플이 포함될 수 있음)
-> 중복된 튜플을 제거하려면 SELECT 절에 DISTINCT 키워드를 사용
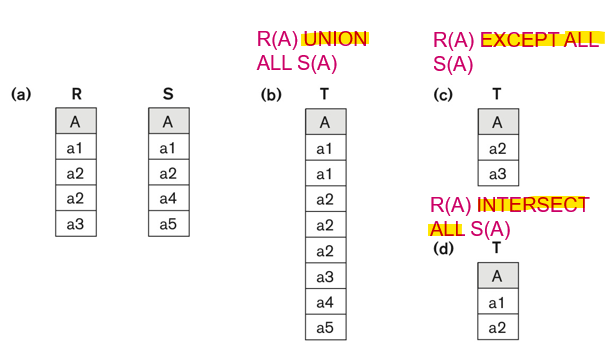
< Set Operations, 집합 연산>
- SQL에서 집합 연산은 2개 이상의 쿼리 결과를 결합하거나 교집합, 차집합을 구할 때 사용
-
UNION - 합집합
: 두 쿼리의 결과를 합집합으로 결합, 중복 튜플은 제거 -
EXCEPT(Difference) - 차집합
: 첫 번째 쿼리의 결과에서 두 번째 쿼리의 결과를 제외한 차집합을 반환
- INTERSECT - 교집합
: 두 쿼리의 결과에서 교집합만 반환
< Multiset Operations>
: 다중집합(multiset)에서는 중복된 튜플을 제거하지 않고 그대로 유지
-
UNION ALL
: 두 쿼리의 결과를 중복을 포함한 합집합으로 결합 -
EXCEPT ALL
: 첫 번째 쿼리의 결과에서 두 번째 쿼리의 결과를 모두 제거하며, 중복된 튜플도 포함 -
INTERSECT ALL
: 두 쿼리의 결과에서 중복된 공통 튜플을 모두 반환
-> Type Compatibility(타입 호환성): 집합 연산이 유효하려면, 각 쿼리의 결과 속성들이 동일한 타입을 가져야 함

- Substring Pattern Matching
* LIKE 비교 연산자
: 문자열 패턴 매칭에 사용됨
% : 0개 이상의 임의의 문자를 대체
_ : 단일 문자를 대체

-> Address 속성 값에 ‘Houston,TX’가 포함된 모든 튜플을 반환

-> Ssn 값에서 세 번째 자리가 1이고, 마지막 4자리가 8901인 모든 튜플을 반환
* BETWEEN 비교 연산자
: 범위 내의 값을 조회
-> BETWEEN A AND B: 주어진 값이 A 이상 B 이하일 때 참

- Arithmetic Operations, 산술 연산자
<기본 산술 연산자>
- 덧셈(+), 뺄셈(–), 곱셈(*), 나눗셈(/)은 SELECT 문의 일부로 포함 가능

* ORDER BY 절
: 결과를 정렬
-> 일반적으로 쿼리의 끝에 사용
-> DESC 키워드: 값을 내림차순(Descending order)으로 정렬
-> ASC 키워드: 값을 오름차순(Ascending order)으로 정렬(기본값)

<DB를 수정하는 3가지 명령어>
- INSERT
: 튜플을 테이블에 삽입

* INSERT 명령어 변형 : Bulk-loading of Several Tuples, 여러 튜플 일괄 로드 (전체 복사)
: 여러 튜플을 테이블에 일괄적으로 로드
-> 기존 테이블 T와 동일한 속성을 가진 새로운 테이블 TNEW를 생설할 수 있음
-> LIKE 와 WITH DATA 구문 사용 시 기존 데이터 전체를 새로운 테이블에 로드할 수 있음(전체 복사)


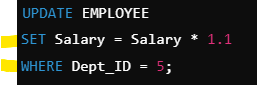
- UPDATE
: 조건을 만족하는 여러 튜플을 갱신(튜플의 속성 값을 수정)
- WHERE 절: 수정할 튜플을 선택
- SET 절: 수정할 속성과 그에 대한 새로운 값을 지정

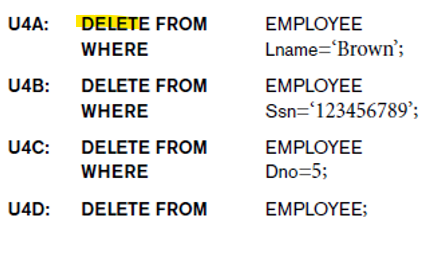
- DELETE
: 조건을 만족하는 여러 튜플을 삭제
-
WHERE 절 사용 시: 삭제할 튜플을 선택
-
WHERE 절 미사용 시: 관계의 모든 튜플이 삭제됨 -> 빈 테이블이 됨
-
튜플은 한 번에 하나의 테이블에서만 삭제 가능
-> 단, 참조 무결성 제약에서 CASCADE 옵션이 설정된 경우, 다른 테이블의 관련 튜플도 연쇄적으로 삭제됨