문자열
1. 유니코드(Unicode)
ASCII 문자
- 유니코드는 ASCII를 확장한 형태
- 영문 알파벳을 사용하는 대표적인 문자 인코딩으로 7 비트로 모든 영어 알파벳을 표현할 수 있음
- 52개의 영문 알파벳 대소문자와, 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자를 포함
- 유니코드 협회(Unicode Consortium)가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
*이 표준에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 다루기 위한 알고리즘 등이 포함됨 - 2010년도 이후 유니코드로 인코딩 방식이 통일되었기 때문에 유니코드를 사용해야 텍스트를 정확하게 저장할 수 있음
2. 인코딩
- 어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것
- 신호를 입력하는 인코딩과 문자를 해독하는 디코딩을 하기 위해서는 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 함
- 인코딩과 디코딩의 기준을 문자열 세트 또는 문자셋(charset)이라고 하는데, 이 문자셋의 국제 표준이 유니코드
3. 인코딩 방식
UTF-8과 UTF-16
- Universal Coded Character Set + Transformation Format – 8-bit
- UTF- 뒤에 등장하는 숫자는 비트(bit)를 의미
1) UTF-8
(1) 가변 길이 인코딩
// `코`라는 문자의 유니코드는 U+CF54 (16진수, HEX)로 표현
// 이를 이진법(binary number)으로 표시하면, `1100-1111-0101-0100`
// 이를 UTF-8로 표시하면, 3byte 의 결과로 표현
let encoder = new TextEncoder() // 기본 인코딩은 'utf-8'
encoder.encode('코') // Uint8Array(3) [236, 189, 148]
(236).toString(2) // "11101100"
(189).toString(2) // "10111101"
(148).toString(2) // "10010100"- UTF-8은 유니코드 한 문자를 나타내기 위해 1 byte(= 8 bits)에서 4 bytes까지 사용
*알파벳은 ASCII 코드는 7비트로 표현되고, UTF-8에서는 1 바이트만으로 표현 가능 - 사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문에 네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩
UTF-8
- ASCII 코드 : 1 byte
- 영어 외 글자 : 2 byte, 3 byte
*한글 : 3 byte- 이모지 등 보조 글자 : 4 byte
(2) 바이트 순서가 고정됨
- UTF-16에 비해 바이트 순서를 따지지 않고, 순서가 정해져 있음
2) UTF-16
// U+ABCD라는 16진수를 있는 그대로 이진법으로 변환하면 `1010-1011-1100-1101`
// 이진법으로 표현된 문자를 16 bits(2 bytes)로 그대로 사용
// 바이트 순서(엔디언)에 따라 UTF-16의 종류도 달라짐- 코드 그대로를 바이트로 표현 가능하고, 바이트 순서가 다양함
- UTF-16은 유니코드 코드 대부분(U+0000부터 U+FFFF; BMP) 을 16 bits로 표현
*기타문자는 32 bit(4 bytes)로 표현하므로 UTF-16도 가변 길이라고 할 수 있으나, 대부분은 2 바이트로 표현
UTF-8
- 한글 : 2 byte
그래픽
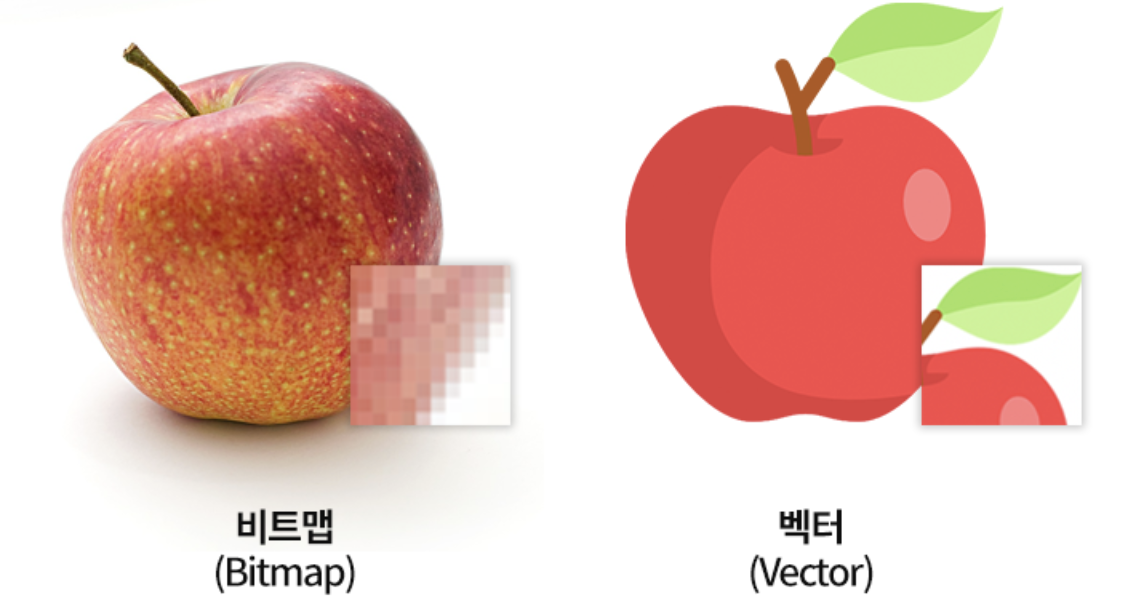
1. 비트맵(Raster)
- 기반 기술 : 픽셀 기반
- 특징 : 사진과 같이 색상의 조합이 다양한 이미지에 적합
- 확대 : 확대에 적합하지 않아 보다 큰 사이즈의 이미지가 필요할 때 사용하려는 크기 이상으로 생성하거나 스캔해야 함
- 크기에 따른 파일 용량 : 큰 크기의 이미지는 큰 파일 사이즈를 가짐
- 상호 변환 : 이미지의 복잡도에 다라 벡터로 변환하는 것에 오랜 시간이 걸림
- 대표적인 파일 포맷 : jpg, gif, png, bmp, psd
- 웹에서의 사용성 : jpg, gif, png 등이 널리 쓰임
2. 벡터
- 기반 기술 : 수학적으로 계산된 Shape 기반
- 특징 : 로고, 일러스트와 같이 제품에 적용되는 이미지에 적합
- 확대 : 품질 저하없이 모든 크기로 확대 가능하며, 해상도의 영향을 받지 않음
- 크기에 따른 파일 용량 : 큰 크기의 벡터 그래픽도 작은 파일 사이즈를 유지할 수 있음
- 상호 변환 : 쉽게 래스터 이미지로 변환 가능
- 대표적인 파일 포맷 : svg, ai
- 웹에서의 사용성 : svg 포맷은 현대의 브라우저에서 대부분 지원

✏️